

MYOLO: A Lightweight Fresh Shiitake Mushroom Detection Model Based on YOLOv3
Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition
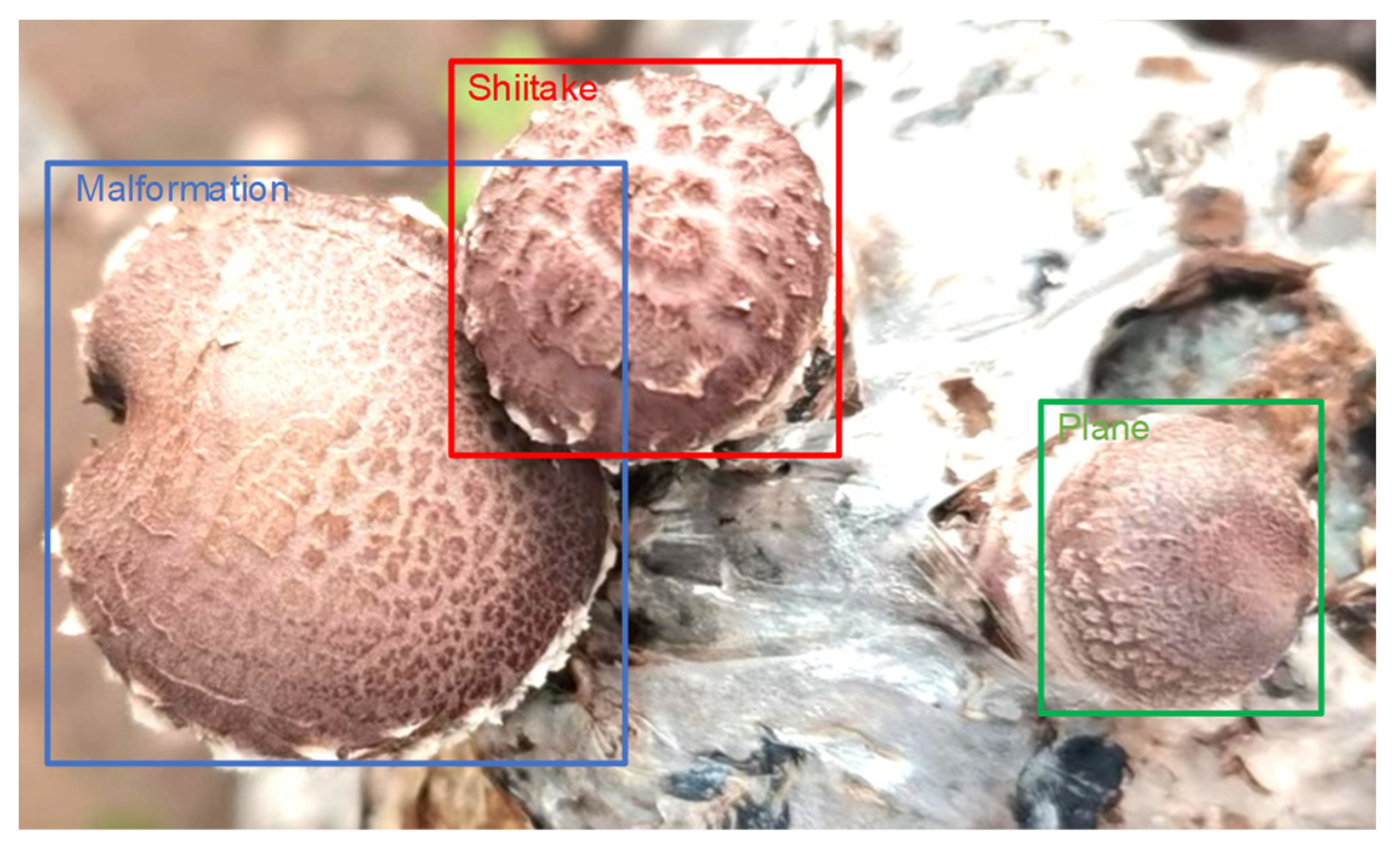
2.2. Image Datasets
2.3. Problems with the YOLOv3 Model
2.4. Model Improvements
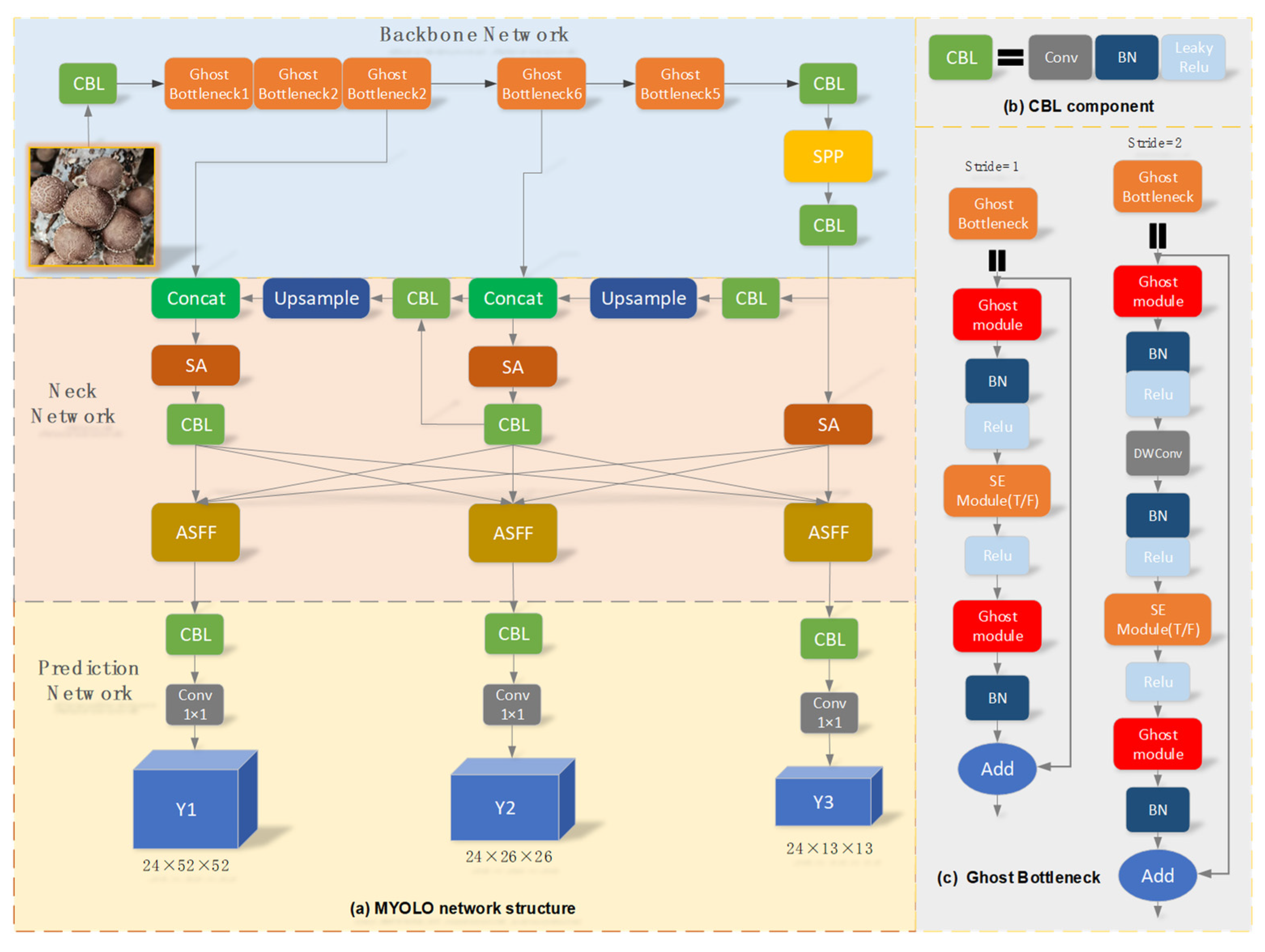
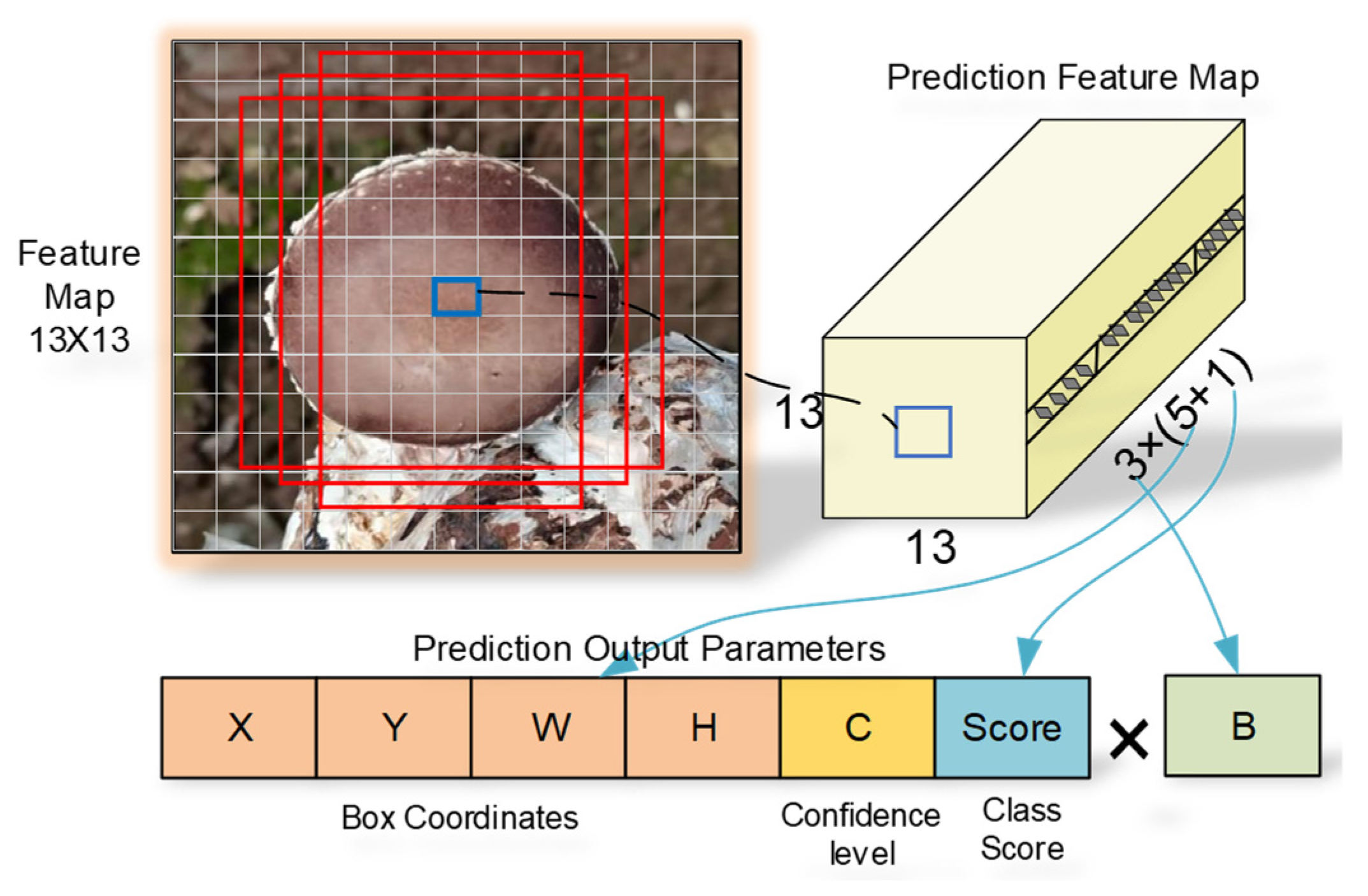
2.4.1. MYOLO Network Structure
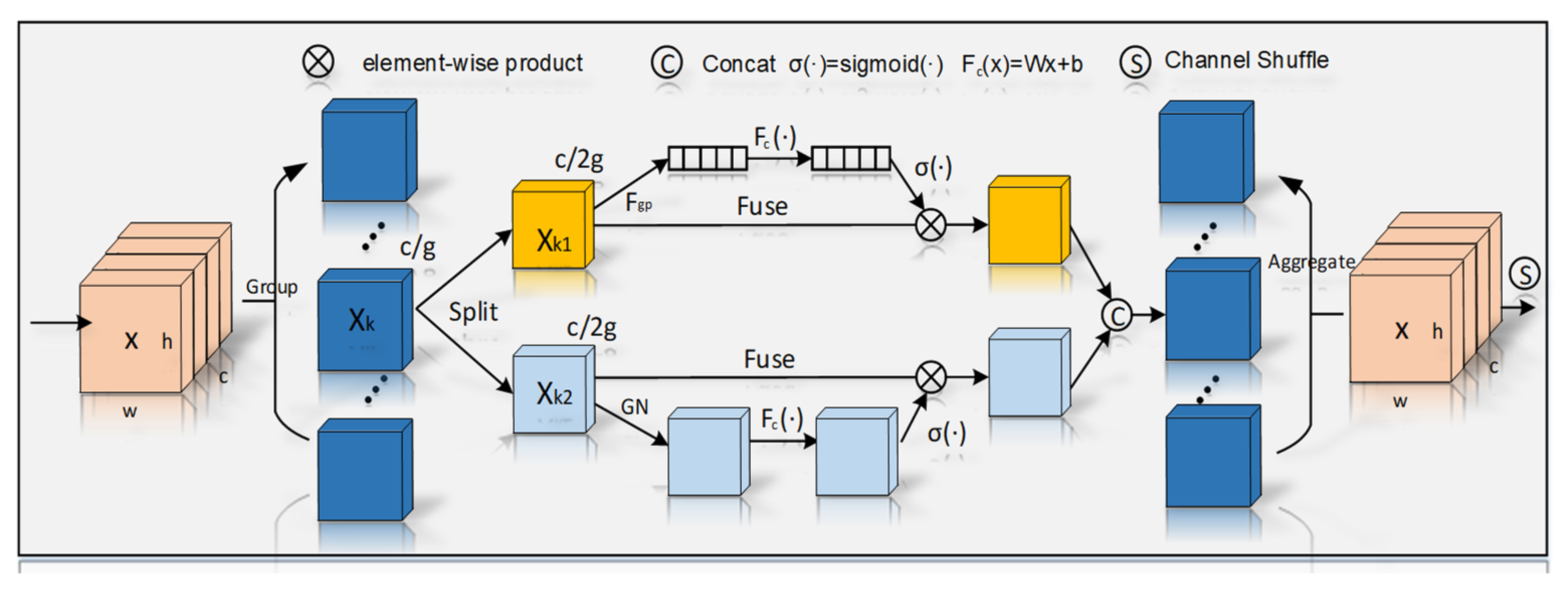
2.4.2. GhostNet16 Network Structure
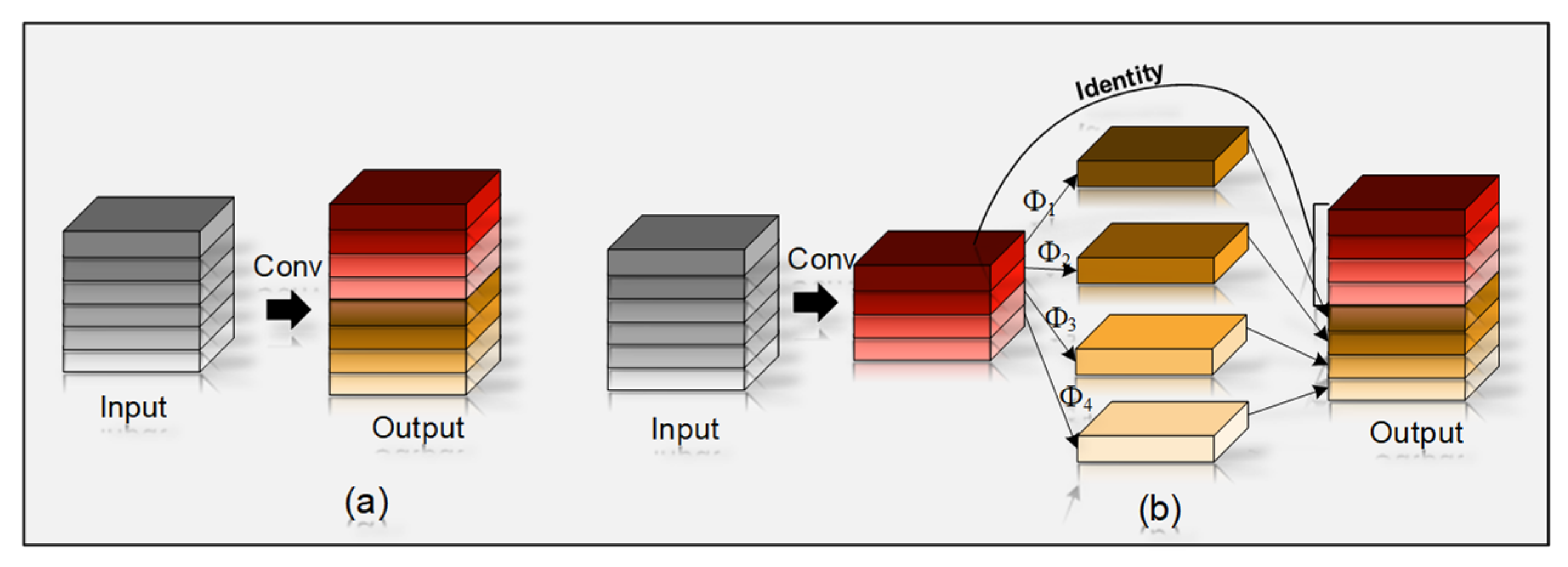
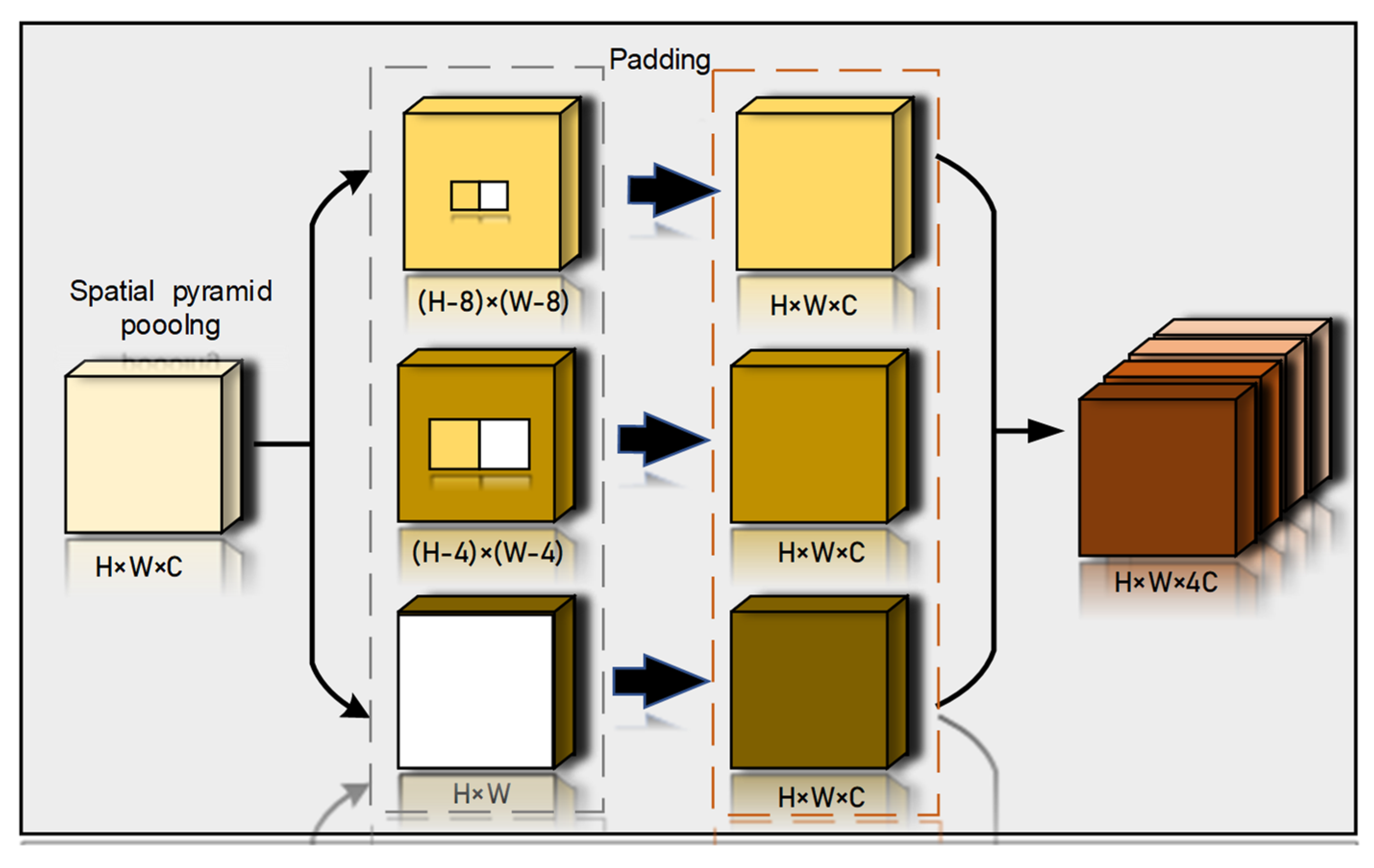
2.4.3. SPP Network Structure
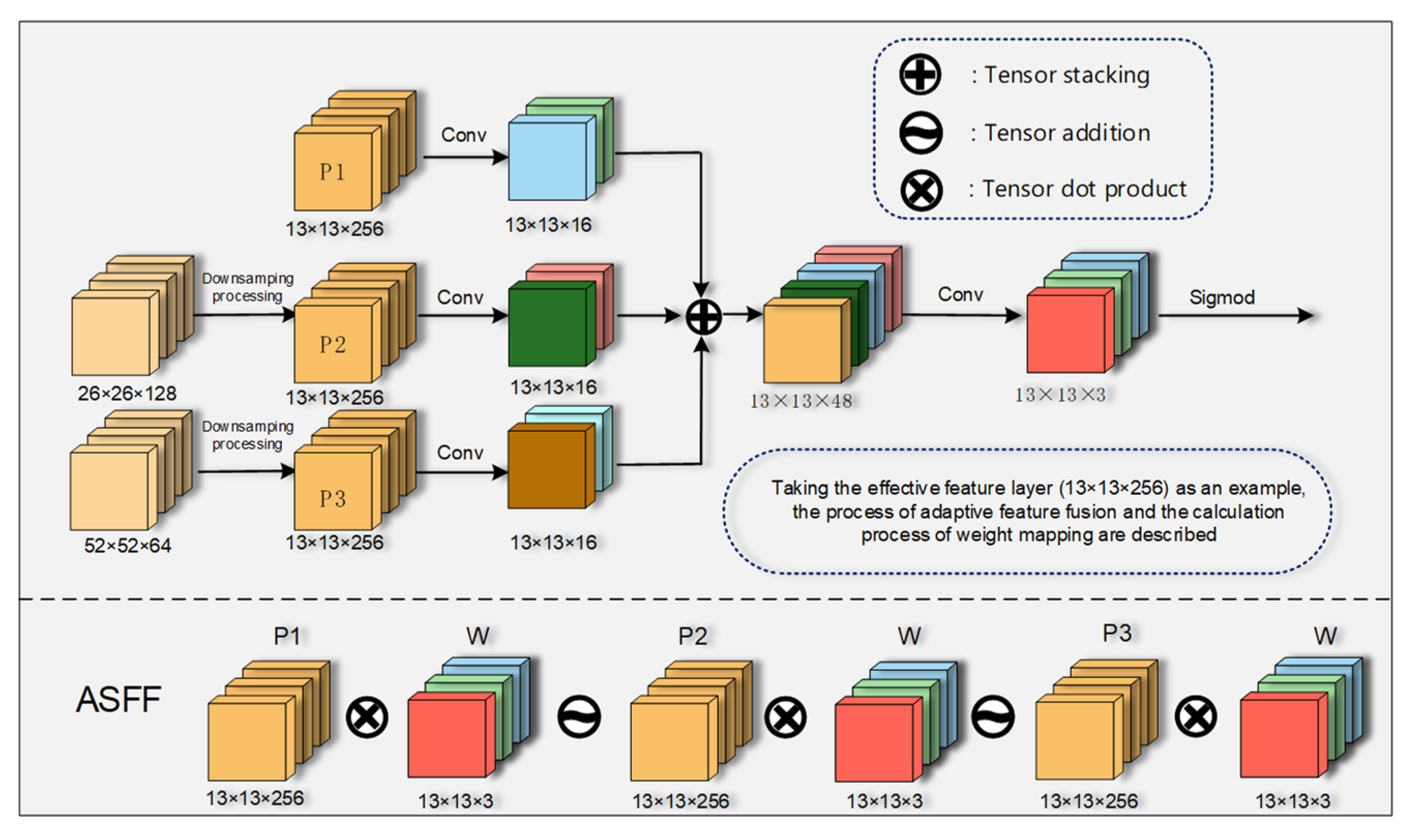
2.4.4. ASA-FPN Network Structure
3. Experimental Design
3.1. Network Training
3.2. Loss Function
3.3. Model Evaluation
4. Experimental Results and Analysis
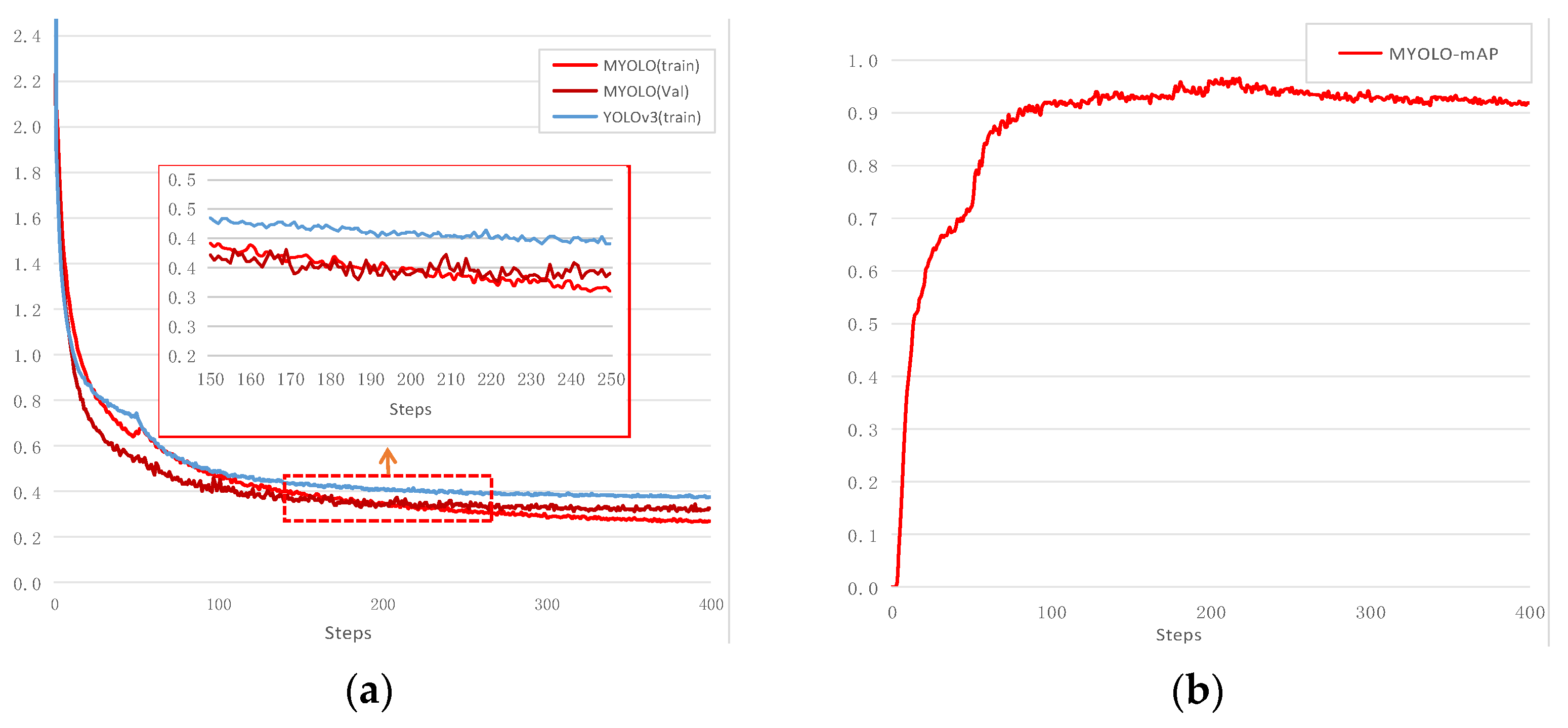
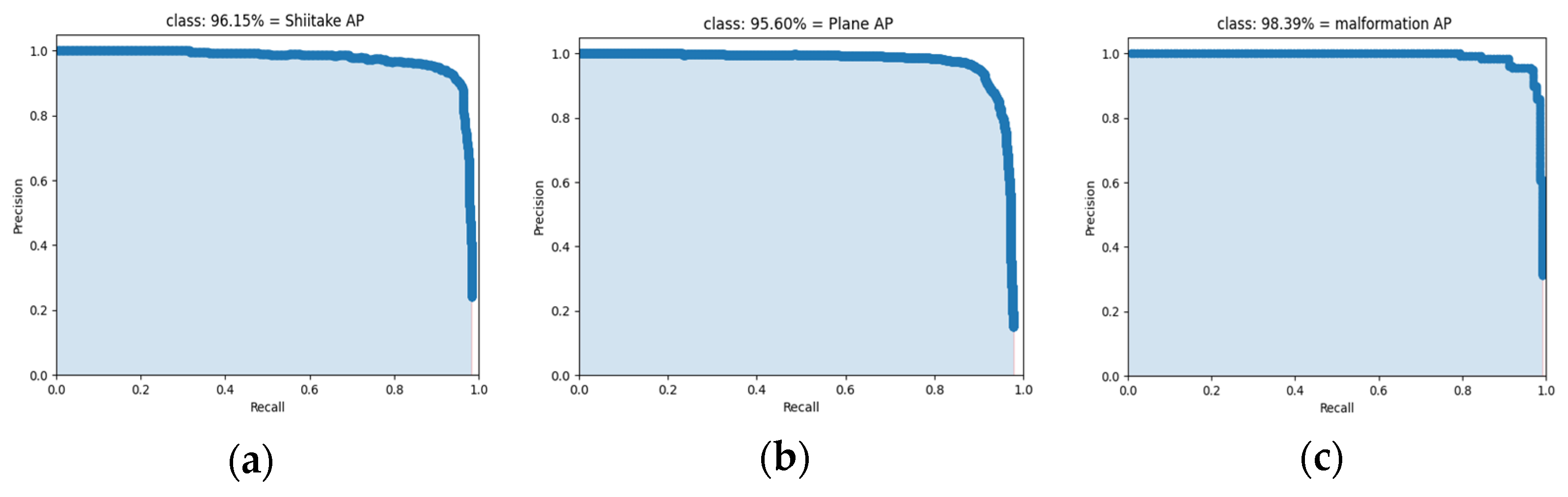
4.1. Experimental Results
4.2. Ablation Experiments
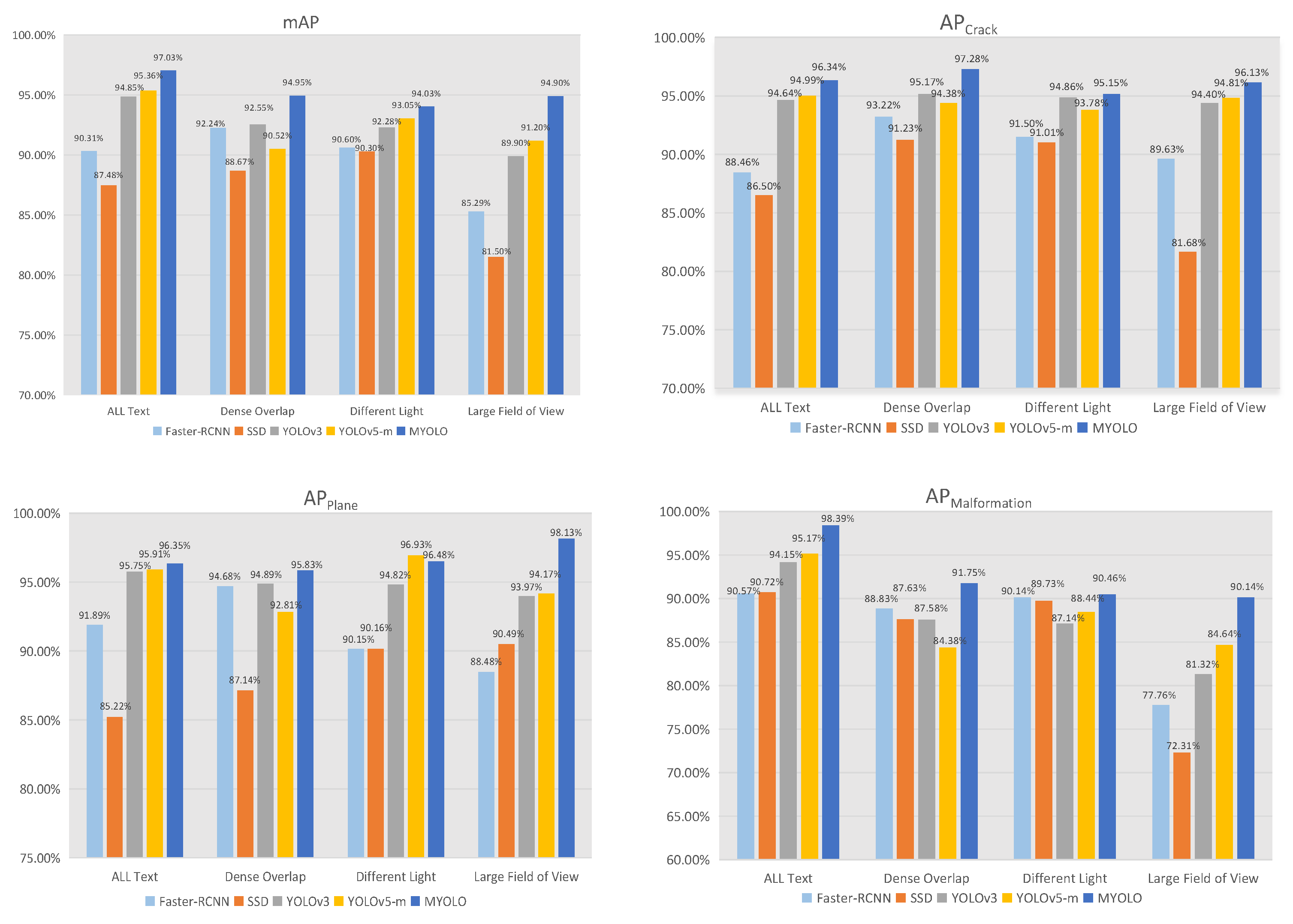
4.3. Multiscene Detection Performance Analysis
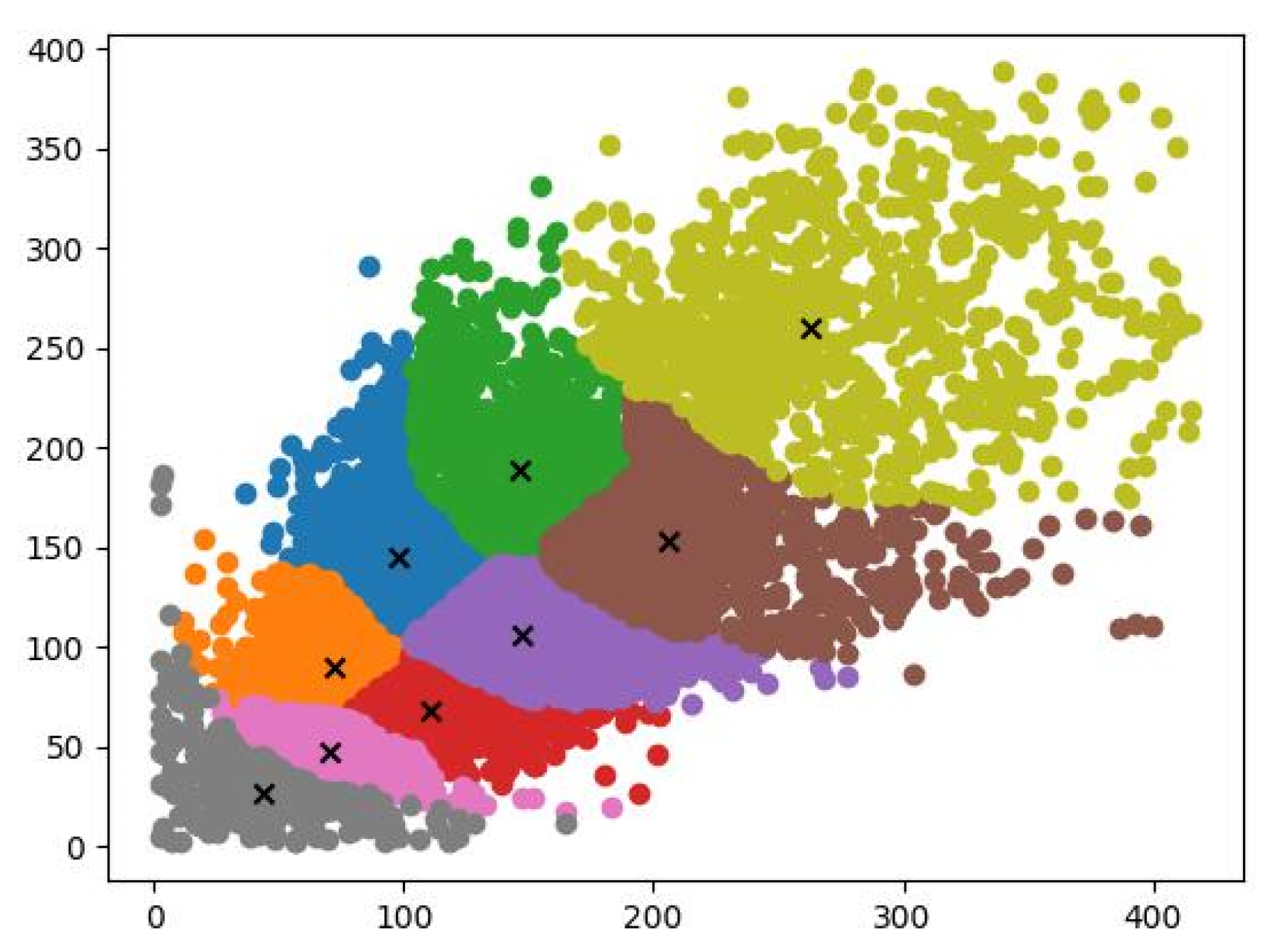
4.4. Feasibility Analysis of Picking Robot Applications
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaishnavi, M.; Sharma, A.; Tiwari, J.; Singh, S.; Sharma, S. Production of edible mushrooms to meet the food security: A review. J. Posit. Psychol. 2022, 6, 4316–4325. [Google Scholar] [CrossRef]
