
Development of a Cascade Intelligent System for Path Planning of the Group of Marine Robotic Complexes
 , , , and
, , , and
Abstract
:1. Introduction
2. Problem Statement
- Development of algorithms for the local path planner of each agent in the group and the global approach of the group motion;
- Implementation of the logical approach for the intragroup policy operation for the interaction of agents in a group, which is based on the communication range and the vision system parameters, which in turn are functions of the current and predicted parameters that describe environmental conditions, including data on the location of agents and their current state;
- Development of an architecture for the intelligent interaction of agents based on the existing intragroup policy.
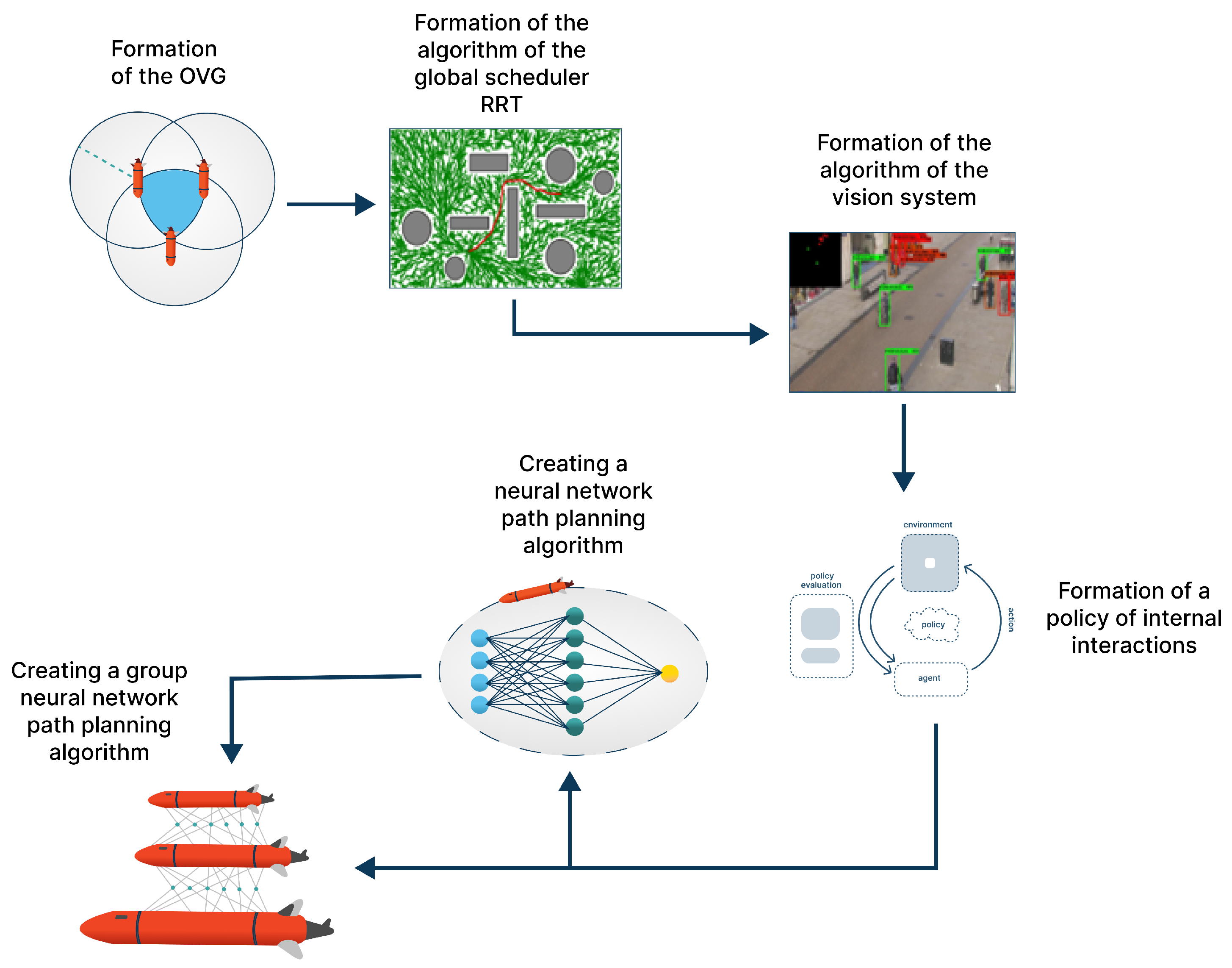
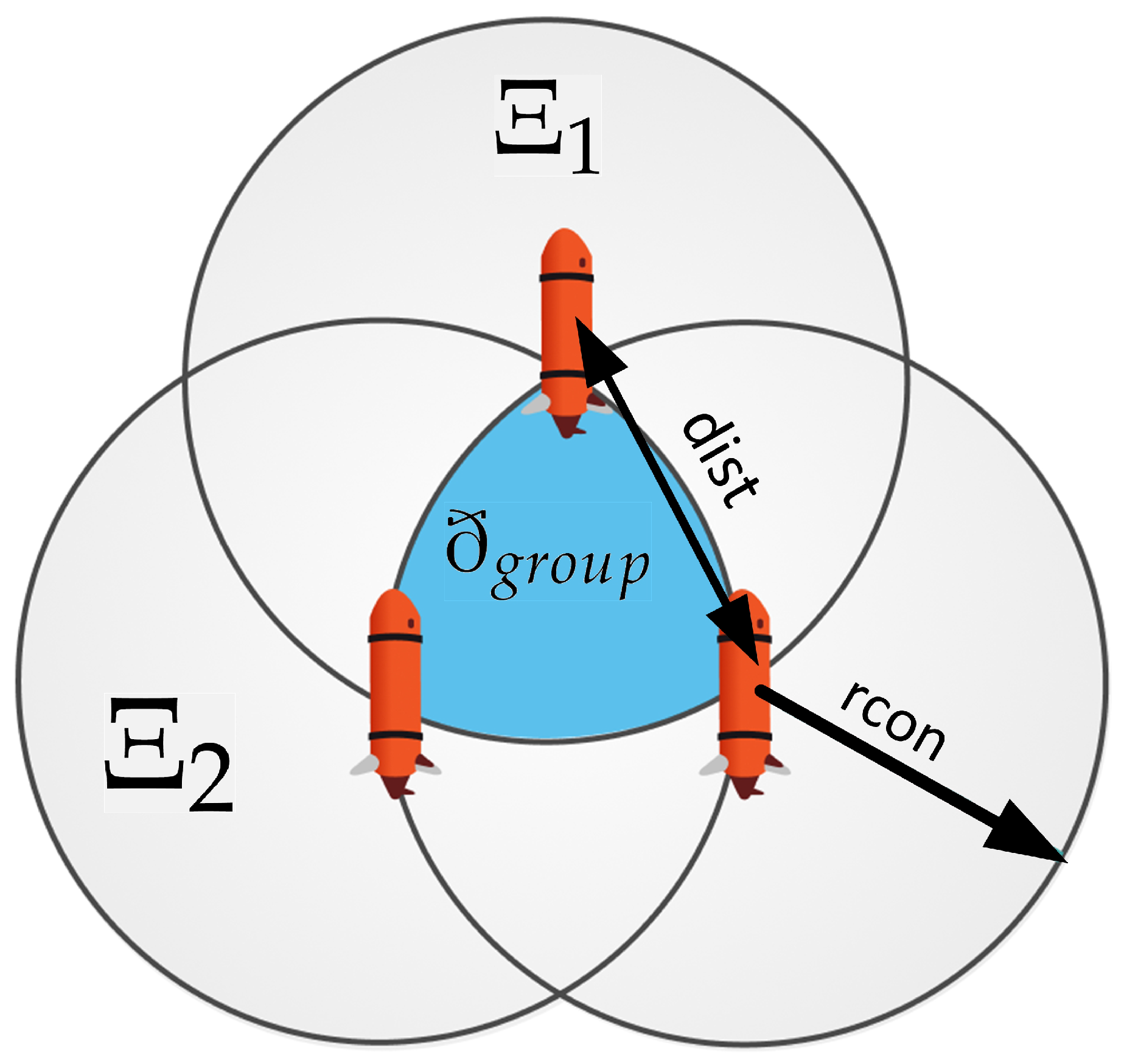
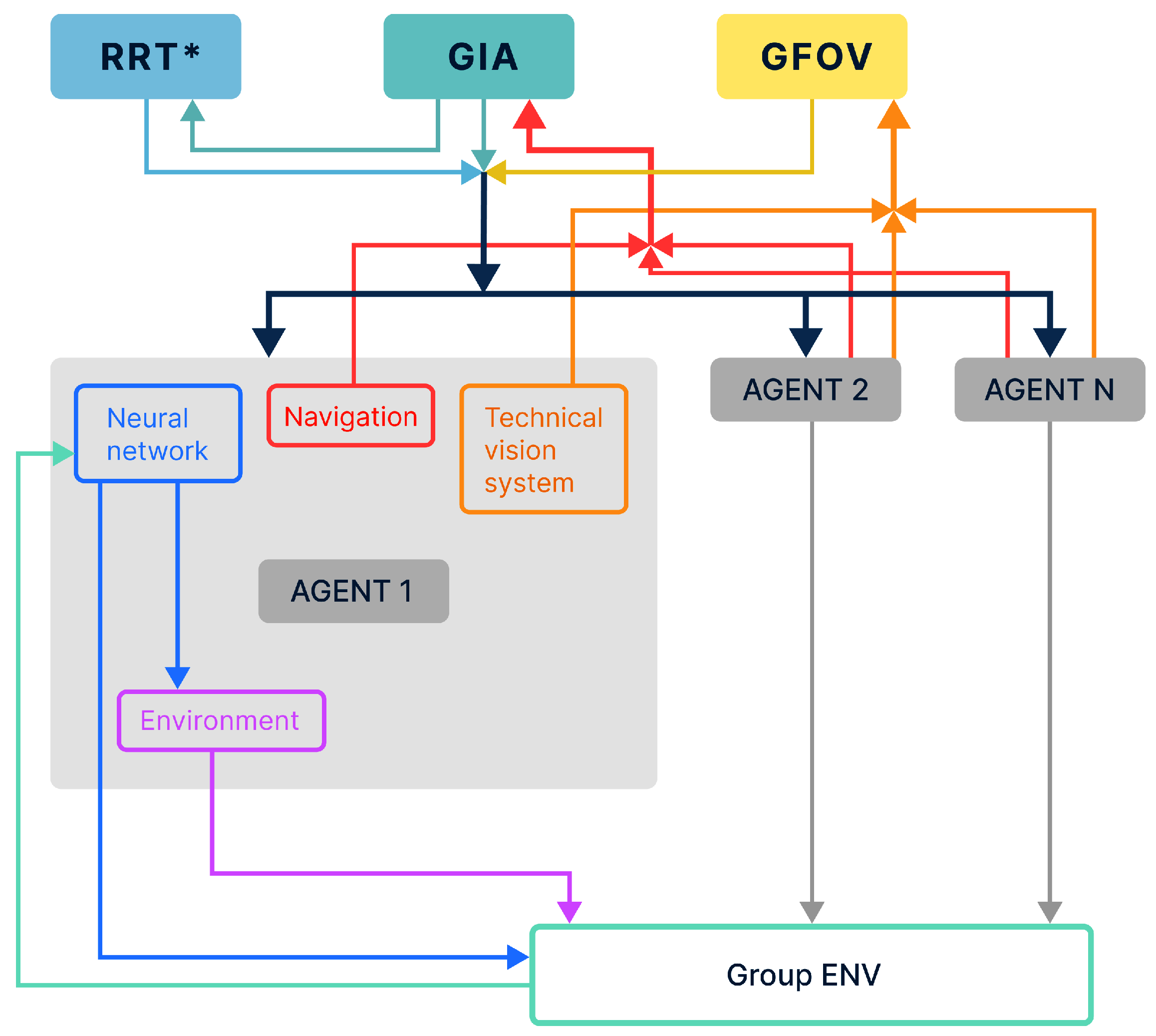
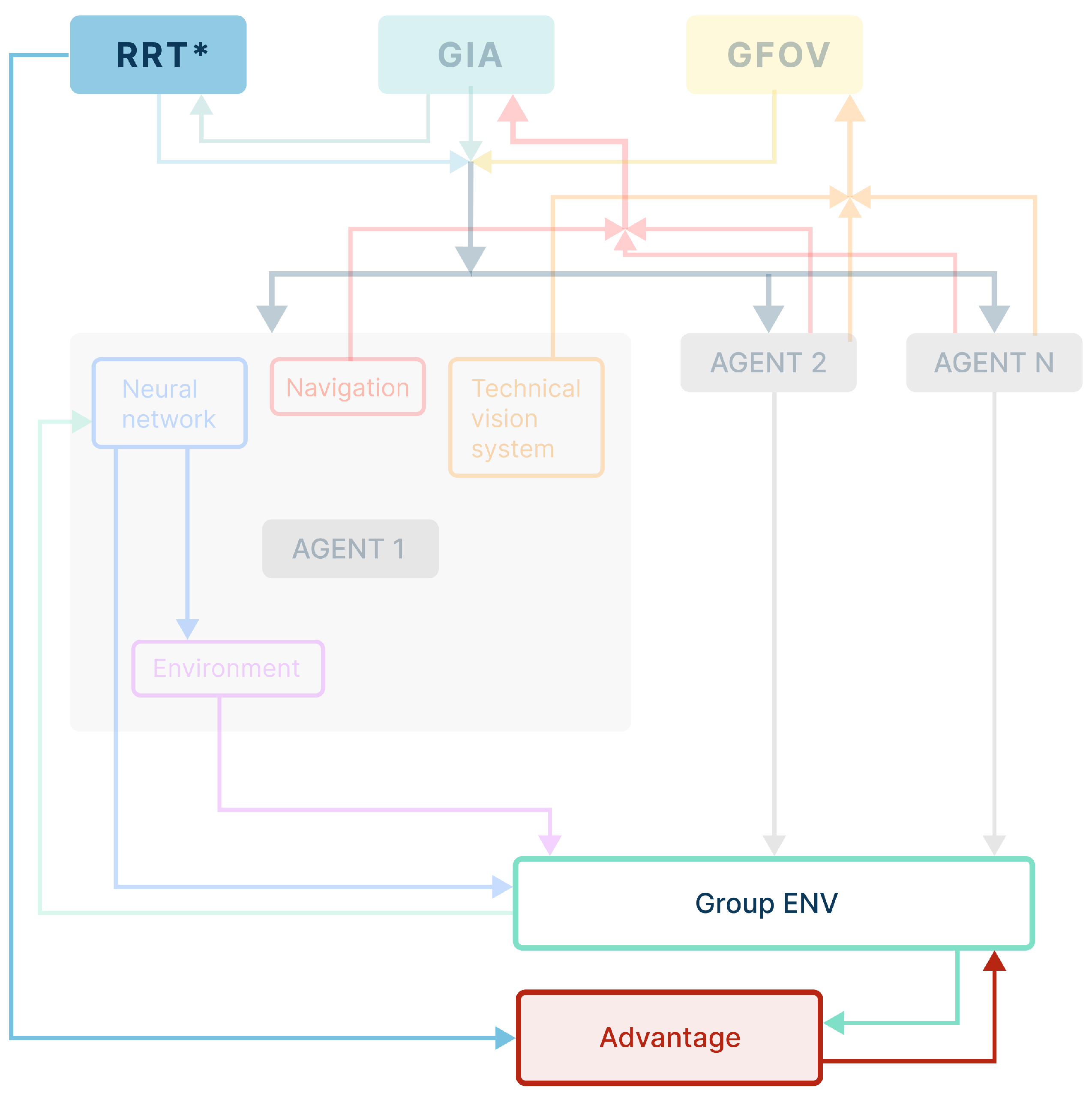
- Formation of an area of group interaction . This module implements the construction of the area space, in which all agents of the group must be located.
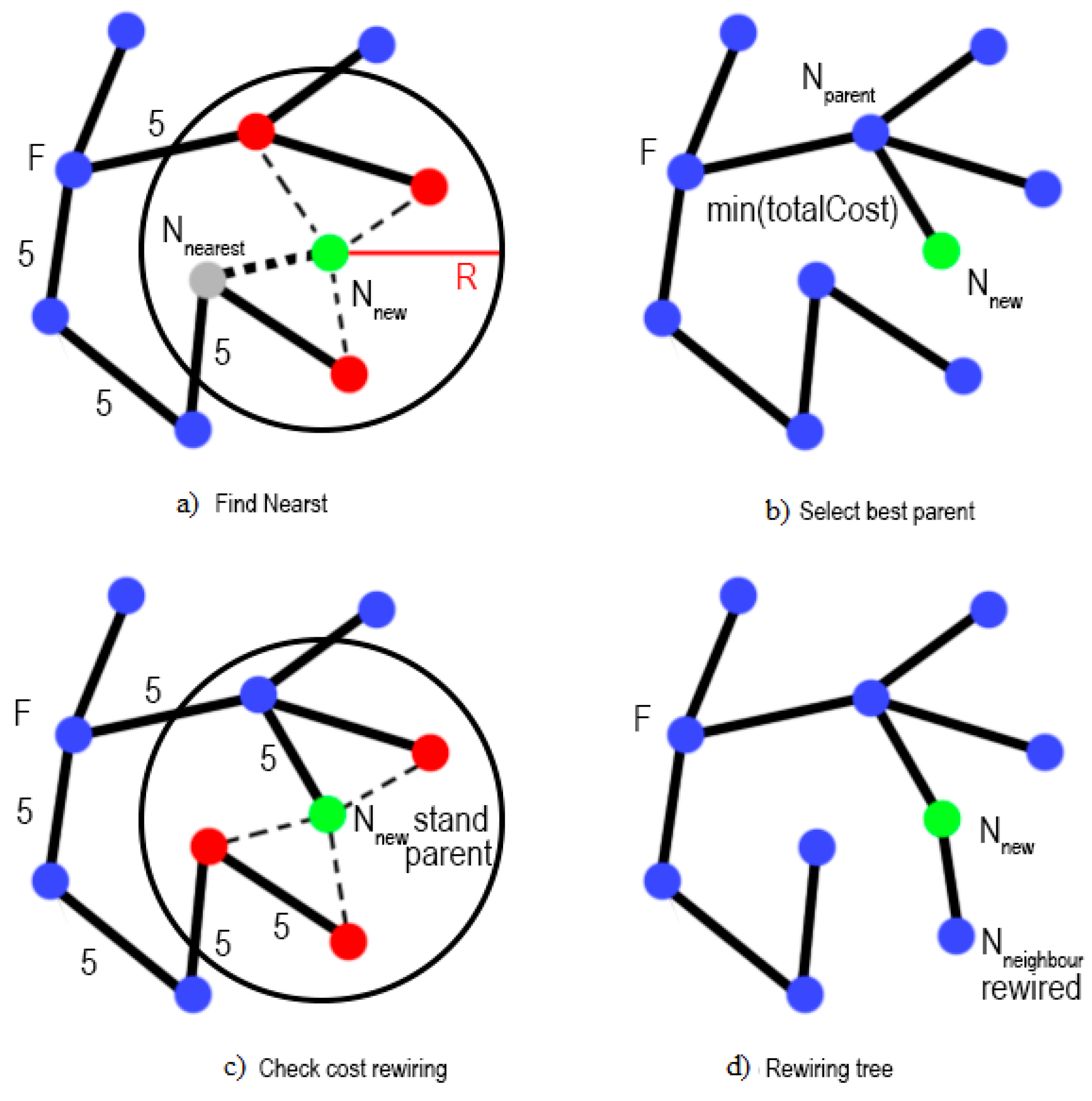
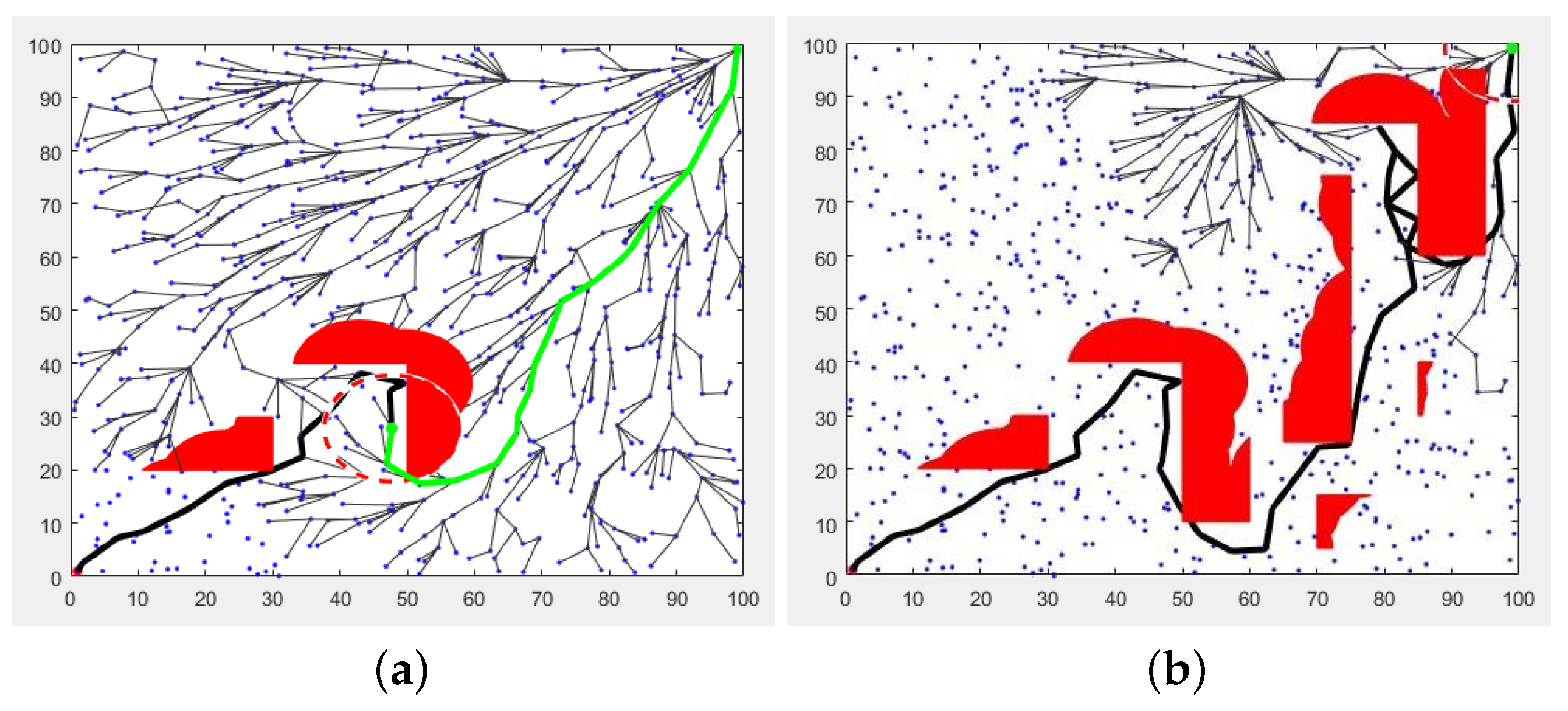
- Global planning algorithm development based on the RRT* method. This algorithm provides real-time trajectory formation of the group without preliminary area mapping.
