
Convolutional Autoencoding of Small Targets in the Littoral Sonar Acoustic Backscattering Domain

Abstract
:1. Introduction
- (i)
- We take the preexisting convolutional autoencoder network concept [23] and apply it to a different data domain: underwater sonar backscattering from small elastic targets.
- (ii)
- We approximate the dimensionality of a feature space for this new data through empirical analysis, and then
- (iii)
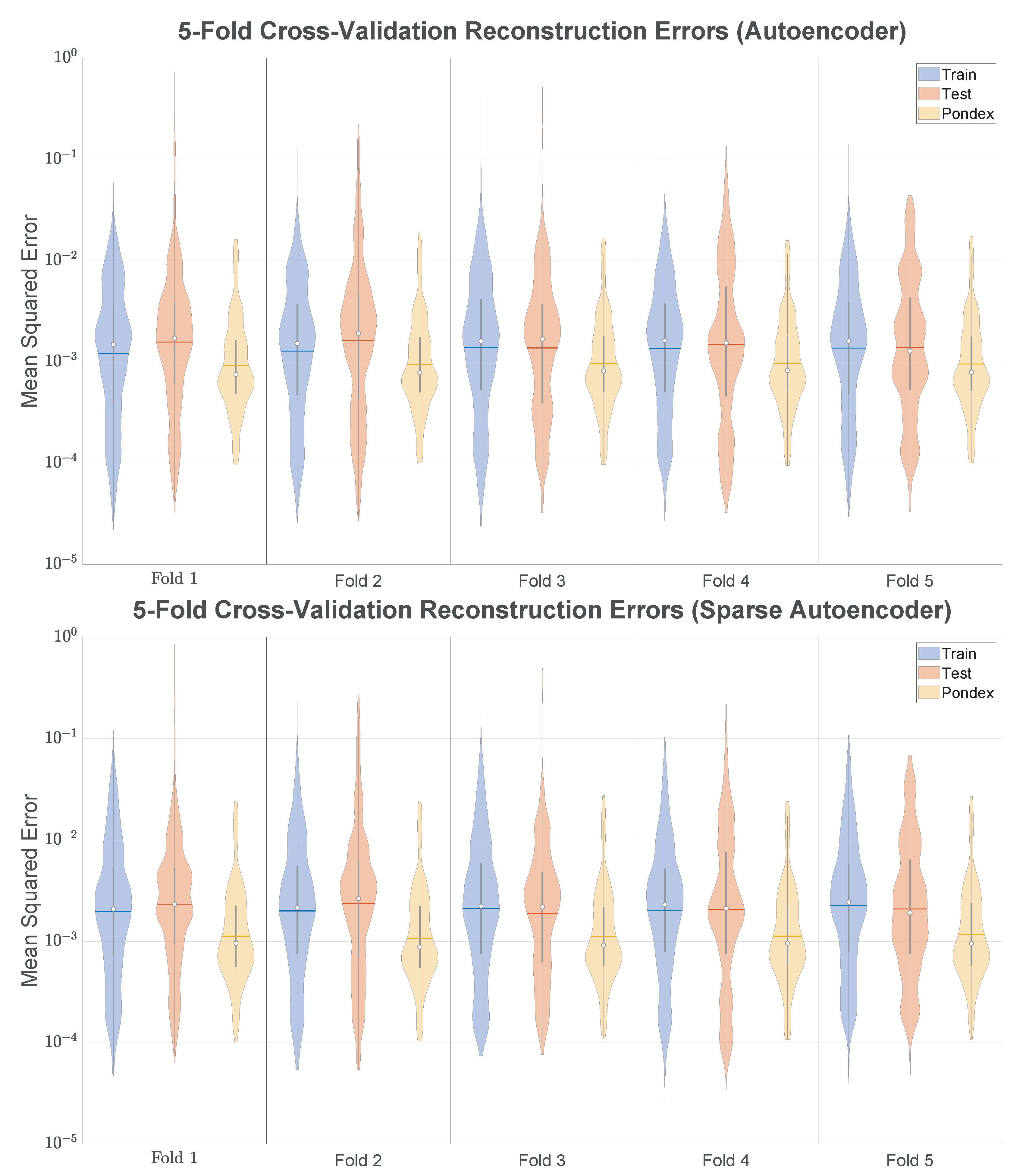
- visualize the multimodal network reconstruction error distributions collected through 5-fold cross-validation.
