
Collaborative Framework for Underwater Object Detection via Joint Image Enhancement and Super-Resolution

Abstract
:1. Introduction
1.1. Underwater Object Detection
1.2. Underwater Image Enhancement and Super-Resolution
1.3. Main Novelties and Contributions
- As opposed to the existing schemes, we present a collaborative framework via joint image enhancement and super-resolution. By employing a joint-oriented network training strategy, the proposed framework is more effective at generating a detection-favoring appearance to stimulate efficient and precise object detection of underwater images.
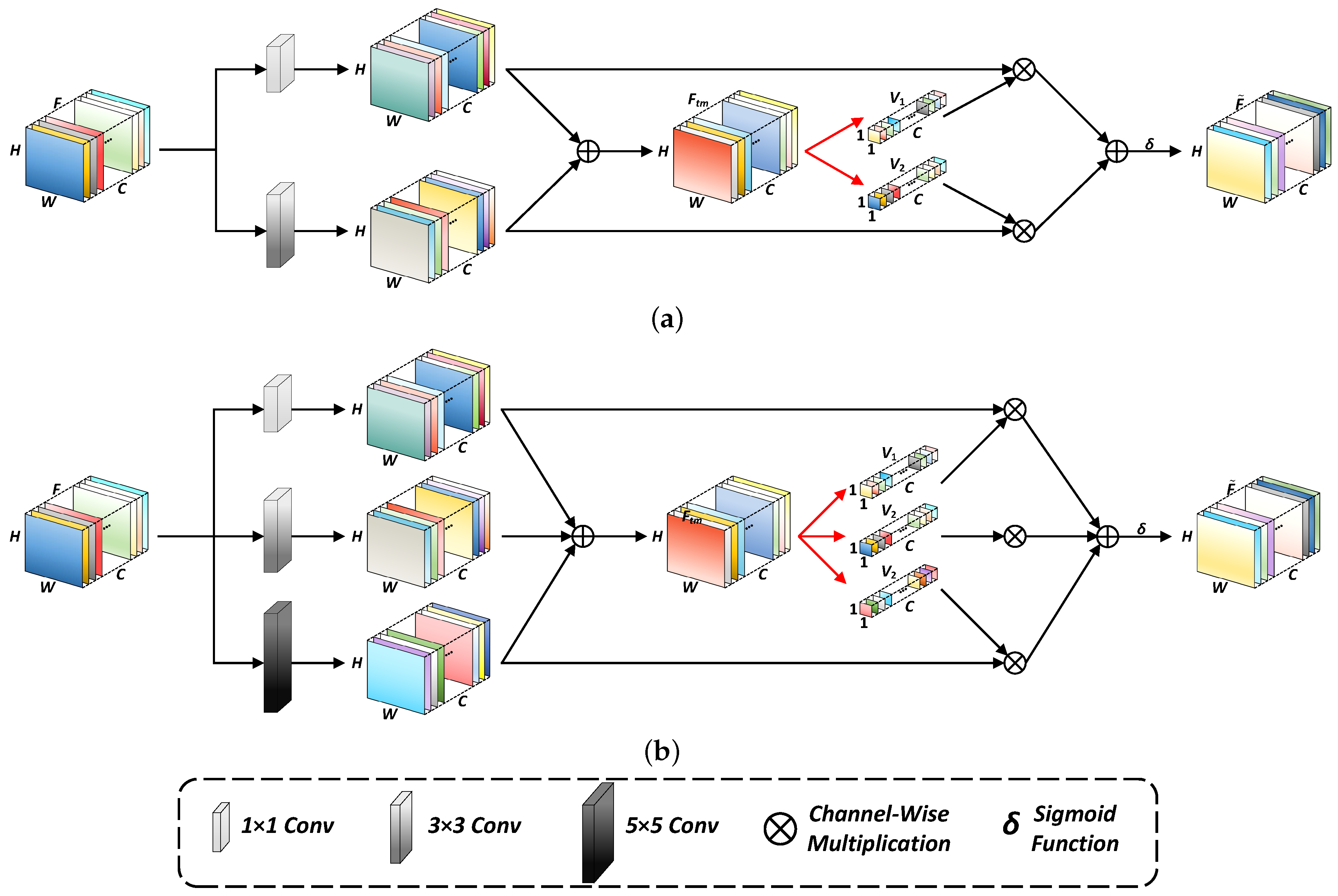
- A plug-and-play self-attention mechanism called multihead blurpooling fusion network (MBFNet) is developed, which enables our proposed framework to capture sufficient contextual information concerning the dependencies between feature maps from a broader and more focused viewpoint, thereby further enhancing UOD performance.