- Vision system (hereinafter referred to as VS) of each agent in the group, which forms a dataset of the existing obstacles in the AV’s n field of view. This algorithm integrates the data received from the VS of each AV into a single field of view (in which case ), which provides the subsequent analysis and a recommendation at the next stage of the planning algorithm operation.
- Formation of a policy for the internal interaction of agents in a group . This module is required for the analysis of all events occurring in the external space around the agent and its reaction to these events based on conditions that determine the current state of other agents in the group , taking the group task into account.
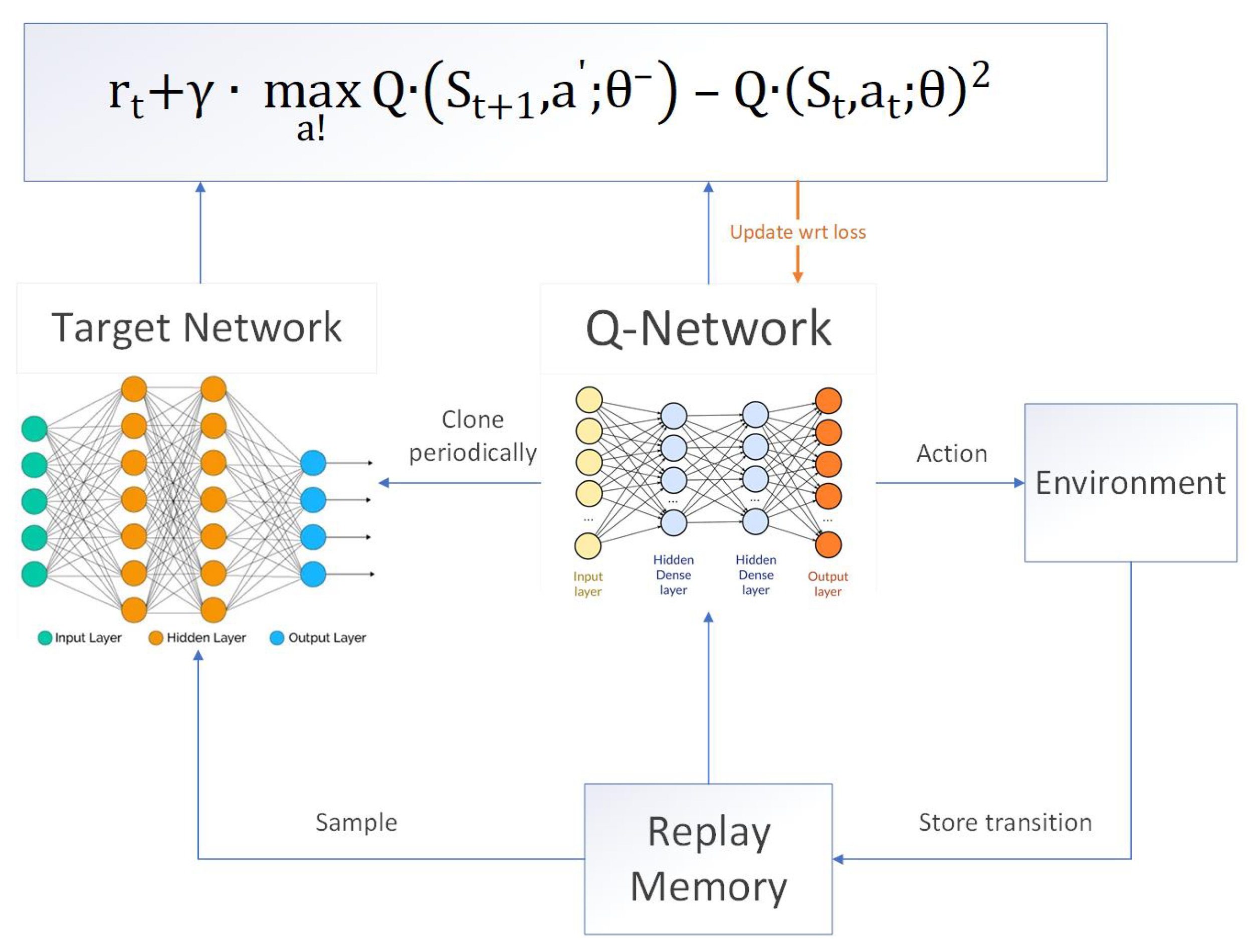
