
Semi-Automatic Systematic Literature Reviews and Information Extraction of COVID-19 Scientific Evidence: Description and Preliminary Results of the COKE Project

 , , ,
, , ,
Abstract
:1. Introduction
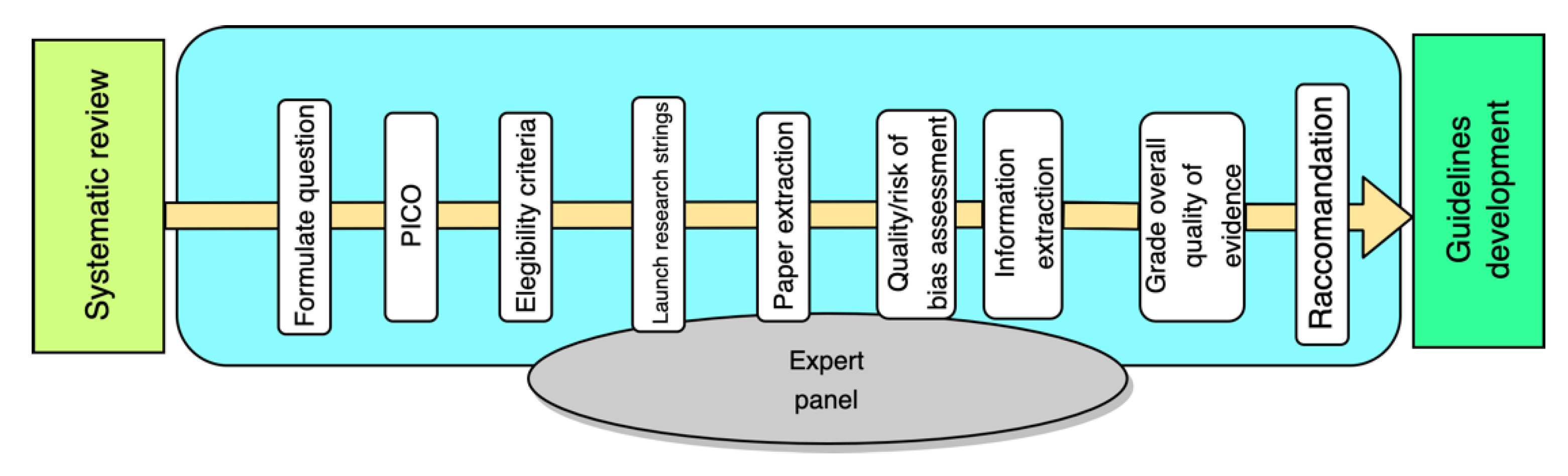
1.1. Guidelines Development and Systematic Literature Reviews
1.2. Rationale and Aim
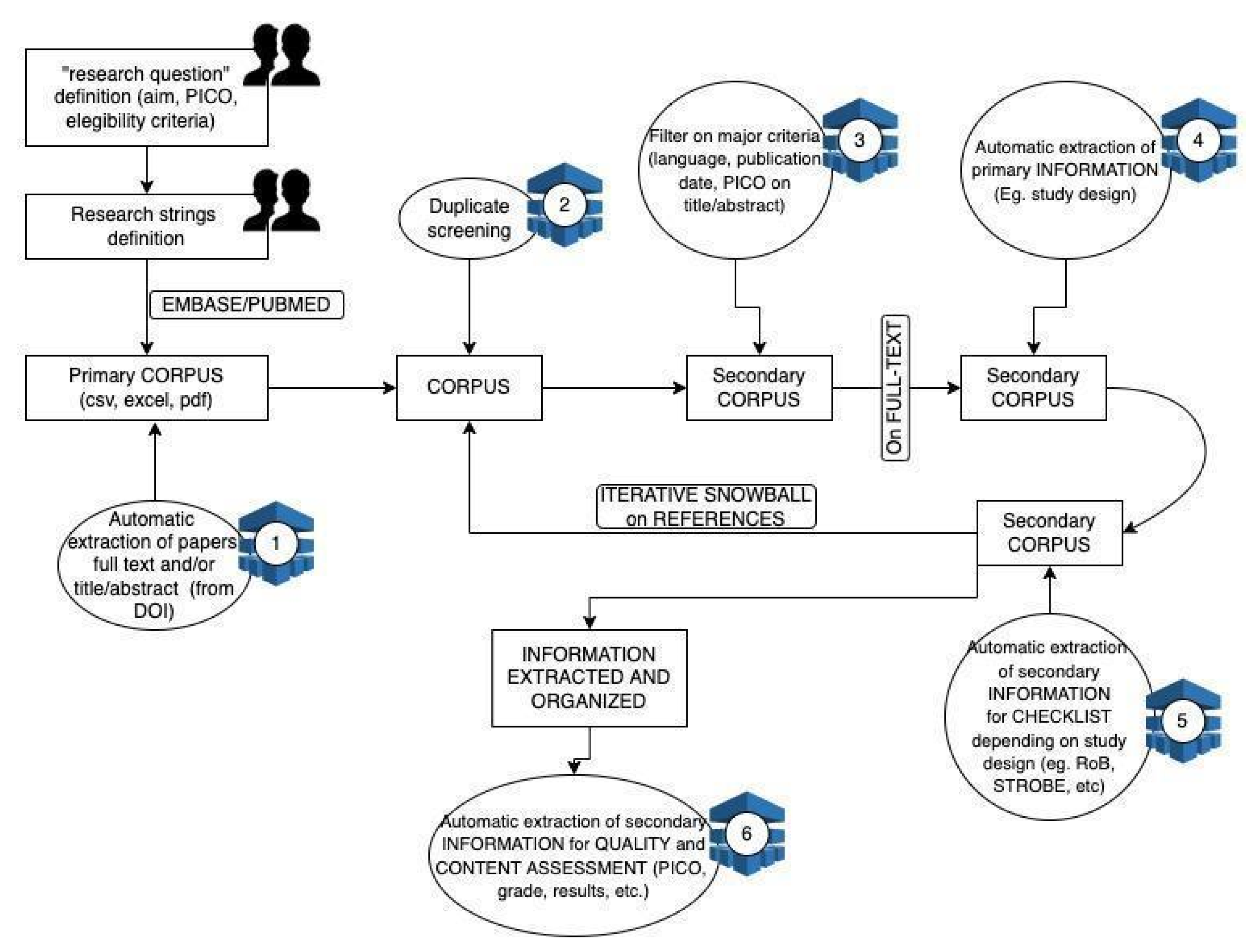
2. The COKE Project
3. Methods
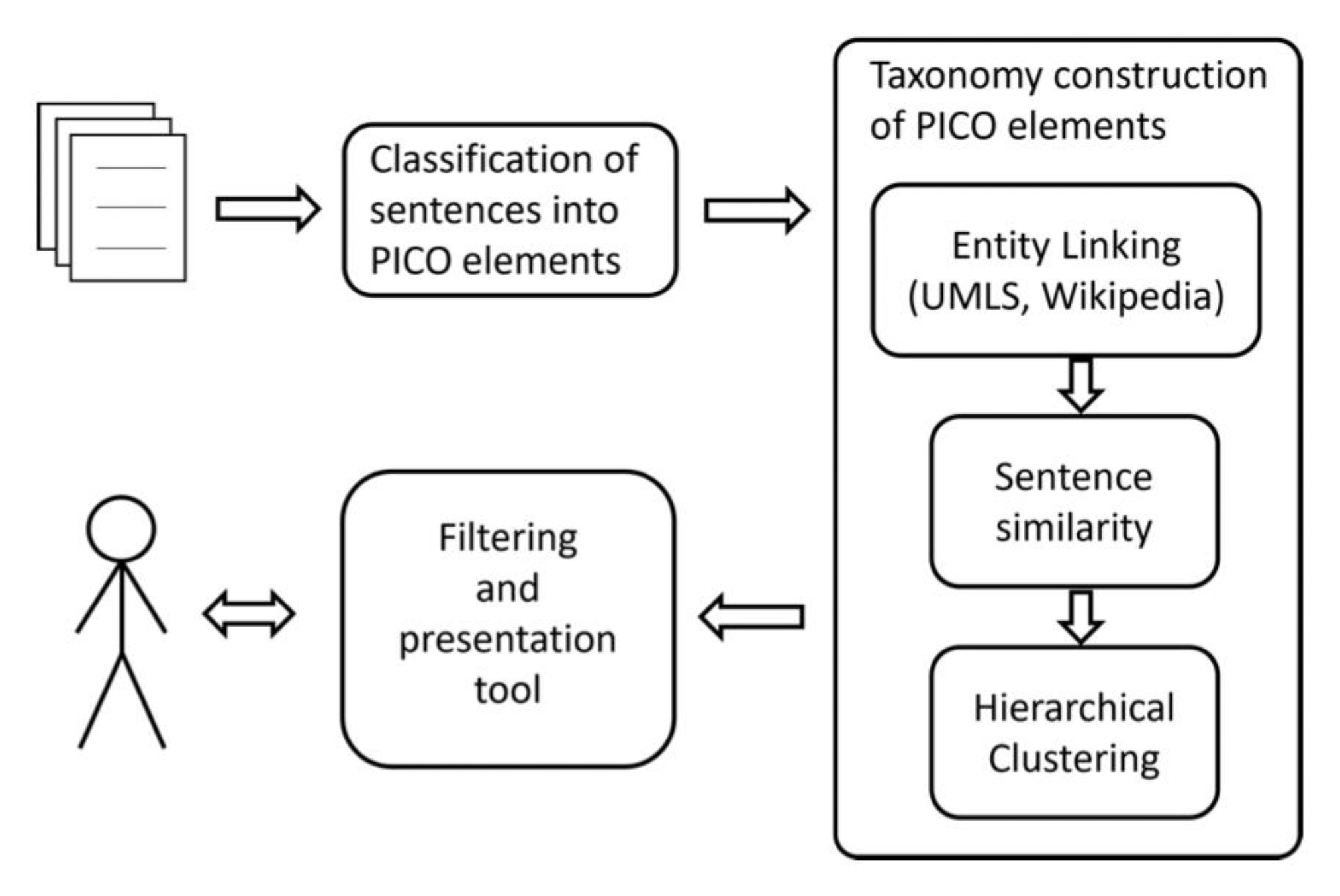
3.1. Organizing and Filtering the Relevant Literature Based on PICO Elements
3.2. Sentence Classification into PICO Elements
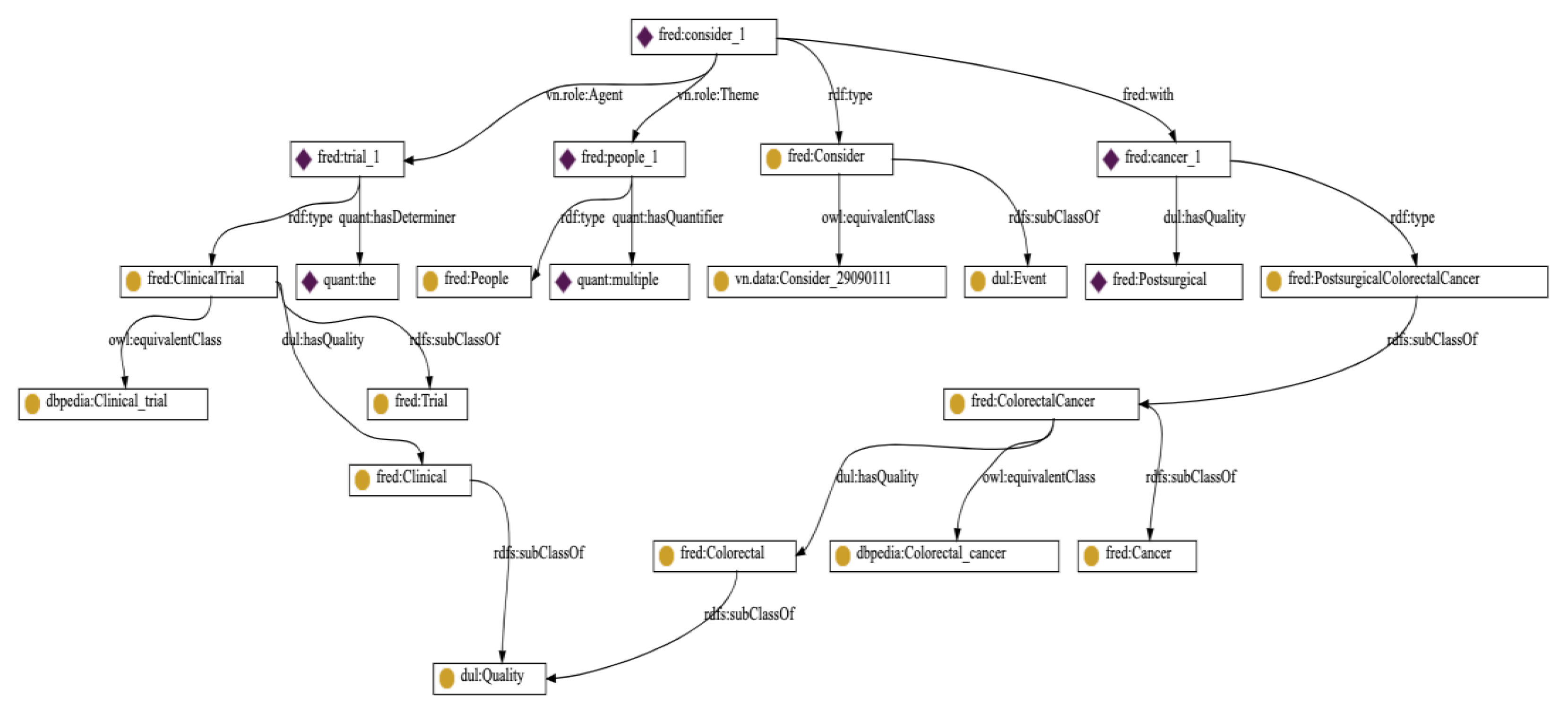
