

Lightweight Underwater Target Detection Algorithm Based on Dynamic Sampling Transformer and Knowledge-Distillation Optimization

Abstract
:1. Introduction
- (1)
- A lightweight Transformer module with dynamic sampling is proposed, revealing the importance of the Transformer sparse sampling dynamic transformation in an underwater environment.
- (2)
- A knowledge-distillation framework for decoupling localization and recognition information applicable to YOLO is integrated, and the effectiveness of this detection algorithm is analyzed.
- (3)
- The training cost of decoupled distillation of localization and recognition information is investigated by experimental comparison, and the effectiveness of this paper’s algorithm is verified by comparison with other mainstream detection algorithms.
2. Related Work
2.1. Target Detection Models
2.2. YOLO-Lite Detection Algorithms
2.3. Knowledge Distillation Strategy
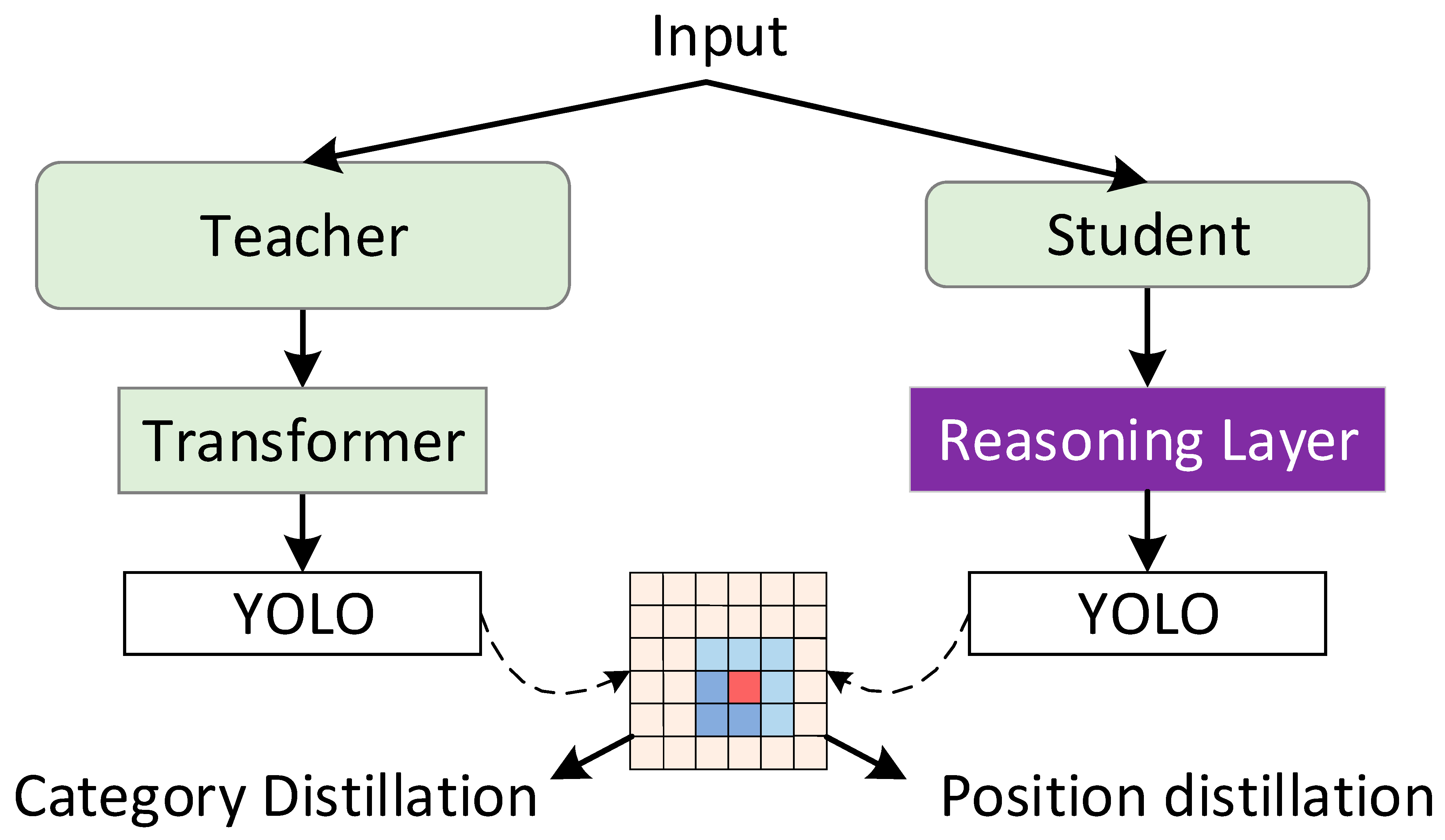
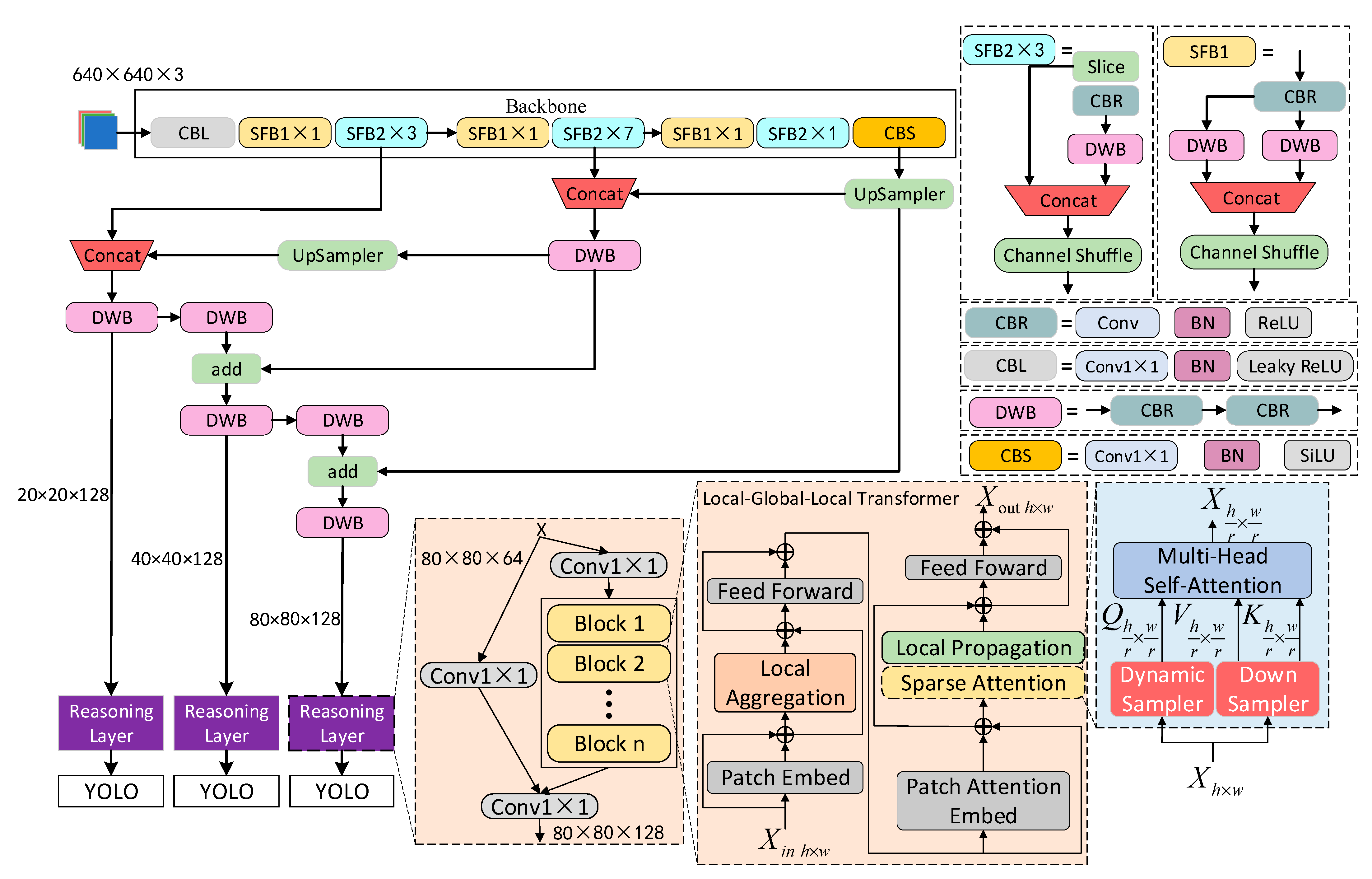
3. Proposed Method
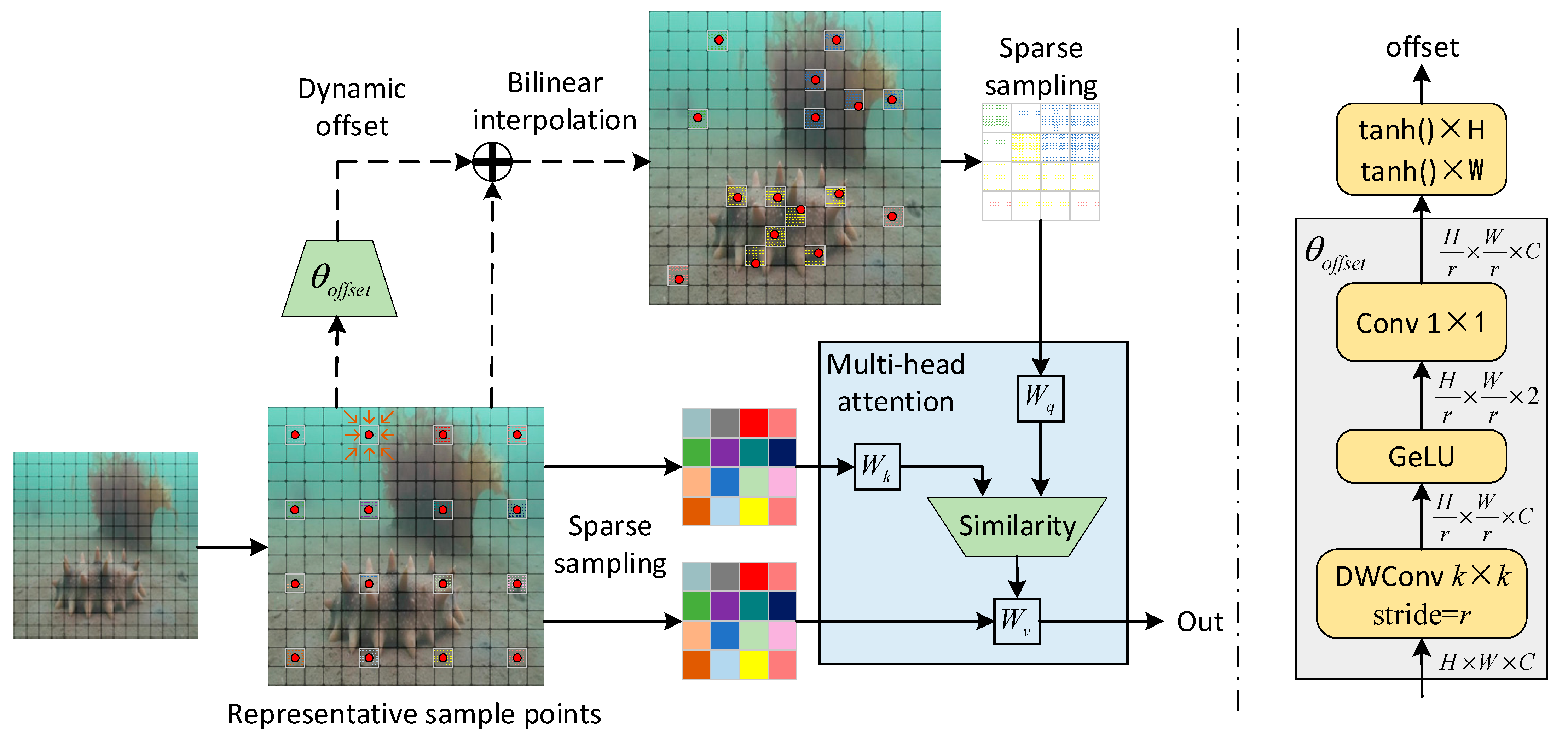
3.1. Dynamic Sampling Transformer
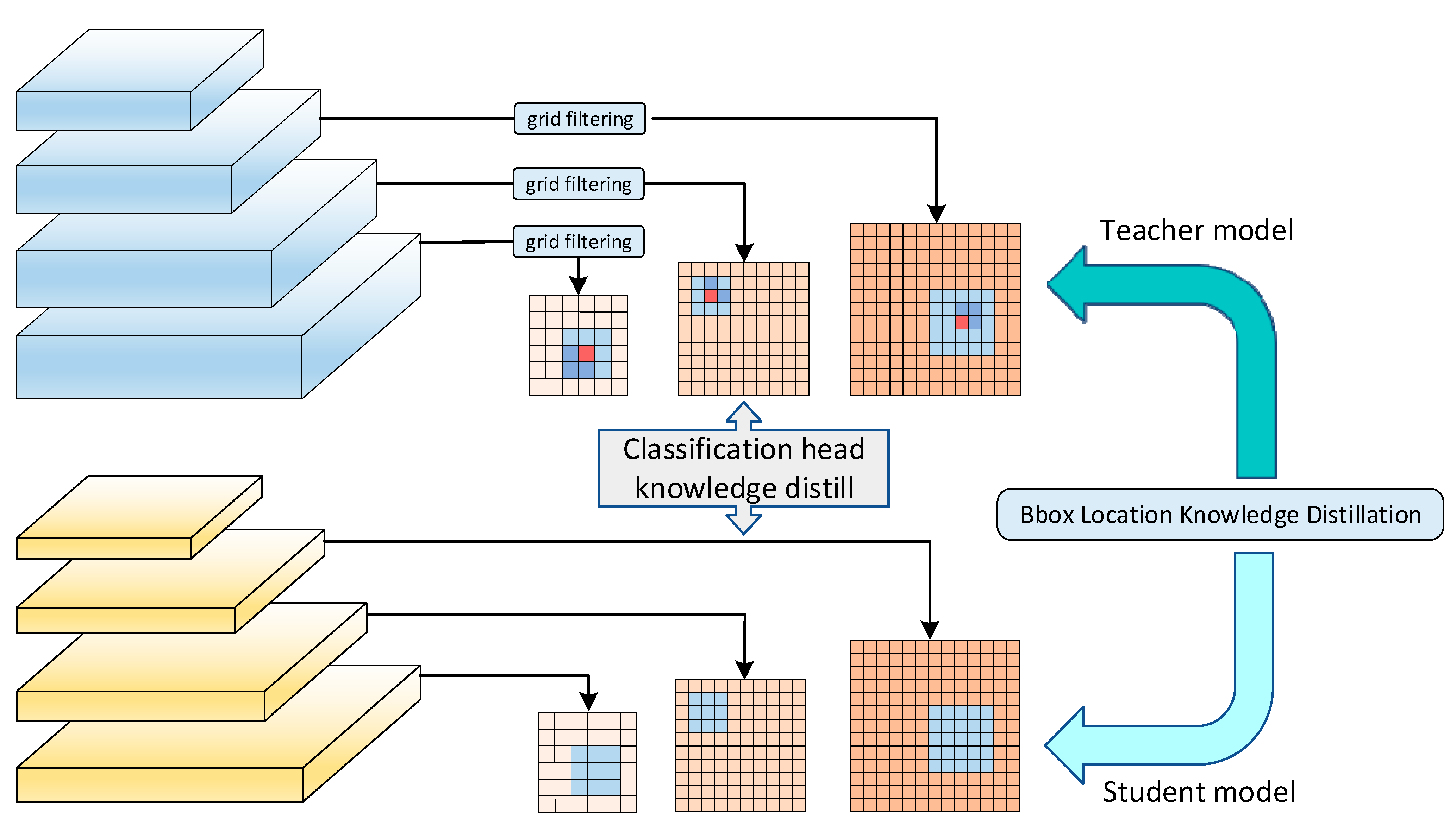
3.2. Positioning Distillation
| Algorithm 1 The grid-filtering algorithm |
| Input: A set of anchor boxes and a set of ground truth boxes . Positive threshold of label assignment. and is the size of f-th Feature layer output. J is the number of ground truth boxes. Output: encodes final position index of the grids, where is the number of pre-set anchor boxes and represents the fields of the center grid. 1: Compute and 2: 3: Filter the positioning grid with indices of 4: return |