- A heuristic step-by-step training strategy is designed for our proposed collaborative framework. Compared with the conventional end-to-end training strategy, our designed step-by-step training strategy can effectively alleviate the potential gradient vanishing or exploding by dividing the whole training process into refined stages, so that the framework architecture can be better controlled.
2. Proposed Method
2.1. Overview of the Proposed Collaborative Framework
2.2. Composition of the Proposed Collaborative Framework
2.2.1. Multihead Blurpooling Fusion Network
2.2.2. Pre-Processing Module
2.2.3. Underwater Object Detection Module
2.3. Loss Function
2.3.1. UIE Loss
2.3.2. MSE Loss
2.3.3. UOD Loss
2.4. Step-by-Step Training Strategy
| Algorithm 1 Step-by-Step Training Strategy |
|
3. Experiments
3.1. Data Processing
3.2. Experimental Setup
3.3. Comparative Study
3.4. Ablation Study
- (1)
- -w/o UIEC: Removing the UIE component so that only the SR component remains operational in the PPM.
- (2)
- -w/o SRC: Removing the SR component so that only the UIE component remains operational in the PPM.
- (3)
- -w/o PPM: Removing both UIE and SR components so that the PPM is completely disabled.
- (4)
- -rp EWA-PPM: Replacing the original channel concatenation with the element-wise addition in the PPM.
- (5)
- -rp MBFNet-I-PPM: Replacing the MBFNet-II with the MBFNet-I in the PPM.
- (6)
- -rp MBFNet-III-PPM: Replacing the MBFNet-II with the MBFNet-III (MBFNet-III is defined as a four-branch structure, which further adds a similar branch guided by a convolutional layer on basis of the MBFNet-II) in the PPM.
- (7)
- -rp MBFNet-II-UODM: Replacing the MBFNet-II with the MBFNet-I in the UODM.
- (8)
- -w/o MBFNet: Removing all the MBFNets embedded in the PPM and UODM.
- (9)
- -rp ETE: Replacing the step-by-step training strategy with the end-to-end training strategy to train the collaborative framework.
- The effectiveness of our proposed PPM has been demonstrated. When either component in the PPM is removed, the corresponding AP values experience a decrease of approximately 11% to 50%. In addition, the channel concatenation has been shown to be an operation that significantly outperforms the element-wise addition, where the latter demonstrates a substantial decrease in different kinds of AP values to 14.5%, 13.6%, and 5.1%, respectively.
- The effectiveness of our proposed MBFNet has been demonstrated. We attempt to modify different versions of the MBFNet, but the detection performance with such changes is significantly inferior to the existing framework. Furthermore, when all the MBFNets are removed, the UOD performance of the framework experiences a drastic decline, with a decrease in different kinds of AP values to 19.1%, 18.9%, and 16.5%, respectively.
