
Prediction of Road Traffic Accidents on a Road in Portugal: A Multidisciplinary Approach Using Artificial Intelligence, Statistics, and Geographic Information Systems

 , , , , , , ,
, , , , , , ,  , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
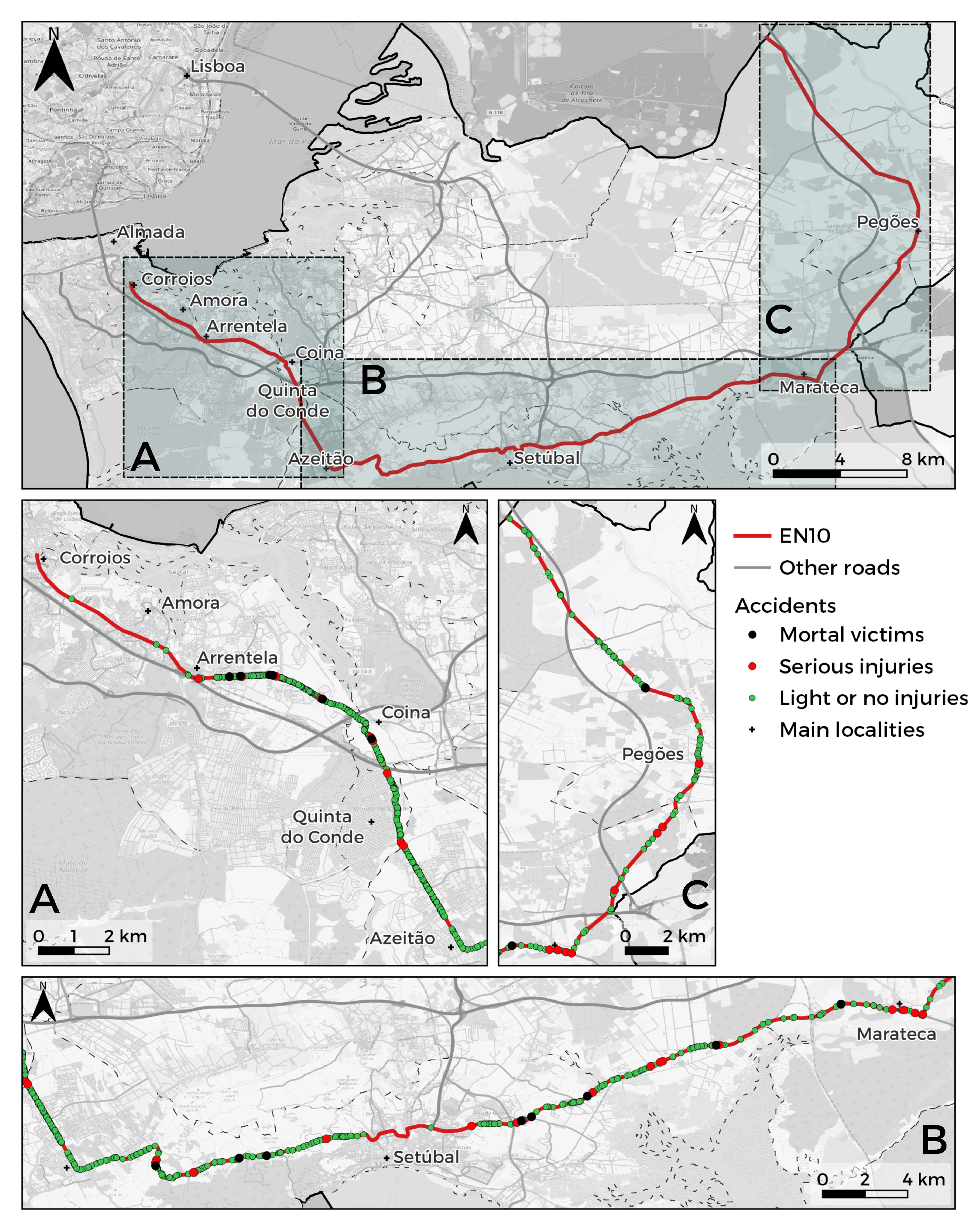
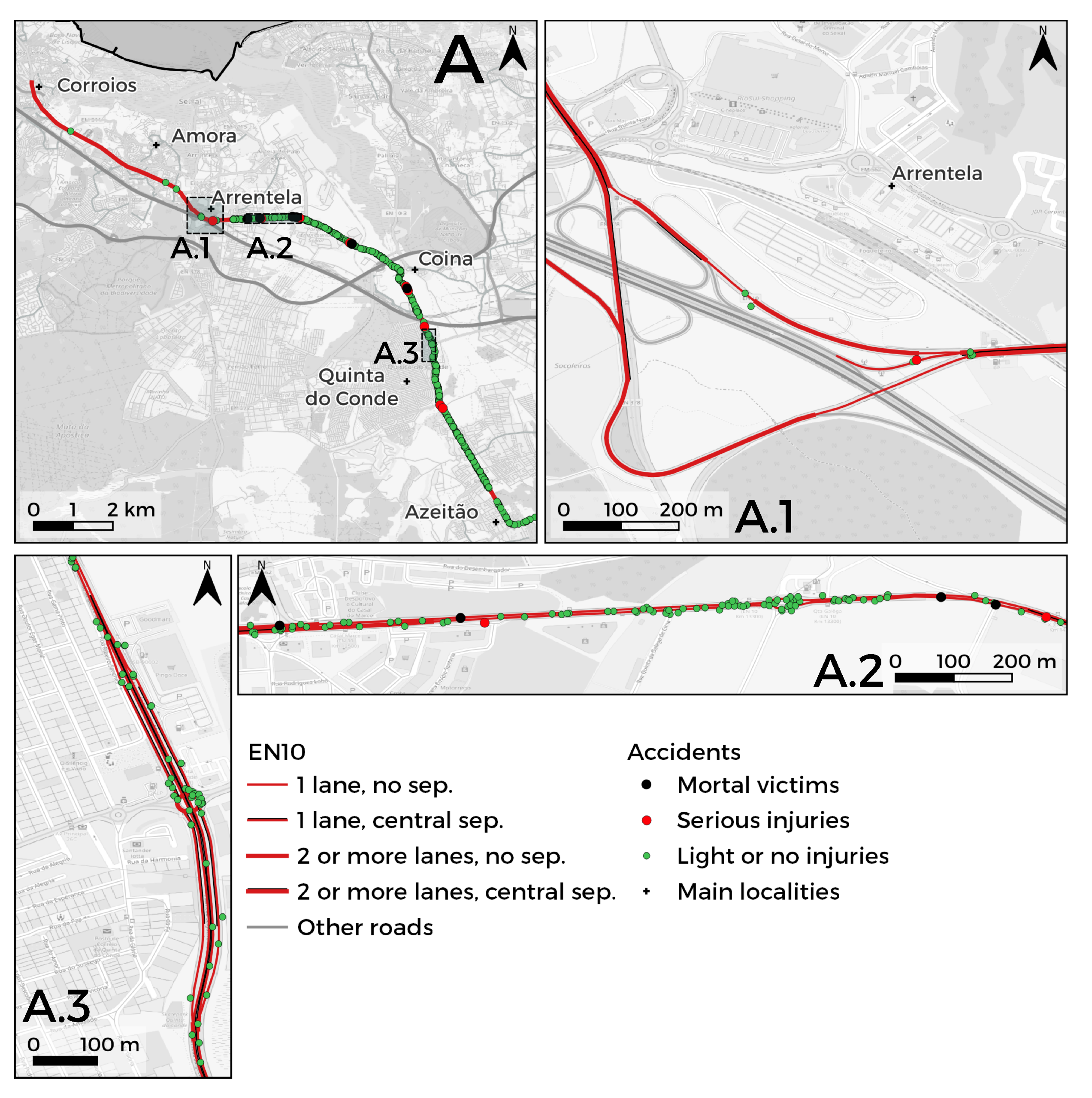
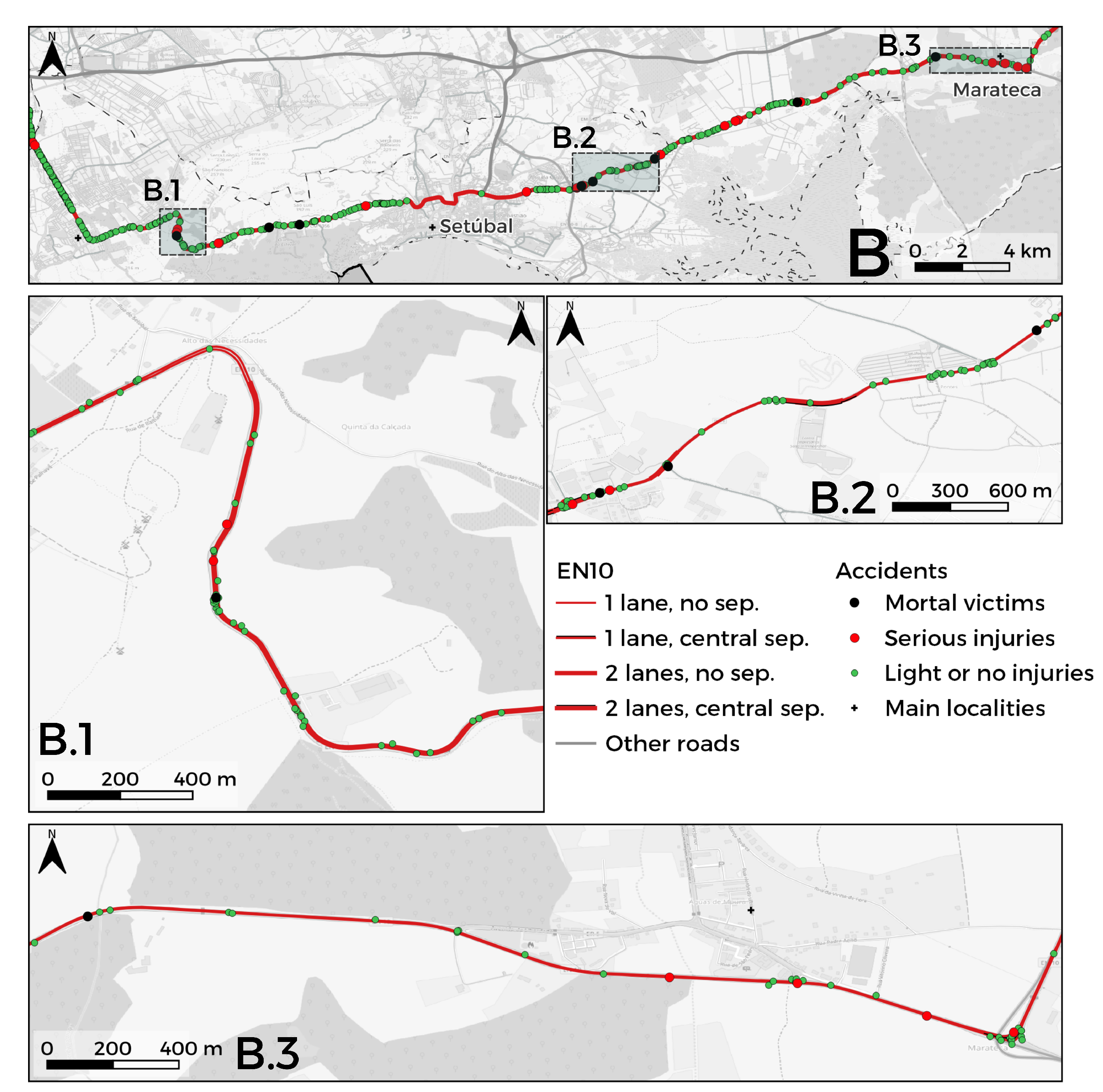
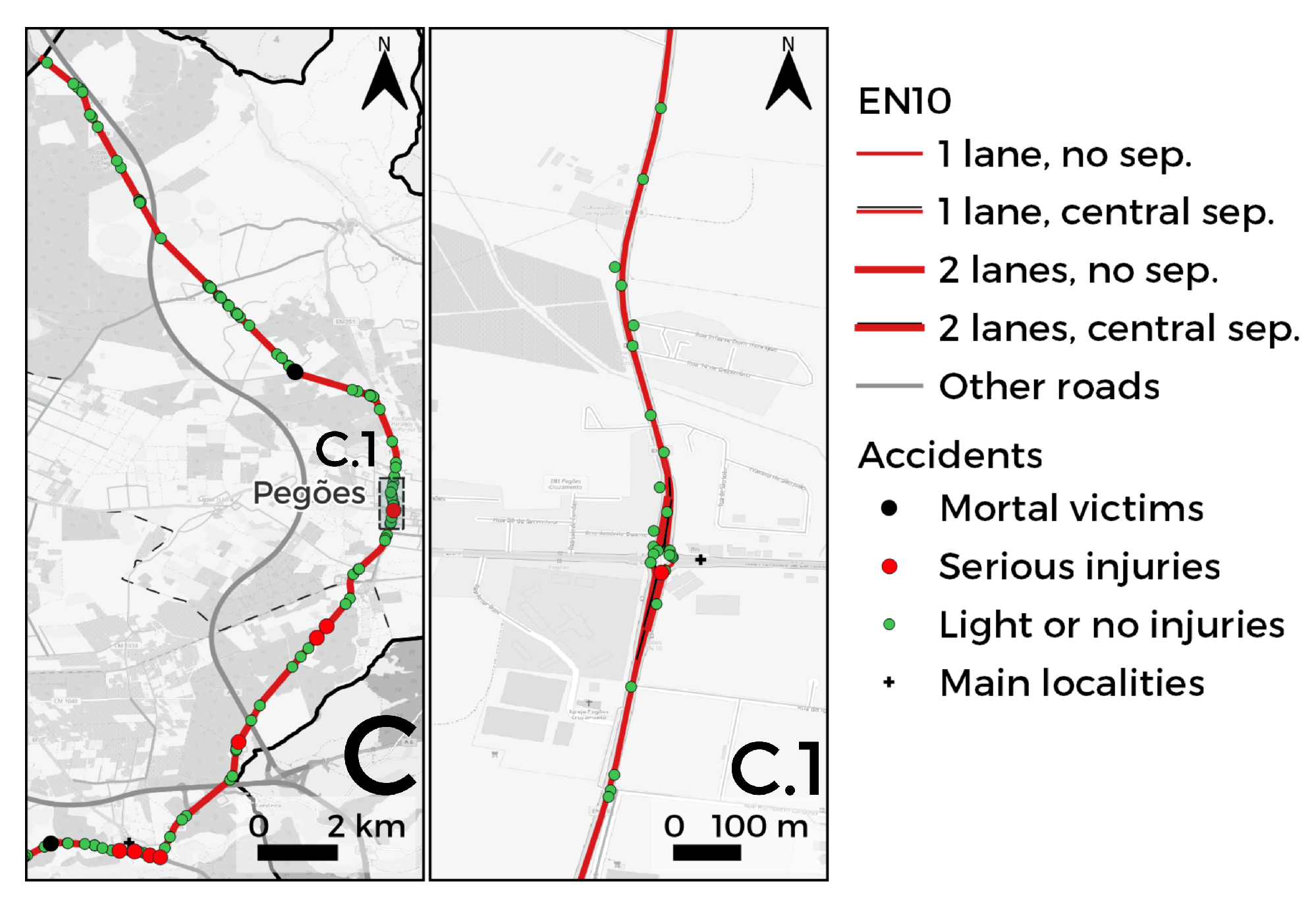
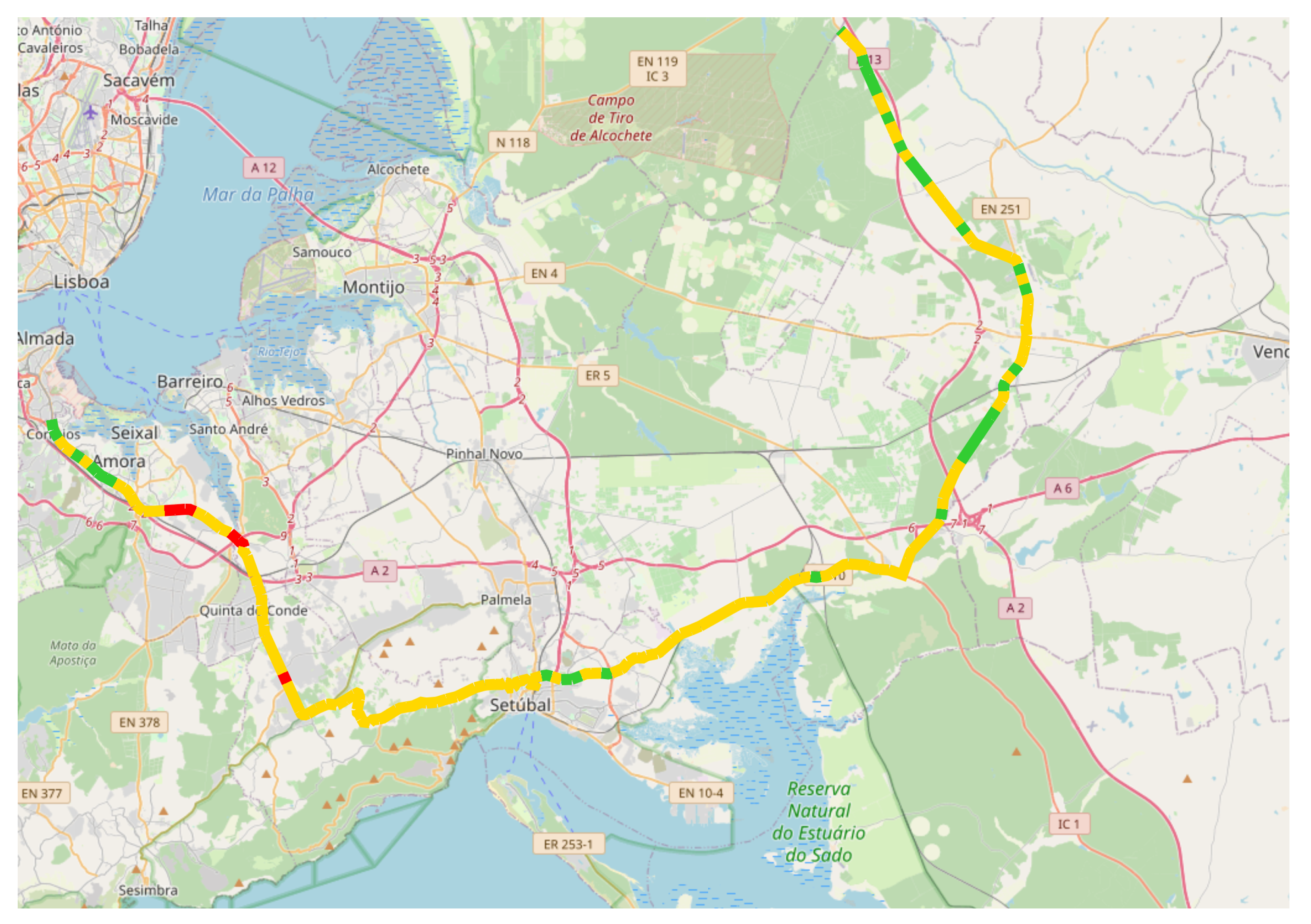
3.1. Study Area
3.1.1. Section A: Northwest-Southeast
3.1.2. Section B: West-East
3.1.3. Section C: South-North