4. Experimental Verification and Analysis
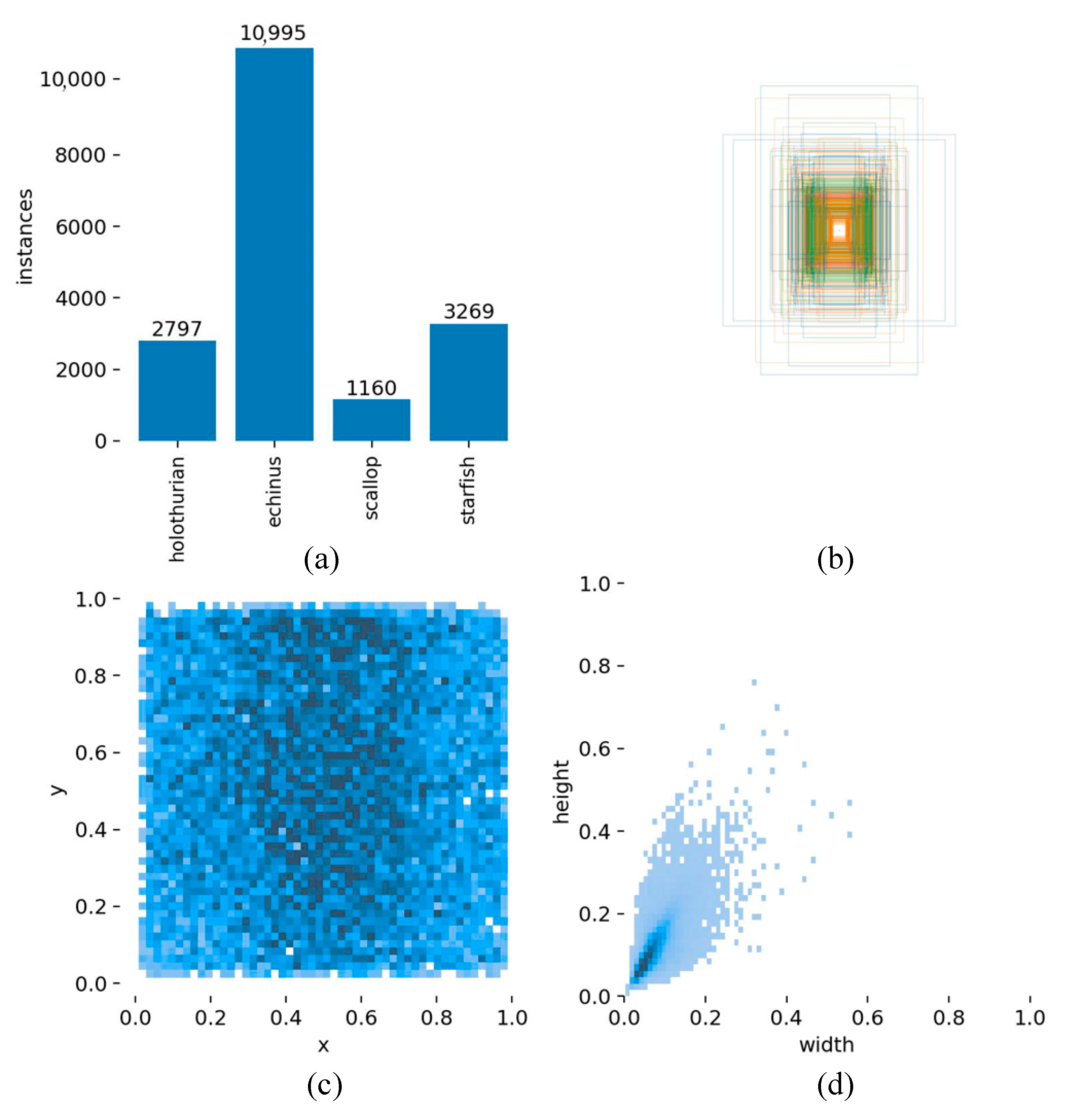
4.1. Experimental Dataset
4.2. Implementation Details
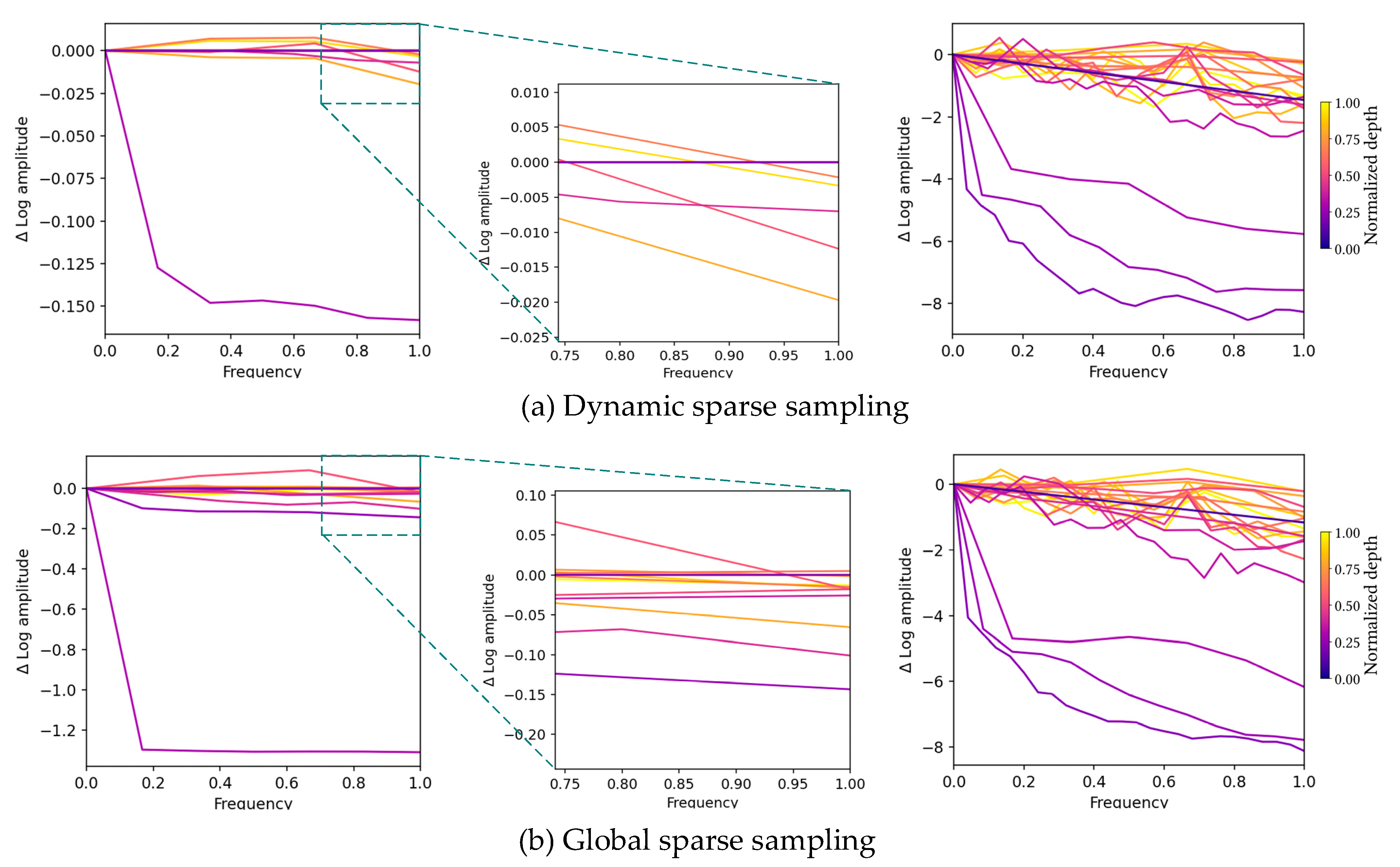
4.3. Dynamic Sampling Branch Analysis
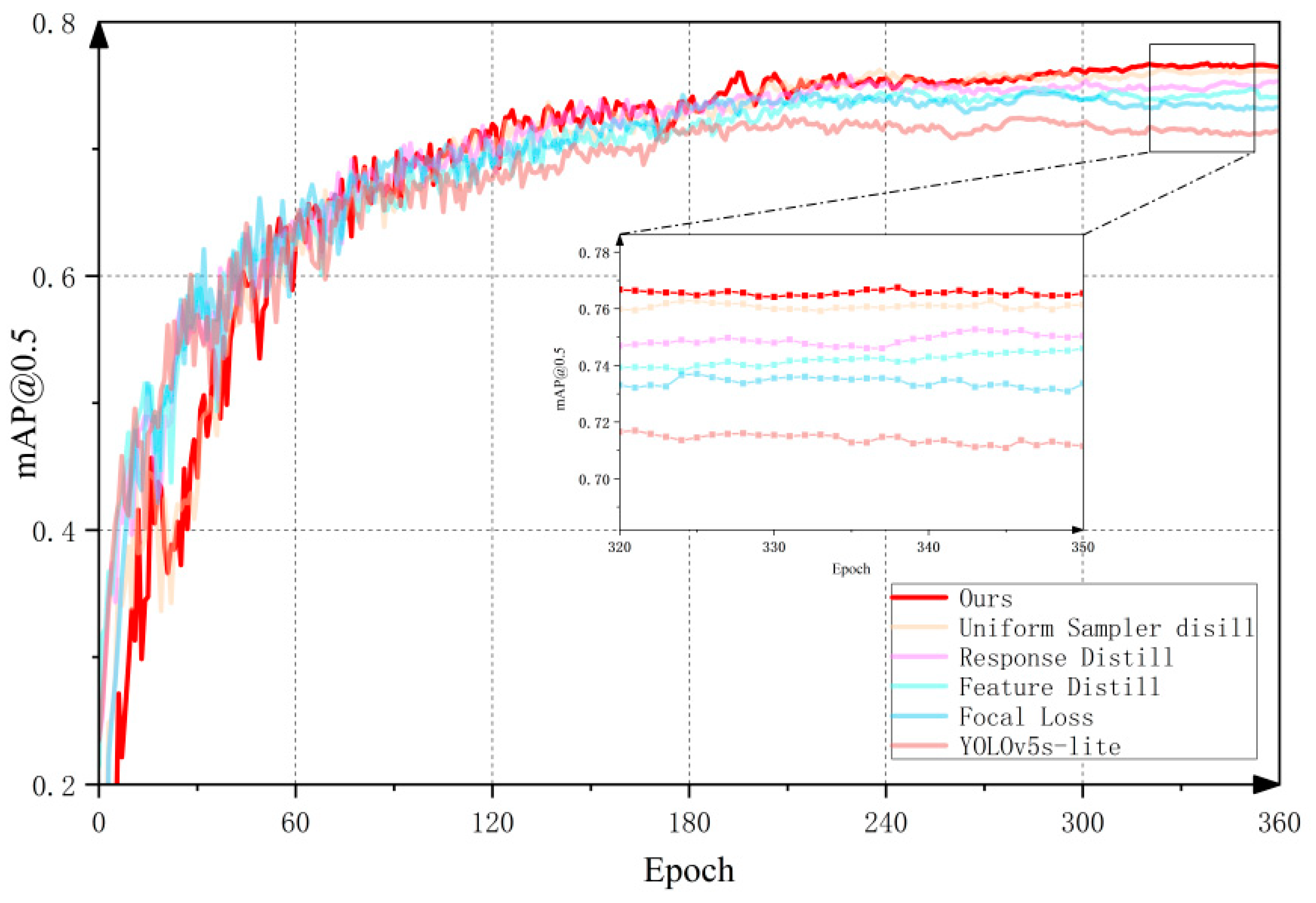
4.4. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, T.; Si, J.; Wang, L.; Xu, C.; Yu, X. Automatic Detection of Underwater Small Targets Using Forward-Looking Sonar Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4207912. [Google Scholar] [CrossRef]
- Wan, Z.; Zhang, L.; Huang, H.; Yang, X. GSDCN: A Customized Two-Stage Neural Network for Benthonic Organism Detection. In The Neural Information Processing; Springer: Cham, Switzerland, 2020; pp. 811–820. [Google Scholar]
- Zhou, J.; Yao, J.; Zhang, W.; Zhang, D. Multi-scale retinex-based adaptive gray-scale transformation method for underwater image enhancement. Multimedia Tools Appl. 2022, 81, 1811–1831. [Google Scholar] [CrossRef]
- Liu, P.; Hongbo, Y.; Hu, Y.; Fu, J. Research on target recognition of underwater robot. In Proceedings of the 2018 IEEE International Conference on Advanced Manufacturing (ICAM), Yunlin, Taiwan, 16–18 November 2018; pp. 463–466. [Google Scholar]
- Sarkar, P.; De, S.; Gurung, S. A Survey on Underwater Object Detection. In Intelligence Enabled Research: DoSIER; Springer: Singapore, 2021; pp. 91–104. [Google Scholar]