- Wang, M.; Zhao, R. A review on nutritional advantages of edible mushrooms and its industrialization development situation in protein meat analogues. J. Funct. Foods. 2023, 3, 1–7. [Google Scholar] [CrossRef]
- Cheute, V.M.S.; Backes, E.; Corrêa, R.C.G. The Global Market for Mushrooms, Their Uses as Dietary Supplements and Associated Safety Issues. In Edible Fungi: Chemical Composition, Nutrition and Health Effects; The Royal Society of Chemistry: London, UK, 23 November 2022; Volume 383, ISBN 978-1-83916-401-9. [Google Scholar]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Arefi, A.; Motlagh, A.M.; Mollazade, K.; Teimourlou, R.F. Recognition and localization of ripen tomato based on machine vision. Australian J. Crop Sci. 2011, 5, 1144–1149. [Google Scholar] [CrossRef]
- Wei, X.; Jia, K.; Lan, J.; Li, Y.; Zeng, Y.; Wang, C. Automatic method of fruit object extraction under complex agricultural background for vision system of fruit picking robot. Optik 2014, 125, 5684–5689. [Google Scholar] [CrossRef]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agri. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Xiong, J.; Lin, R.; Liu, Z.; He, Z.; Tang, L.; Yang, Z.; Zou, X. The recognition of litchi clusters and the calculation of picking point in a nocturnal natural environment. Biosyst. Eng. 2018, 166, 44–57. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar] [CrossRef]
