
Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges


Abstract
:1. Introduction
- We provide an overview of traditional techniques used to detect fake news and modern approaches used for multiclassification using unlabeled data.
- We focus on detecting forms of fake news dispatched on social networks when there is a lack of labeled data.
- We aim to demonstrate how this detection can help in improving and enhancing the quality of trust and transparency in the social network recommendation system.
2. Outline of Objectives
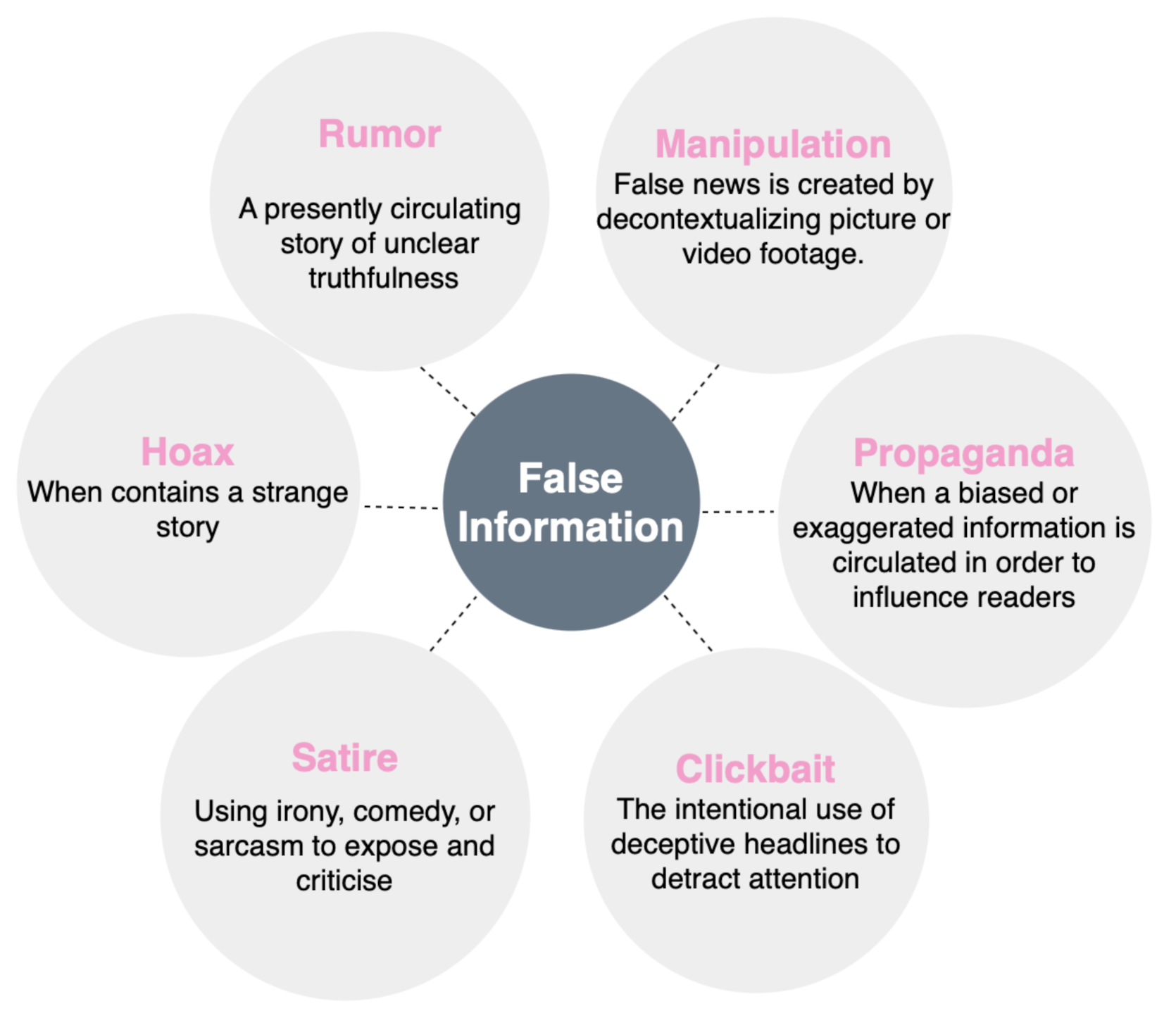
- High level:
- –
- Manufacturing: represents false information published in a newspaper to gain credibility.
