
Prediction of Aerosol Extinction Coefficient in Coastal Areas of South China Based on Attention-BiLSTM

 ,
,
Abstract
:1. Introduction
2. Proposed Methodology of AEC Prediction
2.1. Overall Structure of the Proposed Attention-BiLSTM Method
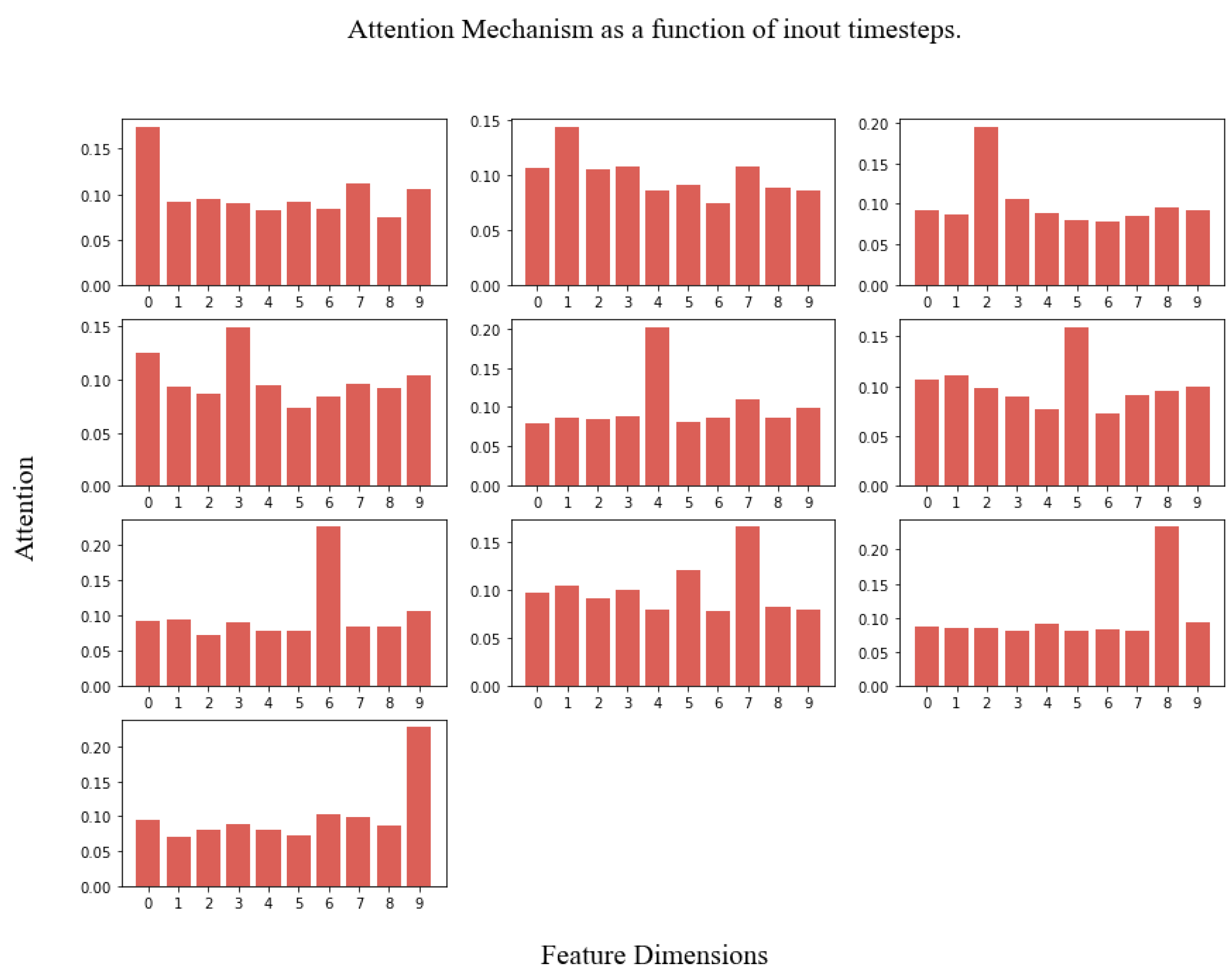
- Attention Mechanism. The traditional attention mechanism reviews the information at each previous time step and selects relevant information to help generate the output. In this paper, however, we select features dimension to find out which feature plays a key role in the prediction result:After using the operation to invert the dimensions, attention weights are multiplied by and then fed to the BiLSTM unit.