- Development of a neural network path planner for each agent in the group, which manages the local trajectory of the agent’s motion and is based on the data received from the built-in VS systems. In addition, this manages the agent’s position in the group interaction area (hereinafter referred to as GIA) and the group interaction policy parameter. This method is based on the DQN approach [61,70] with a modernized error function.
- Development of a group neural network planner, which is aimed at ensuring the synergy of data received from each agent’s individual neural network. This module calculates the group reward policy , and affects the subsequent actions of each agent in the group.
2.1. Development of the GIA Formation Algorithm
2.2. Development of an Algorithm for the MRC Group’s Global Trajectory Planning
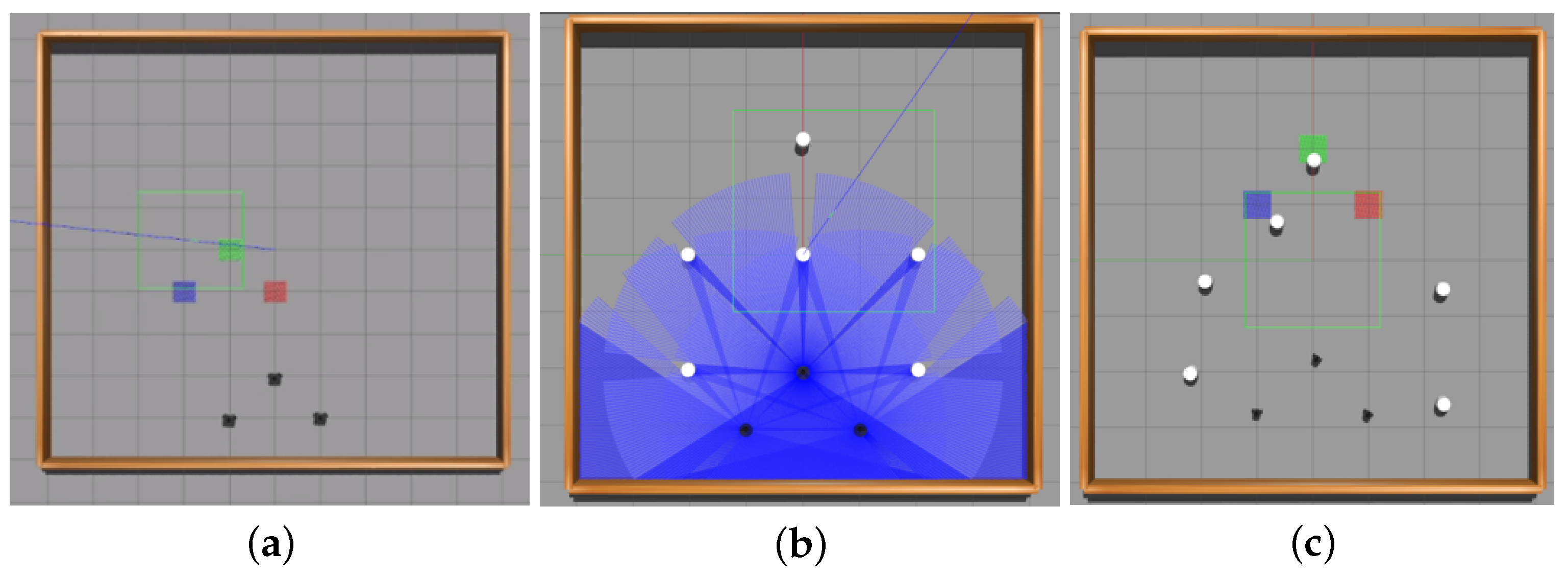
2.3. Development of an Algorithm for the Computer VS of an MRC Agent and Group Field of View (GFOV)
