


Goat-Face Recognition in Natural Environments Using the Improved YOLOv4 Algorithm

 ,
,
Abstract
:1. Introduction
2. Experimental Data
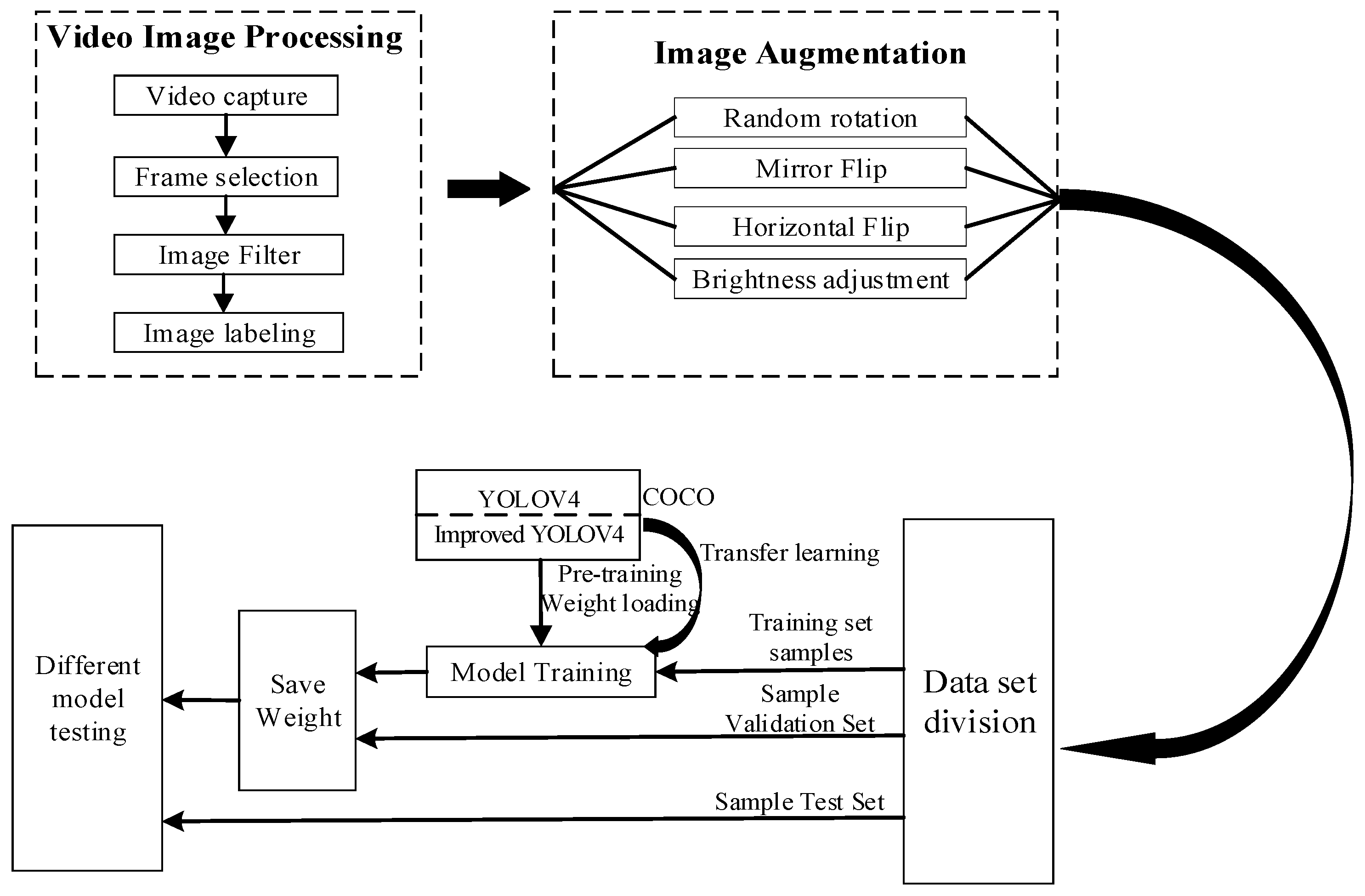
2.1. Experimental Data Sources
2.2. Data Pre-Processing and Labeling
3. YOLOv4 Recognition Algorithm
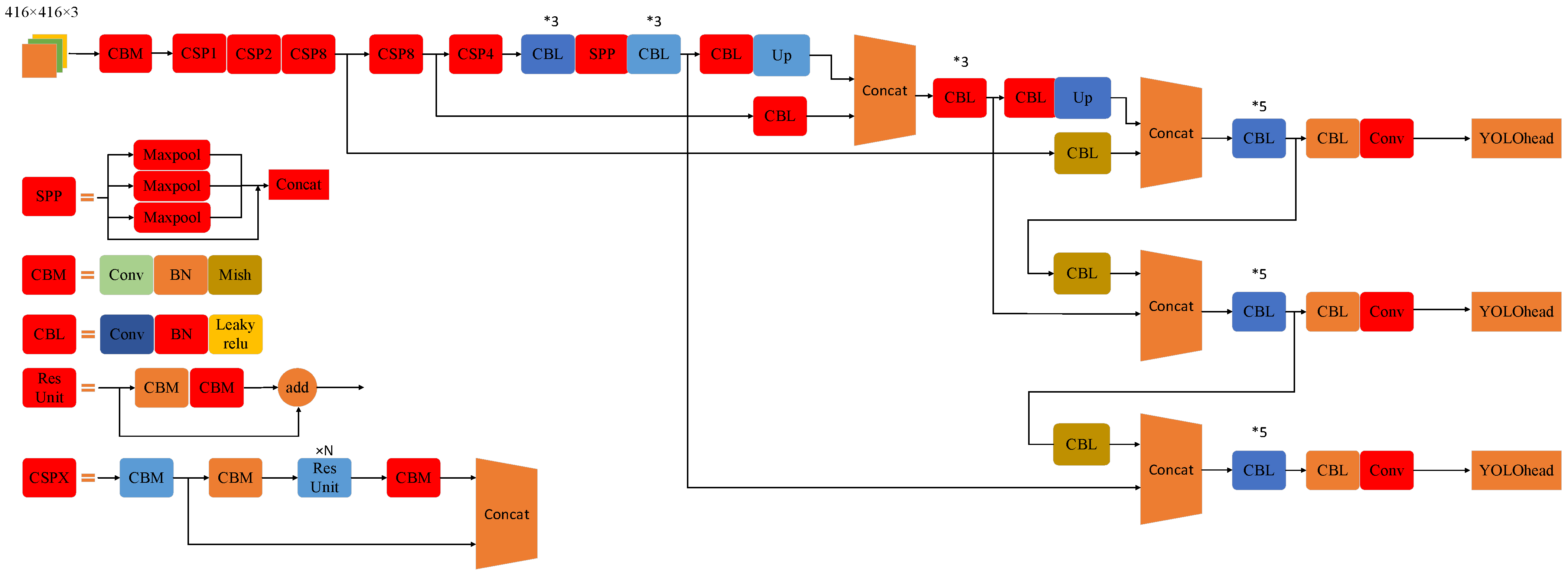
3.1. YOLOv4 Algorithm
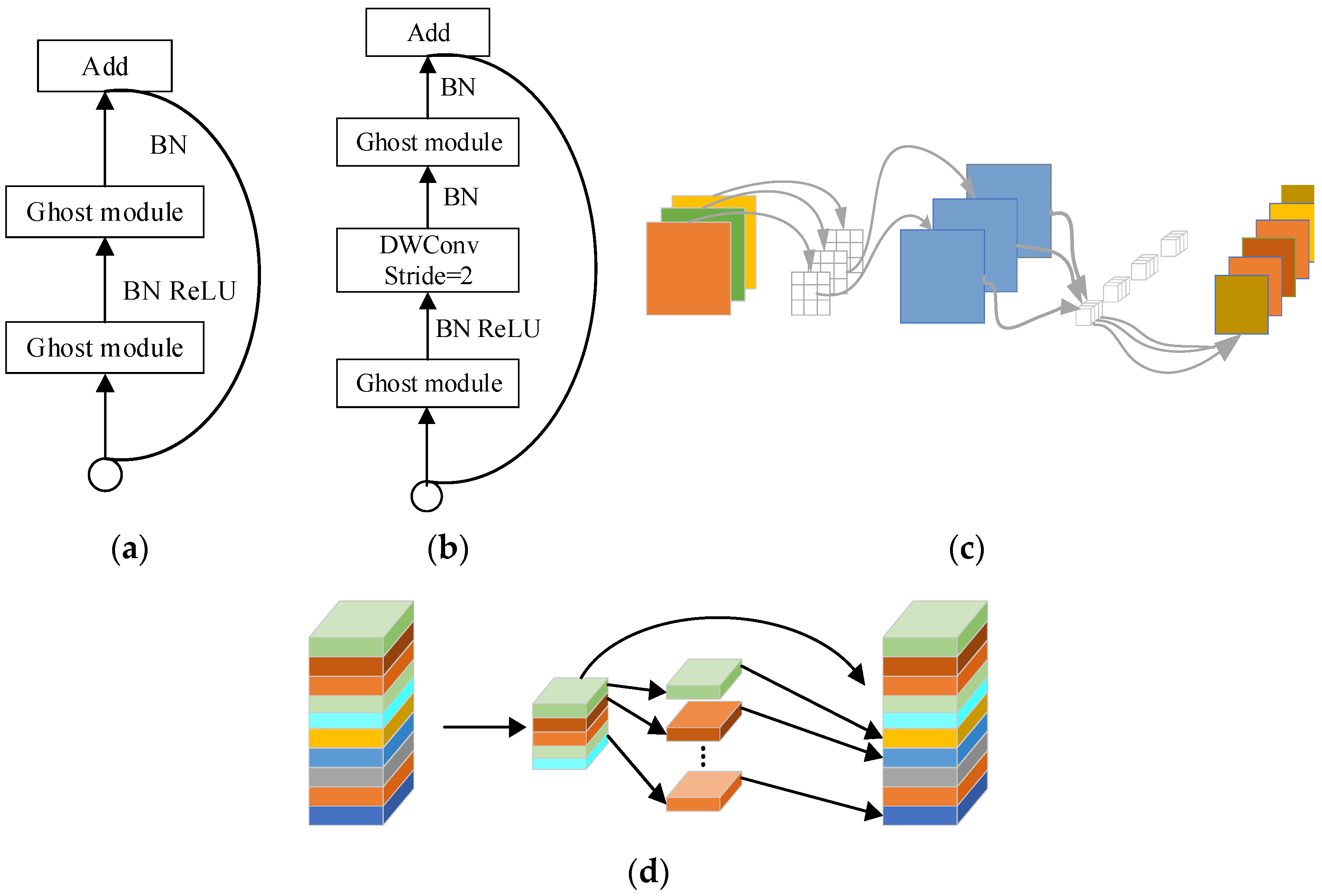
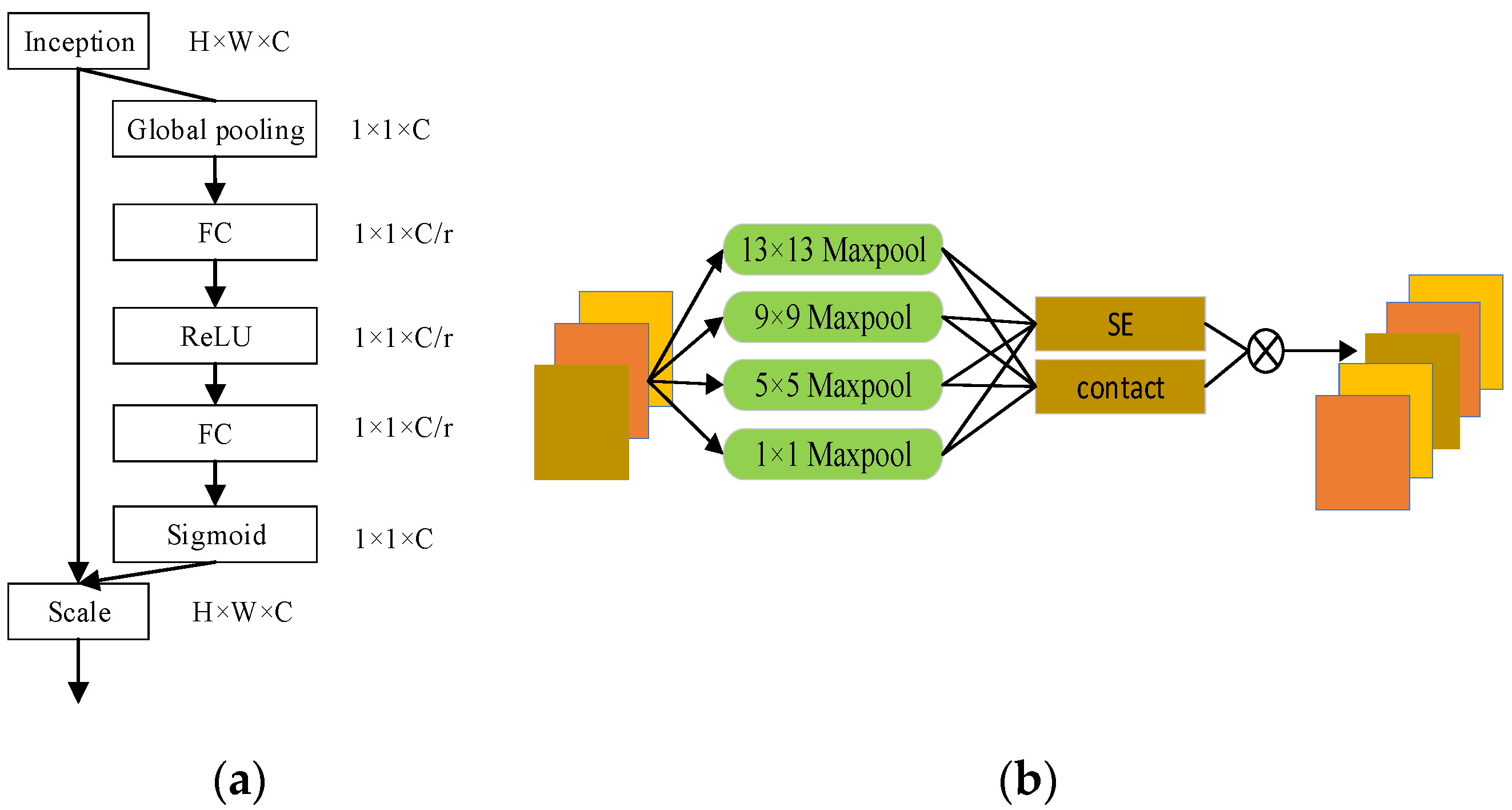
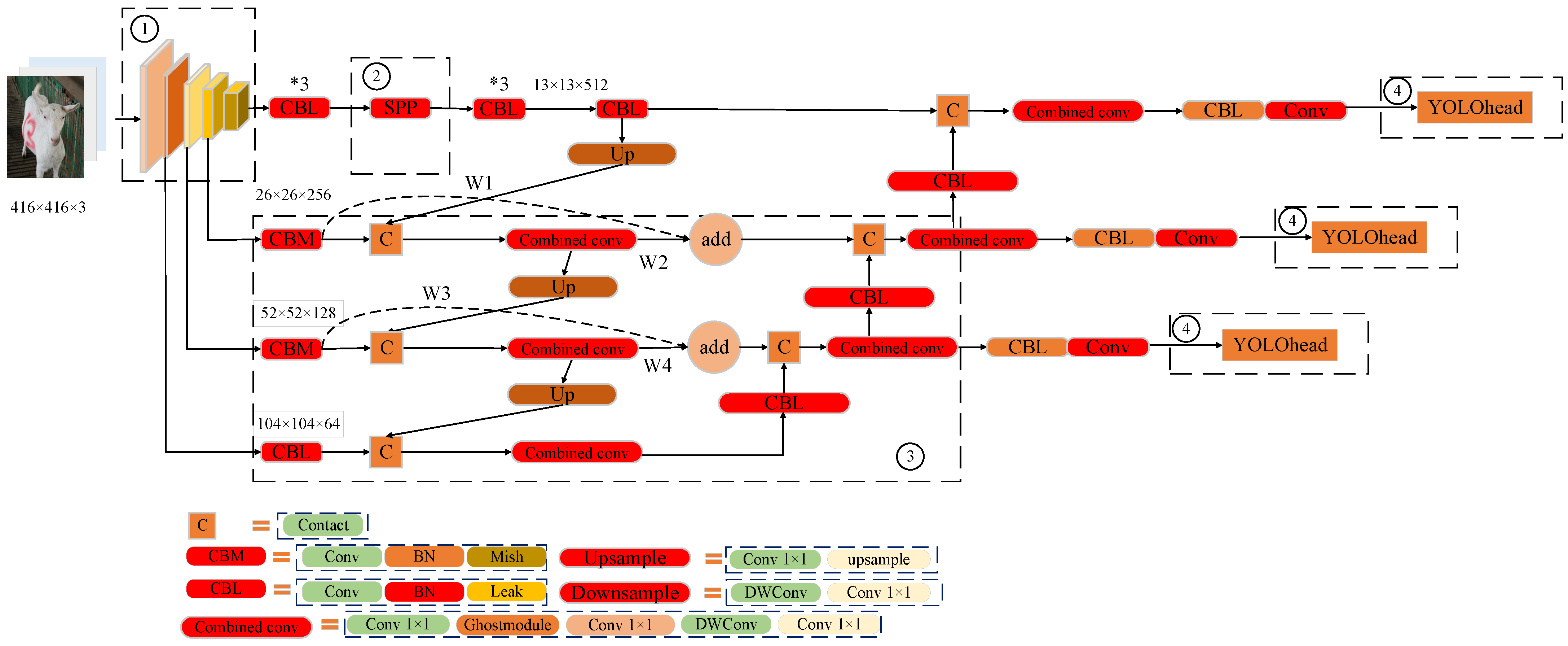
3.2. Improved Goat-Face-Recognition-Algorithm Construction
3.3. YOLOv4 Objective Loss Function
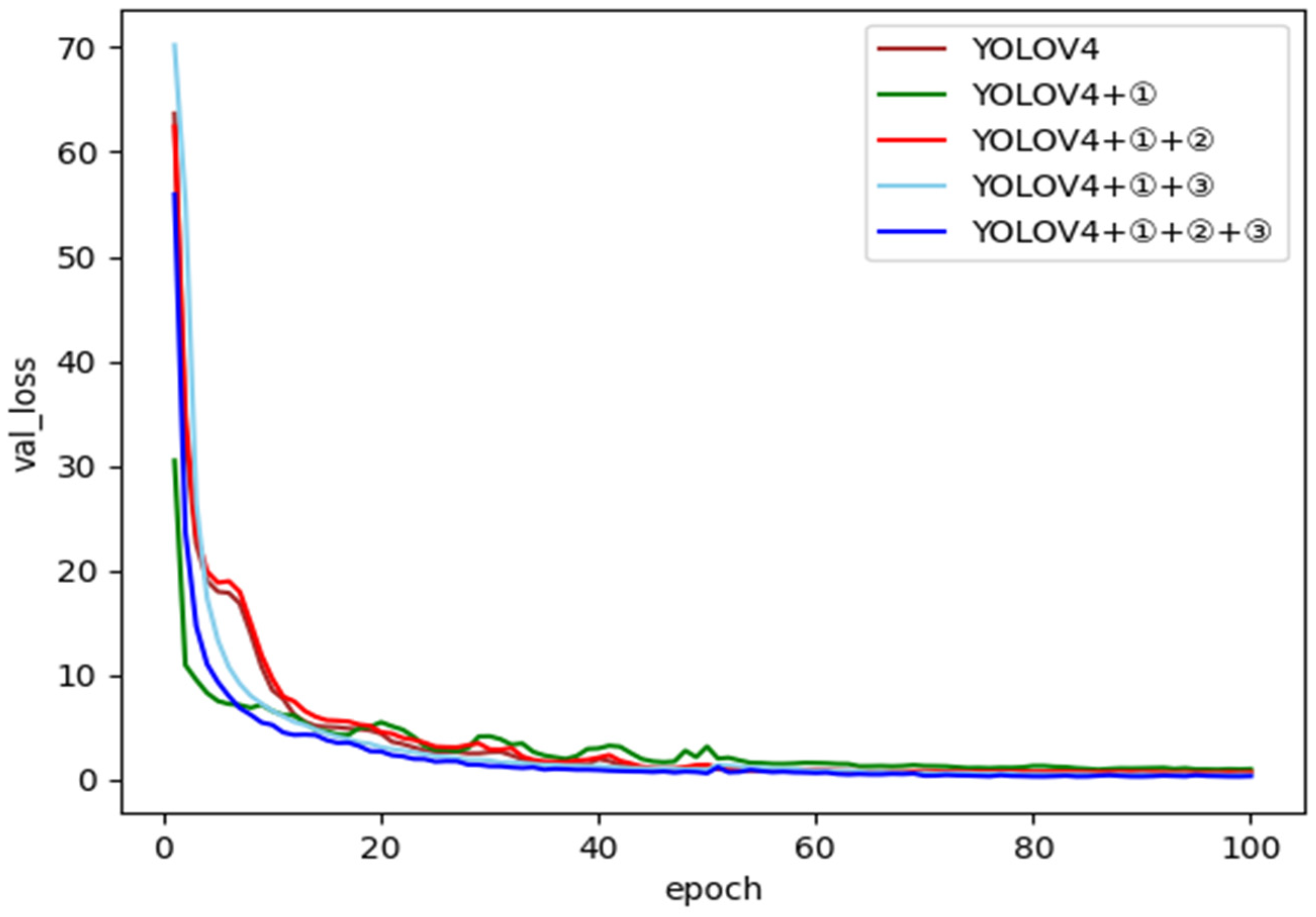
3.4. Training of Models
3.4.1. Model Training and Parameters
3.4.2. Model-Evaluation Indicators
4. Results and Discussion
4.1. Comparison of Frontal Face Results of Different Models
4.2. Recognition Results of Different Models for Side-Facing Dairy Goats
5. Conclusions
- (1)
- The backbone network in YOLOv4 was replaced by a GhostNet lightweight network structure to address the problems of the large number of YOLOv4 network parameters, low accuracy of goat-face-recognition, and slow recognition speed. After replacing the backbone, the goat-face-recognition network can reduce the number of network parameters and improve the operation speed and detection efficiency of the model.
- (2)