- The effectiveness of the step-by-step training strategy in our framework has been demonstrated. When our proposed collaborative framework is trained by the conventional end-to-end strategy, the corresponding AP values have even dropped by more than 30%, indicating a significant decrease in UOD performance.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Wang, X.; Yang, L.T.; Meng, D.; Dong, M.; Ota, K.; Wang, H. Multi-UAV Cooperative Localization for Marine Targets Based on Weighted Subspace Fitting in SAGIN Environment. IEEE Internet Things J. 2022, 9, 5708–5718. [Google Scholar] [CrossRef]
- Wright, A.E.; Conlin, D.L.; Shope, S.M. PAssessing the Accuracy of Underwater Photogrammetry for Archaeology: A Comparison of Structure from Motion Photogrammetry and Real Time Kinematic Survey at the East Key Construction Wreck. J. Mar. Sci. Eng. 2020, 8, 849. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, Y.; Wang, C.; Wang, Q.; Yang, J. Research on Target Tracking for Robotic Fish Based on Low-Cost Scarce Sensing Information Fusion. IEEE Robot. Autom. Lett. 2022, 7, 6044–6051. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Cheng, G.; Yang, M.H. Weakly Supervised Object Localization and Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5866–5885. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Z.; Wang, S.; Tang, T.; Tao, Y.; Yang, C.; Li, H.; Liu, X.; Fan, X. A New Dataset, Poisson GAN and AquaNet for Underwater Object Grabbing. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2831–2844. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-World Underwater Enhancement: Challenges, Benchmarks, and Solutions Under Natural Light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [CrossRef]
- Yeh, C.; Lin, C.H.; Kang, L.W.; Huang, C.H.; Lin, M.H.; Chang, C.Y.; Wang, C.C. Lightweight deep neural network for joint learning of underwater object detection and color conversion. IEEE Trans. Neural Netw. Learn Syst. 2021, 33, 6129–6143. [Google Scholar] [CrossRef]
- Chen, X.; Li, H.; Wu, Q.; Ngan, K.N.; Xu, L. High-quality R-CNN object detection using multi-path detection calibration network. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 715–727. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 37, pp. 379–387. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zeng, L.; Sun, B.; Zhu, D. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Xu, F.; Wang, H.; Sun, X.; Fu, X. Refined marine object detector with attention-based spatial pyramid pooling networks and bidirectional feature fusion strategy. Neural. Comput. Appl. 2022, 34, 14881–14894. [Google Scholar] [CrossRef]
- Liu, J.; Liu, S.; Xu, S.; Zhou, C. Two-Stage Underwater Object Detection Network Using Swin Transformer. IEEE Access 2022, 10, 117235–117247. [Google Scholar] [CrossRef]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhou, X.; Dequan, W.; Philipp, K. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Kim, B.; Mun, J.; On, K.W.; Shin, M.; Lee, J.; Kim, E.S. MSTR: Multi-Scale Transformer for End-to-End Human-Object Interaction Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19556–19565. [Google Scholar] [CrossRef]
- Li, Y.; Guo, J.; Guo, X.; Zhao, J.; Yang, Y.; Hu, Z.; Jin, W.; Tian, Y. Toward in situ zooplankton detection with a densely connected YOLOV3 model. Appl. Ocean Res. 2021, 114, 102783. [Google Scholar] [CrossRef]