3. Development of the Cascade Architecture of the Neural Network Planning Module for Agents of the MRC Group
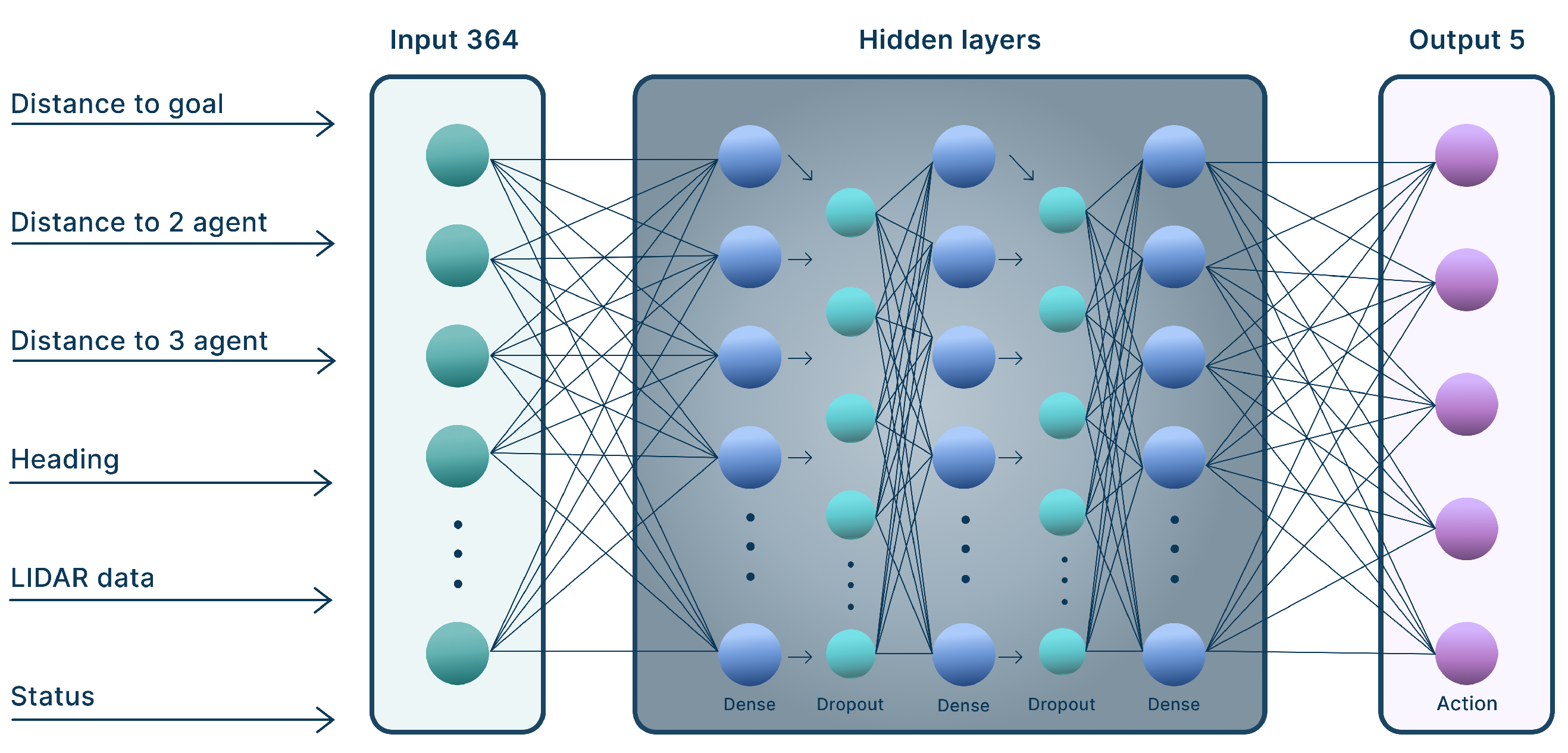
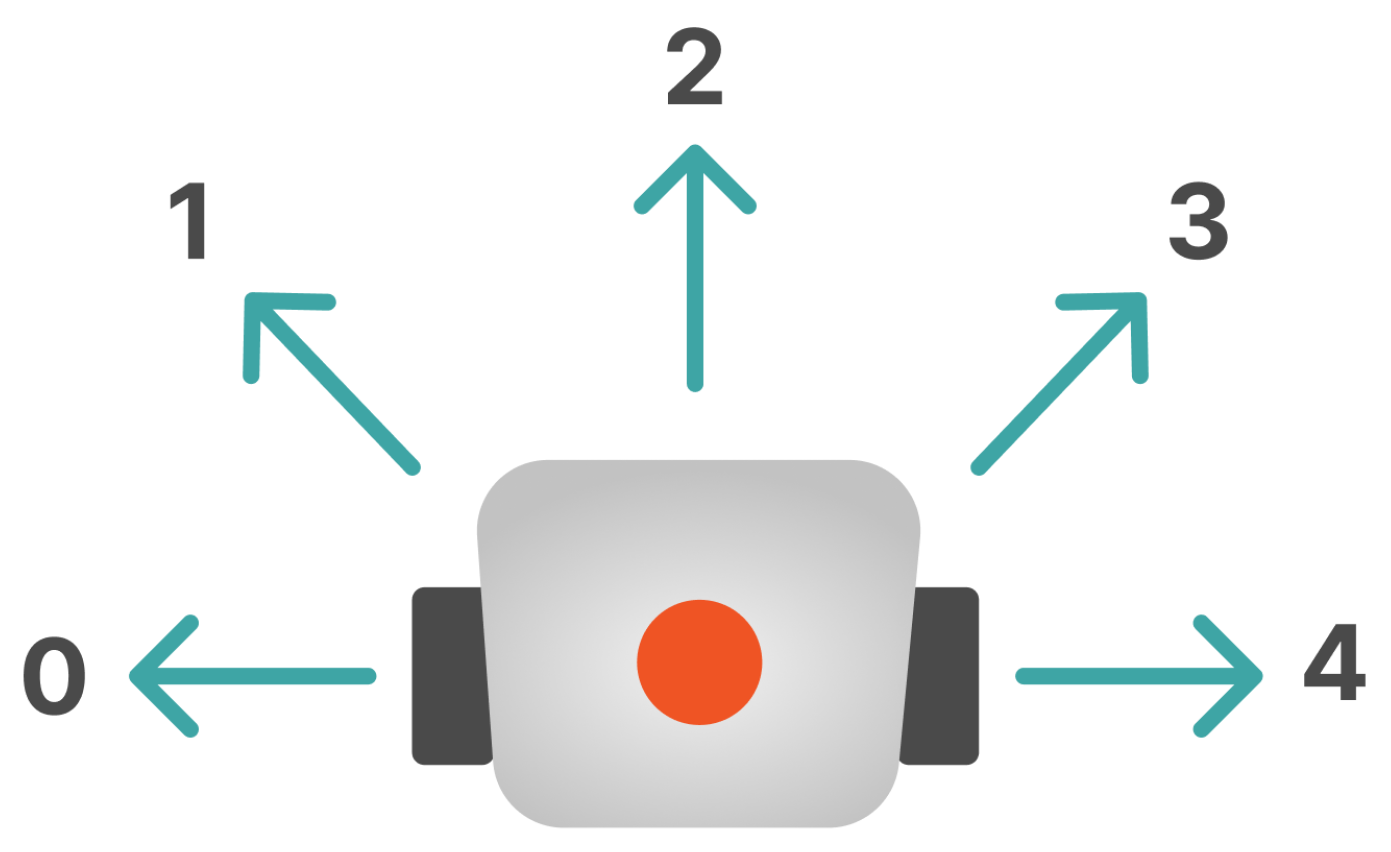
3.1. Development of a Neural Network Agent Action Planner Module in the MRC Group
3.2. Development of a Neural Network Correction Module for MRC Group Action Planning
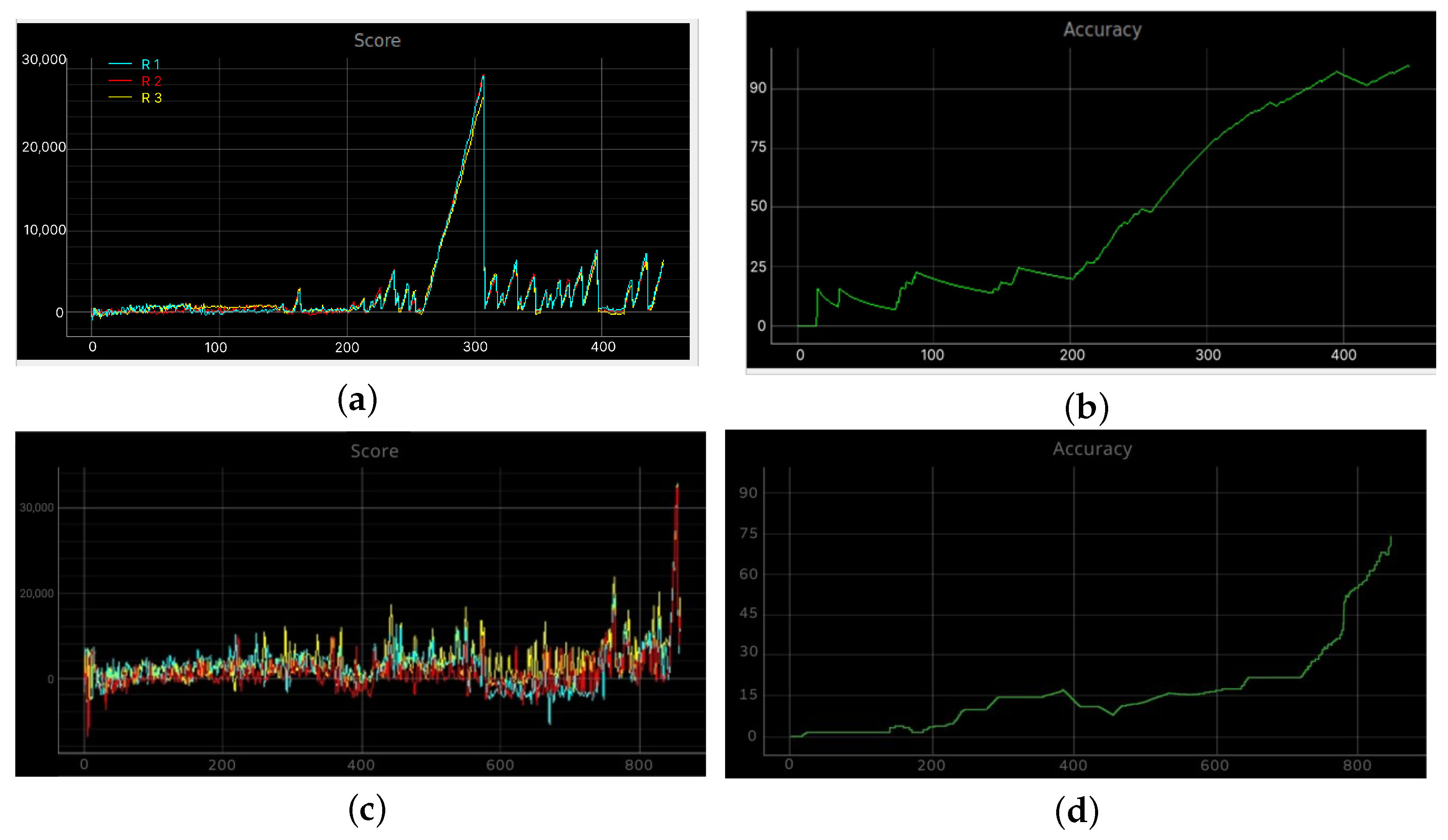
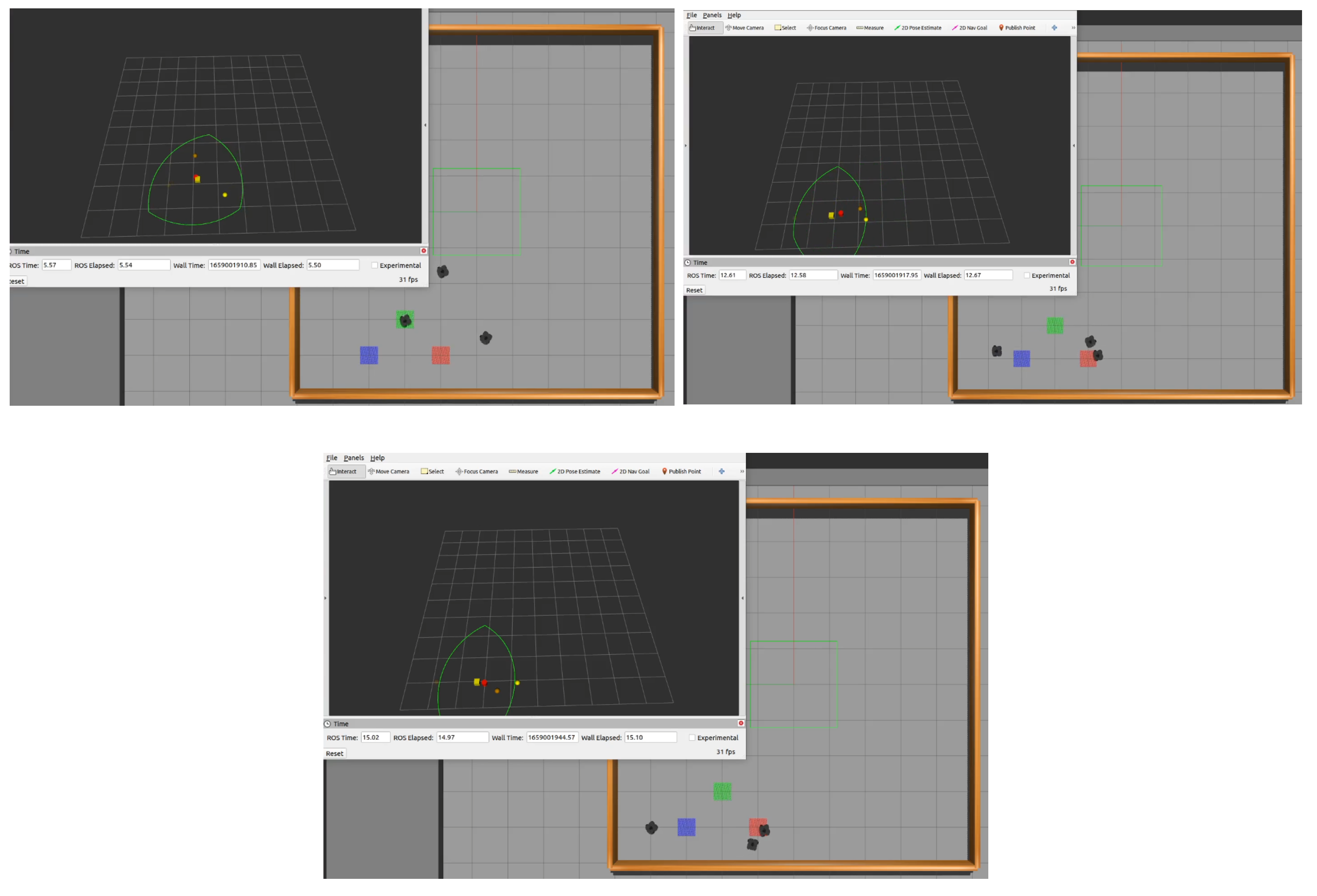
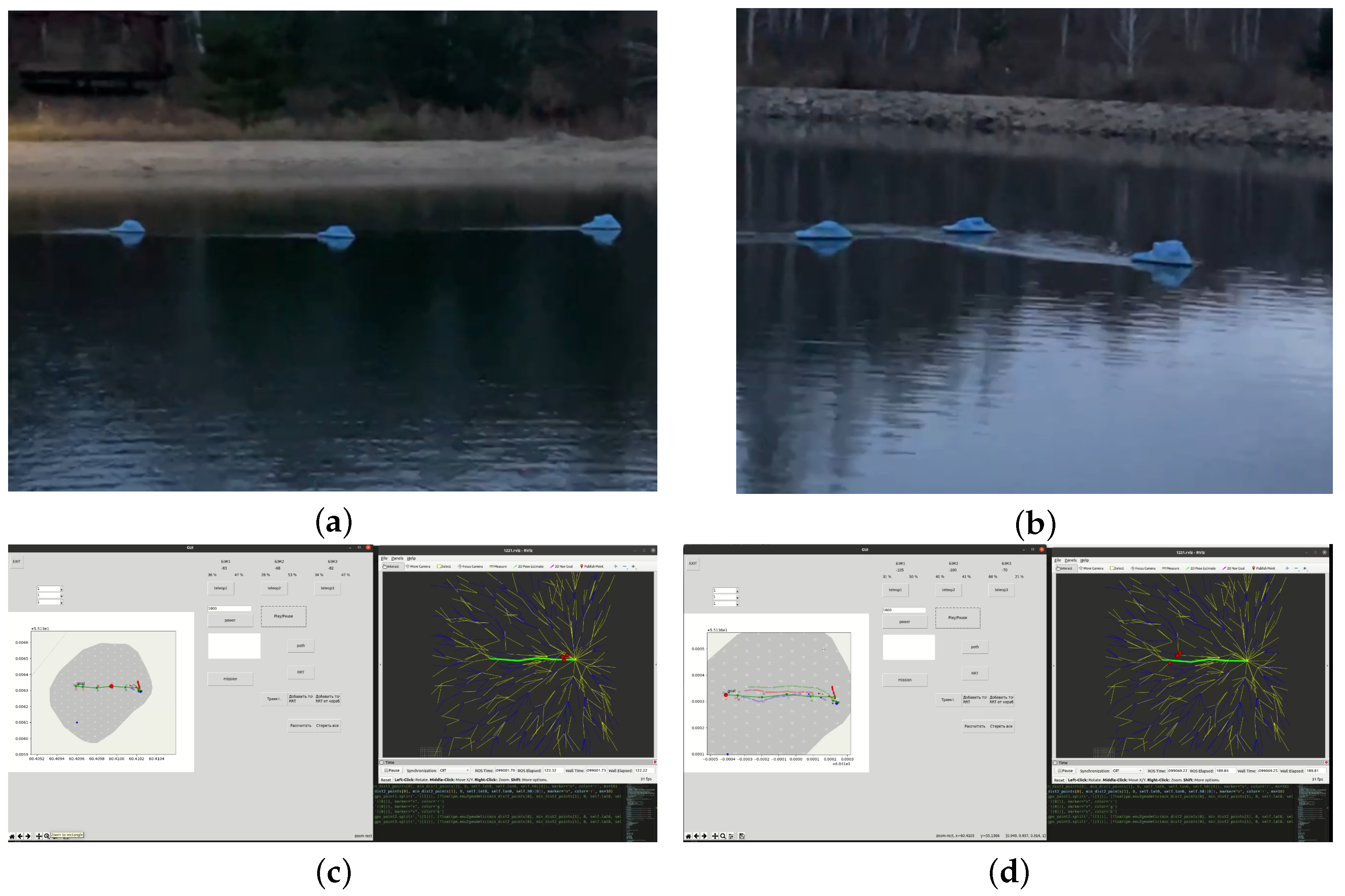
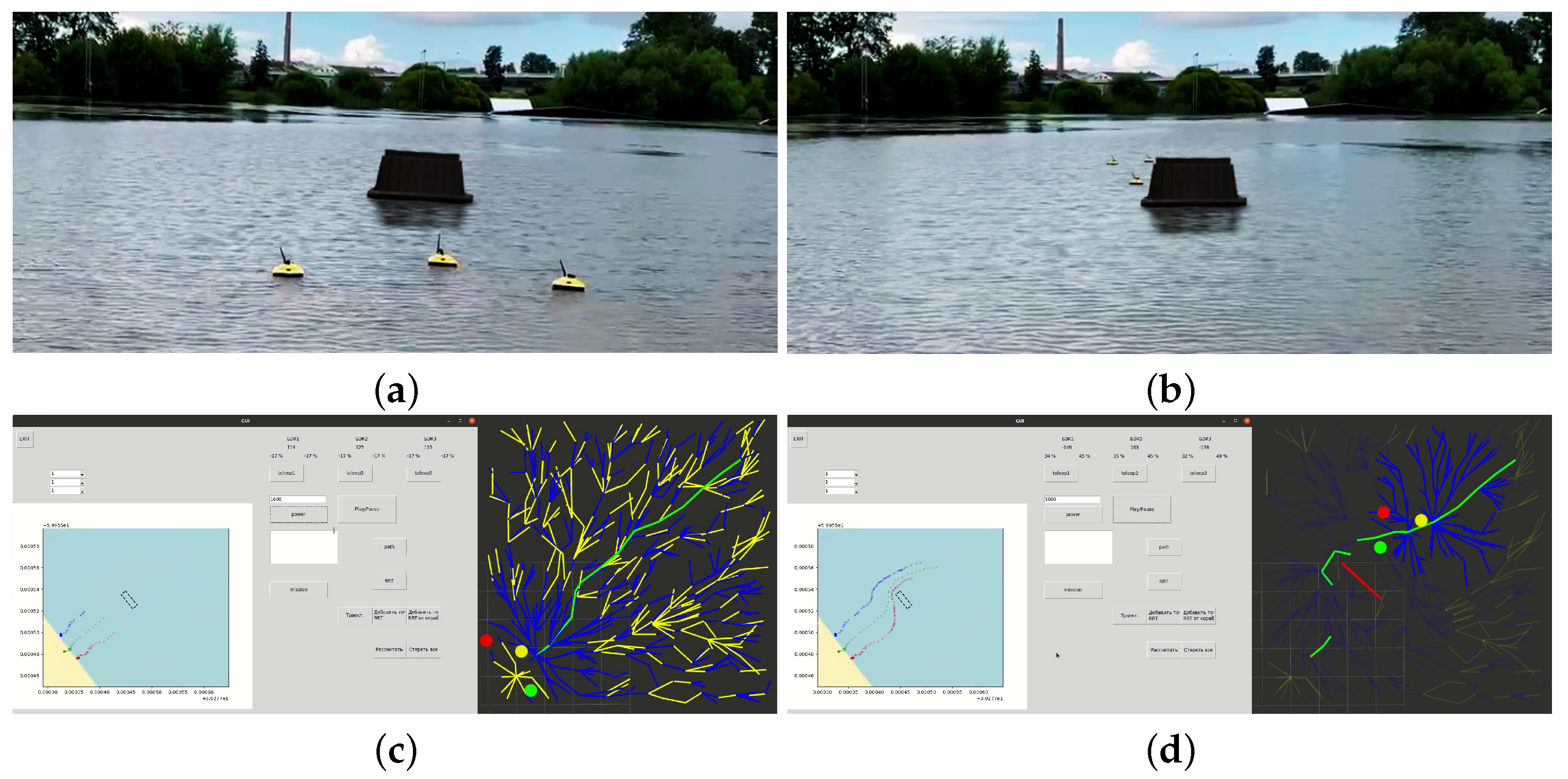
4. Full-Scale Trials of the Developed Modules’ Operation for Planning and Intragroup Interaction Using the Example of a Displacement MRC
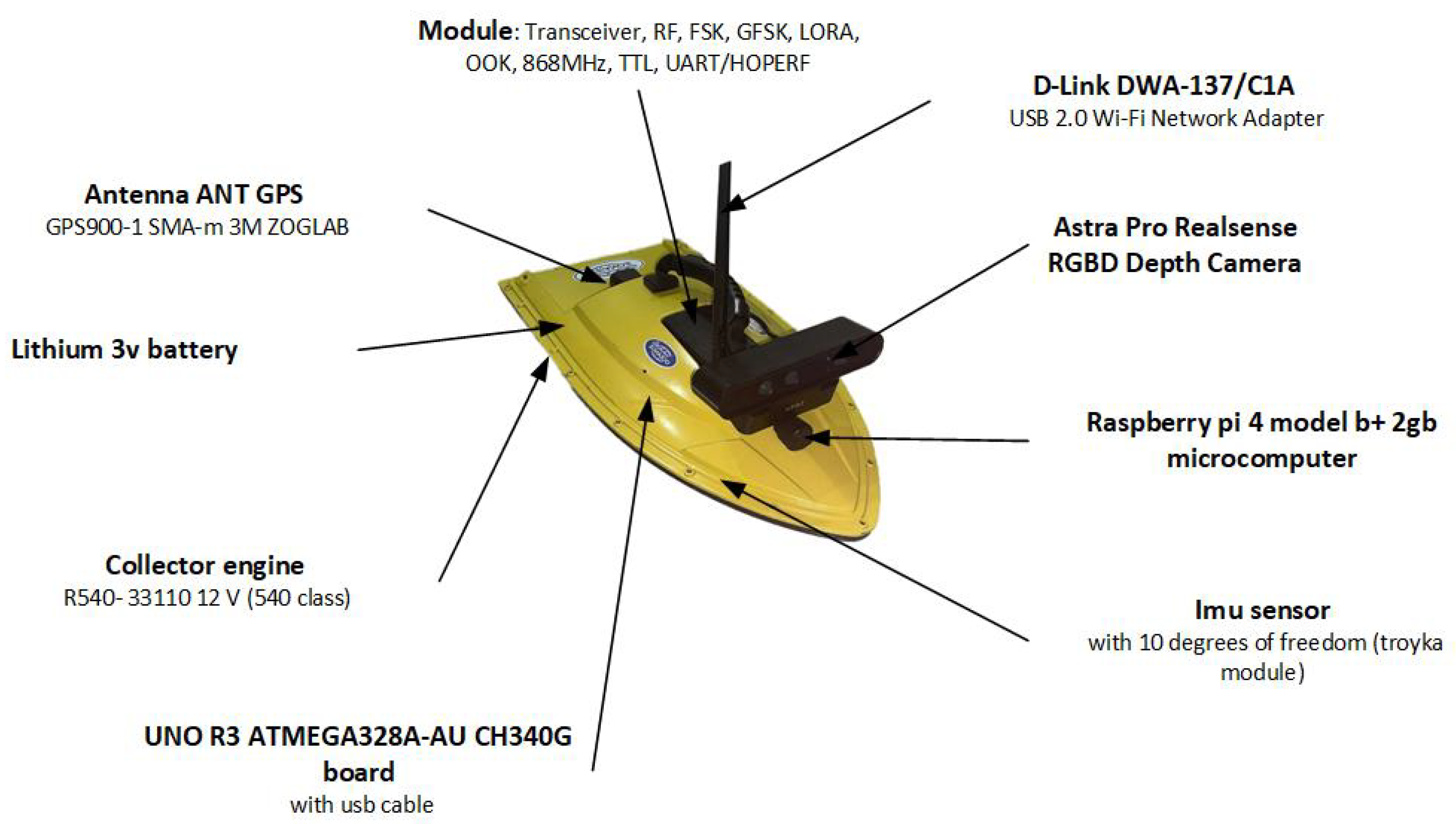
- Module: Transceiver, RF, FSK, GFSK, LORA, OOK, 868 MHz, TTL, UART/HOPERF
- Antenna ant gps GPS900-1 SMA-m 3M ZOGLAB
- Lithium 3v battery
- Two Collector engine R540- 33110 12 V (540 class)
- UNO R3 ATMEGA328A-AU CH340G board with USB cable
