
Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection


Abstract
:1. Introduction
- The proposed method acquires user characteristics from user profiles, and extracts key features from source tweets and comments using BERT and hierarchical attention mechanisms.
- A dual collaborative attention mechanism is proposed to explore the correlation between publishing user profiles and tweet contents, and between tweet contents and associated comments.
- The experimental results on Weibo, CED, and other datasets show that the proposed method significantly improves the performance of rumor detection, and performs well in early rumor detection tasks.
2. Related Works
2.1. Content-Based Methods
2.2. User-Based Methods
2.3. Hybrid Methods
2.4. Propagation-Based Methods
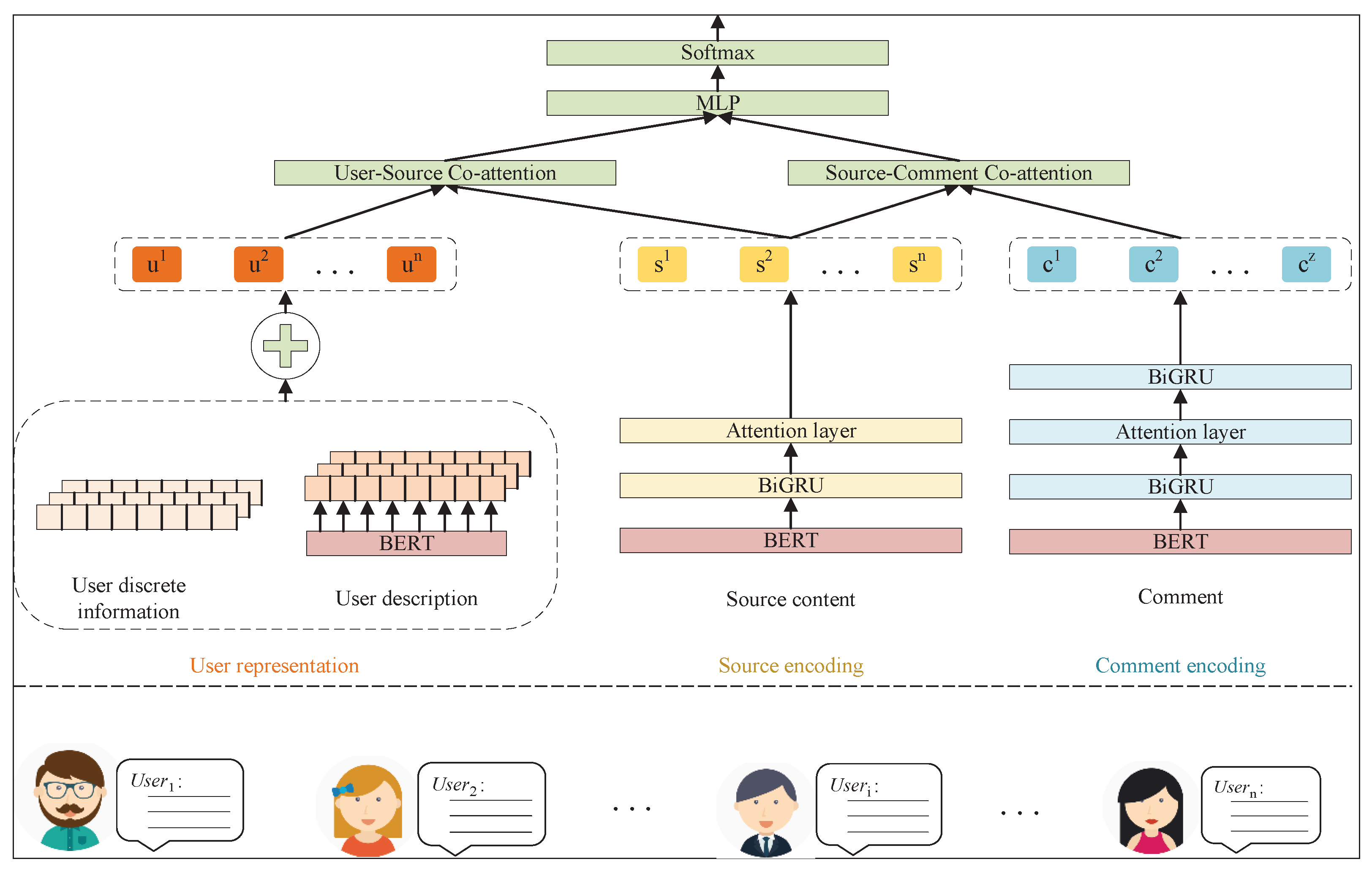
3. Bdconn Method for Rumor Detection
- (1)
- User feature module. This module is used to quantify user information and extract its vector representation.