- BiLSTM unit. The BiLSTM model is used as a basic prediction model to predict AEC:where is the input multiplied by attention weights, is hte size of the hidden layer in the BiLSTM unit. The function is used to train data twice.
- Dense layer. A dense layer is used to convert the output of BiLSTM into a prediction result:Kernel is the weight matrix created by dense layer, and b is the bias vector. The activation function used in the dense layer is .
2.2. Attention Mechanism
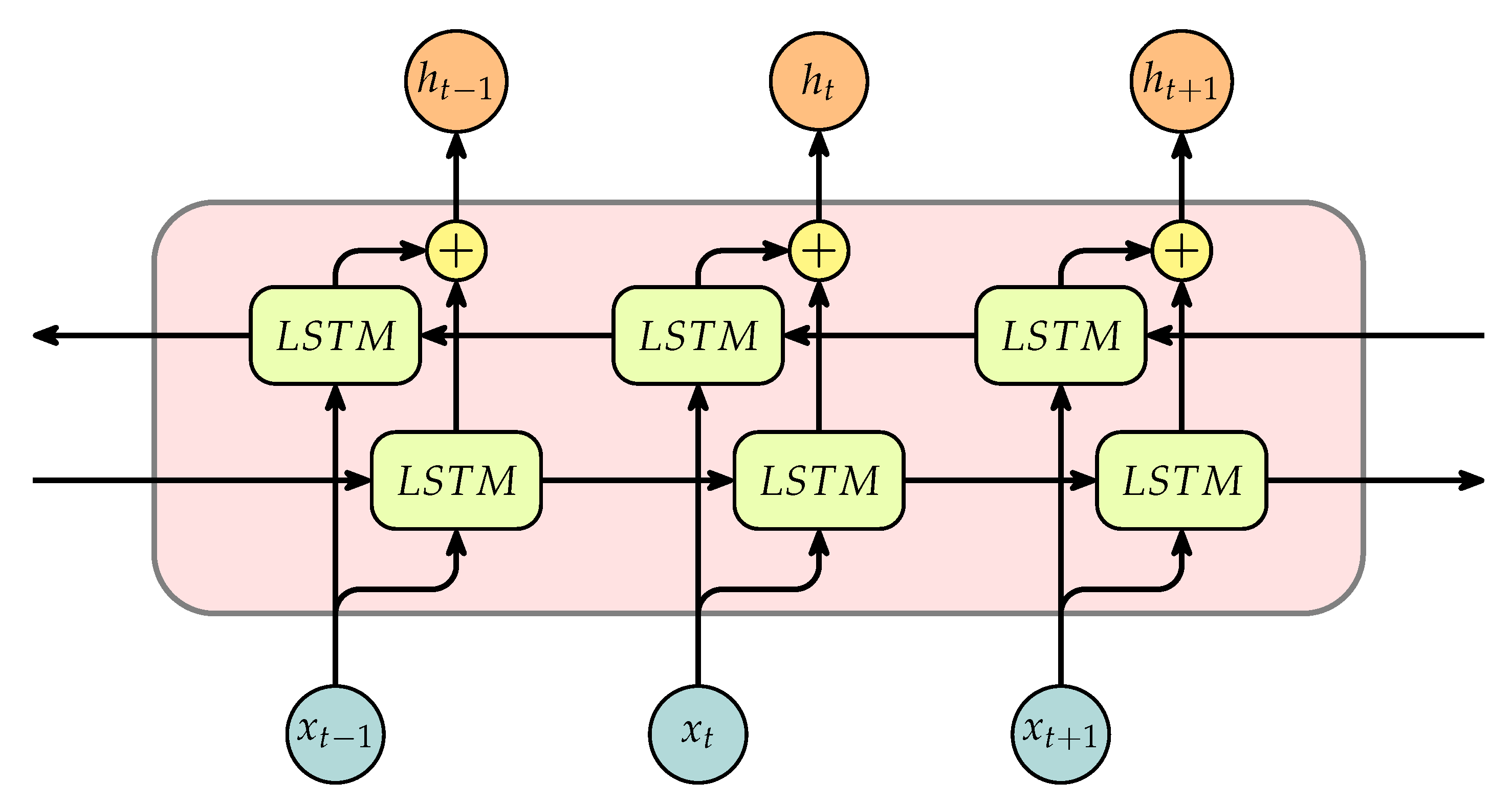
2.3. Bidirectional Long Short-Term Memory
3. Experimental and Evaluation Framework
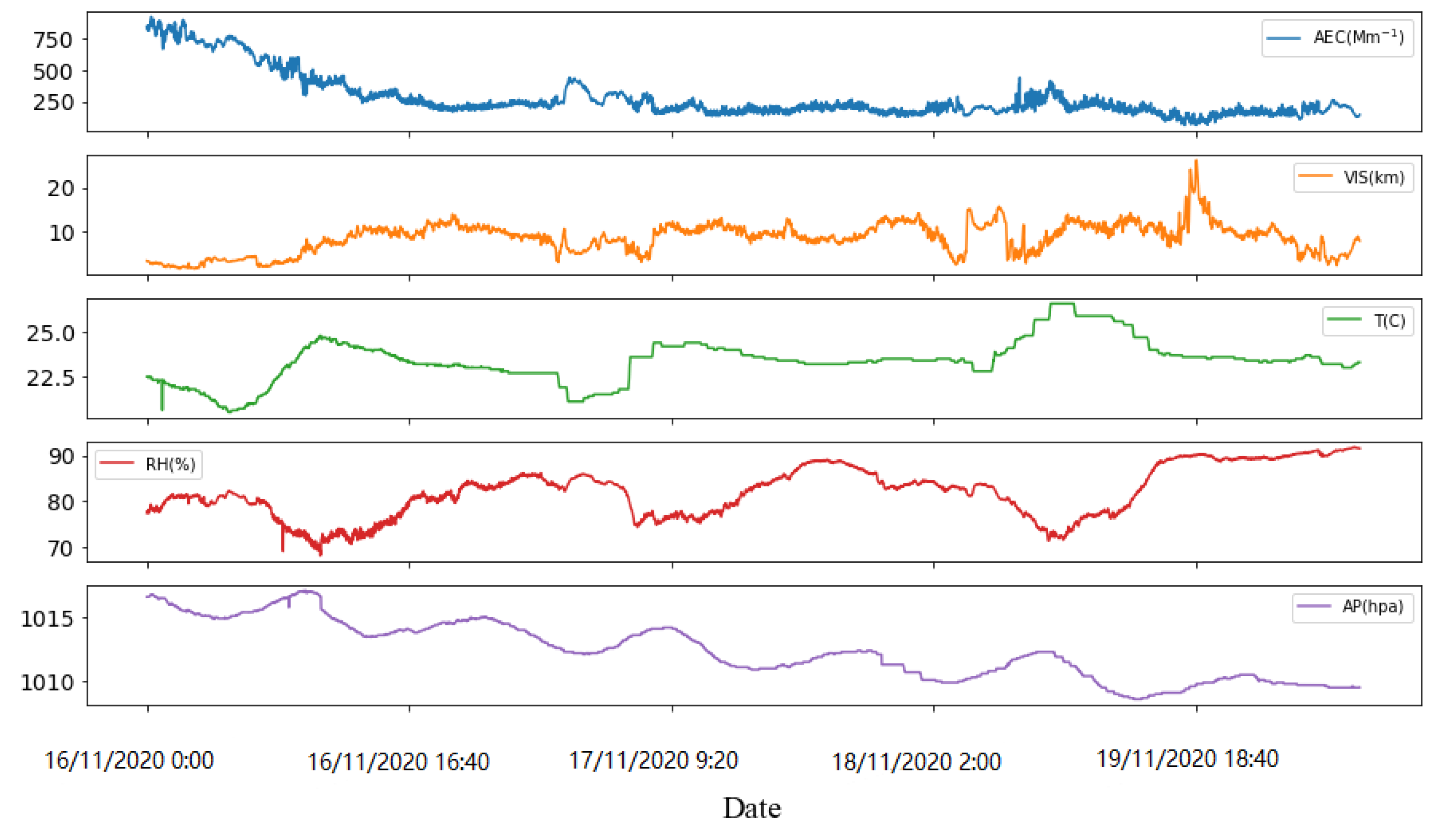
3.1. Data Description
- Marine meteorological science experiment base at Bohe, Maoming, is established and supported by the China Meteorological Administration and the Guangdong Institute of Tropical and Marine Meteorology. The station is a well-known and widely accepted experimental point for marine environment monitoring and marine climate studies.