2. Materials and Methods
2.1. Principle Component Analysis
2.2. Autoencoders
2.3. Data
2.4. Networks
2.5. Training Process
- Preprocess the data as described in Section 2.3.
- Initialize a new autoencoder with random weights and the correct parameters.
- Begin training the autoencoder on the full data set for 100 epochs (unless otherwise specified), using MSE loss.
- Ensure that the loss value is beneath a threshold after one third of the training epochs have completed. Cancel the training and return to Step 2 if it is not.
- Save the final weights of the trained network.
- Repeat from Step 2 until ten sets of weights are saved.
2.6. Evaluation
3. Results
3.1. Learning Rate Determination
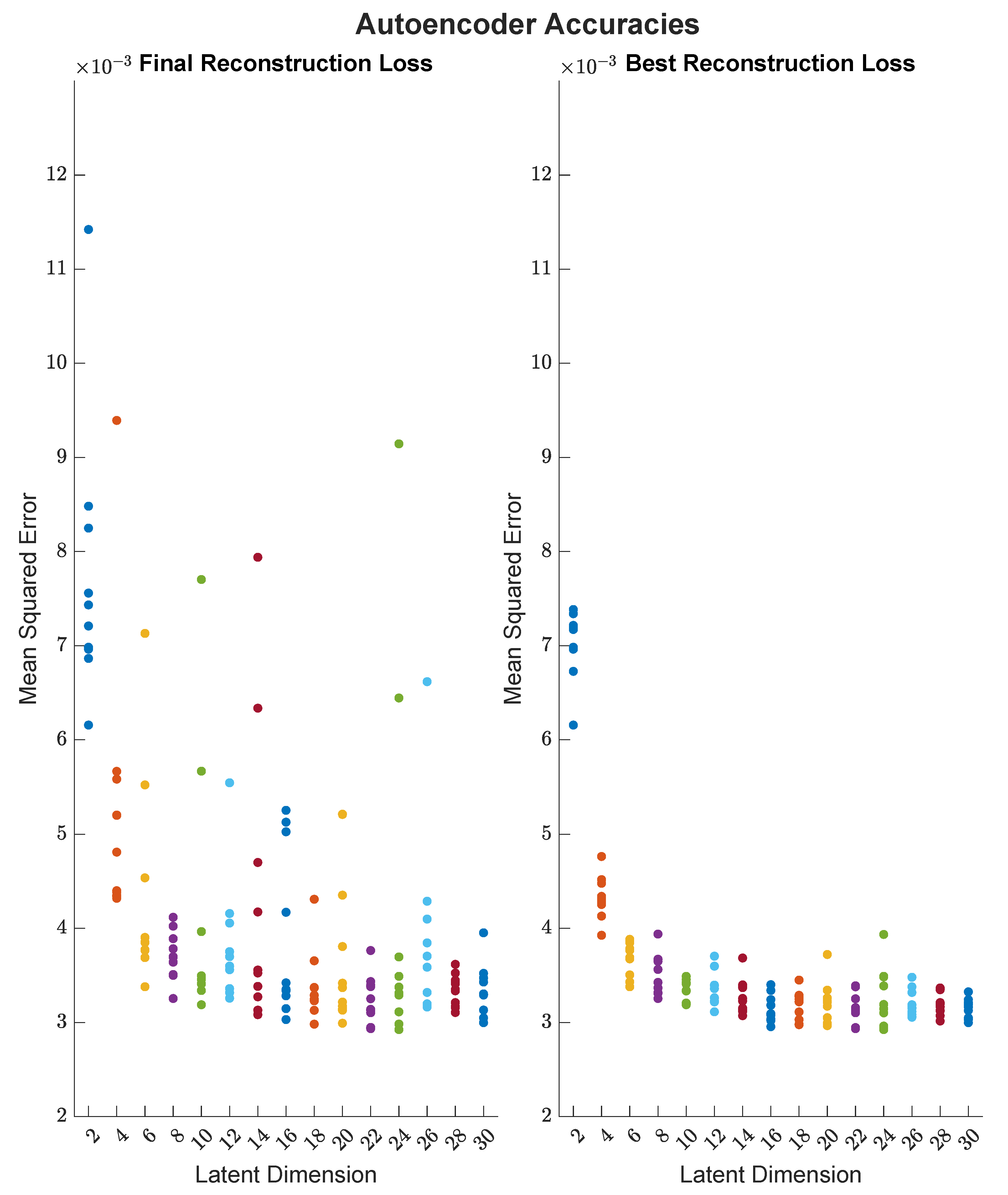
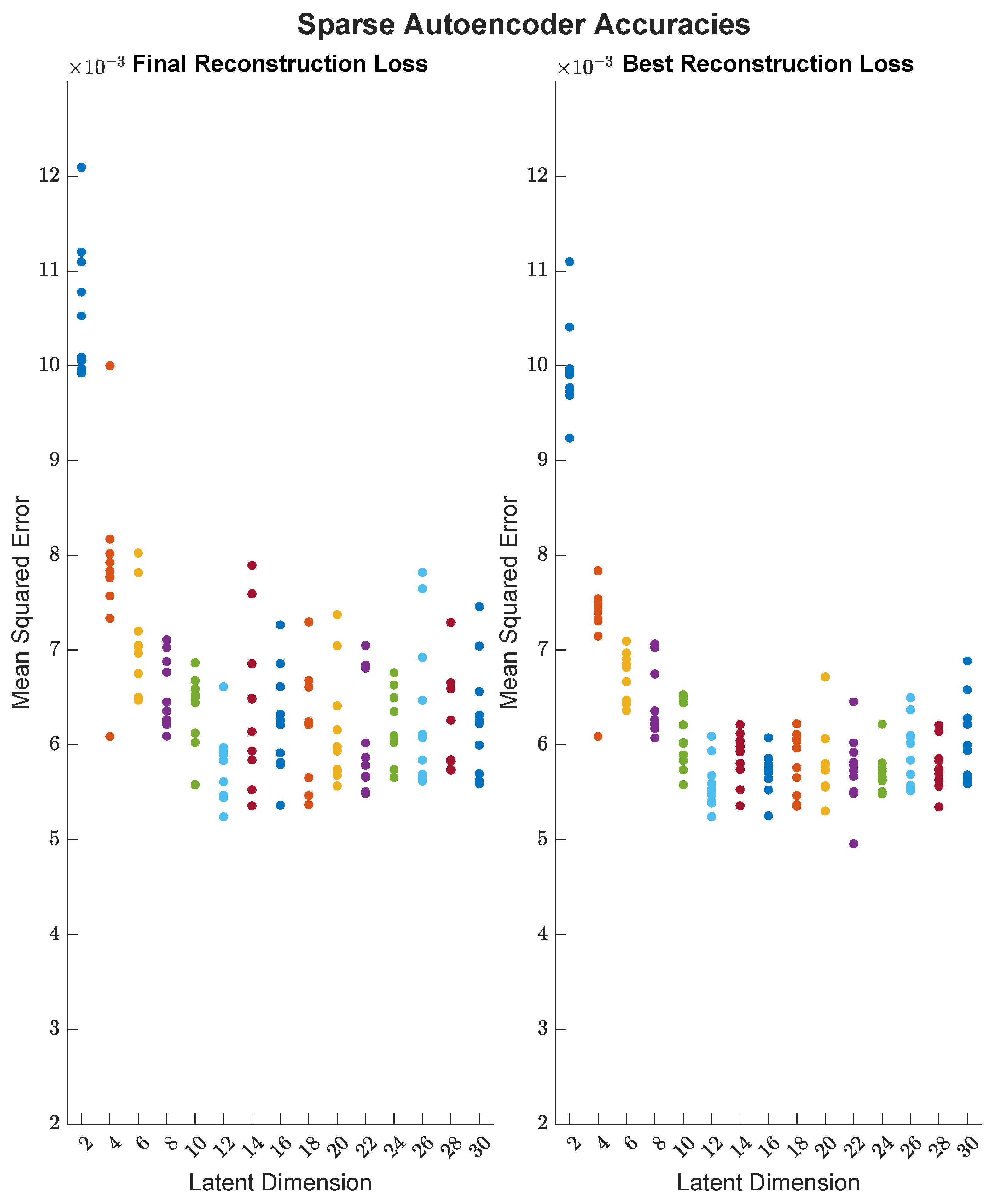
3.2. Latent Space Dimension Comparison
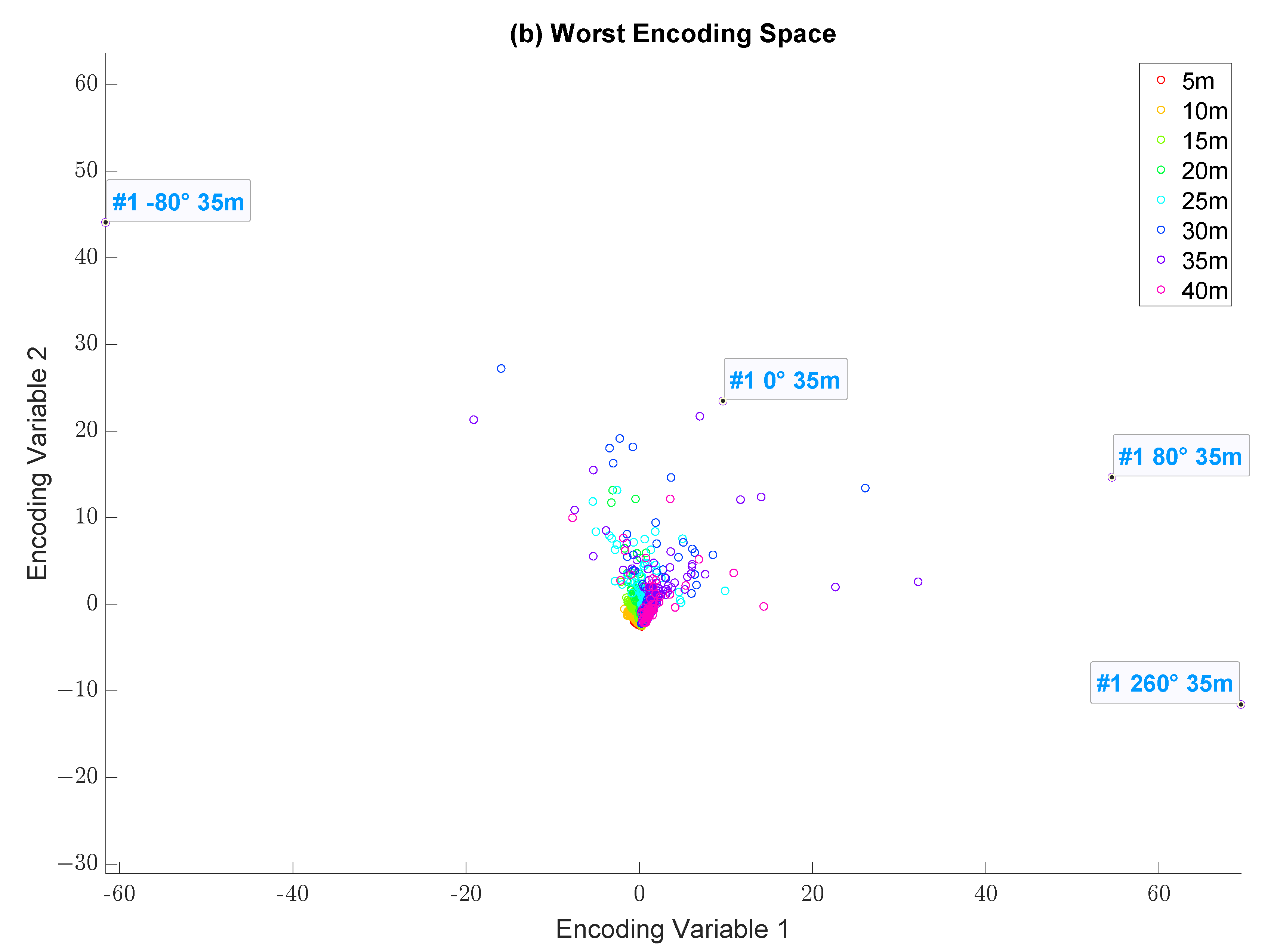
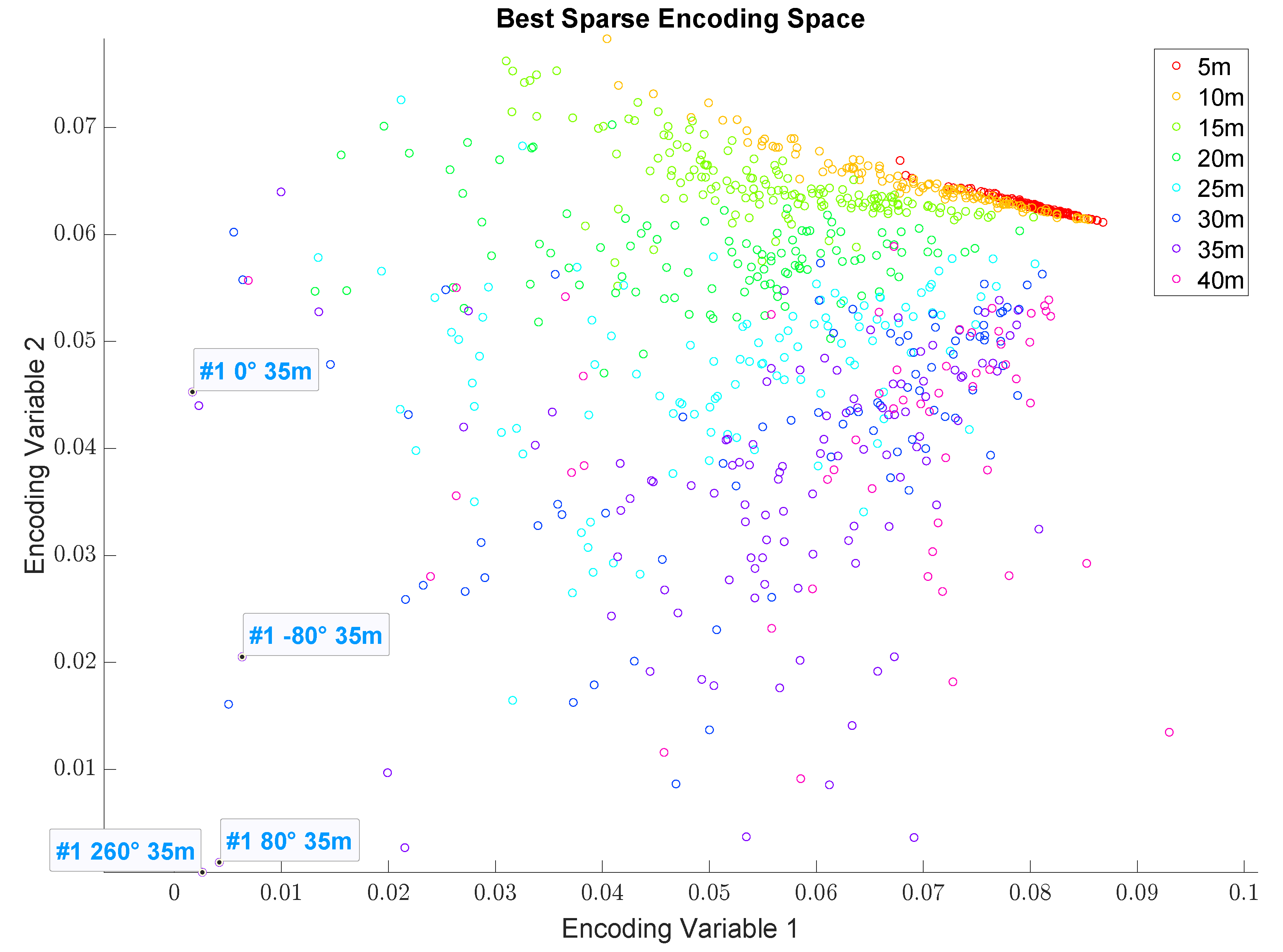
3.3. 2D Encoding Space
3.4. Performance on Unseen Data
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCA | Principal Component Analysis |
| ReLU | Rectified Linear Unit |
| PReLU | Parametric Rectified Linear Unit |
| MSE | Mean Squared Error |
| ATR | Automated Target Recognition |
| GAN | Generative Adversarial Network |
| VAE | Variational Autoencoder |
| UXO | Unexploded Ordinance |
References
- Robinson, M.; Fennell, S.; DiZio, B.; Dumiak, J. Geometry and topology of the space of sonar target echos. J. Acoust. Soc. Am. 2018, 143, 1630–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fei, T.; Kraus, D.; Berkel, P. A new idea on feature selection and its application to the underwater object recognition. Proc. Meet. Acoust. 2012, 17, 070071. [Google Scholar] [CrossRef] [Green Version]