- (2)
- Source text encoding module. This module is used to generate the vector representation of the publisher’s source text.
- (3)
- Comment feature extraction module. This module is used to extract the sentence vector representation from the user’s comments.
- (4)
- Dual co-attention module. This module is used to extract the correlation between user profiles and source tweets, and the correlation between source tweets and comments.
3.1. User Feature Module
3.1.1. User Discrete Information
3.1.2. User Descriptions
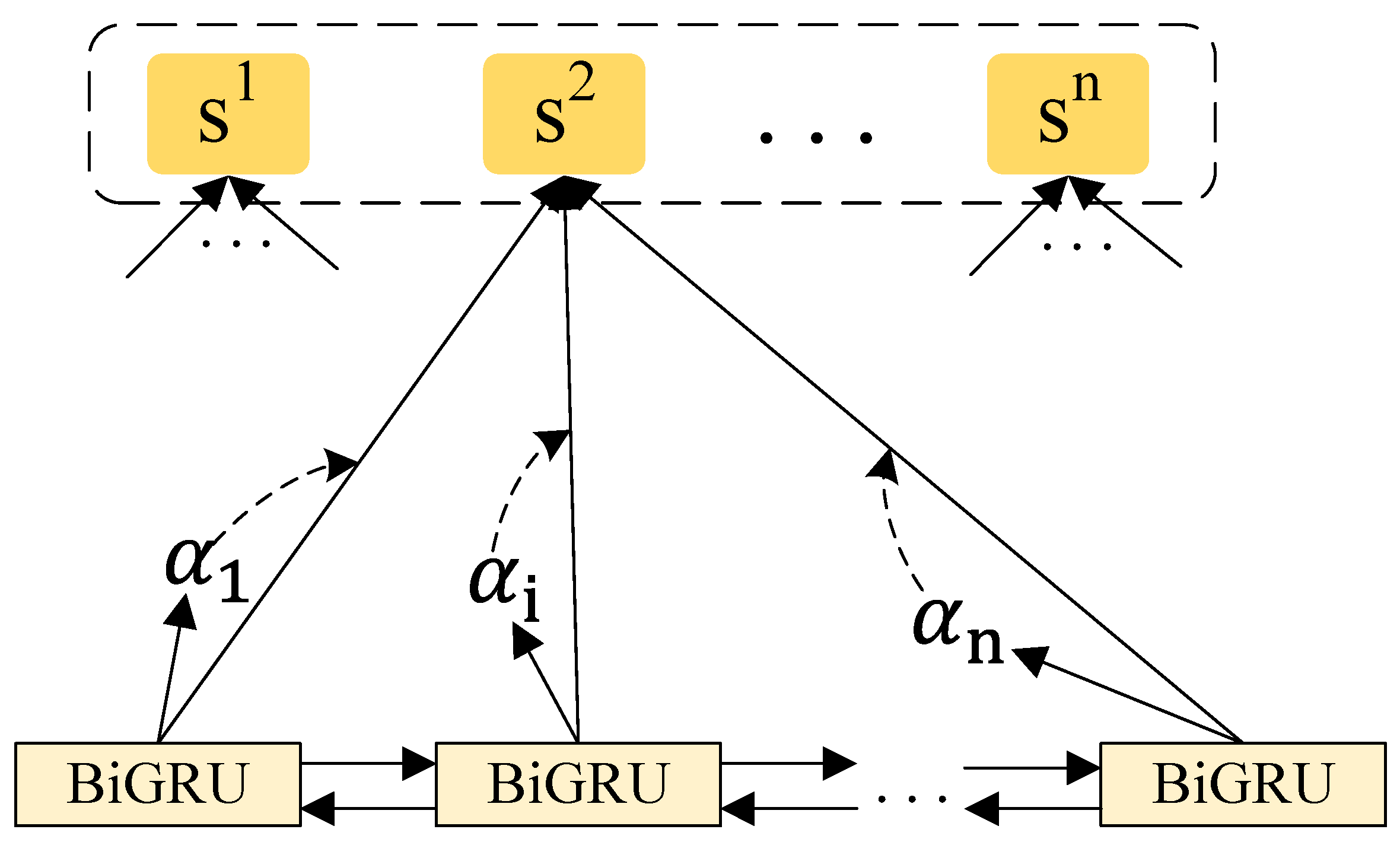
3.2. Source Text Encoding Module and Comment Feature Extraction Module
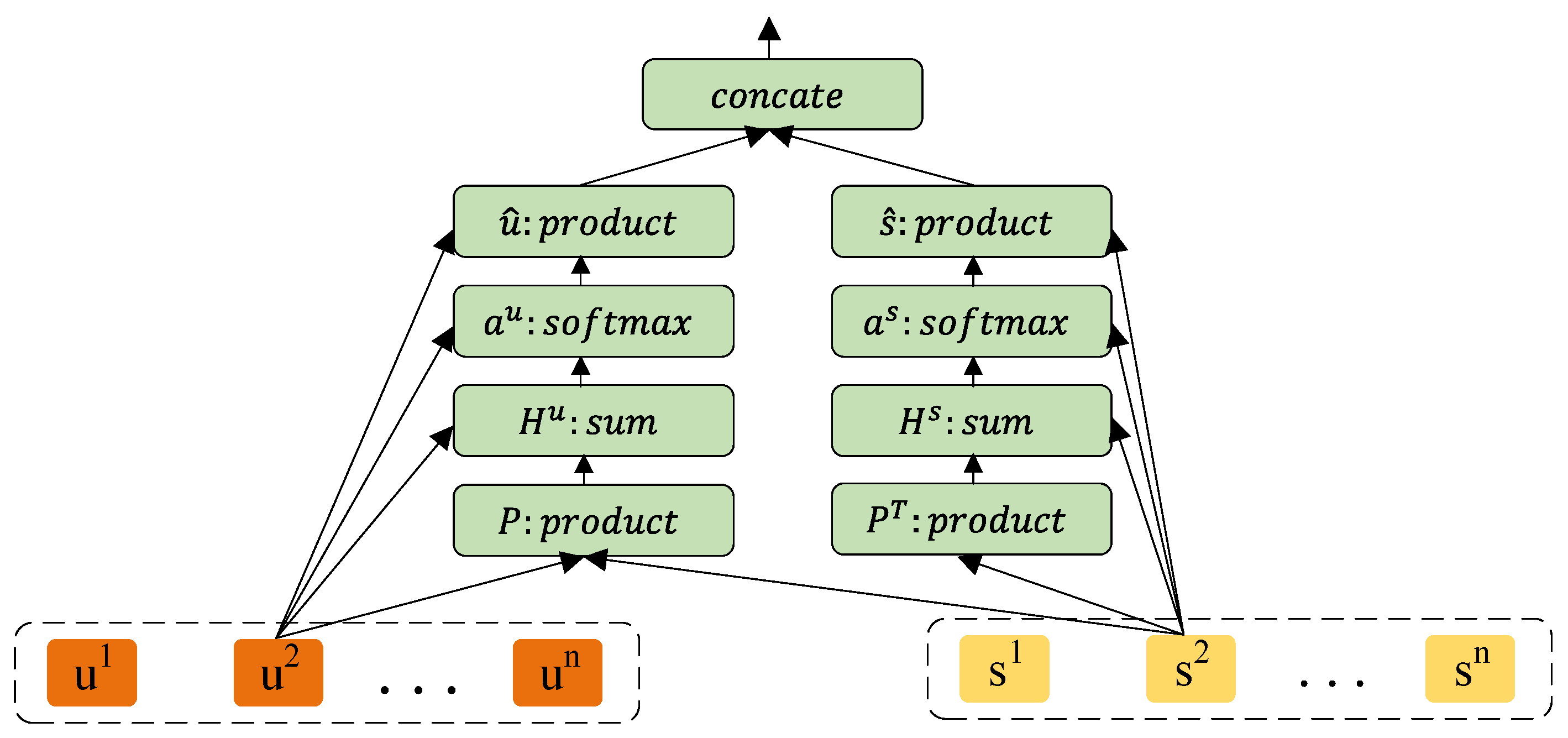
3.3. Dual Co-Attention Module
3.4. Prediction
4. Experiment Results and Analysis
4.1. Dataset
4.2. Baseline Methods
- (1)
- TextCNN [31]: TextCNN uses character-level word2vec to convert microblog events that are composed of source text and comments into vectors. A CNN is utilized to process these vectors, in which multiple convolution filters are used to capture features with different granularities.