- The terrain of the station here is flat, and it is easy to set up an observation platform; data measured and collected in this station can represent China’s typical coastal environments well;
- During that time, the weather was very good, and it was suitable for measuring coastal meteorological and atmospheric parameters.

- AEC, measured by CAPS-ALB. AEC is the target value predicted in the experiment.
- General meteorological parameters, measured by WXT520. The sensor data we used in the experiment include temperature, relative humidity, and air pressure.
- Visibility, measured by SWS-100. There is no doubt that visibility is an important parameter affecting AEC. For higher accuracy, visibility is measured by SWS-100 as an independent parameter in this experiment.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description |
|---|---|
| Date | Observation date |
| AEC | Observed actual value of AEC |
| VIS | Observed actual value of visibility |
| T | Observed actual value of temperature |
| RH | Observed actual value of relative humidity |
| AP | Observed actual value of air pressure |
3.2. Evaluation Metrics for Prediction Capacity
- is the average value of the absolute error between the predicted value and the actual value , and N represents the size of the test set. It can better reflect the actual situation of the predicted value error. The specific equation is:
- is the arithmetic square root of the Mean Squared Errors (), and is the expected value of the square of the difference between the estimated value of the parameter and the true value of the parameter. represents the deviation of the square root between and in the total data size ratio. The smaller the value is, the better the accuracy of the prediction model to describe the experimental data. The equation can be expressed by the following formula:
- To analyze the prediction ability improvement of the proposed method, is chosen to measures how well the predicted values fit the true values. is the ratio of the regression sum of squares to the total deviation of squares. The larger the ratio, the more accurate the model and the more significant the regression effect:offsets the impact of the number of samples on R and is suitable for multiple features time series forecasting. can be defined as follows:where P is the number of features. Ordinary R is suitable for describing the strength of the model’s fitting ability when describing individual features. However, as the number of samples increases, R will inevitably increase, so this paper chooses .
- and represent the improvements in and , respectively. These indicators are defined as follows:
4. Experimental Results
4.1. Data Processing
- Different features have different scales, in order to eliminate the influence of the unit and scale differences between features and treat each dimension feature equally, it is necessary to normalize the features.
- For the loss function of the model, gradient descent converges faster after feature scaling.
4.2. Comparison Methods
- MLP methodMLP is a class of feed-forward (FF) NNs. MLP utilizes a supervised learning technique called back-propagation for training. Its multiple layers and non-linear activation distinguish MLP from a linear perceptron. It can distinguish data that are not linearly separable.
- GRU methodGRU is a variant of the LSTM neural network [37]. It combines the forget and output gates in the LSTM into a new gate called the update gate to obtain fewer parameters and faster training speeds. GRU has been shown to exhibit better performance on certain smaller and less frequent datasets.
- BiLSTM-Attention methodThis method is similar to the proposed method in this paper. The difference is that this method puts attention after BiLSTM.