- Langner, F.A.; Jans, W.; Knauer, C.; Middelmann, W. Advantages and disadvantages of training based object detection/classification in SAS images. Proc. Meet. Acoust. 2012, 17, 070075. [Google Scholar] [CrossRef] [Green Version]
- Sawas, J.; Petillot, Y. Cascade of boosted classifiers for automatic target recognition in synthetic aperture sonar imagery. Proc. Meet. Acoust. 2012, 17, 070074. [Google Scholar] [CrossRef] [Green Version]
- Steiniger, Y.; Groen, J.; Stoppe, J.; Kraus, D.; Meisen, T. A study on modern deep learning detection algorithms for automatic target recognition in sidescan sonar images. Proc. Meet. Acoust. 2021, 44, 070010. [Google Scholar] [CrossRef]
- Warakagoda, N.; Midtgaard, Ø. Retrieval of similar targets in synthetic aperture sonar images with deep learning. Proc. Meet. Acoust. 2020, 40, 070013. [Google Scholar] [CrossRef]
- Bianco, M.J.; Gerstoft, P.; Traer, J.; Ozanich, E.; Roch, M.A.; Gannot, S.; Deledalle, C.A. Machine learning in acoustics: Theory and applications. J. Acoust. Soc. Am. 2019, 146, 3590–3628. [Google Scholar] [CrossRef] [Green Version]
- Williams, D.P.; España, A.; Kargl, S.G.; Williams, K.L. A family of algorithms for the automatic detection, isolation, and fusion of object responses in sonar data. Proc. Meet. Acoust. 2021, 44, 070022. [Google Scholar] [CrossRef]
- El Bergui, A.; Quidu, I.; Zerr, B.; Solaiman, B. Model based classification of mine-like objects in sidescan sonar using the highlight information. Proc. Meet. Acoust. 2012, 17, 070072. [Google Scholar] [CrossRef]