- Imu sensor with 10 degrees of freedom (troyka module)
- Raspberry PI 4 model b+ 2 Gb microcomputer
- D-Link DWA-137/C1A USB 2.0 Wi-Fi Network Adapter
- Astra Pro Realsense RGBD Depth Camera
- Study of the local and global planning performance under real conditions and in two cases (without obstacles and with obstacles).
- Operability validation of the technical vision system and the information exchange module (volumes of transmitted data) in order to build up a common field of view of the group.
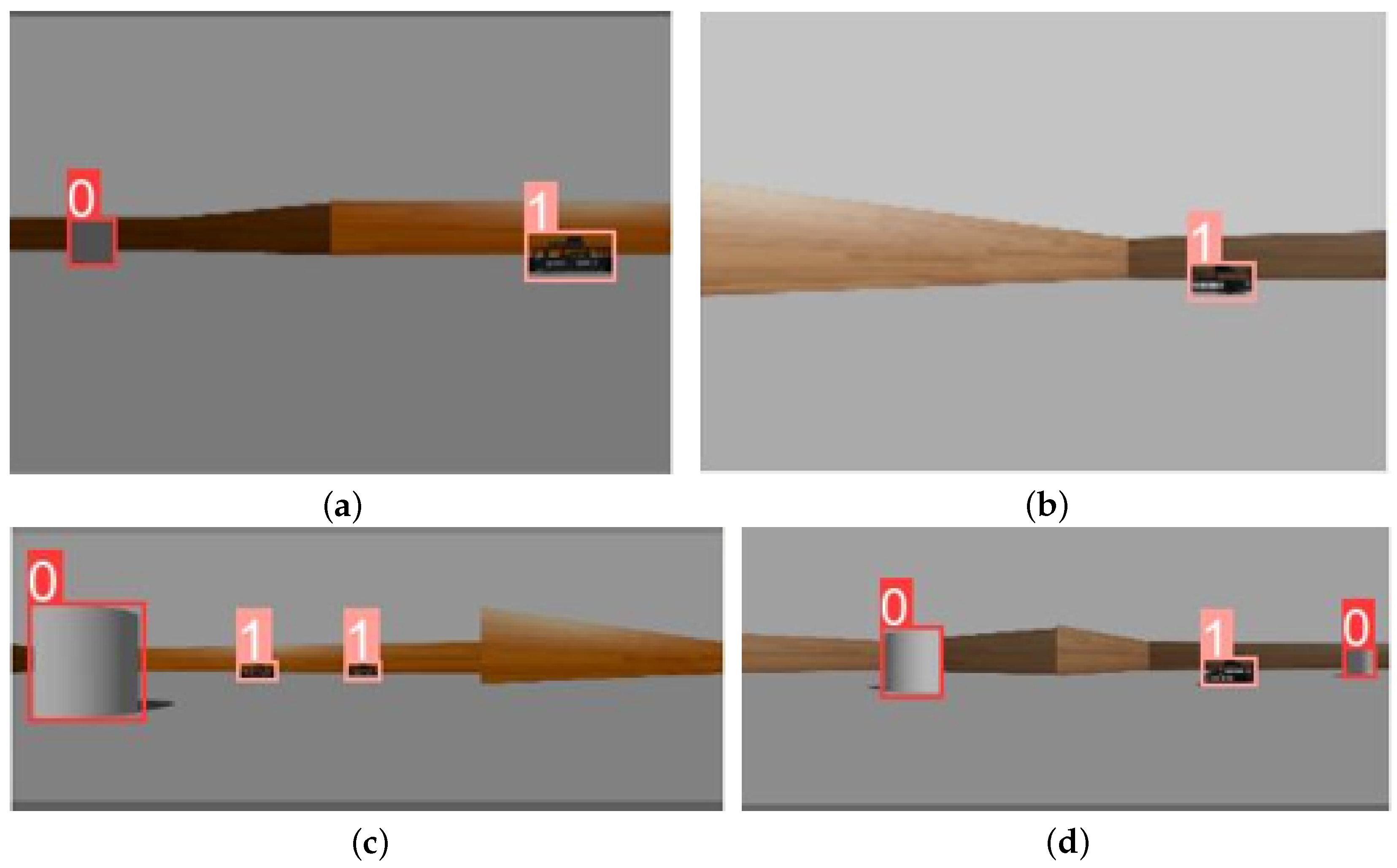
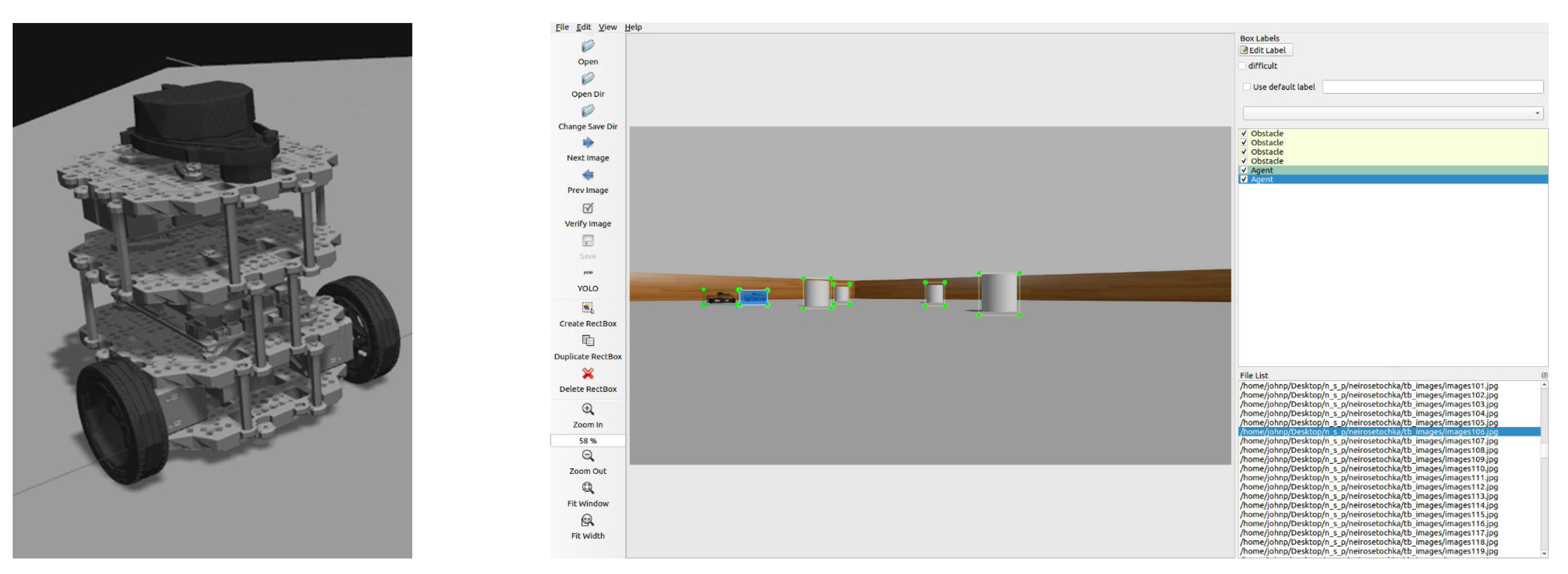
- Formation of a database from the VS system, which is subsequently loaded into the neural network block in order to classify group agents.
- Integration of data obtained from the vision system into the neural network planning system implemented on the hardware of crewless boats.
