
Camera-LiDAR Cross-Modality Fusion Water Segmentation for Unmanned Surface Vehicles


Abstract
:1. Introduction
- We propose a novel camera-LiDAR cross-modality fusion water segmentation method to combine the 2D image and 3D point cloud characteristics. To the best of our knowledge, we are the first to combine 3D LiDAR point cloud and image data to improve the water segmentation performance;
- A novel CMWS dataset is proposed to validate the proposed approach. This is the first water segmentation dataset with images and corresponding point clouds for USVs in inland waterways;
- Extensive experiments are conducted on the CMWS datasets. The results show that the proposed camera-LiDAR cross-modality fusion water segmentation method significantly improves image-only-based methods, achieving improvements in accuracy and MaxF of approximately 2% for all the image-only-based methods.
2. Related Work
2.1. Water Segmentation Methods for USVs
2.2. Water Segmentation Datasets for USVs
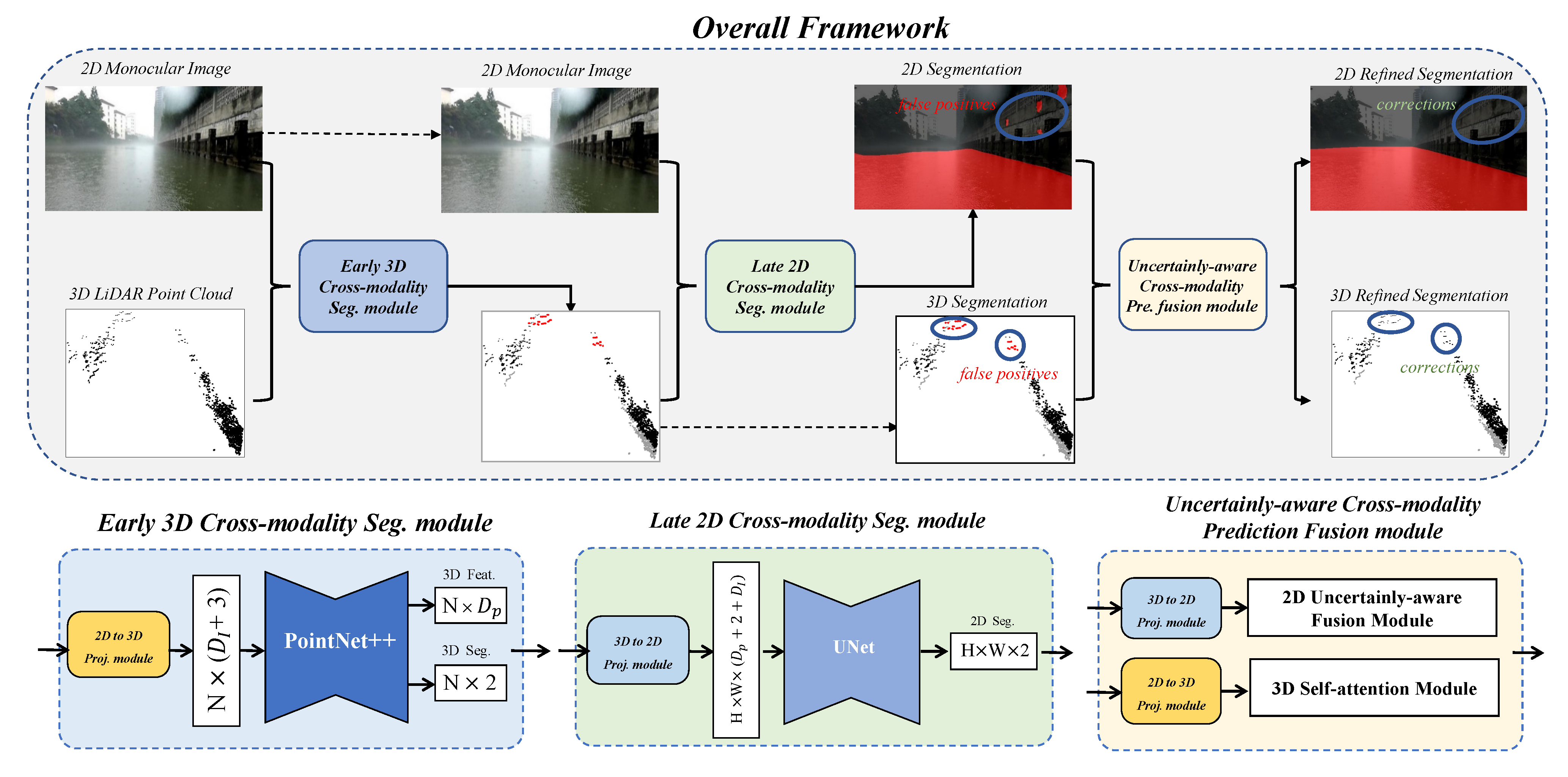
3. Method
3.1. Limitations of the Current Approaches
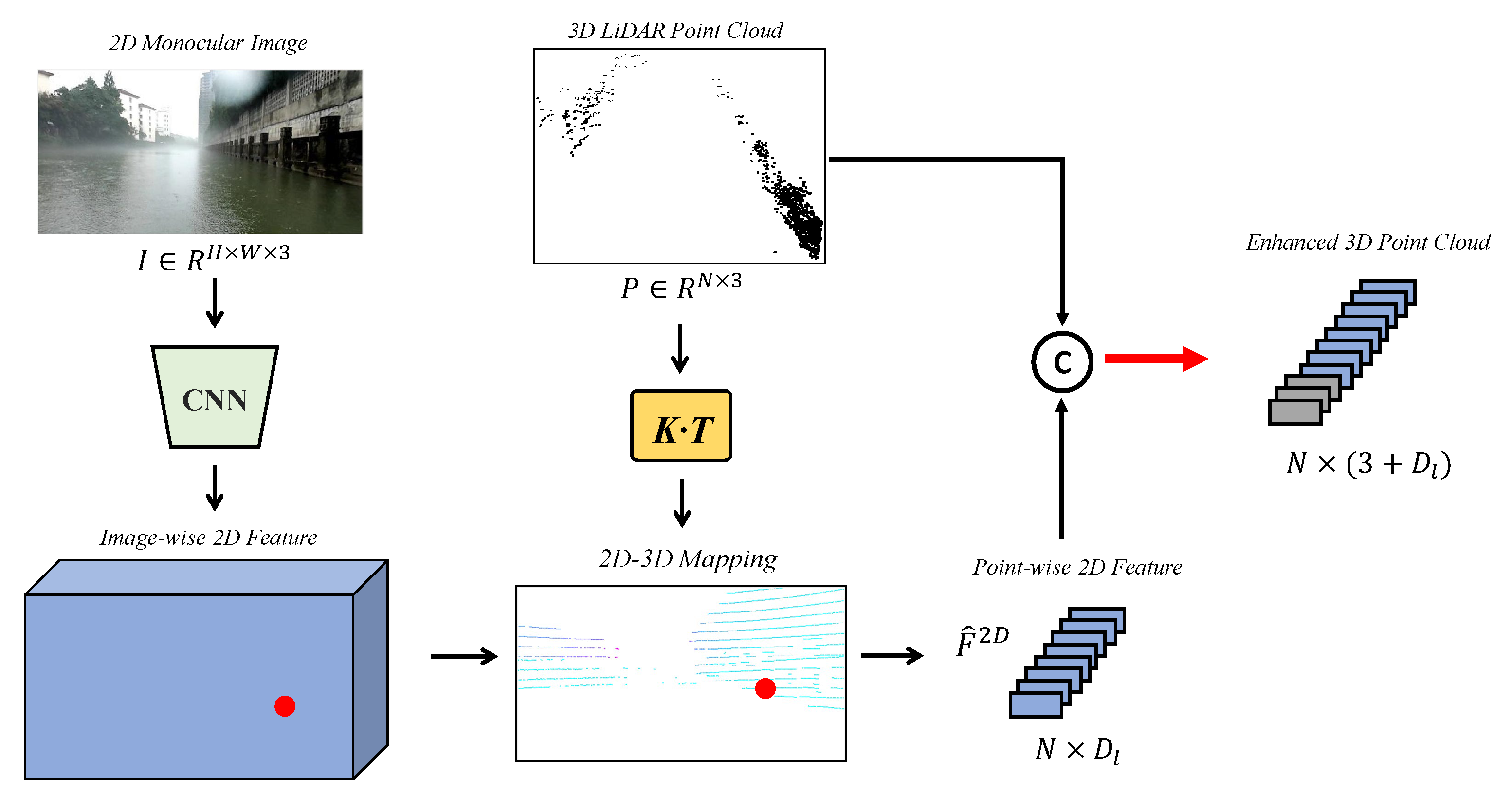
3.2. Early 3D Cross-Modality Segmentation Module
