1. Introduction
In recent years, as the economy and society have continued to evolve, pollution problems caused by the increased consumption of fossil fuels have grown more severe; consequently, many nations have begun to pay more attention to sustainable energy [
1,
2]. Regarding environmental protection, wind energy has inherent advantages over natural gas, coal, and other energy sources. To attain the objective of decarbonization by 2050, substantial expansion is anticipated in the offshore wind power sector in the coming decades [
3,
4]. Offshore wind possesses a greater capacity for generating wind power than terrestrial wind [
5,
6]. Technology for offshore wind speed forecasting that is both accurate and efficient is essential for increasing the utilization rate and economic benefits of wind energy [
7,
8].
The variability and stochastic nature of offshore wind speed are unavoidable consequences of numerous environmental factors. The prediction of offshore wind time series is a challenging aspect of marine forecasting and constitutes an abstract high-level regression problem [
9]. The current state of wind power forecasting methods can be broadly classified into two categories: physical methods and NWP methods. Physical methods utilize NWP information to compute wind speed; however, their reliance on thermodynamics and fluid dynamics results in low efficiency and high computing expenses [
10]. Physical models have a restricted capacity for short-term wind power forecasting [
11] due to the high computational complexity resolved by NWP models.
Statistical and ML techniques optimize model parameters through the utilization of historical data. In addition to requiring substantial computing resources for the training procedure, forecasting models necessitate a considerable volume of sample data [
12]. However, these models exhibit a rapid inference process, enabling the generation of predictions in close proximity to real time. As a result, artificial intelligence has become more significant, and neural network-based deep learning models have garnered considerable interest [
13]. In the early stages of neural network research, relatively rudimentary models such as ANN [
14] and BP [
15] were utilized. The current domain of deep learning frequently employs more intricate deep network architectures, including CNN [
16], RNN [
17], and GRU [
18], as a result of its development. Through the utilization of their distinctive model structures, they are capable of circumventing the gradient vanishing problem and enhancing the resistance of conventional neural networks to local optima that arise during the prediction of highly correlated wind power time series data. This renders them more appropriate for the prediction of short-term wind power output, which is distinguished by substantial data volumes and multidimensional attributes [
19].
Ding et al. [
20], based on the LSTM model, combined with EMD to predict the crosswind speed and downwind speed, then calculate the predicted wind direction value to achieve wind direction prediction. One month of wind monitoring data collected by the structural SHM is used to verify the effectiveness of direct prediction and indirect prediction in the prediction of wind speed and direction. Karim et al. [
21] proposed a RNN prediction model combined with the dynamic adaptive Al-Biruni earth radius algorithm to predict wind power data patterns. Huang et al. [
22] used an LSTM neural network to predict wind speed for each wind turbine to obtain residual values and extract time correlations of wind speed sequences. Zhu et al. [
23] proposed a wind speed prediction model with spatio-temporal correlations, namely the PDCNN. This model is a unified framework that integrates CNN and MLP. Xiong et al. [
24] proposed a multi-dimensional extended feature fusion model AMC-LSTM to predict wind power. The attention mechanism is used to dynamically allocate weights to physical attribute data, which effectively solves the problem that the model cannot distinguish differences in the importance of input data.
Currently, however, the majority of deep learning techniques only utilize time series data from wind sites. Nevertheless, the potential spatial dependence among wind sites must also be taken into account in practical applications [
25]. As a result of their local connectivity and permutation invariance, GNNs have experienced tremendous success in modeling data relational dependencies in recent years [
26].
Geng et al. [
7] proposed a universal graph optimized neural network for multi-node offshore wind speed prediction—the spatio-temporal correlated graph neural network. Khodayar et al. [
27] proposed a scalable graph convolutional deep learning architecture (GCDLA). This model introduces a rough set theory by approximating upper and lower bound parameters in the model. Yu et al. [
28] proposed an SGNN (superposition graph neural network) for feature extraction, which can maximize the utilization of spatial and temporal features for prediction. In the four offshore wind farms used in the experiments, the mean square error of this method is reduced by 9.80% to 22.53%. Xu et al. [
29] proposed a new spatio-temporal prediction model based on optimal weighted GCN and GRU, using DTW distance for constructing optimal weighted graphs between different wind power plant sites. The graph neural network in the above method effectively aggregates the spatio-temporal information, but only considers the overall correlation of the sequence when constructing the adjacency matrix and does not consider that the correlation may be different in local time.
