

Enhancing Traceability Link Recovery with Fine-Grained Query Expansion Analysis

Abstract
:1. Introduction
- A novel approach combining fine-grained correlation analysis and query expansion to solve requirement traceability link recovery is proposed.
- The effectiveness of query expansion for improving the accuracy of requirement traceability link recovery tasks is analyzed by means of the experimental results.
- The experimental results show that our approach achieves state-of-the-art results, demonstrating the effectiveness of this approach.
2. Related Work
3. Our Approach
- (1)
- Parse the requirements and codes into fine-grained elements, according to their structures, and represent them as vectors through word embeddings.
- (2)
- Calculate the similarity between different elements.
- (3)
- Use the query expansion technique to perform secondary queries to filter the results.
- (4)
- Aggregate the fine-grained relations to obtain traceability links.
3.1. Representation
3.2. Similarity Function
3.3. Aggregation Function
3.4. Requirement Document Structure
3.5. Code Structure
3.6. Example
4. Research Design
4.1. Datasets
4.2. Methodology
5. Empirical Results
6. Threats to Validity
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gotel, O.; Finkelstein, C. An analysis of the requirements traceability problem. In Proceedings of the IEEE International Conference on Requirements Engineering, Colorado Springs, CO, USA, 18–22 April 1994; pp. 94–101. [Google Scholar] [CrossRef]
- Florez, J.M. Automated Fine-Grained Requirements-to-Code Traceability Link Recovery. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montreal, QC, Canada, 25–31 May 2019; pp. 222–225. [Google Scholar] [CrossRef]
- Falessi, D.; Di Penta, M.; Canfora, G.; Cantone, G. Estimating the Number of Remaining Links in Traceability Recovery (Journal-First Abstract). In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; Association for Computing Machinery: New York, NY, USA, 2018. ASE ’18. p. 953. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A Vector Space Model for Automatic Indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Marcus, A.; Maletic, J. Recovering documentation-to-source-code traceability links using latent semantic indexing. In Proceedings of the 25th International Conference on Software Engineering, Portland, OR, USA, 3–10 May 2003; pp. 125–135. [Google Scholar] [CrossRef]
- Asuncion, H.U.; Asuncion, A.U.; Taylor, R.N. Software Traceability with Topic Modeling. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1, Cape Town, South Africa, 1–8 May 2010; Association for Computing Machinery: New York, NY, USA, 2010. ICSE ’10. pp. 95–104. [Google Scholar] [CrossRef]