- –
- Manipulation: decontextualization of image or video content to make false news.
- –
- Propaganda: whose aim is to influence public opinion and modify its perception of events.
- Low level:
- –
- Satire or false satirical information whose primary purpose is to provide humor to readers.
- –
- Clickbait: the primary goal of content is to bring attention and encourage users to click on a link to a certain web page.
3. Digital Environments Psychology and Its Impact on Information Sharing Trust
- How can virtual reality influence trust, and thus, impact user decision-making in advance?
- How does reputation within a virtual environment affect trust in infor- mation exchange?
- Why is there a tendency to trust strangers more than they deserve, and why do strangers have a good reputation?
4. State of the Art
4.1. Exploratory Analysis of the Characteristics of Fake News
4.2. Traditional Machine Learning Based Detection
4.3. Deep Learning-Based Detection
4.4. The Effect of Digital Environments on Trustworthiness in Information Exchange
4.5. Social Network-Based Recommendation
4.5.1. Friend-Based Recommendation
4.5.2. Trust-Based Recommendation
- Trust in user relationshipsExisting recommender systems still face a significant problem due to a lack of explanation or inaccurate recommendation results. As a result, adopting a reliable recommender system becomes crucial. Ref. [25] provides a systemic summary of three categories of trust-aware recommender systems: social-aware recommender systems that leverage users’ social relationships; robust recommender systems that filter untruthful noises (e.g., spammers and fake information) enhance attack resistance; and explainable recommender systems that provide explanations of recommended items. They describe how deep learning methods work for the trust-aware recommendation in representation, predictive, and generative learning. Recommendation systems, also known as recommender systems, are one of the most popular topics these days since they are frequently used to anticipate an item for the end-user based on their preferences. The goal of [26] is to gather proof that using social network information between users can improve the quality of standard recommendation systems. They describe the recommendation system approaches and the role of the trust relationship in a social network to overcome the limitation of the traditional approaches. A trust-aware recommendation system provides active users with the flavor he/she like based on his/her direct or indirect trust sources. At the first stage, these words start with the traditional recommendation system, move to the new modern approaches, and focus on the trust recommendation system that has more attention in the current stage. Social media news consumption is growing increasingly common these days. Users gain from social media because of its inherent characteristics of rapid transmission, low cost, and ease of access. Because user engagements on social media can aid in the detection of fake news, Ref. [27] explore the relationship between user profiles and fake/real news. They create real-world datasets that measure users’ trust in fake news and choose representative groups of “experienced” users who can spot false news and “naive” users who are more prone to believe it. They perform a comparative analysis of explicit and implicit profile features between these user groups, revealing their potential to differentiate fake news. Recommender systems are responsible for providing the users with a series of personalized suggestions for specific items. Trust is a concept that recently takes much attention and was considered in online social networks.
- Trust in the systems recommendationsThe authors in [28] provide a recommended reliability quality measure, present an RPI for reliability quality prediction, and an RQR for reliability quality recommendation (RRI). Both quality metrics are predicated on the idea that the stronger a dependability measure is, the better the accuracy findings will be. Users of the internet can share experiences and knowledge and connect with other users using social networks. The activities of these users center on social network services, and they create collaborative content via social networks. Many recent studies on CRMs capable of searching and recommending accurate and necessary information for users amid the sea of virtually infinite information generated were conducted. However, traditional CRMs fail to reflect interactions among users. They also are not capable of reflecting the status or reputation of users in a social network service. Consequently, we proposed a new CRM that is capable of reflecting the status of the content creators, thus overcoming problems associated with the traditional recommendation methods.