3.2. Segmentation of the EN10
3.3. Data
- fatality: victim who dies;
- severe injury: victim whose bodily injury requires hospitalization for more than 24 h and who does not die within 30 days of the accident;
- minor injury: victim whose bodily injury did not require hospitalization, or whose hospitalization has been less than 24 h, and who does not die within 30 days of the accident.
- Road characteristics: segment id (factor variable with categories between 1 and 172 when segments of 500 m are considered, and between 1 and 45 when segments with 2000 m are considered); road layout (curve or straight road); type of road intersection (an intersection, a junction, an entrance connecting branch, a roundabout or outside a road intersection); the number of lanes (1 or 2); quality of pavement classification (categorical variable with 12 categories); type of roadside (segment with paved, unpaved or non-existence roadside); the existence of a tunnel/bridge in the segment and the number of trees in the segment;
- Atmospheric conditions: precipitation, temperature; wind speed; and if is sunny/rainy at a given hour;
- Temporal characteristics: year, month, day of the week, hour, holiday, and if it is a school day;
- Road signals: number of vertical signs; giving away priority signs, complementary signs, confirmation signs, turn signs, information signs, proximity of a locality sign, obligation signs, danger signs, pre-signalling signs, prohibition signs, some other kind of signs, the lane selection and the route allocation signs;
- Velocity information: the speed limit on that segment, and the historical values of the average speed on the segment, in Km/h (given by Waze–https://www.waze.com/pt-PT/live-map/, (accessed on 30 January 2022).