- Lamb, N.; Chuah, M.C. A strawberry detection system using convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2515–2520. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agri. 2019, 163, 104846. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Li, J. Guava detection and pose estimation using a low-cost RGB-D sensor in the field. Sensors 2019, 19, 428. [Google Scholar] [CrossRef] [PubMed]
- Mu, Y.; Chen, T.-S.; Ninomiya, S.; Guo, W. Intact detection of highly occluded immature tomatoes on plants using deep learning techniques. Sensors 2020, 20, 2984. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wu, J.; Fu, L.; Majeed, Y.; Feng, Y.; Li, R.; Cui, Y. Improved kiwifruit detection using pre-trained VGG16 with RGB and NIR information fusion. IEEE Access 2019, 8, 2327–2336. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Computer Vision—ECCV 2016. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 21–37. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agri. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Li, H.; Li, C.; Li, G.; Chen, L. A real-time table grape detection method based on improved YOLOv4-tiny network in complex background. Biosyst. Eng. 2021, 212, 347–359. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-attention-YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation. Comput. Electron. Agri. 2022, 193, 106696. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Y.; Yan, G.; Meng, Q.; Yao, T.; Han, J.; Zhang, B. DSE-YOLO: Detail semantics enhancement YOLO for multi-stage strawberry detection. Comput. Electron. Agri. 2022, 198, 107057. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Automation in agriculture by machine and deep learning techniques: A review of recent developments. Precis. Agri. 2021, 22, 2053–2091. [Google Scholar] [CrossRef]
- Fang, L.; Wu, Y.; Li, Y.; Guo, H.; Zhang, H.; Wang, X.; Xi, R.; Hou, J. Using channel and network layer pruning based on deep learning for real-time detection of ginger images. Agriculture 2021, 11, 1190. [Google Scholar] [CrossRef]
- Zulkiflfley, M.A.; Moubark, A.M.; Saputro, A.H.; Abdani, S.R. Automated apple recognition system using semantic segmentation networks with group and shuffle operators. Agriculture 2022, 12, 756. [Google Scholar] [CrossRef]
- Liu, Q.; Fang, M.; Li, Y.; Gao, M. Deep learning based research on quality classification of shiitake mushrooms. LWT 2022, 168, 113902. [Google Scholar] [CrossRef]
- Yu, L.; Pu, Y.; Cen, H.; Li, J.; Liu, S.; Jing, N.; Ge, J.; Lv, L.; Li, Y.; Xu, Y.; et al. A lightweight neural network-based method for detecting estrus behavior in ewes. Agriculture 2022, 12, 1207. [Google Scholar] [CrossRef]
- Xiang, R.; Zhang, M.; Zhang, J. Recognition for stems of tomato plants at night based on a hybrid joint neural network. Agriculture 2022, 12, 743. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 7132–7141. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Fu, L.; Li, S.; Kong, S.; Ni, R.; Pang, H.; Sun, Y.; Hu, T.; Mu, Y.; Guo, Y.; Gong, H. Lightweight individual cow identification based on Ghost combined with attention mechanism. PLoS ONE 2022, 17, e0275435. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, N.; Qian, T.; Yang, J.; Li, L.; Zhang, Y.; Zheng, X.; Xu, Y.; Zhao, H.; Zhao, J. An enhanced YOLOv5 model for greenhouse cucumber fruit recognition based on color space features. Agriculture 2022, 12, 1556. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Y.; Yu, S.; Wang, R.; Song, Z.; Yan, Y.; Li, F.; Wang, Z.; Tian, F. Automatic detection method of dairy cow feeding behaviour based on YOLO improved model and edge computing. Sensors 2022, 22, 3271. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- MacQueen, J. Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965, 27 December 1965–7 January 1966; Volume 5, pp. 281–297. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Annals Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Liu, C.Y.; Wu, Y.Q.; Liu, J.J.; Sun, Z. Improved YOLOv3 network for insulator detection in aerial images with diverse background interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]
- Khasawneh, N.; Mohammad, F.; Luay, F. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Cluster Comput 2022, 1–11. [Google Scholar] [CrossRef]
