
Sequential Normalization: Embracing Smaller Sample Sizes for Normalization



Abstract
:1. Introduction
1.1. Related Work
2. Methodology
2.1. Formulation
2.2. The Effects of Ghost Normalization
2.2.1. GhostNorm to BatchNorm
2.2.2. GhostNorm to GroupNorm
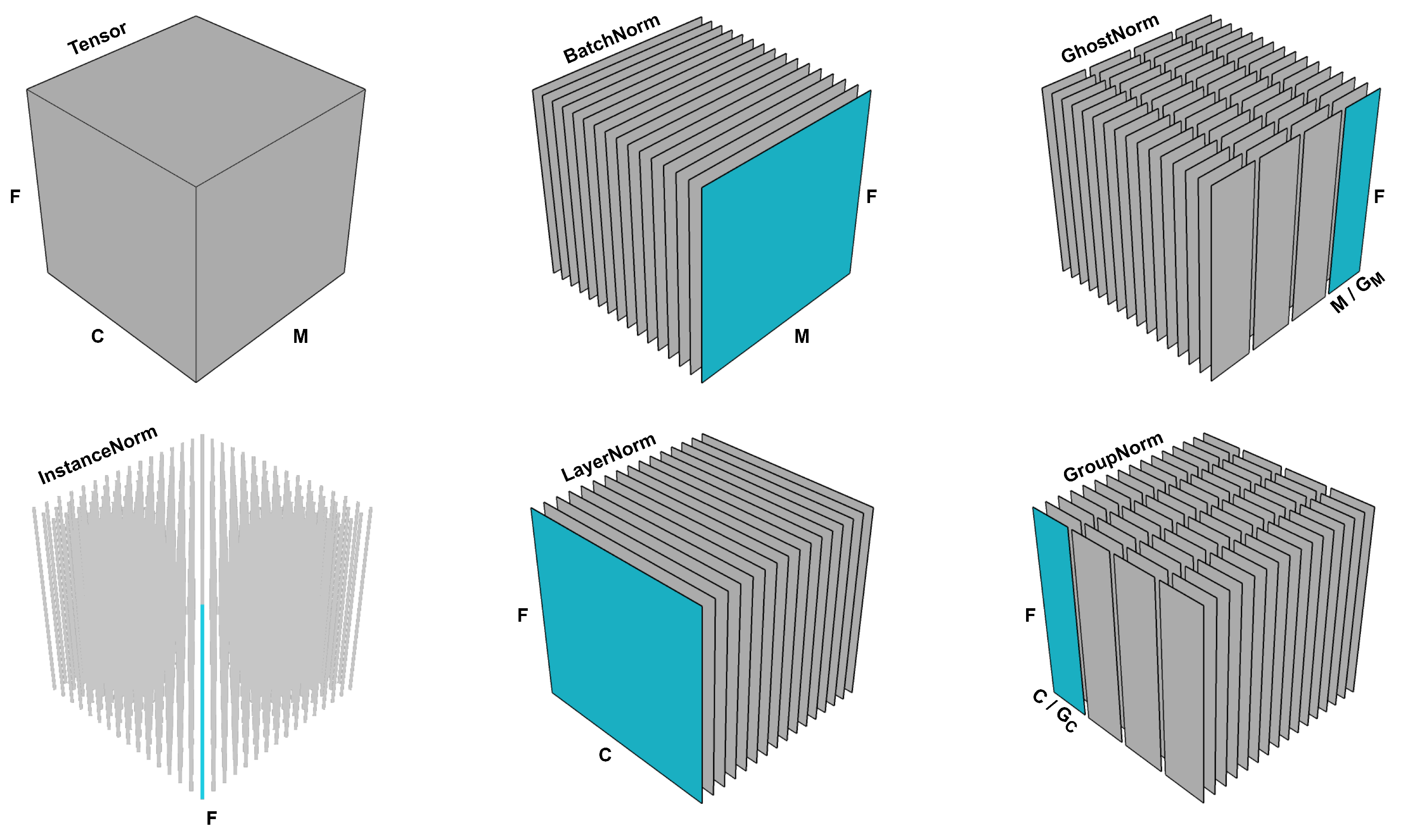
2.3. Implementation
2.3.1. Ghost Normalization
2.3.2. Sequential Normalization
3. Experiments and Results
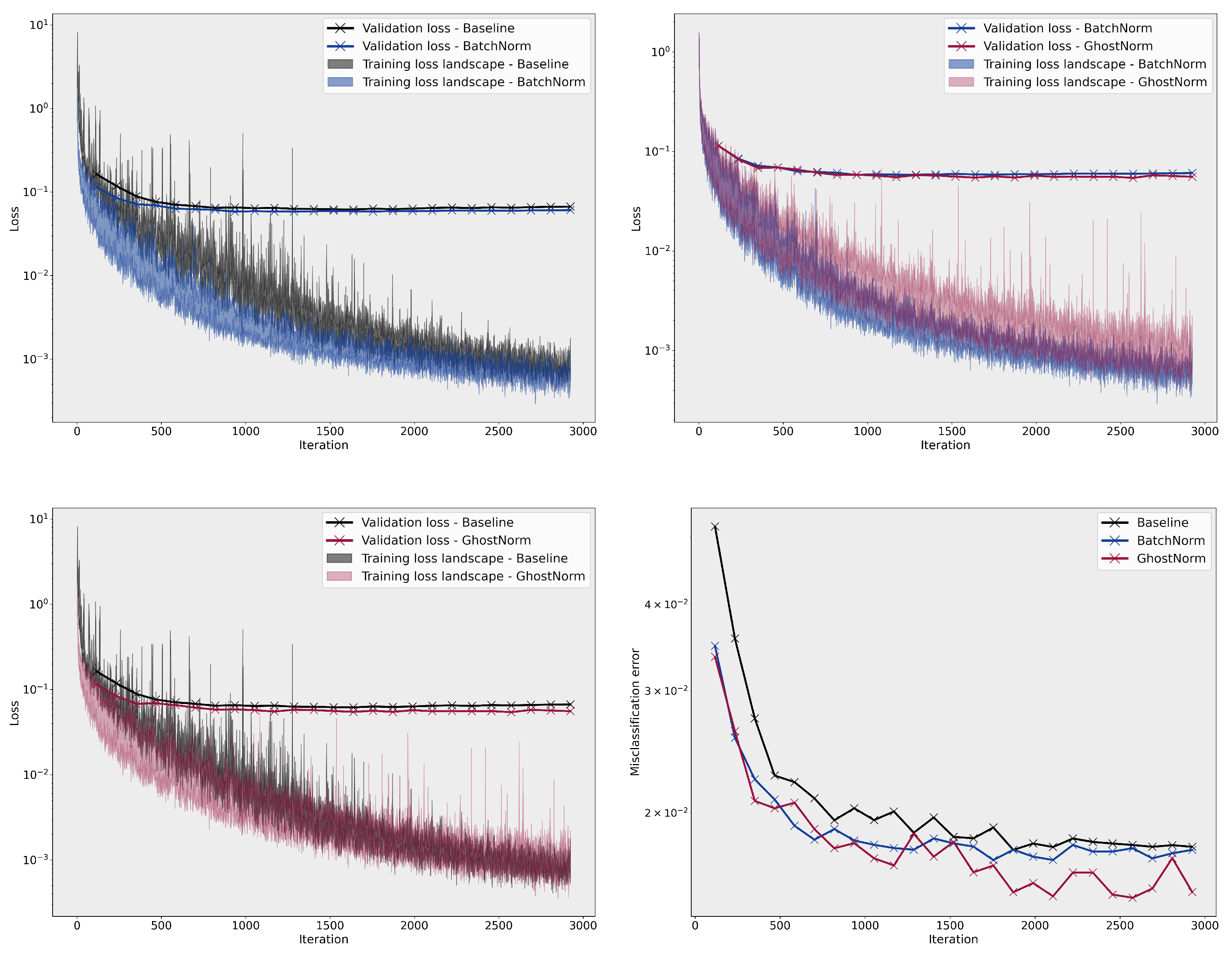
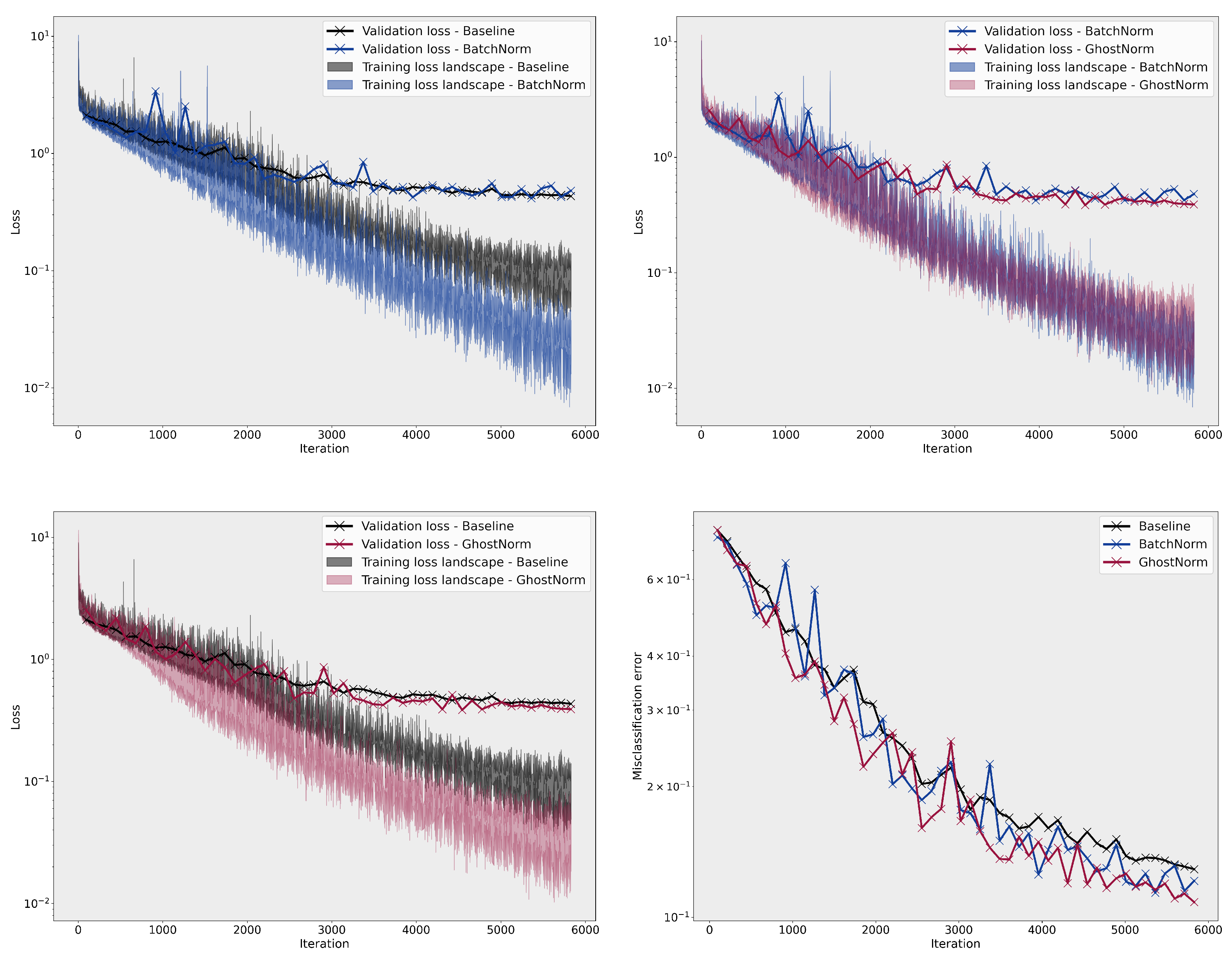
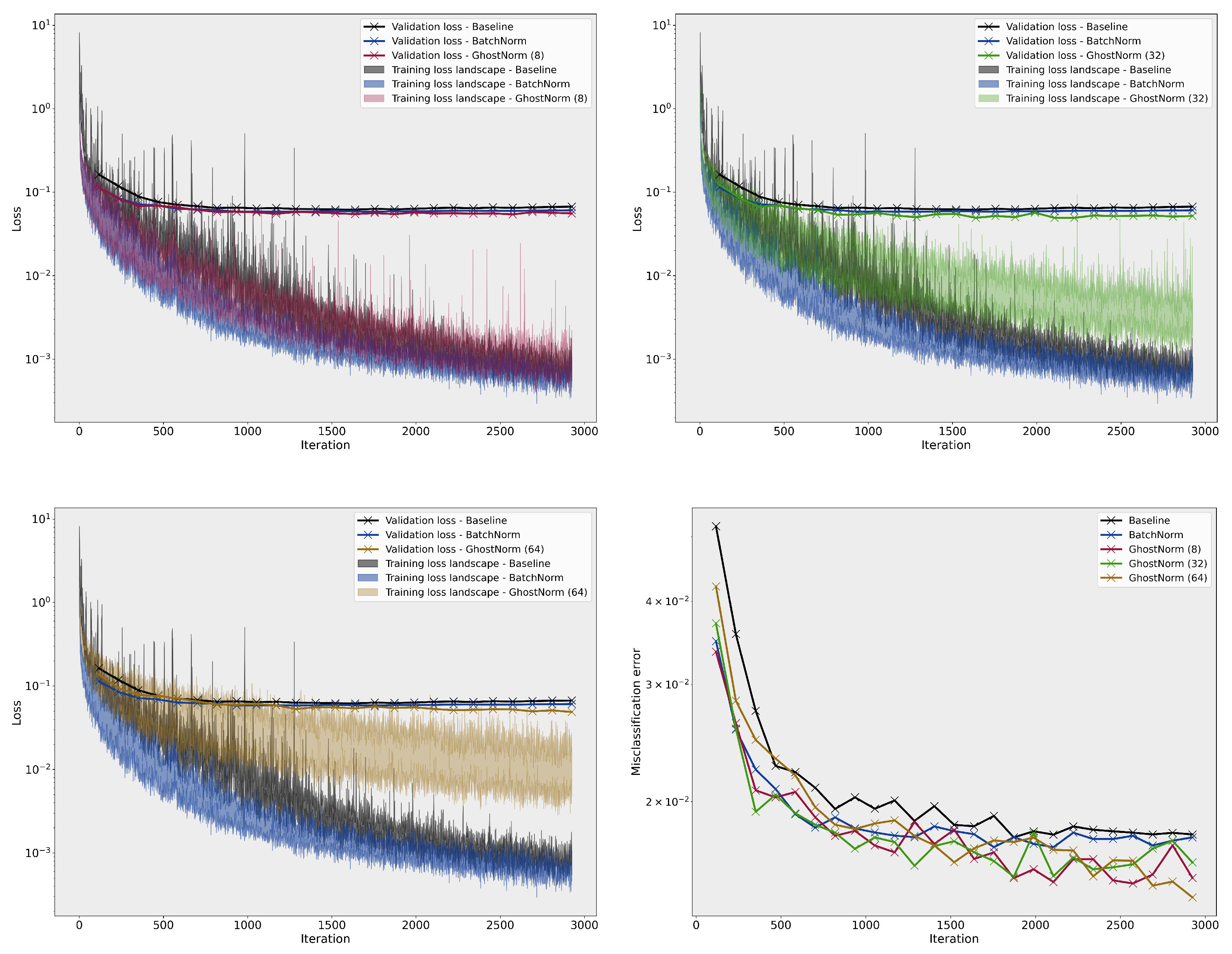
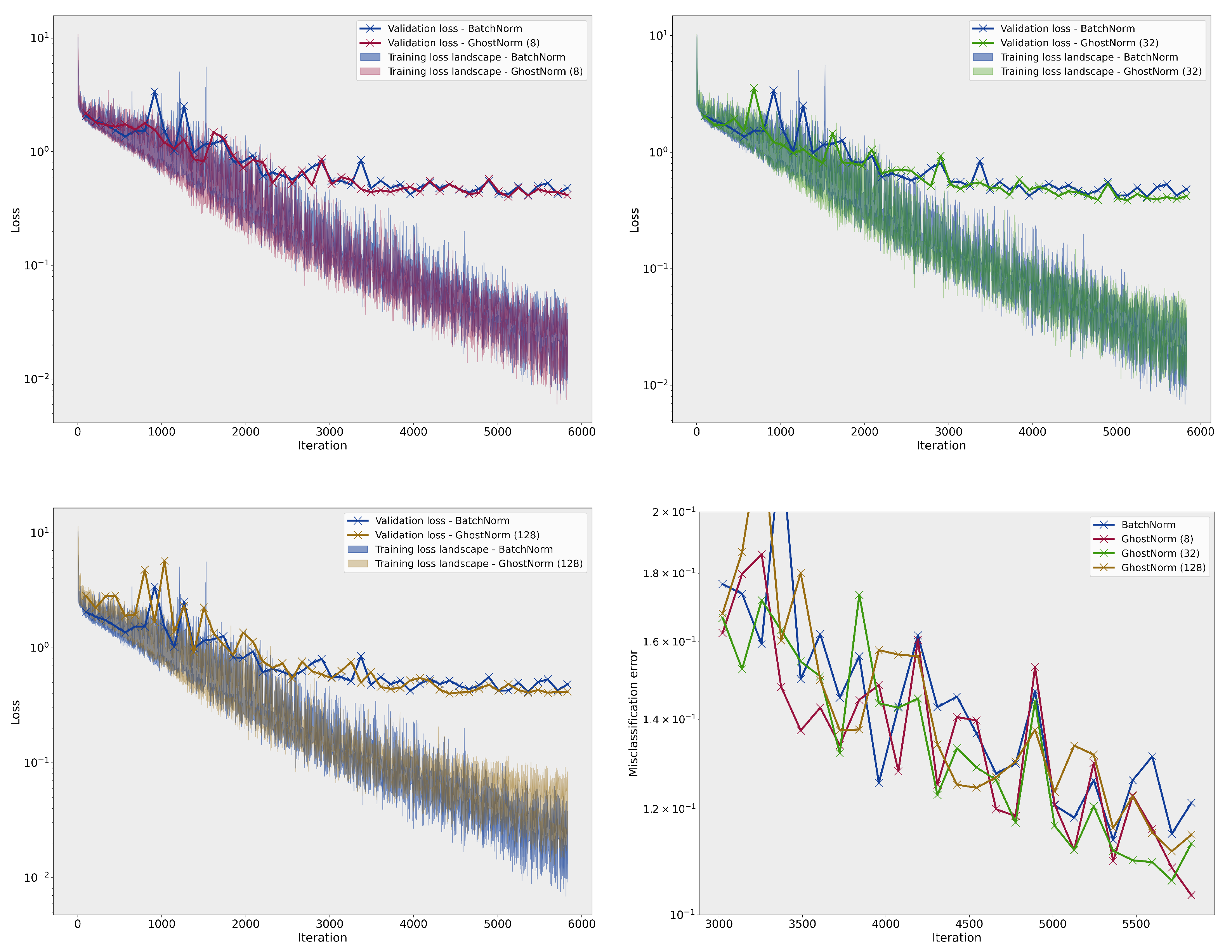
3.1. Loss Landscape Visualisation
3.2. Image Classification
3.2.1. CIFAR–100
3.2.2. CIFAR-10
3.2.3. ImageNet
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. GhostNorm Implementations


Appendix B. Loss Landscape Visualization
Appendix B.1. Implementation Details
Appendix B.2. Loss Landscape
Appendix B.3. Results


