1. Introduction
As one of the important greenhouse economic crops, cucumber plays an important role in the adjustment of agricultural structure and the increase in farmers’ income [
1]. Cucumber downy mildew and bacterial angular spot are commonly occurring diseases in greenhouses. The two diseases have a short disease period and are highly contagious, which can easily cause great economic loss for farmers. Currently, the development of greenhouse intelligent monitoring equipment has made more plant disease classification models that are applied to actual production, which is of great significance to ensure the economic benefits of farmers. However, the limited battery capacity, computation, and storage resources have become key factors that limit the use of deep learning models on edge devices. Many studies chose to deploy diagnosis models to the server-side and transmitted plant disease images taken by edge devices to servers for disease classification [
2,
3,
4]. However, a large amount of data traffic and transportation latency make the model inefficient, unreliable, and time consuming [
5]. Therefore, the question of how to design a disease diagnosis model with low computational energy consumption, small model size, and low computation amount attracts many researchers’ attention.
Traditional disease classification models are mainly built based on machine learning technology. With the rapid development of deep learning, convolutional neural networks (CNNs) have become the basic structure for researchers to build plant disease classification models [
6,
7,
8]. The energy consumed by the convolutional neural network for forwarding propagation is mainly composed of computational energy consumption and memory access energy consumption. Among these, the memory energy of the model is affected by many factors, such as the model structure, the development framework, the hardware status, and so on. Some researchers proposed efficient memory management strategies for CPU (Central Processing Unit) or GPU (Graphic Processing Unit) to reduce memory access energy consumption, and these methods perform better in many tasks [
9,
10]. However, there are fewer studies that put focus on reducing the calculation energy consumption of disease diagnosis models.
