
Calibration Spiking of MIR-DRIFTS Soil Spectra for Carbon Predictions Using PLSR Extensions and Log-Ratio Transformations


Abstract
:1. Introduction
2. Materials and Methods
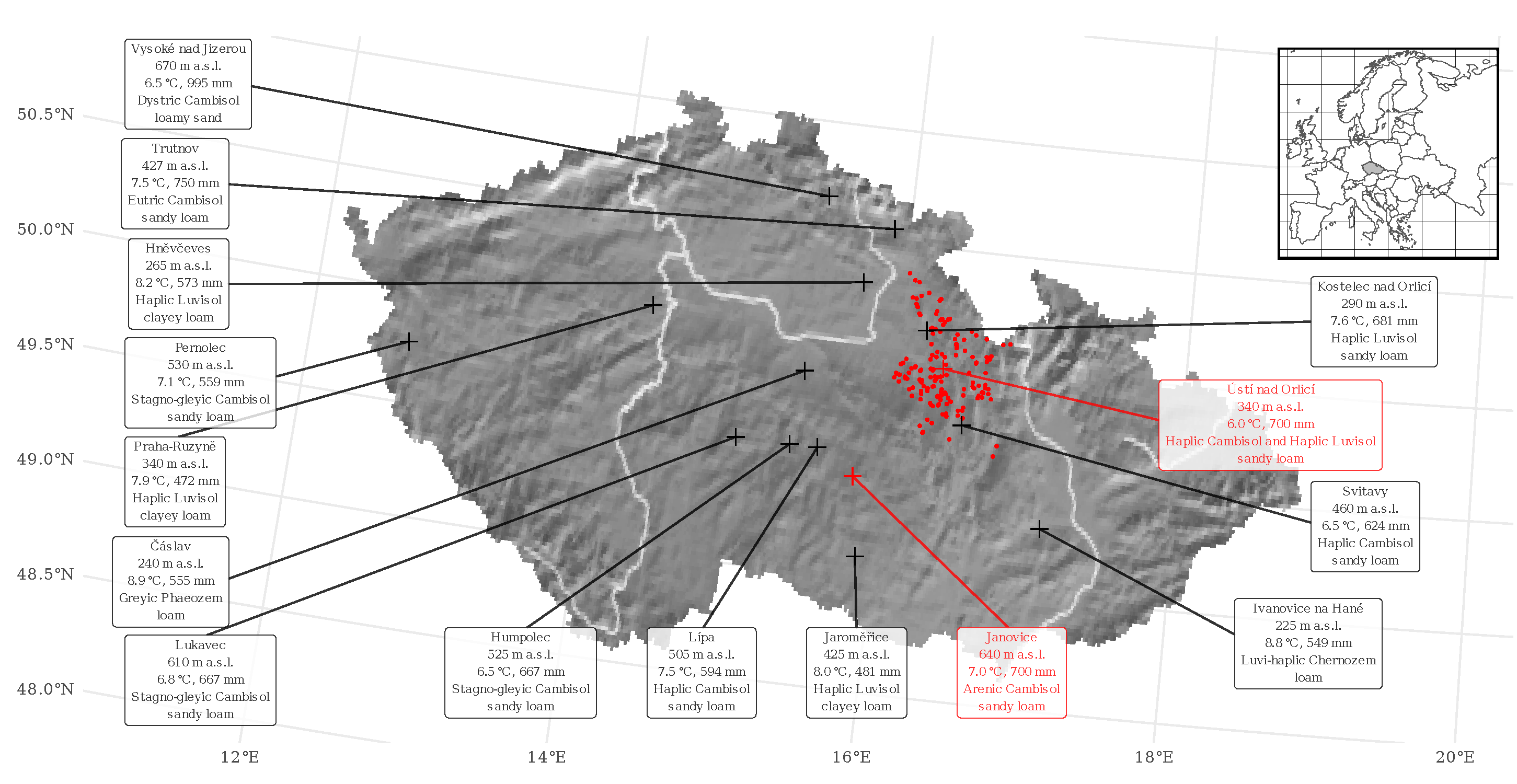
2.1. Site Description and Data Collection
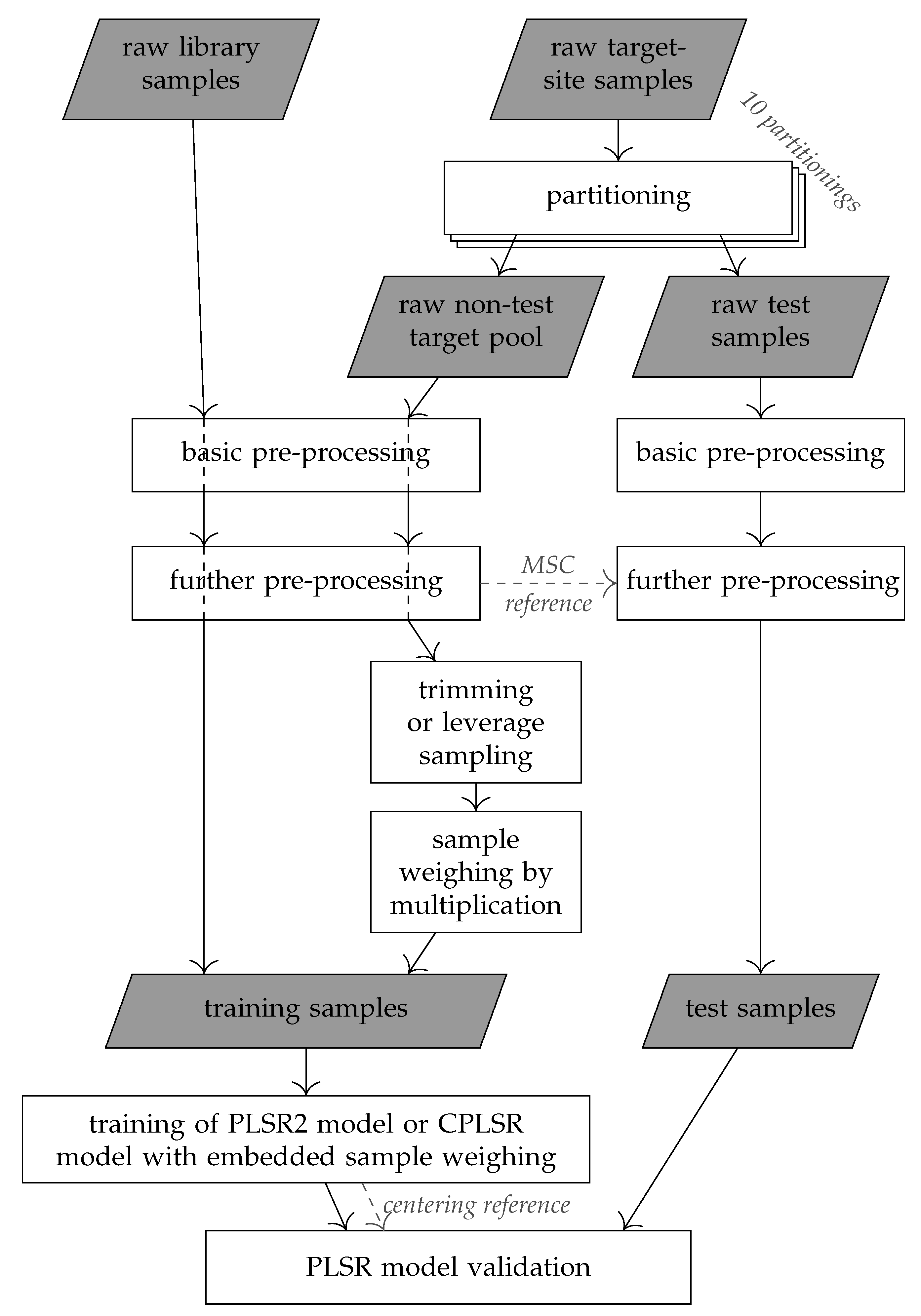
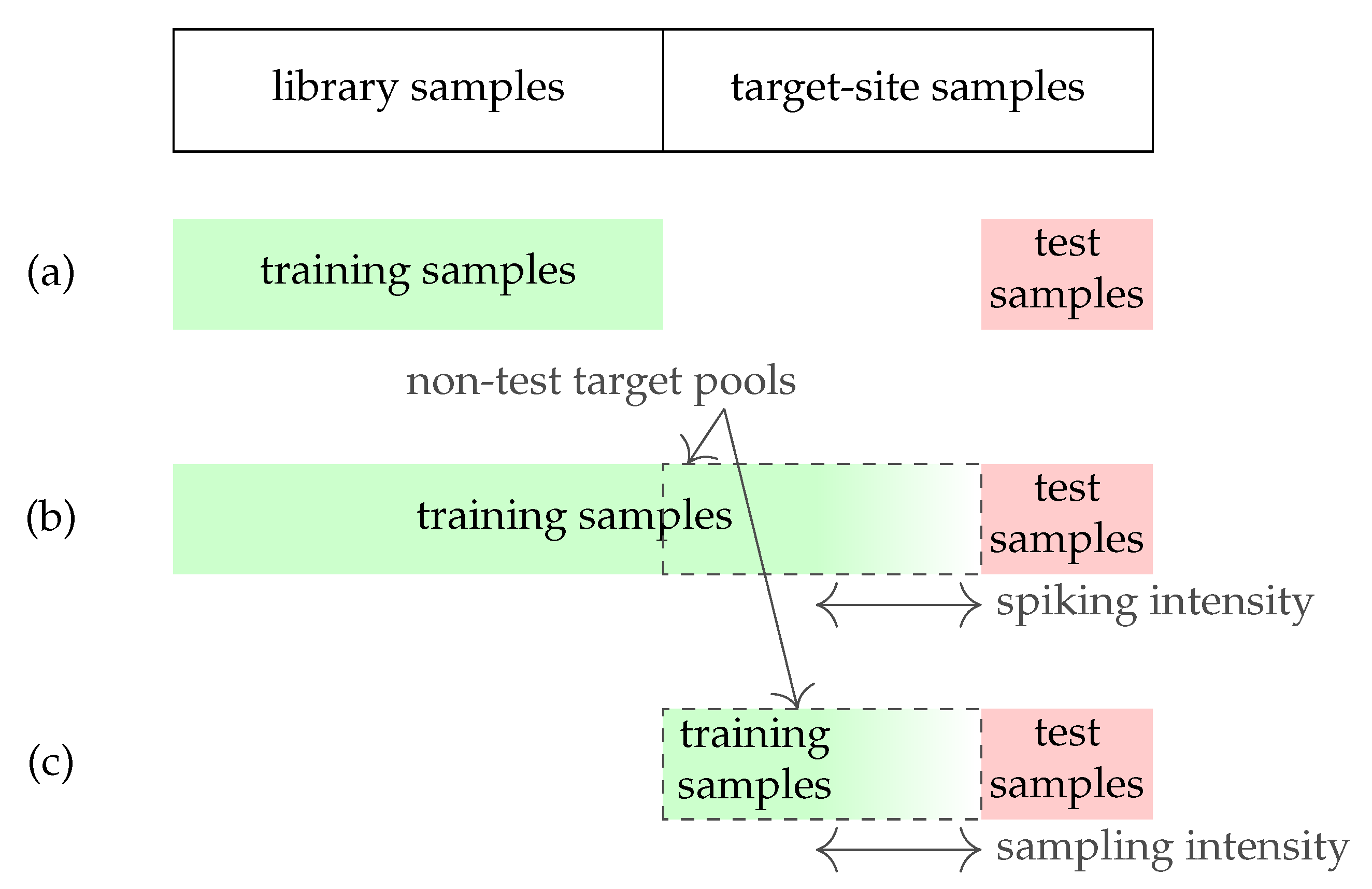
2.2. Data Partitioning and Pre-Processing of MIR-DRIFTS Spectra
2.3. Calibration Spiking
2.4. Reference Laboratory Data Pre-Processing
2.5. PLSR Modeling with Unweighed and Weighed Training Samples
2.6. Reproducing the Study
3. Results
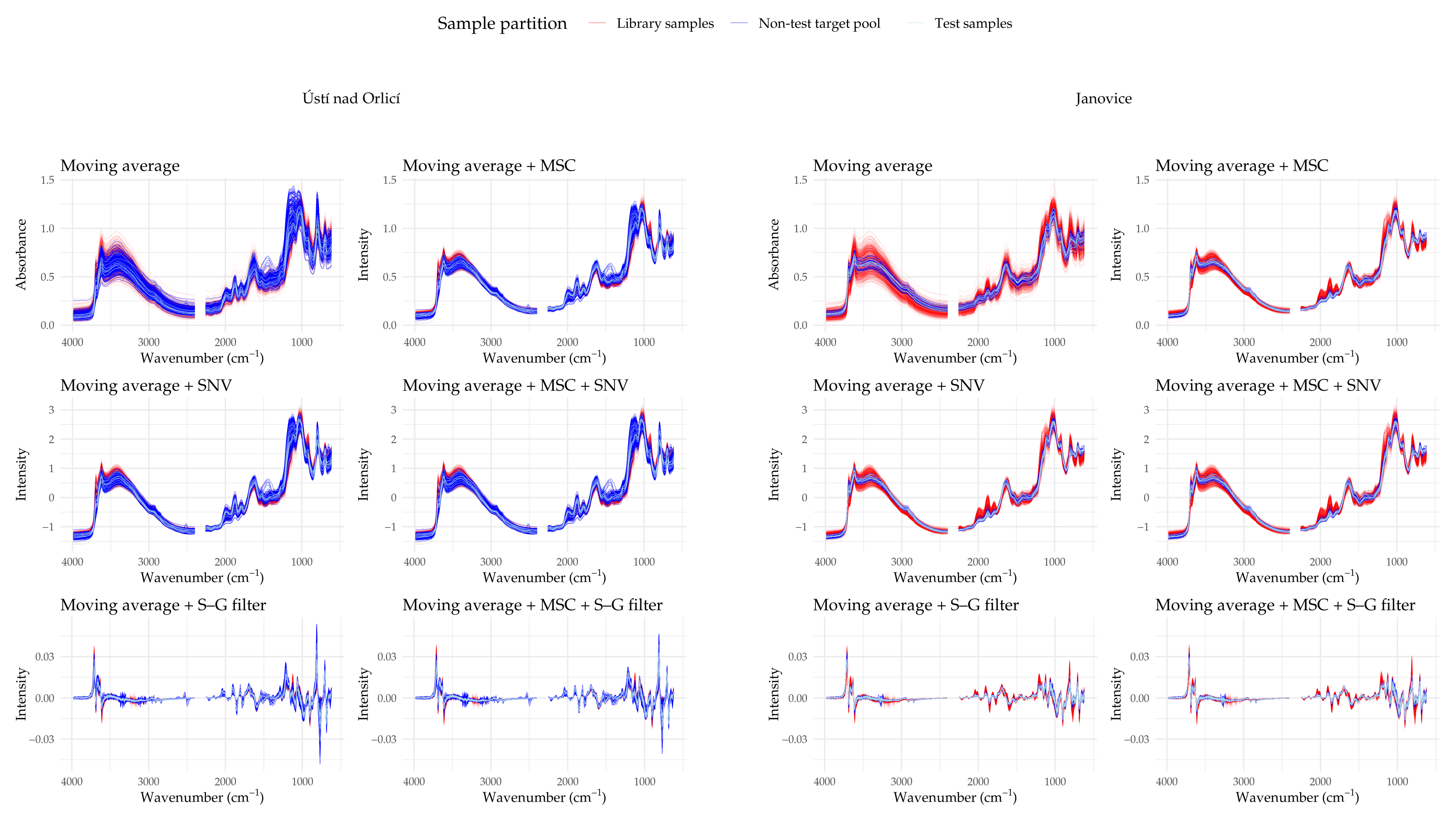
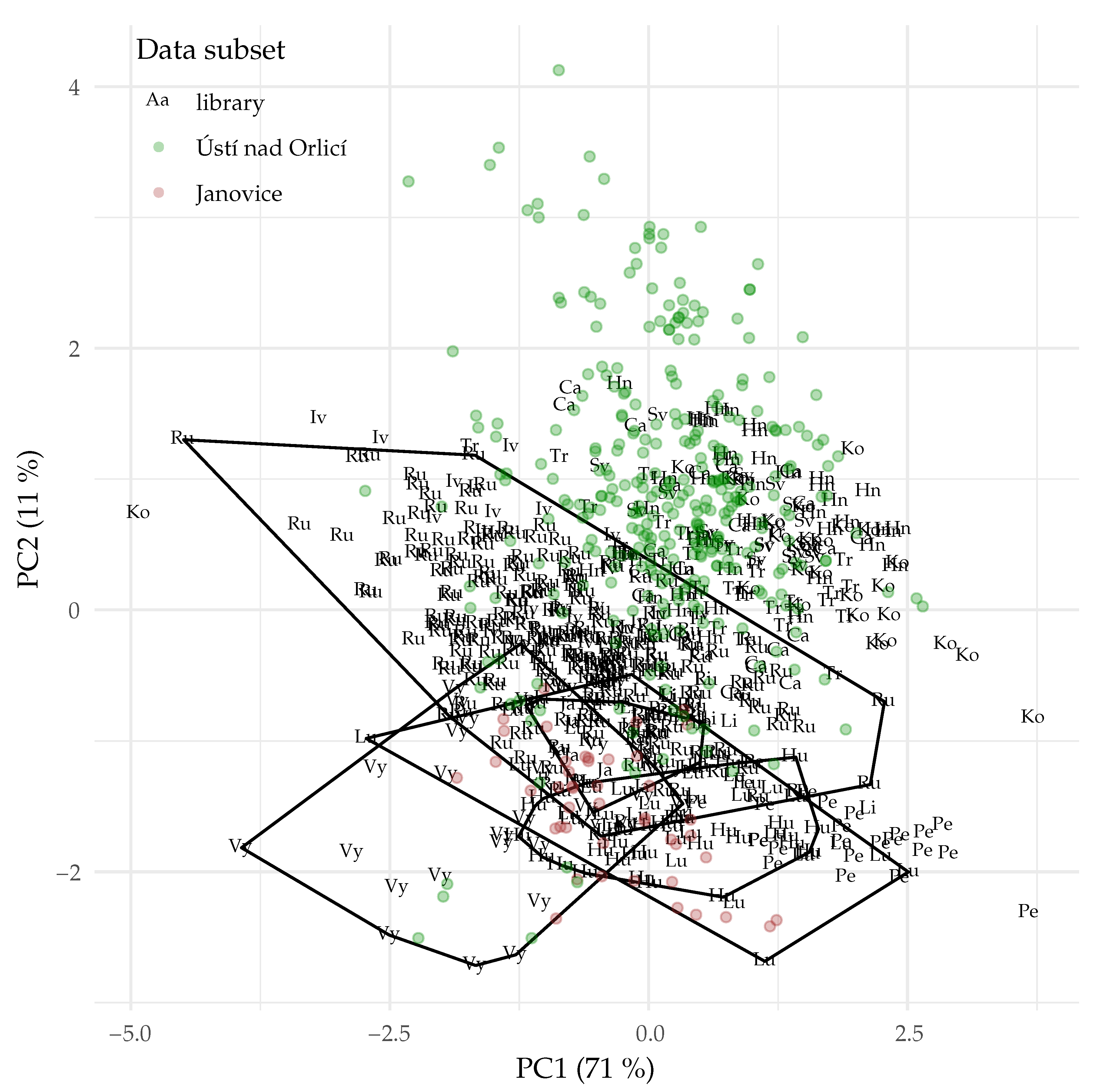
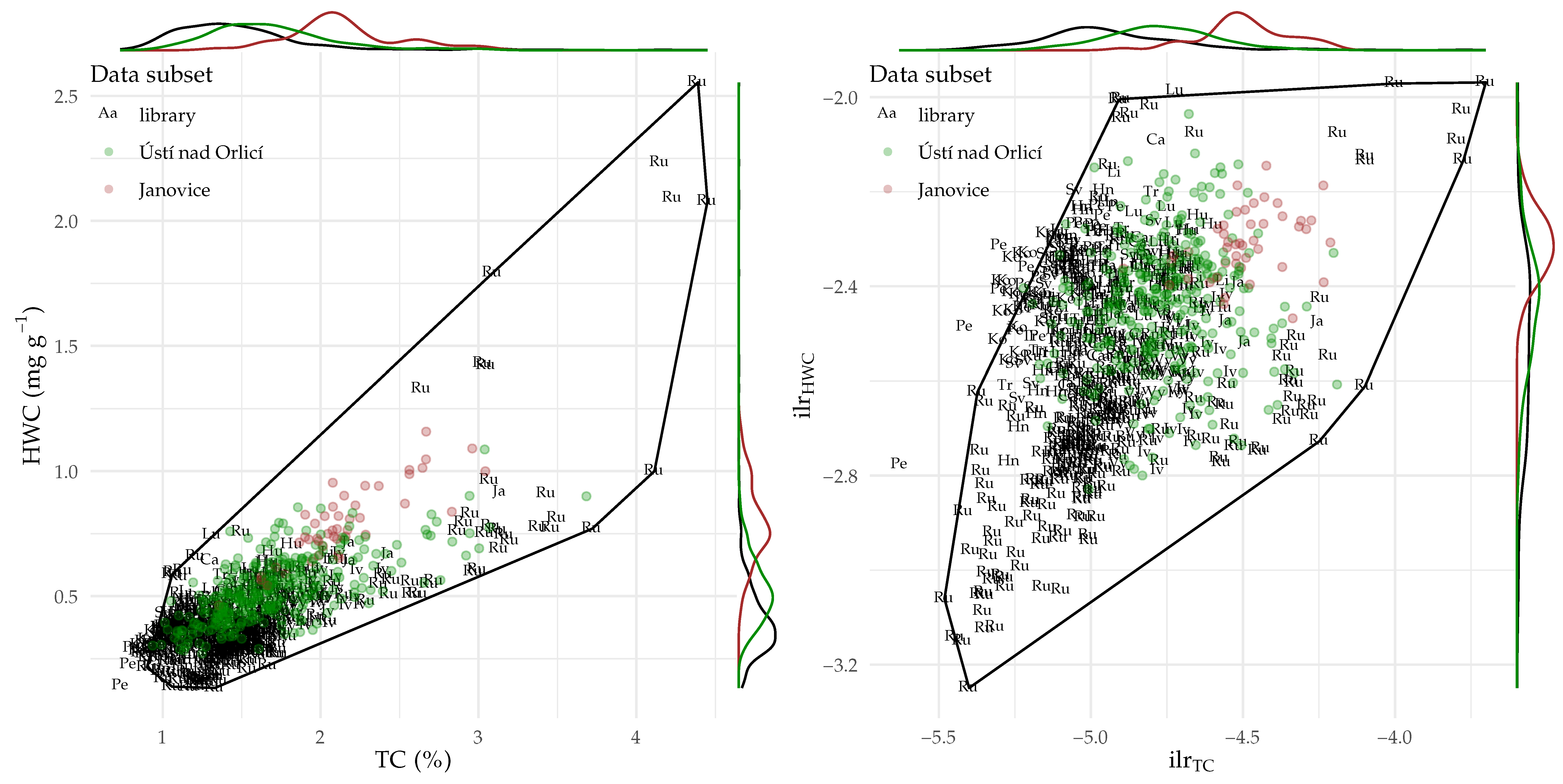
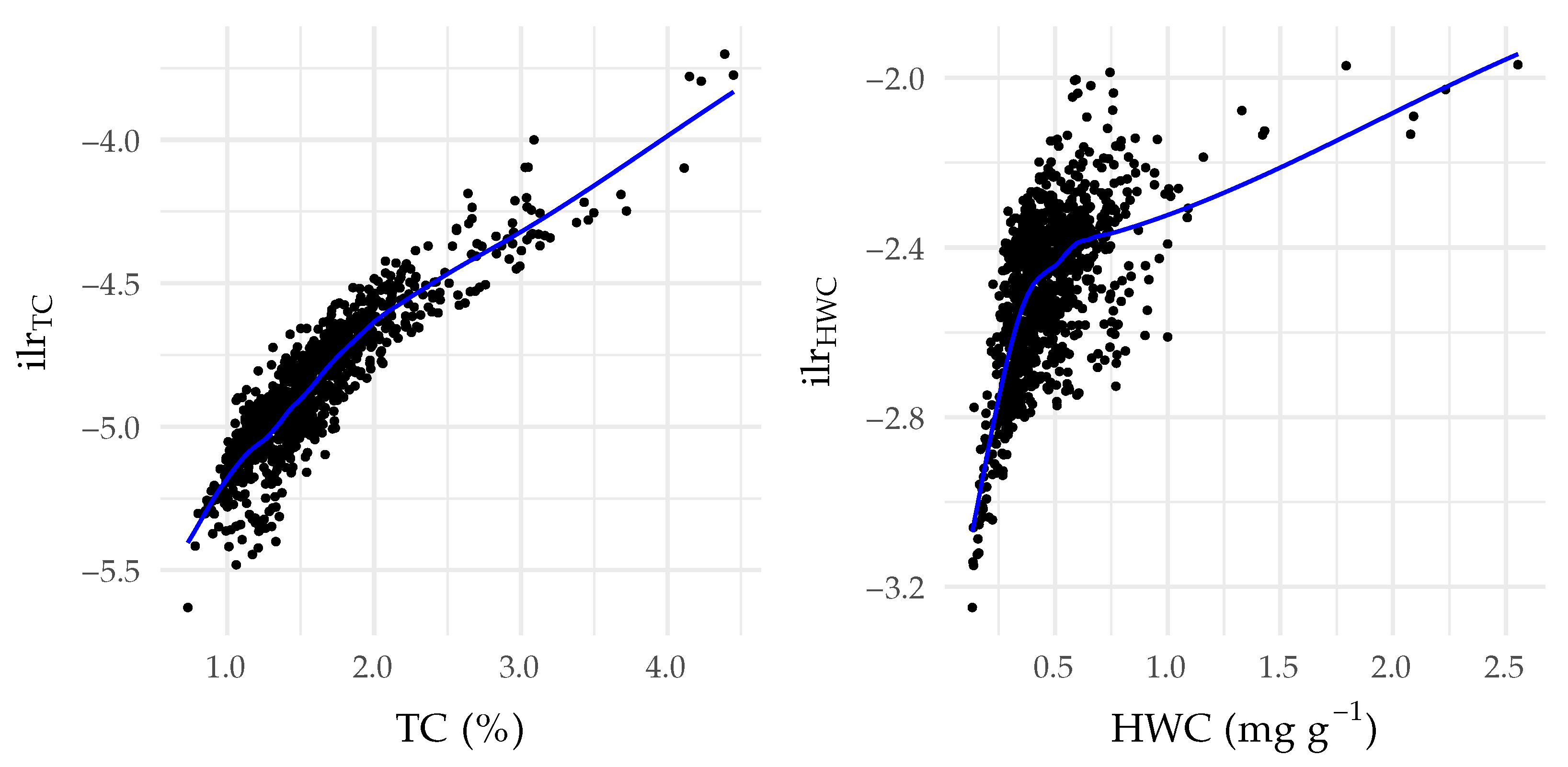
3.1. Patterns in the Raw and Pre-Processed Data
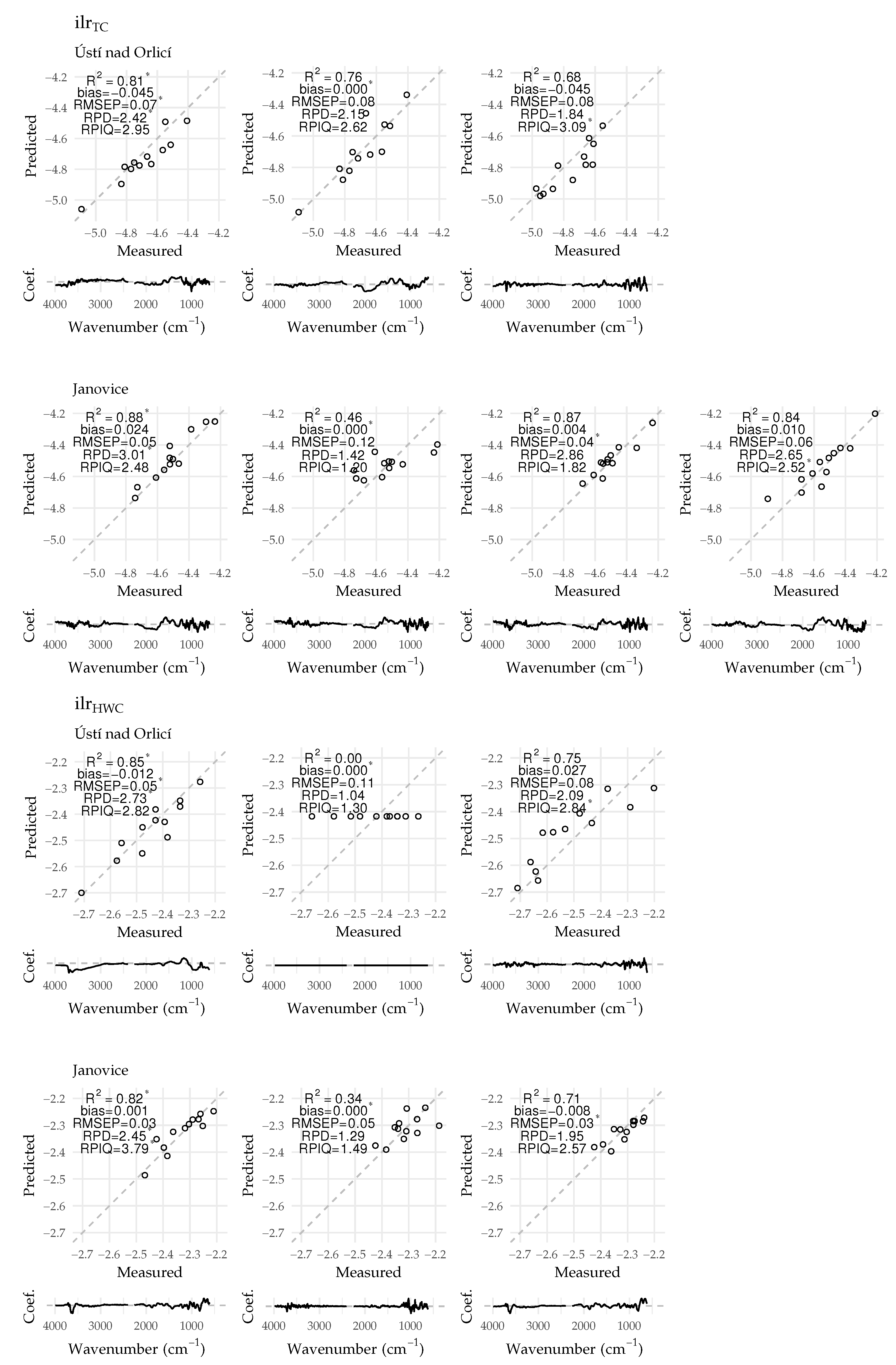
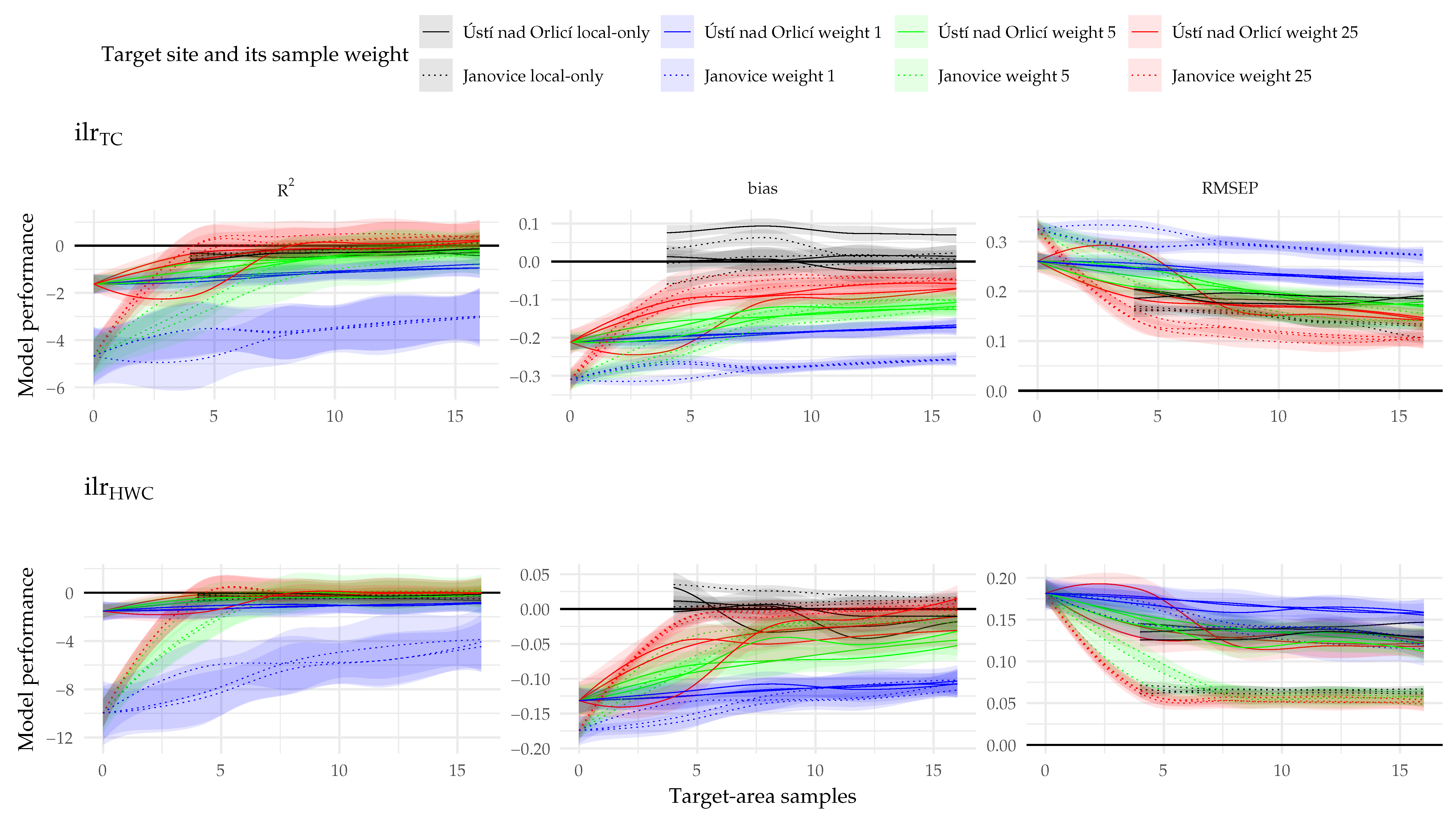
3.2. Accuracy and Precision of the PLSR Models
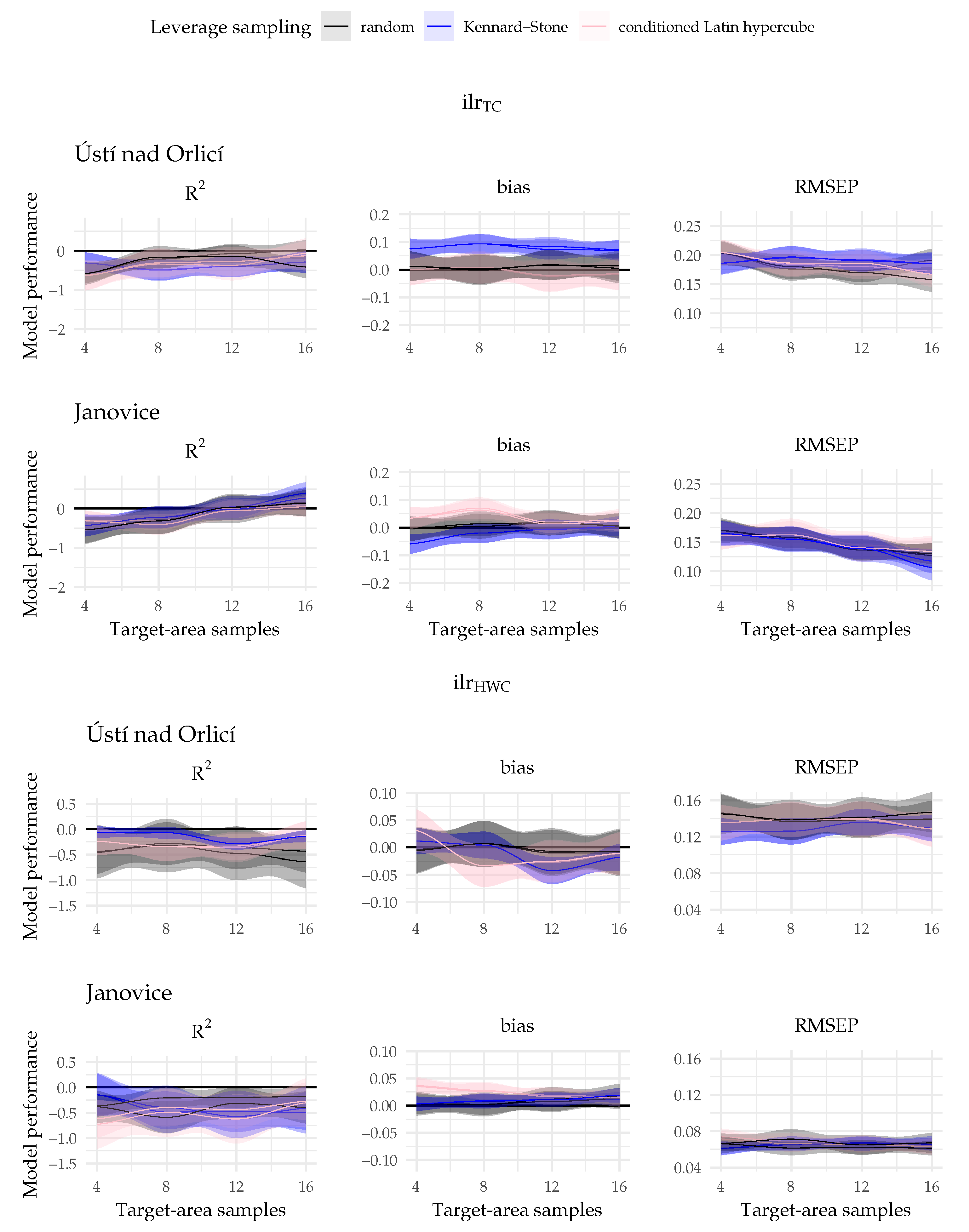
3.3. Factors Affecting PLSR Model Performance
4. Discussion
4.1. Distributional Data Properties and the Effect of Log-Ratio Transformation
4.2. Absolute Performance of the Predictive Models
4.3. Model Performance with Individual Training Data Subsets
4.4. The Effect of Leverage Sampling and Evidence against the CPLSR Internal Weighing Superiority Hypothesis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reeves, D. The role of soil organic matter in maintaining soil quality in continuous cropping systems. Soil Tillage Res. 1997, 43, 131–167. [Google Scholar] [CrossRef]
- Bünemann, E.K.; Bongiorno, G.; Bai, Z.; Creamer, R.E.; De Deyn, G.; De Goede, R.; Fleskens, L.; Geissen, V.; Kuyper, T.W.; Mäder, P.; et al. Soil quality—A critical review. Soil Biol. Biochem. 2018, 120, 105–125. [Google Scholar] [CrossRef]
- Smith, P.; Soussana, J.F.; Angers, D.; Schipper, L.; Chenu, C.; Rasse, D.P.; Batjes, N.H.; Van Egmond, F.; McNeill, S.; Kuhnert, M.; et al. How to measure, report and verify soil carbon change to realize the potential of soil carbon sequestration for atmospheric greenhouse gas removal. Glob. Chang. Biol. 2019, 26, 219–241. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paustian, K.; Collier, S.; Baldock, J.; Burgess, R.; Creque, J.; DeLonge, M.; Dungait, J.; Ellert, B.; Frank, S.; Goddard, T.; et al. Quantifying carbon for agricultural soil management: From the current status toward a global soil information system. Carbon Manag. 2019, 10, 567–587. [Google Scholar] [CrossRef] [Green Version]