- (2)
- HAN [32]: HAN uses word-level word2vec to map Weibo events into vector representations. Its hierarchical attention network structure assigns different attentions to words and sentences. A “word-sentence-event” hierarchical structure is used to represent an event.
- (3)
- GRU-2 [9]: GRU-2 arranges the posts in each microblog in chronological order. Using the time interval generation algorithm, the posts are roughly divided into N parts with the same interval. A two-layer GRU network is used, and its input is the TF-IDF values of the text in the current time interval.
- (4)
- dEFEND [23]: dEFEND is a collaborative attention model for learning the association between long news and its comments. dEFEND captures the top-K important sentences in long news through a hierarchical attention mechanism. These important news sentences and their associated comments are used to generate a representation of the microblog.
- (5)
- TextGCN [35]: TextGCN constructs the corpus into a graph, uses one-hot encoding to process words and documents, and uses TF-IDF values as the weights of the document-word edge to capture global word co-occurrence information, and the relationship between documents and words.
- (6)
- BERT [30]: BERT is a pre-training language model based on a transformer, and uses MLM to generate a deep bidirectional language representation, which performs well in multiple NLP tasks. In its implementation, feature vectors extracted by BERT are input to the fully connected layer to categorize microblog rumor events.
4.3. Experimental Evaluation Index
- (1)
- Accuracy: It is defined as the proportion of the correctly predicted events among all events.
- (2)