3.2.1. 2D-to-3D Projection Module
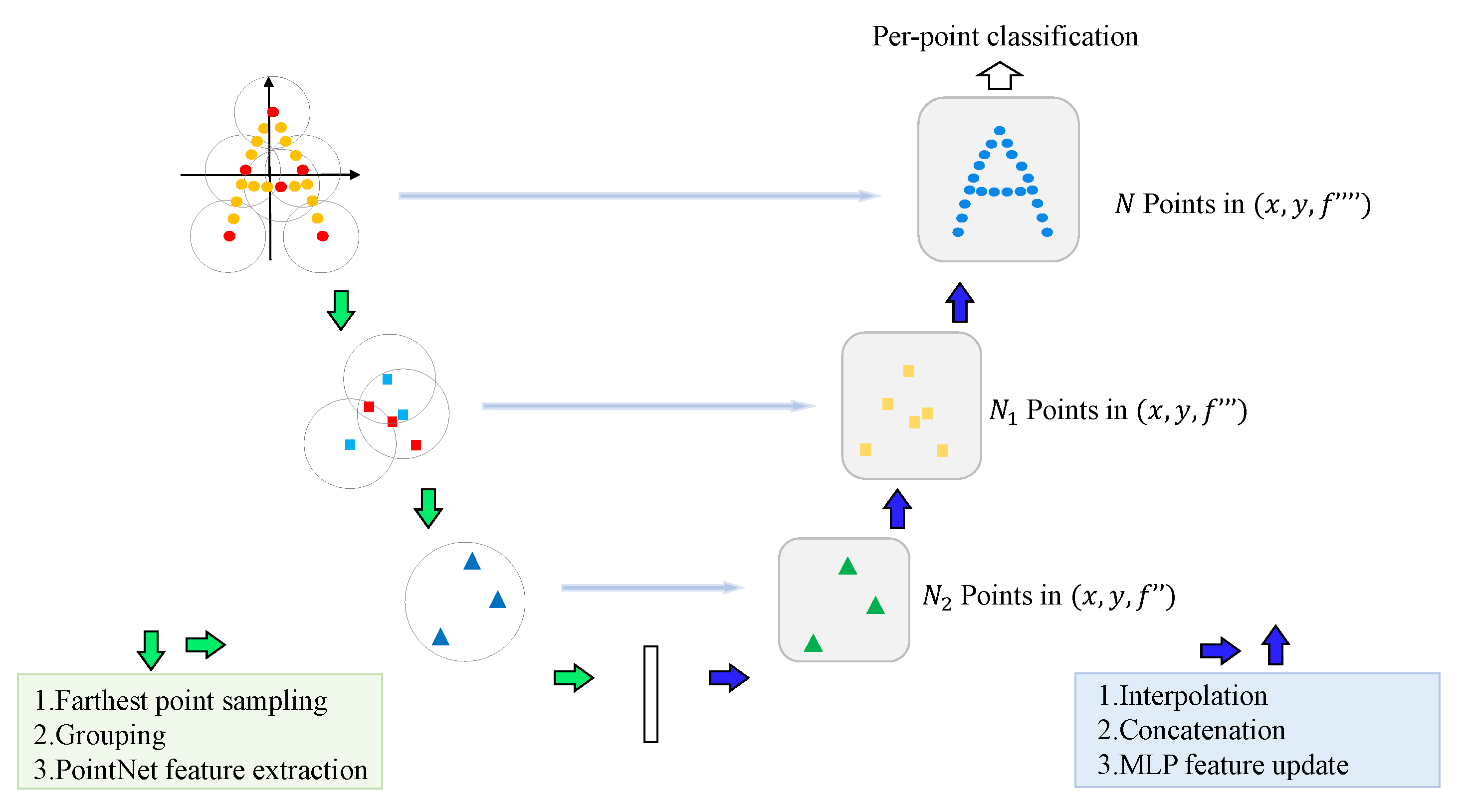
3.2.2. 3D Segmentation Network
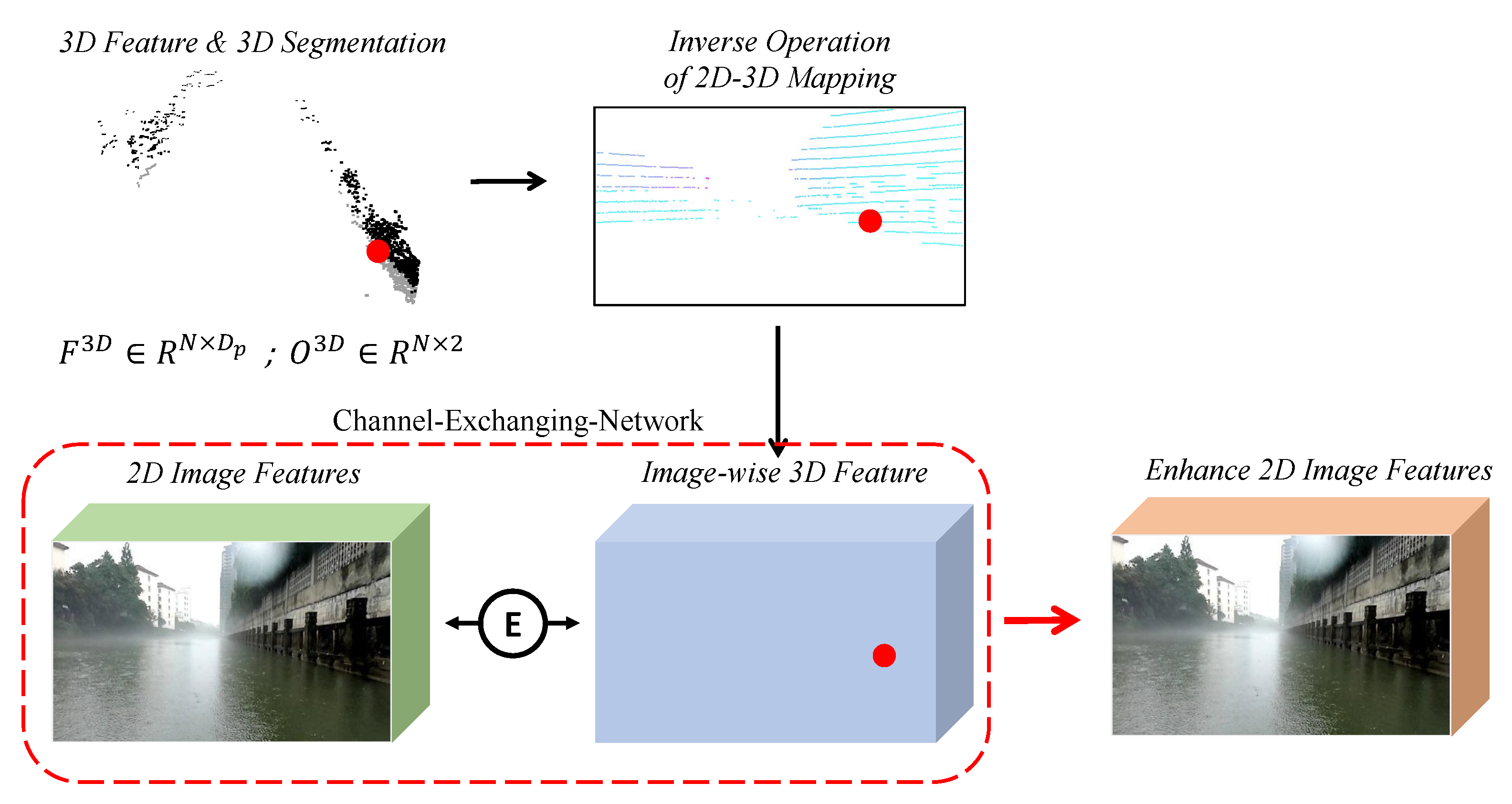
3.3. Late 2D Cross-Modality Segmentation Module
3.3.1. 3D-to-2D Projection Module
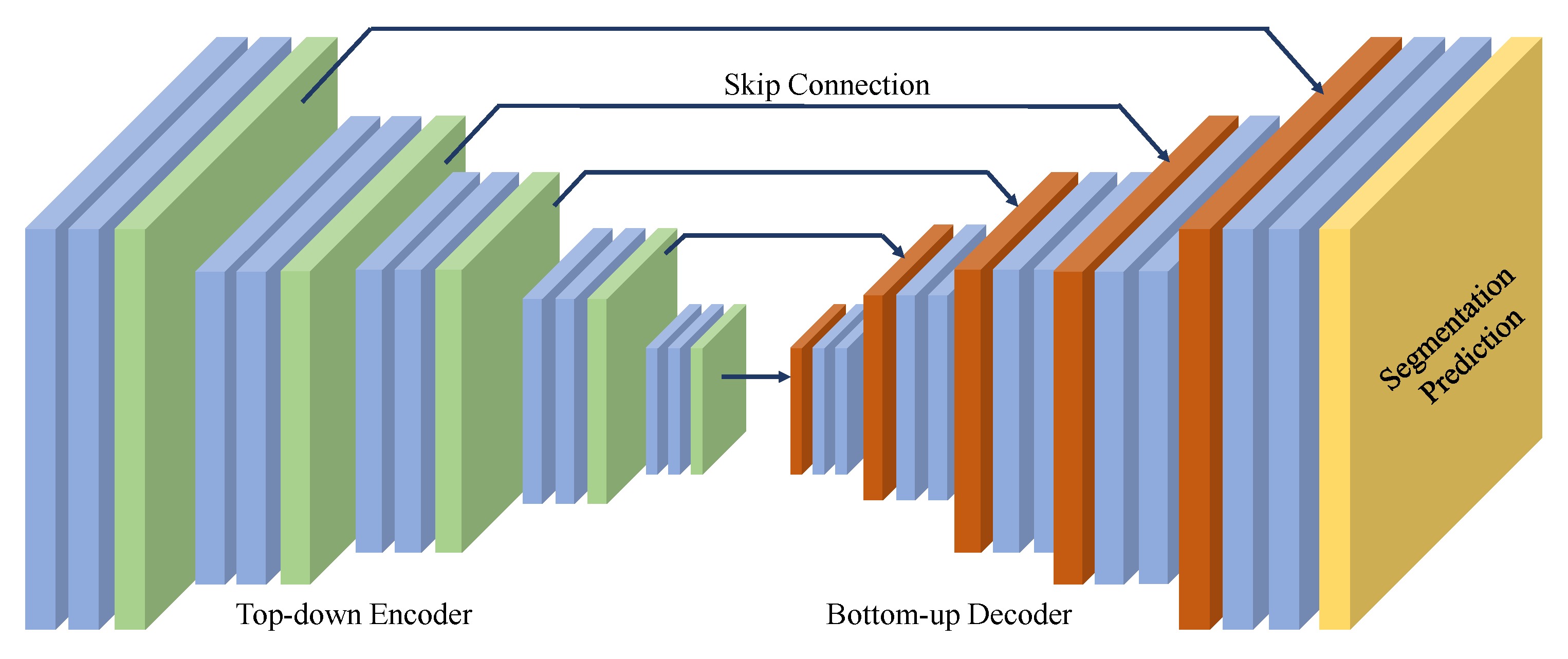
3.3.2. 2D Segmentation Network
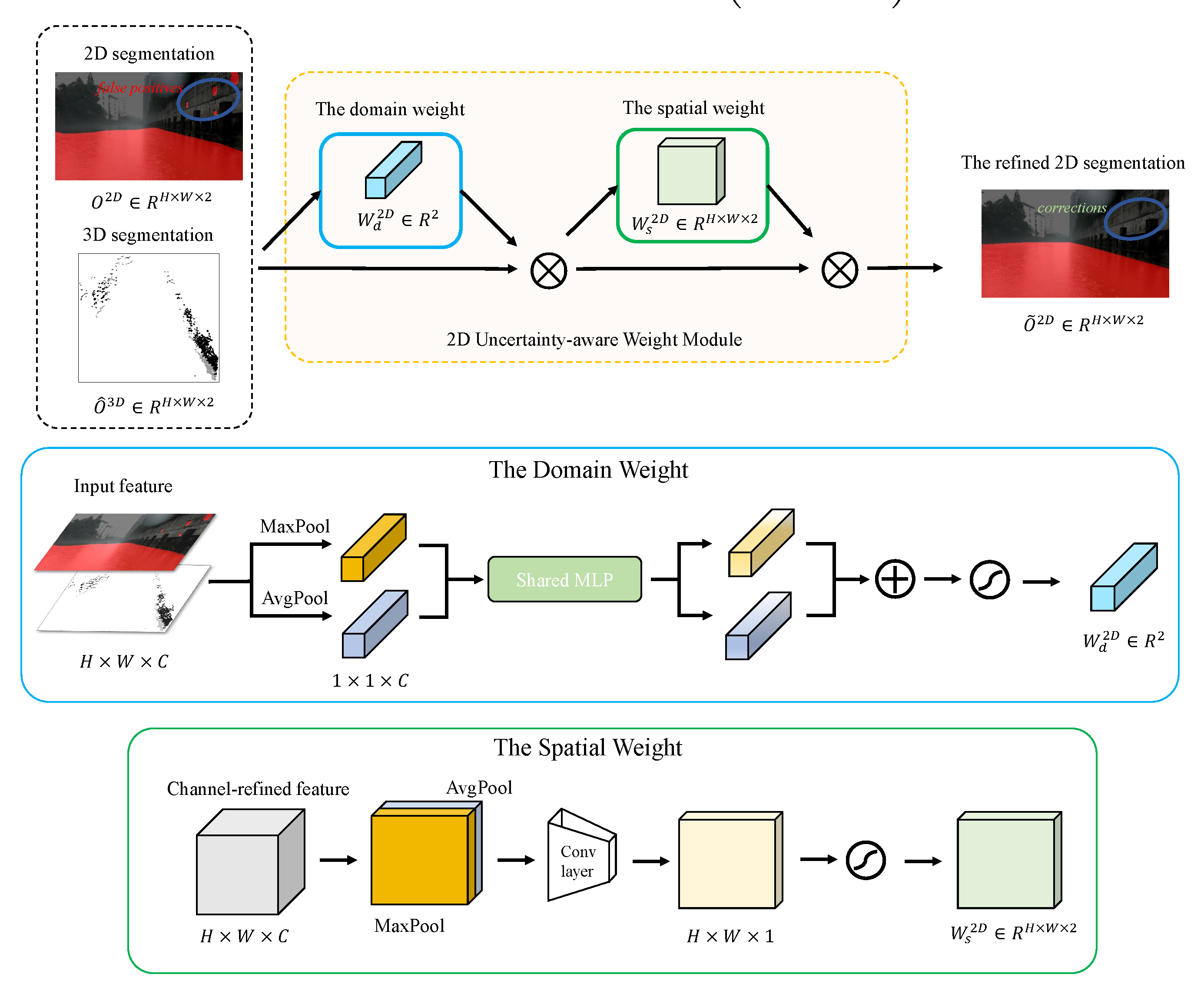
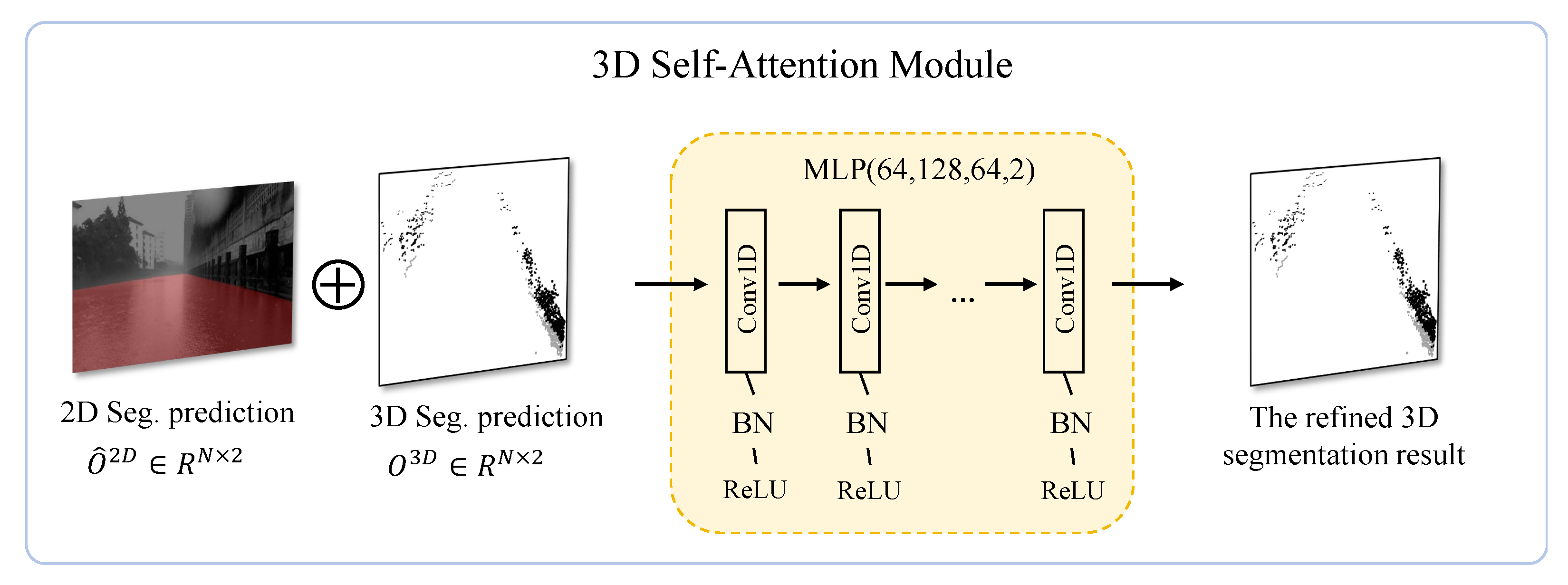
3.4. Uncertainty-Aware Cross-Modality Prediction Fusion Module
3.4.1. 2D Water Segmentation Refinement
3.4.2. 3D Water Segmentation Refinement
4. Experiments
4.1. Cross-Modality Water Segmentation Dataset
4.2. Experimental Settings
4.2.1. Parameter Settings
4.2.2. Evaluation Metrics
4.3. Experimental Results
4.4. Design Analysis
4.4.1. Ablation Study
4.4.2. Image-Wise Feature Fusion Strategy
4.4.3. Cross-Modality Prediction Fusion Strategy
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pastore, T.; Djapic, V. Improving autonomy and control of autonomous surface vehicles in port protection and mine countermeasure scenarios. J. Field Robot. 2010, 27, 903–914. [Google Scholar] [CrossRef]
- Peng, Y.; Yang, Y.; Cui, J.; Li, X.; Pu, H.; Gu, J.; Xie, S.; Luo, J. Development of the USV ‘JingHai-I’and sea trials in the Southern Yellow Sea. Ocean Eng. 2017, 131, 186–196. [Google Scholar] [CrossRef]