- The SPP and PANet structure in YOLOv4 was changed to a pyramid structure with a spatial attention mechanism and a fusion network with a residual structure in the form of double parameters. The improved goat-face-recognition network enhances the detectability of fine-grained features and improves the detection of similar faces. The improved goat-face-recognition network improved on the frontal face recognition of the YOLOv4 by 2.1%, and the mAP reached 96.7%. In terms of the side-face detection, the improved goat-face-recognition model improved on the YOLOv4 by 7% compared. The model’s detection speed was up to 28 frames/s to meet the needs of real-time monitoring. However, the network still needs to be improved in terms of side-face recognition to improve the accuracy with which it identifies individual goats.
- (3)
- This study mainly focuses on the characteristics of goats’ facial texture features, which become less different and difficult to recognize. Furthermore, it proposes a low-cost and high-efficiency improved lightweight YOLOv4 face-recognition model. In order to further achieve individual-goat recognition in flock scenarios, future research will be carried out on flock goats on large-scale farms. By constructing a goat-face-detection network, the interception of goat faces will be achieved. The data will be transmitted to the improved YOLOv4 model to achieve the recognition of goats in multiple situations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kukreja, V.; Kumar, D.; Bansal, A.; Solanki, V. Recognizing wheat aphid disease using a novel parallel real-time technique based on mask scoring RCNN. In Proceedings of the International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Noida, India, 28–29 April 2022. [Google Scholar]
- Kumar, D.; Kukreja, V. Quantifying the severity of loose smut in wheat using MRCNN. In Proceedings of the International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022. [Google Scholar]
- Kumar, D.; Kukreja, V. N-CNN based transfer learning method for classification of powdery mildew wheat disease. In Proceedings of the International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 5–7 March 2021. [Google Scholar]
- Kumar, D.; Kukreja, V.; Kadyan, V.; Mittal, M. Detection of DoS attacks using machine learning techniques. Int. J. Veh. Auton. Syst. 2020, 15, 256–270. [Google Scholar] [CrossRef]
- Kukreja, V.; Kumar, D. Automatic classification of wheat rust diseases using deep convolutional neural networks. In Proceedings of the International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 3–4 September 2021. [Google Scholar]
- Kumar, D.; Vinay, K. An instance segmentation approach for wheat yellow rust disease recognition. In Proceedings of the International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 7–8 December 2021. [Google Scholar]