- Cong, P.; Lv, K.; Feng, H.; Zhou, J. Improved YOLOv3 Model for Workpiece Stud Leakage Detection. Electronics 2022, 11, 3430. [Google Scholar] [CrossRef]
- Khasawneh, N.; Faouri, E.; Fraiwan, M. Automatic Detection of Tomato Diseases Using Deep Transfer Learning. Appl. Sci. 2022, 12, 8467. [Google Scholar] [CrossRef]
- Huang, J.; Qu, L.; Jia, R.; Zhao, B. O2u-net: A Simple Noisy Label Detection Approach for Deep Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3326–3334. [Google Scholar]
- He, X.; Cheng, R.; Zheng, Z.; Wang, Z. Small object detection in traffic scenes based on YOLO-MXANet. Sensors 2021, 21, 7422. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Zhang, M.; Liang, H.; Wang, Z.; Wang, L.; Huang, C.; Luo, X. Damaged Apple Detection with a Hybrid YOLOv3 Algorithm. Inf. Process 2022, in press. [Google Scholar] [CrossRef]
- Bazame, H.C.; Molin, J.P.; Althoff, D.; Martello, M. Detection, classification, and mapping of coffee fruits during harvest with computer vision. Comput. Electron. Agri. 2021, 183, 106066. [Google Scholar] [CrossRef]
- Zhang, J.L.; Su, W.H.; Zhang, H.Y.; Peng, Y. SE-YOLOv5x: An Optimized Model Based on Transfer Learning and Visual Attention Mechanism for Identifying and Localizing Weeds and Vegetables. Agronomy 2022, 12, 2061. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, H.; Li, M.; Su, W.H. Automatic Tandem Dual BlendMask Networks for Severity Assessment of Wheat Fusarium Head Blight. Agriculture 2022, 12, 1493. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Layer | Input | Component Units | Stride | Attention |