- Madeo, D.; Pozzebon, A.; Mocenni, C.; Bertoni, D. A low-cost unmanned surface vehicle for pervasive water quality monitoring. IEEE Trans. Instrum. Meas. 2020, 69, 1433–1444. [Google Scholar] [CrossRef]
- Wang, W.; Gheneti, B.; Mateos, L.A.; Duarte, F.; Ratti, C.; Rus, D. Roboat: An autonomous surface vehicle for urban waterways. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6340–6347. [Google Scholar]
- Zhan, W.; Xiao, C.; Wen, Y.; Zhou, C.; Yuan, H.; Xiu, S.; Zou, X.; Xie, C.; Li, Q. Adaptive semantic segmentation for unmanned surface vehicle navigation. Electronics 2020, 9, 213. [Google Scholar] [CrossRef] [Green Version]
- Mettes, P.; Tan, R.T.; Veltkamp, R. On the segmentation and classification of water in videos. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 1, pp. 283–292. [Google Scholar]
- Achar, S.; Sankaran, B.; Nuske, S.; Scherer, S.; Singh, S. Self-supervised segmentation of river scenes. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 6227–6232. [Google Scholar]
- Kristan, M.; Kenk, V.S.; Kovačič, S.; Perš, J. Fast image-based obstacle detection from unmanned surface vehicles. IEEE Trans. Cybern. 2015, 46, 641–654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taipalmaa, J.; Passalis, N.; Zhang, H.; Gabbouj, M.; Raitoharju, J. High-resolution water segmentation for autonomous unmanned surface vehicles: A novel dataset and evaluation. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. Multinet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhan, W.; Xiao, C.; Wen, Y.; Zhou, C.; Yuan, H.; Xiu, S.; Zhang, Y.; Zou, X.; Liu, X.; Li, Q. Autonomous visual perception for unmanned surface vehicle navigation in an unknown environment. Sensors 2019, 19, 2216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, Y.; Jiang, M.; Zhu, J.; Liu, Y. Are we ready for unmanned surface vehicles in inland waterways? The usvinland multisensor dataset and benchmark. IEEE Robot. Autom. Lett. 2021, 6, 3964–3970. [Google Scholar] [CrossRef]
- Ma, F.; Cavalheiro, G.V.; Karaman, S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3288–3295. [Google Scholar]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4796–4803. [Google Scholar]
