1. Introduction
Classifying vessels of interest from the received ship-radiated noises is a key task in underwater acoustical signal processing [
1,
2,
3]. Many approaches have been proposed for it, some of them focused on the physical feature extraction from the noise [
2,
4,
5], while in recent years, others tried to deal with it in the data-driven manner with the help of popular deep learning methods [
6,
7,
8,
9]. After optimizing the parameters of the models on the training set, deep-learning-like methods automatically extracted abstract features beneficial to the final task from the raw signal waveform or time-frequency spectrogram. And massive impressive improvements on the testing set can be achieved by such trained models compared to conventional feature extraction approaches [
3,
10].
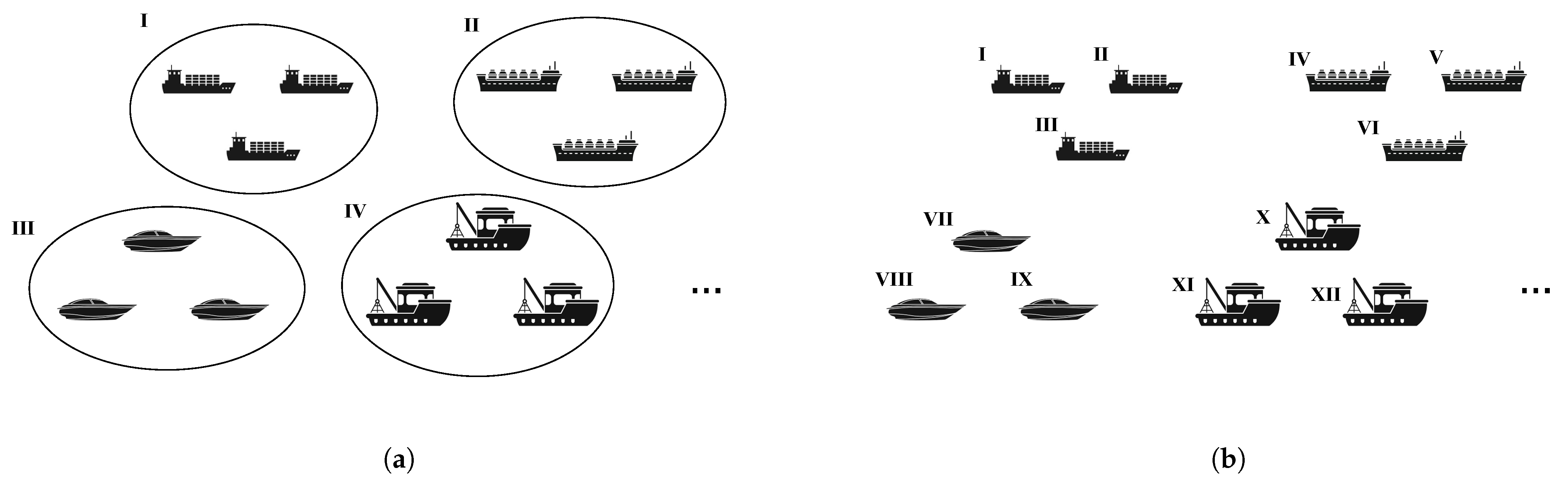
In current research, it was common practice to first assign involved vessels into several coarse categories artificially based on a certain attribute (such as the purpose of the vessel), and then, the effective methods were expected to automatically and accurately classify underlying vessels to one of the above categories (e.g., cargo ships, tankers, etc.) according to the received ship-radiated noise. The decision foundations for an automatic method were the differences in the physical or statistical characteristics of radiated noises, which came from the differences in the engines carried and the hull structure itself. But the division of ship-categories was usually based on practical attributes (such as the purpose as mentioned above). The potential inconsistency between the two led to the large variances between different individual vessels within the same category. For example, the assigned
cargo ships category might include original cargo ships and those converted from passenger ships, whose radiated noises were obviously different. Thus, it could be considered that there was the
large intra-class variances problem in the classification of ship-radiated noises [
11,
12]. A possible solution to this issue is to divide the categories in a fine-grained manner that could decrease the intra-class variances. Based on the received ship-radiated noises, the task of identifying the individual IDs of vessels (named as
ship identification) rather than classifying into the coarse categories (named as
ship classification) was therefore considered in this work. The task of this type might be interesting for some practical applications as well, such as area maritime security, harbor verification for entry and departure of vessels, etc. [
13]. However, to the best of our knowledge, the existing literature has paid less attention to this task.
Ship identification could be understood as a fine-grained setting of the conventional classification, but the fine-grained categories bring not only the conceptual extensions but also some non-trivial changes into the ship identification setting. Obviously, the outputs of methods for the identification problem would be in a higher-dimensional state space because the number of vessel individuals is much greater than that of vessel categories. It increases the difficulty of the task and intensifies the data-hungriness of deep-learning-like algorithms. However, it is difficult to obtain numerous real-world ship-radiated noises from different targets, which has made classification tasks for ship-radiated noises suffer from data scarcity, and such a scenario was called few-shot classification in existing works [
10,
14,
15]. The property of data scarcity is exacerbated by the fine-grained nature of the ship identification problem since the increase of categories greatly dilutes the amount of data in each category. Each vessel may only contain a few minutes or less of real-world data (e.g., 2 min for each vessel), which means that only a few spectrograms may be available after time-frequency analysis. Many existing studies in the classification task of ship-radiated noise tried to cope with the limitation of the real-world data scarcity by redesigning the network architecture. The attention mechanism was employed in [
16] to get the relationship between different low-frequency line spectra of the ship-radiated noise; the recurrent-wavelet auto-encoder architecture was proposed in [
17] to deal with the effect of time-varying marine environments while extracting the periodic frequency components of the ship-radiated noise; and [
18] considered a spectrogram transformer model to obtain the global information of the time-frequency spectrogram automatically. Beyond the architectural design, reducing the need of real-world data for deep neural networks in ship classification tasks by improving learning strategies has also attracted much attention. [
19] argued that the unsupervised pre-training can enable the deep long short-term memory network to effectively address the lack of data; by augmenting the 3D mel-spectrogram of ship-radiated noise in the time and frequency domains [
20], it was believed that the classification performance can be improved with limited real-world data; and [
21] considered that the performance of ship classification tasks would benefit from the ensemble of conventional SoftMax loss and metric-based loss when optimizing the models. However, the available training samples in existing works on classification of ship-radiated noises were still more than hours even with limited real-world data, and the situation of only a few available samples (e.g., <10 spectrograms for each vessel) that might be faced in ship identification has not been fully discussed.