To address the aforementioned obstacles and optimize the utilization of spatio-temporal data, this article centers on the implementation of spatio-temporal data within a graph neural network-based multi-step wind forecasting method. In order to address the issue of inadequate local information capture, this study introduced a dynamic graph-embedding technology and developed a GAT-LSTM network structure to capture spatio-temporal information on wind speed from multiple stations. This research endeavors to produce wind speed forecasts with a greater degree of precision by generating information-enriched time series via multi-step forecasting. The overarching objective is to enable more accurate decision-making within a designated time frame. Within this framework, the objective of this research is to examine multi-step prediction. Each step will have a duration of 10 min, 1 h, and 4 h, and the pre-prediction time resolution will be 10 min.
The contributions of this paper can be summarized as:
To address the insufficient capability in modeling complex spatio-temporal features in existing offshore wind speed prediction research, this study proposes a DGE technique. By constructing subgraphs at each time step, the model’s ability to capture local feature dependencies is effectively enhanced, achieving dynamic modeling of offshore wind fields.
The effective integration of GAT and LSTM networks enables the model to have both the advantages of mining complex nonlinear spatial dependencies and temporal dynamic evolutions. By fully incorporating nodal modal features and topological structures, the capability of modeling temporal correlations of offshore wind fields is significantly improved, achieving accurate multi-step wind speed prediction.
Experimental results show that on the public offshore wind speed dataset from the NDBC (National Data Buoy Center), the proposed model achieves effective multi-step wind speed prediction, verifying the applicability of the method.
3. Experimental Results and Analysis
3.1. Experiment Design
All the experiments in this paper were conducted on a personal computer running on a Windows 11 operating system. The computer is equipped with a 12th Gen Intel(R) Core(TM) i7-12700 processor (Manufacturer: Intel, Santa Clara, CA, USA) and 1660 Supergraphics card (Manufacturer: Nvidia, Santa Clara, CA, USA), and uses a 256 GB SN740 NVMe WD solid state drive for storage (Manufacturer: Western Digital, San Jose, CA, USA). In addition, the PyTorch version used in this paper is 2.1, and the CUDA version is 12.1. numpy is version 1.24.4, pandas is version 2.1.4, and matplotlib is version 3.5.1.
The following experimental results are the average values obtained by repeating experiments 10 times.
3.2. Evaluation Metrics
For the purpose of assessing the performance of the model, this paper employs two evaluation indicators: MAE and RMSE. MAE exhibits enhanced robustness towards outliers or anomalies due to its construction as the mean of absolute errors, rendering it relatively unaffected by substantial error magnitudes. Since RMSE is calculated as the square root of the mean of the squared errors, it becomes more susceptible to large error values. This increases the likelihood that it will penalize significant errors, so it may more accurately reflect the model’s sensitivity to such errors in certain circumstances.
where is the number of data points, is the actual value, and is the predicted value.
3.3. Experimental Results
This section will encompass the execution of the model’s experiments. To evaluate the model’s performance as advertised, two distinct groups of experiments were devised. The initial experiment is the benchmark model experiment, in which the predictive ability of the model is evaluated by comparing it to several benchmark models. Experiment 2 is the ablation experiment, in which each component of the model is progressively substituted in order to determine the effect of each component on performance.
The data used in this study span the time period from 00:00:00 1 January 2022 to 23:50:00 31 October 2022. In order to verify the generalization and robustness of the model, 2-test set cross-validation is used. This strategy can make full use of all the data, and all the data including the test set are involved in the training and evaluation process of the model. Compared with the standard time series cross-validation, the computational overhead is relatively small. Therefore, the initial 60% is designated as the training set, followed by the final 20% as the validation set, and the final 20% is divided equally into a K1-test set and a K2-test set in chronological order. The training set is used to train the model, while the validation set is used to validate the model hyperparameters to prevent overfitting and underfitting, and the test set is used to evaluate the performance of the model.
3.3.1. Experiment I
In Experiment I, the DGE-GAT-LSTM proposed in this paper will be compared with LSTM, BILSTM, GRU, RNN, BIRNN, Seq2Seq and other models, The relevant introduction of each model is as follows:
LSTM is a recurrent neural network designed to process sequential data and capture long-term dependencies through gating units.