- Precision: It represents the proportion of actual rumors among all events predicted to be rumors.
- (3)
- Recall: It indicates the proportion of correctly predicted rumors in all actual rumors.
- (4)
- F1: It is a weighted harmonic average of the Precision and Recall, which is a comprehensive consideration of Precision and Recall.
4.4. Experimental Setup
4.5. Experimental Results and Analysis
4.5.1. Rumor Detection Performance
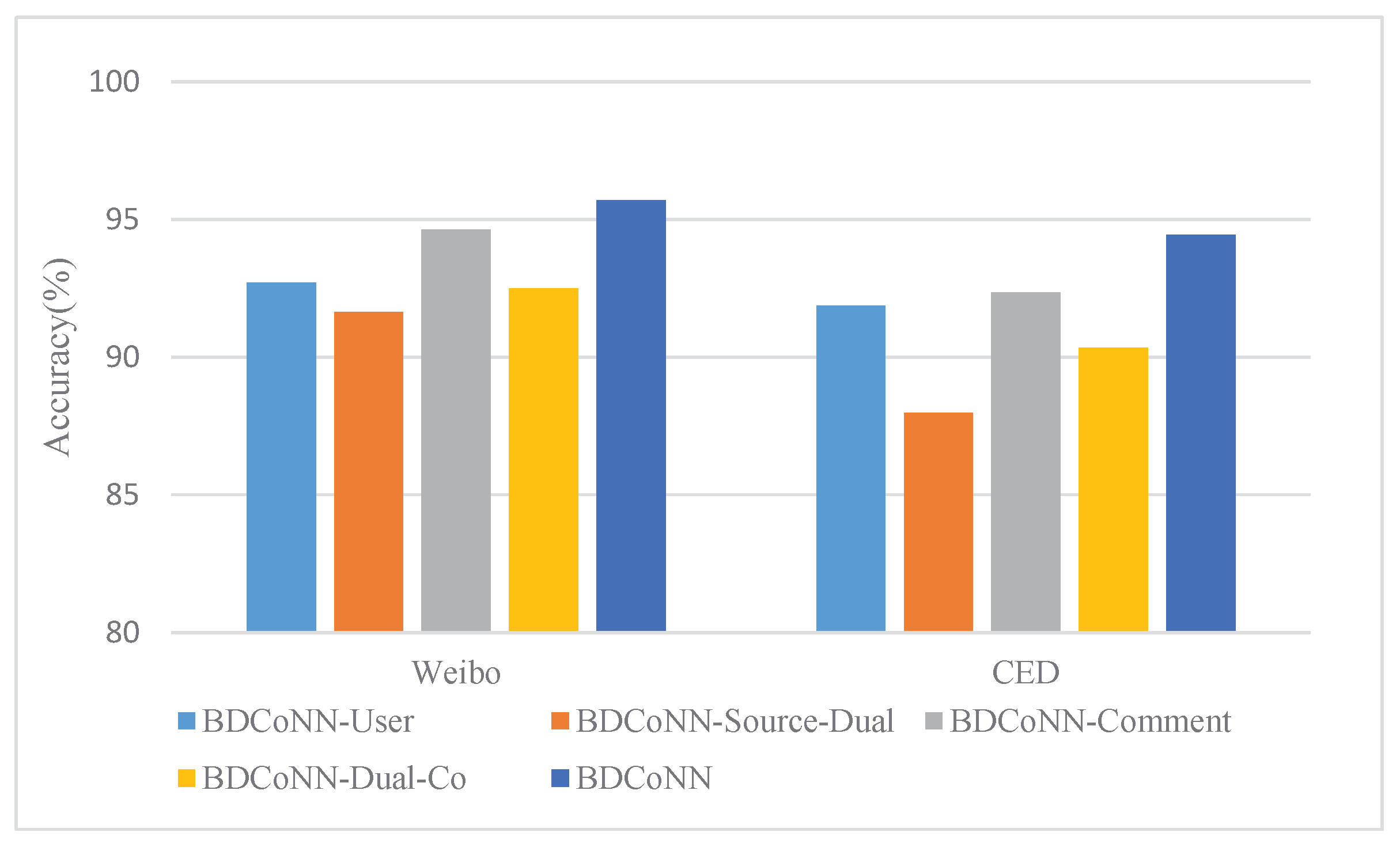
4.5.2. Ablation Experiments
- (1)
- BDCoNN-User: In this experiment, the user feature module was removed, and only the source text and its corresponding comments were considered. The vector representation through the dual co-attention module is obtained, then feed into MLP and softmax layer for rumor prediction.
- (2)
- BDCoNN-Source-Dual: In this experiment, the source text encoding module and the dual co-attention module were removed. The hidden vector extracted from the user feature module was concatenated with the comment hidden vector, which was input into the fully connected layer and softmax layer for rumor detection.
- (3)
- BDCoNN-Comment: In this experiment, the comment feature extraction module was removed, and only the user profile information and the source text were encoded. The correlation between the user feature and the source text feature was learned using the co-attention mechanism, and the results were feed into MLP and softmax layer for classification.
- (4)
- BDCoNN-Dual-Co: In this experiment, the dual co-attention module was removed. The feature vectors of user profiles, source text, and comments were concatenated, and then feed into MLP layer and softmax layer for classification.