Appendix C. Image Classification
Implementation Details
Appendix D. Negative Results
References
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, Q.K. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. arXiv 2013, arXiv:1303.5778. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 2483–2493. [Google Scholar]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding Batch Normalization. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 7694–7705. [Google Scholar]
- Ioffe, S. Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1942–1950. [Google Scholar]
- Lei Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Qiao, S.; Wang, H.; Liu, C.; Shen, W.; Yuille, A. Weight Standardization. arXiv 2019, arXiv:1903.10520. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. arXiv 2018, arXiv:1803.08494. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Luo, C.; Zhan, J.; Wang, L.; Gao, W. Extended Batch Normalization. arXiv 2020, arXiv:2003.05569. [Google Scholar]
- Liang, S.; Huang, Z.; Liang, M.; Yang, H. Instance Enhancement Batch Normalization: An Adaptive Regulator of Batch Noise. arXiv 2019, arXiv:1908.04008v2. [Google Scholar] [CrossRef]
- Singh, S.; Shrivastava, A. EvalNorm: Estimating Batch Normalization Statistics for Evaluation. arXiv 2019, arXiv:1904.06031. [Google Scholar]
- Hoffer, E.; Hubara, I.; Soudry, D. Train Longer, Generalize Better: Closing the Generalization Gap in Large Batch Training of Neural Networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; pp. 1729–1739. [Google Scholar]
- Yan, J.; Wan, R.; Zhang, X.; Zhang, W.; Wei, Y.; Sun, J. Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization. arXiv 2020, arXiv:2001.06838. [Google Scholar]