- Kumar, D.; Kukreja, V. Image-based wheat mosaic virus detection with Mask-RCNN model. In Proceedings of the International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022. [Google Scholar]
- Gu, J.Q.; Wang, Z.H.; Gao, R.H.; Wu, H.R. Recognition method of cow behavior based on combination of image and activities. Trans. Chin. Soc. Agric. Mach. 2021, 52, 141–150. [Google Scholar]
- Wang, K.; Liu, C.H.; Duan, Q.L. Identification of sow oestrus behavior based on MFO-LSTM. Trans. Chin. Soc. Agric. Eng. 2020, 36, 211–219. [Google Scholar]
- Song, H.B.; Ning, M.T.; Ji, C.H.; Li, Z.Y.; Zhu, Q.M. Monitoring of multi-target cow ruminant behavior based on video analysis technology. Trans. Chin. Soc. Agric. Eng. 2017, 34, 219–225. [Google Scholar]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behavior in cattle. Comput. Electron. Agric. Vol. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Liu, Z.C.; Zhai, T.S.; He, D.J. Research status and progress of individual information monitoring of dairy cows in precision breeding. Heilongjiang Anim. Sci. Vet. Med. 2019, 30–33+38. [Google Scholar]
- Xu, B.B.; Wang, W.S.; Guo, L.F.; Chen, G.P. A review and future prospects on cattle recognition based on non-contact identification. J. Agric. Sci. Technol. 2020, 22, 79–89. [Google Scholar]