- Batjes, N.H.; Van Wesemael, B. Chapter Measuring and Monitoring Soil Carbon. In Soil Carbon: Science, Management and Policy for Multiple Benefits; Banwart, S.A., Noellemeyer, E., Milne, E., Eds.; CAB International: Wallingford, UK, 2015; Volume 71, pp. 188–201. [Google Scholar]
- Stenberg, B.; Rossel, R.A.V.; Mouazen, A.M.; Wetterlind, J. Visible and Near Infrared Spectroscopy in Soil Science. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2010; Volume 107, pp. 163–215. [Google Scholar] [CrossRef] [Green Version]
- Kan, Z.R.; Liu, W.X.; Liu, W.S.; Lal, R.; Dang, Y.P.; Zhao, X.; Zhang, H.L. Mechanisms of soil organic carbon stability and its response to no-till: A global synthesis and perspective. Glob. Chang. Biol. 2021, 28, 693–710. [Google Scholar] [CrossRef]
- Körschens, M.; Schulz, E.; Behm, R. Heißwasserlöslicher C und N im Boden als Kriterium für das N-Nachlieferungsvermögen. Zentralblatt Für Mikrobiol. 1990, 145, 305–311. [Google Scholar] [CrossRef]
- Thomas, B.W.; Whalen, J.K.; Sharifi, M.; Chantigny, M.; Zebarth, B.J. Labile organic matter fractions as early-season nitrogen supply indicators in manure-amended soils. J. Plant Nutr. Soil Sci. 2016, 179, 94–103. [Google Scholar] [CrossRef]
- Page, K.; Dalal, R.; Dang, Y. How useful are MIR predictions of total, particulate, humus, and resistant organic carbon for examining changes in soil carbon stocks in response to different crop management? A case study. Soil Res. 2013, 51, 719–725. [Google Scholar] [CrossRef]
- Haynes, R. Labile Organic Matter Fractions as Central Components of the Quality of Agricultural soils: An Overview. Adv. Agron. 2005, 85, 221–268. [Google Scholar] [CrossRef]
- Sanderman, J.; Hengl, T.; Fiske, G.J. Soil carbon debt of 12,000 years of human land use. Proc. Natl. Acad. Sci. USA 2017, 114, 9575–9580. [Google Scholar] [CrossRef] [Green Version]
- Soriano-Disla, J.M.; Janik, L.J.; Viscarra Rossel, R.A.; Macdonald, L.M.; McLaughlin, M.J. The Performance of Visible, Near-, and Mid-Infrared Reflectance Spectroscopy for Prediction of Soil Physical, Chemical, and Biological Properties. Appl. Spectrosc. Rev. 2014, 49, 139–186. [Google Scholar] [CrossRef]
- Bongiorno, G.; Bünemann, E.K.; Oguejiofor, C.U.; Meier, J.; Gort, G.; Comans, R.; Mäder, P.; Brussaard, L.; De Goede, R. Sensitivity of labile carbon fractions to tillage and organic matter management and their potential as comprehensive soil quality indicators across pedoclimatic conditions in Europe. Ecol. Indic. 2019, 99, 38–50. [Google Scholar] [CrossRef]
- Gregorich, E.; Carter, M.; Angers, D.; Monreal, C.; Ellert, B. Towards a minimum data set to assess soil organic matter quality in agricultural soils. Can. J. Soil Sci. 1994, 74, 367–385. [Google Scholar] [CrossRef] [Green Version]