|---|---|---|---|---|
| 0 | 416 × 416 × 3 | Conv2d 3 × 3 | 2 | Add |
| 1 | 208 × 208 × 16 | G-bneck 3 × 3 | 1 | No |
| 2 | 208 × 208 × 16 | G-bneck 3 × 3 | 2 | No |
| 3 | 104 × 104 × 24 | G-bneck 3 × 3 | 1 | No |
| 4 | 104 × 104 × 24 | G-bneck 5 × 5 | 2 | Add |
| 5 | 52 × 52 × 40 | G-bneck 5 × 5 | 1 | Add |
| 6 | 52 × 52 × 40 | G-bneck 3 × 3 | 2 | No |
| 7 | 26 × 26 × 80 | G-bneck 3 × 3 | 1 | No |
| 8 | 26 × 26 × 80 | G-bneck 3 × 3 | 1 | No |
| 9 | 26 × 26 × 80 | G-bneck 3 × 3 | 1 | No |
| 10 | 26 × 26 × 80 | G-bneck 3 × 3 | 1 | Add |
| 11 | 26 × 26 × 112 | G-bneck 3 × 3 | 1 | Add |
| 12 | 26 × 26 × 112 | G-bneck 5 × 5 | 2 | Add |
| 13 | 13 × 13 × 160 | G-bneck 5 × 5 | 1 | No |
| 14 | 13 × 13 × 160 | G-bneck 5 × 5 | 1 | Add |
| 15 | 13 × 13 × 160 | G-bneck 5 × 5 | 1 | No |
| 16 | 13 × 13 × 160 | G-bneck 5 × 5 | 1 | Add |
| Hardware or Software | Configuration |
|---|---|
| CPU | Intel i9-10700H |
| RAM | 24 GB |
| SSD | 256 GB |
| Operating system | Window 10 |
| GPU | NVIDIA GeForce GTX 2080Ti 11 GB |
| Development environment | Python 3.8, Pytorch 1.12, CUDA 11.3 |
| Model | CIOU | Migration Learning | mAP | Training Time (Epoch = 400) |
|---|---|---|---|---|
| YOLOv3 | × | √ | 94.85% | 5 h 52 min |
| MYOLO-R | × | √ | 96.31% | 5 h 14 min |
| MYOLO | √ | √ | 97.03% | 4 h 45 min |
