4.2. Prediction Results Using Source Dataset (the Base DNN Model)
The results of the grid search cross-validation for hyperparameter optimization of the DNN model using a total of 690 source data (1000 TEU) are presented in
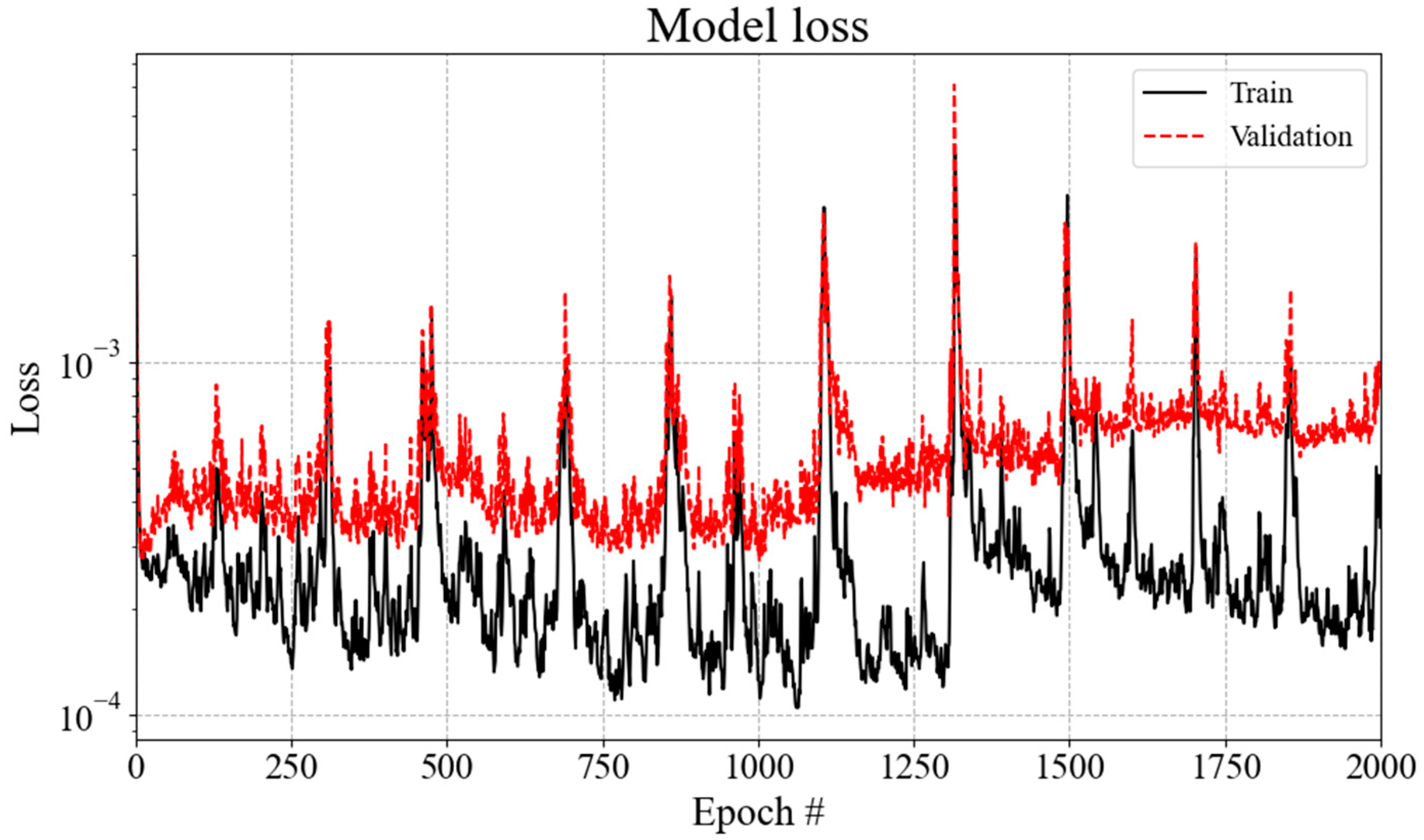
Figure 9. The mean squared error (MSE) was used to assess the prediction accuracy for each hyperparameter. In this study, three hyperparameters were optimized, and the optimal values for each parameter are as follows; (1) batch size: (4, 8, 16, 32, 64, 128), (2) epochs: (100, 500, 1000, 2000, 3000) and (3) learning rate: (0.001, 0.005, 0.01, 0.05, 0.1). The final hyperparameters determined for the base DNN model were chosen based on the consideration of a small mean squared error value while considering the training speed. The training hyperparameters for the base DNN model were set as follows: batch size = 64, epochs = 2000, and learning rate = 0.01. Using this combination of selected hyperparameters, the model was trained for a total of 18,000 iterations on the 1000 TEU containership dataset. The prediction accuracy of the base DNN training model is quantified by an MSE of approximately 0.0008, as shown in
Figure 10. The peak of the loss typically occurs during mini-batch training with split data.