- Yao, Z.; Tan, H.; Tian, F.; Zhou, Y.; Zhang, C. Research progress of computer vision technology in wisdom goat farm. China Feed 2021, 7–12. [Google Scholar]
- Leslie, E.; Hernandez-Jover, M.; Newman, R.; Holyoake, P. Assessment of acute pain experienced by piglets from ear tagging, ear notching and intraperitoneal injectable transponders. Appl. Anim. Behav. Sci. 2010, 127, 86–95. [Google Scholar] [CrossRef]
- Gonzales Barron, U.; Corkey, G.; Barry, B.; Butler, F.; McDonnell, K.; Ward, S. Assessment of retinal recognition technology as a biometric method for goat identification. Comput. Electron. Agric. 2008, 60, 156–166. [Google Scholar] [CrossRef]
- Adell, N.; Puig, P.; Rojas-Olivares, A.; Caja, G.; Carne, S.; Salama, A.A.K. A bivariate model for retinal image identification in lamb. Comput. Electron. Agric. 2012, 87, 108–112. [Google Scholar] [CrossRef]
- Wei, Z. Research on Imperfect Bivine Iris Recognition Based on Combination of Local Features and Gloabal Features. Master’s Thesis, Southeast University, Nanjing, China, 2017. [Google Scholar]
- Xie, L.L. Design and research of convolutional neural networks based intelligent campus face recognition system. Comput. Era 2021, 72–74. [Google Scholar]
- Wang, B.; Le, H.X.; Li, W.J.; Zhang, M.H. Mask detection algorithm based on improved YOLO lightweight network. Comput. Eng. Appl. 2021, 57, 62–69. [Google Scholar]