In this study, reducing computation amount and changing feature extraction are explored to reduce the model’s computational energy consumption. Concretely, CNNs extract disease spot features by sliding the convolutional kernel on images, and the parameters of convolutional kernels constantly adjust and update in the process of backpropagation to obtain stronger feature extraction capabilities. This learning method makes models designed based on CNNs attain some promising results on disease diagnosis tasks, but feature extraction methods also cause the model to have high computational energy consumption. From the perspective of reducing the computation amount of convolution models, traditional methods manually select specific disease features to build simple diagnostic models. Zhou et al. [
11] proposed using a single-feature two-dimensional XY-color histogram to select features as the input of the classifier. Many researchers [
12,
13,
14,
15] designed algorithms to obtain plant disease spots features. They firstly extracted multiple features such as color, texture, spot area, and the number of lesion regions and then send these features to simple classification models. The above methods greatly reduce the calculation amount of the model, but fewer input features will reduce the classification accuracy of the model. Convolution models can not only extract detailed features such as color and texture of diseased spots but also extract high-level semantical features of diseased spots. This is the main reason that convolutional neural networks have higher diagnostic accuracy compared with traditional machine learning methods. To obtain better diagnosis performance, some researchers built models with complex structures, but this induces a larger amount of parameters in models and makes these models require more storage resources [
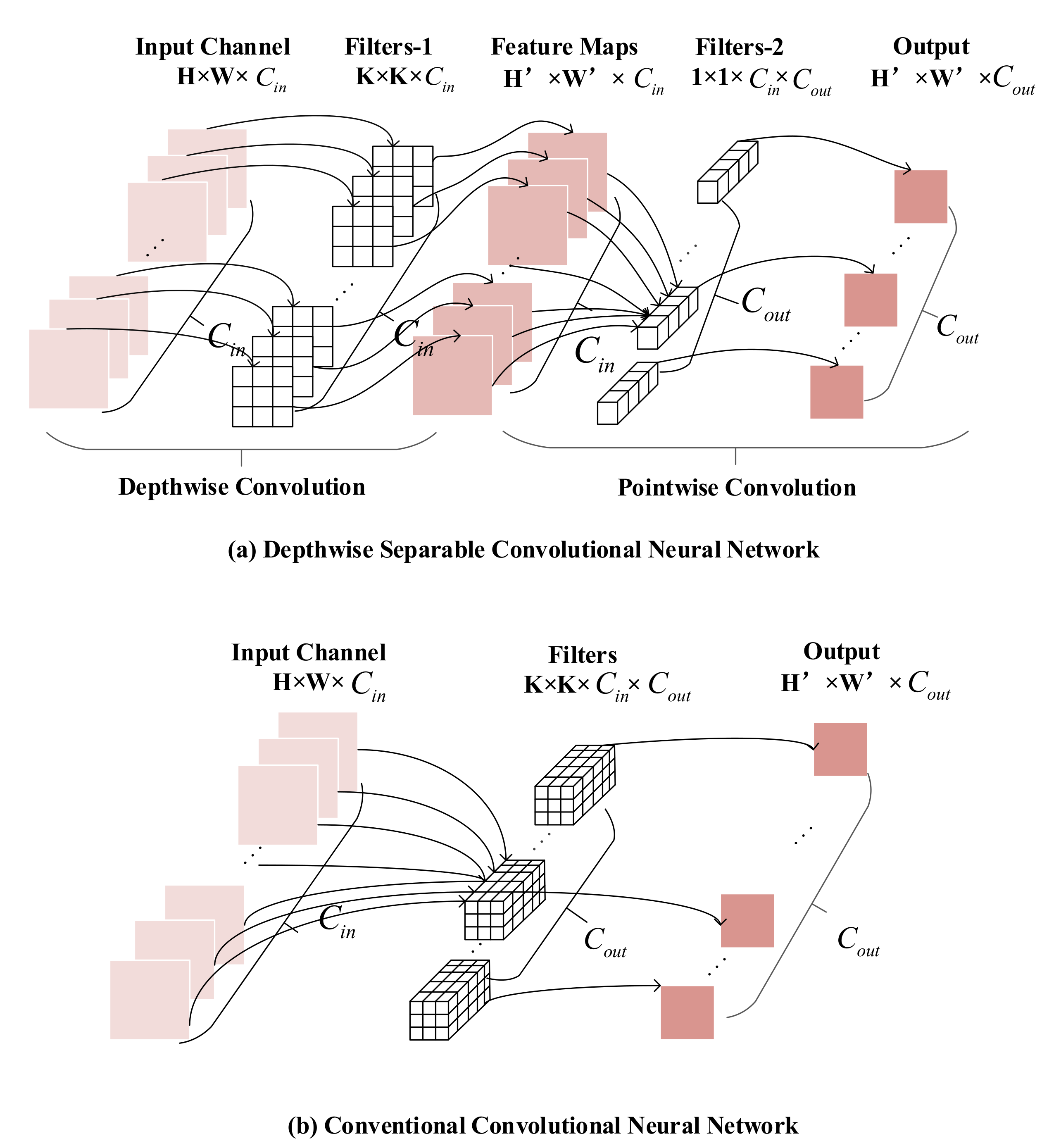
16]. Recently, the depthwise separable convolution module has provided a new solution on model compression. Kamal et al. [
17] and De Ocampo and Dadios [
18] used the depthwise separable convolution module to construct models, which greatly reduced the size and computation of the model and improved the applicability of the model on mobile devices. However, the module will reduce the diagnosis accuracy of models. To improve the diagnosis effect, some researchers used an optimization method to ensure classification accuracies, such as the squeeze-and-excitation module [
19,
20,
21]. These studies gave us a lot of inspiration.