- Sammelmann, G.S. Simulation, Beam-forming, and Visualization of Bistatic Synthetic Aperture Sonar; Government Report OMB 0704-0188; DTIC: Fort Belvoir, VA, USA, 2010. [Google Scholar]
- Bays, M.J.; Shende, A.; Stilwell, D.J.; Redfield, S.A. A solution to the multiple aspect coverage problem. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1531–1537. [Google Scholar] [CrossRef]
- Kriminger, E.; Cobb, J.T.; Príncipe, J.C. Online active learning for automatic target recognition. IEEE J. Ocean. Eng. 2014, 40, 583–591. [Google Scholar] [CrossRef]
- Du, X.; Seethepalli, A.; Sun, H.; Zare, A.; Cobb, J.T. Environmentally-adaptive target recognition for SAS imagery. In Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XXII; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10182, p. 101820I. [Google Scholar]
- Stack, J. Automation for underwater mine recognition: Current trends and future strategy. In Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XVI; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 8017, p. 80170K. [Google Scholar]
- Dobeck, G.J. Algorithm fusion for automated sea mine detection and classification. In Proceedings of the MTS/IEEE Oceans 2001. An Ocean Odyssey. Conference Proceedings (IEEE Cat. No. 01CH37295), Honolulu, HI, USA, 5–8 November 2001; Volume 1, pp. 130–134. [Google Scholar]
- Kargl, S. Acoustic Response of Underwater Munitions near a Sediment Interface: Measurement Model Comparisons and Classification Schemes; Technical Report; Washington University Seattle Applied Physics Lab: Washington, DC, USA, 2015. [Google Scholar]
- Kargl, S.G.; Williams, K.L.; Thorsos, E.I.; Lopes, J.L. Synthetic aperture sonar simulations of cylindrical targets. J. Acoust. Soc. Am. 2009, 125, 2733. [Google Scholar] [CrossRef]
