A Study on Enhancement of Fish Recognition Using Cumulative Mean of YOLO Network in Underwater Video Images



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. YOLO and Learning Data
2.1. YOLO
2.2. Learning Data and Video Image
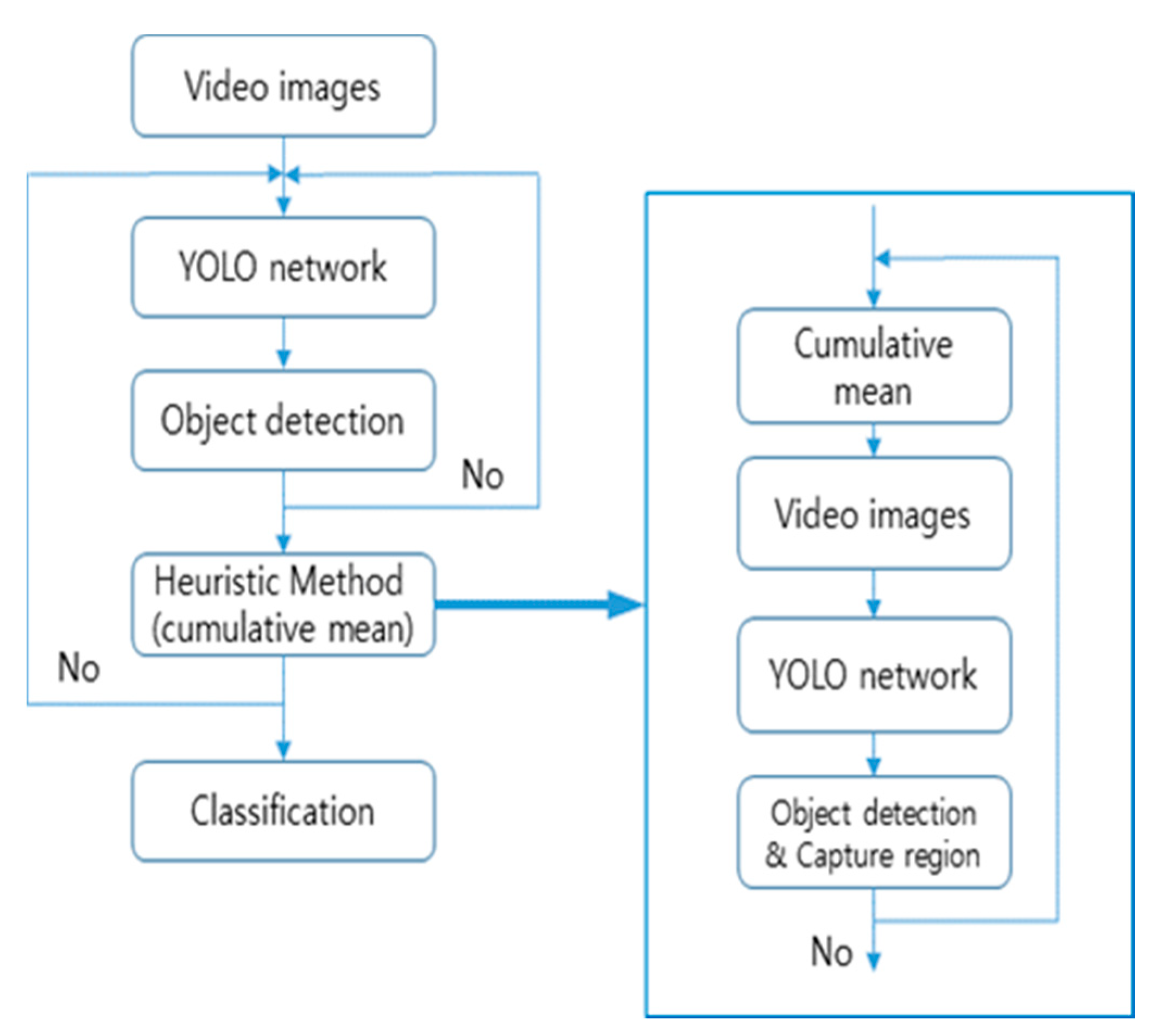
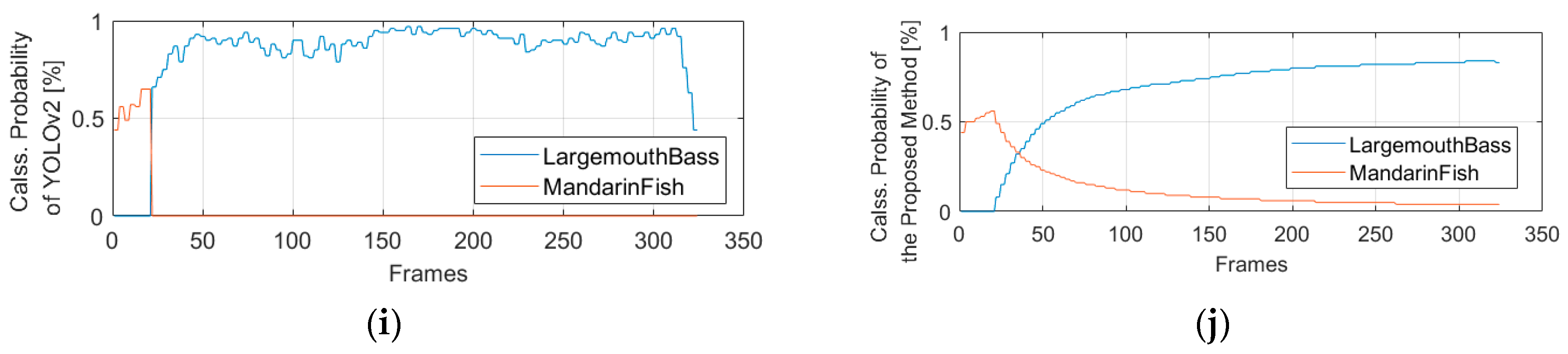
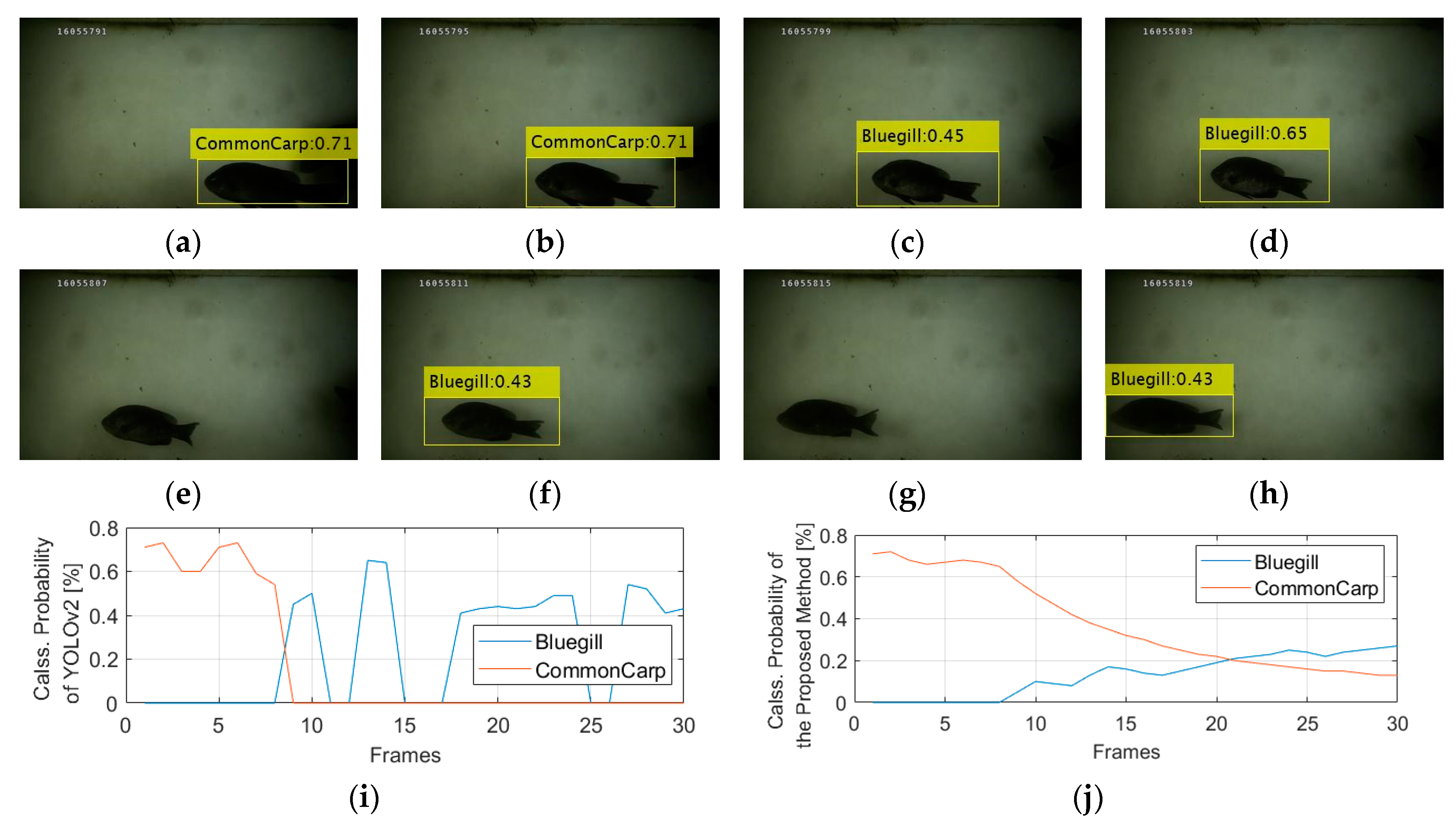
3. Proposed Method
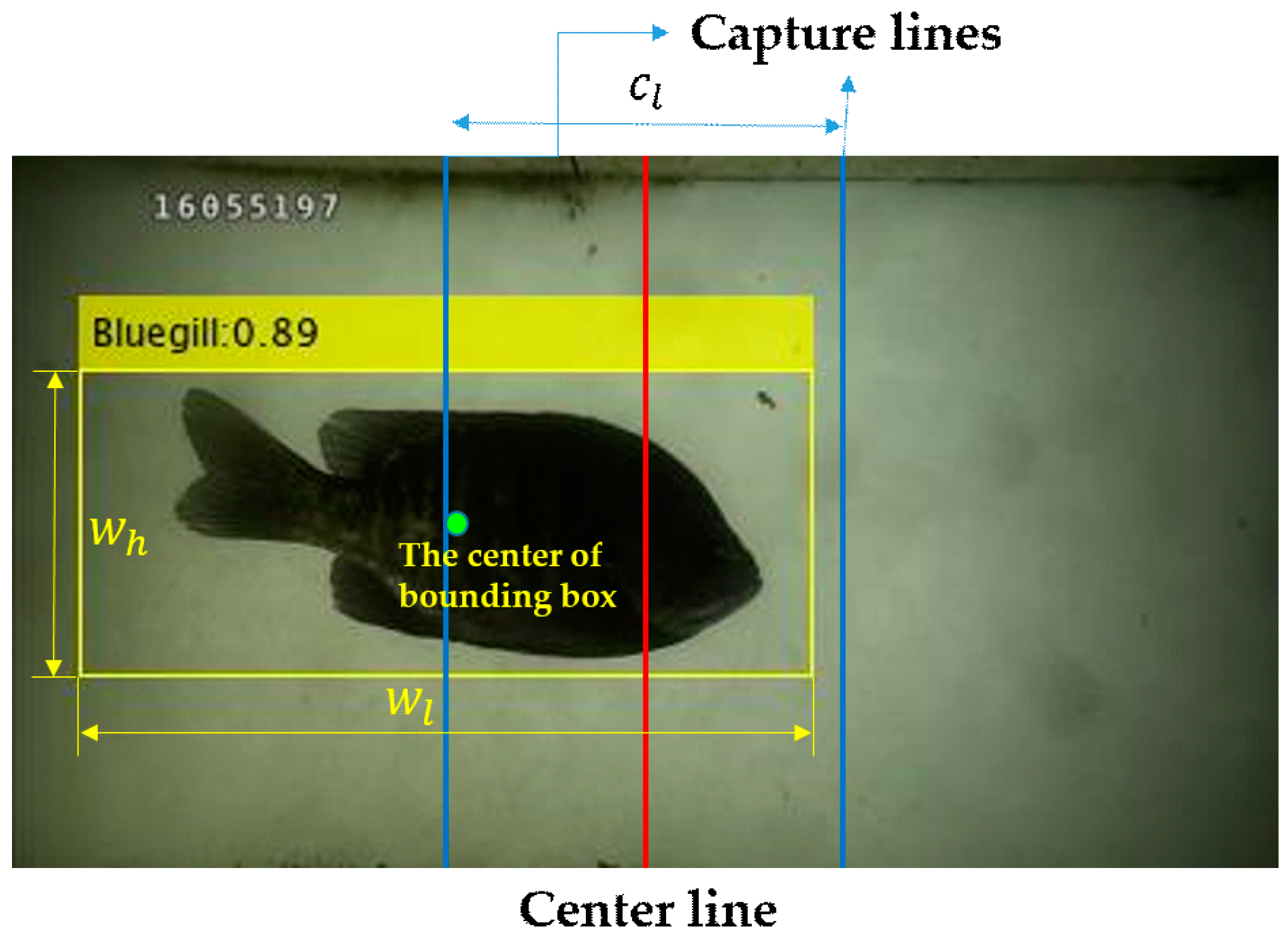
3.1. Heuristic Method
3.2. Cumulative Mean of The YOLO Network
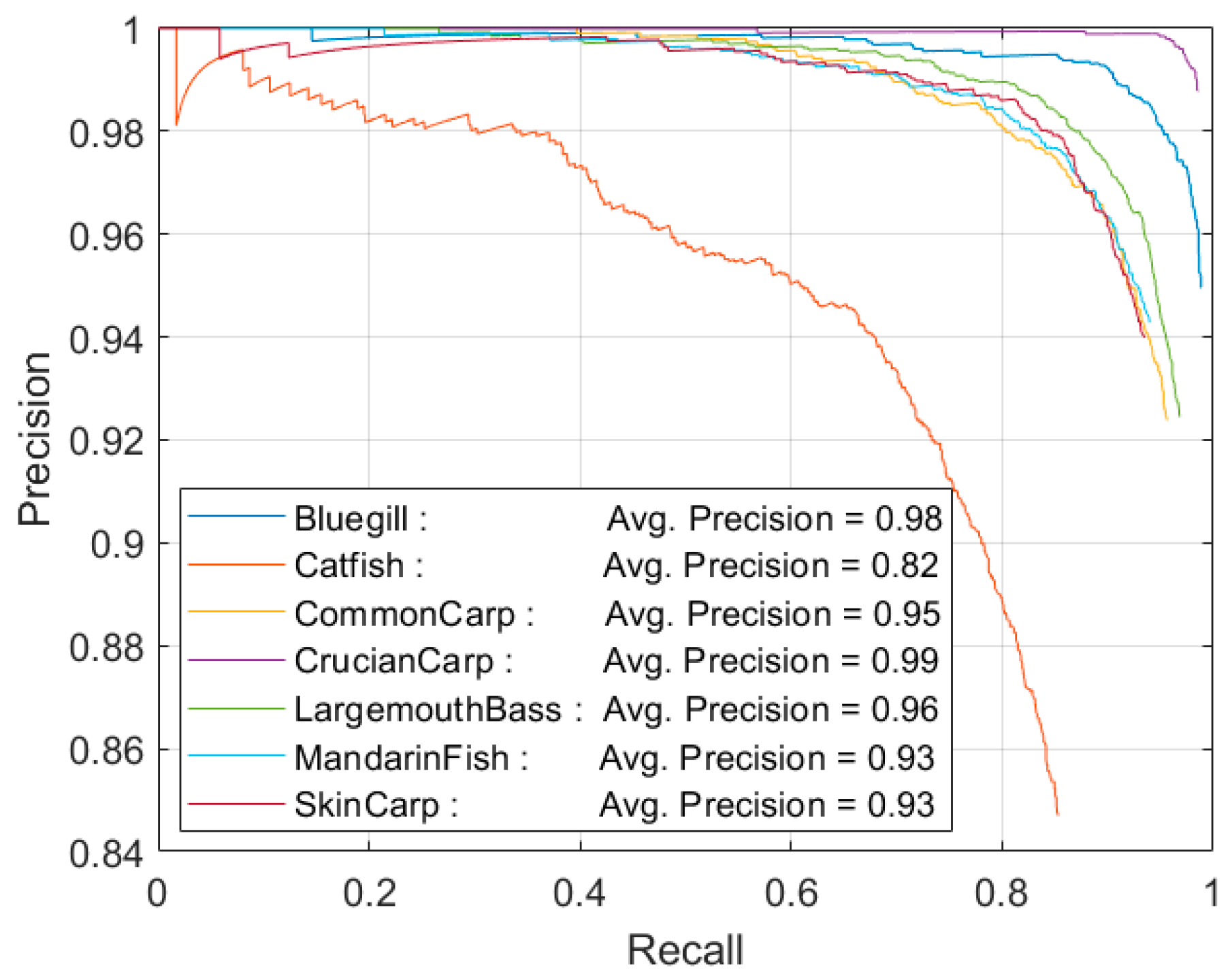
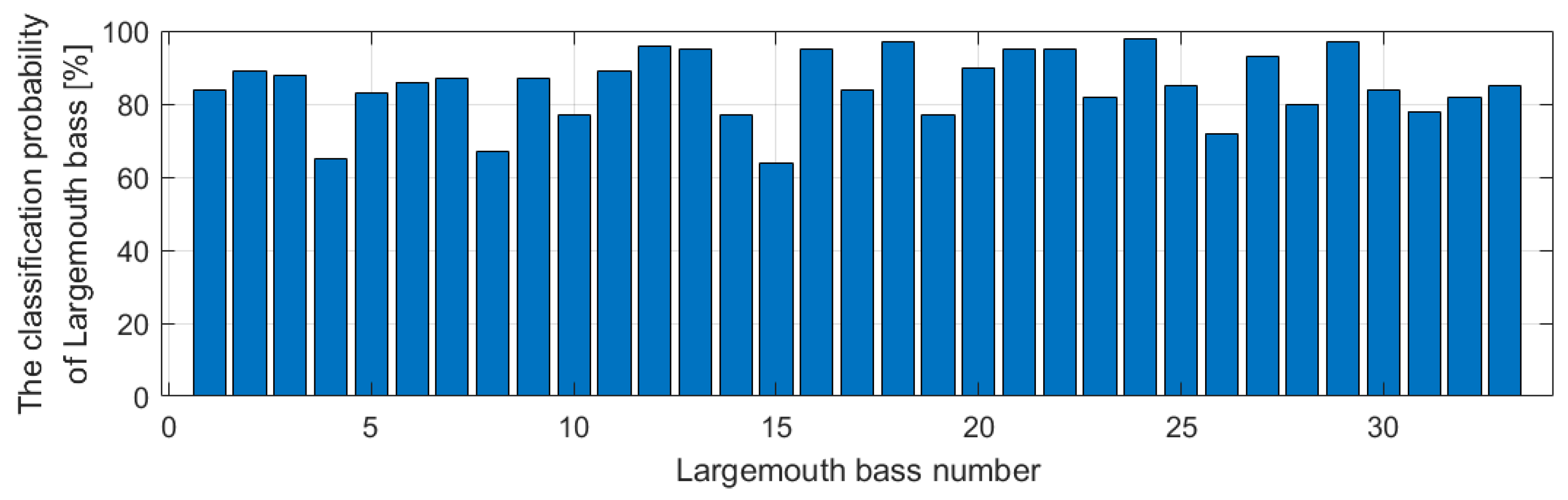
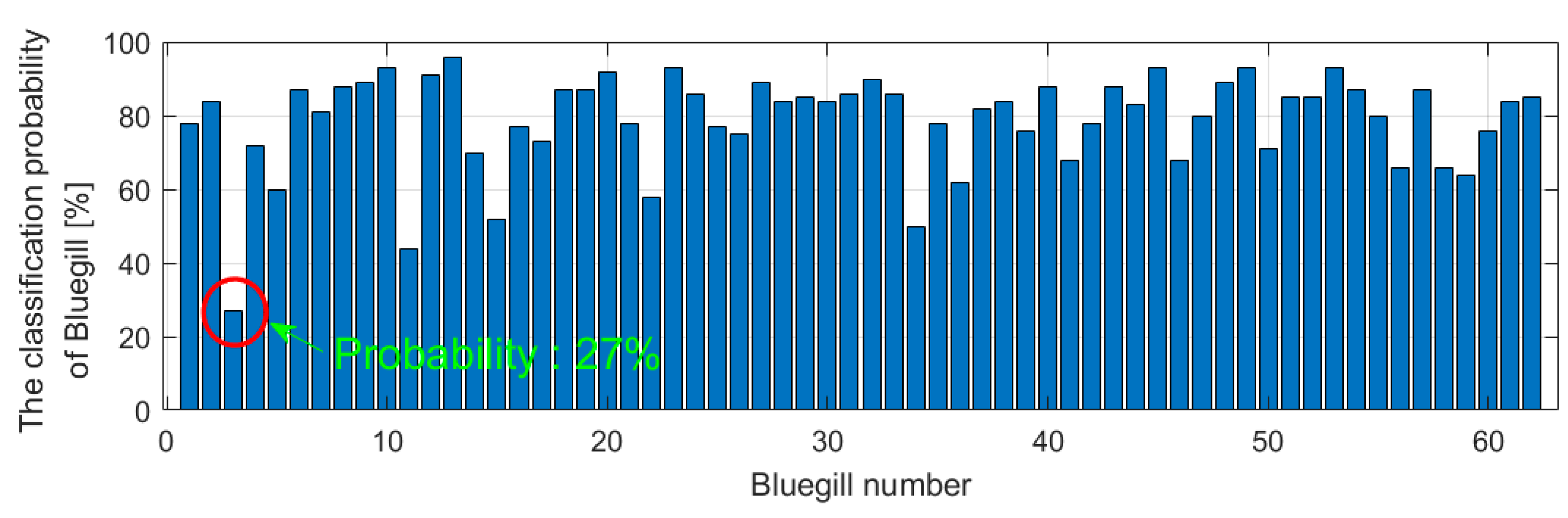
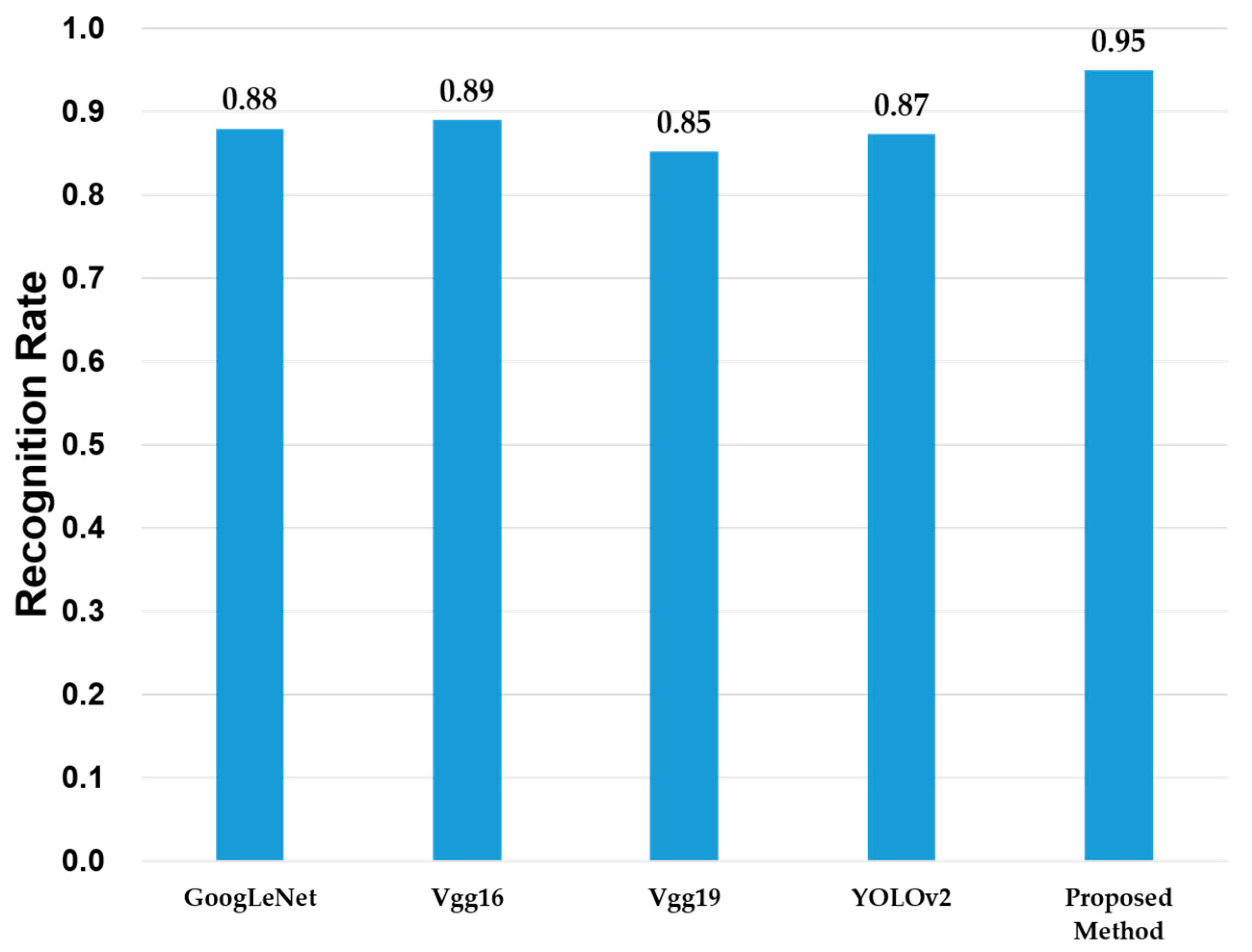
4. Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Buckland, S.T.; Turnock, B.J. A Robust Line Transect Method. Biometrics 1992, 48, 901–909. [Google Scholar] [CrossRef]