- Tang, F.G.; Wu, X.D.; Zhu, Z.Y.; Wan, Z.G.; Chang, Y.C.; Du, Z.P.; Gu, L.L. An end-to-end face recognition method with alignment learning. Optik 2020, 205, 164238. [Google Scholar] [CrossRef]
- Chen, Y.S.; Kuan, C.Y.; Hsu, J.T.; Lin, T.T. Lightweight Cow Face Recognition Algorithm based on Few-Shot Learning for Edge Computing Application. In Proceedings of the American Society of Agricultural and Biological Engineers (ASABE), Anaheim, CA, USA, 12–16 July 2021. [Google Scholar]
- Kumar, S.; Pandey, A.; Satwik, K.S.R.; Kumar, S.; Singh, S.K.; Singh, A.K.; Mohan, A. Deep learning framework for recognition of cattle using muzzle point image pattern. Measurement 2018, 116, 1–17. [Google Scholar] [CrossRef]
- Huang, W.J.; Zhu, W.X.; Ma, C.H.; Guo, Y.Z. Weber Texture local descriptor for identification of group-housed pigs. Sensors 2020, 20, 4649. [Google Scholar] [CrossRef]
- Weng, Z.; Meng, F.; Liu, S.Q.; Zhang, Y.S.; Zheng, Z.Q. Cattle face recognition based on a Two-Branch convolutional neural network. Comput. Electron. Agric. 2022, 196, 1–9. [Google Scholar] [CrossRef]
- Yang, S.Q.; Liu, Y.Q.H.; Wang, Z.; Han, Y.Y.; Wang, Y.S.; Lan, X.Y. Improved YOLO V4 model for face recognition of diary cow by fusing coordinate information. Trans. Chin. Soc. Agric. Eng. 2021, 37, 129–135. [Google Scholar]
- Yan, H.W.; Liu, Z.Y.; Cui, Q.L.; Hu, Z.W. Multi-object pig detection based on feature pyramid attention and deep convolutional network. Trans. Chin. Soc. Agric. Eng. 2020, 36, 193–202. [Google Scholar]
