The Comparison of Density-Based Clustering Approach among Different Machine Learning Models on Paddy Rice Image Classification of Multispectral and Hyperspectral Image Data

Abstract
:1. Introduction
- The ability to interpret different types of characteristic spectra is solved by increasing ancillary information [5,6,7,11,12] to improve the classification accuracy of an image. Researchers usually use supervised classifiers to resolve image processing problems [10,13,14,15]. Therefore, ancillary information has become an alternative component of the analyzed dataset to enhance classification outcomes. Adding different types of band information may help improve classification results.
- Suitable classification approaches for models can improve classification results. In addition, the selection of applicable mathematical algorithms for high-precision parameters is important to model the data and verify the classification outcomes. Generally speaking, the establishment of synchronized image capture and ground survey operations can provide high accuracy in various modeling and different features [14,15,16,17,18,19].
2. Materials and Methods
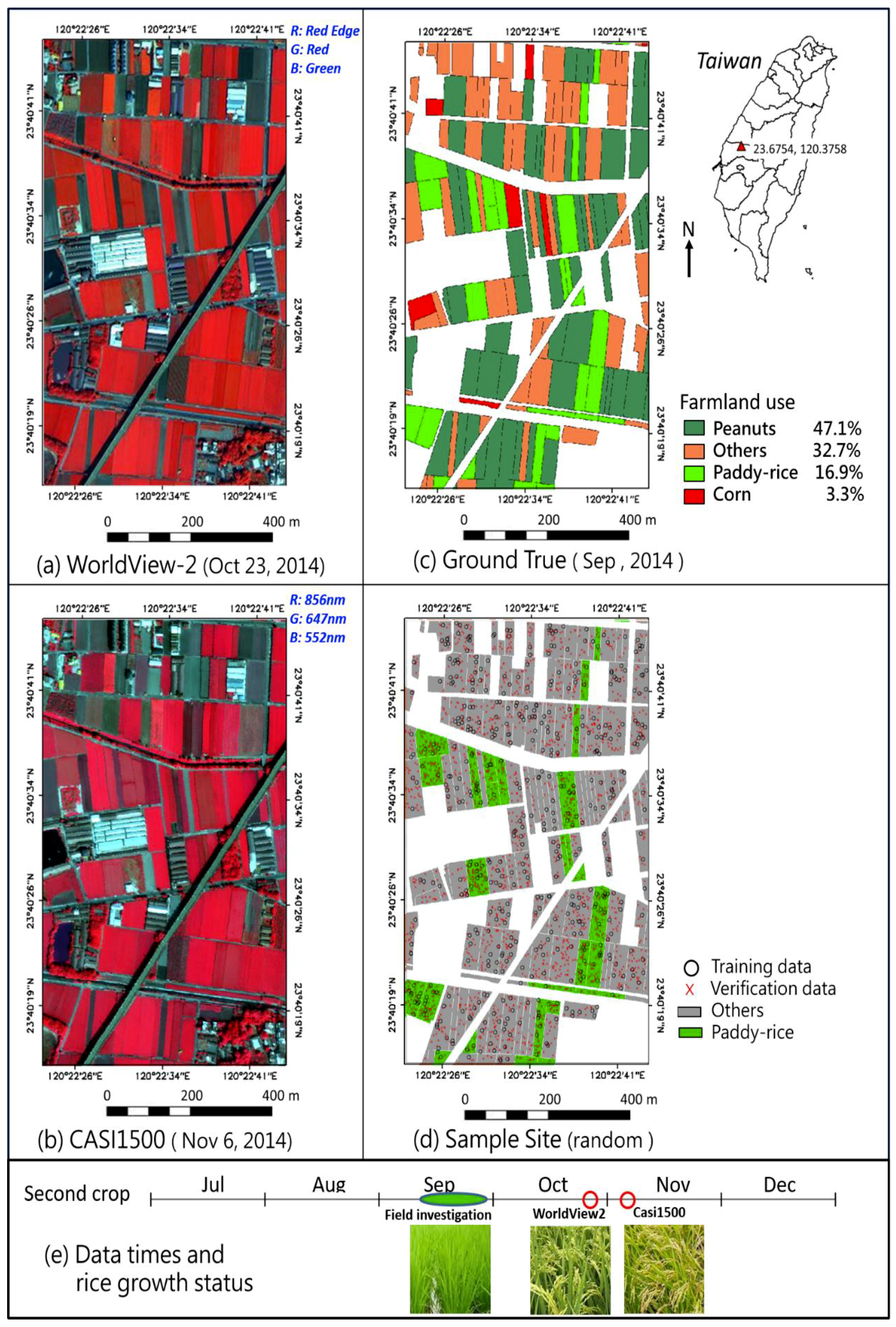
2.1. Study Area
2.2. Introduction on CASI-1500 and WorldView-2 Image Data
2.3. Selection of Training and Testing Samples
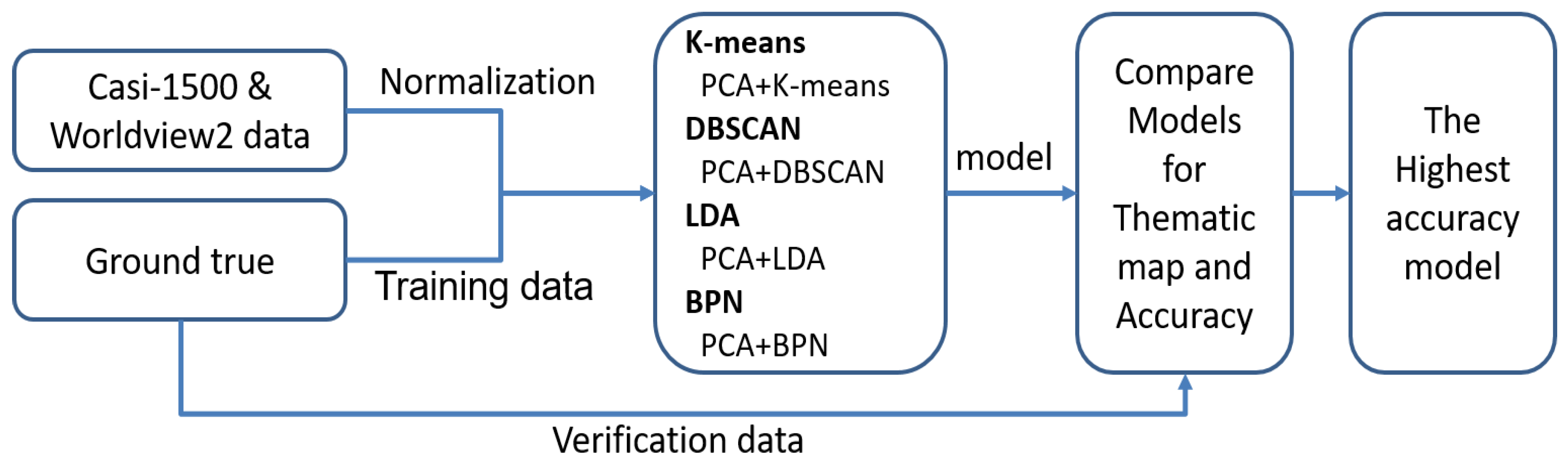
2.4. Classification Modeling for Experiments
2.4.1. K-Means
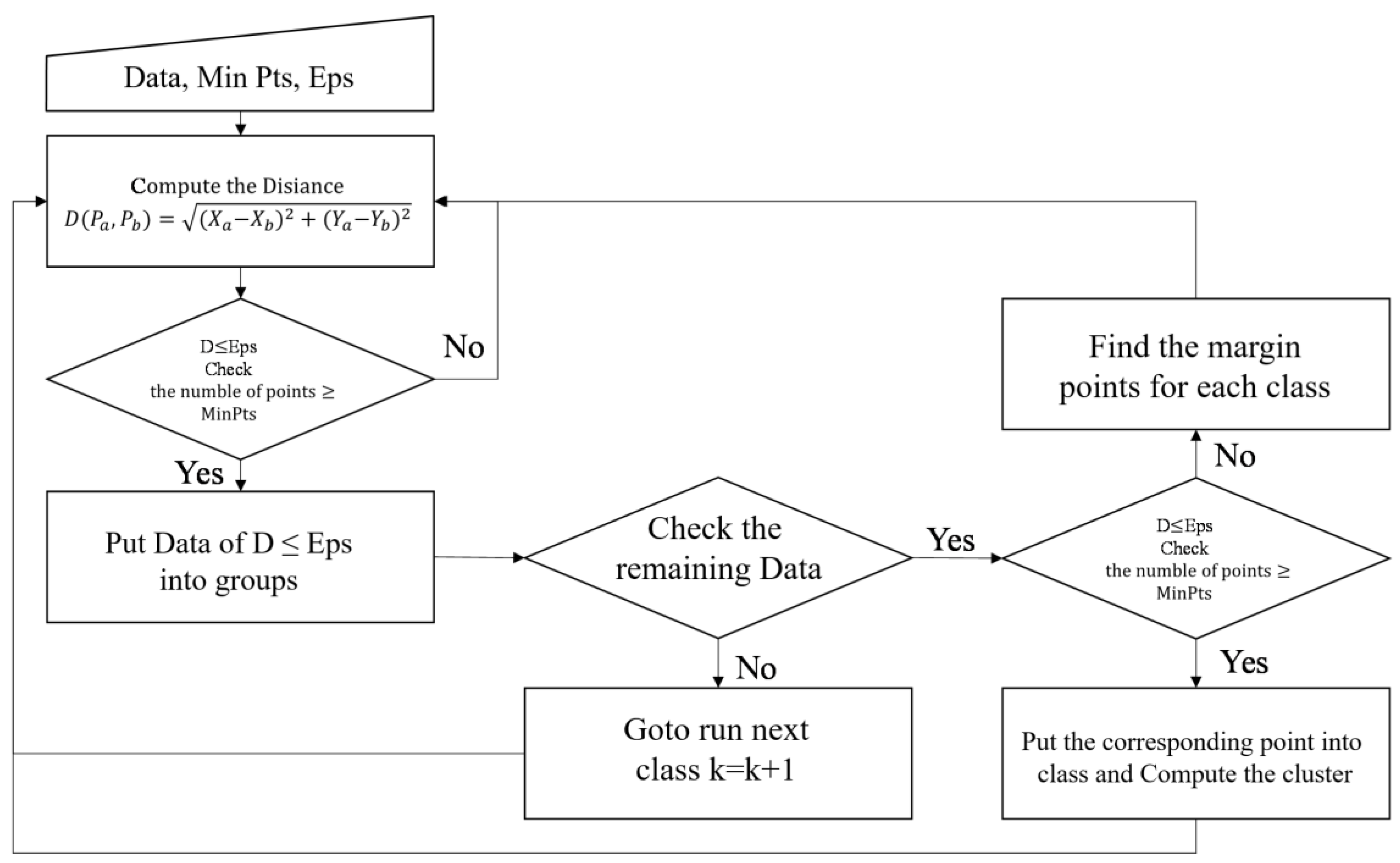