BILSTM considers context information simultaneously through forward and backward LSTM layers and is suitable for a variety of sequence tasks.
GRU is a recurrent neural network similar to LSTM with fewer parameters and a lower computational cost.
RNN is one of the earliest sequence models, but it faces the vanishing gradient problem and is not suitable for long-term dependence tasks.
BIRNN combines a forward and backward RNN or LSTM layers to fully understand sequence data and is suitable for a variety of tasks.
Seq2Seq models are used for sequence-to-sequence tasks, including machine translation and speech recognition, and consist of an encoder and a decoder.
In order to achieve more convincing results in the benchmark experiment, this paper uses a grid search to search the hyperparameters of the benchmark model, aiming to find the optimal parameters to compare with the proposed model. The goal of a grid search is the number of hidden layers and the number of network layers. The search ranges are [32, 64, 128] and [1, 2, 3]. The determined optimal parameters of each benchmark model are shown in
Table 2.
To ensure the fairness of the experiment, the remaining hyperparameters are consistent: the epoch is 30, the sliding window size is 24, and the batch size is 24. In order to avoid over-connection, dense edges are also ensured for the subsequent extraction of spatial features. The cosine similarity threshold is 0.4. This means that there are more than 0.4 connections between nodes. This means that there is a connection between nodes greater than 0.4. The SGD optimizer was used with a learning rate of 0.005, momentum = 0.9, and weight_decay = 1 × 10
−6. The prediction results are shown in
Table 3.
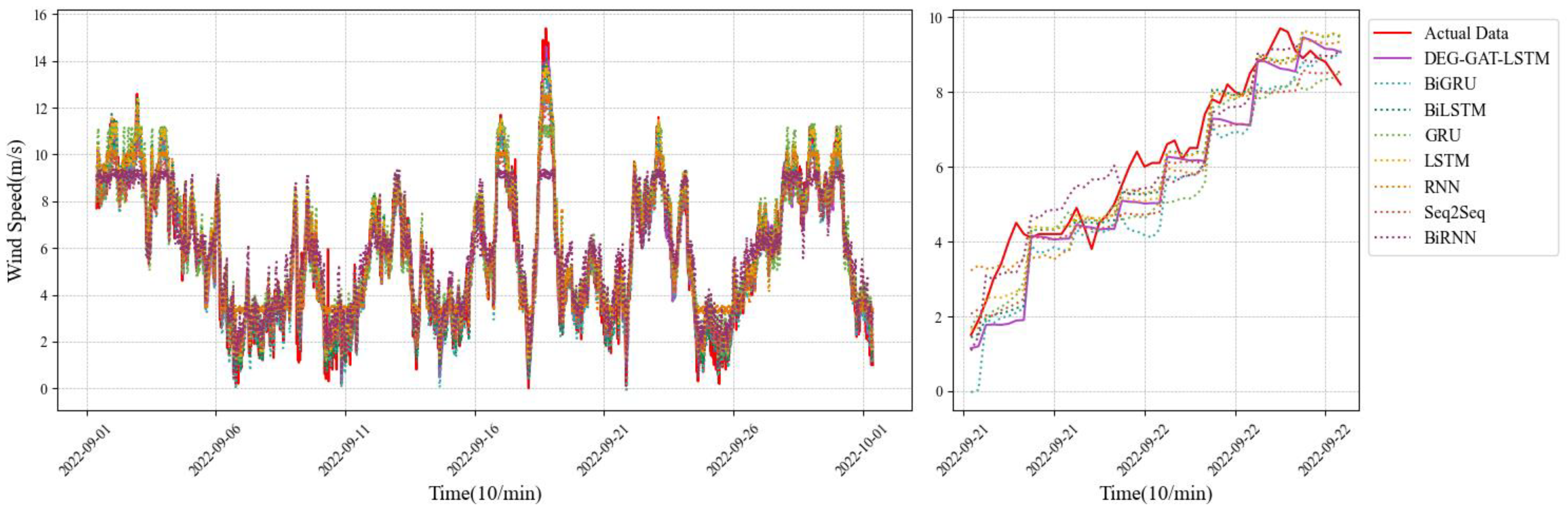
By examining
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 and
Table 3, it is evident that the DGE-GAT-LSTM model, which was proposed, obtained the smallest MAE and RMSE values for single-step, 6-step, and 24-step predictions, respectively. This finding underscores the model’s superior performance in terms of predictions.