- Guo, J.; Cheng, J.; Cleland-Huang, J. Semantically Enhanced Software Traceability Using Deep Learning Techniques. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 3–14. [Google Scholar] [CrossRef]
- Guo, J.; Gibiec, M.; Cleland-Huang, J. Tackling the term-mismatch problem in automated trace retrieval. Empir. Softw. Eng. 2017, 22, 1103–1142. [Google Scholar] [CrossRef]
- Niu, H.; Keivanloo, I.; Zou, Y. Learning to rank code examples for code search engines. Empir. Softw. Eng. 2017, 22, 259–291. [Google Scholar] [CrossRef]
- Aung, T.W.W.; Huo, H.; Sui, Y. A Literature Review of Automatic Traceability Links Recovery for Software Change Impact Analysis. In Proceedings of the 28th International Conference on Program Comprehension, Seoul, Republic of Korea, 13–15 July 2020; Association for Computing Machinery: New York, NY, USA, 2020. ICPC ’20. pp. 14–24. [Google Scholar] [CrossRef]
- Mahmoud, A.; Niu, N.; Xu, S. A semantic relatedness approach for traceability link recovery. In Proceedings of the 2012 20th IEEE International Conference on Program Comprehension (ICPC), Passau, Germany, 11–13 June 2012; pp. 183–192. [Google Scholar] [CrossRef]
- Ye, X.; Bunescu, R.; Liu, C. Learning to Rank Relevant Files for Bug Reports Using Domain Knowledge. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; Association for Computing Machinery: New York, NY, USA, 2014. FSE 2014. pp. 689–699. [Google Scholar] [CrossRef]
- Moran, K.; Palacio, D.N.; Bernal-Cárdenas, C.; McCrystal, D.; Poshyvanyk, D.; Shenefiel, C.; Johnson, J. Improving the Effectiveness of Traceability Link Recovery Using Hierarchical Bayesian Networks. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June–19 July 2020; Association for Computing Machinery: New York, NY, USA, 2020. ICSE ’20. pp. 873–885. [Google Scholar] [CrossRef]
- Hey, T.; Chen, F.; Weigelt, S.; Tichy, W.F. Improving Traceability Link Recovery Using Fine-grained Requirements-to-Code Relations. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; pp. 12–22. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. arXiv 2018, arXiv:1802.06893. [Google Scholar] [CrossRef]
- Zhao, T.; Cao, Q.; Sun, Q. An Improved Approach to Traceability Recovery Based on Word Embeddings. In Proceedings of the 2017 24th Asia-Pacific Software Engineering Conference (APSEC), Nanjing, China, 4–8 December 2017; pp. 81–89. [Google Scholar] [CrossRef]
- Lohar, S.; Amornborvornwong, S.; Zisman, A.; Cleland-Huang, J. Improving Trace Accuracy through Data-Driven Configuration and Composition of Tracing Features. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, Saint Petersburg, Russia, 18–26 August 2013; Association for Computing Machinery: New York, NY, USA, 2013. ESEC/FSE 2013. pp. 378–388. [Google Scholar] [CrossRef]