In terms of feature extraction methods, the multiplicative calculation method of the convolutional neural network makes the model consume more energy on devices [
22]. To solve this problem, Courbariaux et al. [
23] constructed BinaryConnect, a neural network with a mixture of binary and single precision, and converted the network weight into binary, achieving a very high accuracy at that time. Hubara et al. [
24] proposed to convert the activation function into binary at runtime, which increased the speed by seven times on the GPU. Although the above methods achieved good energy-saving effects, the low classification accuracy of the binary neural network is still a main factor restricting its application. Chen et al. [
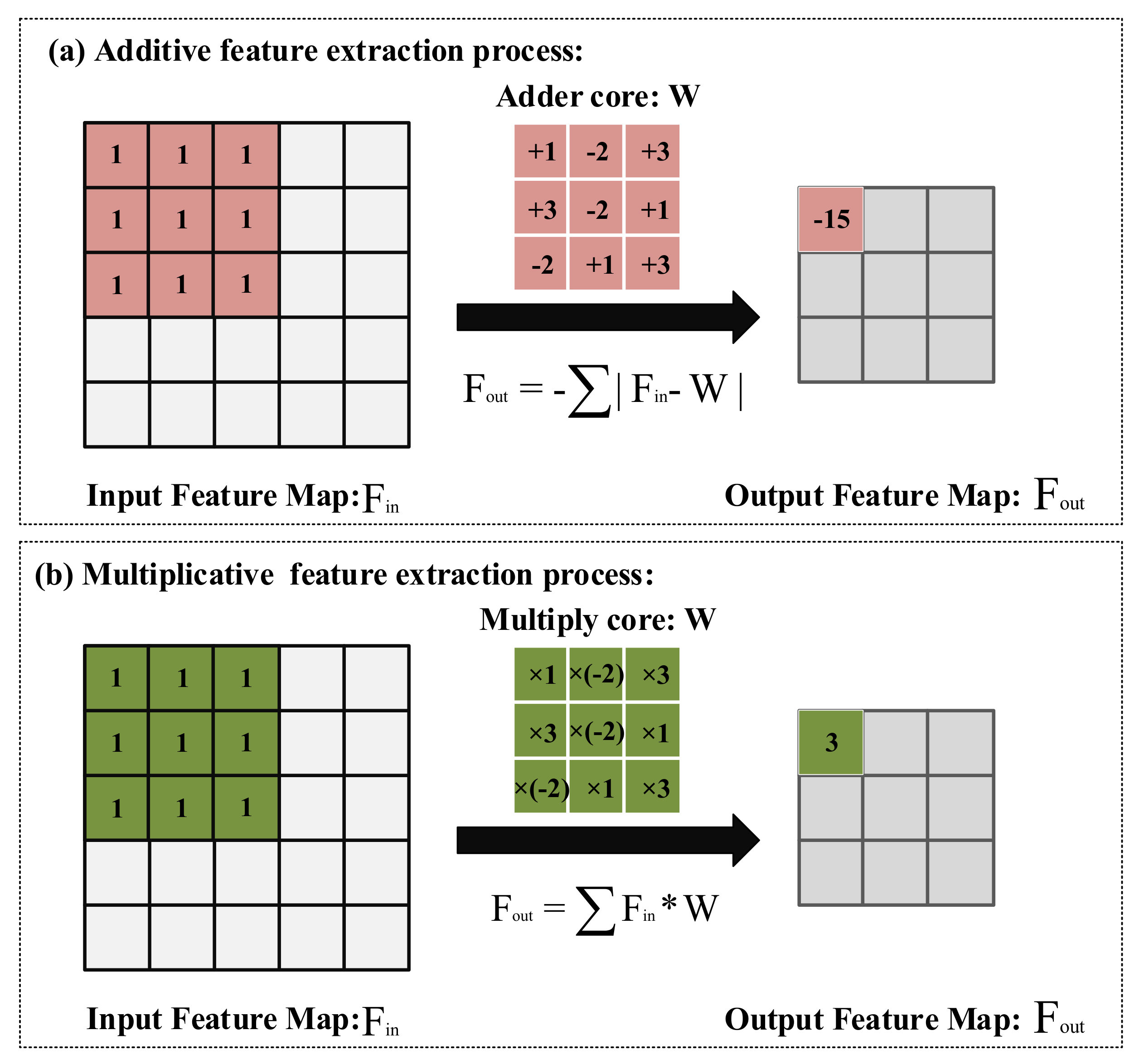
22] proposed using addition to extract features from images, which can greatly reduce the calculation energy consumption of the model. This study proves that addition as a feature extraction method is feasible.