- Chen, L.; Zhou, F.; Wang, S.; Dong, J.; Li, N.; Ma, H.; Wang, X.; Zhou, H. SWIPENET: Object detection in noisy underwater scenes. Pattern Recognit. 2022, 132, 108926. [Google Scholar] [CrossRef]
- Zhang, X.; Fang, X.; Pan, M.; Yuan, L.; Zhang, Y.; Yuan, M.; Lv, S.; Yu, H. A Marine Organism Detection Framework Based on the Joint Optimization of Image Enhancement and Object Detection. Sensors 2021, 21, 7205. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; He, X.; Shao, F.; Lu, G.; Jiang, Q.; Hu, R.; Li, J. A Novel Attention-Based Lightweight Network for Multiscale Object Detection in Underwater Images. J. Sens. 2022, 2022, 2582687. [Google Scholar] [CrossRef]
- Feng, H.; Xu, L.; Yin, X.; Chen, Z. Underwater salient object detection based on red channel correction. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 446–449. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural, Barcelona, Spain, 5–10 December 2016. [Google Scholar] [CrossRef]
- Xu, F.; Wang, H.; Peng, J.; Fu, X. Scale-aware feature pyramid architecture for marine object detection. Neural Comput. Appl. 2021, 33, 3637–3653. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar] [CrossRef] [Green Version]
- Aksoy, T.; Halici, U. Analysis of visual reasoning on one-stage object detection. arXiv 2022, arXiv:2202.13115. [Google Scholar] [CrossRef]