- Hu, Z.W.; Yang, H.; Lou, T.T. Detection of herd Pigs using double attention feature pyramid Network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 166–174. [Google Scholar]
- He, Y.T.; Li, B.; Zhang, F.; Tao, H.B.; Gu, L.C.; Jiao, J. Pig face recognition based on improved YOLOv3. J. China Agric. Univ. 2021, 26, 53–62. [Google Scholar]
- Wang, R.; Shi, Z.F.; Gao, R.H.; Li, Q.F. Pig individual recognition based on multi-scale convolutional network in variable environment. Acta Agric. Univ. Jiangxiensis 2020, 42, 391–400. [Google Scholar]
- Yang, A.Q.; Xue, Y.J.; Huang, H.S.; Huang, N.; Tong, X.X.; Zhu, X.M.; Yang, X.F.; Mao, L.; Zheng, C. Lactating sow image segmentation based on fully convolutional networks. Trans. Chin. Soc. Agric. Eng. 2017, 33, 219–225. [Google Scholar]
- Han, D.; Wang, B.; Wang, L.; Hou, Y.C.; Tian, H.Q.; Zhang, S.L. Individual Pain Recognition Method of Goat Based on Improved VGGNet. Trans. Chin. Soc. Agric. Mach. 2022, 53, 311–317. [Google Scholar]
- Zhang, H.M.; Zhou, L.X.; Li, Y.H.; Hao, J.Y.; Sun, Y.; Li, S.Q. Sheep face recognition method based on improved MobileFaceNet. Trans. Chin. Soc. Agric. Mach. 2022, 53, 267–274. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FPS | mAP | Weight/M | Params | Flops/G | Memory/M |
|---|---|---|---|---|---|---|