- Hu, J.; Zhao, D.; Zhang, Y.; Zhou, C.; Chen, W. Real-time nondestructive fish behavior detecting in mixed polyculture system using deep-learning and low-cost devices. Expert Syst. Appl. 2021, 178, 115051. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Qin, H.; Chen, Q. Self-Supervised Pre-Training Joint Framework: Assisting Lightweight Detection Network for Underwater Object Detection. J. Mar. Sci. Eng. 2023, 11, 604. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO:Transformer-Based YOLO for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, W.; Du, X.; Yan, Z. Underwater Small Target Detection Based on YOLOX Combined with MobileViT and Double Coordinate Attention. Mar. Sci. Eng. 2023, 11, 1178. [Google Scholar] [CrossRef]
- Jian, M.W.; Liu, X.Y.; Luo, H.J.; Lu, X.; Yu, H.; Dong, J. Underwater image processing and analysis: A review. Signal Process. Image Commun. 2021, 91, 116088. [Google Scholar] [CrossRef]
- Qi, Q.; Zhang, Y.; Tian, F.; Wu, Q.J.; Li, K.; Luan, X.; Song, D. Underwater image co-enhancement with correlation feature matching and joint learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1133–1147. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Z.; Yang, Q.; Sheng, B. Deep colorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 415–423. [Google Scholar]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.H.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimedia 2019, 21, 3106–3121. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 1. [Google Scholar]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Passarella, L.S.; Mahajan, S.; Pal, A.; Norman, M.R. Reconstructing high resolution ESM data through a novel fast super resolution convolutional neural network (FSRCNN). Geophys. Res. Lett. 2022, 49, e2021GL097571. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4467–4480. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part II 14; Springer International Publishing: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, feedback and focus for salient object detection. In Proceedings of the American Association for Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Categories | Definitions | Advantages | Disadvantages |
|---|---|---|---|---|
| UIE | Physical Model-Based [41,42] | Estimating background light and transmission map based on underwater optical imaging formulation | Sensitive to transparency, scattering effects, and absorption coefficients of water | Difficulty in parameter adjustment and optimization with limited generalization |
| Nonphysical Model-Based [43,44] | Directly modifying image pixels | Simple and easy-to-implement | Lacking theoretical basis and guidance from physical models | |
| Learning-Based [45,46] | Learning the mapping functions between paired raw and enhanced images | Strong performance in constructing complex mapping with excellent generalization | Requiring sufficient training data | |
| SR | Interpolation-Based [49] | Interpolating pixel values between known adjacent pixel grids | Simple and cost-effective | Limited improvement in high-frequency image details |