- Zhu, H.; Xie, Y.; Huang, H.; Jing, C.; Rong, Y.; Wang, C. DB-YOLO: A Duplicate Bilateral YOLO Network for Multi-Scale Ship Detection in SAR Images. Sensors 2021, 21, 8146. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.H.; Zhong, J.X.; Liu, S.; Li, T.; Li, G. ROIMIX: Proposal-Fusion Among Multiple Images for Underwater Object Detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar]
- Jiang, L.; Wang, Y.; Jia, Q.; Xu, S.; Liu, Y.; Fan, X.; Wang, R. Underwater Species Detection using Channel Sharpening Attention. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4259–4267. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. Multimed. Tools Appl. 2021, 80, 4037–4051. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 2017, 30, 742–751. [Google Scholar]
- Dai, X.; Jiang, Z.; Wu, Z.; Bao, Y.; Wang, Z.; Liu, S.; Zhou, E. General instance distillation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar] [CrossRef]
- Pang, J.; Liu, W.; Liu, B.; Tao, D.; Zhang, K.; Lu, X. Interference Distillation for Underwater Fish Recognition. In Proceedings of the 6th Asian Conference on Pattern Recognition, Jeju, Republic of Korea, 9–12 November 2021; pp. 62–74. [Google Scholar]
- Zheng, Z.; Ye, R.; Hou, Q.; Ren, D.; Wang, P.; Zuo, W.; Cheng, M.-M. Localization distillation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9397–9406. [Google Scholar]
