

Underwater Target Detection Lightweight Algorithm Based on Multi-Scale Feature Fusion

Abstract
:1. Introduction
2. Related Work
2.1. YOLOv5-lite Detection Framework
2.2. Vision Transformer Models
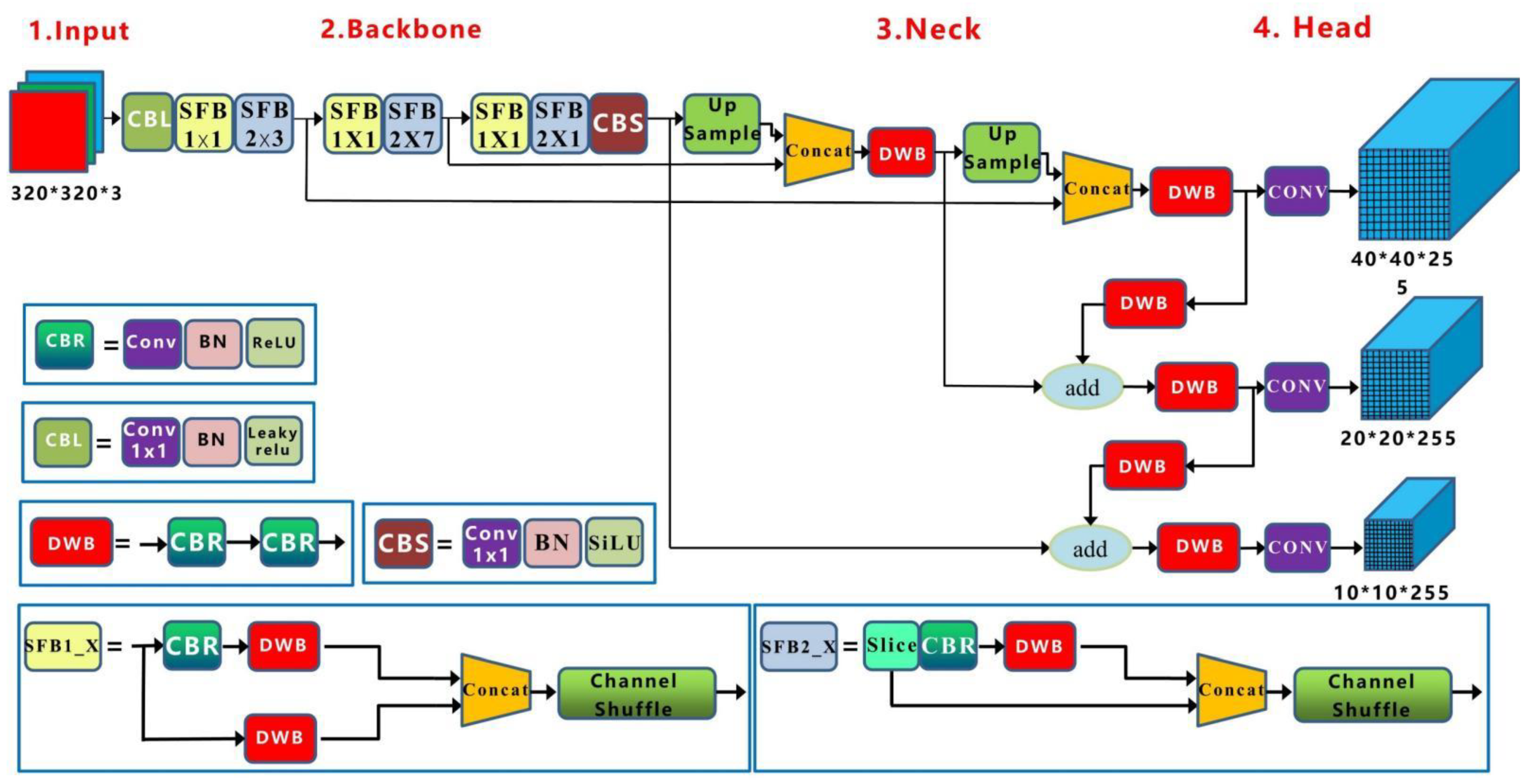
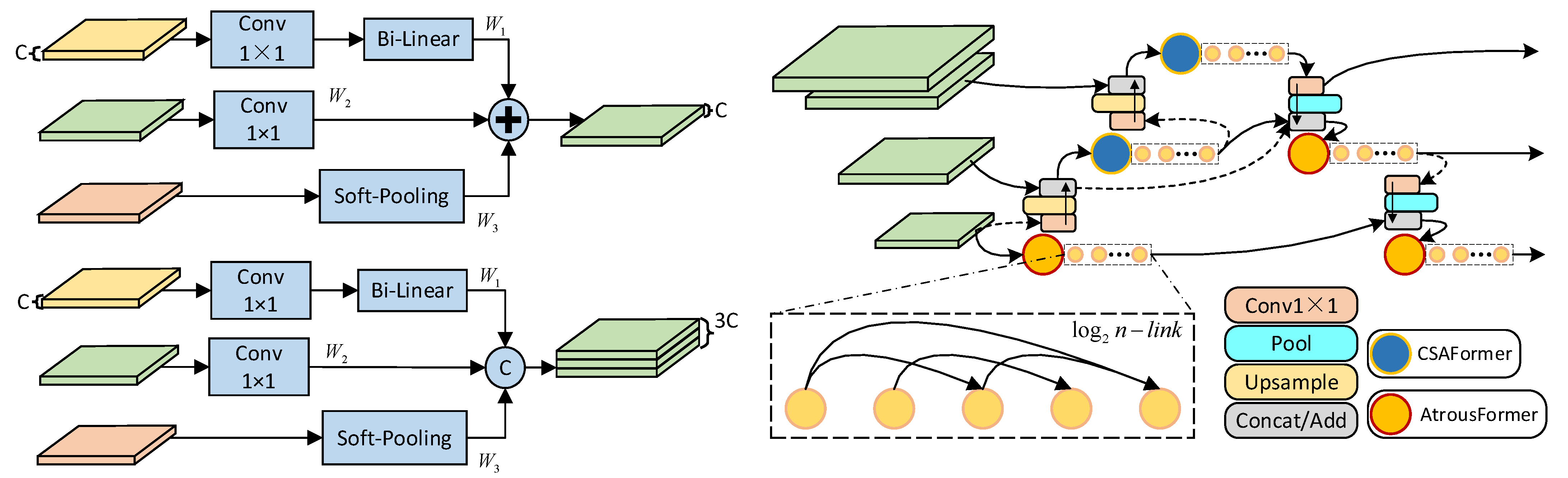
3. YOLOv5-lite Detection Framework with Multi-Scale Feature Fusion
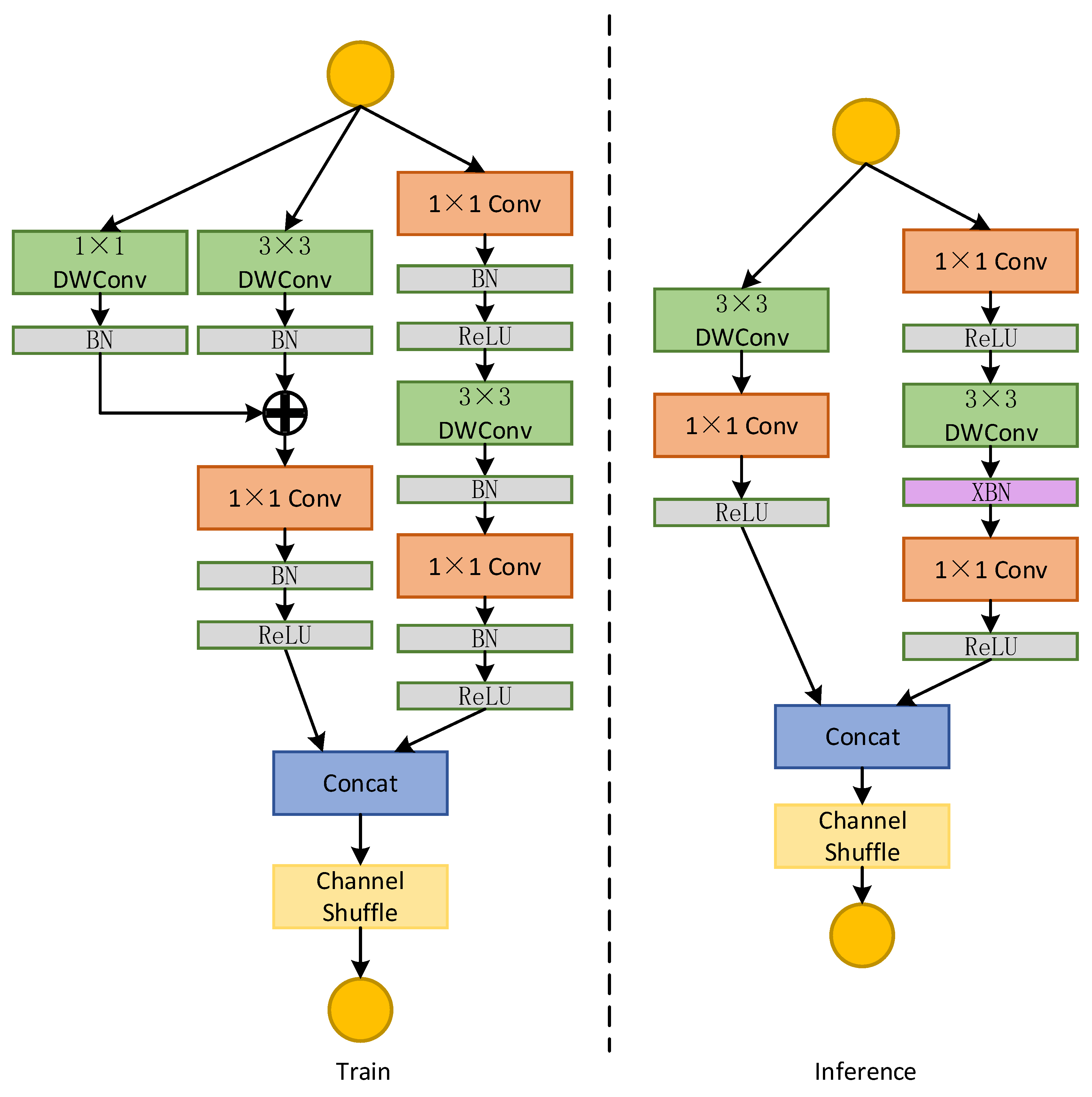
3.1. Backbone Network Design
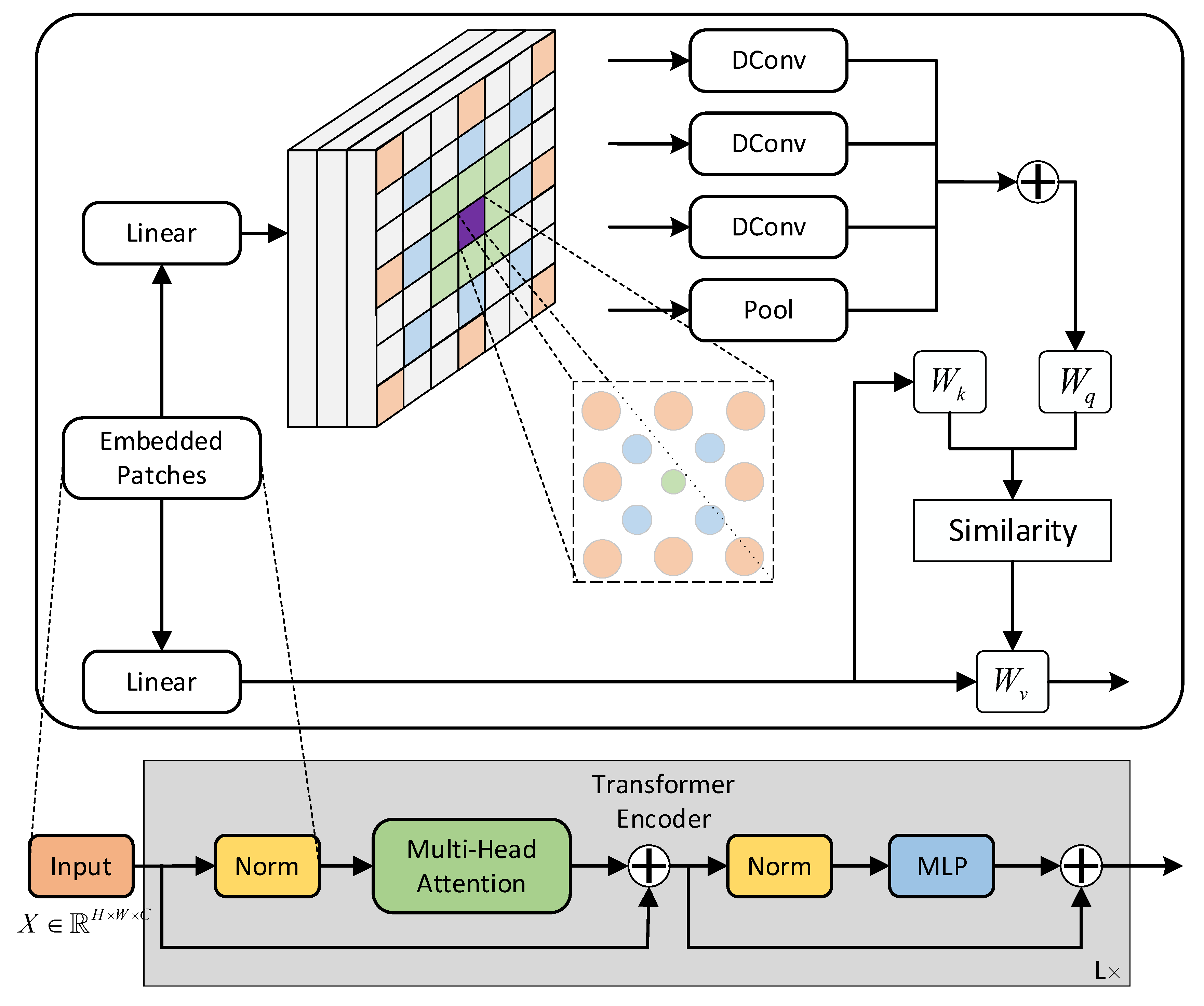
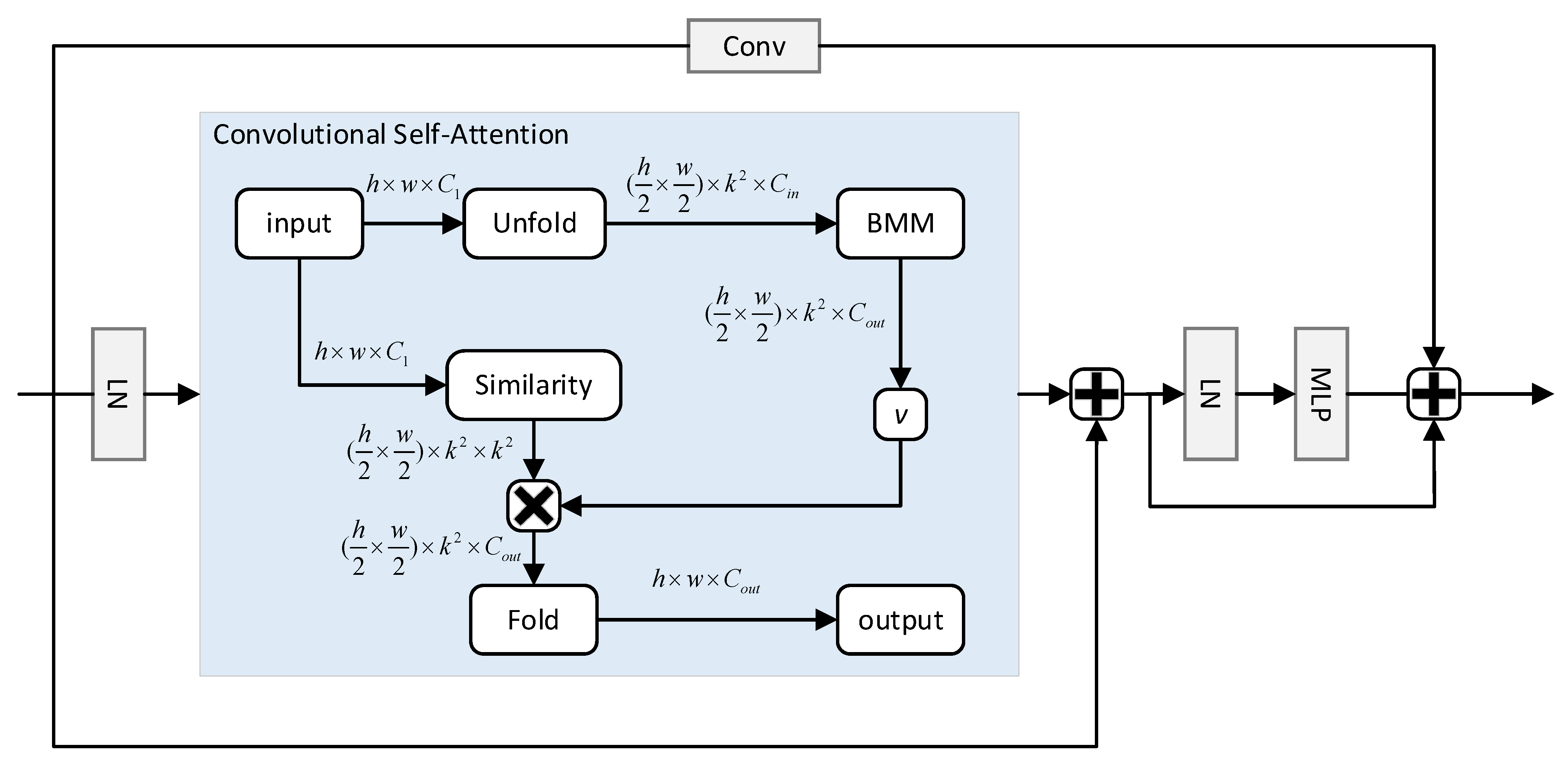
3.2. Transformer Modules Design
3.3. Multi-Scale Neck Structure Improvement
4. Experimental Verification and Analysis
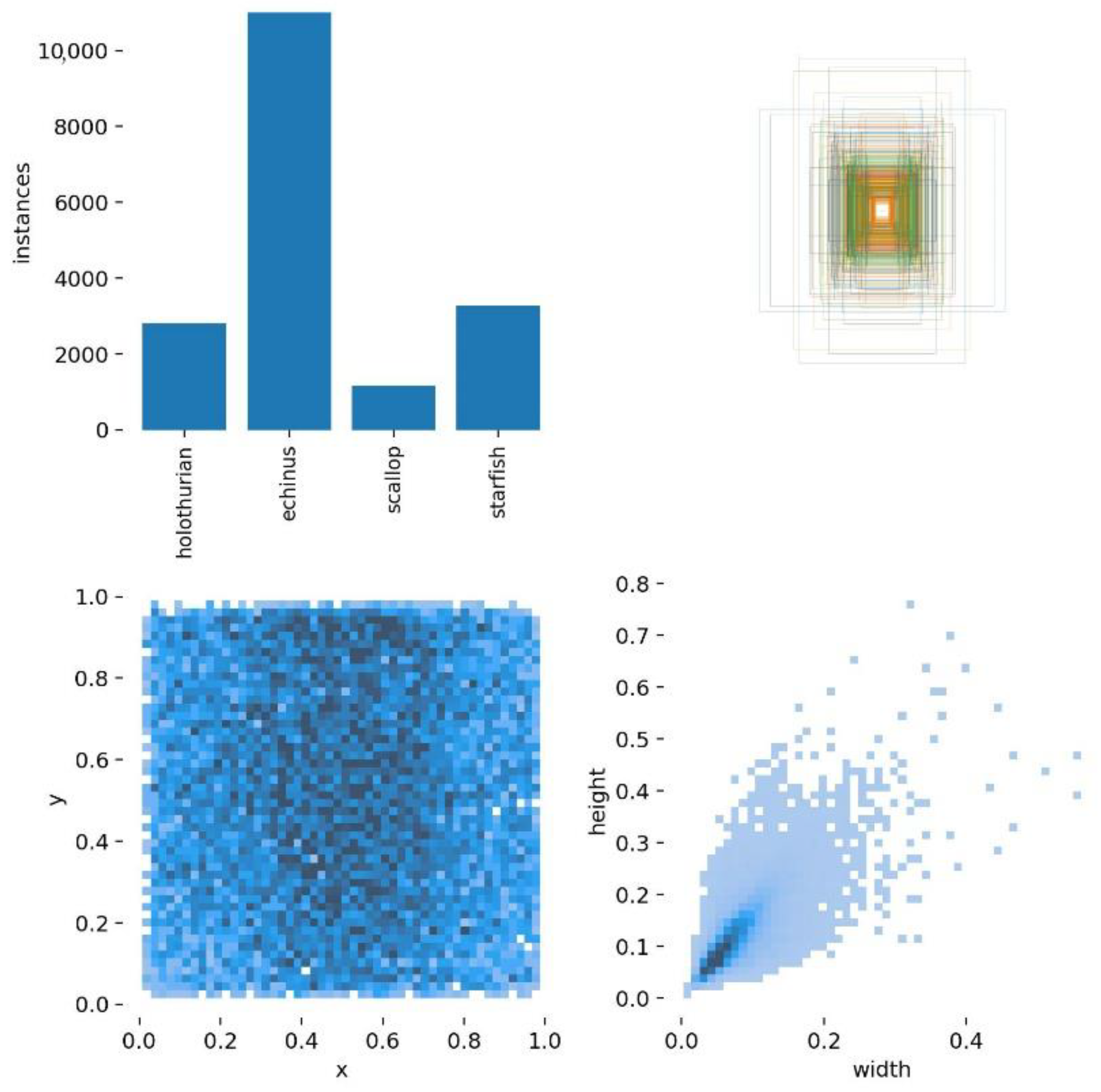
4.1. Experimental Data Set
4.2. Experimental Parameter Setting
4.3. Ablation Experiments
4.4. Intermediate Characteristics Analysis
4.5. Algorithm Comparison Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al Muksit, A.; Hasan, F.; Emon, M.F.H.B.; Haque, M.R.; Anwary, A.R.; Shatabda, S. YOLO-Fish: A robust fish detection model to detect fish in realistic underwater environment. Ecol. Inform. 