3.3. Extracting PICO Elements Taxonomies
3.4. Filtering Tool
4. Preliminary Results: A Case Study on the COVID-19 Literature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koffman, J.; Gross, J.; Etkind, S.N.; Selman, L. Uncertainty and COVID-19: How are we to respond? J. R. Soc. Med. 2020, 113, 211–216. [Google Scholar] [CrossRef] [PubMed]
- Sanmarchi, F.; Golinelli, D.; Lenzi, J.; Esposito, F.; Capodici, A.; Reno, C.; Gibertoni, D. Exploring the gap between excess mortality and COVID-19 deaths in 67 countries. JAMA Netw. Open 2021, 4, e2117359. [Google Scholar] [CrossRef] [PubMed]
- Hua, J.; Shaw, R. Corona virus (COVID-19) “infodemic” and emerging issues through a data lens: The case of China. Int. J. Environ. Res. Public Health 2020, 17, 2309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bin Naeem, S.; Bhatti, R. The Covid-19 ‘infodemic’: A new front for information professionals. Health Inf. Libr. J. 2020, 37, 233–239. [Google Scholar] [CrossRef] [PubMed]
- The Lancet Infectious Diseases. The COVID-19 infodemic. Lancet Infect. Dis. 2020, 20, 875. [Google Scholar] [CrossRef]
- Saperstein, Y.; Ong, S.Y.; Al-Bermani, T.; Park, J.; Saperstein, Y.; Olayinka, J.; Jaiman, A.; Winer, A.; Salifu, M.O.; McFarlane, S.I. COVID-19 guidelines changing faster than the virus: Implications of a clinical decision support app. Int. J. Clin. Res. Trials 2020, 5, 148. [Google Scholar] [CrossRef]
- Gao, F.; Tao, L.; Huang, Y.; Shu, Z. Management and data sharing of COVID-19 pandemic information. Biopreserv. Biobank. 2020, 18, 570–580. [Google Scholar] [CrossRef]
- WHO. Therapeutics and COVID-19: Living Guideline. Available online: https://www.who.int/publications/i/item/WHO-2019-nCoV-therapeutics-2021.1 (accessed on 31 March 2021).