- Ji, W.; Peng, J.; Xu, B.; Zhang, T. Real-time detection of underwater river crab based on multi-scale pyramid fusion image enhancement and MobileCenterNet model. Comput. Electron. Agric. 2023, 204, 107522. [Google Scholar] [CrossRef]
- Han, Y.; Chen, L.; Luo, Y.; Ai, H.; Hong, Z.; Ma, Z.; Wang, J.; Zhou, R.; Zhang, Y. Underwater Holothurian Target-Detection Algorithm Based on Improved CenterNet and Scene Feature Fusion. Sensors 2022, 22, 7204. [Google Scholar] [CrossRef] [PubMed]
- Huang, A.; Zhong, G.; Li, H.; Choi, D. Underwater Object Detection Using Restructured SSD. In Proceedings of the CAAI International Conference on Artificial Intelligence, Beijing, China, 27–28 August 2022; pp. 526–537. [Google Scholar]
- Dinakaran, R.; Zhang, L.; Li, C.-T.; Bouridane, A.; Jiang, R. Robust and Fair Undersea Target Detection with Automated Underwater Vehicles for Biodiversity Data Collection. Remote Sens. 2022, 14, 3680. [Google Scholar] [CrossRef]
- Wang, X.; Lin, J.; Zhao, J.; Yang, X.; Yan, J. EAutoDet: Efficient Architecture Search for Object Detection. In European Conference on Computer Vision, Glasgow, UK, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 668–684. [Google Scholar]
- Bancud, G.E.; Labanon, A.J.; Abreo, N.A.; Kobayashi, V. Combining Image Enhancement Techniques and Deep Learning for Shallow Water Benthic Marine Litter Detection. In Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; Springer Nature: Cham, Switzerland, 2023; pp. 137–149. [Google Scholar] [CrossRef]