- Xiao, L.; Wang, R.; Dai, B.; Fang, Y.; Liu, D.; Wu, T. Hybrid conditional random field based camera-LIDAR fusion for road detection. Inf. Sci. 2018, 432, 543–558. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Bovcon, B.; Muhovič, J.; Perš, J.; Kristan, M. The mastr1325 dataset for training deep usv obstacle detection models. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 3431–3438. [Google Scholar]
- Wang, Y.; Huang, W.; Sun, F.; Xu, T.; Rong, Y.; Huang, J. Deep multimodal fusion by channel exchanging. Adv. Neural Inf. Process. Syst. 2020, 33, 4835–4845. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Mohan, R.; Valada, A. Efficientps: Efficient panoptic segmentation. Int. J. Comput. Vis. 2021, 129, 1551–1579. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision Transformer Adapter for Dense Predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Lopez-Fuentes, L.; Rossi, C.; Skinnemoen, H. River segmentation for flood monitoring. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3746–3749. [Google Scholar]
- Ling, G.; Suo, F.; Lin, Z.; Li, Y.; Xiang, J. Real-time Water Area Segmentation for USV using Enhanced U-Net. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 2533–2538. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 549–565. [Google Scholar]
- Barekatain, M.; Martí, M.; Shih, H.F.; Murray, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Okutama-action: An aerial view video dataset for concurrent human action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 28–35. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Mandal, M.; Kumar, L.K.; Vipparthi, S.K. Mor-uav: A benchmark dataset and baselines for moving object recognition in uav videos. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle WA, USA, 12–16 October 2020; pp. 2626–2635. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Zhang, M.; Lucas, J.; Ba, J.; Hinton, G.E. Lookahead optimizer: K steps forward, 1 step back. Adv. Neural Inf. Process. Syst. 2019, 32, 9597–9608. [Google Scholar]
- Fritsch, J.; Kuehnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 1693–1700. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Input | Acc(%)↑ | MaxF(%)↑ | AvgPrec(%)↑ | PRE(%)↑ | REC(%)↑ | FPR(%)↓ | FNR(%)↓ |
|---|---|---|---|---|---|---|---|---|
| UNet [25] | I | 94.31 | 94.85 | 92.03 | 93.59 | 96.14 | 6.41 | 3.86 |
| FCN [11] | I | 95.38 | 96.38 | 95.69 | 97.13 | 95.64 | 2.87 | 4.36 |