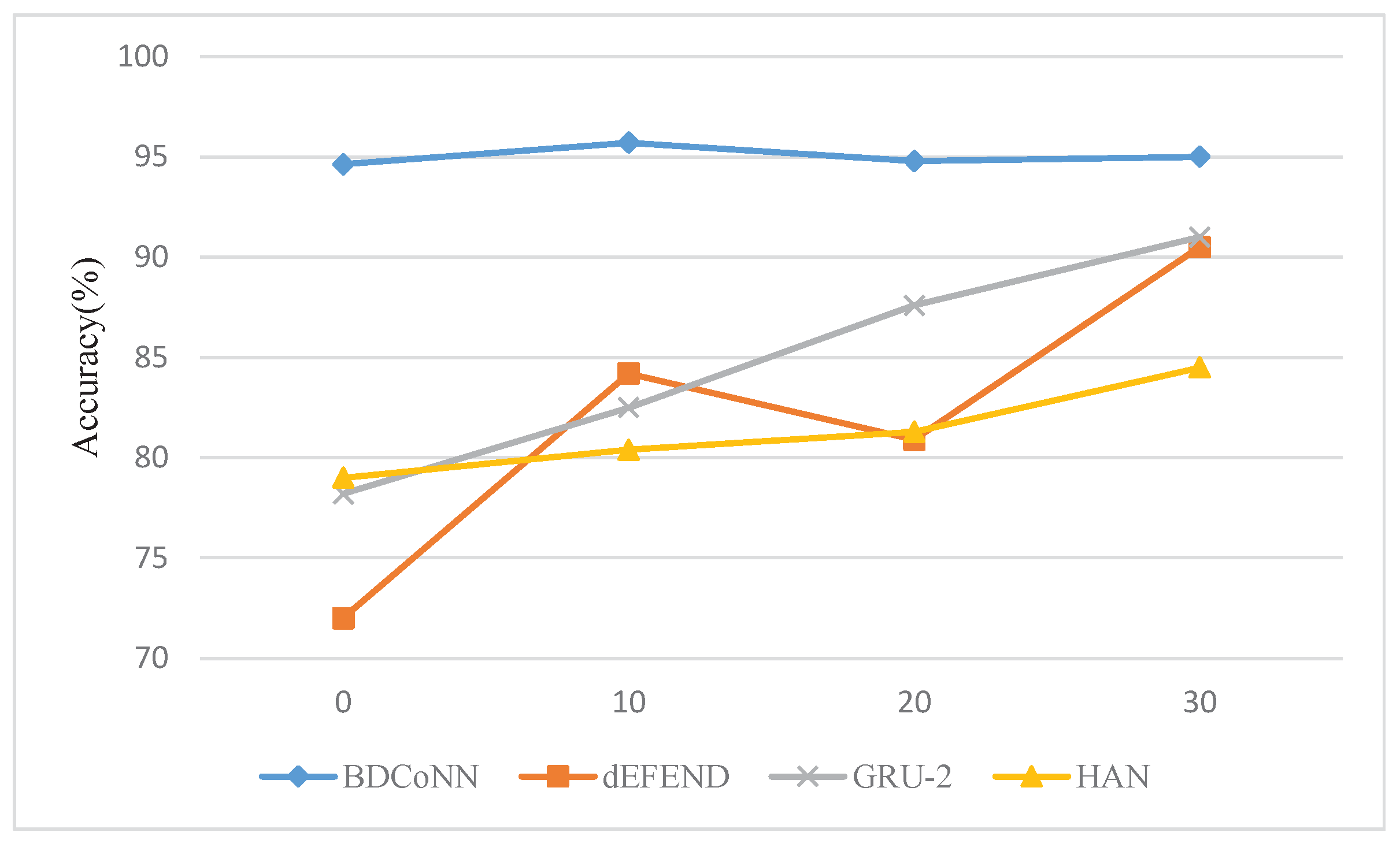
4.5.3. Early Rumor Detection
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Dharawat, A.; Lourentzou, I.; Morales, A.; Zhai, C. Drink bleach or do what now? covid-hera: A dataset for risk-informed health decision making in the presence of covid19 misinformation. arXiv 2020, arXiv:2010.08743. [Google Scholar]
- Morales, A.; Narang, K.; Sundaram, H.; Zhai, C. CrowdQM: Learning aspect-level user reliability and comment trustworthiness in discussion forums. Adv. Knowl. Discov. Data Min. 2020, 12084, 592. [Google Scholar]
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53, 109. [Google Scholar] [CrossRef]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and Resolution of Rumours in Social Media: A Survey. ACM Comput. Surv. 2018, 51, 32. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Liang, G.; Jiang, F.; Xu, C.; Yang, J.; Chen, J.; Wang, H. Social Network Rumor Detection: A Survey. Acta Electron. Sin. 2020, 48, 1421–1435. [Google Scholar]
- Zhang, Q.; Zhang, S.; Dong, J.; Xiong, J.; Cheng, X. Automatic Detection of Rumor on Social Network. In Natural Language Processing and Chinese Computing; Li, J., Ji, H., Zhao, D., Feng, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 113–122. [Google Scholar]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring Minds: Early Detection of Rumors in Social Media from Enquiry Posts. In Proceedings of the WWW ’15: 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2015; pp. 1395–1405. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y.; Wong, K.F. Detect Rumors Using Time Series of Social Context Information on Microblogging Websites. In Proceedings of the CIKM ’15: 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1751–1754. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; MItra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the IJCAI ’16: 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3818–3824. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 797–806. [Google Scholar]
- Tu, K.; Chen, C.; Hou, C.; Yuan, J.; Li, J.; Yuan, X. Rumor2vec: A rumor detection framework with joint text and propagation structure representation learning. Inf. Sci. 2021, 560, 137–151. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, Y.; Liu, K. Perceiving more truth: A dilated-block-based convolutional network for rumor identification. Inf. Sci. 2021, 569, 746–765. [Google Scholar] [CrossRef]
- Xu, S.; Liu, X.; Ma, K.; Dong, F.; Xiang, S.; Bing, C. Rumor Detection on Microblogs Using Dual-Grained Feature via Graph Neural Networks. In PRICAI 2021: Trends in Artificial Intelligence; Pham, D.N., Theeramunkong, T., Governatori, G., Liu, F., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 205–216. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call Attention to Rumors: Deep Attention Based Recurrent Neural Networks for Early Rumor Detection. In Trends and Applications in Knowledge Discovery and Data Mining; Ganji, M., Rashidi, L., Fung, B.C.M., Wang, C., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 40–52. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learning. In Proceedings of the WWW ’19: World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 3049–3055. [Google Scholar] [CrossRef]