4.6. Our Proposed Work
5. Methodology
5.1. Aim of the Study
- Difference between fake news forms
- Multiclass classification using unlabeled data:
- Label estimation based on similarity between unlabeled item and the whole labeled dataset to enhance and improve the self-training algorithm.
- Comparison between new estimated labels using similarity and new labels predicted by the voting majority.
- Social network recommendation systemNevertheless, there is an important lack of research into reliability and trust in news dispatched on social networks. Trust in social networks is a crucial part of our daily lives, and we should concentrate more on the trust in system recommendations.
5.2. Methodology and Approach
- Step 1: Vectorization
- Step 2: Trust Network Construction
- Step 3: Initial Prediction
- Step 4: Trust Network Reconstruction
- Step 5: Final Prediction
- Step 6: Recommendation

5.2.1. Vectorization
5.2.2. Trust Network Construction
5.2.3. Initial Prediction
5.2.4. Trust Network Reconstruction
5.2.5. Final Prediction
5.2.6. Recommendation
6. Experiments and Results
6.1. Data Collection Process
6.2. Dataset
6.3. Data Preprocessing
6.4. Methodology
6.5. Experiment Results
6.5.1. Compared Fake News Detection Results
6.5.2. Experimental Results
7. Discussion and Limitations
- Difference between fake news forms posted on social networks.
- Multiclass classification using unlabeled data.
- Improving the trust and transparency in the social network recommendation system.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alzanin, S.M.; Azmi, A.M. Detecting rumors in social media: A survey. Procedia Comput. Sci. 2018, 142, 294–300. [Google Scholar] [CrossRef]
- Yenala, H.; Jhanwar, A.; Chinnakotla, M.K.; Goyal, J. Deep learning for detecting inappropriate content in text. Int. J. Data Sci. Anal. 2018, 6, 273–286. [Google Scholar] [CrossRef] [Green Version]
- Oumaima, S.; Soulaimane, K.; Omar, B. Artificial Intelligence in Predicting the Spread of Coronavirus to Ensure Healthy Living for All Age Groups. In Emerging Trends in ICT for Sustainable Development; Ahmed, M.B., Mellouli, S., Braganca, L., Abdelhakim, B.A., Bernadetta, K.A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 11–18. [Google Scholar]
- Oumaima, S. How Can We Analyse Emotions on Twitter during an Epidemic Situation? A Features Engineering Approach to Evaluate People’s Emotions during The COVID-19 Pandemic. Available online: https://doi.org/10.17605/OSF.IO/U9H52 (accessed on 23 August 2021).