3.4. Negative Samples Generation
3.5. Machine Learning Models
3.6. Models Fitting
- RNS approach: after the pre-processing phase, a random sample of the negative samples is obtained such that the majority class has four times more cases than the minority class. The training dataset has now 1114 entries with RTA and 4416 without RTA. The LR uses a 10-fold cross-validation. The C5.0 uses 20 boosting iterations and a rules model. For the RF, the number of variables randomly collected to be sampled at each split time was 255, with a 10-fold cross-validation.
- DNS approach: same procedure as in the random sampling approach, but in the RF the number of variables randomly collected to be sampled at each split time was 128, with a 10-fold cross-validation.
- ROSE approach: after the pre-processing phase and random sampling of the negative samples such that the majority class has four times more cases than the minority class, the minority class was oversampled using the ROSE technique. The training dataset has now 4230 entries with RTA and 4270 without accidents. The LR uses a 10-fold cross-validation, the C5.0 a 25 repetitions bootstrap with 20 trials and a rules model. In the RF, the number of variables randomly collected to be sampled at each split time was 128, with a 10-fold cross-validation.
- RNS approach: The number of variables randomly collected to be sampled at each split time was 127;
- DNS approach: The RF the number of variables randomly collected to be sampled at each split time was 64;
- ROSE approach: The RF used 64 for the number of variables randomly collected to be sampled at each split time. After the oversampling approach, the training dataset has 4175 entries with RTA and 4325 without RTA.
- RNS approach: the final test dataset had 393 entries with RTA and 1552 entries without RTA.
- DNS approach: the final dataset had 393 entries with RTA and 1552 entries without RTA.
- ROSE approach: the final dataset had 1013 entries with RTA and 928 entries without RTA.
- RNS approach: the final test dataset had 372 entries with RTA and 959 entries without RTA.
- DNS approach: the final dataset had 372 entries with RTA and 959 without RTA.
- ROSE approach: the final dataset had 972 entries with RTA and 175 entries without RTA.
4. Results
- 1139 total RTA (4% of the RTA recorded in the Setúbal district) of which 299 were with minor injuries, 29 with serious injuries and 16 with deaths.
- 954 RTA were collisions, 165 were crashes and 20 were pedestrian running-over.
- The highest number of RTA was recorded in the municipalities of Setúbal (n = 467), Seixal (n = 291) and Sesimbra (n = 126).
- The majority of RTA with victims occurred on level roads with a straight line; a large part of the pavement was recorded with good quality and in places with a paved roadside.
- About 10% of the RTA occurred at sunrise/sunset times.
- The highest number of RTA was registered during working hours (59.2%, n = 674) (i.e., between 07:00 and 20:00) and working days (72.1%, n = 821) (Monday to Friday).
- The majority of RTA involved light vehicles (833 out of 1261, 73.4%), 184 (16.2%) involved motorcycles and 118 (10.4%) involved heavy vehicles.
- In 1059 RTA at least 1 driver was subjected to alcohol control. From a total of 2005 drivers who tested for alcohol, approximately 3% of them reported a rate above the legal limits (i.e., rate above 0.5 g/L), resulting in RTA’s with 3 serious injuries and 1 death.
- 293 RTA (4% of the RTA recorded in the Setúbal district) of which were registered 92 with minor injuries, 10 with serious injuries and 2 with deaths.
- 236 RTA were collisions, 51 were crashes and 6 were pedestrian running-over.
- The highest number of RTA was recorded in the municipalities of Setúbal (n = 102), Seixal (n = 94) and Sesimbra (n = 45).
- The majority of RTA with victims occurred on level roads with a straight line; a large part of the pavement had reasonable quality and in places with a paved roadside.
- Only 8% of the RTA not occurred at sunrise/sunset times.
- The highest number of RTA was registered during working hours (79.5%, n = 233) (i.e., between 07:00 and 20:00) and working days (76.1%, n = 223) (Monday to Friday).
- The majority of RTA involved light vehicles (73.8%, n = 214), 58 (20%) involved motorcycles and 18 (6.2%) involved heavy vehicles.
- In 95 RTA, at least 1 driver was subjected to alcohol control. From a total of 170 drivers who tested for alcohol, approximately 2% of them reported a rate above the legal limits (i.e., rate above 0.5 g/L), resulting in RTA’s with 3 minor injuries.
- The EN10 road, with shorter segments, improves the discrimination measures. Therefore, for this specific road with very heterogeneous characteristics, the usage of shorter segments improves the prediction performance;
- When comparing the performance of the three approaches used to balance the RTA data, the ROSE approach performs better. Sampling the majority class, followed by an oversampling of the minority class (RTA), allowed us to obtain an approximately balanced dataset for training and testing and resulted in better prediction performance. It is noteworthy that DNS, by selecting negative cases similar to the positive cases, presents always worst results than RNS.
- The LR algorithm presents a slightly better performance than C5.0, having both much better results than the RF, either in the DNS and ROSE approaches and for both segment lengths. For the DNS approach (the one with the worst performance) the C5.0 presents better discrimination measures than the LR.
