
Estimating Body Weight in Captive Rabbits Based on Improved Mask RCNN

Abstract
:1. Introduction
2. Materials and Methods
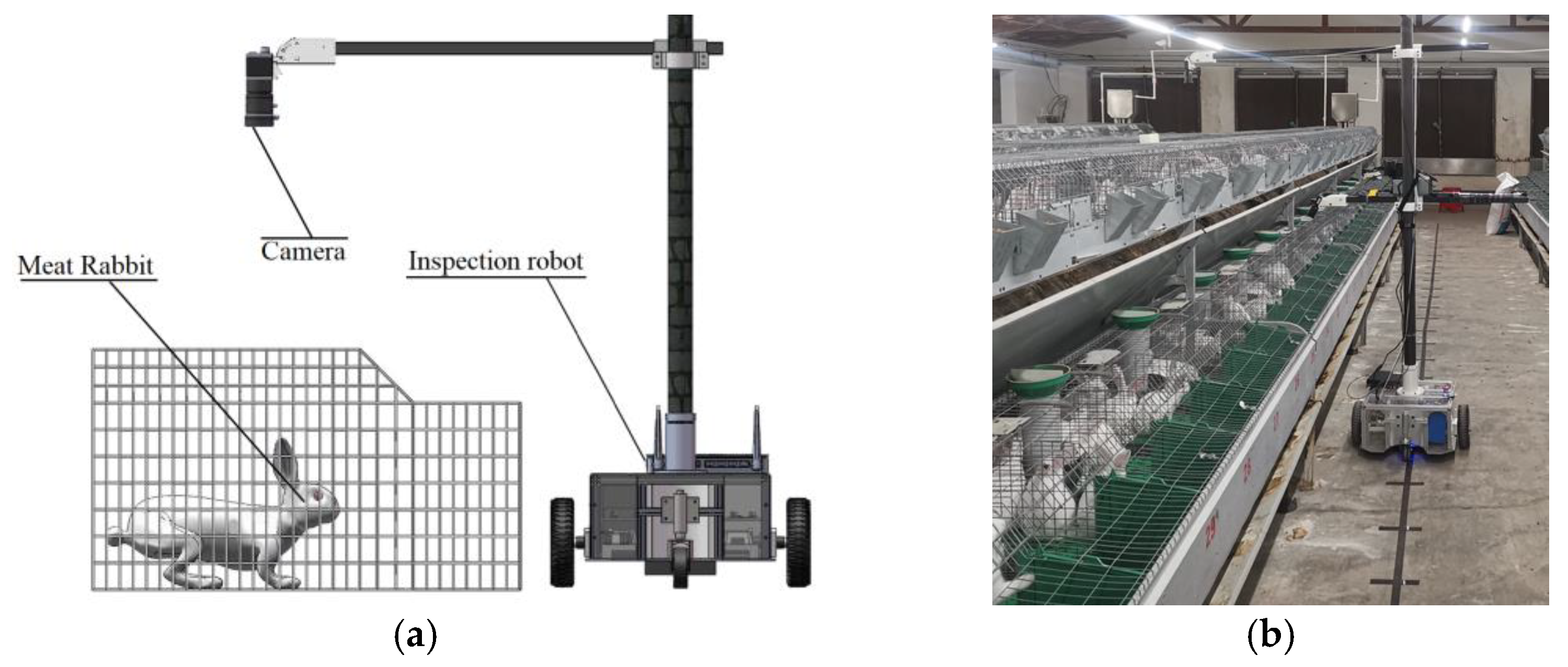
2.1. Data Acquisition
2.2. Meat Rabbit Instance Segmentation Network Based on Improved Mask RCNN
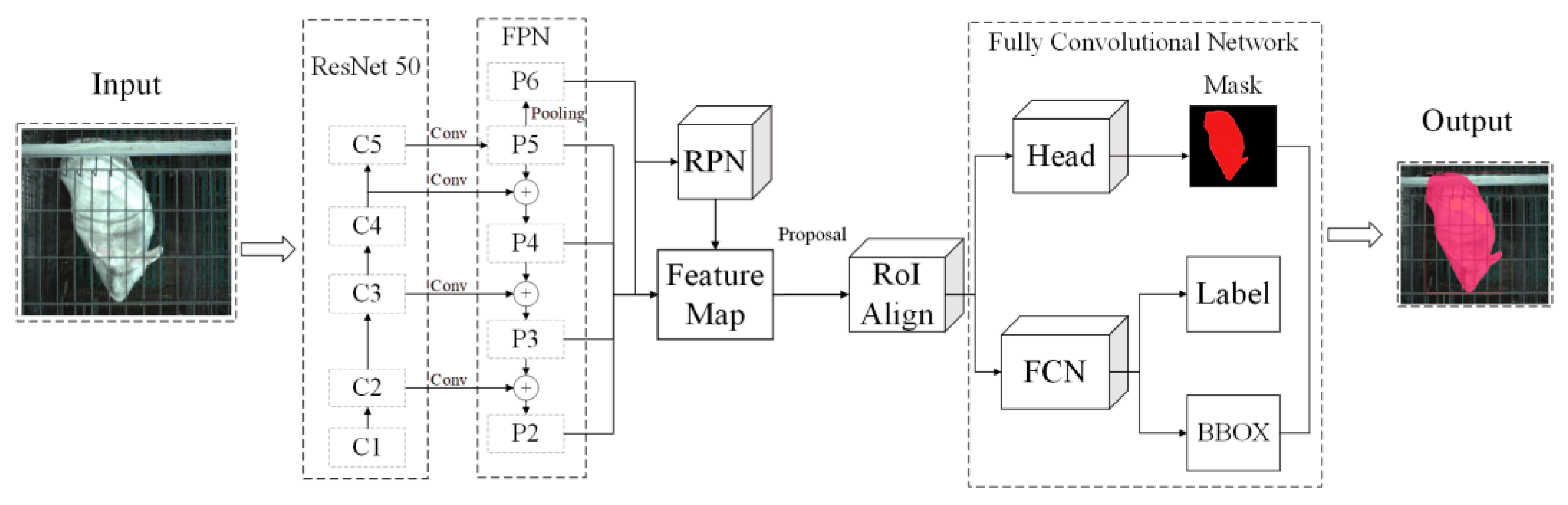
2.2.1. The Structure of Mask RCNN
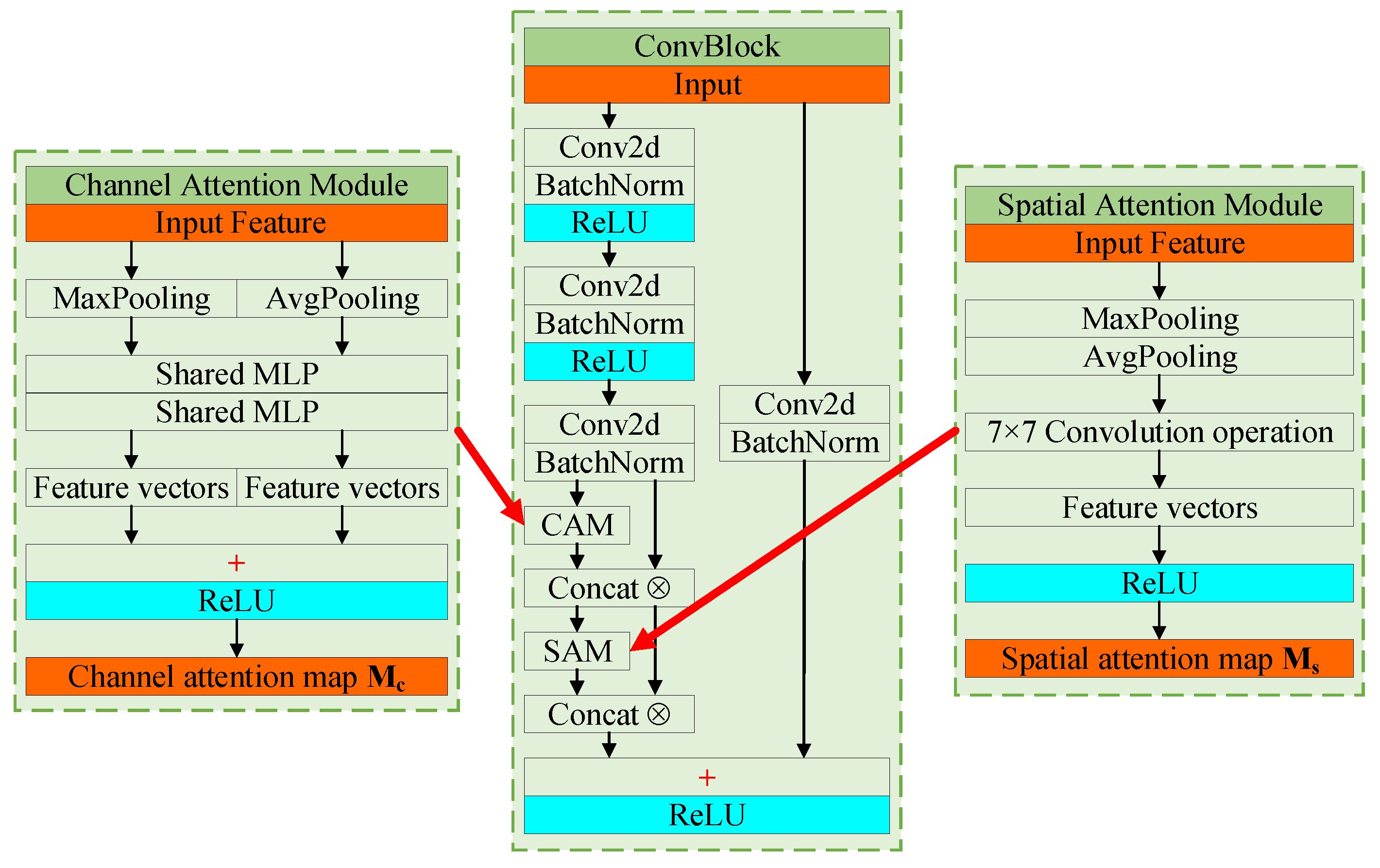
2.2.2. Optimized Backbone Network Based on Attention Mechanism
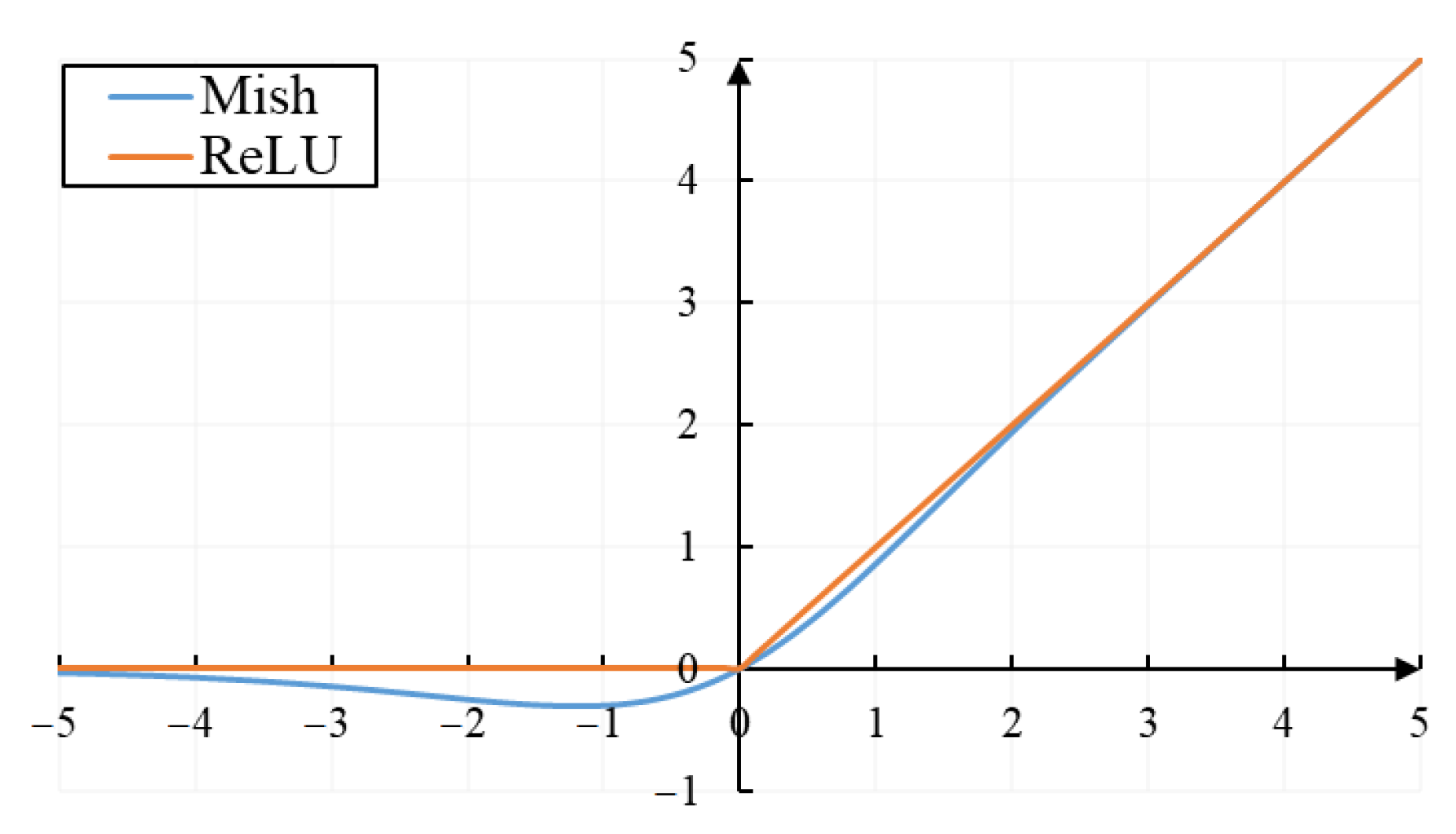
2.2.3. Optimized Backbone Network Based on Improved Activation Function
2.2.4. Optimized Boundary Feature Based on PointRend Technique
2.2.5. Data Acquisition and Dataset Construction
2.3. Feature Extraction of Rabbit Body
2.3.1. Pretreatment of Rabbit Mask Image
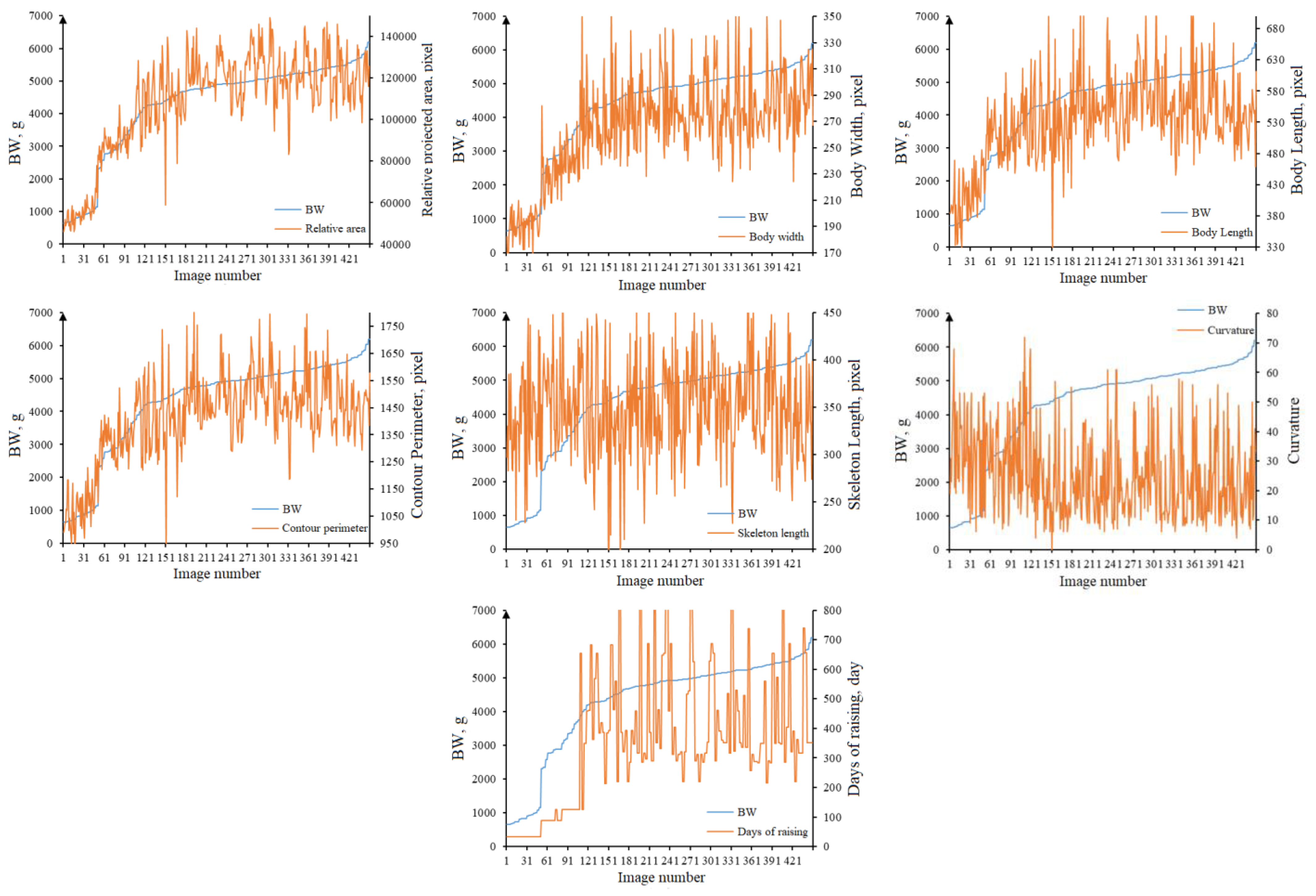
2.3.2. Feature Extraction