- de Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M.F. Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information 2021, 12, 38. [Google Scholar] [CrossRef]
- Ji, Z.; Pi, H.; Wei, W.; Xiong, B.; Wpzniak, M.; Dama, R. Recommendation Based on Review Texts and Social Communities: A Hybrid Model. IEEE Access 2019, 7, 40416–40427. [Google Scholar] [CrossRef]
- Hassan, T.; McCrickard, D.S. Trust and Trustworthiness in Social Recommender Systems. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Collins, B.; Hoang, D.T.; Nguyen, N.T.; Hwang, D. Trends in combating fake news on social media—A survey. J. Inf. Telecommun. 2020, 1–20. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Q.; Si, L.; Liu, Y. Rumor Detection on Social Media: Datasets, Methods and Opportunities. arXiv 2019, arXiv:1911.07199. [Google Scholar]
- Heuer, H.; Breiter, A. Trust in news on social media. In Proceedings of the 10th Nordic Conference on Human-Computer Interaction, Oslo, Norway, 29 September–3 October 2018. [Google Scholar]
- Wu, L.; Rao, Y.; Yu, H.; Wang, Y.; Nazir, A. False Information Detection on Social Media via a Hybrid Deep Model. In Proceedings of the International Conference on Social Informatics, Saint-Petersburg, Russia, 25–28 September 2018. [Google Scholar]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing Social Media Messages in Mass Emergency: Survey Summary. In Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018. [Google Scholar]
- Stitini, O.; Kaloun, S.; Bencharef, O. The Recommendation of a Practical Guide for Doctoral Students Using Recommendation System Algorithms in the Education Field. In Innovations in Smart Cities Applications; Ahmed, M.B., RakKaraș, İ., Santos, D., Sergeyeva, O., Boudhir, A.A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 4, pp. 240–254. [Google Scholar]
- Oumaima, S.; Soulaimane, K.; Omar, B. Latest Trends in Recommender Systems Applied in the Medical Domain: A Systematic Review. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March–2 April 2020. [Google Scholar] [CrossRef]
- Tanha, J. A multiclass boosting algorithm to labeled and unlabeled data. Int. J. Mach. Learn. Cybern. 2019, 10, 3647–3665. [Google Scholar] [CrossRef]
- Martineau, M.; Raveaux, R.; Conte, D.; Venturini, G. Learning error-correcting graph matching with a multiclass neural network. Pattern Recognit. Lett. 2020, 134, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Kaneko, T.; Sato, I.; Sugiyama, M. Online Multiclass Classification Based on Prediction Margin for Partial Feedback. arXiv 2019, arXiv:1902.01056. [Google Scholar]
- Tayyaba, R.; Wasi, H.B.; Arslan, S.; Usman, A.M. Multi-Label Fake News Detection using Multi-layered Supervised Learning. In Proceedings of the 2019 11th International Conference on Computer and Automation Engineering (ICCAE 2019), New York, NY, USA, 23–25 February 2019; pp. 73–77. [Google Scholar] [CrossRef]
- Vijayaraghavan, S.; Wang, Y.; Guo, Z.; Voong, J.; Xu, W.; Nasseri, A.; Cai, J.; Li, L.; Vuong, K.; Wadhwa, E. Fake News Detection with Different Models. arXiv 2020, arXiv:2003.04978. [Google Scholar]
- Leonardi, S.; Rizzo, G.; Morisio, M. Automated Classification of Fake News Spreaders to Break the Misinformation Chain. Information 2021, 12, 248. [Google Scholar] [CrossRef]
- Duradoni, M.; Collodi, S.; Perfumi, S.C.; Guazzini, A. Reviewing Stranger on the Internet: The Role of Identifiability through “Reputation” in Online Decision Making. Future Int. 2021, 13, 110. [Google Scholar] [CrossRef]
- Duradoni, M.; Paolucci, M.; Bagnoli, F.; Guazzini, A. Fairness and Trust in Virtual Environments: The Effects of Reputation. Future Int. 2018, 10, 50. [Google Scholar] [CrossRef] [Green Version]
- Duradoni, M. Reputation Matters the Most: The Reputation Inertia Effect. Hum. Behav. Emerg. Technol. 2020, 2, 71–81. [Google Scholar] [CrossRef]
- Gao, P.; Baras, J.; Golbeck, J. Trust-aware Social Recommender System Design. In Doctor Consortium of 2015 International Conference On Information Systems Security and Privacy; Science and Technology Publications, Lda: Setúbal, Portugal, 2018. [Google Scholar]