2.4.2. DBSCAN
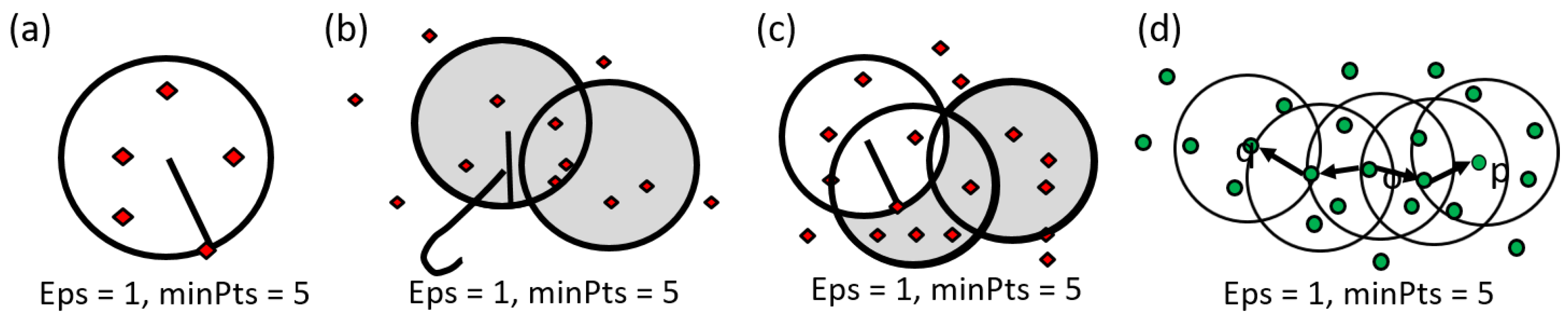
- Directly density reachable: each of the sample points is tested against the cluster-center with the associated radius. If this point falls in the range, the rest of the points will also be tested. This procedure is called directly density reachable which makes a cluster group of D. Please see Figure 2b. The developed program system will automatically count the number of sample data, which is either greater than the minimum data number given or not. This minimal data number given is named as MinPts. Please see Figure 2c. For instance, if the user defined it as MinPts = 5, the program will search the nearby data which fall in this range with the Eps = 1.