- Yang, F.; Liu, Y.; Yu, X.; Yang, M. Automatic Detection of Rumor on Sina Weibo. In Proceedings of the MDS ’12: ACM SIGKDD Workshop on Mining Data Semantics, Beijing, China, 12–16 August 2012; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Shu, K.; Zhou, X.; Wang, S.; Zafarani, R.; Liu, H. The Role of User Profiles for Fake News Detection. In Proceedings of the ASONAM ’19: 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Columbia, VB, Canada, 27–30 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 436–439. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.F. Early Detection of Fake News on Social Media Through Propagation Path Classification with Recurrent and Convolutional Networks. 2018. Available online: https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewPaper/16826 (accessed on 18 August 2021).
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the WWW ’11: 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 675–684. [Google Scholar] [CrossRef]
- Jin, Z.; Cao, J.; Guo, H.; Zhang, Y.; Luo, J. Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs. In Proceedings of the MM ’17: 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 795–816. [Google Scholar] [CrossRef]
- Qi, P.; Cao, J.; Yang, T.; Guo, J.; Li, J. Exploiting Multi-domain Visual Information for Fake News Detection. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 518–527. [Google Scholar] [CrossRef] [Green Version]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. DEFEND: Explainable Fake News Detection. In Proceedings of the KDD ’19: 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 395–405. [Google Scholar] [CrossRef]
- Zhou, K.; Shu, C.; Li, B.; Lau, J.H. Early Rumour Detection. In Human Language Technologies, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1614–1623. [Google Scholar] [CrossRef]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W.; Rong, Y.; Huang, J. Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks. Proc. AAAI Conf. Artif. Intell. 2020, 34, 549–556. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wong, K.F. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1980–1989. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.J.; Li, C.T. GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 505–514. [Google Scholar] [CrossRef]
- Yahui, L.; Xiaolong, J.; Huawei, S.; Bao, P.; Xueqi, C. A Survey on Rumor Identification over Social Media. Chin. J. Comput. 2020, 41, 108–130. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media: A Data Mining Perspective. Sigkdd Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Human Language Technologies, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Human Language Technologies, Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Song, C.; Yang, C.; Chen, H.; Tu, C.; Liu, Z.; Sun, M. CED: Credible Early Detection of Social Media Rumors. IEEE Trans. Knowl. Data Eng. 2021, 33, 3035–3047. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User Name | User Discrete Information | User Description |