5. Discussion
6. Final Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANSR | Autoridade Nacional de Segurança Rodoviária (National Road Safety Authority) |
| BEAV | Statistical Bulletin of Road Traffic Accidents |
| DNS | Directional Negative Sampling Approach |
| EN | National Road |
| GNR | Guarda Nacional Republicana (National Republican Guard) |
| IP | Infraestruturas de Portugal (infrastructures of Portugal) |
| IPMA | Instituto Português do Mar e da Atmosfera (Portuguese Institute for Sea |
| and Atmosphere) | |
| LR | Logistic Regression |
| MCC | Matthew’s Correlation Coefficient |
| ML | Machine Learning |
| MOPREVIS | Modeling and Prediction of Road Traffic Accidents in the District of Setúbal |
| NPV | Negative Predictive Values |
| PPV | Positive Predictive Values |
| RF | Random Forest |
| RNS | Random Negative Sampling Approach |
| ROSE | Random Over-Sampling Examples |
| RTA | Road Traffic Accidents |
References
- WHO. Preventing Injuries and Violence: An Overview; Technical Report; World Health Organization: Geneva, Switzerland, 2022.
- European Commission. European Road Safety Observatory. In Annual Statistical Report on Road Safety in the EU, 2021; Technical Report; European Commission, Directorate General for Transport: Brussels, Belgium, 2022. [Google Scholar]
- Lusa. Sinistralidade Rodoviária Tem Impacto Económico e Social Negativo de 1, 2% do PIB–Governo. 2018. Available online: https://www.rtp.pt/noticias/pais/sinistralidade-rodoviaria-tem-impacto-economico-e-social-negativo-de-12-do-pib-governo_n1112193 (accessed on 25 November 2022).
- Infante, P.; Jacinto, G.; Afonso, A.; Rego, L.; Nogueira, V.; Quaresma, P.; Saias, J.; Santos, D.; Nogueira, P.; Silva, M.; et al. Comparison of statistical and machine-learning models on road traffic accident severity classification. Computers 2022, 11, 80. [Google Scholar] [CrossRef]
- Nogueira, P.; Silva, M.; Infante, P.; Nogueira, V.; Manuel, P.; Afonso, A.; Jacinto, G.; Rego, L.; Quaresma, P.; Saias, J.; et al. Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal. ISPRS Int. J. Geo-Inf. 2023, 12, 93. [Google Scholar] [CrossRef]
- Santos, D.; Saias, J.; Quaresma, P.; Nogueira, V.B. Machine learning approaches to traffic accident analysis and hotspot prediction. Computers 2021, 10, 157. [Google Scholar] [CrossRef]
- Man, C.K.; Quddus, M.; Theofilatos, A. Transfer learning for spatio-temporal transferability of real-time crash prediction models. Accid. Anal. Prev. 2022, 165, 106511. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, K.; Ma, W.; Abdel-Aty, M.; Li, L. Real-time safety analysis for expressways considering the heterogeneity of different segment types. J. Saf. Res. 2022, 80, 349–361. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Lu, J.; Liu, X.; Qu, W. A genetic programming approach for real-time crash prediction to solve trade-off between interpretability and accuracy. J. Transp. Saf. Secur. 2022. [Google Scholar] [CrossRef]
- Guo, M.; Zhao, X.; Yao, Y.; Yan, P.; Su, Y.; Bi, C.; Wu, D. A study of freeway crash risk prediction and interpretation based on risky driving behavior and traffic flow data. Accid. Anal. Prev. 2021, 160, 106328. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Q.; Xu, C.; Liu, P.; Wang, Y. Investigating the predictability of crashes on different freeway segments using the real-time crash risk models. Accid. Anal. Prev. 2021, 159, 106213. [Google Scholar] [CrossRef] [PubMed]
- Chand, A.; Jayesh, S.; Bhasi, A. Road traffic accidents: An overview of data sources, analysis techniques and contributing factors. Mater. Today Proc. 2021, 47, 5135–5141. [Google Scholar] [CrossRef]
- Silva, P.B.; Andrade, M.; Ferreira, S. Machine learning applied to road safety modeling: A systematic literature review. J. Traffic Transp. Eng. (Engl. Ed.) 2020, 7, 775–790. [Google Scholar] [CrossRef]
- Gutierrez-Osorio, C.; Pedraza, C. Modern data sources and techniques for analysis and forecast of road accidents: A review. J. Traffic Transp. Eng. (Engl. Ed.) 2020, 7, 432–446. [Google Scholar] [CrossRef]
- Hossain, M.; Abdel-Aty, M.; Quddus, M.A.; Muromachi, Y.; Sadeek, S.N. Real-time crash prediction models: State-of-the-art, design pathways and ubiquitous requirements. Accid. Anal. Prev. 2019, 124, 66–84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohammed, A.A.; Ambak, K.; Mosa, A.M.; Syamsunur, D. A review of traffic accidents and related practices worldwide. Open Transp. J. 2019, 13, 65–83. [Google Scholar] [CrossRef] [Green Version]
- Abdulhafedh, A. Road crash prediction models: Different statistical modeling approaches. J. Transp. Technol. 2017, 7, 190. [Google Scholar] [CrossRef]