- Chen, L.; Yang, Y.; Wang, Z.; Zhang, J.; Zhou, S.; Wu, L. Underwater Target Detection Lightweight Algorithm Based on Multi-Scale Feature Fusion. J. Mar. Sci. Eng. 2023, 11, 320. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuang, Y.; Jia, P.; Wu, C.; Xu, H.; Liu, Z. A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline. J. Mar. Sci. Eng. 2022, 10, 1204. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wang, Y.; Wu, H.; Chen, X.; Xu, C.; Xu, C. Distilling object detectors via decoupled features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, Z.; Cheng, Z.; Lu, J.; Xu, Y.; Niu, Y.; He, F. Distilling Object Detectors with Global Knowledge. In European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 422–438. [Google Scholar]
- Yang, C.; Ochal, M.; Storkey, A.J.; Crowley, E.J. Prediction-Guided Distillation for Dense Object Detection. In European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 123–138. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), Montreal, QC, Canada, 11 October 2021; pp. 122–138. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Martinez, B. EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 294–311. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, X.; Cheng, S.; Anguelov, D. PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar] [CrossRef]
- Park, N.; Kim, S. How Do Vision Transformers Work? In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Knowledge Types | Knowledge Sources |
|---|---|---|
| DeFeat [34] | FPN Features | Hint layer |