4.3. Results Analysis and Discussion
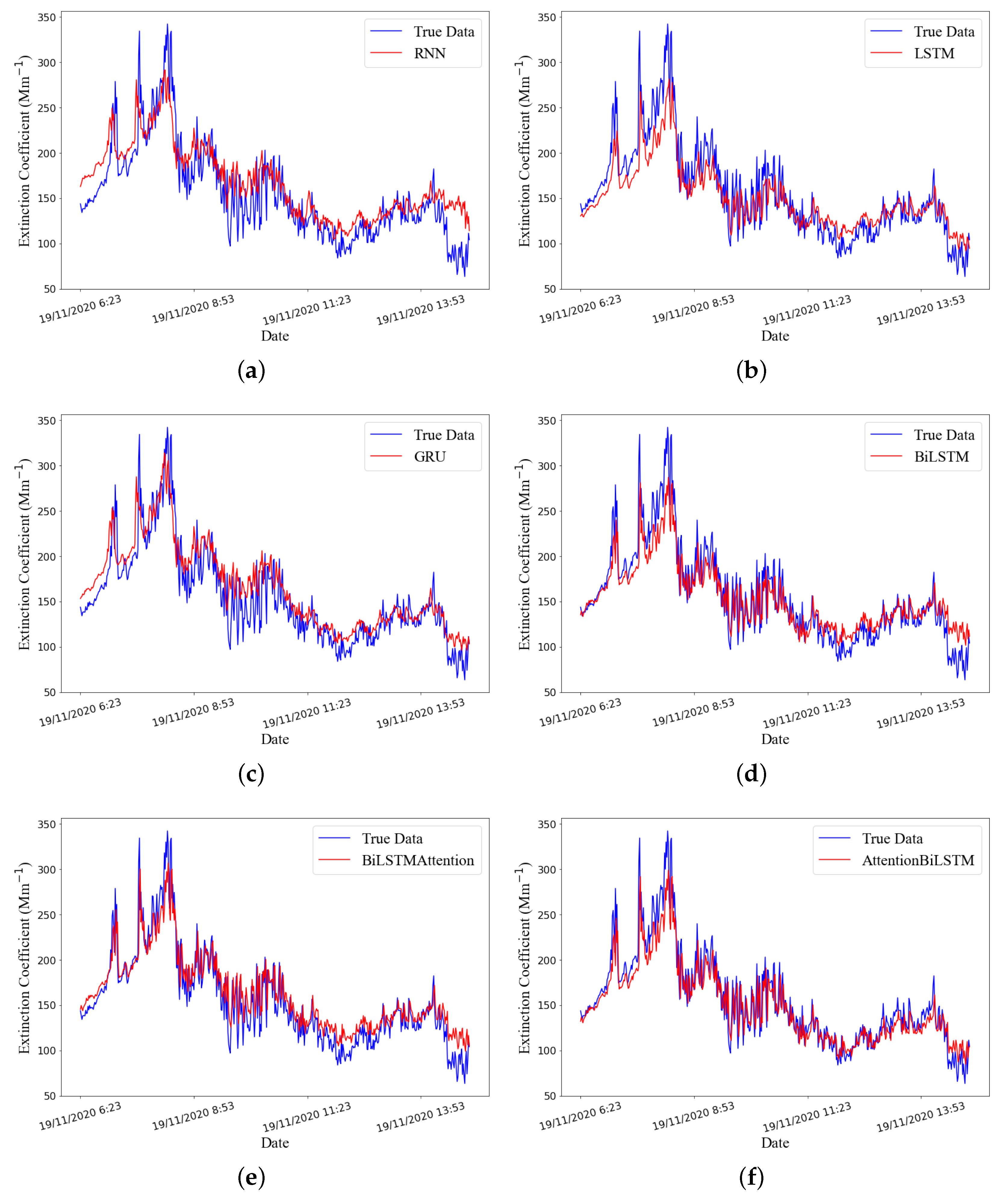
- Models based on LSTM obtain better performance than the traditional RNN model.As Table 2 and Table 3 show that for the AEC prediction in the Maoming area, the LSTM and LSTM variants have higher prediction accuracy than RNN. For instance, compared with the MLP, other methods’ percentage improvements in were , , , , , and , respectively, in dataset A, while they were , , , , , and , respectively, in dataset B; the percentage improvements in were , , , , , and , respectively, in dataset A, while they were , , , , , and , respectively, in dataset B.Figure 8 shows the estimated prediction error results of different AEC prediction methods in APM. According to this figure, some positive findings could be obtained: (1) LSTM methods have higher prediction accuracy than traditional methods in AEC prediction; (2) compared with normal LSTM methods, the forecasting capacities of BiLSTM approaches is superior; and (3) the attention mechanism can slightly improve the accuracy of prediction.