2022, 72, 101847. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, T.; Guo, W.; Zhao, W.; Cai, L. Underwater occlusion object recognition with fusion of significant environmental features. J. Electron. Imaging 2022, 31, 023016. [Google Scholar] [CrossRef]
- Ntakolia, C.; Moustakidis, S.; Siouras, A. Autonomous path planning with obstacle avoidance for smart assistive systems. Expert Syst. Appl. 2023, 213, 119049. [Google Scholar] [CrossRef]
- Sun, Z.; Lv, Y. Underwater attached organisms intelligent detection based on an enhanced YOLO. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; pp. 1118–1122. [Google Scholar] [CrossRef]
- Yao, Y.; Qiu, Z.; Zhong, M. Application of improved MobileNet-SSD on underwater sea cucumber detection robot. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; Volume 1, pp. 402–407. [Google Scholar] [CrossRef]
- Wei, Q.; Chen, W. Underwater Object Detection of an UVMS Based on WGAN. In Proceedings of the 2021 China Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 702–707. [Google Scholar] [CrossRef]
- Hao, W.; Xiao, N. Research on Underwater Object Detection Based on Improved YOLOv4. In Proceedings of the 2021 8th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Beijing, China, 10–12 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 166–171. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Fan, X.; Lu, L.; Shi, P.; Zhang, X. A novel sonar target detection and classification algorithm. Multimed. Tools Appl. 2022, 81, 10091–10106. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural net-work for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distil-lation through attention. In Proceedings of the International Conference on Machine Learning, Online, 13–15 December 2021; pp. 10347–10357. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobileformer: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2, p. 6. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, L.; Zhou, Y.; Wang, T.; Luo, J.; Liu, X. Delving into the Estimation Shift of Batch Normalization in a Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 753–762. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Yang, C.; Wang, Y.; Zhang, J.; Zhang, H.; Wei, Z.; Lin, Z.; Yuille, A. Lite Vision Transformer with Enhanced Self-Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11988–11998. [Google Scholar] [CrossRef]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. GiraffeDet: A Heavy-Neck Paradigm for Object Detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10357–10366. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Locali-zation. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, T.; Si, J.; Wang, L.; Xu, C.; Yu, X. Automatic Detection of Underwater Small Targets Using Forward-Looking Sonar Images. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 4207912. [Google Scholar] [CrossRef]
- Pang, J.; Liu, W.; Liu, B.; Tao, D.; Zhang, K.; Lu, X. Interference Distillation for Underwater Fish Recognition. In Proceedings of the Asian Conference on Pattern Recognition, Macau SAR, China, 4–8 December 2022; pp. 62–74. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, F.; Wang, S.; Dong, J.; Li, N.; Ma, H.; Wang, X.; Zhou, H. SWIPENET: Object detection in noisy underwater scenes. Pattern Recognit. 2022, 132, 108926. [Google Scholar] [CrossRef]
- Paul, S.; Chen, P.Y. Vision transformers are robust learner. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 26–27 February 2022; Volume 36, pp. 2071–2081. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generalized-FPN | CSA Former | Arous Former | Soft Pool | mAP (%) | Total Parameters of the Model | Total Model Calculation (GFLOPS) |
|---|---|---|---|---|---|---|
| 73.8 | 5,574,845 | 16.2 | ||||
| ✓ | 74.1 | 5,640,642 | 16.3 | |||
| ✓ | 74.2 | 6,200,397 | 17.7 | |||
| ✓ | 76.3 | 11,561,597 | 17.8 | |||
| ✓ | ✓ | ✓ | 77.1 | 5,773,330 | 16.9 | |