| RDM [35] | Prototype Generation Module Features | TS-Space |
| PGD [36] | Key Predictive Regions | Hint layer |
| CWD [37] | Channel Distribution | Hint layer |
| Method | mAP | Param (M) | Inference Memory (Batch = 4) | GFLOPs |
|---|---|---|---|---|
| Original Network | 72.5 | 1.57 | 2138 MB | 4.0 |
| Reason-Transformer | 74.3 | 2.14 | 4622 MB | 4.5 |
| Uniform sparse sampling | 73.6 | 2.10 | 2510 MB | 4.8 |
| Dynamic sparse sampling | 74.1 | 2.10 | 2522 MB | 4.9 |
| Center Point | Grid Filter 4 Neighborhoods | Grid Filter 8 Neighborhoods | Direct Response Distillation | Feature Map Distillation | mAP |
|---|---|---|---|---|---|
| - | - | - | - | - | 72.5 |
| ✓ | - | - | - | - | 73.8 |
| - | ✓ | - | - | - | 74.2 |
| - | - | ✓ | - | - | 74.2 |
| - | - | - | ✓ | - | 73.5 |
| - | - | - | - | ✓ | 74.3 |
| - | ✓ | - | - | ✓ | 74.3 |
| Class-Loss | Class 1 | Class 2 | Class 3 | Class 4 |
|---|---|---|---|---|
| AP | ||||
| CE | 61.2 | 90.6 | 65.2 | 80.2 |
| Focal | 62.7 | 90.6 | 64.4 | 80.9 |
| Ploy | 63.5 | 88.7 | 64.2 | 80.8 |
| Ploy-distill | 67.8 | 90.9 | 66.9 | 81.2 |
| Method | Time Spent in Detection (ms) | Size | mAP | Parameters (M) |
|---|---|---|---|---|
| Faster RCNN (Vgg) | 35.7 | 300 × 300 | 67.4 | 134.7 |
| Faster RCNN (Resnet) | - | 512 × 512 | 73.2 | - |
| SA-FPN | - | 1280 × 768 | 75.3 | - |
| R-FCN | 25.2 | 1000 × 600 | 75.2 | 31.9 |
| MobileNet-SSD | - | 300 × 300 | 61.2 | 5.50 |
| SSD | 21.2 | 300 × 300 | 64.5 | 24.2 |