2.4. Rabbit Weight Regression Model Based on Optimized Machine Learning
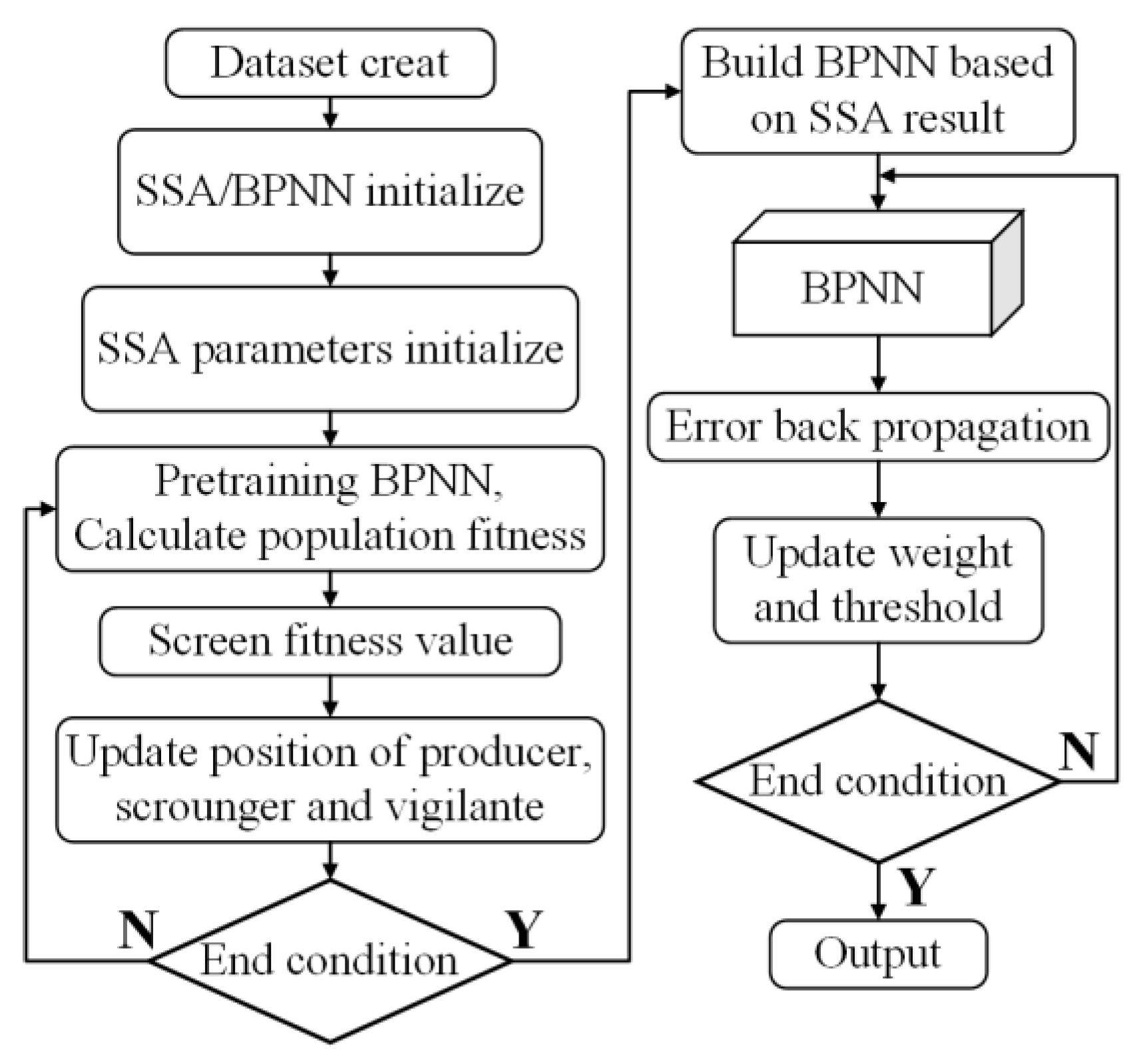
2.4.1. Sparrow Search Algorithm
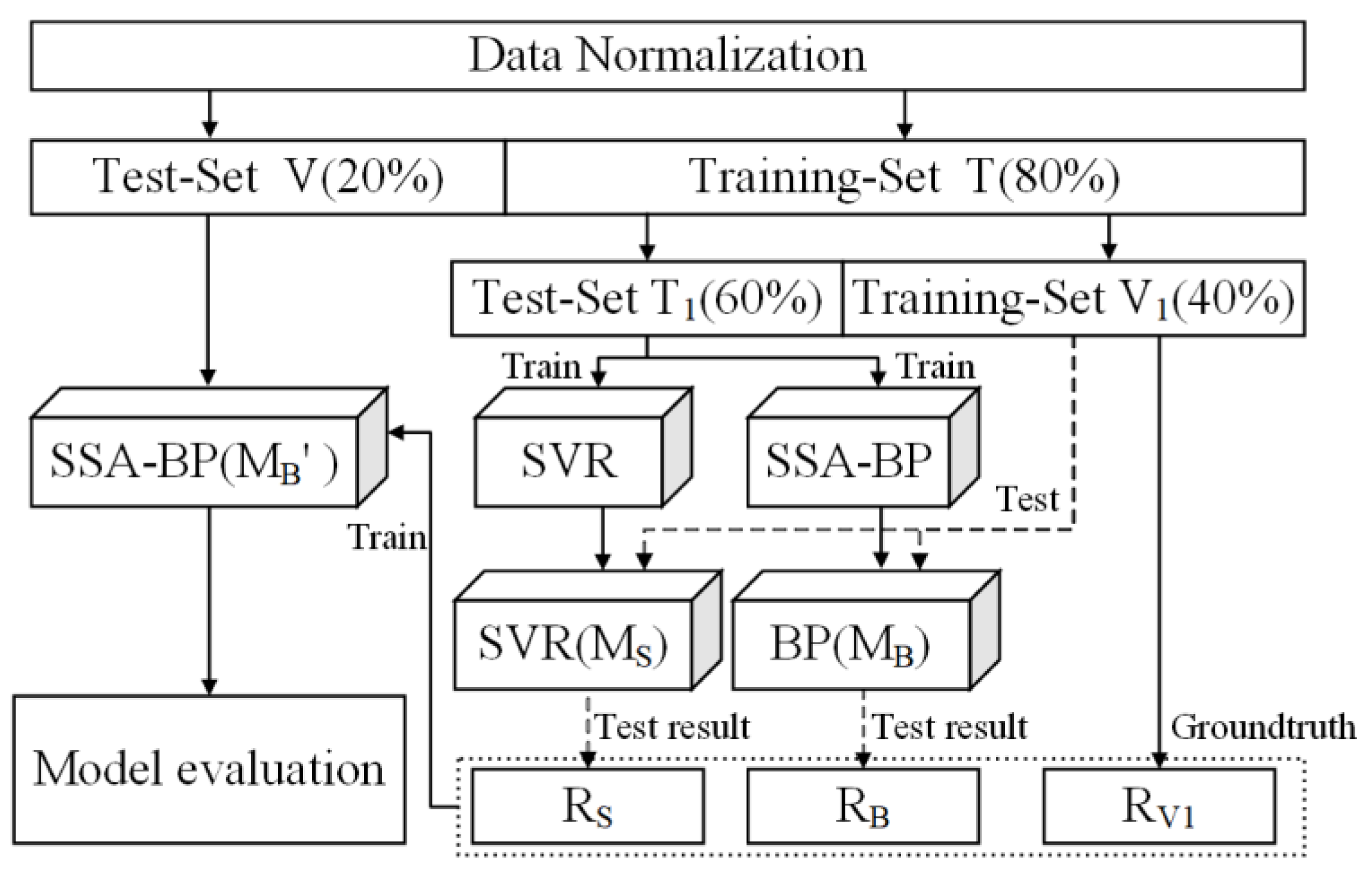
2.4.2. Meat Rabbit Weight Regression Model Based on SVR-SSA-BPNN
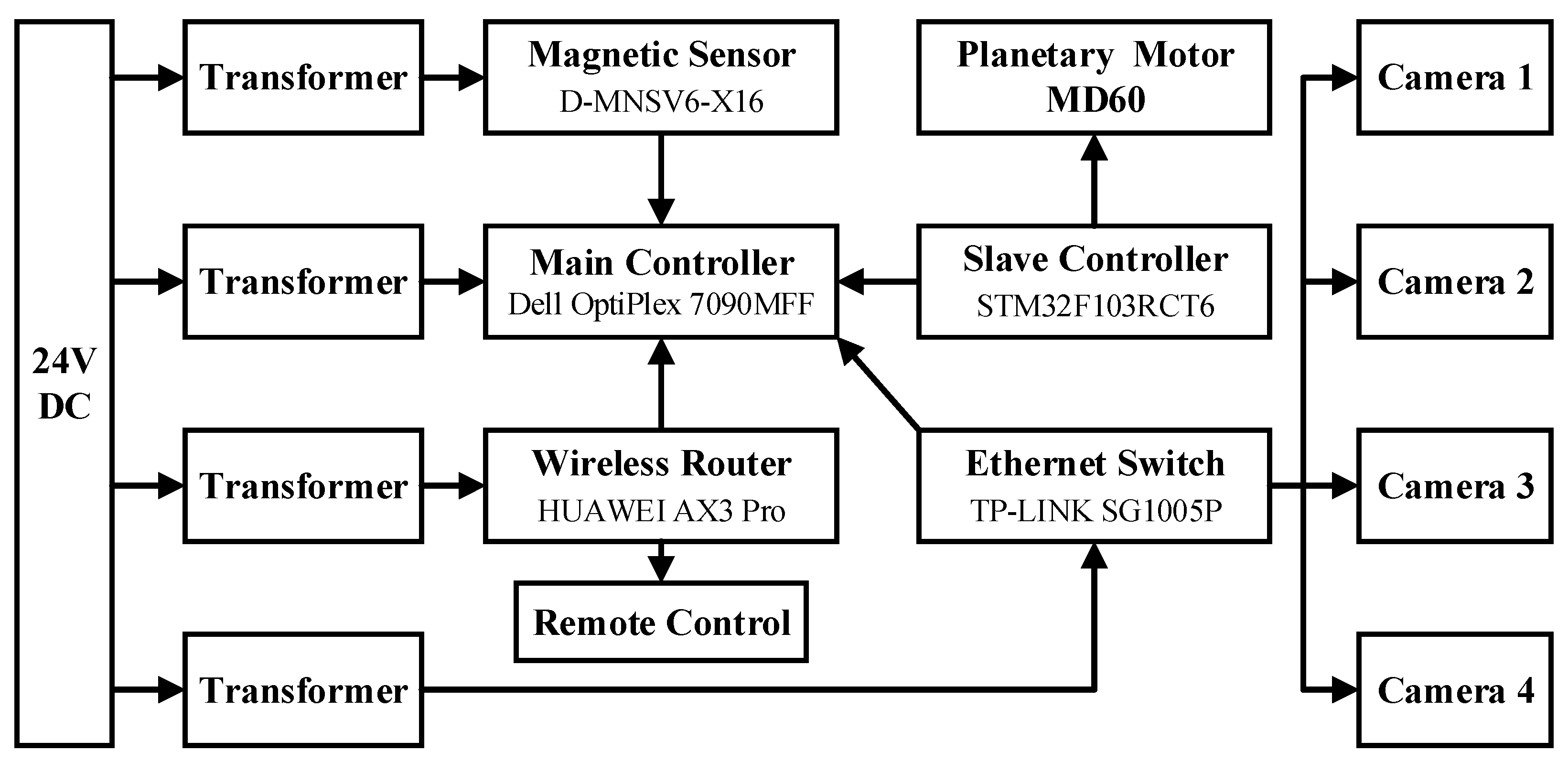
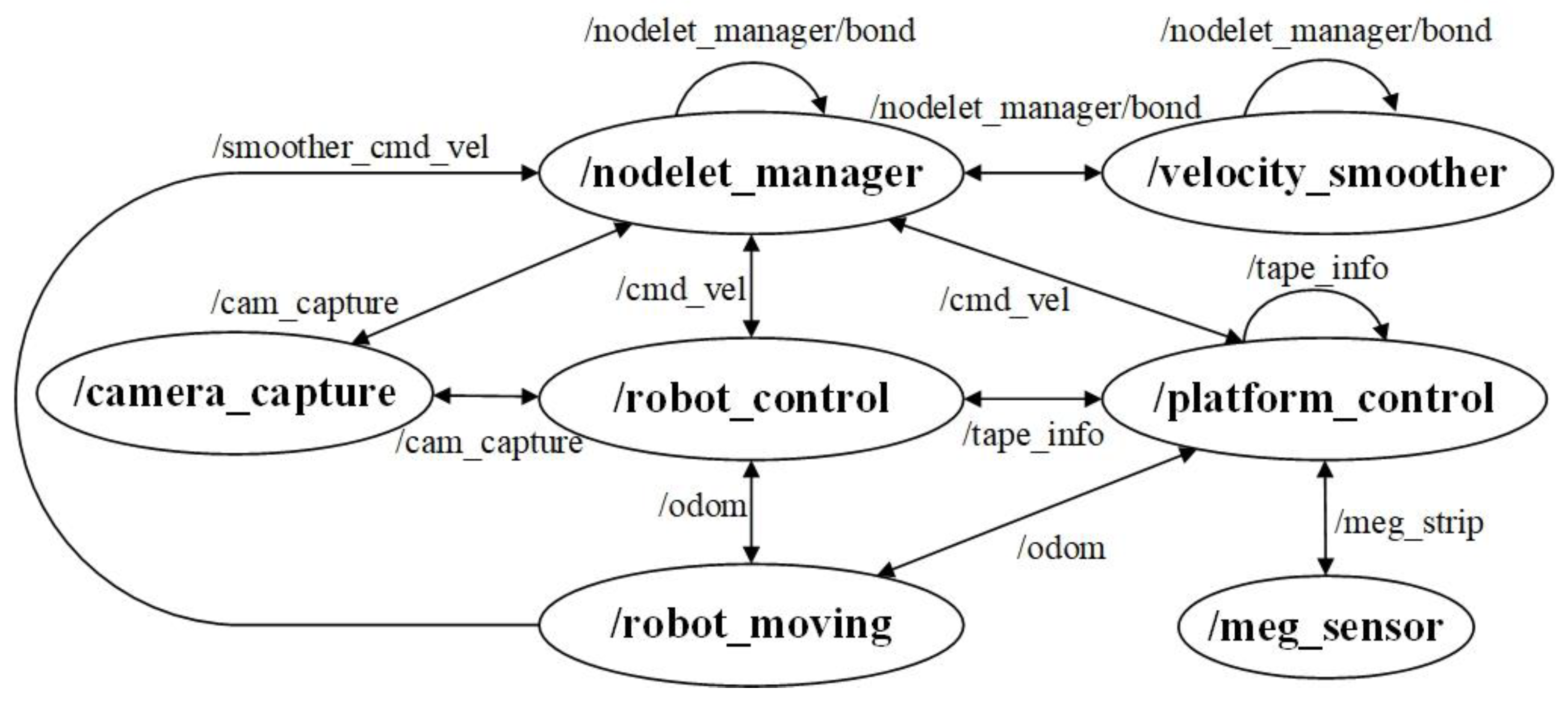
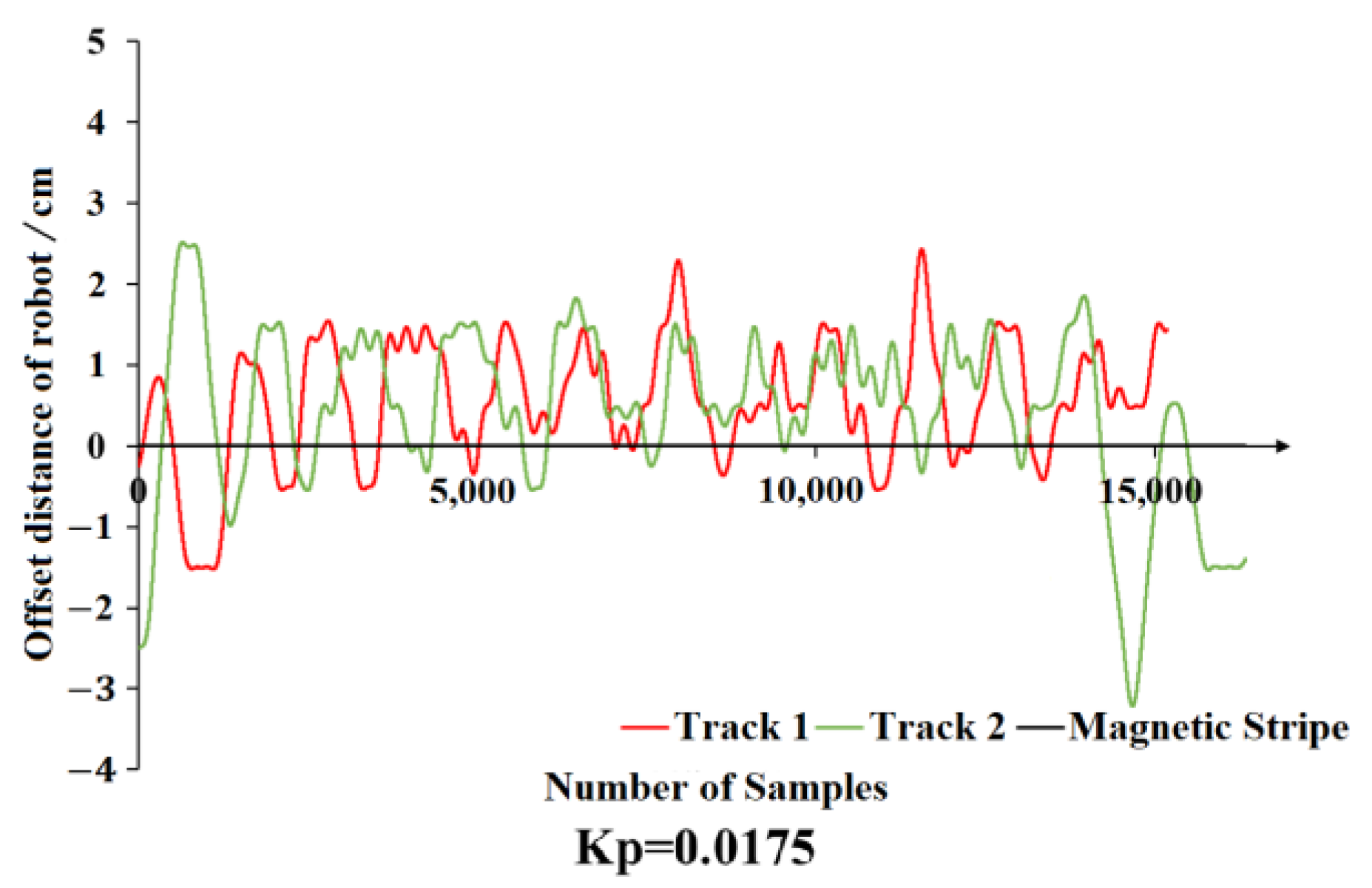
2.5. Algorithm Platform
3. Results
3.1. Performance of Meat Rabbit Instance Segmentation Network
3.1.1. Network Group and Performance Evaluation Indexes
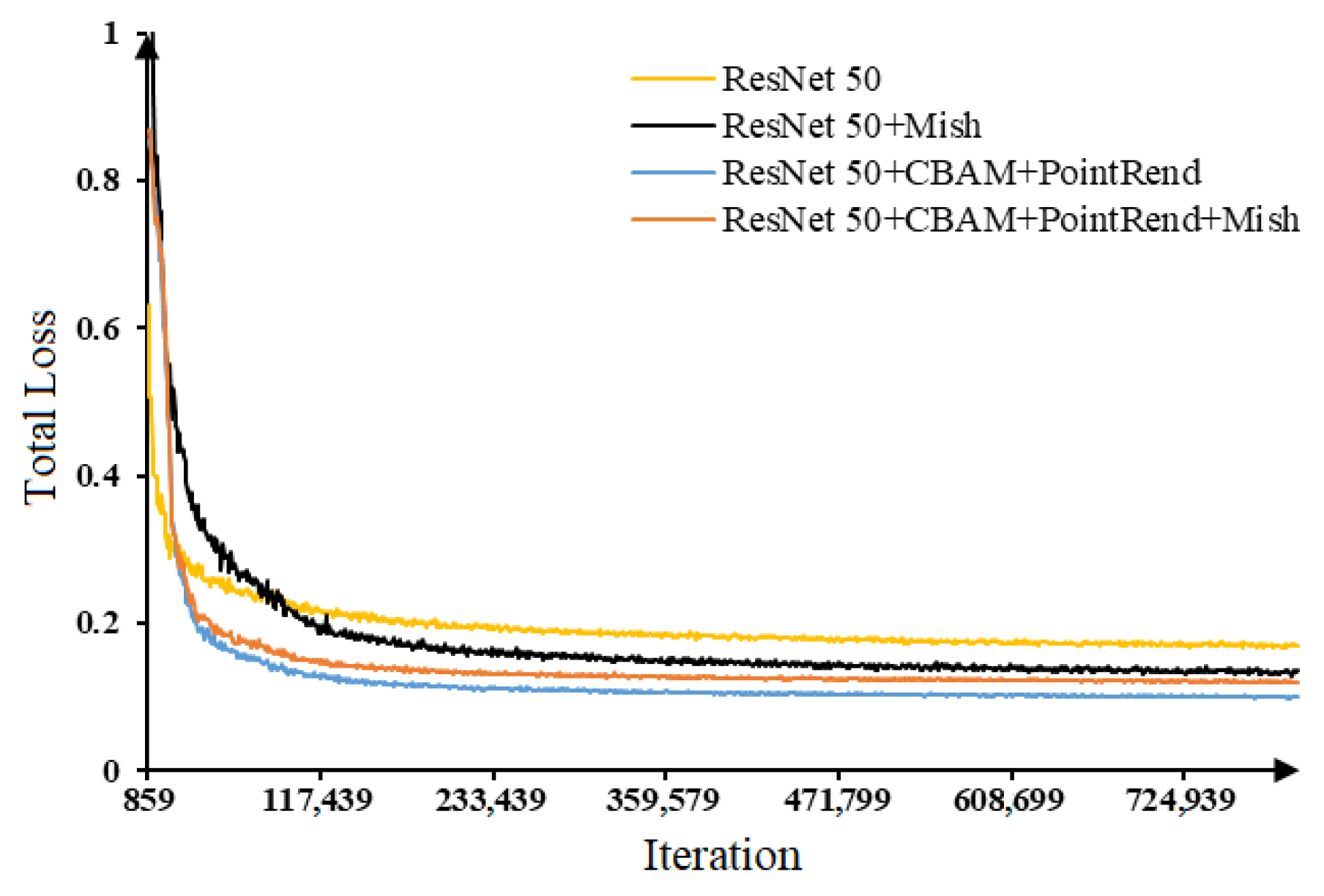
3.1.2. Performance of Improved Mask RCNN
3.2. Performance of Meat Rabbit Weight Estimation Network
3.2.1. The Dataset of Meat Rabbit Weight Estimation Network
3.2.2. Weight Estimation Network Performance Evaluation Indexes
3.2.3. Parameter Tuning of BPNN, SVR, and SSA
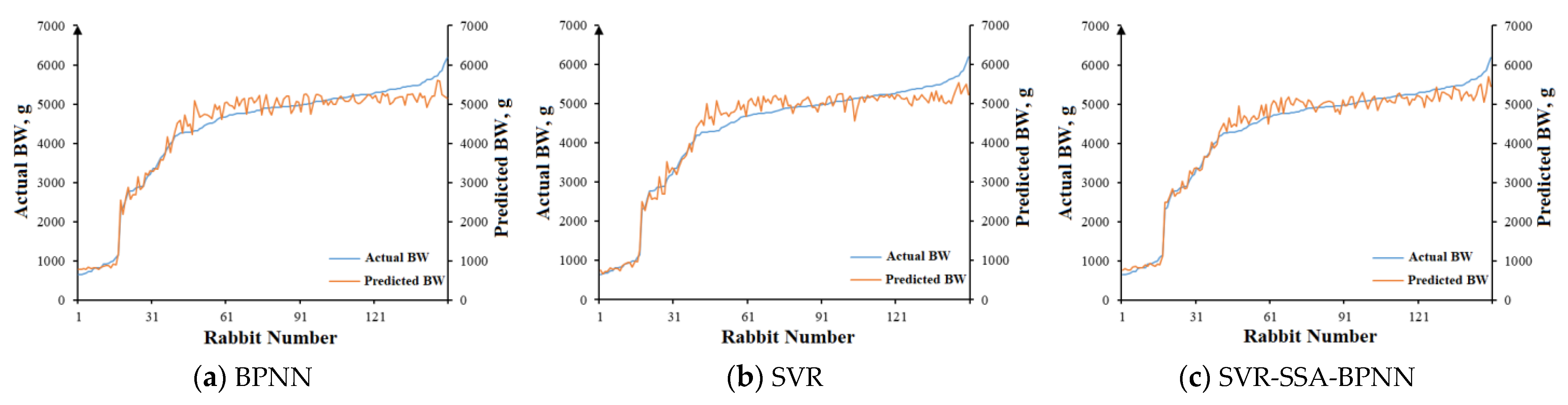