Motivated by the above studies, we propose an energy-saving plant disease diagnosis model with less computation energy consumption. The core contributions can be summarized as follows:
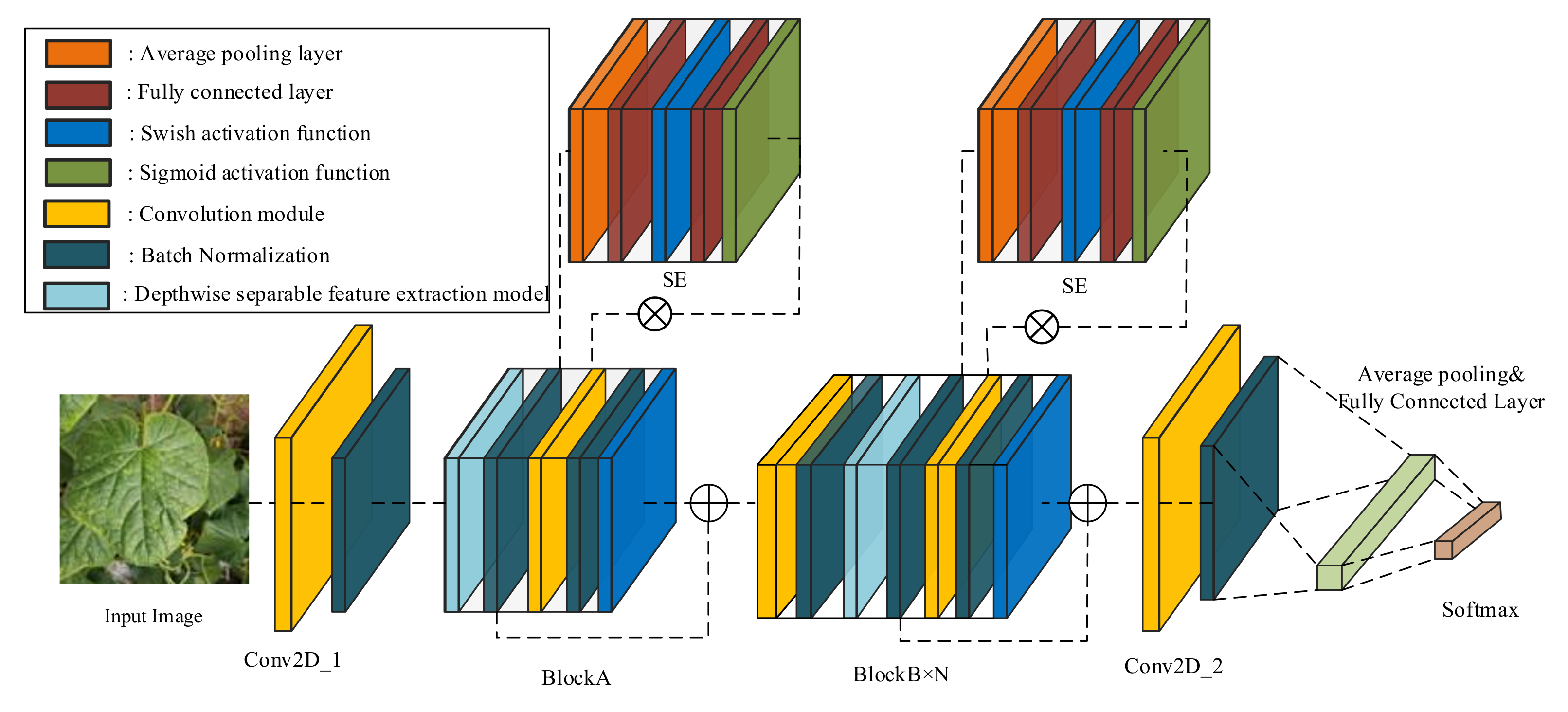
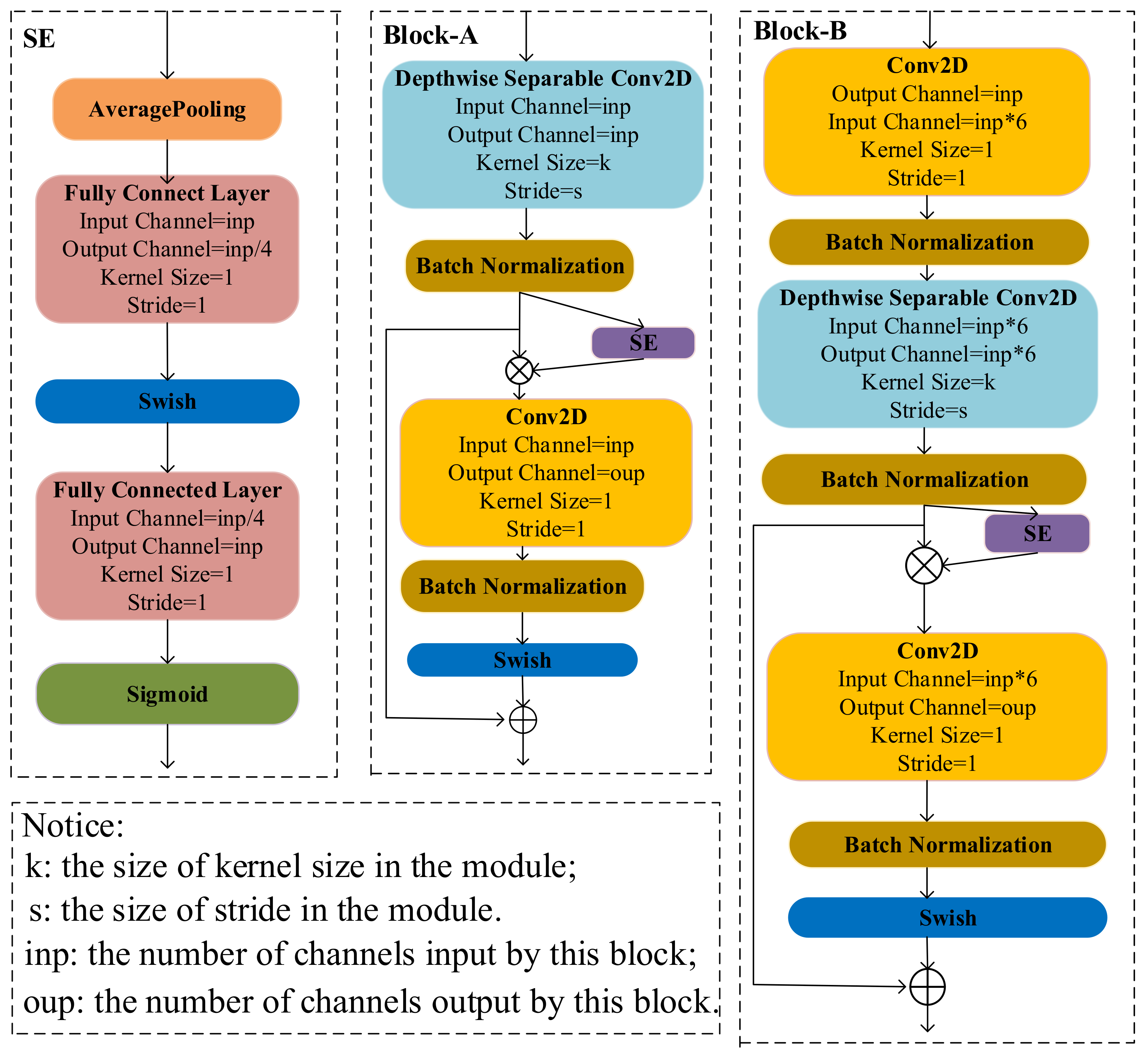
Considering that models constructed by depthwise separable convolution modules have a small calculation amount, the cucumber disease dataset is constructed based on it. To improve the model’s classification accuracy on the cucumber disease dataset with complex backgrounds, the squeeze-and-excitation module, the shortcut connection, and the channel expansion strategy are used to construct a model called CNNLight.