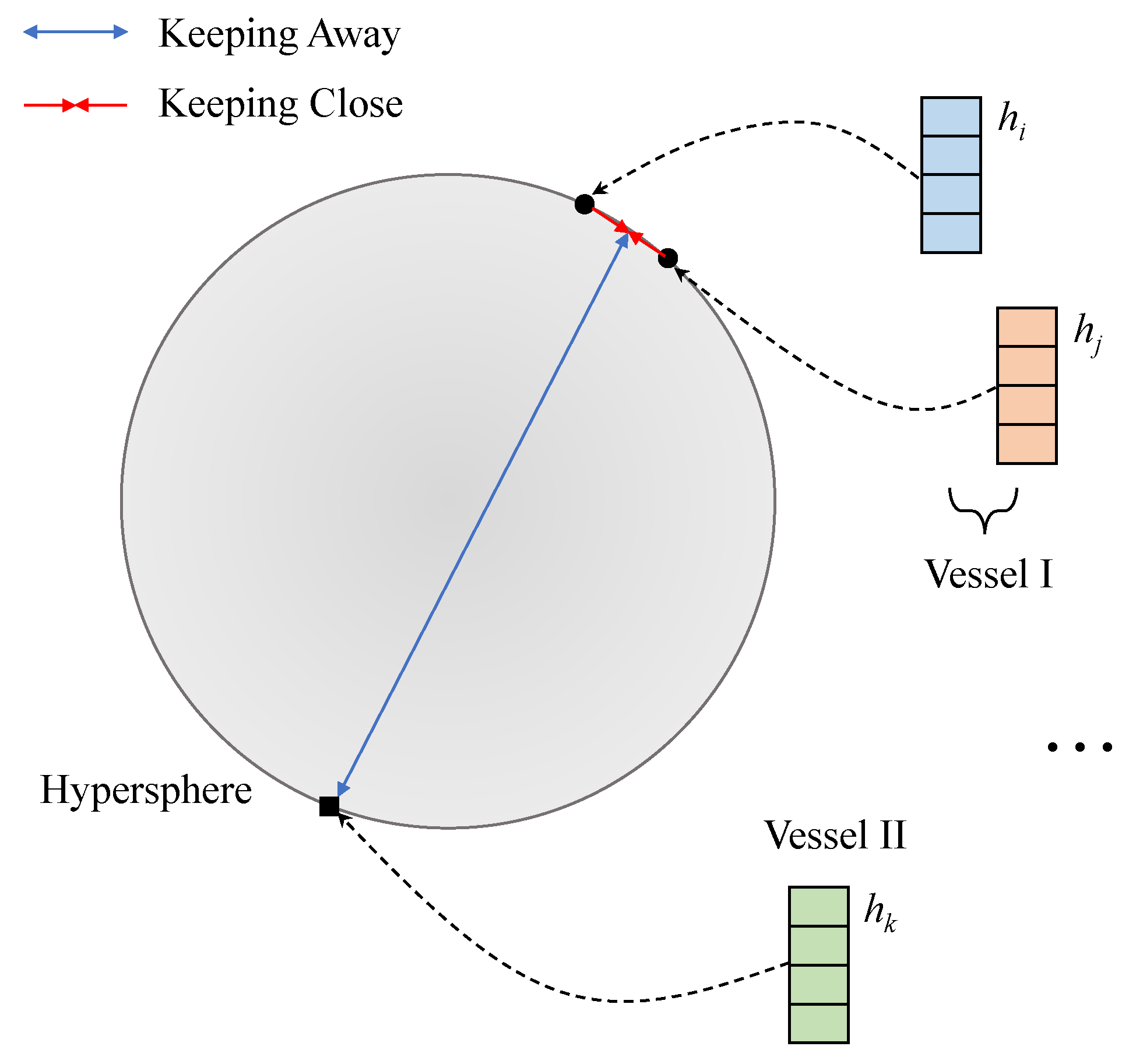
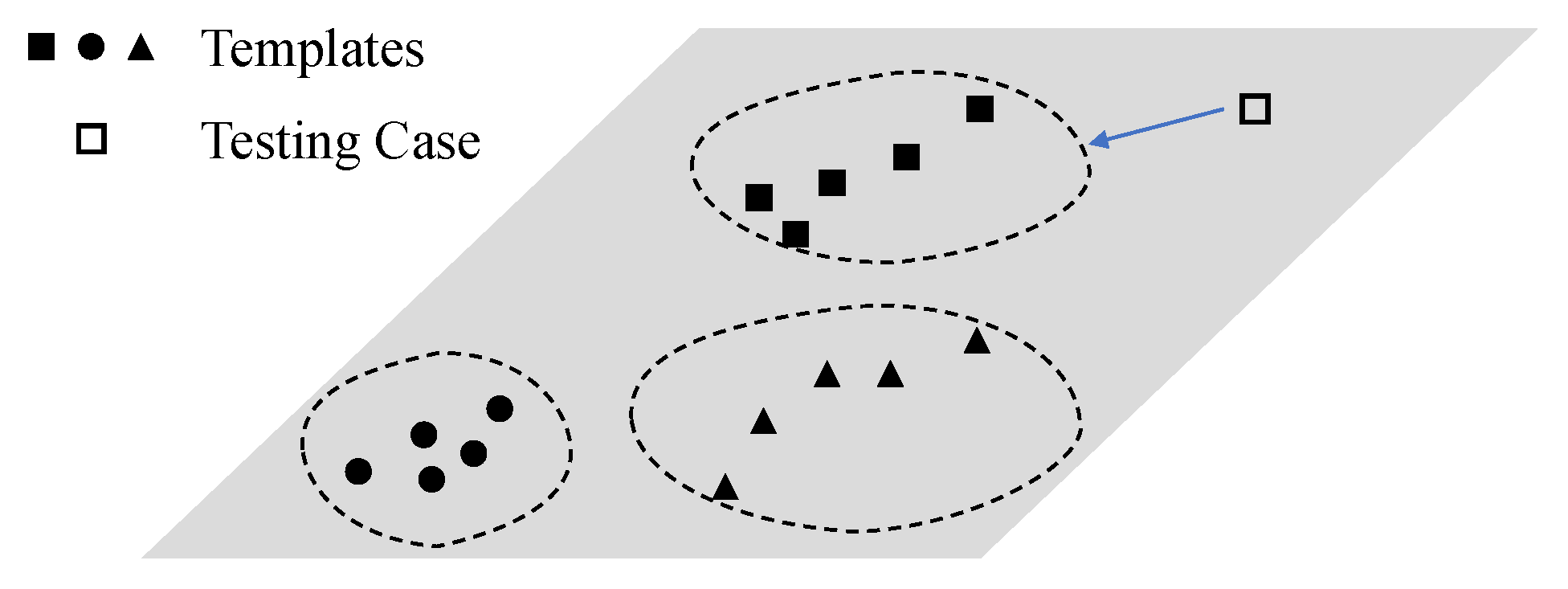
Moreover, since ship identification methods need to distinguish each individual of vessels, a certain class (individual) of samples in the training set for methods could be considered as templates for the individual in other soundscapes. This situation is also different from conventional ship classification. The potential benefit of available individual registration templates is less considered in the ship classification problem.