For a 1-step (10 min) prediction, the MAE index of DGE-GAT-LSTM model decreases by 1–7%, and the RMSE index decreases by 2–9%, respectively. For a 6-step (10 min) prediction, the MAE index of the DGE-GAT-LSTM model decreases by 6–37%, and the RMSE index decreases by 4–36%, respectively. For a 24-step (10 min) prediction, the MAE index of DGE-GAT-LSTM model decreases by 1–8%, and the RMSE index decreases by 1–6%, respectively.
Experimental results show that compared with traditional sequence prediction models (such as LSTM, BILSTM, GRU, BIGRU, etc.), the DGE-GAT-LSTM model shows superior accuracy and efficiency in each time increment in the prediction task. The results prove that the DGE-GAT-LSTM model can effectively capture the dynamic characteristics and complex dependencies in time series data through its combination of a dynamic graph embedding strategy and a graph attention network, as well as the application of a long short-term memory network when dealing with time series prediction problems, thus providing a more accurate prediction.
3.3.2. Experiment II
Principally, a comparison of ablation experiments is conducted in this experiment. To ascertain the extent to which each model component can influence the overall model, the following five model groups are established:
Model1 purpose: The original model serves as a baseline for comparison
Model without residuals: model2 Objective: To analyze the effect of the residual structure
Model without graph attention: model3 Objective: To verify the effectiveness of the graph attention mechanism
Model without LSTM: model4 Objective: To test the effect of LSTM on the model performance
Model5 without DGE objective: To test the performance of dynamic graph embedding
Epochs are all 30, the batch size is 24, the sliding window size is 24, an Adam optimizer is used, and the learning rate is 0.001. The experimental results are shown in
Figure 12 and
Figure 13 and
Table 4.
The MAE of Model2 is 0.4298, which is 25.69% higher than the baseline model, and the RMSE is 0.5548, which is 21.96% higher than the baseline model. This indicates that the residual structure has a positive impact on the model performance, and its absence leads to an increase in error. The MAE of Model3 is 0.3729, 9.06% higher than that of the baseline model, and RMSE is 0.5027, 10.50% higher than that of the baseline model. This shows that the graph attention mechanism plays an important role in improving the accuracy of the model. The MAE of Model4 is 1.9339, which is 465.57% higher than the baseline model, and the RMSE is 2.3262, which is 411.37% higher than the baseline model. This significant performance degradation strongly indicates that LSTM is critical to the performance of the model, which can significantly improve the accuracy and stability of prediction. The MAE and RMSE of Model5 are 0.4112, 20.26% higher than the baseline model, and 0.5361, 17.84% higher than the baseline model. This indicates that DGE also contributes positively to the model, and missing it leads to performance degradation. Therefore, residual structure, graph attention mechanism, LSTM and dynamic graph embedding are crucial for improving the prediction accuracy of the model.
4. Conclusions and Future Work
In this paper, the proposed model DGE-GAT-LSTM is evaluated through the above experiments to predict the multi-step forward wind speed at a given location of NDBC buoys through experimental simulations using real wind speed data. The direct method does not suffer from error propagation like the recursive method, so it can be used for multi-step ahead prediction. Three different long-term time horizons (1-step, 6-step, 24-step) are considered to compare the ability of the algorithm to predict wind speed. The experimental results show the superiority of the proposed model, which is better than the baseline model in most time step predictions. The effect of each component on the model can be seen through the ablation experiment of Experiment 2. Among them, the extraction of spatial information and temporal information is particularly important and the proposed dynamic graph embedding technique also improves the accuracy of the wind speed prediction.
In future work, the influence of different temporal similarities on the model performance will be considered, and some more complex parallel computing structures will be used to reduce the model computing time. A more complex and interpretable cross-validation will be used to split the dataset to ensure that the model’s ability to predict future points is fully evaluated, which better reflects the generalization ability of the model. The optimal parameter configuration for each model in future work will be investigated and the applicability in different datasets or application scenarios will be explored. The study of the model’s generalization to different seasons will be considered.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}