| DeepLabV3+ [26] | I | 96.33 | 96.69 | 95.50 | 96.54 | 96.83 | 3.46 | 3.17 |
| CM-UNet (Ours) | L+I | 96.77 | 97.34 | 95.86 | 96.94 | 97.75 | 3.06 | 2.25 |
| +2.46 | +2.49 | +3.83 | +3.35 | +1.61 | −3.35 | −1.61 | ||
| CM-FCN (Ours) | L+I | 97.64 | 97.83 | 96.28 | 97.78 | 97.97 | 2.22 | 2.03 |
| +2.26 | +1.45 | +0.59 | +0.65 | +2.33 | −0.65 | −2.33 | ||
| CM-DeepLabV3+ | L+I | 98.08 | 98.24 | 96.77 | 97.49 | 98.00 | 2.51 | 2.00 |
| (Ours) | +1.75 | +1.55 | +1.27 | +0.95 | +1.17 | −0.95 | −1.17 |
| Model | 3D CM | 2D CM | Fusion | 3D Segmentation | 2D Segmentation | ||||
|---|---|---|---|---|---|---|---|---|---|
| MaxF | AvgPrec | PRE | MaxF | AvgPrec | PRE | ||||
| A | 78.91 | 79.38 | 83.59 | 94.85 | 92.03 | 93.59 | |||
| B | √ | 86.13 | 85.12 | 86.22 | - | - | - | ||
| C | √ | 78.91 | 79.38 | 83.59 | 95.53 | 94.26 | 94.98 | ||
| D | √ | √ | 86.13 | 85.12 | 86.22 | 96.82 | 95.12 | 95.62 | |
| E | √ | √ | √ | 89.64 | 89.73 | 87.77 | 97.34 | 95.86 | 96.94 |
| Fusion Method | MaxF (%) | AvgPrec (%) | PRE (%) |
|---|---|---|---|
| Max | 90.98 | 91.13 | 87.98 |
| Sum | 93.71 | 92.9 | 92.19 |
| Concatenation | 94.83 | 94.46 | 94.16 |
| Conv-CBAM [39] | 96.82 | 95.12 | 95.62 |