- Baldock, J.; Hawke, B.; Sanderman, J.; Macdonald, L. Predicting contents of carbon and its component fractions in Australian soils from diffuse reflectance mid-infrared spectra. Soil Res. 2013, 51, 577–595. [Google Scholar] [CrossRef] [Green Version]
- Zimmermann, M.; Leifeld, J.; Fuhrer, J. Quantifying soil organic carbon fractions by infrared-spectroscopy. Soil Biol. Biochem. 2007, 39, 224–231. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, X.; Drury, C.; Chantigny, M.; Gregorich, E.; Miller, J.; Bittman, S.; Reynolds, D.; Yang, J. Infrared spectroscopy prediction of organic carbon and total nitrogen in soil and particulate organic matter from diverse Canadian agricultural regions. Can. J. Soil Sci. 2018, 98, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Calderón, F.J.; Reeves, J.B.; Collins, H.P.; Paul, E.A. Chemical Differences in Soil Organic Matter Fractions Determined by Diffuse-Reflectance Mid-Infrared Spectroscopy. Soil Sci. Soc. Am. J. 2011, 75, 568–579. [Google Scholar] [CrossRef] [Green Version]
- Janik, L.J.; Skjemstad, J.; Shepherd, K.; Spouncer, L. The prediction of soil carbon fractions using mid-infrared-partial least square analysis. Soil Res. 2007, 45, 73–81. [Google Scholar] [CrossRef] [Green Version]
- Gredilla, A.; De Vallejuelo, S.F.O.; Elejoste, N.; De Diego, A.; Madariaga, J.M. Non-destructive Spectroscopy combined with chemometrics as a tool for Green Chemical Analysis of environmental samples: A review. TrAC Trends Anal. Chem. 2016, 76, 30–39. [Google Scholar] [CrossRef]
- Barra, I.; Haefele, S.M.; Sakrabani, R.; Kebede, F. Soil spectroscopy with the use of chemometrics, machine learning and pre-processing techniques in soil diagnosis: Recent advances–A review. TrAC Trends Anal. Chem. 2021, 135, 116166. [Google Scholar] [CrossRef]
- Armenta, S.; De la Guardia, M. Vibrational spectroscopy in soil and sediment analysis. Trends Environ. Anal. Chem. 2014, 2, 43–52. [Google Scholar] [CrossRef]
- Du, C.; Zhou, J. Evaluation of Soil Fertility Using Infrared Spectroscopy—A Review. In Climate Change, Intercropping, Pest Control and Beneficial Microorganisms; Springer: Dordrecht, The Netherlands, 2009; pp. 453–483. [Google Scholar] [CrossRef]
- Reeves III, J.B. Near- versus mid-infrared diffuse reflectance spectroscopy for soil analysis emphasizing carbon and laboratory versus on-site analysis: Where are we and what needs to be done? Geoderma 2010, 158, 3–14. [Google Scholar] [CrossRef]