| ✓ | ✓ | ✓ | ✓ | 77.5 | 5,740,690 | 19.7 |
| Method | Backbone | Size | mAP (%) | Parameters |
|---|---|---|---|---|
| SSD | VGG | 300 × 300 | 64.5 | 24,013,232 |
| RetinaNet | ResNet50 | 600 × 600 | 68.9 | 55,938,472 |
| YOLOv4 | DarkNet-CSP | 416 × 416 | 78.0 | 64,363,101 |
| YOLOv5s | DarkNet | 416 × 416 | 76.7 | 7,071,633 |
| YOLOv5l | DarkNet | 416 × 416 | 77.2 | 46,563,790 |
| YOLOv5s-lite | DarkNet | 416 × 416 | 70.1 | 1,649,853 |
| YOLOv5s-lite (our) | DarkNet | 416 × 416 | 73.4 | 1,432,930 |
| YOLOv5g-lite | DarkNet | 416 × 416 | 73.8 | 5,574,845 |
| YOLOv5g-lite (our) | DarkNet | 416 × 416 | 77.5 | 5,740,690 |
| Models | Average Test Time (ms) | fps |
|---|---|---|
| YOLOv5-lite-s-tran (*) | 32.0 | 30.98 |
| TPH-YOLO | 24.5 | 40.75 |
| YOLOv5-lite-g(ours) | 20.7 | 48.28 |
| YOLOv5-lite-s-tran | 18.6 | 53.58 |
| YOLOv5-lite-s(ours) | 18.4 | 54.39 |
| Models | AP | mAP | |||
|---|---|---|---|---|---|
| Holothurian | Echinus | Scallops | Starfish | ||