- Center of Excellence for Software & Systems Traceability (CoEST)-Datasets. Available online: http://sarec.nd.edu/coest/datasets.html (accessed on 6 October 2022).
- Panichella, A.; McMillan, C.; Moritz, E.; Palmieri, D.; Oliveto, R.; Poshyvanyk, D.; De Lucia, A. When and How Using Structural Information to Improve IR-Based Traceability Recovery. In Proceedings of the 2013 17th European Conference on Software Maintenance and Reengineering, Genova, Italy, 5–8 March 2013; pp. 199–208. [Google Scholar] [CrossRef]
- Kuang, H.; Mäder, P.; Hu, H.; Ghabi, A.; Huang, L.; Lü, J.; Egyed, A. Can method data dependencies support the assessment of traceability between requirements and source code? J. Softw. Evol. Process 2015, 27, 838–866. [Google Scholar] [CrossRef]
- Yang, Y.; Xia, X.; Lo, D.; Bi, T.; Grundy, J.; Yang, X. Predictive Models in Software Engineering: Challenges and Opportunities. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–72. [Google Scholar] [CrossRef]
- Ruan, H.; Chen, B.; Peng, X.; Zhao, W. DeepLink: Recovering issue-commit links based on deep learning. J. Syst. Softw. 2019, 158, 110406. [Google Scholar] [CrossRef]
- Chen, L.; Wang, D.; Wang, J.; Wang, Q. Enhancing Unsupervised Requirements Traceability with Sequential Semantics. In Proceedings of the 2019 26th Asia-Pacific Software Engineering Conference (APSEC), Putrajaya, Malaysia, 2–5 December 2019; pp. 23–30. [Google Scholar] [CrossRef]
- Mills, C.; Escobar-Avila, J.; Bhattacharya, A.; Kondyukov, G.; Chakraborty, S.; Haiduc, S. Tracing with Less Data: Active Learning for Classification-Based Traceability Link Recovery. In Proceedings of the 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME), Cleveland, OH, USA, 29 September–4 October 2019; pp. 103–113. [Google Scholar] [CrossRef]
- Mills, C.; Escobar-Avila, J.; Haiduc, S. Automatic Traceability Maintenance via Machine Learning Classification. In Proceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 369–380. [Google Scholar] [CrossRef]
- Prause, C.R. Maintaining Fine-Grained Code Metadata Regardless of Moving, Copying and Merging. In Proceedings of the 2009 Ninth IEEE International Working Conference on Source Code Analysis and Manipulation, Edmonton, AB, Canada, 20–21 September 2009; pp. 109–118. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
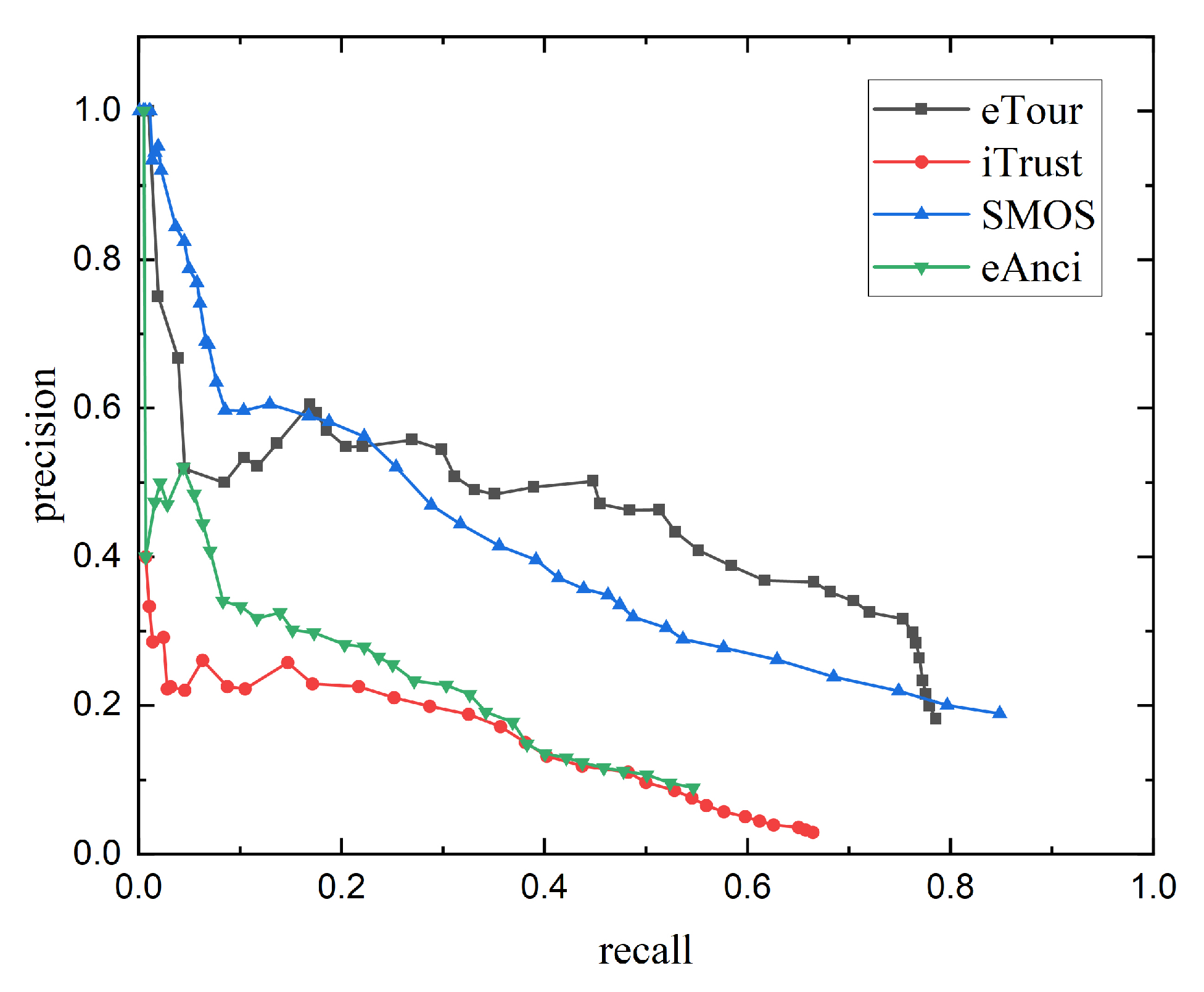{kind=link}
| Project | Domain | Language | Source Code | Source Artifacts | Covered Source | Target Artifacts | Covered Target | Links | Source/ Target |
|---|---|---|---|---|---|---|---|---|---|