- Bellon-Maurel, V.; McBratney, A. Near-infrared (NIR) and mid-infrared (MIR) spectroscopic techniques for assessing the amount of carbon stock in soils—Critical review and research perspectives. Soil Biol. Biochem. 2011, 43, 1398–1410. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, X.; Drury, C.; Chantigny, M.; Gregorich, E.; Miller, J.; Bittman, S.; Reynolds, W.D.; Yang, J. Infrared spectroscopy estimation methods for water-dissolved carbon and amino sugars in diverse Canadian agricultural soils. Can. J. Soil Sci. 2018, 98, 484–499. [Google Scholar] [CrossRef]
- Nocita, M.; Stevens, A.; Van Wesemael, B.; Aitkenhead, M.; Bachmann, M.; Barthès, B.; Dor, E.B.; Brown, D.J.; Clairotte, M.; Csorba, A.; et al. Chapter Four-Soil Spectroscopy: An Alternative to Wet Chemistry for Soil Monitoring. Adv. Agron. 2015, 132, 139–159. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Borůvka, L.; Saberioon, M.; Vašát, R. Visible, Near-Infrared, and Mid-Infrared Spectroscopy Applications for Soil Assessment with Emphasis on Soil Organic Matter Content and Quality: State-of-the-Art and Key Issues. Appl. Spectrosc. 2013, 67, 1349–1362. [Google Scholar] [CrossRef]
- Seidel, M.; Hutengs, C.; Ludwig, B.; Thiele-Bruhn, S.; Vohland, M. Strategies for the efficient estimation of soil organic carbon at the field scale with vis-NIR spectroscopy: Spectral libraries and spiking vs. local calibrations. Geoderma 2019, 354, 113856. [Google Scholar] [CrossRef]
- Deiss, L.; Margenot, A.J.; Culman, S.W.; Demyan, M.S. Tuning support vector machines regression models improves prediction accuracy of soil properties in MIR spectroscopy. Geoderma 2020, 365, 114227. [Google Scholar] [CrossRef]
- Dangal, S.R.; Sanderman, J.; Wills, S.; Ramirez-Lopez, L. Accurate and Precise Prediction of Soil Properties from a Large Mid-Infrared Spectral Library. Soil Syst. 2019, 3, 11. [Google Scholar] [CrossRef] [Green Version]
- Clairotte, M.; Grinand, C.; Kouakoua, E.; Thébault, A.; Saby, N.P.; Bernoux, M.; Barthès, B.G. National calibration of soil organic carbon concentration using diffuse infrared reflectance spectroscopy. Geoderma 2016, 276, 41–52. [Google Scholar] [CrossRef]
- Baumann, P.; Helfenstein, A.; Gubler, A.; Keller, A.; Meuli, R.G.; Wachter, D.; Lee, J.; Viscarra Rossel, R.A.; Six, J. Developing the Swiss mid-infrared soil spectral library for local estimation and monitoring. Soil 2021, 7, 525–546. [Google Scholar] [CrossRef]
- Seybold, C.A.; Ferguson, R.; Wysocki, D.; Bailey, S.; Anderson, J.; Nester, B.; Schoeneberger, P.; Wills, S.; Libohova, Z.; Hoover, D.; et al. Application of Mid-Infrared Spectroscopy in Soil Survey. Soil Sci. Soc. Am. J. 2019, 83, 1746–1759. [Google Scholar] [CrossRef]