- Dong, M.; Yuan, F.; Yao, L.; Wang, X.; Xu, X.; Zhu, L. Trust in Recommender Systems: A Deep Learning Perspective. arXiv 2020, arXiv:2004.03774. [Google Scholar]
- Tharwat, M.E.A.A.; Jacob, D.W.; Fudzee, M.F.M.; Kasim, S.; Ramli, A.A.; Lubis, M. The Role of Trust to Enhance the Recommendation System Based on Social Network. Int. J. Adv. Sci. Eng. Inf. Technol. 2020, 10, 1387–1395. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Liu, H. Understanding User Profiles on Social Media for Fake News Detection. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 430–435. [Google Scholar]
- Bobadilla, J.; Gutiérrez, A.; Ortega, F.; Zhu, B. Reliability quality measures for recommender systems. Inf. Sci. 2018, 442–443, 145–157. [Google Scholar] [CrossRef]
- Gereme, F.; Zhu, W.; Ayall, T.; Alemu, D. Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting. Information 2021, 12, 20. [Google Scholar] [CrossRef]
- Kasnesis, P.; Toumanidis, L.; Patrikakis, C.Z. Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information 2021, 12, 409. [Google Scholar] [CrossRef]
- Galal, S.; Nagy, N.; El-Sharkawi, M.E. CNMF: A Community-Based Fake News Mitigation Framework. Information 2021, 12, 376. [Google Scholar] [CrossRef]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural user response generator: Fake news detection with collective user intelligence. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI’18), Stockholm, Sweden, 13–19 July 2018; pp. 3834–3840. [Google Scholar] [CrossRef] [Green Version]
- Fact Checking. Available online: https://hrashkin.github.io/factcheck.html (accessed on 24 February 2021).
- Getting Real about Fake News. Available online: https://www.kaggle.com/mrisdal/fake-news/data (accessed on 24 February 2021).
- Granik, M.; Mesyura, V. Fake news detection using naive Bayes classifier. In Proceedings of the 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), Kyiv, Ukraine, 29 May–2 June 2017; pp. 900–903. [Google Scholar] [CrossRef]
- Lyu, S.; Lo, D.C.T. Fake News Detection by Decision Tree. In Proceedings of the 2020 Southeast Con, Raleigh, NC, USA, 28–29 March 2020; pp. 1–2. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Contribution | Definition of Problem Handled |
|---|---|
| [23] | Good reputation subjects tend to attract other positive. The reputation inertia effect feedback, regardless of personal/actual experience. Conversely, bad reputation similarity subjects are more likely to attract negative evaluations. |
| [22] | Fairness and trust are two important aspects Reputation Effects on prosocial behaviors in the virtual environment of social interactions. |
| [21] | There is evidence that on the internet we tend to trust strangers more than we reasonably should because we implicitly represent/treat them as having a good reputation. |
| Contribution | Fake News Detection | ||
|---|---|---|---|
| Classic Detection | New Different Detection | Trust in Social Networks | |
| [29] | ✓ | × | × |
| [30] | × | ✓ | ✓ |
| [5] | × | ✓ | ✓ |
| [31] | × | ✓ | ✓ |
| [11] | ✓ | × | × |
| [9] | ✓ | × | ✓ |
| [2] | ✓ | × | × |
| [10] | × | ✓ | ✓ |
| [27] | × | ✓ | ✓ |
| [32] | ✓ | × | × |
| Our Approach | ✓ | ✓ | ✓ |
| Free Contextual Approach | Modern Contextual Approach | ||
|---|---|---|---|
| Word2Vec | ULMFiT | BERT | |
| Description | Word2Vec, a neural network-based approach for learning word embeddings utilized in different NLP applications. The basic principle underlying word2vec is that the vectors created are learned by comprehending the words context. | ULMFiT, which stands for Universal Language Model Finetuning, is a transfer learning method that uses a standard 3-layer LSTM architecture for pretraining and fine-tuning tasks and Language modeling (LM) as the source task due to its ability to capture general language features and provide a large amount of data that can be fed to other downstream NLP tasks. | BERT is another language representation learning approach that encodes context using attention transformers rather than bidirectional LSTMs. |
| Why We Use | - | - |
|