| eTour | Tourism | EN/IT | JAVA | 58 | 0.983 | 116 | 0.767 | 308 | 0.50 |
| iTrust | Healthcare | EN | JAVA | 131 | 0.802 | 226 | 0.385 | 286 | 0.58 |
| SMOS | Education | EN/IT | JAVA | 67 | 1.000 | 100 | 0.684 | 1044 | 0.67 |
| eAnci | Governance | EN | JAVA | 139 | 0.281 | 55 | 1.000 | 567 | 2.53 |
| Project | Method | Precision | Recall | Threshold | k | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ORG | OPT | ORG | OPT | ORG | OPT | Improve | Maj | Final | |||
| eTour | FTLR | 0.405 | 0.456 | 0.565 | 0.516 | 0.472 | 0.484 | 0.012 | 0.59 | 0.42 | - |
| FQETLR | 0.397 | 0.476 | 0.610 | 0.516 | 0.481 | 0.495 | 0.014 | 0.57 | 0.41 | 1 | |
| iTrust | FTLR | 0.180 | 0.231 | 0.322 | 0.273 | 0.231 | 0.250 | 0.19 | 0.54 | 0.44 | - |
| FQETLR | 0.171 | 0.256 | 0.357 | 0.294 | 0.232 | 0.274 | 0.042 | 0.54 | 0.42 | 2 | |
| SMOS | FTLR | 0.451 | 0.370 | 0.288 | 0.455 | 0.352 | 0.408 | 0.056 | 0.62 | 0.48 | - |
| FQETLR | 0.444 | 0.402 | 0.317 | 0.416 | 0.370 | 0.409 | 0.039 | 0.62 | 0.46 | 4 | |
| eAnci | FTLR | 0.294 | 0.240 | 0.220 | 0.282 | 0.252 | 0.259 | 0.007 | 0.58 | 0.48 | - |
| FQETLR | 0.265 | 0.233 | 0.236 | 0.303 | 0.250 | 0.264 | 0.014 | 0.57 | 0.48 | 4 | |
| Approach | eTour | iTrust | SMOS | eAnci | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | MAP | Pre | Rec | MAP | Pre | Rec | MAP | Pre | Rec | MAP | ||||||
| FTLR | 0.287 | 0.455 | 0.352 | 0.330 | 0.151 | 0.297 | 0.200 | 0.227 | 0.417 | 0.140 | 0.209 | 0.398 | 0.215 | 0.125 | 0.158 | 0.142 | 0.230 |
| FQETLR | 0.286 | 0.510 | 0.366 | 0.328 | 0.157 | 0.336 | 0.214 | 0.23 | 0.423 | 0.180 | 0.253 | 0.409 | 0.242 | 0.178 | 0.205 | 0.143 | 0.260 |
| +cd | 0.307 | 0.445 | 0.363 | 0.339 | 0.144 | 0.255 | 0.184 | 0.214 | 0.420 | 0.138 | 0.208 | 0.399 | 0.226 | 0.127 | 0.163 | 0.142 | 0.229 |
| *+cd | 0.286 | 0.506 | 0.366 | 0.339 | 0.155 | 0.297 | 0.204 | 0.216 | 0.419 | 0.172 | 0.244 | 0.410 | 0.249 | 0.176 | 0.206 | 0.144 | 0.255 |
| +mc | 0.282 | 0.451 | 0.347 | 0.275 | 0.176 | 0.353 | 0.235 | 0.266 | 0.439 | 0.155 | 0.229 | 0.420 | 0.227 | 0.185 | 0.204 | 0.148 | 0.254 |
| *+mc | 0.277 | 0.503 | 0.358 | 0.281 | 0.168 | 0.381 | 0.233 | 0.271 | 0.438 | 0.193 | 0.268 | 0.432 | 0.228 | 0.247 | 0.237 | 0.148 | 0.274 |
| +uct | 0.398 | 0.620 | 0.485 | 0.523 | 0.151 | 0.297 | 0.200 | 0.227 | 0.426 | 0.277 | 0.336 | 0.418 | 0.306 | 0.194 | 0.237 | 0.146 | 0.315 |
| *+uct | 0.390 | 0.646 | 0.487 | 0.531 | 0.157 | 0.336 | 0.214 | 0.230 | 0.422 | 0.313 | 0.360 | 0.425 | 0.294 | 0.213 | 0.247 | 0.146 | 0.327 |
| +mc+cd | 0.273 | 0.432 | 0.335 | 0.277 | 0.180 | 0.322 | 0.231 | 0.258 | 0.438 | 0.145 | 0.217 | 0.418 | 0.242 | 0.183 | 0.209 | 0.149 | 0.229 |