- Cezar, E.; Nanni, M.R.; Guerrero, C.; Da Silva Junior, C.A.; Cruciol, L.G.T.; Chicati, M.L.; Silva, G.F.C. Organic matter and sand estimates by spectroradiometry: Strategies for the development of models with applicability at a local scale. Geoderma 2019, 340, 224–233. [Google Scholar] [CrossRef]
- Capron, X.; Walczak, B.; De Noord, O.; Massart, D. Selection and weighting of samples in multivariate regression model updating. Chemom. Intell. Lab. Syst. 2005, 76, 205–214. [Google Scholar] [CrossRef]
- Guerrero, C.; Zornoza, R.; Gómez, I.; Mataix-Beneyto, J. Spiking of NIR regional models using samples from target sites: Effect of model size on prediction accuracy. Geoderma 2010, 158, 66–77. [Google Scholar] [CrossRef]
- Guerrero, C.; Stenberg, B.; Wetterlind, J.; Viscarra Rossel, R.; Maestre, F.; Mouazen, A.M.; Zornoza, R.; Ruiz-Sinoga, J.; Kuang, B. Assessment of soil organic carbon at local scale with spiked NIR calibrations: Effects of selection and extra-weighting on the spiking subset. Eur. J. Soil Sci. 2014, 65, 248–263. [Google Scholar] [CrossRef] [Green Version]
- Stork, C.L.; Kowalski, B.R. Weighting schemes for updating regression models–a theoretical approach. Chemom. Intell. Lab. Syst. 1999, 48, 151–166. [Google Scholar] [CrossRef]
- Sankey, J.B.; Brown, D.J.; Bernard, M.L.; Lawrence, R.L. Comparing local vs. global visible and near-infrared (VisNIR) diffuse reflectance spectroscopy (DRS) calibrations for the prediction of soil clay, organic C and inorganic C. Geoderma 2008, 148, 149–158. [Google Scholar] [CrossRef] [Green Version]
- Frank, I.E.; Friedman, J.H. A Statistical View of Some Chemometrics Regression Tools. Technometrics 1993, 35, 109–135. [Google Scholar] [CrossRef]
- Brown, D.J.; Bricklemyer, R.S.; Miller, P.R. Validation requirements for diffuse reflectance soil characterization models with a case study of VNIR soil C prediction in Montana. Geoderma 2005, 129, 251–267. [Google Scholar] [CrossRef]
- Jean-Philippe, S.R.; Labbé, N.; Franklin, J.A.; Johnson, A. Detection of mercury and other metals in mercury contaminated soils using mid-infrared spectroscopy. Proc. Int. Acad. Ecol. Environ. Sci. 2012, 2, 139–149. [Google Scholar]
- Stellacci, A.M.; Castellini, M.; Diacono, M.; Rossi, R.; Gattullo, C.E. Assessment of soil quality under different soil management strategies: Combined use of statistical approaches to select the most informative soil physico-chemical indicators. Appl. Sci. 2021, 11, 5099. [Google Scholar] [CrossRef]
- Bricklemyer, R.S.; Brown, D.J.; Barefield, J.E.; Clegg, S.M. Intact Soil Core Total, Inorganic, and Organic Carbon measurement Using Laser-Induced Breakdown Spectroscopy. Soil Sci. Soc. Am. J. 2011, 75, 1006–1018. [Google Scholar] [CrossRef]