| Why We Not Use | Word2Vec models generate embeddings that are context-independent. | ULMFit uses a concatenation of right-to-left and left-to-right LSTMs and ULMFit uses a unidirectional LSTM. | - |
| Before Preprocessing | After Preprocessing |
|---|---|
| Red State: News Sunday reported this morning that Anthony Weiner is cooperating with the FBI, which has re-opened (yes, lefties: “re-opened”) the investigation into Hillary Clinton’s classified emails. Watch as Chris Wallace reports the breaking news during the panel segment near the end of the show: the news is breaking while we’re on the air. Our colleague Bret Baier has just sent us an e-mail saying he has two sources who say that Anthony Weiner, who also had co-ownership of that laptop with his estranged wife Huma Abedin, is cooperating with the FBI investigation, had given them the laptop, so therefore they didn’t need a warrant to get in to see the contents of said laptop. Pretty interesting development of federal investigations will often cooperate, hoping that they will get consideration from a judge at sentencing. Given Weiner’s well-known penchant for lying, it’s hard to believe that a prosecutor would give Weiner a deal based on an agreement to testify, unless his testimony were very strongly corroborated by hard evidence. But cooperation can take many forms—and, as Wallace indicated on this morning’s show, one of those forms could be signing a consent form to allow the contents of devices that they could probably get a warrant for anyway. We’ll see if Weiner’s cooperation extends beyond that. More Related. | State news Sunday reported this morning that Anthony Weiner is cooperating with which lefties opened investigation into Hillary Clinton classified emails. Watch Chris Wallace reports breaking news during panel segment near show news breaking while colleague Bret Baier just sent mail saying sources that Anthony Weiner also ownership that laptop with estranged wife Huma Abedin cooperating with investigation given them laptop therefore they didn’t need warrant contents said laptop pretty interesting development targets federal investigations will often cooperate hoping that they will consideration from judge sentencing given Weiner well known penchant lying hard believe that prosecutor would give Weiner deal based agreement testify unless testimony were very strongly corroborated hard evidence cooperation take many forms Wallace indicated this morning show those forms could signing consent form allow contents devices that they could probably warrant anyway Weiner cooperation extends beyond that more related. |
| Metric | [29] | [20] | [11] | Our Approach |
|---|---|---|---|---|
| Accuracy | 0.96 | - | 0.33 | 0.96 |
| Precision | 0.98 | 0.80 | - | 0.96 |
| Recall | 0.98 | 0.81 | 0.59 | 0.96 |
| F1 | 0.98 | 0.80 | 0.43 | 0.96 |
| Different Models | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Logistic Regression | 0.76 | 0.76 | 0.76 | 0.76 |
| Naïve Bayes | 0.44 | 0.69 | 0.44 | 0.39 |
| Decision Tree | 0.41 | 0.35 | 0.41 | 0.35 |
| Linear SVM | 0.73 | 0.74 | 0.73 | 0.73 |
| Different Models | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Logistic Regression | 0.93 | 0.93 | 0.93 | 0.91 |
| Naïve Bayes | 0.71 | 0.73 | 0.71 | 0.66 |
| Decision Tree | 0.74 | 0.62 | 0.74 | 0.67 |
| Linear SVM | 0.94 | 0.94 | 0.94 | 0.91 |
| Different Models | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Logistic Regression | 0.96 | 0.96 | 0.96 | 0.96 |
| Naïve Bayes | 0.64 | 0.67 | 0.67 | 0.55 |
| Decision Tree | 0.64 | 0.60 | 0.64 | 0.60 |
| Linear SVM | 0.95 | 0.95 | 0.95 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stitini, O.; Kaloun, S.; Bencharef, O. Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges. Information 2022, 13, 128. https://doi.org/10.3390/info13030128
Stitini O, Kaloun S, Bencharef O. Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges. Information. 2022; 13(3):128. https://doi.org/10.3390/info13030128
Chicago/Turabian StyleStitini, Oumaima, Soulaimane Kaloun, and Omar Bencharef. 2022. "Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges" Information 13, no. 3: 128. https://doi.org/10.3390/info13030128