| MYOLO-N | √ | × | 89.73% | 4 h 47 min |
| Model | FPN | GhostNet16 | SPP | ASA-FPN | mAP | Total Parameters | Speed |
|---|---|---|---|---|---|---|---|
| YOLOv3 | √ | × | × | × | 94.85% | 61.53 M | 35.94 ms |
| YOLO-A | √ | √ | × | × | 94.90% | 22.88 M | 17.45 ms |
| YOLO-B | √ | √ | √ | × | 95.64% | 23.93 M | 18.01 ms |
| YOLO-M | × | √ | √ | √ | 97.03% | 29.37 M | 19.78 ms |
| Algorithm | FLOP (G) | Total Parameters (M) | Speed (ms) | F1 (%) | mAP (%) |
|---|---|---|---|---|---|
| Faster-RCNN | 370.21 | 137.1 | 129.65 | 89.30 | 90.31 |
| SSD | 62.75 | 26.3 | 23.02 | 85.67 | 87.48 |
| YOLOv3 | 66.17 | 62.0 | 35.94 | 92.01 | 94.85 |
| YOLOv5-m | 21.38 | 21.3 | 17.95 | 92.33 | 95.36 |
| MYOLO | 21.36 | 29.8 | 19.78 | 94.02 | 97.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cong, P.; Feng, H.; Lv, K.; Zhou, J.; Li, S. MYOLO: A Lightweight Fresh Shiitake Mushroom Detection Model Based on YOLOv3. Agriculture 2023, 13, 392. https://doi.org/10.3390/agriculture13020392
Cong P, Feng H, Lv K, Zhou J, Li S. MYOLO: A Lightweight Fresh Shiitake Mushroom Detection Model Based on YOLOv3. Agriculture. 2023; 13(2):392. https://doi.org/10.3390/agriculture13020392
Chicago/Turabian StyleCong, Peichao, Hao Feng, Kunfeng Lv, Jiachao Zhou, and Shanda Li. 2023. "MYOLO: A Lightweight Fresh Shiitake Mushroom Detection Model Based on YOLOv3" Agriculture 13, no. 2: 392. https://doi.org/10.3390/agriculture13020392