- Al-Mistarehi, B.W.; Alomari, A.H.; Imam, R.; Mashaqba, M. Using Machine Learning Models to Forecast Severity Level of Traffic Crashes by R Studio and ArcGIS. Front. Built Environ. 2022, 8, 860805. [Google Scholar] [CrossRef]
- Boo, Y.; Choi, Y. Comparison of mortality prediction models for road traffic accidents: An ensemble technique for imbalanced data. BMC Public Health 2022, 22, 1476. [Google Scholar] [CrossRef]
- Brühwiler, L.; Fu, C.; Huang, H.; Longhi, L.; Weibel, R. Predicting individuals’ car accident risk by trajectory, driving events, and geographical context. Comput. Environ. Urban Syst. 2022, 93, 101760. [Google Scholar] [CrossRef]
- Dong, S.; Khattak, A.; Ullah, I.; Zhou, J.; Hussain, A. Predicting and analyzing road traffic injury severity using boosting-based ensemble learning models with SHAPley Additive exPlanations. Int. J. Environ. Res. Public Health 2022, 19, 2925. [Google Scholar] [CrossRef]
- Yan, M.; Shen, Y. Traffic Accident Severity Prediction Based on Random Forest. Sustainability 2022, 14, 1729. [Google Scholar] [CrossRef]
- Ahmed, S.; Hossain, M.A.; Bhuiyan, M.M.I.; Ray, S.K. A Comparative Study of Machine Learning Algorithms to Predict Road Accident Severity. In Proceedings of the 2021 20th International Conference on Ubiquitous Computing and Communications (IUCC/CIT/DSCI/SmartCNS), London, UK, 20–22 December 2021; pp. 390–397. [Google Scholar] [CrossRef]
- Bedane, T.T.; Assefa, B.G.; Mohapatra, S.K. Preventing Traffic Accidents through Machine Learning Predictive Models. In Proceedings of the 2021 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), Bahir Dar, Ethiopia, 22–24 November 2021; pp. 36–41. [Google Scholar] [CrossRef]
- Najafi Moghaddam Gilani, V.; Hosseinian, S.M.; Ghasedi, M.; Nikookar, M. Data-driven urban traffic accident analysis and prediction using logit and machine learning-based pattern recognition models. Math. Probl. Eng. 2021, 2021, 9974219. [Google Scholar] [CrossRef]
- Malik, S.; El Sayed, H.; Khan, M.A.; Khan, M.J. Road Accident Severity Prediction—A Comparative Analysis of Machine Learning Algorithms. In Proceedings of the 2021 IEEE Global Conference on Artificial Intelligence and Internet of Things (GCAIoT), Dubai, United Arab Emirates, 12–16 December 2021; pp. 69–74. [Google Scholar] [CrossRef]
- Assi, K. Traffic Crash Severity Prediction—A Synergy by Hybrid Principal Component Analysis and Machine Learning Models. Int. J. Environ. Res. Public Health 2020, 17, 7598. [Google Scholar] [CrossRef] [PubMed]
- Nour, M.K.; Naseer, A.; Alkazemi, B.; Jamil, M.A. Road traffic accidents injury data analytics. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 762–770. [Google Scholar] [CrossRef]
- Yassin, S.S.; Pooja. Road accident prediction and model interpretation using a hybrid K-means and random forest algorithm approach. SN Appl. Sci. 2020, 2, 1576. [Google Scholar] [CrossRef]
- Mokoatle, M.; Vukosi Marivate, D.; Michael Esiefarienrhe Bukohwo, P. Predicting road traffic accident severity using accident report data in South Africa. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai, United Arab Emirates, 18–20 June 2019; pp. 11–17. [Google Scholar] [CrossRef]
- Guerra, A.; Gadhiya, V.; Srisurin, P. Crash Prediction on Road Segments using Machine Learnings Methods. ASEAN Eng. J. 2022, 12, 27–37. [Google Scholar] [CrossRef]
- Ndume, V.A.; Rutalebwa, E.C.; Runyoro, A.A.K. Prediction of Road Accidents Trend in Tanzania Using ARIMA Model: The Road Safety Implication by 2021–2030. Int. J. Traffic Transp. Eng. 2022, 11, 1–7. [Google Scholar] [CrossRef]
- Farhan, A.; Kattan, L.; Tay, R. Collisions on local roads: Model development and policy level scenario analysis. Can. J. Civ. Eng. 2020, 47, 77–87. [Google Scholar] [CrossRef]
- Costa, J.O.; Maria, A.P.; Pereira, P.A.; Freitas, E.F.; Soares, F.E. Portuguese two-lane highways: Modelling crash frequencies for different temporal and spatial aggregation of crash data. Transport 2018, 33, 92–103. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Du, B.; Hu, X.; Sun, L.; Han, L.; Lv, W. Deep spatio-temporal graph convolutional network for traffic accident prediction. Neurocomputing 2021, 423, 135–147. [Google Scholar] [CrossRef]
- QGIS Development Team. QGIS Geographic Information System. QGIS Association. Available online: https://www.qgis.org (accessed on 30 January 2022).
- ANSR. Manual de Prenchimento. Boletim Estatístico de Acidente de Viação. 2013. Available online: http://www.ansr.pt/Estatisticas/BEAV/Documents/MANUALPREENCHIMENTOBEAV.pdf (accessed on 25 November 2022).