- Service information, navigation information, and 3D camera data = 1.2 mb;
- Service information, navigation information, and LIDAR data = 1.5 kb.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sens. 2022, 14, 3824. [Google Scholar] [CrossRef]
- Aslan, M.F.; Durdu, A.; Yusefi, A.; Yilmaz, A. HVIOnet: A deep learning based hybrid visual–inertial odometry approach for unmanned aerial system position estimation. Neural Netw. 2022, 155, 461–474. [Google Scholar] [CrossRef] [PubMed]
- Ji, Q.; Fu, S.; Tan, K.; Thorapalli Muralidharan, S.; Lagrelius, K.; Danelia, D.; Andrikopoulos, G.; Wang, X.V.; Wang, L.; Feng, L. Synthesizing the optimal gait of a quadruped robot with soft actuators using deep reinforcement learning. Robot. Comput.-Integr. Manuf. 2022, 78, 102382. [Google Scholar] [CrossRef]
- Kouppas, C.; Saada, M.; Meng, Q.; King, M.; Majoe, D. Hybrid autonomous controller for bipedal robot balance with deep reinforcement learning and pattern generators. Robot. Auton. Syst. 2021, 146, 103891. [Google Scholar] [CrossRef]
- Gupta, P.; Rasheed, A.; Steen, S. Ship performance monitoring using machine-learning. Ocean Eng. 2022, 254, 111094. [Google Scholar] [CrossRef]
- Maevskij, A.M.; Zanin, V.Y.; Kozhemyakin, I.V. Promising high-tech export-oriented and demanded by the domestic market areas of marine robotics. Robot. Tech. Cybern. 2022, 10, 5–13. [Google Scholar] [CrossRef]
- Sokolov, S.S.; Nyrkov, A.P.; Chernyi, S.G.; Zhilenkov, A.A. The Use Robotics for Underwater Research Complex Objects. Adv. Intell. Syst. Comput. 2017, 556, 421–427. [Google Scholar] [CrossRef]
- Pshikhopov, V.; Gurenko, B.V.; Beresnev, M.; Nazarkin, A. Implementation of underwater glider and identification of its parameters. J. Teknol. 2016, 78, 109–114. [Google Scholar] [CrossRef] [Green Version]
- da Silva Tchilian, R.; Rafikova, E.; Gafurov, S.A.; Rafikov, M. Optimal Control of an Underwater Glider Vehicle. Procedia Eng. 2017, 176, 732–740. [Google Scholar] [CrossRef]
- Tian, X.; Zhang, L.; Zhang, H. Research on Sailing Efficiency of Hybrid-Driven Underwater Glider at Zero Angle of Attack. J. Mar. Sci. Eng. 2022, 10, 21. [Google Scholar] [CrossRef]
- Wang, P.; Xinliang, T.; Wenyue, L.; Zhihuan, H.; Yong, L. Dynamic modeling and simulations of the wave glider. Appl. Math. Model. 2019, 66, 77–96. [Google Scholar] [CrossRef]
- Nechaev, Y.I.; Nikushchenko, D.V. Interpretation function of dynamic of an underwater vehicle in non-stationary environment. Mar. Intellect. Technol. 2022, 2, 139–147. [Google Scholar] [CrossRef]
- Nechaev, Y.I.; Nikushchenko, D.V. Digital models of unsteady dynamics of underwater vehicle in the cloud computing environment. Mar. Intellect. Technol. 2022, 3, 346–352. [Google Scholar] [CrossRef]
- Li, D.; Du, L. AUV Trajectory Tracking Models and Control Strategies: A Review. J. Mar. Sci. Eng. 2021, 9, 1020. [Google Scholar] [CrossRef]
- Kot, R. Review of Collision Avoidance and Path Planning Algorithms Used in Autonomous Underwater Vehicles. Electronics 2022, 11, 2301. [Google Scholar] [CrossRef]
- Zhilenkov, A.A.; Chernyi, S.G.; Sokolov, S.S.; Nyrkov, A.P. Intelligent autonomous navigation system for UAV in randomly changing environmental conditions. J. Intell. Fuzzy Syst. 2020, 38, 6619–6625. [Google Scholar] [CrossRef]
- Beloglazov, D.A.; Guzik, V.F.; Kosenko, E.Y.; Kruhmalev, V.; Medvedev, M.Y.; Pereverzev, V.A.; Pshihopov, V.H.; Solovyov, V.V.; Finaev, V.I.; P’yavchenko, A.N.; et al. Intelligent Trajectory Planning of Moving Objects in Environments with Obstacles; Fizmatlit: Moscow, Russia, 2014; p. 450. (In Russian) [Google Scholar]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Kenzin, M.; Bychkov, I.; Maksimkin, N. A Hierarchical Approach to Intelligent Mission Planning for Heterogeneous Fleets of Autonomous Underwater Vehicles. J. Mar. Sci. Eng. 2022, 10, 1639. [Google Scholar] [CrossRef]
- Shu, M.; Zheng, X.; Li, F.; Wang, K.; Li, Q. Numerical Simulation of Time-Optimal Path Planning for Autonomous Underwater Vehicles Using a Markov Decision Process Method. Appl. Sci. 2022, 12, 3064. [Google Scholar] [CrossRef]
- Maevskij, A.M.; Zanin, V.Y.; Kozhemyakin, I. Development of a combined control system for resident/intervention AUV based on behavioral methods. Izv. SFedU. Eng. Sci. 2020, 1, 119–133. [Google Scholar] [CrossRef]
- Maevskij, A.; Gorelyi, A.; Morozov, R. Development of a Hybrid Method for Planning the Movement of a Group of Marine Robotic Complexes in a Priori Unknown Environment with Obstacles. In Proceedings of the 2021 IEEE 22nd International Conference of Young Professionals in Electron Devices and Materials (EDM), Souzga, Russia, 30 June–4 July 2021; pp. 461–466. [Google Scholar] [CrossRef]
- Li, J.H.; Kang, H.; Kim, M.G.; Lee, M.J.; Cho, G.R.; Jin, H.S. Adaptive Formation Control of Multiple Underactuated Autonomous Underwater Vehicles. J. Mar. Sci. Eng. 2022, 10, 1233. [Google Scholar] [CrossRef]
- Pshihopov, V.H.; Gajduk, A.R.; Medvedev, M.Y.; Gontar, D.N.; Solovyov, V.V.; Martyanov, O.V. The concept of the robotics operational group. Izv. Yufu. Tekhnicheskie-Nauk. Izv. Sfedu. Eng. Sci. 2020, 1, 6–16. (In Russian) [Google Scholar]
- Pshikhopov, V.; Medvedev, M.; Gaiduk, A.; Kolesnikov, A. Control Method for Heterogeneous Vehicle Groups Control in Obstructed 2-D Environments. Lect. Notes Comput. Sci. 2016, 9812, 40–47. [Google Scholar] [CrossRef]
- Pshikhopov, V. Path Planning for Vehicles Operating in Uncertain 2D Environments; Butterworth-Heinemann: Woburn, MA, USA, 2017; p. 298. [Google Scholar] [CrossRef]
- Zhou, W.J.; Subagdja, B.; Tan, A.H.; Ong, D.W.S. Hierarchical control of multi-agent reinforcement learning team in real-time strategy (RTS) games. Expert Syst. Appl. 2021, 186, 115707. [Google Scholar] [CrossRef]
- Zheng, H.; Li, X.; Chen, J.; Dong, J.; Zhang, Y.; Lin, C. One4All: Manipulate One Agent to Poison the Cooperative Multi-Agent Reinforcement Learning. Comput. Secur. 2023, 124, 103005. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Samvelyan, M.; Rashid, T.; Witt, C.S.D.; Farquhar, G.; Nardelli, N.; Rudner, T.G.J.; Hung, C.M.; Torr, P.H.S.; Foerster, J.N.; Whiteson, S. The StarCraft Multi-Agent Challenge. arXiv 2019, arXiv:1902.04043. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, H.; Wang, X.; Wu, Y.; Keutzer, K.; Gonzalez, J.; Tian, Y. Multi-Agent Collaboration via Reward Attribution Decomposition. arXiv 2020, arXiv:2010.08531. [Google Scholar] [CrossRef]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar] [CrossRef]
- Bonse, R.; Kockelkorn, W.; Smelik, R.M.; Veelders, P.; Moerman, W. Learningagents in Quake III; Technical Report; University of Utrecht, Department of Computer Science: Utrecht, The Netherlands, 2004. [Google Scholar]
- Li, J.; Zhai, X.; Xu, J.; Li, C. Target Search Algorithm for AUV Based on Real-Time Perception Maps in Unknown Environment. Machines 2021, 9, 147. [Google Scholar] [CrossRef]
- Yang, J.; Xi, M.; Wen, J.; Li, Y.; Song, H.H. A digital twins enabled underwater intelligent internet vehicle path planning system via reinforcement learning and edge computing. Digit. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Shen, L.; Mao, P.; Fang, Q.; Wang, J. A Trajectory Tracking Approach for Aerial Manipulators Using Nonsingular Global Fast Terminal Sliding Mode and an RBF Neural Network. Machines 2022, 10, 1021. [Google Scholar] [CrossRef]
- Kim, J.C.; Kim, M.H.; Suh, H.E.; Naseem, M.T.; Lee, C.S. Hybrid Approach for Facial Expression Recognition Using Convolutional Neural Networks and SVM. Appl. Sci. 2022, 12, 5493. [Google Scholar] [CrossRef]
- Zhu, J.; Li, A.; Qin, F.; Che, H.; Wang, J. A Novel Hybrid Method Based on Deep Learning for an Integrated Navigation System during DVL Signal Failure. Electronics 2022, 11, 2980. [Google Scholar] [CrossRef]
- Shi, J.; Fang, J.; Zhang, Q.; Wu, Q.; Zhang, B.; Gao, F. Dynamic Target Tracking of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2022, 10, 1406. [Google Scholar] [CrossRef]
- Yan, Z.; Klochkov, Y.; Xi, L. Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics). Robotics 2022, 11, 83. [Google Scholar] [CrossRef]
- Yildirim, S.; Sagiroglu, S. Artificial Neural Networks in Robot Control Systems: A Survey Paper. Math. Comput. Appl. 2002, 7, 103–112. [Google Scholar] [CrossRef]
- Liang, J.; Huang, W.; Zhou, F.; Liang, J.; Lin, G.; Xiao, E.; Li, H.; Zhang, X. Double-Loop PID-Type Neural Network Sliding Mode Control of an Uncertain Autonomous Underwater Vehicle Model Based on a Nonlinear High-Order Observer with Unknown Disturbance. Mathematics 2022, 10, 3332. [Google Scholar] [CrossRef]
- Anderlini, E.; Parker, G.G.; Thomas, G. Docking Control of an Autonomous Underwater Vehicle Using Reinforcement Learning. Appl. Sci. 2019, 9, 3456. [Google Scholar] [CrossRef] [Green Version]