| Conv-CEN [19] | 97.34 | 95.86 | 96.94 |
| Fusion Method | 3D Segmentation | 2D Segmentation | ||||
|---|---|---|---|---|---|---|
| MaxF (%) | AvcgPrec (%) | PRE (%) | MaxF (%) | AvgPrec (%) | PRE (%) | |
| Max | 87.13 | 85.96 | 85.6 | 95.32 | 94.66 | 94.44 |
| Sum | 87.93 | 86.01 | 86.06 | 96.13 | 95.69 | 95.73 |
| Mean | 88.27 | 88.23 | 87.17 | 96.58 | 95.58 | 95.93 |
| Uncertainty-aware | 89.64 | 89.73 | 87.77 | 97.34 | 95.86 | 96.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Zhang, J.; Liu, C.; Li, X.; Peng, Y. Camera-LiDAR Cross-Modality Fusion Water Segmentation for Unmanned Surface Vehicles. J. Mar. Sci. Eng. 2022, 10, 744. https://doi.org/10.3390/jmse10060744
Gao J, Zhang J, Liu C, Li X, Peng Y. Camera-LiDAR Cross-Modality Fusion Water Segmentation for Unmanned Surface Vehicles. Journal of Marine Science and Engineering. 2022; 10(6):744. https://doi.org/10.3390/jmse10060744
Chicago/Turabian StyleGao, Jiantao, Jingting Zhang, Chang Liu, Xiaomao Li, and Yan Peng. 2022. "Camera-LiDAR Cross-Modality Fusion Water Segmentation for Unmanned Surface Vehicles" Journal of Marine Science and Engineering 10, no. 6: 744. https://doi.org/10.3390/jmse10060744