3.2.4. Performance of the Meat Rabbit Weight Estimation Network
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nyalala, I.; Okinda, C.; Kunjie, C.; Korohou, T.; Nyalala, L.; Chao, Q. Weight and volume estimation of poultry and products based on computer vision systems: A review. Poult. Sci. 2021, 100, 101072. [Google Scholar] [CrossRef] [PubMed]
- Mortensen, A.K.; Lisouski, P.; Ahrendt, P. Weight prediction of broiler chickens using 3D computer vision. Comput. Electron. Agric. 2016, 123, 319–326. [Google Scholar] [CrossRef]
- Amraei, S.; Abdanan Mehdizadeh, S.; Salari, S. Broiler weight estimation based on machine vision and artificial neural network. Brit. Poult. Sci. 2017, 58, 200–205. [Google Scholar] [CrossRef] [PubMed]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.P.H.; Niewold, T.A.; Ödberg, F.O.; Berckmans, D. Automatic weight estimation of individual pigs using image analysis. Comput. Electron. Agric. 2014, 107, 38–44. [Google Scholar] [CrossRef]
- Zhuang, C.; Shen, M.; Liu, L.; Yao, W.; Zheng, H.; Wang, M. Weight estimation model of breeding chickens based on neural network and machine learning. J. Chin. Agric. Univ. 2021, 26, 107–114. [Google Scholar]
- Wang, L.; Sun, C.; Li, W.; Ji, Z.; Zhang, X.; Wang, Y.; Lei, P.; Yang, X. Establishment of broiler quality estimation model based on depth image and BP neural network. Trans. Chin. Soc. Agric. Eng. 2017, 33, 199–205. [Google Scholar]
- Kuzuhara, Y.; Kawamura, K.; Yoshitoshi, R.; Tamaki, T.; Sugai, S.; Ikegami, M.; Kurokawa, Y.; Obitsu, T.; Sugino, T.; Yasuda, T. A preliminarily study for predicting body weight and milk properties in lactating Holstein cows using a three-dimensional camera system. Comput. Electron. Agric. 2015, 111, 186–193. [Google Scholar] [CrossRef]