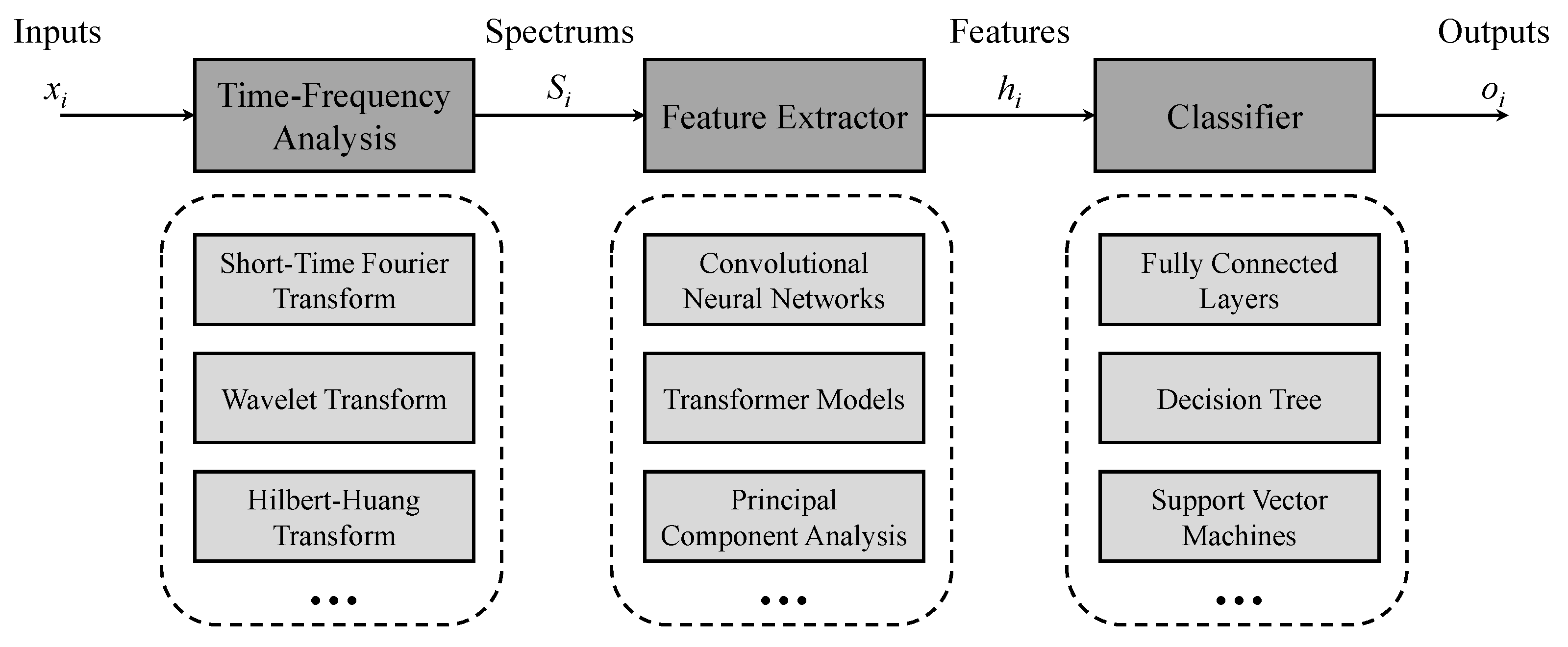
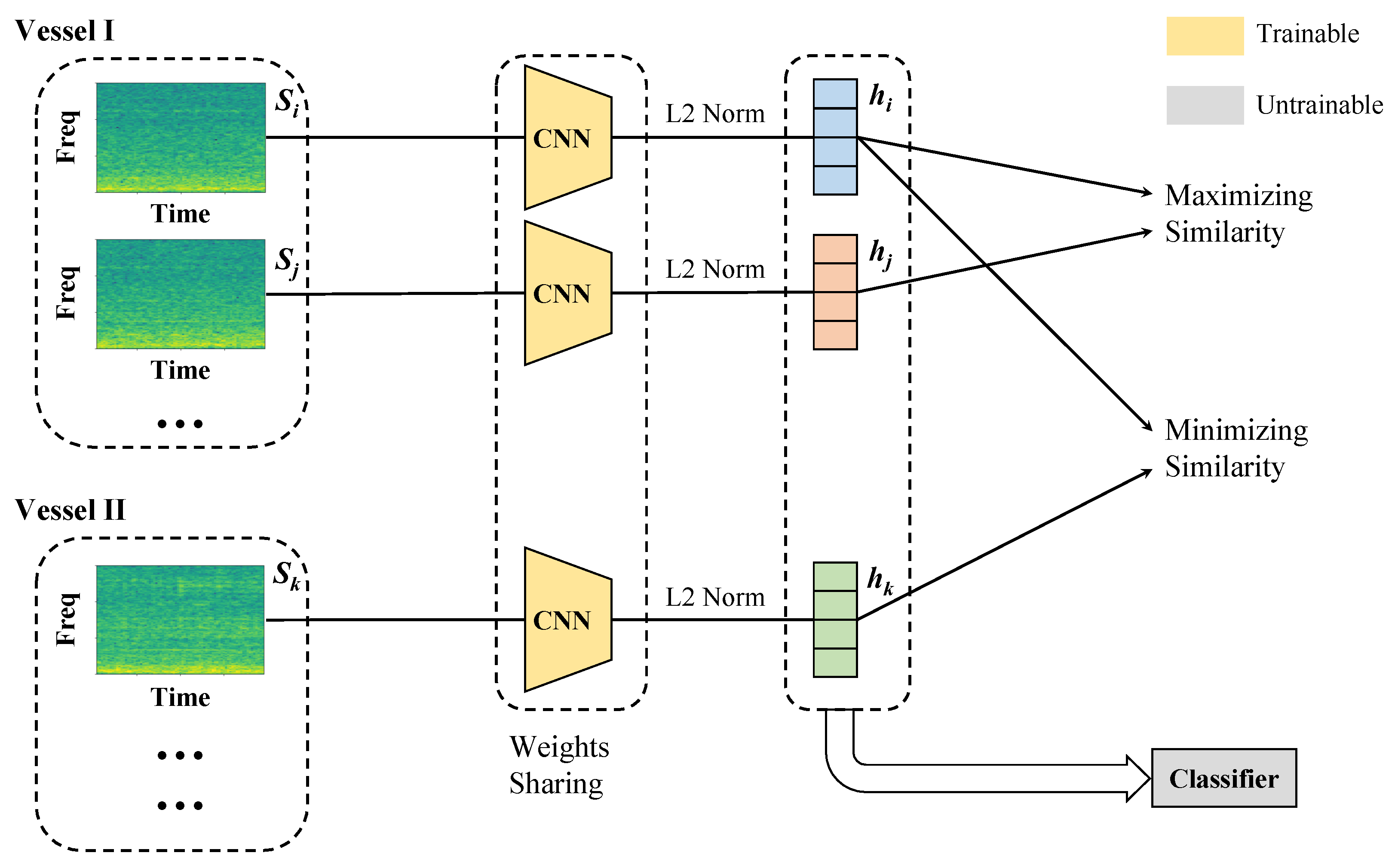
We proposed a contrastive-learning-based method to adapt the few-shot ship identification problem. It did not contain a parameterized classifier, and only employed the convolutional neural networks (CNN) as the feature extractor to map the time-frequency spectrogram into the abstract feature space. In the training phase, the proposed method constructed sample-pairs consisting of real-world samples, where the sample-pairs from the same individual’s samples were called as positive pairs, while those from different individuals’ samples were as negative pairs. And the optimization goal was to make the features of positive pairs close, while making those of negative pairs far away, instead of bringing the classifier output of a sample closer to its label. In the testing phase, it treated the training samples as registration templates for each individual, and achieved parameter-free classification by calculating the distance between the testing samples and all templates and selecting the closest one as the discrimination result. The main contributions of this paper are as follows,
The contrastive-learning-based method was proposed for real-world few-shot ship identification from the received noises. It optimized the parameters of the feature extractor by making positive pairs close and negative pairs far away.
The available samples were utilized as templates for comparison in addition to serving as the training set. The parameter-free classifier was achieved by choosing the closest distance between the testing samples and all templates in the feature space.
The performance of the proposed method was verified on the sea-trial datasets, and the role of the number of available samples was also discussed. The results confirmed the advantages of our method in solving the few-shot ship identification problem.
4. Experiments, Results and Discussion
In this section, we verified and discussed the performance of the proposed methods for the ship identification task via the sea-trial datasets. Firstly, the sea-trial datasets and settings of identification tasks were presented, and the implementation of the methods was detailed; the advantages of the proposed methods were then revealed by comparing with the baselines under different identification settings; and finally, the target-wise performance, the convergence of the methods and the role on performance of the number of samples available in training were analyzed by empirical studies.
4.1. Sea-Trial Experiments and Datasets
There were two publicly accessible datasets,
ShipsEar [
41] and
DeepShip [
42], in the ship classification tasks.
DeepShip dataset did not disclose the auxiliary information about the vessels in addition to the data itself and labels on categories. Hence, the dataset cannot be used for our ship identification tasks because it was not possible to know the details about ship IDs of the same category of data. For the
ShipsEar dataset, we constructed a ship identification dataset,
SID1, based on the provided information on vessels and receiving time of the hydrophone. The selected data IDs [
41] were shown in
Table 1, and they were all from the passenger boats. Thus, methods developed on the
SID1 needed to identify five different passenger boats. Each selected vessel included at least two utterances with the significant separation in the receiving time (more than four hours apart), one of which was employed for training and the others for testing. Its purpose was to expose the training and testing samples in significantly different soundscapes, in order that the obtained results during the testing were exactly related to the generalization of the methods instead of the overfitting.