- Indahl, U.G.; Liland, K.H.; Næs, T. Canonical partial least squares—a unified PLS approach to classification and regression problems. J. Chemom. 2009, 23, 495–504. [Google Scholar] [CrossRef]
- Wetterlind, J.; Stenberg, B. Near-infrared spectroscopy for within-field soil characterization: Small local calibrations compared with national libraries spiked with local samples. Eur. J. Soil Sci. 2010, 61, 823–843. [Google Scholar] [CrossRef] [Green Version]
- Kunzová, E.; Hejcman, M. Yield development of winter wheat over 50 years of FYM, N, P and K fertilizer application on black earth soil in the Czech Republic. Field Crop. Res. 2009, 111, 226–234. [Google Scholar] [CrossRef]
- Šimon, T. Quantitative and qualitative characterization of soil organic matter in the long-term fallow experiment with different fertilization and tillage. Arch. Agron. Soil Sci. 2007, 53, 241–251. [Google Scholar] [CrossRef]
- Madaras, M.; Koubova, M.; Lipavský, J. Stabilization of available potassium across soil and climatic conditions of the Czech Republic. Arch. Agron. Soil Sci. 2010, 56, 433–449. [Google Scholar] [CrossRef]
- Stehlíková, I.; Madaras, M.; Lipavský, J.; Šimon, T. Study on some soil quality changes obtained from long-term experiments. Plant Soil Environ. 2016, 62, 74–79. [Google Scholar] [CrossRef]
- Smatanová, M.; Vodáková, M. Porovnání účinnosti Digestátů s Různými Typy Hnojiv při Hospodaření ve Zranitelné Oblasti; Technical Report; Ústřední Kontrolní a Zkušební ústav Zemědělský: Brno, Czech Republic, 2020. [Google Scholar]
- Lipavský, J.; Kubát, J.; Zobač, J. Long-term effects of straw and farmyard manure on crop yields and soil properties. Arch. Agron. Soil Sci. 2008, 54, 369–379. [Google Scholar] [CrossRef]
- Hejcman, M.; Kunzová, E.; Šrek, P. Sustainability of winter wheat production over 50 years of crop rotation and N, P and K fertilizer application on illimerized luvisol in the Czech Republic. Field Crop. Res. 2012, 139, 30–38. [Google Scholar] [CrossRef]
- Sparling, G.; Vojvodić-Vuković, M.; Schipper, L. Hot-water-soluble C as a simple measure of labile soil organic matter: The relationship with microbial biomass C. Soil Biol. Biochem. 1998, 30, 1469–1472. [Google Scholar] [CrossRef]