- Carlucho, I.; De Paula, M.; Wang, S.; Petillot, Y.; Acosta, G.G. Adaptive low-level control of autonomous underwater vehicles using deep reinforcement learning. Robot. Auton. Syst. 2018, 107, 71–86. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, C.; Wei, Y.; Zhang, C. Bounded neural adaptive formation control of multiple underactuated AUVs under uncertain dynamics. ISA Trans. 2020, 105, 111–119. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, C.; Wei, Y.J.; Zhang, C. Filter-backstepping based neural adaptive formation control of leader-following multiple AUVs in three dimensional space. Ocean Eng. 2020, 201, 107150. [Google Scholar] [CrossRef]
- Fahn, C.S.; Chen, S.C.; Wu, P.Y.; Chu, T.L.; Li, C.H.; Hsu, D.Q.; Wang, H.H.; Tsai, H.M. Image and Speech Recognition Technology in the Development of an Elderly Care Robot: Practical Issues Review and Improvement Strategies. Healthcare 2022, 10, 2252. [Google Scholar] [CrossRef] [PubMed]
- Rodziewicz-Bielewicz, J.; Korzeń, M. Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation. Sensors 2022, 22, 6518. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Chehri, A.; Hassan, M.M.; Jeon, G. IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 4107. [Google Scholar] [CrossRef]
- Hong Khai, T.; Abdullah, S.N.H.S.; Hasan, M.K.; Tarmizi, A. Underwater Fish Detection and Counting Using Mask Regional Convolutional Neural Network. Water 2022, 14, 222. [Google Scholar] [CrossRef]
- Li, S.; Yang, W.; Xu, L.; Li, C. An Environmental Perception Framework for Robotic Fish Formation Based on Machine Learning Methods. Appl. Sci. 2019, 9, 3573. [Google Scholar] [CrossRef] [Green Version]
- Thum, G.W.; Tang, S.H.; Ahmad, S.A.; Alrifaey, M. Toward a Highly Accurate Classification of Underwater Cable Images via Deep Convolutional Neural Network. J. Mar. Sci. Eng. 2020, 8, 924. [Google Scholar] [CrossRef]
- Martin-Abadal, M.; Piñar-Molina, M.; Martorell-Torres, A.; Oliver-Codina, G.; Gonzalez-Cid, Y. Underwater Pipe and Valve 3D Recognition Using Deep Learning Segmentation. J. Mar. Sci. Eng. 2021, 9, 5. [Google Scholar] [CrossRef]
- Zhang, G.; Xu, Z.; Hou, Z.; Yang, W.; Liang, J.; Yang, G.; Wang, J.; Wang, H.; Han, C. A Systematic Error Compensation Strategy Based on an Optimized Recurrent Neural Network for Collaborative Robot Dynamics. Appl. Sci. 2020, 10, 6743. [Google Scholar] [CrossRef]
- Truong, H.V.A.; Tran, D.T.; Ahn, K.K. A Neural Network Based Sliding Mode Control for Tracking Performance with Parameters Variation of a 3-DOF Manipulator. Appl. Sci. 2019, 9, 2023. [Google Scholar] [CrossRef] [Green Version]
- Yeo, S.J.; Choi, W.S.; Hong, S.Y.; Song, J.H. Enhanced Convolutional Neural Network for In Situ AUV Thruster Health Monitoring Using Acoustic Signals. Sensors 2022, 22, 7073. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, B.; Wu, K.; Chepinskiy, S.A.; Zhilenkov, A.A.; Chernyi, S.; Krasnov, A.Y. A visual terrain classification method for mobile robots’ navigation based on convolutional neural network and support vector machine. Trans. Inst. Meas. Control 2021, 44, 744–753. [Google Scholar] [CrossRef]
- Ren, J.; Huang, X.; Huang, R.N. Efficient Deep Reinforcement Learning for Optimal Path Planning. Electronics 2022, 11, 3628. [Google Scholar] [CrossRef]
- Malik, A.; Lischuk, Y.; Henderson, T.; Prazenica, R. A Deep Reinforcement-Learning Approach for Inverse Kinematics Solution of a High Degree of Freedom Robotic Manipulator. Robotics 2022, 11, 44. [Google Scholar] [CrossRef]
- Tang, W.; Cheng, C.; Ai, H.; Chen, L. Dual-Arm Robot Trajectory Planning Based on Deep Reinforcement Learning under Complex Environment. Micromachines 2022, 13, 564. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Zhang, H.; Lin, C.; Yu, D.; Li, C. AUV Obstacle Avoidance Planning Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2021, 9, 1166. [Google Scholar] [CrossRef]
- Lan, W.; Jin, X.; Chang, X.; Wang, T.; Zhou, H.; Tian, W.; Zhou, L. Path planning for underwater gliders in time-varying ocean current using deep reinforcement learning. Ocean Eng. 2022, 262, 112226. [Google Scholar] [CrossRef]
- Hadi, B.; Khosravi, A.; Sarhadi, P. Deep reinforcement learning for adaptive path planning and control of an autonomous underwater vehicle. Appl. Ocean Res. 2022, 129, 103326. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef] [Green Version]
- Luo, T.; Subagdja, B.; Wang, D.; Tan, A.H. Multi-Agent Collaborative Exploration through Graph-based Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Agents (ICA), Jinan, China, 18–21 October 2019; pp. 2–7. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, I.H.; Brewitt, C.; Carlucho, I.; Christianos, F.; Dunion, M.; Fosong, E.; Garcin, S.; Guo, S.; Gyevnar, B.; McInroe, T.; et al. Deep Reinforcement Learning for Multi-Agent Interaction. AI Commun. 2022. [Google Scholar] [CrossRef]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Bahrpeyma, F.; Reichelt, D. A review of the applications of multi-agent reinforcement learning in smart factories. Front. Robot. AI 2022, 9, 1027340. [Google Scholar] [CrossRef]
- Xiaofei, Y.; Yilun, S.; Wei, L.; Hui, Y.; Weibo, Z.; Zhengrong, X. Global path planning algorithm based on double DQN for multi-tasks amphibious unmanned surface vehicle. Ocean Eng. 2022, 266, 112809. [Google Scholar] [CrossRef]
- Xu, J.; Wang, X.; Liu, P.; Duan, Q. Adaptive Proportional-Integral Sliding Mode-Based Fault Tolerant Control for Autonomous Underwater Vehicles with Thrusters Saturation and Potential Failure. J. Mar. Sci. Eng. 2022, 10, 1614. [Google Scholar] [CrossRef]
- Vu, Q.V.; Dinh, T.A.; Nguyen, T.V.; Tran, H.V.; Le, H.X.; Pham, H.V.; Kim, T.D.; Nguyen, L. An Adaptive Hierarchical Sliding Mode Controller for Autonomous Underwater Vehicles. Electronics 2021, 10, 2316. [Google Scholar] [CrossRef]
- Zhao, W.; Han, F.; Su, Z.; Qiu, X.; Zhang, J.; Zhao, Y. An Improved Underwater Recognition Algorithm for Subsea X-Tree Key Components Based on Deep Transfer Learning. J. Mar. Sci. Eng. 2022, 10, 1562. [Google Scholar] [CrossRef]
- Kot, R. Review of Obstacle Detection Systems for Collision Avoidance of Autonomous Underwater Vehicles Tested in a Real Environment. Electronics 2022, 11, 3615. [Google Scholar] [CrossRef]
- Jiang, C.; Ren, H.; Ye, X.; Zhu, J.; Zeng, H.; Nan, Y.; Sun, M.; Ren, X.; Huo, H. Object detection from UAV thermal infrared images and videos using YOLO models. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102912. [Google Scholar] [CrossRef]
- Official ROS. 2022. Available online: https://www.ros.org/ (accessed on 25 November 2022).
- Project TurtleBot3. 2022. Available online: https://emanual.robotis.com/docs/en/platform/turtlebot3/overview/ (accessed on 25 November 2022).
- Newman, W. A Systematic Approach to Learning Robot Programming with ROS; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Nikushchenko, D.; Maevskij, A.; Kozhemyakin, I.; Ryzhov, V.; Goreliy, A.; Sulima, T. Development of a Structural-Functional Approach for Heterogeneous Glider-Type Marine Robotic Complexes’ Group Interaction to Solve Environmental Monitoring and Patrolling Problems. J. Mar. Sci. Eng. 2022, 10, 1531. [Google Scholar] [CrossRef]
- Huang, S.; Kanervisto, A.; Raffin, A.; Wang, W.; Ontañón, S.; Dossa, R.F.J. A2C is a special case of PPO. arXiv 2022, arXiv:2205.09123. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.433 | 0.451 | 0.442 | 0.432 | 0.442 | 0.412 | 0.421 | 0.412 | 0.423 | 0.411 | |
| 26.82 | 27.112 | 28.023 | 25.93 | 29.12 | 26.84 | 26.93 | 30.03 | 26.34 | 28.53 | |
| 27.23 | 26.91 | 28.93 | 27.26 | 27.42 | 25.81 | 25.96 | 27.34 | 27.45 | 27.53 | |
| 26.12 | 29.14 | 27.34 | 26.32 | 26.75 | 28.21 | 28.96 | 26.78 | 28.44 | 29.53 |
| Sample | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.433 | 0.451 | 0.442 | 0.432 | 0.442 | 0.412 | 0.421 | 0.412 | 0.423 | 0.411 | 0.413 | 0.411 | 0.441 | 0.421 | 0.403 | |
| 38.79 | 46.46 | 46.75 | 39.92 | 39.1 | 39.84 | 42.88 | 47.5 | 40.13 | 45.42 | 42.77 | 43.8 | 40.9 | 45.57 | 45.83 | |
| 44.38 | 41.67 | 40 | 37.78 | 39.02 | 44.26 | 37.58 | 44.35 | 41.87 | 40.09 | 43.05 | 44.78 | 47.72 | 41.56 | 37.49 | |
| 47.38 | 46.4 | 38.74 | 41.57 | 45.94 | 40.35 | 41.06 | 42.93 | 46.13 | 41.84 | 44.03 | 47.48 | 37.78 | 37.22 | 41.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikushchenko, D.; Maevskiy, A.; Kozhemyakin, I.; Ryzhov, V.; Bondar, A.; Goreliy, A.; Pechaiko, I.; Nikitina, E. Development of a Cascade Intelligent System for Path Planning of the Group of Marine Robotic Complexes. J. Mar. Sci. Eng. 2023, 11, 610. https://doi.org/10.3390/jmse11030610
Nikushchenko D, Maevskiy A, Kozhemyakin I, Ryzhov V, Bondar A, Goreliy A, Pechaiko I, Nikitina E. Development of a Cascade Intelligent System for Path Planning of the Group of Marine Robotic Complexes. Journal of Marine Science and Engineering. 2023; 11(3):610. https://doi.org/10.3390/jmse11030610
Chicago/Turabian StyleNikushchenko, Dmitry, Andrey Maevskiy, Igor Kozhemyakin, Vladimir Ryzhov, Alexander Bondar, Artem Goreliy, Ivan Pechaiko, and Ekaterina Nikitina. 2023. "Development of a Cascade Intelligent System for Path Planning of the Group of Marine Robotic Complexes" Journal of Marine Science and Engineering 11, no. 3: 610. https://doi.org/10.3390/jmse11030610