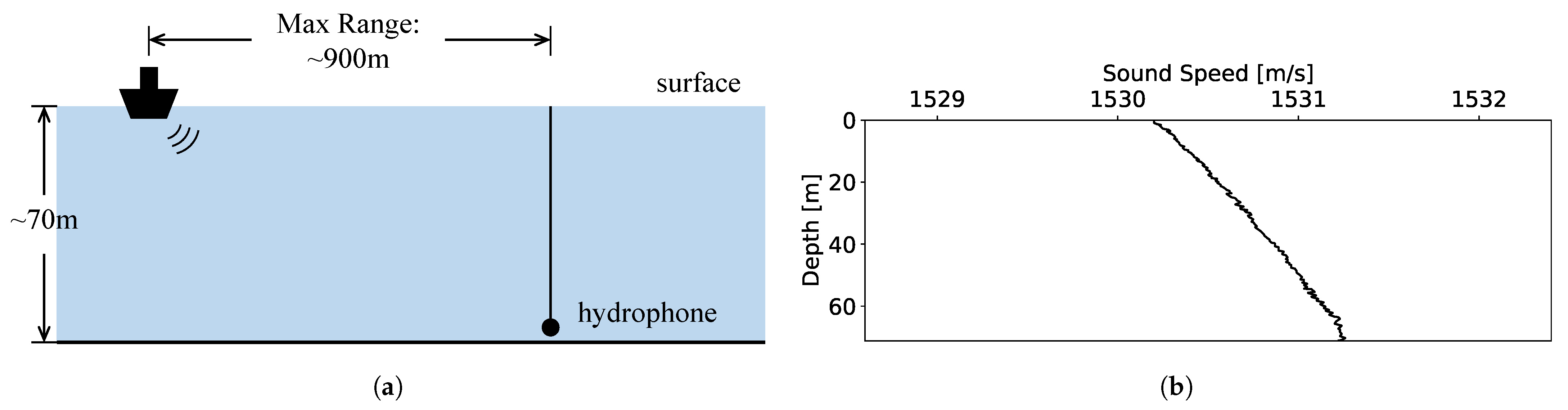
Beyond the open-source datasets, sea trials were carried out in the northern South China Sea during 2022 (
Figure 7), in which the hydrophone received the radiated noises from vessels passing in its vicinity (with the sampling rate of 5000 Hz), and the average ocean depth of the experimental area was about 70 m. The corresponding ship IDs were confirmed by the automatic identification system (AIS). For avoiding the potential interference, an utterance of received noise was considered as the
effective utterance when the source vessel was within
nautical miles near the hydrophone and there were no other oceanic vehicles within 2 nautical miles during this period. In addition, as in the construction of
SID1, the selected vessels were required to have more than two temporal-separated effective utterances for splitting the training and testing sets. With the filtering of the above two conditions, the real-world data on radiated noises was obtained, and it was called as
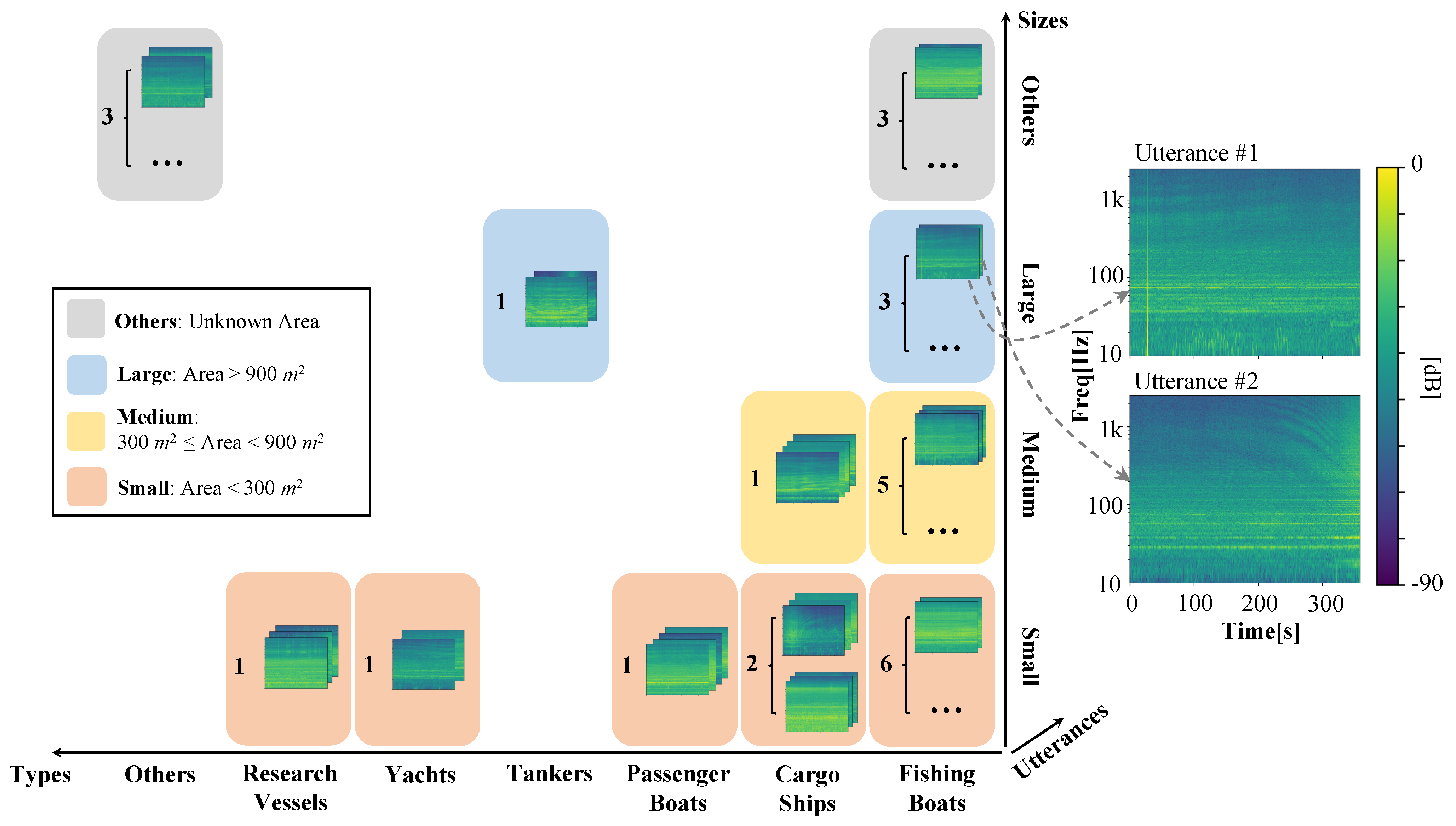
VOS (Vessel Observation by Single-hydrophone) data. There were 27 different individual vessels with a total of 67 utterances of the uniform length of 6 min. These vessels fell into 6 known categories based on the purpose; and they were assigned into 3 types according to their sizes, where vessels with the area (a product of length and width) greater than 900 m
were defined as
large vessels, those smaller than 300 m
were defined as
small vessels and the rest were
medium vessels. Examples of the time-frequency spectrums and other details on
VOS data could be found in
Figure 8.
Two datasets,
SID2 and
SID3, were established for the ship identification tasks based on the above
VOS data (
Table 2). Three individual fishing boats with different sizes (large, medium and small) were selected to form
SID2, and all available vessels were selected to form
SID3. This meant that the methods developed on
SID2 were asked to identify 3 different fishing boats, whereas those developed on
SID3 had to identify 27 different targets. Obviously,
SID3 was more difficult than other counterparts. Under the
N-way
K-shot setting, the number of vessels here was the value of
N, and for emphasizing the property of few-shot scenarios,
K was set to 5 in this work if not specified.