| Reconstruction-Based [50,51] | Inferring inverse degradation process based on prior information | Promising preservation of enhanced image structures and details | Sensitive to noise and artifacts, and requiring additional prior information | |
| Learning-Based [52,53,54] | Learning the mapping functions between paired low- and high-resolution images | Superior performance in capturing and generating image details and textures | Requires sufficient training data |
| Dataset | Species Category | Annotations | Data Type |
|---|---|---|---|
| URPC2020 | Holothurian | 5537 | Jpg images |
| Echinus | 22,343 | ||
| Star fish | 6841 | ||
| Scallop | 6720 | ||
| Brackish | Big fish | 3241 | Video occurrences |
| Crab | 6538 | ||
| Jelly fish | 637 | ||
| Shrimp | 548 | ||
| Small fish | 9556 | ||
| Star fish | 5093 |
| Method | Backbone | AP(%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Scallop | Starfish | Holothurian | Echinus | |||||
| Faster R-CNN [15] | VGG-16 | 31.25 | 53.90 | 48.33 | 60.93 | 24.34 | 48.73 | 20.01 |
| SSD [23] | VGG-16 | 55.19 | 75.75 | 47.34 | 79.73 | 27.76 | 64.50 | 17.78 |
| CenterNet [24] | ResNet-50 | 68.57 | 79.96 | 51.81 | 85.22 | 31.82 | 71.39 | 22.23 |
| RetinaNet [25] | ResNet-50 | 28.76 | 59.20 | 47.75 | 54.80 | 21.45 | 47.63 | 15.68 |
| YOLOv3 [26] | DarkNet-53 | 67.31 | 74.87 | 55.21 | 78.28 | 31.20 | 68.92 | 29.01 |
| YOLOv4 [27] | CSPDarkNet-53 | 61.49 | 69.89 | 59.10 | 79.53 | 31.28 | 67.54 | 28.75 |
| YOLOv5m | CSPDarkNet-53-M | 70.82 | 77.87 | 77.79 | 86.17 | 43.21 | 78.16 | 38.53 |
| YOLOv5l | CSPDarkNet-53-L | 76.17 | 79.17 | 73.60 | 88.30 | 44.28 | 79.13 | 42.13 |
| YOLOx [28] | ResNet-50 | 65.28 | 76.68 | 51.58 | 84.40 | 31.92 | 69.49 | 24.56 |
| YOLOv7 [29] | ELAN-Net-L | 57.78 | 79.49 | 46.95 | 85.58 | 29.81 | 67.45 | 20.13 |
| DETR [30] | ResNet-50 | 69.93 | 84.28 | 62.07 | 87.22 | 42.16 | 75.87 | 40.07 |
| YOLOv4-AFFM [36] | MobileNetv2 | 73.06 | 86.00 | 66.85 | 90.14 | 36.61 | 79.01 | 29.78 |
| YOLOx-DCA [38] | MobileVIT | 79.22 | 86.77 | 72.28 | 88.73 | 41.82 | 81.75 | 37.63 |
| YOLOv5m-PPM | CSPDarkNet-53-M | 66.62 | 80.08 | 51.98 | 84.53 | 32.30 | 70.08 | 24.06 |
| YOLOv5l-PPM | CSPDarkNet-53-L | 71.89 | 83.31 | 59.19 | 86.19 | 36.21 | 75.14 | 29.40 |
| DETR-PPM | ResNet-50 | 78.51 | 86.55 | 71.39 | 87.91 | 37.91 | 81.09 | 27.03 |
| Ours | ResNet-50 | 80.95 | 81.38 | 76.72 | 90.04 | 44.51 | 82.27 | 40.73 |
| Method | Backbone | AP(%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Crab | Fish | Jellyfish | Shrimp | Smallfish | Starfish | |||||
| Faster R-CNN [15] | VGG-16 | 54.81 | 64.75 | 7.25 | 21.48 | 17.50 | 85.74 | 12.34 | 41.92 | 11.01 |
| SSD [23] | VGG-16 | 24.01 | 87.28 | 21.25 | 22.36 | 11.38 | 79.08 | 15.56 | 40.94 | 14.31 |
| CenterNet [24] | ResNet-50 | 75.25 | 89.55 | 27.97 | 28.27 | 11.39 | 91.08 | 22.86 | 53.92 | 18.31 |
| RetinaNet [25] | ResNet-50 | 66.71 | 83.75 | 18.43 | 20.30 | 7.30 | 86.72 | 18.21 | 47.20 | 15.34 |
| YOLOv3 [26] | DarkNet-53 | 70.92 | 83.71 | 21.96 | 24.02 | 7.70 | 86.01 | 26.17 | 49.05 | 23.49 |
| YOLOv4 [27] | CSPDarkNet-53 | 65.53 | 87.91 | 0.01 | 8.71 | 26.15 | 91.73 | 17.71 | 46.67 | 13.22 |
| YOLOv5m | CSPDarkNet-53-M | 87.08 | 77.47 | 45.00 | 62.32 | 42.73 | 94.99 | 39.12 | 68.27 | 38.03 |
| YOLOv5l | CSPDarkNet-53-L | 87.06 | 95.95 | 65.00 | 75.38 | 32.55 | 94.56 | 44.33 | 75.08 | 42.14 |