To further reduce the computation energy consumption of the model, an additive feature extraction method is used to construct the depthwise separable additive feature extraction module and the additive squeeze-and-excitation module.
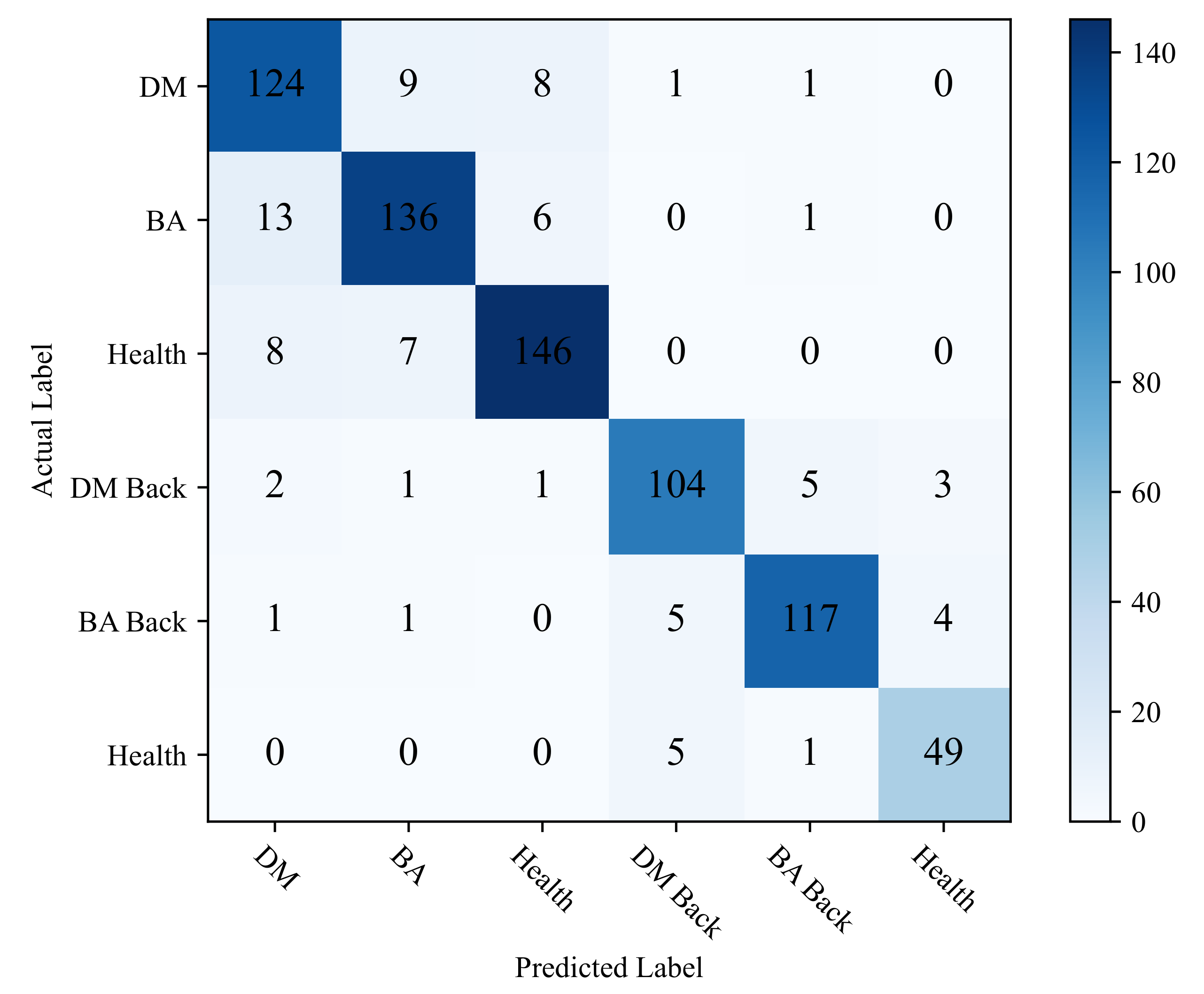
Modules constructed by additive feature extraction methods are used to construct ADDLight, which has the same structure as CNNLight. The experimental results show that ADDLight has low calculation energy consumption and relatively high classification accuracy for the cucumber disease task.