- Centers for Disease Control and Prevention. Interim Public Health Recommendations for Fully Vaccinated People. Available online: https://stacks.cdc.gov/view/cdc/105629 (accessed on 6 July 2021).
- European Centre for Disease Prevention and Control; World Health Organization Regional Office for Europe. Methods for the Detection and Characterisation of SARS-CoV-2 Variants; ECDC; WHO Regional Office for Europe: Stockholm, Sweden; Copenhagen, Denmark, 2021. [Google Scholar]
- Schünemann, H.J.; Wiercioch, W.; Etxeandia-Ikobaltzeta, I.; Falavigna, M.; Santesso, N.; Mustafa, R.; Ventresca, M.; Brignardello-Petersen, R.; Laisaar, K.-T.; Kowalski, S.; et al. Guidelines 2.0: Systematic development of a comprehensive checklist for a successful guideline enterprise. Can. Med. Assoc. J. 2014, 186, E123–E142. [Google Scholar] [CrossRef] [Green Version]
- Boetto, E.; Golinelli, D.; Carullo, G.; Fantini, M.P. Frauds in scientific research and how to possibly overcome them. J. Med. Ethics 2021, 47, e19. [Google Scholar] [CrossRef]
- Aviv-Reuven, S.; Rosenfeld, A. Publication patterns’ changes due to the COVID-19 pandemic: A longitudinal and short-term scientometric analysis. Scientometrics 2021, 126, 6761–6784, published online ahead of print. [Google Scholar] [CrossRef]
- Malmasi, S.; Hosomura, N.; Chang, L.-S.; Brown, C.J.; Skentzos, S.; Turchin, A. Extracting healthcare quality information from unstructured data. AMIA Annu. Symp. Proc. 2018, 2017, 1243–1252. [Google Scholar] [PubMed]
- Hahn, U.; Oleynik, M. Medical information extraction in the age of deep learning. Yearb. Med. Inform. 2020, 29, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, J.; Wang, M.; Li, Y.; Liang, Y.; Xu, D. Using internet search engines to obtain medical information: A comparative study. J. Med. Internet Res. 2012, 14, e74. [Google Scholar] [CrossRef] [PubMed]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. WHO Handbook for Guideline Development, 2nd ed.; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- Kitano, H. Artificial intelligence to win the Nobel prize and beyond: Creating the engine for scientific discovery. AI Mag. 2016, 37, 39–49. [Google Scholar] [CrossRef] [Green Version]
- Nature Index. Available online: https://www.natureindex.com/news-blog/the-top-coronavirus-research-articles-by-metrics (accessed on 23 June 2020).