| YOLOx [28] | ResNet-50 | 77.71 | 82.44 | 28.01 | 33.11 | 36.06 | 94.43 | 30.13 | 58.63 | 29.04 |
| YOLOv7 [29] | ELAN-Net-L | 78.82 | 93.30 | 35.29 | 44.63 | 18.27 | 93.21 | 31.25 | 60.59 | 27.65 |
| DETR [30] | ResNet-50 | 88.04 | 94.50 | 67.39 | 74.00 | 27.17 | 94.04 | 43.18 | 74.19 | 41.02 |
| YOLOv4-AFFM [36] | MobileNetv2 | 86.86 | 95.66 | 64.33 | 75.47 | 32.40 | 94.57 | 44.31 | 74.88 | 41.33 |
| YOLOx-DCA [38] | MobileVIT | 85.61 | 92.11 | 36.79 | 56.65 | 41.50 | 94.30 | 35.21 | 67.83 | 33.97 |
| YOLOv5m-PPM | CSPDarkNet-53-M | 75.56 | 85.02 | 25.49 | 28.16 | 9.02 | 87.90 | 21.03 | 51.86 | 20.65 |
| YOLOv5l-PPM | CSPDarkNet-53-L | 79.99 | 88.20 | 36.19 | 40.69 | 11.58 | 90.64 | 27.06 | 57.13 | 24.79 |
| DETR-PPM | ResNet-50 | 75.11 | 92.59 | 46.00 | 54.97 | 20.68 | 91.31 | 33.19 | 63.44 | 30.87 |
| Ours | ResNet-50 | 89.07 | 96.52 | 75.56 | 81.40 | 37.71 | 95.04 | 47.32 | 79.21 | 45.21 |
| Method | Backbone | #param (M) | FLOPs (G) | Inference Time (ms) | FPS |
|---|---|---|---|---|---|
| Faster R-CNN [15] | VGG-16 | 28.30 | 909.57 | 58.12 | 17.20 |
| SSD [23] | VGG-16 | 3.941 | 2.653 | 6.22 | 160.27 |
| CenterNet [24] | ResNet-50 | 33.67 | 70.21 | 7.08 | 141.21 |
| RetinaNet [25] | ResNet-50 | 36.39 | 69.71 | 20.81 | 48.03 |
| YOLOv3 [26] | DarkNet-53 | 61.54 | 65.62 | 10.69 | 94.49 |
| YOLOv4 [27] | CSPDarkNet-53 | 63.95 | 59.98 | 13.28 | 75.33 |
| YOLOv5m | CSPDarkNet-53-M | 21.01 | 21.39 | 18.95 | 52.75 |
| YOLOv5l | CSPDarkNet-53-L | 46.65 | 48.42 | 11.07 | 90.31 |
| YOLOx [28] | ResNet-50 | 54.15 | 65.77 | 22.75 | 43.95 |
| YOLOv7 [29] | ELAN-Net-L | 37.62 | 44.98 | 20.21 | 49.49 |
| DETR [30] | ResNet-50 | 36.74 | 31.924 | 21.64 | 46.28 |
| YOLOv4-AFFM [36] | MobileNetv2 | 10.73 | 63.22 | 21.47 | 44.18 |
| YOLOx-DCA [38] | MobileVIT | 4.51 | 25.35 | 27.28 | 56.73 |
| Ours | ResNet-50 | 26.63 | 48.94 | 24.97 | 40.05 |
| Method | |||
|---|---|---|---|
| -w/o UIEC | 35.91 (↓ 19.3%) | 72.70 (↓ 11.6%) | 19.20 (↓ 52.8%) |
| -w/o SRC | 37.43 (↓ 15.9%) | 69.83 (↓ 15.1%) | 33.89 (↓ 16.6%) |
| -w/o PPM | 37.91 (↓ 14.8%) | 69.76 (↓ 15.2%) | 35.89 (↓ 11.8%) |
| -rp EWA-PPM | 38.06 (↓ 14.5%) | 71.05 (↓ 13.6%) | 38.67 (↓ 5.1%) |
| -rp MBFNet-I-PPM | 37.46 (↓ 15.8%) | 77.31 (↓ 6.1%) | 35.16 (↓ 13.7%) |
| -rp MBFNet-III-PPM | 40.07 (↓ 9.9%) | 71.31 (↓ 13.3%) | 39.05 (↓ 9.9%) |
| -rp MBFNet-II-UODM | 35.89 (↓ 19.4%) | 66.52 (↓ 19.1%) | 33.12 (↓ 18.6%) |
| -w/o MBFNet | 36.01 (↓ 19.1%) | 66.76 (↓ 18.9%) | 34.00 (↓ 16.5%) |
| -rp ETE | 27.18 (↓ 38.9%) | 56.87 (↓ 30.9%) | 25.13 (↓ 38.3%) |
| Ours | 44.51 | 82.27 | 40.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, X.; Liu, G.-P.; Cai, C.-T. Collaborative Framework for Underwater Object Detection via Joint Image Enhancement and Super-Resolution. J. Mar. Sci. Eng. 2023, 11, 1733. https://doi.org/10.3390/jmse11091733
Ji X, Liu G-P, Cai C-T. Collaborative Framework for Underwater Object Detection via Joint Image Enhancement and Super-Resolution. Journal of Marine Science and Engineering. 2023; 11(9):1733. https://doi.org/10.3390/jmse11091733
Chicago/Turabian StyleJi, Xun, Guo-Peng Liu, and Cheng-Tao Cai. 2023. "Collaborative Framework for Underwater Object Detection via Joint Image Enhancement and Super-Resolution" Journal of Marine Science and Engineering 11, no. 9: 1733. https://doi.org/10.3390/jmse11091733