4.2. Implementation of Methods
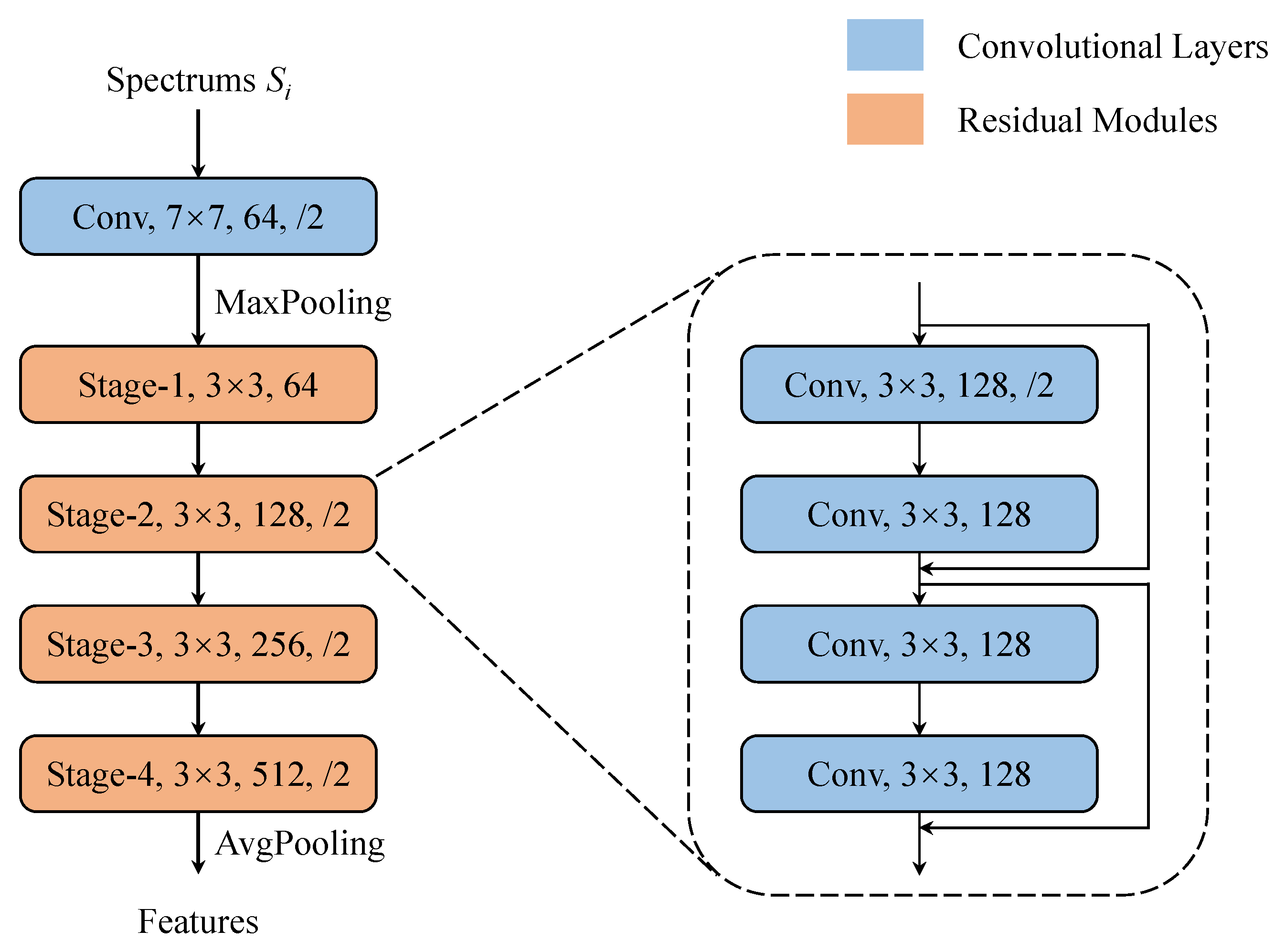
In order to verify the effectiveness of the proposed method in the few-shot ship identification tasks, two baseline methods were implemented for comparison. The first baseline utilized an FC layer to map features into class vectors and trained the CNN by minimizing the cross-entropy loss between the class vectors and their labels, which was a conventional strategy in ship classification tasks, and we called it as SCNet. We tried to argue the superiority of the framework of contrastive learning and the mechanism of parameter-free classification in the proposed method by empirical comparisons with this baseline on the concern tasks.
The second baseline was from a classical Siamese network architecture [
40,
43], which also adopted the contrastive learning strategy, but when solving the multi-objective optimization in Equations (
2) and (
3) via the single-objective loss, the
contrastive loss as following was employed instead of the
InfoNCE loss in Equation (
6):
where
y was 1 for positive pairs and 0 for negative pairs, and
D was a hyperparameter representing the expected distance between samples for negative pairs. The baseline was marked as
SiamNet, and the advantages of our training strategy in the few-shot scenarios were shown by comparing with it.
The baselines and our method were implemented with the PyTorch framework [
44] and accelerated by an NVIDIA GeForce RTX 3090 Ti graphics card. During the optimization, the Adam optimizer [
33] was employed to update the weights of CNN. For the fair comparison, the baselines adopted the same architecture of CNN as our method in
Section 3.2, and the initialization of CNN weights and hyperparameters in optimization followed the default settings of PyTorch version 1.12.1. Moreover, for the baselines, utterances were preprocessed in the same way in
Section 3.1 to obtain spectrums
for further identification. Other settings about the training in this work were presented in
Table 3.
When evaluating the performance of the methods, we picked one utterance for each vessel to be identified for the training and tested the methods by using the utterances in other soundscapes that were different from the training one due to the receiving time of the hydrophone or working conditions of vessels. To quantify the identification performance, we employed the precision
p, recall
r, F1-score
and accuracy
, which were commonly used in the ship classification tasks. They were defined as in Equations (
11) and (
12):
where true positive (TP) represented the utterances that were predicted to be the ship IDs of 1, and their actual IDs were also 1; false positive (FP) represented those that were predicted to be the ship IDs of 1, but their actual IDs were 0; false negative (FN) represented those that were predicted to be the ship IDs of 0, but their actual IDs were 1; while true negative (TN) represented those that were predicted to be the ship IDs of 0, and their actual IDs were also 0. For the multi-class identification, we calculated the macro average of these metrics by treating all classes equally. Moreover, we reported the confusion matrices on different identification tasks for the proposed method, which presented the rich information about the behavior of our method.