- Järvinen, O.; Väisänen, R.A. Estimating relative densities of breeding birds by the line transect method. Oikos 1975, 7, 43–48. [Google Scholar] [CrossRef]
- Buckland, S.T.; Garthwaite, P.H. Quantifying Precision of Mark-Recapture Estimates Using the Bootstrap and Related Methods. Biometrics 1991, 47, 255–268. [Google Scholar] [CrossRef]
- Miller, C.R.; Joyce, P.; Waits, L. P. A new method for estimating the size of small populations from genetic mark-recapture data. Mol. Ecol. 2005, 14, 1991–2005. [Google Scholar] [CrossRef] [PubMed]
- Vitkalova, A.V.; Feng, L.; Rybin, A.N.; Gerber, B.D.; Miquelle, D.G.; Wang, T.; Yang, H.; Shevtsova, E.I.; Aramilev, V.V.; Ge, J. Transboundary cooperation improves endangered species monitoring and conservation actions: A case study of the global population of Amur leopards. Conserv. Lett. 2018, 11, 12574. [Google Scholar] [CrossRef]
- Bischof, R.; Brøseth, H.; Gimenez, O. Wildlife in a Politically Divided World: Insularism Inflates Estimates of Brown Bear Abundance. Conserv. Lett. 2016, 9, 122–130. [Google Scholar] [CrossRef]
- Siddiqui, S.A.; Salman, A.; Malik, M.I.; Shafait, F.; Mian, A.; Shortis, M.S.; Harvey, E.S. Automatic fish species classification in underwater videos: Exploiting pre-trained deep neural network models to compensate for limited labelled data. ICES J. Mar. Sci. 2018, 75, 374–389. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Rekha, B.S.; Srinivasan, G.N.; Reddy, S.K.; Kakwani, D.; Bhattad, N. Fish Detection and Classification Using Convolutional Neural Networks. In Proceedings of the International Conference On Computational Vision and Bio Inspired Computing, Coimbatore, India, 25–26 September 2019; pp. 1221–1231. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Park, J.-H.; Choi, Y.-K. Efficient Data Acquisition and CNN Design for Fish Species Classification in Inland Waters. J. Inform. Commun. Converg. Eng. 2020, 18, 106–114. [Google Scholar] [CrossRef]
- Briseño-Avena, C.; Schmid, M.S.; Swieca, K.; Sponaugle, S.; Brodeur, R.D.; Cowen, R.K. Three-dimensional cross-shelf zooplankton distributions off the Central Oregon Coast during anomalous oceanographic conditions. Prog. Oceanogr. 2020, 188, 102436. [Google Scholar] [CrossRef]
- Swieca, K.; Sponaugle, S.; Briseño-Avena, C.; Schmid, M.S.; Brodeur, R.D.; Cowen, R.K. Changing with the tides: Fine-scale larval fish prey availability and predation pressure near a tidally modulated river plume. Mar. Ecol. Prog. Ser. 2020, 650, 217–238. [Google Scholar] [CrossRef]
- Schmid, M.S.; Cowen, R.K.; Robinson, K.; Luo, Y.J.; Briseño-Avena, C.; Sponaugle, S. Prey and predator overlap at the edge of a mesoscale eddy: Fine-scale, in-situ distributions to inform our understanding of oceanographic processes. Sci. Rep. 2020, 10, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Theophilo, A.; Ramos, F.; de Geus, P. Malicious Software Classification Using VGG16 Deep Neural Network’s Bottleneck Features. In Information Technology-New Generations, Proceedings of the Advances in Intelligent Systems and Computing; Latifi, S., Ed.; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Ma, Y. Deepfood: Deep learning-based food image recognition for computer-aided dietary assessment. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the Inclusive Smart Cities and Digital Health. ICOST 2016; Chang, C., Chiari, L., Cao, Y., Jin, H., Mokhtari, M., Aloulou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 37–48. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the 1st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Park, J.-H.; Choi, Y.-K.; Kang, C. Fast Cropping Method for Proper Input Size of Convolutional Neural Networks in Underwater Photography. J. Soc. Inf. Disp. 2020, 28, 872–881. [Google Scholar] [CrossRef]
- Lu, X.; Lin, Z.; Shen, X.; Mech, R.; Wang, J.Z. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 990–998. [Google Scholar] [CrossRef]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Lin, Z.; Jin, H.; Yang, J.; Wang, J.Z. Rapid: Rating pictorial aesthetics using deep learning. In Proceedings of the 22nd ACM International Conference on Multimedia (MM’14); Association for Computing Machinery: New York, NY, USA, 2014; pp. 457–466. [Google Scholar] [CrossRef]
- Ma, S.; Liu, J.; Chen, C.W. A-lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolului, HI, USA, 21–26 July 2017; pp. 722–731. [Google Scholar] [CrossRef] [Green Version]
- Park, J.-H.; Hwang, K.-B.; Park, H.-M.; Choi, Y.-K. Application of CNN for Fish Species Classification. J. Korea Inst. Inf. Commun. Eng. 2019, 23, 39–46. [Google Scholar]
- Rosenblatt, M. A central limit theorem and a strong mixing condition. Proc. Natl. Acad. Sci. USA 1956, 42, 43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoeffding, W.; Robbins, H. The central limit theorem for dependent random variables. Duke Math. J. 1948, 15, 773–780. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.-H.; Kang, C. A Study on Enhancement of Fish Recognition Using Cumulative Mean of YOLO Network in Underwater Video Images. J. Mar. Sci. Eng. 2020, 8, 952. https://doi.org/10.3390/jmse8110952
Park J-H, Kang C. A Study on Enhancement of Fish Recognition Using Cumulative Mean of YOLO Network in Underwater Video Images. Journal of Marine Science and Engineering. 2020; 8(11):952. https://doi.org/10.3390/jmse8110952
Chicago/Turabian StylePark, Jin-Hyun, and Changgu Kang. 2020. "A Study on Enhancement of Fish Recognition Using Cumulative Mean of YOLO Network in Underwater Video Images" Journal of Marine Science and Engineering 8, no. 11: 952. https://doi.org/10.3390/jmse8110952