- Khan, K.S.; Kunz, R.; Kleijnen, J.; Antes, G. Five steps to conducting a systematic review. J. R. Soc. Med. 2003, 96, 118–121. [Google Scholar] [CrossRef]
- Cooper, H. Research Synthesis and Meta-Analysis: A Step-by-Step Approach; SAGE Publications: Thousand Oaks, CA, USA, 2015. [Google Scholar]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.A.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. J. Clin. Epidemiol. 2009, 62, e1–e34. [Google Scholar] [CrossRef] [Green Version]
- Boaz, A.; Ashby, D.; Young, K. Systematic Reviews: What Have They Got to Offer Evidence Based Policy and Practice? ESRC UK Centre for Evidence Based Policy and Practice: London, UK, 2002. [Google Scholar]
- Oliver, S.; Dickson, K.; Bangpan, M. Systematic Reviews: Making Them Policy Relevant. A Briefing for Policy Makers and Systematic Reviewers; UCL Institute of Education: London, UK, 2015. [Google Scholar]
- Booth, A. Searching for qualitative research for inclusion in systematic reviews: A structured methodological review. Syst. Rev. 2016, 5, 74. [Google Scholar] [CrossRef] [Green Version]
- Guyatt, G.; Oxman, A.D.; Akl, E.A.; Kunz, R.; Vist, G.; Brozek, J.; Norris, S.; Falck-Ytter, Y.; Glasziou, P.; DeBeer, H.; et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J. Clin. Epidemiol. 2011, 64, 383–394. [Google Scholar] [CrossRef]
- Marshall, I.J.; Wallace, B.C. Toward systematic review automation: A practical guide to using machine learning tools in research synthesis. Syst. Rev. 2019, 8, 163. [Google Scholar] [CrossRef]
- Schmidt, L.; Olorisade, B.K.; McGuinness, L.A.; Thomas, J.; Higgins, J.P.T. Data extraction methods for systematic review (semi)automation: A living systematic review. F1000Research 2021, 10, 401. [Google Scholar] [CrossRef] [PubMed]
- Khalil, H.; Ameen, D.; Zarnegar, A. Tools to support the automation of systematic reviews: A scoping review. J. Clin. Epidemiol. 2021, 144, 22–42. [Google Scholar] [CrossRef]
- Etzioni, O.; Banko, M.; Cafarella, M.J. Machine Reading; Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 2006; Volume 6, pp. 1517–1519. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Borah, R.; Brown, A.; Capers, P.L.; Kaiser, K.A. Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ Open 2017, 7, e012545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gangemi, A.; Presutti, V.; Recupero, D.R.; Nuzzolese, A.G.; Draicchio, F.; Mongiovì, M. Semantic web machine reading with FRED. Semant. Web 2017, 8, 873–893. [Google Scholar] [CrossRef]
- Marshall, I.J.; Kuiper, J.; Wallace, B.C. RobotReviewer: Evaluation of a system for automatically assessing bias in clinical trials. J. Am. Med. Inform. Assoc. 2015, 23, 193–201. [Google Scholar] [CrossRef] [Green Version]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Kirrane, S.; Labra Gayo, J.E.; Navigli, R.; Neumaier, R.; et al. Knowledge Graphs. Synthesis Lectures on Data, Semantics, and Knowledge; Morgan and Claypool Publishers: San Rafael, CA, USA, 2021; Volume 12, pp. 1–257. [Google Scholar]
- Eco, U. Peirce’s Notion of Interpretant. Comp. Lit. 1976, 91, 1457–1472. [Google Scholar] [CrossRef]
- Gangemi, A.; Recupero, D.R.; Mongiovì, M.; Nuzzolese, A.G.; Presutti, V. Identifying motifs for evaluating open knowledge extraction on the web. Knowl. Based Syst. 2016, 108, 33–41. [Google Scholar] [CrossRef]
- Schuler, K.K. VerbNet: A Broad-Coverage, Comprehensive Verb Lexicon; University of Pennsylvania: Philadelphia, PA, USA, 2005. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A Nucleus for a Web of Open Data; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Jin, D.; Szolovits, P. Pico element detection in medical text via long short-term memory neural networks. In Proceedings of the BioNLP Workshop, Melbourne, Australia, 19 July 2018; pp. 67–75. [Google Scholar]