4.3. Performance for Different Settings of Ship Identification
The proposed method and the baselines were compared under the
N-way
K-shot framework with
. For the dataset
SID1, 5 different passenger boats were required to be identified, so
N was 5. The performance of these methods was shown in
Table 4. It could be seen that the performance of the conventional SCNet, which was usually used in the ship classification tasks, was limited because the available training samples were not enough. It was only slightly more accurate than the random guessing (with the accuracy of
versus
). The performance of
SiamNet adopting the contrastive learning strategy has been greatly improved (with the accuracy of
), but it was still not as good as our proposed method (with the accuracy of
). The confusion matrix of the proposed method was also visualized in
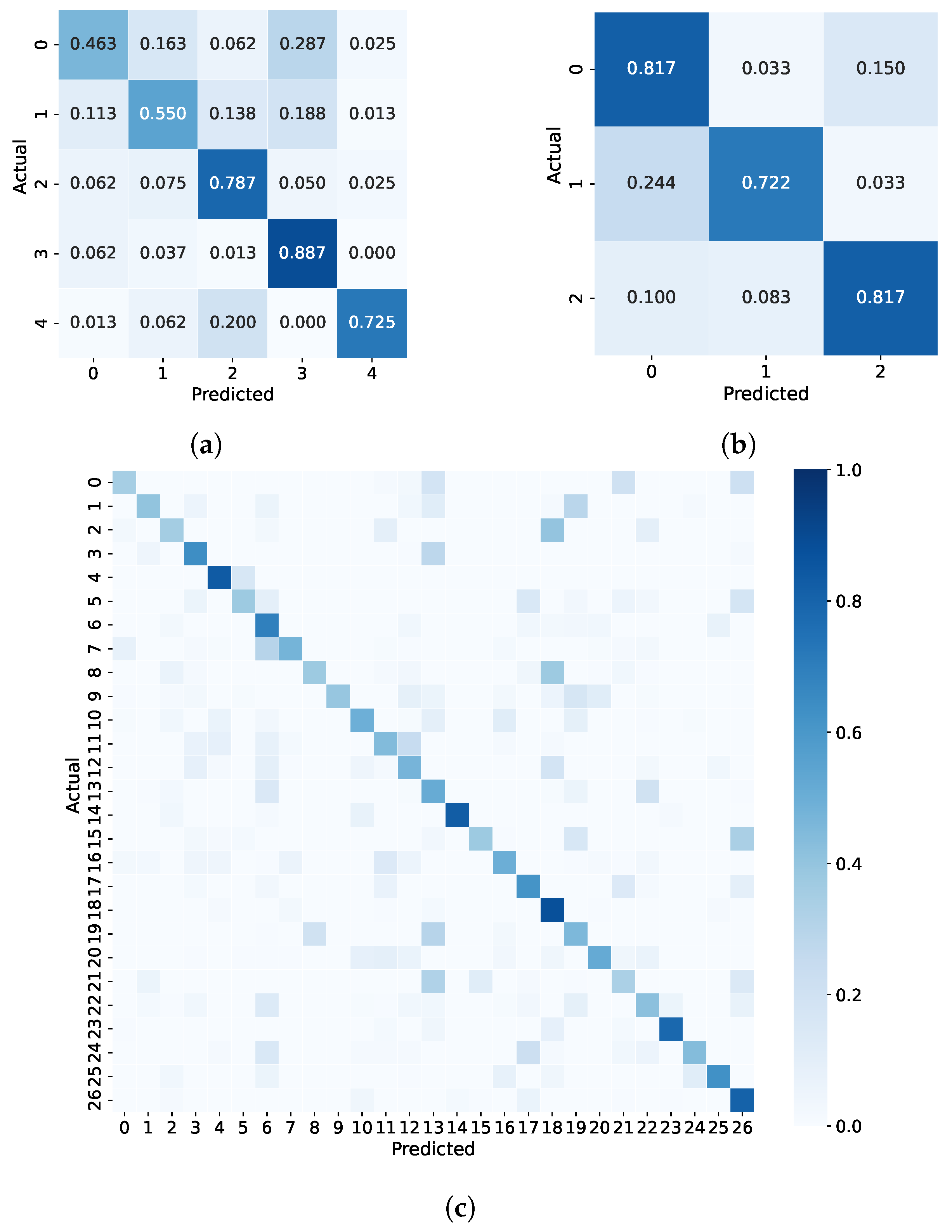
Figure 9a. The bright spots (with the high proportion) in the confusion matrix were almost along the diagonal of matrix, which showed that our method did work on the identification dataset, even though only 5 samples (10 s in total) were available.
Furthermore, in order to make the arguments more solid, we implemented the proposed method and the baselines on other identification datasets,
SID2 and
SID3, constructed from a completely independent sea trial data (VOS data) to discuss and compare their performance. The average results of precision, recall, F1-score and accuracy were listed in
Table 5 and
Table 6, and the results on confusion matrices were shown in
Figure 9b,c. The performance metrics of all methods were improved when the task difficulty dropped from 5-vessel identification to 3-vessel identification. However,
SCNet still didn’t work due to limited training samples, its accuracy was almost the same as random guessing (
versus
). The proposed method had the best performance on the
SID2 regardless of which evaluation metric was focused. When the number of vessels to be identified increased from 5 to 27, the performance of all methods obviously decreased. This was reasonable since the ID pool of vessels was significantly enlarged and the methods needed to face more choices when classifying. On the
SID3, accuracies of both
SCNet and
SiamNet dropped below
, while the proposed method achieved the accuracy over
even on this challenging dataset. The diagonal distribution of bright spots in the confusion matrix also confirmed that the proposed method was still trustworthy under the 27-vessel identification task.
4.4. Target-Wise Performance of the Proposed Method
Next, the performance on each individual vessel of the proposed method in the ship identification task was discussed via the metrics of precision, recall and F1-score. And the high-dimensional features of each individual learned by our method were reduced in dimensionality by the
t-SNE method [
45] and then visualized. The discussions were based on numerical experiments carried out on the dataset,
SID1, composed of the open-source real-world data.
The vessel-wise results of the proposed method on the