| YOLOv5-lite-s | 58.0 | 88.5 | 55.3 | 78.6 | 70. 1 |
| YOLOv5-lite-s(ours) | 64.0 | 91.5 | 57.2 | 80.7 | 73.4 |
| YOLOv5-lite-g | 65.2 | 90.2 | 60.0 | 79.8 | 73. 8 |
| YOLOv5-lite-g(ours) | 69.9 | 91.4 | 64.6 | 84.1 | 77.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Yang, Y.; Wang, Z.; Zhang, J.; Zhou, S.; Wu, L. Underwater Target Detection Lightweight Algorithm Based on Multi-Scale Feature Fusion. J. Mar. Sci. Eng. 2023, 11, 320. https://doi.org/10.3390/jmse11020320
Chen L, Yang Y, Wang Z, Zhang J, Zhou S, Wu L. Underwater Target Detection Lightweight Algorithm Based on Multi-Scale Feature Fusion. Journal of Marine Science and Engineering. 2023; 11(2):320. https://doi.org/10.3390/jmse11020320
Chicago/Turabian StyleChen, Liang, Yuyi Yang, Zhenheng Wang, Jian Zhang, Shaowu Zhou, and Lianghong Wu. 2023. "Underwater Target Detection Lightweight Algorithm Based on Multi-Scale Feature Fusion" Journal of Marine Science and Engineering 11, no. 2: 320. https://doi.org/10.3390/jmse11020320