| RetinaNet | - | 600 × 600 | 68.9 | 53.3 |
| CenterNet | 21.8 | 512 × 512 | 73.57 | 32.69 |
| YOLOv4 | 22.8 | 416 × 416 | 78.0 | 61.38 |
| YOLOv7 | 21.4 | 416 × 416 | 79.1 | 36.9 |
| YOLOv7-tiny | 21.2 | 416 × 416 | 77.9 | 6.2 |
| YOLOv5s | 20.7 | 416 × 416 | 76.7 | 6.74 |
| YOLOv5l | 21.7 | 416 × 416 | 77.2 | 44.40 |
| YOLOv5s-lite | 20.5 | 416 × 416 | 70.1 | 1.57 |
| YOLOv5s-lite (ours) | 20.7 | 416 × 416 | 76.7 | 2.10 |
| YOLOv5g-lite | 20.6 | 416 × 416 | 73.8 | 5.32 |
| YOLOv5g-lite (ours) | 21.0 | 416 × 416 | 78.8 | 5.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Yang, Y.; Wang, Z.; Zhang, J.; Zhou, S.; Wu, L. Lightweight Underwater Target Detection Algorithm Based on Dynamic Sampling Transformer and Knowledge-Distillation Optimization. J. Mar. Sci. Eng. 2023, 11, 426. https://doi.org/10.3390/jmse11020426
Chen L, Yang Y, Wang Z, Zhang J, Zhou S, Wu L. Lightweight Underwater Target Detection Algorithm Based on Dynamic Sampling Transformer and Knowledge-Distillation Optimization. Journal of Marine Science and Engineering. 2023; 11(2):426. https://doi.org/10.3390/jmse11020426
Chicago/Turabian StyleChen, Liang, Yuyi Yang, Zhenheng Wang, Jian Zhang, Shaowu Zhou, and Lianghong Wu. 2023. "Lightweight Underwater Target Detection Algorithm Based on Dynamic Sampling Transformer and Knowledge-Distillation Optimization" Journal of Marine Science and Engineering 11, no. 2: 426. https://doi.org/10.3390/jmse11020426