- Džeroski, S.; Kocev, D.; Panov, P. Special issue on discovery science. Mach. Learn. 2016, 105, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Priem, J.; Groth, P.; Taraborelli, D. The altmetrics collection. PLoS ONE 2012, 7, 48753. [Google Scholar] [CrossRef] [Green Version]
- Nuzzolese, A.G.; Ciancarini, P.; Gangemi, A.; Peroni, S.; Poggi, F.; Presutti, V. Do altmetrics work for assessing research quality? Scientometrics 2019, 118, 539–562. [Google Scholar] [CrossRef] [Green Version]
- Boetto, E.; Fantini, M.P.; Gangemi, A.; Golinelli, D.; Greco, M.; Nuzzolese, A.G.; Presutti, V.; Rallo, F. Using altmetrics for detecting impactful research in quasi-zero-day time-windows: The case of COVID-19. Scientometrics 2021, 126, 1189–1215. [Google Scholar] [CrossRef] [PubMed]
- Van de Schoot, R.; de Bruin, J.; Schram, R.; Zahedi, P.; de Boer, J.; Weijdema, F.; Kramer, B.; Huijts, M.; Hoogerwerf, M.; Ferdinands, G.; et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat. Mach. Intell. 2021, 3, 125–133. [Google Scholar] [CrossRef]
- Bodenreider, O. The unified medical language system (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [Green Version]
- Donnelly, K. SNOMED-CT: The advanced terminology and coding system for eHealth. Stud. Health Technol. Inform. 2006, 121, 279. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Jin, D.; Szolovits, P. Advancing PICO element detection in biomedical text via deep neural networks. Bioinformatics 2020, 36, 3856–3862. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.-t.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; Ho So, C.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Fraser, K.C.; Nejadgholi, I.; De Bruijn, B.; Li, M.; LaPlante, A.; El Abidine, K.Z. Extracting UMLS concepts from medical text using general and domain-specific deep learning models. arXiv 2019, arXiv:1910.01274. [Google Scholar]
- Raiman, J.; Raiman, O. Deeptype: Multilingual entity linking by neural type system evolution. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Mohan, S.; Li, D. Medmentions: A large biomedical corpus annotated with UMLS concepts. In Proceedings of the Automated Knowledge Base Construction (AKBC), Amherst, MA, USA, 20–21 May 2019. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- White, R.W.; Kules, B.; Bederson, B. Exploratory search interfaces: Categorization, clustering and beyond: Report on the xsi 2005 workshop at the human-computer interaction laboratory, University of Maryland. ACM SIGIR Forum. 2005, 39, 52–56. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| A | 0.884 | 0.850 | 0.867 | 153 |
| C | 0.796 | 0.854 | 0.824 | 96 |
| I | 0.312 | 0.625 | 0.417 | 8 |
| M | 0.750 | 0.543 | 0.630 | 94 |
| O | 0.748 | 0.821 | 0.782 | 184 |
| P | 0.479 | 0.469 | 0.474 | 49 |
| Accuracy | 0.757 | 584 | ||
| Macro avg. | 0.662 | 0.694 | 0.666 | 584 |
| Weighted avg. | 0.763 | 0.757 | 0.756 | 584 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golinelli, D.; Nuzzolese, A.G.; Sanmarchi, F.; Bulla, L.; Mongiovì, M.; Gangemi, A.; Rucci, P. Semi-Automatic Systematic Literature Reviews and Information Extraction of COVID-19 Scientific Evidence: Description and Preliminary Results of the COKE Project. Information 2022, 13, 117. https://doi.org/10.3390/info13030117
Golinelli D, Nuzzolese AG, Sanmarchi F, Bulla L, Mongiovì M, Gangemi A, Rucci P. Semi-Automatic Systematic Literature Reviews and Information Extraction of COVID-19 Scientific Evidence: Description and Preliminary Results of the COKE Project. Information. 2022; 13(3):117. https://doi.org/10.3390/info13030117
Chicago/Turabian StyleGolinelli, Davide, Andrea Giovanni Nuzzolese, Francesco Sanmarchi, Luana Bulla, Misael Mongiovì, Aldo Gangemi, and Paola Rucci. 2022. "Semi-Automatic Systematic Literature Reviews and Information Extraction of COVID-19 Scientific Evidence: Description and Preliminary Results of the COKE Project" Information 13, no. 3: 117. https://doi.org/10.3390/info13030117