- The BiLSTM model based on the attention mechanism achieves a better prediction effect than other methods.Figure 9 shows different methods’ performances in a Taylor diagram, which is often used to evaluate the accuracy of models. The scatter in the Taylor diagram represents the model; the radial distance from the dot represents the ratio of the standard deviation of the model to the observation, indicating the model’s ability to simulate the center amplitude. The closer the standard deviation is to one, the better the simulation ability; is a measure of the distance between the model and the observation, represented in the figure as a dotted green semicircle with point A as the center; the correlation coefficient is determined by the azimuth position of the model. When the model prediction result is more consistent with the observed value, the closer the model point is to the observation point in the x-axis; thus, the model has a high correlation with the observation. This figure shows that the method proposed in this paper obtains the best performance in AEC prediction than other traditional NN methods.
5. Concluding Remarks
- Different meteorological parameters need to be added as features in the future. According to attention mechanism theory, our method will automatically adjusts the weights of different features.
- More geographic locations should be selected for prediction, which will make experimental results more convincing.
- Long-sequence time-series forecasting (LSTF) must be considered. In practical application problems, we need to forecast long time series. Our next work, we will focus on improving the forecast time and making the research more practical while ensuring the forecast accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramanathan, V.; Crutzen, P.J.; Kiehl, J.; Rosenfeld, D. Aerosols, climate, and the hydrological cycle. Science 2001, 294, 2119–2124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lyamani, H.; Olmo, F.; Alados-Arboledas, L. Light scattering and absorption properties of aerosol particles in the urban environment of Granada, Spain. Atmos. Environ. 2008, 42, 2630–2642. [Google Scholar] [CrossRef]
- Griggs, M. Measurements of atmospheric aerosol optical thickness over water using ERTS-1 data. J. Air Pollut. Control Assoc. 1975, 25, 622–626. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remer, L.A.; Kaufman, Y.J.; Holben, B.N. Interannual variation of ambient aerosol characteristics on the east coast of the United States. J. Geophys. Res. Atmos. 1999, 104, 2223–2231. [Google Scholar] [CrossRef]
- Kanakidou, M.; Seinfeld, J.; Pandis, S.; Barnes, I.; Dentener, F.J.; Facchini, M.C.; Dingenen, R.V.; Ervens, B.; Nenes, A.; Nielsen, C.; et al. Organic aerosol and global climate modelling: A review. Atmos. Chem. Phys. 2005, 5, 1053–1123. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, Y.J.; Tanré, D.; Boucher, O. A satellite view of aerosols in the climate system. Nature 2002, 419, 215–223. [Google Scholar] [CrossRef]
- Chatterjee, A.; Michalak, A.M.; Kahn, R.A.; Paradise, S.R.; Braverman, A.J.; Miller, C.E. A geostatistical data fusion technique for merging remote sensing and ground-based observations of aerosol optical thickness. J. Geophys. Res. Atmos. 2010, 115. [Google Scholar] [CrossRef] [Green Version]
- Gathman, S.G. Optical properties of the marine aerosol as predicted by the Navy aerosol model. Opt. Eng. 1983, 22, 220157. [Google Scholar] [CrossRef]
- Vignati, E.; De Leeuw, G.; Berkowicz, R. Modeling coastal aerosol transport and effects of surf-produced aerosols on processes in the marine atmospheric boundary layer. J. Geophys. Res. Atmos. 2001, 106, 20225–20238. [Google Scholar] [CrossRef] [Green Version]