SID1 were shown in
Table 7. It could be found that the identification performance of our method was varying for each vessel. The method identified vessels iii, iv and v very well, and the F1-scores for them were all above
. Comparatively, there were the poor performance for the proposed method when vessels i and ii were focused Even if the average metrics on the identification was close to
, the F1-scores for these two vessels were still below
.
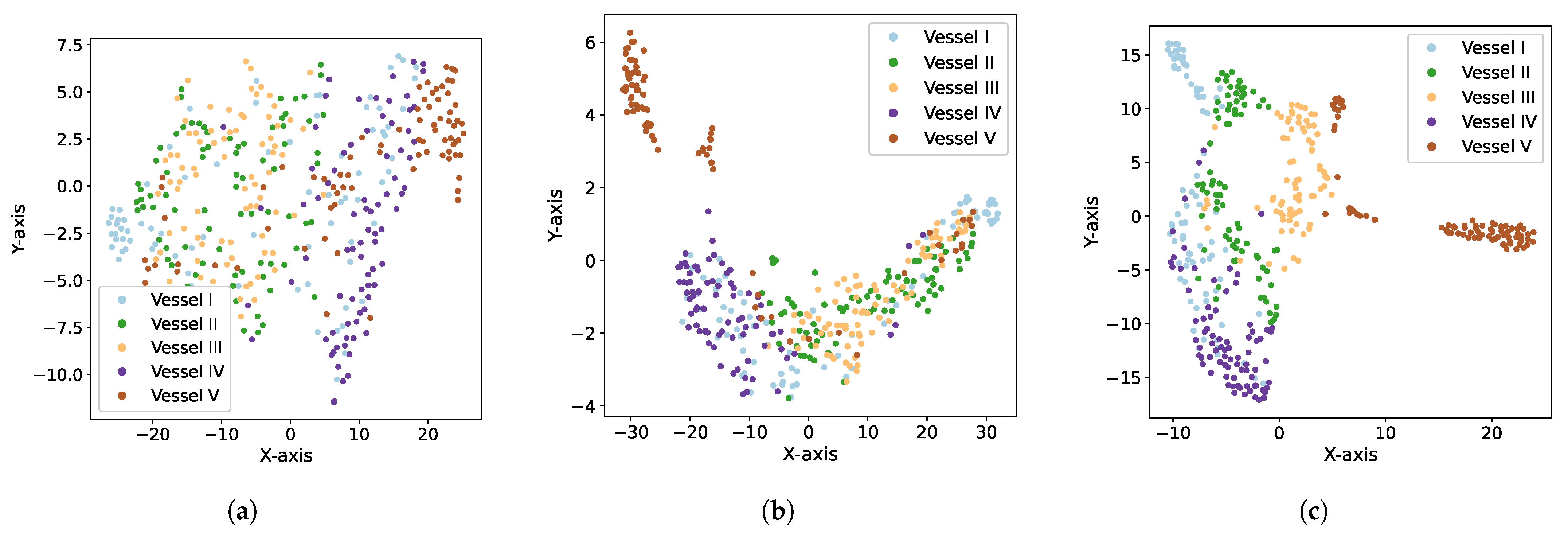
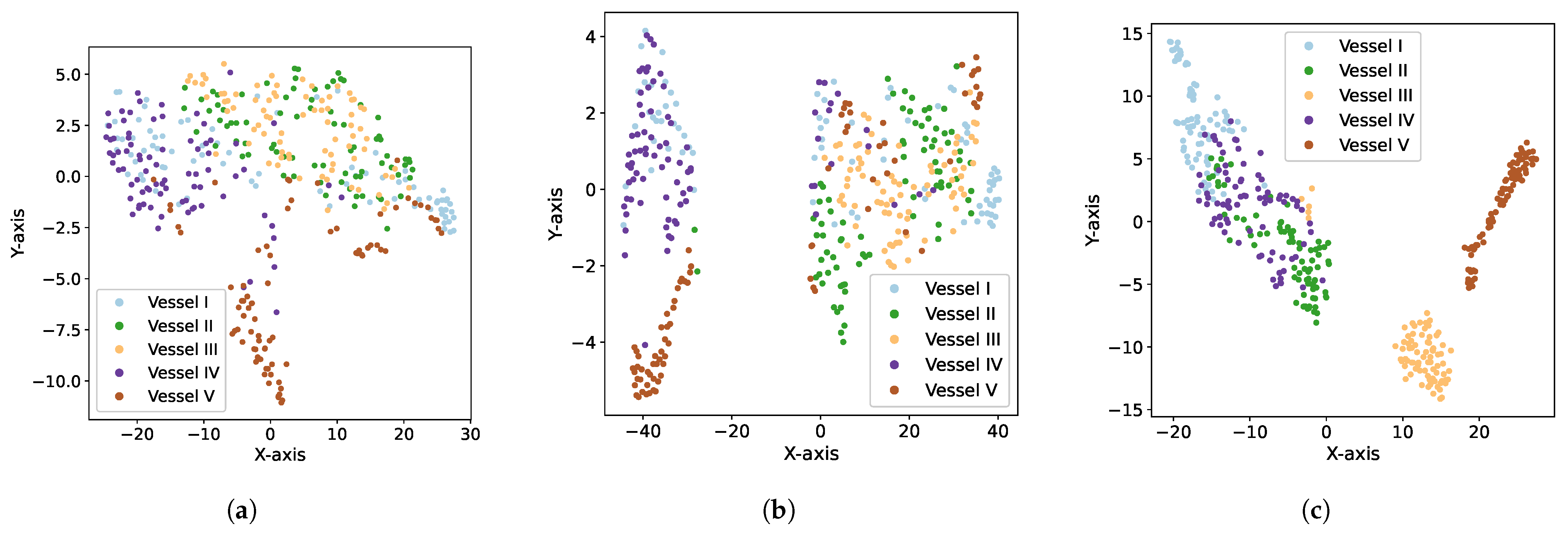
The visualization of the high-dimensional features in
Figure 10 might be helpful to analyze the reasons behind the performance inconsistency on different vessels. With our training strategies, the feature extractor extracted the more discriminative features of vessels iii, iv and v, while for vessels i and ii, the obtained features were aliased with those of other vessel individuals (
Figure 10a). Discrimination or not at the feature level led to differences in the behavior when identifying each vessel. Moreover, comparing with the features obtained from the conventional
SCNet (
Figure 10b) and the Siamese network
SiamNet (
Figure 10c), the proposed method was superiority in the training strategy of the feature extractor
with the same architecture, which prompted the model to put the features of the same vessel in different soundscapes together and keep those of the different vessels apart.
SiamNet was also with the same intention, but it did not do this well from the visualized results, while the strategy of training the feature extractor with FC layers and the cross-entropy loss obviously failed in the few-shot scenario.
4.5. Convergence under Varying Hyperparameter
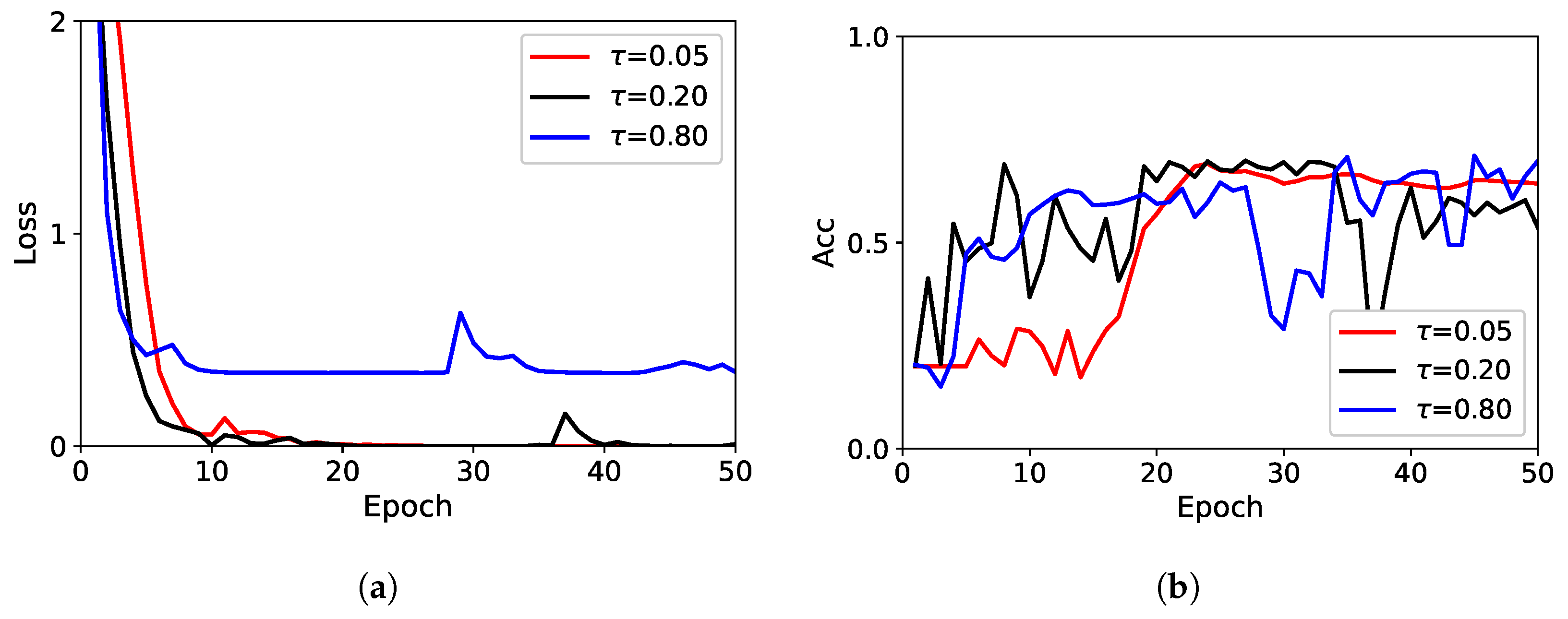
As analyzed theoretically in
Section 3.3, different values of the hyperparameter
in Equation (
6) affected the convergence of the proposed method during the training. The difference in convergence led to varying in the generalization performance of the model on the testing set. We empirically studied the difference in the convergence of the method caused by
on the
SID1 dataset.
was set to
,
, and
, which represented undersized
, oversized
, and our default value, respectively. The loss of the method on the training set and the accuracy on the testing set were presented in
Figure 11 with the increasing number of epochs in the training.
The convergence of the method was accelerated when increased, but the optimization for parameters in CNN also became unstable; meanwhile, too large also made the method converge on a high platform. For the generalization on the testing set, the different values of had little effect on the final performance of accuracy, and the best results that were achieved by the three showed almost no difference. However, a too small increased the number of epochs required for the method to achieve the good generalization, while a too large made it difficult to select a suitable number of epochs due to the unstable training. They could have an impact on how the proposed method behaved in practice.