- Misiuk, B.; Brown, C.J.; Robert, K.; Lacharité, M. Harmonizing multi-source sonar backscatter datasets for seabed mapping using bulk shift approaches. Remote Sens. 2020, 12, 601. [Google Scholar] [CrossRef] [Green Version]
- Hefner, B.T.; Jackson, D.R.; Ivakin, A.N.; Wendelboe, G. Physics-based inversion of multibeam sonar data for seafloor characterization. J. Acoust. Soc. Am. 2013, 134, 4240. [Google Scholar] [CrossRef]
- Mukherjee, K.; Gupta, S.; Ray, A.; Phoha, S. Symbolic analysis of sonar data for underwater target detection. IEEE J. Ocean. Eng. 2011, 36, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Ballard, D.H. Modular Learning in Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Seattle, WA, USA, 13–17 July 1987. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2017; Chapter 14; pp. 493–516. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems 29; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc.: Red Hook, NY, USA, 2016; pp. 2180–2188. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the NIPS 2016, Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2234–2242. [Google Scholar]
- Chen, J.L.; Summers, J.E. Deep neural networks for learning classification features and generative models from synthetic aperture sonar big data. Proc. Meet. Acoust. 2016, 29, 032001. [Google Scholar] [CrossRef] [Green Version]
- Karl Pearson, F.R.S. LIII. On lines and planes of closest fit to systems of points in space. Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning; Information Science and Statistics; Springer Science+Business Media: New York, NY, USA, 2006; Chapter 12; pp. 559–599. [Google Scholar]