| *+mc+cd | 0.278 | 0.497 | 0.356 | 0.284 | 0.171 | 0.357 | 0.232 | 0.260 | 0.445 | 0.181 | 0.257 | 0.432 | 0.226 | 0.238 | 0.232 | 0.149 | 0.269 |
| +uct+cd | 0.411 | 0.623 | 0.495 | 0.516 | 0.144 | 0.255 | 0.184 | 0.214 | 0.439 | 0.277 | 0.340 | 0.421 | 0.314 | 0.194 | 0.240 | 0.146 | 0.315 |
| *+uct+cd | 0.402 | 0.649 | 0.497 | 0.518 | 0.155 | 0.297 | 0.204 | 0.216 | 0.426 | 0.307 | 0.357 | 0.426 | 0.305 | 0.212 | 0.250 | 0.145 | 0.327 |
| +uct+mc | 0.390 | 0.568 | 0.462 | 0.477 | 0.176 | 0.353 | 0.235 | 0.266 | 0.443 | 0.297 | 0.356 | 0.442 | 0.270 | 0.215 | 0.239 | 0.150 | 0.323 |
| *+uct+mc | 0.383 | 0.61 | 0.471 | 0.469 | 0.168 | 0.381 | 0.233 | 0.271 | 0.437 | 0.327 | 0.374 | 0.451 | 0.260 | 0.240 | 0.250 | 0.148 | 0.332 |
| +uct+mc+cd | 0.405 | 0.565 | 0.472 | 0.471 | 0.180 | 0.322 | 0.231 | 0.258 | 0.451 | 0.288 | 0.352 | 0.442 | 0.294 | 0.220 | 0.252 | 0.150 | 0.327 |
| *+uct+mc+cd | 0.397 | 0.610 | 0.481 | 0.472 | 0.171 | 0.357 | 0.232 | 0.260 | 0.444 | 0.317 | 0.370 | 0.451 | 0.265 | 0.236 | 0.250 | 0.150 | 0.333 |
| Approach | eTour | iTrust | SMOS | eAnci | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | MAP | Pre | Rec | MAP | Pre | Rec | MAP | Pre | Rec | MAP | |||||
| S2Trace | 0.101 | 0.364 | 0.158 | - | 0.196 | 0.417 | 0.267 | - | - | - | - | - | - | - | - | - |
| COMET | 0.412 | 0.464 | 0.437 | 0.467 | 0.361 | 0.231 | 0.282 | 0.252 | 0.166 | 0.816 | 0.276 | 0.293 | - | - | - | - |
| FTLR | 0.405 | 0.565 | 0.472 | 0.471 | 0.18 | 0.322 | 0.231 | 0.258 | 0.451 | 0.288 | 0.352 | 0.442 | 0.294 | 0.220 | 0.252 | 0.150 |
| FQETLR | 0.397 | 0.610 | 0.481 | 0.472 | 0.171 | 0.357 | 0.232 | 0.260 | 0.444 | 0.317 | 0.370 | 0.451 | 0.265 | 0.236 | 0.250 | 0.150 |
| WQI | 0.088 | 0.415 | 0.145 | - | 0.198 | 0.322 | 0.245 | - | - | - | - | - | - | - | - | - |
| ALCATRAL | 0.425 | 0.427 | 0.425 | - | 0.504 | 0.228 | 0.309 | - | 0.513 | 0.444 | 0.476 | - | - | - | - | - |
| TRAIL | 0.572 | 0.65 | 0.608 | - | 0.568 | 0.658 | 0.609 | - | 0.871 | 0.735 | 0.797 | - | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, T.; She, K.; Shen, Y.; Xu, X.; Yu, Y. Enhancing Traceability Link Recovery with Fine-Grained Query Expansion Analysis. Information 2023, 14, 270. https://doi.org/10.3390/info14050270
Peng T, She K, Shen Y, Xu X, Yu Y. Enhancing Traceability Link Recovery with Fine-Grained Query Expansion Analysis. Information. 2023; 14(5):270. https://doi.org/10.3390/info14050270
Chicago/Turabian StylePeng, Tao, Kun She, Yimin Shen, Xiangliang Xu, and Yue Yu. 2023. "Enhancing Traceability Link Recovery with Fine-Grained Query Expansion Analysis" Information 14, no. 5: 270. https://doi.org/10.3390/info14050270