The prediction accuracy for the test dataset not used during training was evaluated to validate the learning level of the base DNN model.
Table 6 presents the evaluation metrics for the test dataset of the source data, which is the 1000 TEU containership. MSE and MAPE indicate higher prediction accuracy as their values become smaller, and an
value closer to 1 signifies that the test dataset not used in training is being well predicted. The DNN model can accurately predict viscous resistance and wake distribution in the propeller plane, as evidenced by the high level of accuracy.
Figure 11 displays the predicted viscous resistance results for the two above-mentioned test cases. The average error of the viscous resistance coefficient of model
is significantly small, being
, which is less than 0.005% of the target value.
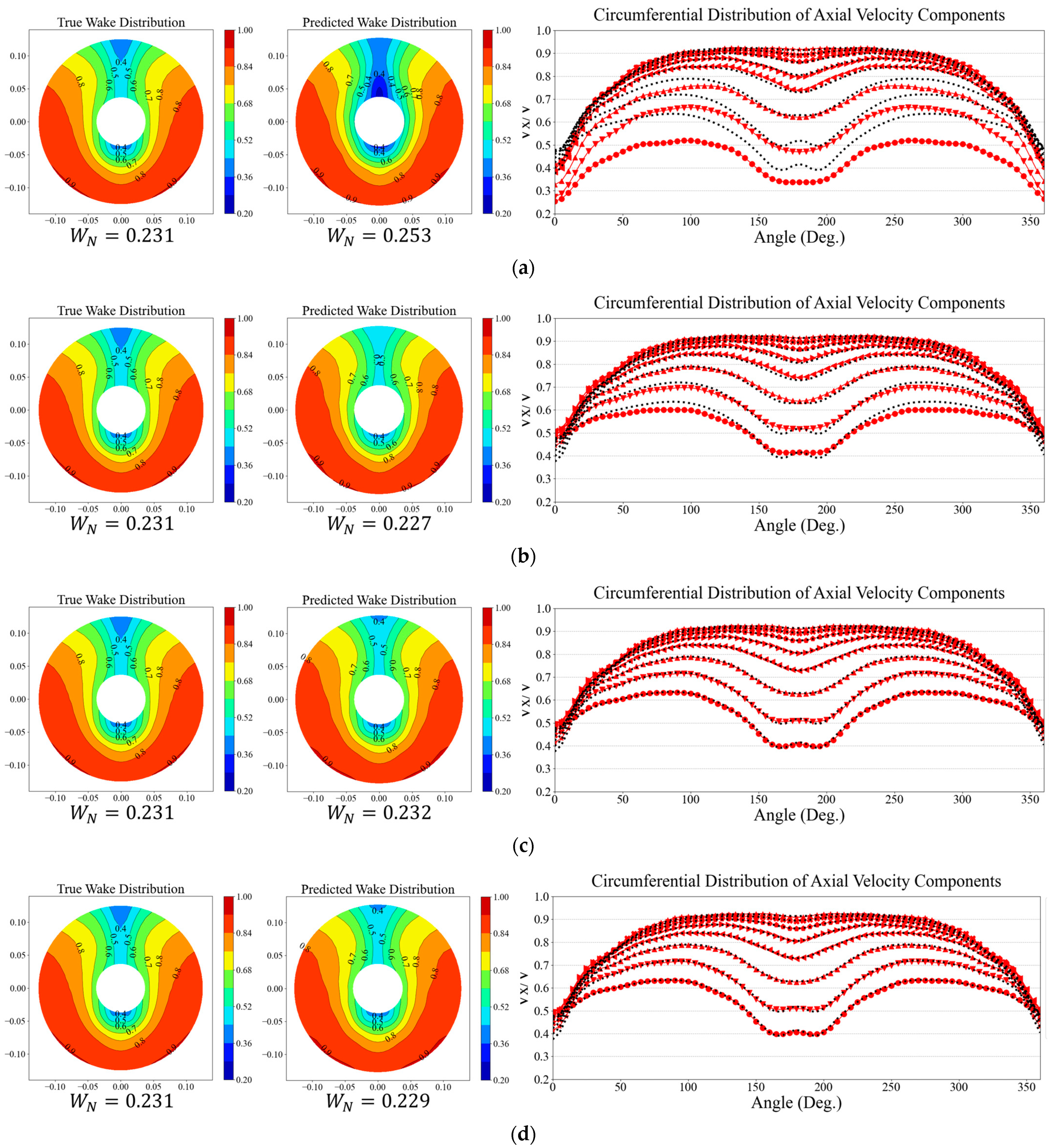
Figure 12 compares the true data obtained from CFD analysis with the results predicted by the DNN. The true wake distribution is given on the left, and the predicted data are shown on the right. The true data for the circumferential distribution of the axial velocity component are depicted as black dashed lines, while the predicted data are represented by red symbols and solid lines. As observed in
Figure 12, the true and predicted data closely match with high accuracy. In addition, the predicted nominal wake fractions
are different from the true values only by less than 0.001, which corresponds to 0.39% error. Here, the nominal wake fraction is computed as follows:
Circumferential mean velocity of each component,
is the averaged value of the velocity at the corresponding radius and can be calculated as:
Total nominal mean velocity is obtained from the value of circumferential axial mean velocity between radius of propeller hub,
and radius of the propeller,
at the propeller plane and computed as follows:
This further leads to the calculation of the nominal wake fraction
as follows:
The DNN model is capable of accurately predicting not only wake distribution but also viscosity resistance. The neural network that serves as the basis for transfer learning on a small amount of data requires sufficient prediction accuracy. Given the results above, it can be concluded that the base DNN model can effectively capture the design variables of the FCF and establish a strong association with both the viscous resistance coefficient and wake distribution, demonstrating high accuracy in its predictions.
4.3. Prediction Results Using Target Dataset (DNN-TL Model)
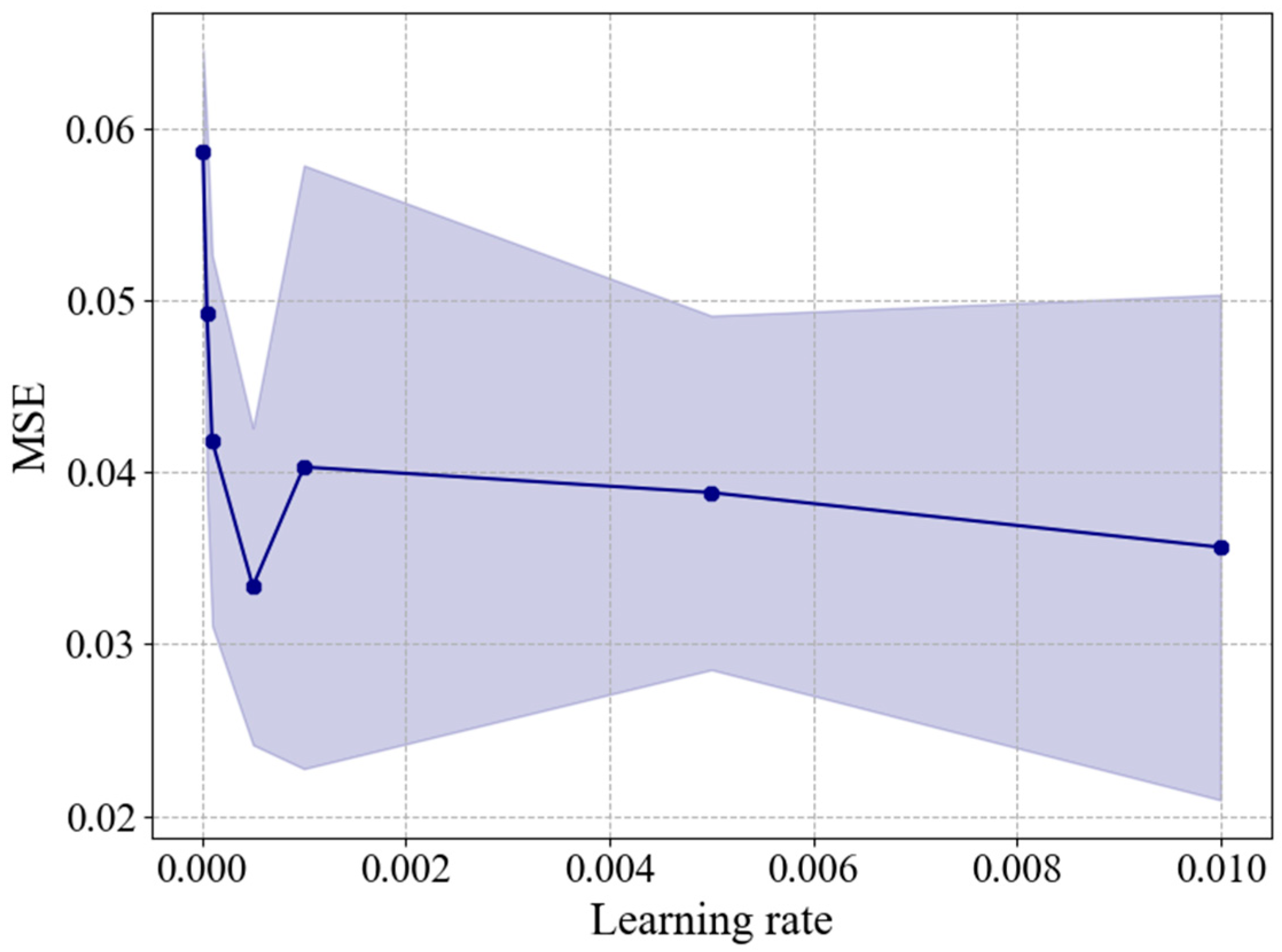
The DNN-TL model is reconstructed and retrained based on the weights of the previously trained DNN model, using only the target dataset. Since the size of the target dataset is considerably smaller (150 datasets) compared to the source dataset, a smaller learning rate is necessary to ensure training accuracy. Therefore, it is necessary to find the optimal learning rate value for the training dataset of the DNN-TL model. The optimization was performed with learning rates (0.00001, 0.00005, 0.0001, 0.0005, 0.001, 0.005, 0.01), and the comparison of MSE values for each value is shown in
Figure 13. In this study, the optimal learning rate value for predicting the viscous resistance and wake distribution of the target dataset (2500 TEU and 3600 TEU) is determined to be 0.0005. Based on this, the parameters of the DNN-TL model were constructed. To verify the prediction of viscous resistance and wake distribution based on transfer learning, different configurations were tested: DNN-TL models with 1, 4, and 5 fixed layers, as well as a DNN-TL model without any fixed layers (
Table 7). Fine-tuning was performed on each of these configurations, and their performances were compared. In the DNN-TL model, the weights of neurons are initialized based on the previously trained base model, and the model is retrained and reconstructed using the training dataset from the target dataset.
The prediction accuracy based on the fine-tuning of hidden layer weights was evaluated to verify the level of learning.
Figure 14 compares the predicted viscous resistance coefficients of the model ship for each fine-tuning condition. The black-filled bar chart represents the true values obtained from CFD analysis, while the red dashed-filled bars represent the predicted results from each fine-tuning condition. The viscosity resistance performance was compared using one test dataset for each of the 2500 TEU and 3600 TEU containerships.