- Rinnan, Å.; Van den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Peris-Díaz, M.D.; Krężel, A. A guide to good practice in chemometric methods for vibrational spectroscopy, electrochemistry, and hyphenated mass spectrometry. TrAC Trends Anal. Chem. 2021, 135, 116157. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer Aided Design of Experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. A conditioned Latin hypercube method for sampling in the presence of ancillary information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Chen, S.; Arrouays, D.; Angers, D.A.; Martin, M.P.; Walter, C. Soil carbon stocks under different land uses and the applicability of the soil carbon saturation concept. Soil Tillage Res. 2019, 188, 53–58. [Google Scholar] [CrossRef]
- Six, J.; Conant, R.T.; Paul, E.A.; Paustian, K. Stabilization mechanisms of soil organic matter: Implications for C-saturation of soils. Plant Soil 2002, 241, 155–176. [Google Scholar] [CrossRef]
- Janik, L.; Forrester, S.; Rawson, A. The prediction of soil chemical and physical properties from mid-infrared spectroscopy and combined partial least-squares regression and neural networks (PLS-NN) analysis. Chemom. Intell. Lab. Syst. 2009, 97, 179–188. [Google Scholar] [CrossRef]
- Kynčlová, P.; Filzmoser, P.; Hron, K. Modeling compositional time series with vector autoregressive models. J. Forecast. 2015, 34, 303–314. [Google Scholar] [CrossRef]
- Blair, G.J.; Lefroy, R.D.B.; Lisle, L. Soil Carbon Fractions Based on their Degree of Oxidation, and the Development of a Carbon Management Index for Agricultural Systems. Aust. J. Agric. Res. 1995, 46, 1459–1466. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, X.; Hron, K. Partial least squares regression with compositional response variables and covariates. J. Appl. Stat. 2021, 48, 3130–3149. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Chapter Model Assessment and Selection. In The Elements of Statistical Learning; Springer: New York, NY, USA, 2009; pp. 219–260. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Oksanen, J.; Blanchet, F.G.; Friendly, M.; Kindt, R.; Legendre, P.; McGlinn, D.; Minchin, P.R.; O’Hara, R.B.; Simpson, G.L.; Solymos, P.; et al. Vegan: Community Ecology Package. Available online: https://CRAN.R-project.org/package=vegan (accessed on 19 February 2020).
- Stevens, A.; Ramirez-Lopez, L. An Introduction to the Prospectr Package. Available online: https://cran.r-project.org/web/packages/prospectr/vignettes/prospectr.html (accessed on 9 May 2022).
- Mevik, B.H.; Wehrens, R.; Liland, K.H. pls: Partial Least Squares and Principal Component Regression. Available online: https://CRAN.R-project.org/package=pls (accessed on 19 February 2020).
- Roudier, P. clhs: A R Package for Conditioned Latin Hypercube Sampling. Available online: https://CRAN.R-project.org/package=clhs (accessed on 19 February 2020).