- Duan, E.; Fang, P.; Wang, H.; Jin, N. Meat rabbit image segmentation and weight estimation model based on deep convolution neural network. Trans. Chin. Soc. Agric. Mach. 2021, 52, 259–267. [Google Scholar]
- Fairchild, C.; Harman, T.L. ROS Robotics by Example; Packt Publishing Ltd.: Birmingham, UK, 2016; ISBN 1785286706. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European confer-ence on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Mannam, V.; Zhang, Y.; Zhu, Y.; Nichols, E.; Wang, Q.; Sundaresan, V.; Zhang, S.; Smith, C.; Bohn, P.W.; Howard, S.S. Real-time image denoising of mixed Poisson–Gaussian noise in fluorescence microscopy images using ImageJ. Optica 2022, 9, 335–345. [Google Scholar] [CrossRef]
- Melnyk, R.; Hatsosh, D.; Levus, Y. Contacts detection in PCB image by thinning, clustering and flood-filling. In Proceedings of the 2021 IEEE 16th International Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 22–25 September 2021; pp. 370–374. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- LeCun, Y.; Touresky, D.; Hinton, G.; Sejnowski, T. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School, San Mateo, CA, USA; 1988; pp. 21–28. [Google Scholar]
- Huang, Z.; Liao, M.; Zhang, H.; Zhang, J.; Ma, S.; Zhu, Q. Predicting tunnel squeezing using the SVM-BP combination model. Geotech-Nical Geol. Eng. 2022, 40, 1387–1405. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AP/% | MPA/% | The Time Used for Single Image/ |
|---|---|---|---|
| A | 99.0 | 94.8 | 0.12 |
| B | 99.3 | 95.1 | 0.15 |
| C | 99.1 | 98.7 | 0.13 |