- Summers, C.; Dinneen, M.J. Four Things Everyone Should Know to Improve Batch Normalization. arXiv 2020, arXiv:1906.03548. [Google Scholar]
- Wu, J.; Hu, W.; Xiong, H.; Huan, J.; Braverman, V.; Zhu, Z. On the Noisy Gradient Descent that Generalizes as SGD. arXiv 2019, arXiv:1906.07405. [Google Scholar]
- Smith, S.L.; Elsen, E.; De, S. On the Generalization Benefit of Noise in Stochastic Gradient Descent. arXiv 2020, arXiv:2006.15081. [Google Scholar]
- De, S.; Smith, S.L. Batch Normalization Biases Residual Blocks towards the Identity Function in Deep Networks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Bronskill, J.; Gordon, J.; Requeima, J.; Nowozin, S.; Turner, R.E. TaskNorm: Rethinking Batch Normalization for Meta-Learning. arXiv 2020, arXiv:2003.03284. [Google Scholar]
- Luo, P.; Ren, J.; Peng, Z.; Zhang, R.; Li, J. Differentiable Learning-to-Normalize via Switchable Normalization. arXiv 2019, arXiv:1806.10779. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. arXiv 2019, arXiv:1909.13719. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. arXiv 2019, arXiv:1805.09501. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do ImageNet Classifiers Generalize to ImageNet? arXiv 2019, arXiv:1902.10811. [Google Scholar]
- Smith, L.N.; Topin, N. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. arXiv 2017, arXiv:1708.07120. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2017, arXiv:1605.07146. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Validation Accuracy | Testing Accuracy | |
|---|---|---|
| BatchNorm | ||
| Noisy BatchNorm | ||
| GhostNorm () | - | |
| GhostNorm () | - | |
| GhostNorm () | ||
| GhostNorm () | - | |
| SeqNorm (, ) | - | |
| SeqNorm (, ) | - | |
| SeqNorm (, ) | ||
| SeqNorm (, ) | - | |
| SeqNorm (, ) | - | |
| BatchNorm w/ RandAugment | ||
| GhostNorm w/ RandAugment | ||
| SeqNorm w/ RandAugment |
| Validation Accuracy | Testing Accuracy | |
|---|---|---|
| CIFAR–10 | ||
| BatchNorm | ||
| GhostNorm () | ||
| SeqNorm (, ) | ||
| ImageNet | ||
| BatchNorm | ||
| GhostNorm () | ||
| SeqNorm (, ) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dimitriou, N.; Arandjelović, O. Sequential Normalization: Embracing Smaller Sample Sizes for Normalization. Information 2022, 13, 337. https://doi.org/10.3390/info13070337
Dimitriou N, Arandjelović O. Sequential Normalization: Embracing Smaller Sample Sizes for Normalization. Information. 2022; 13(7):337. https://doi.org/10.3390/info13070337
Chicago/Turabian StyleDimitriou, Neofytos, and Ognjen Arandjelović. 2022. "Sequential Normalization: Embracing Smaller Sample Sizes for Normalization" Information 13, no. 7: 337. https://doi.org/10.3390/info13070337