|---|---|---|
| Sogou input method | bi_followers_count: 368 friends_count: 693 followers_count: 2,985,442 statuses_count: 6980 favourites_count: 490 comments_count: 45 | [Sogou input method smart version 2.0] lick on the light bulb or the number “0” to trigger, the software, film and television music, and the website will be available immediately after input; Chameleon, perceives the input environment, changes the color, and provides more accurate input candidates. download link: xxx[Business Cooperation] QQ: xxx |
| Guangzhou part-time full-time official website | bi_followers_count: 435 friends_count: 1516 followers_count: 636,767 statuses_count: 8285 favourites_count: 13 comments_count: 72 | For companies to post recruitment information or part-time full-time recruitment, please contact QQ: xxx, and release the latest and most complete Guangzhou part-time full-time internship information every day. All the information released is free of card charges [please add QQ directly, not private messages] |
| Statistics | CED | |
|---|---|---|
| User | 2,746,818 | 1,278,567 |
| Posts | 3,805,656 | 1,392,561 |
| Events | 4664 | 3387 |
| Rumors | 2313 | 1538 |
| Non-Rumors | 2351 | 1849 |
| Method | Class | CED | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Precison | Recall | F1 | Accuracy | Precison | Recall | F1 | ||
| HAN [32] | R | 0.845 | 0.834 | 0.852 | 0.847 | 0.852 | 0.853 | 0.865 | 0.859 |
| N | 0.860 | 0.843 | 0.851 | 0.885 | 0.842 | 0.863 | |||
| TextCNN [31] | R | 0.875 | 0.883 | 0.854 | 0.868 | 0.871 | 0.859 | 0.867 | 0.863 |
| N | 0.867 | 0.893 | 0.880 | 0.888 | 0.881 | 0.885 | |||
| GRU-2 [9] | R | 0.910 | 0.876 | 0.916 | 0.898 | 0.906 | 0.890 | 0.916 | 0.898 |
| N | 0.952 | 0.864 | 0.906 | 0.913 | 0.898 | 0.905 | |||
| dEFEND [23] | R | 0.905 | 0.863 | 0.923 | 0.892 | 0.896 | 0.873 | 0.909 | 0.891 |
| N | 0.940 | 0.891 | 0.915 | 0.912 | 0.902 | 0.907 | |||
| TextGCN [35] | R | 0.881 | 0.960 | 0.842 | 0.897 | 0.899 | 0.896 | 0.892 | 0.894 |
| N | 0.790 | 0.944 | 0.860 | 0.896 | 0.892 | 0.904 | |||
| BERT [30] | R | 0.918 | 0.954 | 0.881 | 0.916 | 0.927 | 0.895 | 0.951 | 0.926 |
| N | 0.887 | 0.956 | 0.920 | 0.960 | 0.897 | 0.928 | |||
| BDCoNN | R | 0.957 | 0.943 | 0.969 | 0.956 | 0.946 | 0.916 | 0.978 | 0.946 |
| N | 0.970 | 0.947 | 0.959 | 0.978 | 0.918 | 0.947 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bing, C.; Wu, Y.; Dong, F.; Xu, S.; Liu, X.; Sun, S. Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection. Information 2022, 13, 25. https://doi.org/10.3390/info13010025
Bing C, Wu Y, Dong F, Xu S, Liu X, Sun S. Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection. Information. 2022; 13(1):25. https://doi.org/10.3390/info13010025
Chicago/Turabian StyleBing, Changsong, Yirong Wu, Fangmin Dong, Shouzhi Xu, Xiaodi Liu, and Shuifa Sun. 2022. "Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection" Information 13, no. 1: 25. https://doi.org/10.3390/info13010025