- Plaut, E. From Principal Subspaces to Principal Components with Linear Autoencoders. arXiv 2018, arXiv:1804.10253. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2017; Chapter 5; pp. 115–117. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Ng, A. Sparse Autoencoder. Stanford CS294A Lecture Notes. Online. 2011. Available online: https://web.stanford.edu/class/cs294a/sparseAutoencoder_2011new.pdf (accessed on 1 November 2022).
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Williams, K.L.; Kargl, S.G.; Thorsos, E.I.; Burnett, D.S.; Lopes, J.L.; Zampolli, M.; Marston, P.L. Acoustic scattering from a solid aluminum cylinder in contact with a sand sediment: Measurements, modeling, and interpretation. J. Acoust. Soc. Am. 2010, 127, 3356–3371. [Google Scholar] [CrossRef] [PubMed]
- Kargl, S.G.; Williams, K.L. Full Scale Measurement and Modeling of the Acoustic Response of Proud and Buried Munitions at Frequencies from 1–30 kHz; Final Report; University of Washington, SERDP: Washington, DC, USA, 2012. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 1 November 2022).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 1 November 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2017; Chapter 6; pp. 197–217. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the ICCV 2015, IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Andrew, L.; Maas, A.Y.H.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech, and Language Processing; International Conference on Machine Learning, Atlanta, GA, USA, 16 June 2013. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; Volume 9. [Google Scholar]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the ICLR 2015, International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; Volume 3. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Bechtold, B. Violin Plots for Matlab. Release v0.1. Github Release. 2016. Available online: https://github.com/bastibe/Violinplot-Matlab/releases/tag/v0.1 (accessed on 1 November 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 5 m | 10 m | 15 m | 20 m | 25 m | 30 m | 35 m | 40 m | |
|---|---|---|---|---|---|---|---|---|
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – |
| 5 m | 10 m | 15 m | 20 m | 25 m | 30 m | 35 m | 40 m | |
|---|---|---|---|---|---|---|---|---|
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – | ||||
| – | – | – | – | – |
| 5 m | |||||||||
| 10 m |
| 5 m | |||||||||
| 10 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Linhardt, T.J.; Sen Gupta, A.; Bays, M. Convolutional Autoencoding of Small Targets in the Littoral Sonar Acoustic Backscattering Domain. J. Mar. Sci. Eng. 2023, 11, 21. https://doi.org/10.3390/jmse11010021
Linhardt TJ, Sen Gupta A, Bays M. Convolutional Autoencoding of Small Targets in the Littoral Sonar Acoustic Backscattering Domain. Journal of Marine Science and Engineering. 2023; 11(1):21. https://doi.org/10.3390/jmse11010021
Chicago/Turabian StyleLinhardt, Timothy J., Ananya Sen Gupta, and Matthew Bays. 2023. "Convolutional Autoencoding of Small Targets in the Littoral Sonar Acoustic Backscattering Domain" Journal of Marine Science and Engineering 11, no. 1: 21. https://doi.org/10.3390/jmse11010021