4. Discussion
The question of how to design a model with high applicability on edge devices is an urgent problem in the agricultural engineering field. In this study, we used a depthwise separable feature extraction module and the squeeze-and-excitation module (SE) as basic modules to design a low energy-consumption model. The experimental results show that SE can make up for the deficiency of the low classification accuracy caused by the depthwise separable feature extraction module. Chen et al. [
20] had the same idea as this study, but they only used the squeeze-and-excitation module to improve MobileNet’s classification performance rather than exploring a new combination structure. Their experimental results show that their proposed model with the depthwise separable convolution module and SE module is 1.15% higher than that of MobileNet-V2 on the rice dataset. In addition, the shortcut connection and channel expansion strategies are also used to improve classification accuracy. The ablation experiment shows good improvement for the two strategies. Both experiments of [
36,
37] were consistent with our experimental results.
To reduce the computational energy consumption of the model on edge devices, the proposed model is constructed by using an additive feature extraction method. The experimental results show that the adder disease classification model can greatly reduce energy consumption and prolong the working time of greenhouse devices, but the addition method impairs the classification performance of the model to a certain extent. Distinct from our method, De et al. [
38] used the quantization method to compress the 32-bit parameters of the model into 4-bits in order to reduce the energy consumption and calculation amount of the model. The experimental results show that the quantization method can reduce the average energy consumption of the model by 6.5 times, and model quantization also reduces the classification accuracy of the model by about 1%. Although the experimental results proved that model quantization had little influence on classification accuracy, the model only used four categories of coffee-infected leaves for training and testing; thus, its conclusion was not very convincing in terms of classification accuracy. Similarly, Zhou et al. [
19] quantified MobileNet’s weight tensor and activation function data from 32-bit to 8-bit. In their experiment, the quantization method reduced the model size of MobileNet V2 from 17.5 MB to 4.5 MB but resulted in a 1.1% loss in model classification accuracy. In this paper, the model size of the cucumber disease classification model we constructed in this paper is only 0.479 MB, and energy consumption was reduced to 96% by using the additive feature extraction method. Although the accuracy of the model is reduced by 1.1% compared with CNNLight, this model still has high applicability in real application scenarios. In future studies, we will continue to explore the main reasons affecting the classification accuracy of the adder cucumber disease classification model.
5. Conclusions
To improve the model’s applicability on edge devices and to extend the working time of the device, this study aims at constructing a low-energy-consumption additive cucumber disease classification model from the perspective of changing the feature extraction method and reducing computation amounts. The main achievements can be summarized as follows.
Firstly, we used the depthwise separable feature extraction module, the squeeze-and-excitation module, the short-cut connection strategy, and channel expansion strategy to design a lightweight cucumber disease classification model with good classification accuracy. The computational energy consumption of the model was reduced from the perspective of reducing the computation amount.
Secondly, the depthwise additive feature extraction and the additive squeeze-and-excitation modules were constructed to construct the disease classification model. Since the addition calculation has lower computational consumption than other operations, the model designed in this study also reduces computational energy consumption from the perspective of changing the calculation method.
Thirdly, compared with the convolutional neural network with the same structure, the computational energy consumption of the adder cucumber disease classification model is reduced by 96.1%. The experimental result shows that the model has high applicability for greenhouse edge devices. Although the final classification accuracy of the model is 1.1% lower than that of the convolutional neural network with the same structure, the classification accuracy of 89.1% can still meet the requirements of the cucumber disease warning task under complex environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}