We aim to provide a general approach for improving the performance of translational and bilinear KGC models by learning implicit representations of the type and type constraints of entities via unsupervised learning. Our method uses the location of an entity embedding as the entity type representation. Each relation has prototype embeddings to represent type constraints on the head and the tail. The concept of ProtoE is based on two observations: (1) entities in facts about a relation r have the same type(s) and (2) these entities tend to form cluster(s) in the feature space. Details of these two observations are described below.
and
must satisfy the type constraint in
r. That is, the head entities and tail entities with respect to a relation
r imply the type constraints in
r, and as all
and
satisfy the certain type constraints in
r,
and
can be divided into a group of subsets
Second, consider the score function and its margin for facts and false claims in bilinear and translational models. Let
be a score function in bilinear models,
and
be embeddings (vectors) of
h and
t, and
contain parameters for defining the bilinear form in
r. We can rewrite
as
to emphasize that the bilinear form
is parameterized by
. Let
be a triple of a fact and
be a triple of a false claim. The score margin is
Therefore, for bilinear models, embeddings of qualified and disqualified entities in r tend to be located at different locations in the feature space.
For translational models, let
be the score function in the form of a distance, and let
and
be the projected embeddings of the heads and tails (for TransE,
and
). Then, the score margin is
where
is a fact and
and
are false triples. Hence, entity embeddings in bilinear and translational models for a relation tend to form cluster(s) in the feature space.
ProtoE uses multiple prototype embeddings in each relation to capture the cluster(s) of the head and tail embeddings. Unlike previous works, which use only one embedding as type constraints, the prototype embeddings in ProtoE can capture multiple type constraints in relations. The locations of these prototype embeddings represent the type constraints, and the entity embeddings are calibrated based on the prototype embeddings in all relations that have corresponding entities as facts.
Figure 2 shows the general structure of ProtoE. Relations in
Figure 2 are associated with five prototype embeddings for the head and six prototype embeddings for the tail. Entity embeddings
and prototype embeddings
are used to check whether entities satisfy the type constraints in the relation. The prototype embeddings (the blue column vectors) and
are used to evaluate type compatibility. The triple plausibility of
is mainly evaluated based on the score function
in the base model. The type compatibility and the result from
are used to determine the plausibility of a triple
. Details of our method are given in the following subsections.
3.1. Prototype Embeddings
The prototype embeddings represent local areas in which entity embeddings are more likely to have a high score for relation
r. Let
,
be two prototype matrices whose column vectors are prototype embeddings of relation
r for head and tail entities, respectively.
m and
n are the numbers of prototype embeddings for the head and tail, respectively, in each relation (Theoretically, our method supports a relation-specific setting of
m and
n, i.e.,
and
for
.). Our method evaluates the compatibility of entities to
r as follows.
in Equation (
9) are entity embeddings from the base model. For complex embeddings, the real part and complex part are concatenated, that is
, and for translational models that project entity embeddings,
and
are projected embeddings. The
function is
where
is the entity embedding and
corresponds to the prototype matrix in Equation (
9).
represents column vectors (prototype embeddings) in
.
N is the number of prototype embeddings;
or
.
The essential part in Equation (
9) is the inner product between the entity embeddings and the prototype embeddings. The idea behind Equation (
9) is based on the squared distance:
The squared distance is disproportional to , so we can use as a proxy measure for type compatibility. Because entities in a relation have embeddings that tend to form clusters in the feature space, the combination of the max and softmax functions aims to associate entity embeddings to a prototype embedding to represent the cluster. As discussed at the beginning of this section, these entities are more likely to have the same type because they satisfy type constraints in multiple relations. Therefore, locations of entity embeddings are decided by the base KGC models and all data in the training set, and the locations of prototype embeddings in r are decided by the number of training data and entities that are related to r.
For some knowledge graphs, such as those whose facts are about relations between words, it is difficult to define the type on entities. In this case, the prototype embeddings lose the identity of the type indicator. They only represent the local areas that contain embeddings of entities that are more likely to be true for the relation.
We extend the score function in our method so that the entity adequacy measured by
g in Equation (
9) takes effect in the evaluation of the plausibility of a triple. The score function in our method is
is the sigmoid function. ∘ represents one of two algebra operations, namely addition (“+”) or multiplication (“×”). These two operations reflect different strategies for utilizing type information in a triple plausibility evaluation.
The addition (“+”) strategy follows “OR” logic. The candidate entities appear at the top locations of the prediction as long as the total score is large. The sigmoid function in g guarantees that the prediction will not be dominated by entities that are apparently not the answer ( is low) even if they well match the type constraint (scores from g are high).