- Van den Boogaart, K.G.; Tolosana-Delgado, R. “compositions”: A unified R package to analyze compositional data. Comput. Geosci. 2008, 34, 320–338. [Google Scholar] [CrossRef]
- Stallman, R.M.; McGrath, R.; Smith, P.D. GNU Make. A Program for Directing Recompilation; Free Software Foundation: Boston, MA, USA, 2016. [Google Scholar]
- Courtès, L.; Wurmus, R. Reproducible and User-Controlled Software Environments in HPC with Guix. In Proceedings of the Euro-Par 2015: Parallel Processing Workshops, Vienna, Austria, 24–25 August 2015; pp. 579–591. [Google Scholar] [CrossRef] [Green Version]
- Saeys, W.; Mouazen, A.M.; Ramon, H. Potential for Onsite and Online Analysis of Pig Manure Using Visible and Near Infrared Reflectance Spectroscopy. Biosyst. Eng. 2005, 91, 393–402. [Google Scholar] [CrossRef]
- Farmer, V. Transverse and longitudinal crystal modes associated with OH stretching vibrations in single crystals of kaolinite and dickite. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2000, 56, 927–930. [Google Scholar] [CrossRef]
- Madejová, J.; Kečkéš, J.; Pálková, H.; Komadel, P. Identification of components in smectite/kaolinite mixtures. Clay Miner. 2002, 37, 377–388. [Google Scholar] [CrossRef]
- Tatzber, M.; Stemmer, M.; Spiegel, H.; Katzlberger, C.; Haberhauer, G.; Gerzabek, M. An alternative method to measure carbonate in soils by FT-IR spectroscopy. Environ. Chem. Lett. 2007, 5, 9–12. [Google Scholar] [CrossRef]
- Demyan, M.; Rasche, F.; Schulz, E.; Breulmann, M.; Müller, T.; Cadisch, G. Use of specific peaks obtained by diffuse reflectance Fourier transform mid-infrared spectroscopy to study the composition of organic matter in a Haplic Chernozem. Eur. J. Soil Sci. 2012, 63, 189–199. [Google Scholar] [CrossRef]
- D’acqui, L.; Pucci, A.; Janik, L. Soil properties prediction of western Mediterranean islands with similar climatic environments by means of mid-infrared diffuse reflectance spectroscopy. Eur. J. Soil Sci. 2010, 61, 865–876. [Google Scholar] [CrossRef]
- Knox, N.; Grunwald, S.; McDowell, M.; Bruland, G.; Myers, D.; Harris, W. Modelling soil carbon fractions with visible near-infrared (VNIR) and mid-infrared (MIR) spectroscopy. Geoderma 2015, 239–240, 229–239. [Google Scholar] [CrossRef]
- Ng, W.; Minasny, B.; Malone, B.; Filippi, P. In search of an optimum sampling algorithm for prediction of soil properties from infrared spectra. PeerJ 2018, 6, e5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinkle, J.; Rayens, W. Partial least squares and compositional data: Problems and alternatives. Chemom. Intell. Lab. Syst. 1995, 30, 159–172. [Google Scholar] [CrossRef]
- Calderón, F.J.; Culman, S.; Six, J.; Franzluebbers, A.J.; Schipanski, M.; Beniston, J.; Grandy, S.; Kong, A.Y. Quantification of Soil Permanganate Oxidizable C (POXC) Using Infrared Spectroscopy. Soil Sci. Soc. Am. J. 2017, 81. [Google Scholar] [CrossRef]
- Yang, X.; Xie, H.; Drury, C.; Reynolds, W.; Yang, J.; Zhang, X. Determination of organic carbon and nitrogen in particulate organic matter and particle size fractions of Brookston clay loam soil using infrared spectroscopy. Eur. J. Soil Sci. 2012, 63, 177–188. [Google Scholar] [CrossRef]
- Stumpe, B.; Weihermüller, L.; Marschner, B. Sample preparation and selection for qualitative and quantitative analyses of soil organic carbon with mid-infrared reflectance spectroscopy. Eur. J. Soil Sci. 2011, 62, 849–862. [Google Scholar] [CrossRef]
- Parikh, S.J.; Goyne, K.W.; Margenot, A.J.; Mukome, F.N.; Calderón, F.J. Chapter One - Soil Chemical Insights Provided Through Vibrational Spectroscopy. Adv. Agron. 2014, 126, 1–148. [Google Scholar] [CrossRef] [Green Version]
- Tinti, A.; Tugnoli, V.; Bonora, S.; Francioso, O. Recent applications of vibrational mid-Infrared (IR) spectroscopy for studying soil components: A review. J. Cent. Eur. Agric. 2015, 16, 1–22. [Google Scholar] [CrossRef]
- Reeves, J.B. Mid-infrared diffuse reflectance spectroscopy: Is sample dilution with KBr necessary, and if so, when? Am. Lab. 2003, 35, 24–28. [Google Scholar]
- Brown, D.J. Using a global VNIR soil-spectral library for local soil characterization and landscape modeling in a 2nd-order Uganda watershed. Geoderma 2007, 140, 444–453. [Google Scholar] [CrossRef]
- Vohland, M.; Ludwig, B.; Seidel, M.; Hutengs, C. Quantification of soil organic carbon at regional scale: Benefits of fusing vis-NIR and MIR diffuse reflectance data are greater for in situ than for laboratory-based modelling approaches. Geoderma 2022, 405, 115426. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment a | Est. | Layout b | Crop Rotation c | Reference |
|---|---|---|---|---|
| CRE | 1956 | 1b × 3t | various (25%)–(WW or TR)–(POT or SB or SM)–(SBA or WW) | [49] |
| CRT | 1984 | 5b × 1t | WW and SBA (50–100%) complemented with CL, O, PEA, SB, SM | unpublished |
| FE | 1958 | 1b × 7t | fallow | [50] |
| FFFE | 1979 | 1b × 6t | (AL or CL)–WW–SM–WW–SBA–(SB or POT)–SBA | [51] |
| IOSDV | 1983 | 1b × 4t | (SB or POT)–SBA–WBA | [52] |
| OaMNFE(dc) | 2011 | 1b × 5t | POT–WW–SM–SBA–OSR–WW | [53] |
| OaMNFE(sf) | 1965 | 1b × 6t | WW–POT–SBA–LCM–WW–POT–O–CL | [54] |
| RFE | 1955 | 2b × 8t | SW–SB or AL–AL–WW–SB–SBA–POT–WW–SB–SBA | [55] |
| Statistics | Sample Partition | C Measurement | |||
|---|---|---|---|---|---|
| Raw | ilr-Transformed | ||||
| TC | HWC | ilrTC | ilrHWC | ||
| range | (%) | (mg g−1) | |||
| library | 0.73–4.45 | 0.13–2.55 | −5.63–−3.70 | −3.25–−1.97 | |
| Ústí nad Orlicí | 0.94–3.68 | 0.27–1.09 | −5.22–−4.19 | −2.83–−2.04 | |
| Janovice | 1.35–3.04 | 0.46–1.16 | −4.89–−4.21 | −2.47–−2.15 | |
| median | (%) | (mg g−1) | |||
| library | 1.41 | 0.38 | −4.98 | −2.54 | |
| Ústí nad Orlicí | 1.65 | 0.51 | −4.77 | −2.43 | |
| Janovice | 2.10 | 0.77 | −4.51 | −2.31 | |
| IQR | (pp) | (mg g−1) | |||
| library | 0.45 | 0.16 | 0.27 | 0.29 | |
| Ústí nad Orlicí | 0.46 | 0.17 | 0.23 | 0.17 | |
| Janovice | 0.32 | 0.16 | 0.14 | 0.09 | |
| n | library | 603 | |||
| Ústí nad Orlicí | 335 | ||||
| Janovice | 45 | ||||
| Performance Measure | ilrTC | ilrHWC | ||
|---|---|---|---|---|
| Ústí nad Orlicí | Janovice | Ústí nad Orlicí | Janovice | |
| R2 | −9.10 [−3.97, 0.33] 0.81 | −18.79 [−8.76, 0.57] 0.88 | −6.90 [−1.36, 0.18] 0.85 | −37.43 [−18.98, 0.35] 0.82 |
| bias | −0.42 [−0.30, 0.16] 0.32 | −0.49 [−0.47, 0.07] 0.21 | −0.19 [−0.13, 0.07] 0.14 | −0.28 [−0.24, 0.04] 0.09 |
| RMSEP | 0.07 [0.13, 0.35] 0.51 | 0.04 [0.08, 0.48] 0.51 | 0.05 [0.11, 0.19] 0.24 | 0.03 [0.04, 0.26] 0.29 |
| RPD | 0.33 [0.47, 1.27] 2.42 | 0.23 [0.33, 1.60] 3.01 | 0.37 [0.68, 1.15] 2.73 | 0.17 [0.23, 1.29] 2.45 |
| RPIQ | 0.30 [0.62, 1.70] 3.09 | 0.13 [0.26, 1.45] 2.52 | 0.38 [0.69, 1.26] 2.84 | 0.18 [0.30, 1.59] 3.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Żelazny , W.R.; Šimon , T. Calibration Spiking of MIR-DRIFTS Soil Spectra for Carbon Predictions Using PLSR Extensions and Log-Ratio Transformations. Agriculture 2022, 12, 682. https://doi.org/10.3390/agriculture12050682
Żelazny WR, Šimon T. Calibration Spiking of MIR-DRIFTS Soil Spectra for Carbon Predictions Using PLSR Extensions and Log-Ratio Transformations. Agriculture. 2022; 12(5):682. https://doi.org/10.3390/agriculture12050682
Chicago/Turabian StyleŻelazny , Wiktor R., and Tomáš Šimon . 2022. "Calibration Spiking of MIR-DRIFTS Soil Spectra for Carbon Predictions Using PLSR Extensions and Log-Ratio Transformations" Agriculture 12, no. 5: 682. https://doi.org/10.3390/agriculture12050682