4.6. Performance versus the Number of Training Samples
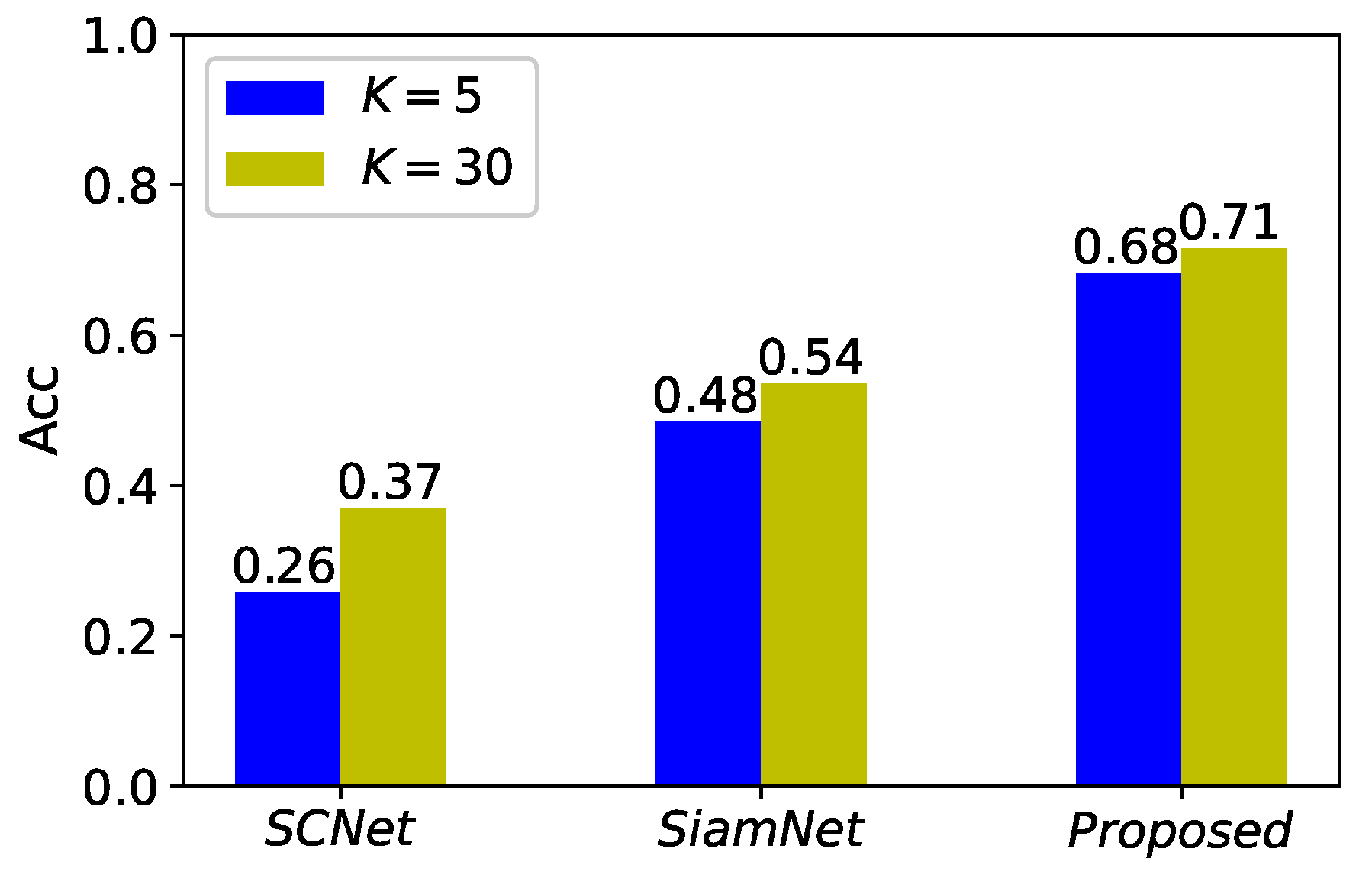
Finally, we empirically discussed the changes brought by different values of
K under the
N-way
K-shot setting to the ship identification task on the
SID1. The performance on accuracy of the proposed method and baselines with
and
was shown in
Figure 12. It could be found that more samples available for the training (caused by the increasing of
K) improved the performance of all three methods, with the improvement on performance of
SCNet being more significant than that of the contrastive learning methods.
The underlying reason might be that the classifier in
SCNet consisting of FC layers was more sensitive to the increase in the number of data samples, while there were not the parameterized classifiers in the
SiamNet and the proposed method, and therefore the performance gains from the increase in the available data were not as great for the latter two. The diversity brought by more real-world data allowed the methods to face more construction cases of sample-pairs during the training, and resulted in the improvement of feature extraction, which also promoted the final identification performance. Visualization of features learned by different methods when
was also provided in
Figure 13. Compared to
Figure 10, the features learned by all methods were more discriminative than their own counterparts previously when the data available for the training was increased. Therefore, it could be argued that the performance gain brought to
SCNet by the increase in training samples came from the coupling of both more distinguishable features and the more powerful classifier, while that brought to
SiamNet and the proposed method was mainly from the first one. As a result, the performance gains of the latter two were smaller than that of the former.
4.7. Limitations and Future Works
In practice, port access verification or maritime security usually need to accurately identify whether the ship ID is a registered ID to provide a basis for the further response, where the limited data issue for each registered vessel should be considered as a major challenge. These tasks fit well with the few-shot ship identification discussed in this work, and the proposed method deals with it via adjusting the optimization objective of the training pipeline. There are some limitations for the practical application of the proposed method:
Busy seas make multi-vessel interference almost inevitable, and the problem is simplified in this work by manually picking the interference-free moments of the vessels.
The dataset constructed in this work employs the noises from near-field vessels, and how the acoustical distortion of noises from far-field vessels affect the identification performance needs further study.
The evaluation in this work ensures generalization of the proposed method to both time- and space-variation in the same ocean because the constructed datasets in
Section 4.1 are with temporal-separated utterances. However, it needs further investigation whether the method is still generalizable and what features can be re-used under the large-scale environmental changes caused by different target ocean.
5. Conclusions
In this work, we focused on the few-shot ship identification scenario, which aimed to utilize only a very few data samples (usually, smaller than 10 for each class) to develop a system that can automatically and accurately identify each vessel individuals that might be in different soundscapes. We made it well-defined with the N-way K-shot setting and proposed a contrastive-learning-based method for it. When training the model, it transformed the loss minimization between the prediction of samples with their labels into the maximization of similarity between positive pairs and minimization of that between negative pairs by constructing sample-pairs; and translated this multi-objective optimization into a solvable single-objective optimization via the InfoNCE loss. In the practical inference, a distance-based classifier was employed instead of the FC layers with numerous parameters; it avoided the training of the classifier that was difficult in few-shot applications by comparing the distance between the testing samples and the available registration templates on the feature space and assigning a testing sample as the ship ID of the registration templates closest to it.
The advantages of our method were validated on different sea-trial data. On the real-world tasks of 5-ship identification, 3-ship identification and 27-ship identification, the proposed method achieved the best performance with accuracies of , and ; whereas the SCNet with conventional classification strategies only achieved accuracies of , and , and the SiamNet with classical contrastive strategies achieved accuracies of , and . The method was discussed in more detail on the 5-ship identification task. It was considered that the performance of our method on the identification of each individual vessel was inconsistent by the feature visualization and the vessel-wise analysis of identification results of the method. Furthermore, we also empirically studied the effect on convergence of the hyperparameter in our method and the potential gains for the methods from the increase of data samples available for the training. In conclusion, it could be argued that the proposed contrastive-learning-based ship identification method worked well in the real-world few-shot applications.



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}