Figure 15 and
Figure 16 illustrate the comparison of predicted results for harmonic wake distribution and circumferential distribution of axial velocity components for both 2500 TEU and 3600 TEU. The left figure shows the harmonic wake distribution obtained from CFD analysis, and the middle part displays the predicted wake distribution from each fine-tuning condition. In the case where the weights of all five hidden layers are fixed (the all fixed layer case), there is an error of 18% specifically in the viscosity resistance coefficient (
) for the 3600 TEU containership. The accuracy of predicting the axial velocity distribution in the propeller plane is also quite low, and it can be observed that it is trying to follow the wake distribution characteristics of the 1000 TEU used in the base DNN model. In the case of “Fixed 4 layer”, where only the weights of the last layer among the layers were trained,
for 2500 TEU and 3600 TEU show errors of 0.38% and −3.6%, respectively. This indicates an improvement in prediction accuracy compared to the “All fixed layer” case. In
Figure 15b and
Figure 16b, compared to the “All fixed layer”, there is an attempt to capture the characteristics of each hull form. This indicates that the weights of the last hidden layer among the hidden layers play a role in conveying a certain level of knowledge about the target datasets (2500 TEU and 3600 TEU). The prediction results for the fixed 1 layer, where only the weights of the first hidden layer are not retrained, and the no fixed layer, where all layers are retrained, show a quite similar trend. The
prediction results for both 2500 TEU and 3600 TEU exhibit errors within 0.5%. When observing the wake distribution and axial velocity components figures, it is evident that the characteristics of each linear component are sufficiently captured. Furthermore, the errors in the nominal wake fraction
between the TL predictions and the true values are 0.0 for the 2500 TEU (
Figure 15c) and 0.001 (
Figure 16c), which amounts to 0% and 0.43%, respectively. This exemplifies the accuracy of the present TL prediction in wake field prediction.
Table 8 presents the prediction accuracy metrics for the test dataset that was not used in the training process under each fine-tuning condition. MSE and MAPE are metrics where lower values indicate higher accuracy in predictions.
, on the other hand, is a measure of how well the model explains the variance in the data. A higher
value, closer to 1, indicates a better predictive performance. Generally, when
, it is considered to have a reasonably good predictive accuracy, while
indicates moderate predictive performance, and
suggests poor predictive performance [
21]. The
score for the “All fixed layer” case is −4.163, indicating no prediction capability on the test dataset. Conversely, when the first hidden layer is fixed, it exhibits the highest scores across all accuracy metrics. It is considered that the weights of the first layer in the previously trained base DNN model were tailored to capture the characteristics of the viscous resistance coefficient on the containership and the axial velocity on the propeller plane. The remaining hidden layers seem to have been designed to understand the fluid characteristics by hull form. To assess the level of prediction accuracy in this study, the performance was compared to accuracy metrics from other literature that used transfer learning for predictions. Solis and Calvo-Valverde [
22] applied DNN and TL to time series prediction, and their optimal prediction model achieved an MAPE value of approximately 9%. Zhou et al. [
23] predicted the dynamic behavior of a gas turbine engine using transfer learning, and in their optimal prediction model, they achieved MSE and
values of 0.00466 and 0.881, respectively. The MSE, MAPE, and
values in this paper all fall within a similar range, indicating that the prediction model applied with transfer learning is at a satisfactory level of accuracy.
Figure 17 compares the predicted radial profiles of axial velocity components from the four tuning cases with their true values. The green circles represent the predictions from the “All fixed layer” condition, the black squares are from the case where the first four layers were fixed (fixed 4 layer), the blue triangles represent the condition where only the first layer was fixed (fixed 1 layer), and the red “X” symbols depict the predictions from the “No fixed layer” condition. In the case of “All fixed layer”, significant discrepancies are observed between the predicted values and the true values across all radii. On the other hand, for the “Fixed 1 layer” and “No fixed layer” cases, it can be observed that the predicted values closely follow the trends of the true values.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}