- Jo, T. Machine Learning Foundations: Supervised, Unsupervised, and Advanced Learning; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Gan, J.; Li, L.; Zhang, D.; Yi, Z.; Xiang, Q. An alternative method for traffic accident severity prediction: Using deep forests algorithm. J. Adv. Transp. 2020, 2020, 1257627. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Algorithms | ||||||
|---|---|---|---|---|---|---|
| Segment: 500 m | Segment: 2000 m | |||||
| Measure | LR | RF | C5.0 | LR | RF | C5.0 |
| Accuracy | 0.681 | 0.674 | 0.677 | 0.690 | 0.677 | 0.677 |
| Sensibility | 0.888 | 0.802 | 0.845 | 0.871 | 0.828 | 0.836 |
| Specificity | 0.597 | 0.622 | 0.609 | 0.620 | 0.618 | 0.615 |
| PPV | 0.472 | 0.462 | 0.467 | 0.471 | 0.457 | 0.457 |
| NPV | 0.929 | 0.885 | 0.906 | 0.925 | 0.903 | 0.906 |
| G-mean | 0.728 | 0.706 | 0.717 | 0.735 | 0.716 | 0.717 |
| F-score | 0.616 | 0.586 | 0.601 | 0.611 | 0.589 | 0.591 |
| MCC | 0.441 | 0.383 | 0.412 | 0.441 | 0.401 | 0.405 |
| AUC | 0.828 | 0.787 | 0.813 | 0.813 | 0.786 | 0.799 |
| Machine Learning Algorithms | ||||||
|---|---|---|---|---|---|---|
| Segment: 500 m | Segment: 2000 m | |||||
| Measure | LR | RF | C5.0 | LR | RF | C5.0 |
| Accuracy | 0.604 | 0.563 | 0.520 | 0.600 | 0.528 | 0.588 |
| Sensibility | 0.679 | 0.613 | 0.799 | 0.634 | 0.659 | 0.656 |
| Specificity | 0.584 | 0.551 | 0.449 | 0.591 | 0.495 | 0.571 |
| PPV | 0.293 | 0.257 | 0.269 | 0.282 | 0.248 | 0.279 |
| NPV | 0.878 | 0.849 | 0.898 | 0.865 | 0.852 | 0.868 |
| G-mean | 0.630 | 0.581 | 0.599 | 0.612 | 0.571 | 0.612 |
| F-score | 0.409 | 0.362 | 0.402 | 0.390 | 0.360 | 0.391 |
| MCC | 0.212 | 0.132 | 0.203 | 0.182 | 0.124 | 0.183 |
| AUC | 0.671 | 0.622 | 0.660 | 0.648 | 0.601 | 0.649 |
| Machine Learning Algorithms | ||||||
|---|---|---|---|---|---|---|
| Segment: 500 m | Segment: 2000 m | |||||
| Measure | LR | RF | C5.0 | LR | RF | C5.0 |
| Accuracy | 0.738 | 0.718 | 0.711 | 0.734 | 0.693 | 0.716 |
| Sensibility | 0.871 | 0.835 | 0.842 | 0.857 | 0.791 | 0.821 |
| Specificity | 0.602 | 0.616 | 0.596 | 0.606 | 0.591 | 0.607 |
| PPV | 0.691 | 0.656 | 0.646 | 0.695 | 0.669 | 0.686 |
| NPV | 0.821 | 0.810 | 0.812 | 0.802 | 0.730 | 0.764 |
| G-mean | 0.724 | 0.717 | 0.709 | 0.720 | 0.684 | 0.706 |
| F-score | 0.771 | 0.735 | 0.731 | 0.767 | 0.725 | 0.748 |
| MCC | 0.492 | 0.459 | 0.448 | 0.479 | 0.390 | 0.439 |
| AUC | 0.818 | 0.783 | 0.796 | 0.803 | 0.757 | 0.777 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Infante, P.; Jacinto, G.; Santos, D.; Nogueira, P.; Afonso, A.; Quaresma, P.; Silva, M.; Nogueira, V.; Rego, L.; Saias, J.; et al. Prediction of Road Traffic Accidents on a Road in Portugal: A Multidisciplinary Approach Using Artificial Intelligence, Statistics, and Geographic Information Systems. Information 2023, 14, 238. https://doi.org/10.3390/info14040238
Infante P, Jacinto G, Santos D, Nogueira P, Afonso A, Quaresma P, Silva M, Nogueira V, Rego L, Saias J, et al. Prediction of Road Traffic Accidents on a Road in Portugal: A Multidisciplinary Approach Using Artificial Intelligence, Statistics, and Geographic Information Systems. Information. 2023; 14(4):238. https://doi.org/10.3390/info14040238
Chicago/Turabian StyleInfante, Paulo, Gonçalo Jacinto, Daniel Santos, Pedro Nogueira, Anabela Afonso, Paulo Quaresma, Marcelo Silva, Vitor Nogueira, Leonor Rego, José Saias, and et al. 2023. "Prediction of Road Traffic Accidents on a Road in Portugal: A Multidisciplinary Approach Using Artificial Intelligence, Statistics, and Geographic Information Systems" Information 14, no. 4: 238. https://doi.org/10.3390/info14040238