In contrast to addition, the multiplication (“×”) operation follows “AND” logic. Entities at the top locations must have high scores from all components, namely head entity type compatibility (), interdependence of the head and tail entities (), and tail entity type compatibility (.
in Equation (
10) is a scalar hyperparameter, and
is the score function in the base KGC model. The sigmoid function
and the hyperparameter
in Equation (
10) are used to smooth scores of entity compatibility. The sigmoid function keeps the sign of the score from
unchanged, and
makes the score function in the base model (
) and the entity compatibility score (
and
) consistent, as discussed below.
In Equation (
10), the score function in the base model
should always represent the plausibility of triples. This requirement is satisfied in bilinear models. For translational models, which use distance to represent implausibility, we multiply the score function by
. Take the score function in TransR (Equation (
5)) as an example.
in Equation (
10) with TransR as the base model is
The purpose of this change is to keep the role of
and
g consistent. For a query in the form of
,
as the correct tail entity is given and it must satisfy the type constraints in
r. All entities in the knowledge graph are evaluated based on
and
to pick appropriate candidates for the missing head. Only entities that have high type compatibility (
is high) and make the triple plausible (the score from
is high) are picked as candidates. Similarly, candidates for the query
must have a high score from both
and
. Therefore, in the scenario where the base model uses distance as a measure of implausibility, the transformation by Equation (
11) guarantees that plausible triples will have a high score in
(i.e., the absolute value of
is low, as
). For the same reason, if
is transformed by Equation (
11), the smooth hyperparameter
will be in
so that if a triple
is a fact, the score
will be scaled with smaller
by
and
. For bilinear models,
.
The number of prototype embeddings (
m and
n) affects the performance of our model in link prediction. Because the number of types is unknown, it is difficult to know the explicit, appropriate
m and
n values for relations. If
m or
n is too large, prototype embeddings may split entity embeddings that should be in the same cluster into multiple clusters whose locations are far away in the feature space, and some prototype embeddings will become orphans in the feature space. As a result, prototype embeddings capture the entity type, but the locations of these entity embeddings are inappropriate for distinguishing facts and false claims related to them. If
m and
n are too small, the type compatibility from
and
will be inaccurate because the number of type constraints in relations is not well represented by the associated prototype embeddings. For knowledge graphs that contain facts about the real world,
m and
n should be large enough to capture the diverse types taken by each relation. A few orphan prototype embeddings will not affect performance because they are not associated with any location where entity embeddings are located, and the max function in Equation (
9) prevents their use in the score function in Equation (
10). For knowledge bases whose entities do not have an explicit type,
m and
n should be relatively small because prototype embeddings are not type indicators in this case.
The score function
in Equation (
10) and the function
g in Equation (
9) are used in two loss functions to learn all embeddings in the model. The following subsection gives the purpose and form of these loss functions.
3.2. Loss Functions in ProtoE
There are two loss functions in ProtoE, namely one for learning prototype, relation, and entity embeddings and the other for calibrating embedding locations.
The loss function for learning entity and relation embeddings is given in Equation (
12).
is a scalar hyperparameter. Similar to many other KGC models, we use negative sampling in loss functions and optimize entity and relation embeddings using back-propagation.
is the training data.
and
are negative examples of the fact
.
and
are corrupted entities from negative sampling.
The task of
is to learn entity and relation embeddings. The score function
is from Equation (
10). Entity and relation embeddings are learned using the score function of the base model in
in this loss function. Even though the prototype embeddings appear in
, it is insufficient to optimize these prototype embeddings using only the loss function because of the sigmoid function on
and
. Because the derivative of the sigmoid function is in the form of
, if
or
is too high or too low, the sigmoid function that wrapped them will have small gradients. As a result, the prototype and entity embeddings will barely change their locations in the back-propagation of the gradients. Note that the score function
in Equation (
10) is not wrapped by the sigmoid function, and thus, the optimization of entity and relation embeddings does not have the same problem.
Due to the problem caused by the sigmoid function, we introduce another loss function to calibrate entity and prototype embeddings:
where
is the training set and
and
are corrupted facts. The hinge loss
aims to separate entities that do not satisfy type constraints in a relation
r from the prototype embeddings in
and
. Because the functions
and
are in
, the constant 1 in the hinge loss ensures
. For entities that satisfy the type constraints,
and
are close to 1, but for negative entities that do not satisfy the type constraints,
and
may not be close to 0. With the help of the hinge loss
, the embeddings of these negative entities will be moved away from the local areas represented by prototype embeddings in the back-propagation. Furthermore, because
is the loss function that calibrates the relative locations of entity and prototype embeddings, there is no need to consider the score from base models that represent the plausibility of triples in this loss, so the sigmoid function used in Equation (
10) is no longer needed. The avoidance of the sigmoid function allows gradients back-propagated to prototype and entity embeddings by
to not perish.