| YOLOv4 | 26 | 94.6 | 244.0 | 64,093,851 | 29.98 | 606.95 |
| YOLOv4+① | 35 | 85.8 | 152.0 | 39,982,331 | 13.00 | 266.69 |
| YOLOv4+①+② | 31 | 89.9 | 153.0 | 40,015,643 | 13.00 | 266.70 |
| YOLOv4+①+③ | 30 | 93.4 | 57.0 | 11,440,293 | 4.62 | 428.61 |
| YOLOv4+①+②+③ | 28 | 96.7 | 57.6 | 11,473,605 | 4.62 | 428.62 |
| Model | Goat6 | Goat9 | Goat13 | Goat17 | Goat21 | mAP |
|---|---|---|---|---|---|---|
| YOLOv4 | 38 | 42 | 24 | 32 | 24 | 71 |
| YOLOv4+① | 38 | 42 | 24 | 32 | 24 | 58 |
| YOLOv4+①+② | 38 | 42 | 24 | 32 | 24 | 69 |
| YOLOv4+①+③ | 38 | 42 | 24 | 32 | 24 | 72 |
| YOLOv4+①+②+③ | 38 | 42 | 24 | 32 | 24 | 78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Wang, S.; Cui, X.; Wang, X.; Cao, W.; Yu, H.; Fu, S.; Pan, X. Goat-Face Recognition in Natural Environments Using the Improved YOLOv4 Algorithm. Agriculture 2022, 12, 1668. https://doi.org/10.3390/agriculture12101668
Zhang F, Wang S, Cui X, Wang X, Cao W, Yu H, Fu S, Pan X. Goat-Face Recognition in Natural Environments Using the Improved YOLOv4 Algorithm. Agriculture. 2022; 12(10):1668. https://doi.org/10.3390/agriculture12101668
Chicago/Turabian StyleZhang, Fu, Shunqing Wang, Xiahua Cui, Xinyue Wang, Weihua Cao, Huang Yu, Sanling Fu, and Xiaoqing Pan. 2022. "Goat-Face Recognition in Natural Environments Using the Improved YOLOv4 Algorithm" Agriculture 12, no. 10: 1668. https://doi.org/10.3390/agriculture12101668