| D | 99.2 | 95.7 | 0.17 |
| Structure of Hidden Layer | Training Algorithms | r | RMSE | MAE |
|---|---|---|---|---|
| (4) | Trainlm | 0.969 | 356.8 | 278.2 |
| Trainbr | 0.971 | 347.5 | 276.1 | |
| Trainscg | 0.960 | 407.5 | 320.7 | |
| (5) | Trainlm | 0.968 | 358.9 | 278.2 |
| Trainbr | 0.973 | 334.5 | 261.2 | |
| Trainscg | 0.954 | 436.1 | 332.5 | |
| (6) | Trainlm | 0.971 | 341.8 | 267.9 |
| Trainbr | 0.973 | 335.2 | 261.8 | |
| Trainscg | 0.965 | 379.6 | 302.4 | |
| (4,6) | Trainlm | 0.967 | 365.7 | 288.6 |
| Trainbr | 0.975 | 323.1 | 246.9 | |
| Trainscg | 0.953 | 440.9 | 350.2 | |
| (5,6) | Trainlm | 0.971 | 346.9 | 259.5 |
| Trainbr | 0.980 | 291.2 | 223.0 | |
| Trainscg | 0.955 | 430.3 | 331.7 | |
| (6,5) | Trainlm | 0.971 | 356.0 | 271.6 |
| Trainbr | 0.964 | 385.0 | 275.8 | |
| Trainscg | 0.965 | 381.7 | 301.6 |
| Model | r | RMSE | MAE | δ, 100% |
|---|---|---|---|---|
| BPNN | 0.980 | 291.2 | 223.0 | 6.1 |
| SVR | 0.961 | 355.0 | 278.4 | 8.7 |
| SVR-SSA-BPNN | 0.987 | 227.3 | 172.7 | 4.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, E.; Hao, H.; Zhao, S.; Wang, H.; Bai, Z. Estimating Body Weight in Captive Rabbits Based on Improved Mask RCNN. Agriculture 2023, 13, 791. https://doi.org/10.3390/agriculture13040791
Duan E, Hao H, Zhao S, Wang H, Bai Z. Estimating Body Weight in Captive Rabbits Based on Improved Mask RCNN. Agriculture. 2023; 13(4):791. https://doi.org/10.3390/agriculture13040791
Chicago/Turabian StyleDuan, Enze, Hongyun Hao, Shida Zhao, Hongying Wang, and Zongchun Bai. 2023. "Estimating Body Weight in Captive Rabbits Based on Improved Mask RCNN" Agriculture 13, no. 4: 791. https://doi.org/10.3390/agriculture13040791