Both
and
are used in the learning of entity embeddings, but they utilize training data using different approaches.
does not distinguish the training data, while
is computed over relations iteratively. Because
adjusts embeddings to distinguish facts
and corrupted triples
and
,
adjusts entity and prototype embeddings to capture type constraints in relations. There are cases where entities in corrupted triples satisfy the type constraints, but the triples themselves are not facts, e.g.,
(Tokyo, is-located-in, the U.K.), (London, is-located-in, Japan). If we optimize parameters by joining the loss as
, it may cause the model to over-fit and fail to distinguish corrupted triples from facts because the entity embeddings will be too close to prototype embeddings, resulting in a small score margin (cf. discussion at the beginning of
Section 3 about the score margin of bilinear and translational models). To prevent such over-fitting,
and
are used in the optimization using different strategies.
is used in each epoch during the training and
is used only every
T epochs with a different learning rate. The learning rates
and
are different, where
. The effects of loss functions on embeddings in the optimization are explained in
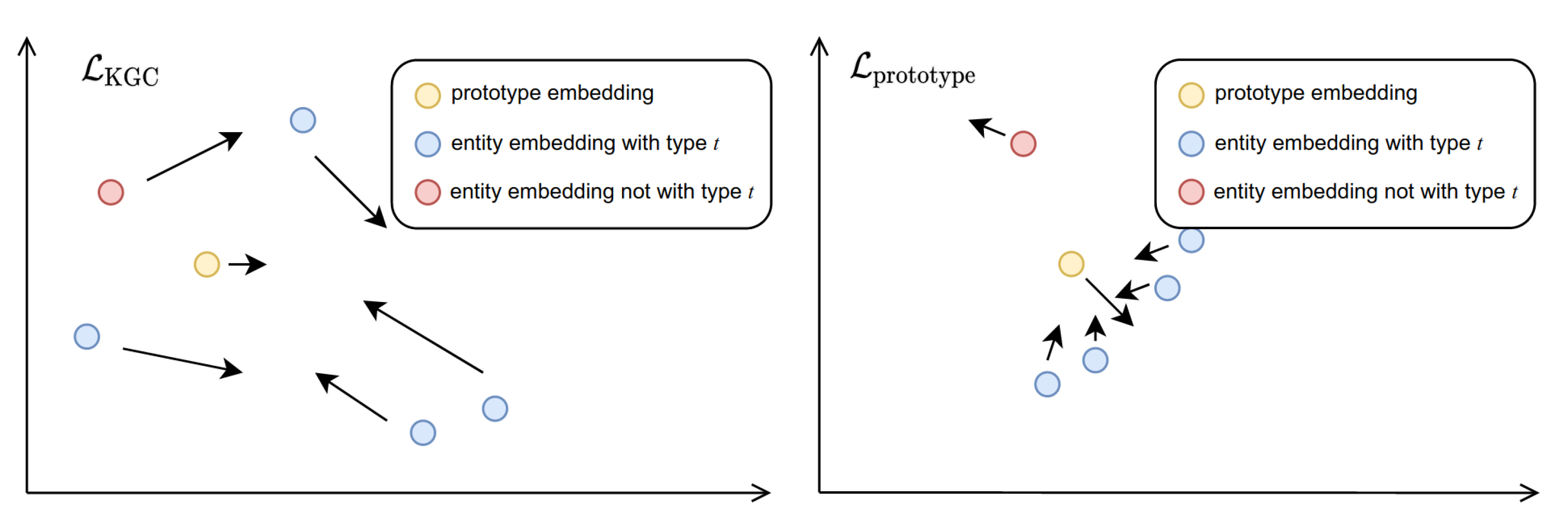
Figure 3. The procedure of adjusting entity and prototype embeddings by
and
is shown on the left and right, respectively. The yellow point is the prototype embedding for type
x. Blue points are entity embeddings whose type is represented by the prototype embedding. The red point is an entity embedding whose type should not be represented by the prototype embedding. Arrows represent the movement directions of embeddings by the gradients in the optimization. The figure on the left shows the accumulated adjustment from
in
T epochs. Due to the gradients from the sigmoid function in
, the offset of prototype embeddings is not as significant as that for entity embeddings. The right figure shows the calibration of embeddings from gradients by
at the
T-th epoch. Because of the different learning rates for these two loss functions, offsets from
are not as significant as those in the left figure, but the movement directions are more toward the location in which the prototype embeddings are located.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}