- Tedeschi, G.; Piazzola, J. Development of a 2D marine aerosol transport model: Application to the influence of thermal stability in the marine atmospheric boundary layer. Atmos. Res. 2011, 101, 469–479. [Google Scholar] [CrossRef]
- Piazzola, J.J.; Kaloshin, G.; De Leeuw, G.; van Eijk, A.M. Aerosol extinction in coastal zones. In Proceedings of the Optics in Atmospheric Propagation and Adaptive Systems VII; International Society for Optics and Photonics: Bellingham, WA, USA, 2004; Volume 5572, pp. 94–100. [Google Scholar]
- Pan, Y.; Cui, S.; Rao, R. A model for predicting coastal aerosol size distributions in Chinese seas. Earth Space Sci. 2020, 7, e2020EA001136. [Google Scholar] [CrossRef]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in Java Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Gupta, N. Artificial neural network. Netw. Complex Syst. 2013, 3, 24–28. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: Delhi, India, 2009. [Google Scholar]
- Pal, N.R.; Pal, S.; Das, J.; Majumdar, K. SOFM-MLP: A hybrid neural network for atmospheric temperature prediction. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2783–2791. [Google Scholar] [CrossRef]
- Haiming, Z.; Xiaoxiao, S. Study on prediction of atmospheric PM2.5 based on RBF neural network. In Proceedings of the 2013 Fourth International Conference on Digital Manufacturing & Automation, Qindao, China, 29–30 June 2013; pp. 1287–1289. [Google Scholar]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Hüsken, M.; Stagge, P. Recurrent neural networks for time series classification. Neurocomputing 2003, 50, 223–235. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1310–1318. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured attention networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Shih, S.Y.; Sun, F.K.; Lee, H.Y. Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef] [Green Version]
- Adil, M.; Wu, J.Z.; Chakrabortty, R.K.; Alahmadi, A.; Ansari, M.F.; Ryan, M.J. Attention-Based STL-BiLSTM Network to Forecast Tourist Arrival. Processes 2021, 9, 1759. [Google Scholar] [CrossRef]
- Liu, D.; Tang, L.; Shen, G.; Han, X. Traffic speed prediction: An attention-based method. Sensors 2019, 19, 3836. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Jing, H.; Chang, Y.; Liu, Q. Gated recurrent unit based recurrent neural network for remaining useful life prediction of nonlinear deterioration process. Reliab. Eng. Syst. Saf. 2019, 185, 372–382. [Google Scholar] [CrossRef]










| Prediction Approaches | |||
|---|---|---|---|
| RNN | 33.1% | 36.8% | 0.679 |
| LSTM | 41.8% | 45.0% | 0.758 |
| GRU | 47.4% | 48.8% | 0.804 |
| BiLSTM | 50.0% | 51.5% | 0.821 |
| BiLSTM-Attention | 51.0% | 55.0% | 0.829 |
| Proposed Method | 52.8% | 56.6% | 0.84 |
| Prediction Approaches | |||
|---|---|---|---|
| RNN | 21.1% | 16.4% | 0.727 |
| LSTM | 30.4% | 28.0% | 0.788 |
| GRU | 33.0% | 31.4% | 0.808 |
| BiLSTM | 36.3% | 34.6% | 0.822 |
| BiLSTM-Attention | 46.2% | 44.9% | 0.873 |
| Proposed Method | 51.3% | 51.4% | 0.896 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Cui, S.; Qiao, Z.; Zhang, Z.; Zhu, W.; Li, X.; Qian, X. Prediction of Aerosol Extinction Coefficient in Coastal Areas of South China Based on Attention-BiLSTM. J. Mar. Sci. Eng. 2022, 10, 545. https://doi.org/10.3390/jmse10040545
Ye Z, Cui S, Qiao Z, Zhang Z, Zhu W, Li X, Qian X. Prediction of Aerosol Extinction Coefficient in Coastal Areas of South China Based on Attention-BiLSTM. Journal of Marine Science and Engineering. 2022; 10(4):545. https://doi.org/10.3390/jmse10040545
Chicago/Turabian StyleYe, Zhou, Shengcheng Cui, Zhi Qiao, Zihan Zhang, Wenyue Zhu, Xuebin Li, and Xianmei Qian. 2022. "Prediction of Aerosol Extinction Coefficient in Coastal Areas of South China Based on Attention-BiLSTM" Journal of Marine Science and Engineering 10, no. 4: 545. https://doi.org/10.3390/jmse10040545