- Density reachable: in certain cases, for instance, the data points in a scatter diagram are a group but they are distributed linearly. The program will check each of the data with each of their neighboring points to see whether they falls in the minimal density or not. That is, a series of data may distribute as a rectangle shape and they are density reachable. Furthermore, these data could also be targets of clustering. Please see Figure 2d.
- Outlier analysis of DBSCAN: as mentioned before, if a sample point does not fall in any of the ranges defined by the user, it is called an outlier or noise data. Since the DBSCAN algorithm can detect noise data, our developed program can be robust to outliers. In essence, the outlier analysis data in image classification are very important. Since the majority of the data could be observed by the main target category, a salt and pepper effect could also be significantly affected by the minor data. The DBSCAN can remove them to a list table. Figure 3 show steps for DBSCAN.
2.4.3. LDA
2.4.4. BPN
2.5. Data Pre-Processing with Evaluation Model
3. Results and Discussion
3.1. Generation of Thematic Map
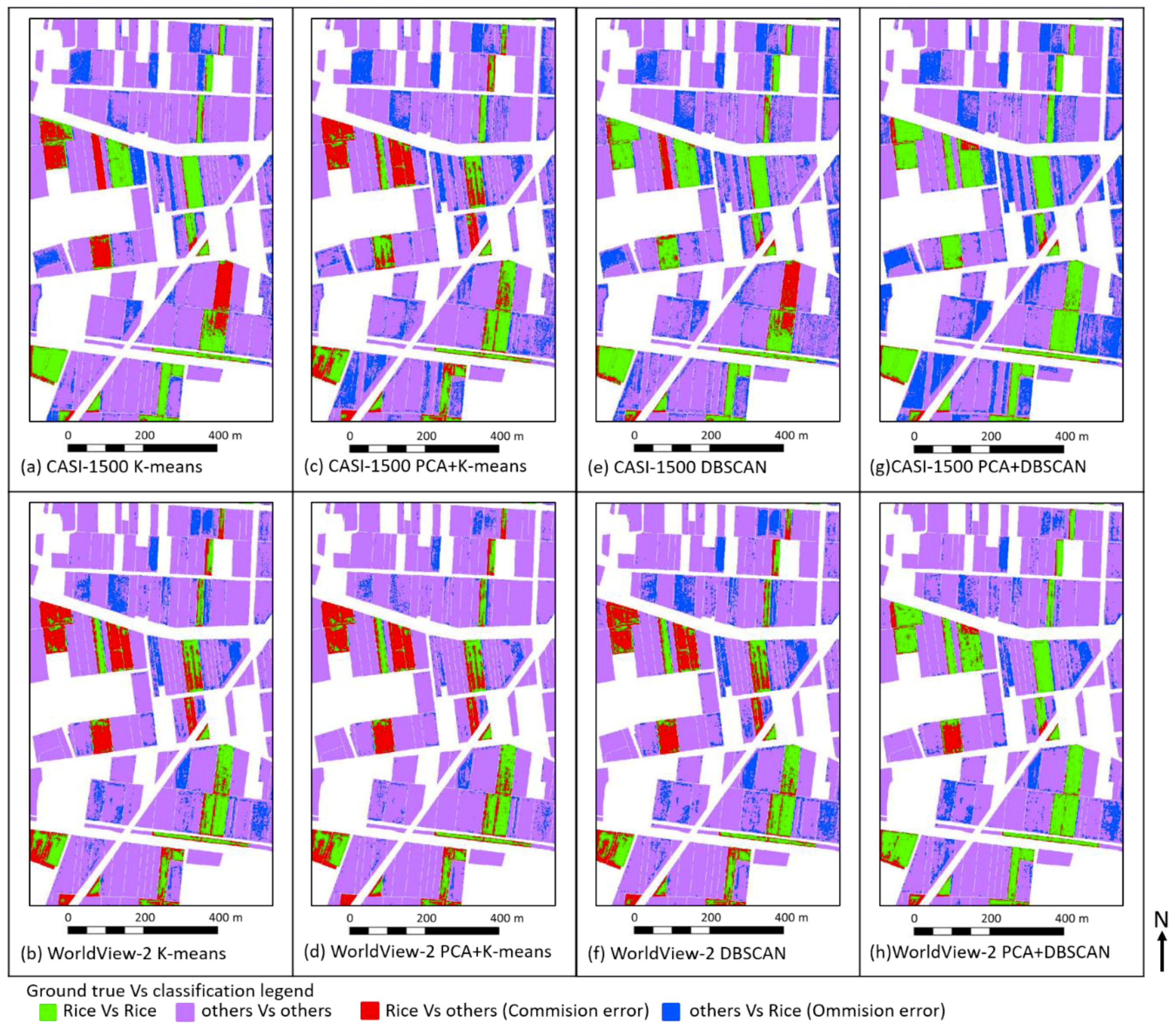
3.1.1. The Thematic Map Generated by K-Means
3.1.2. The Thematic Map Generated by DBSCAN
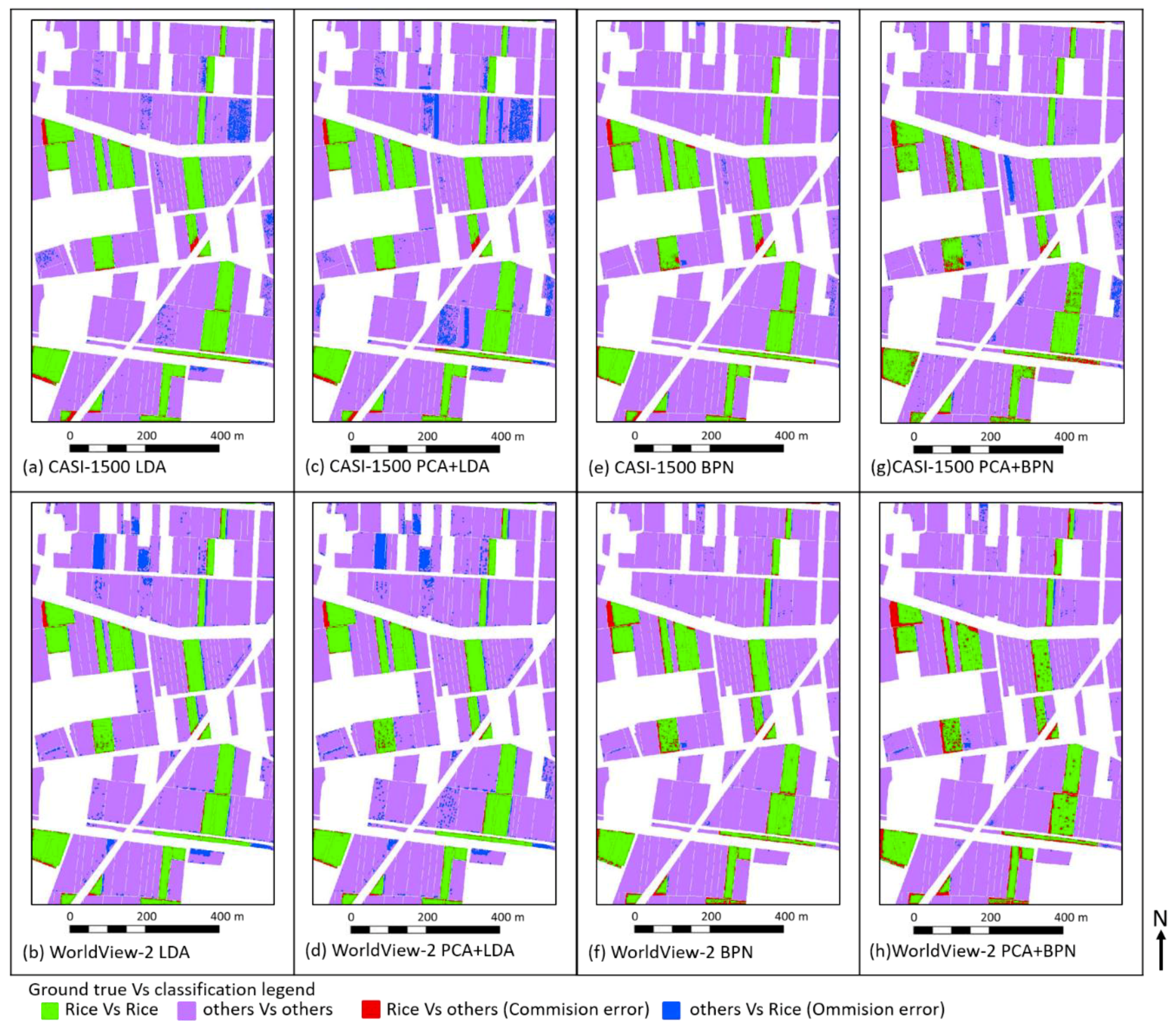
3.1.3. The Thematic Map Generated by LDA
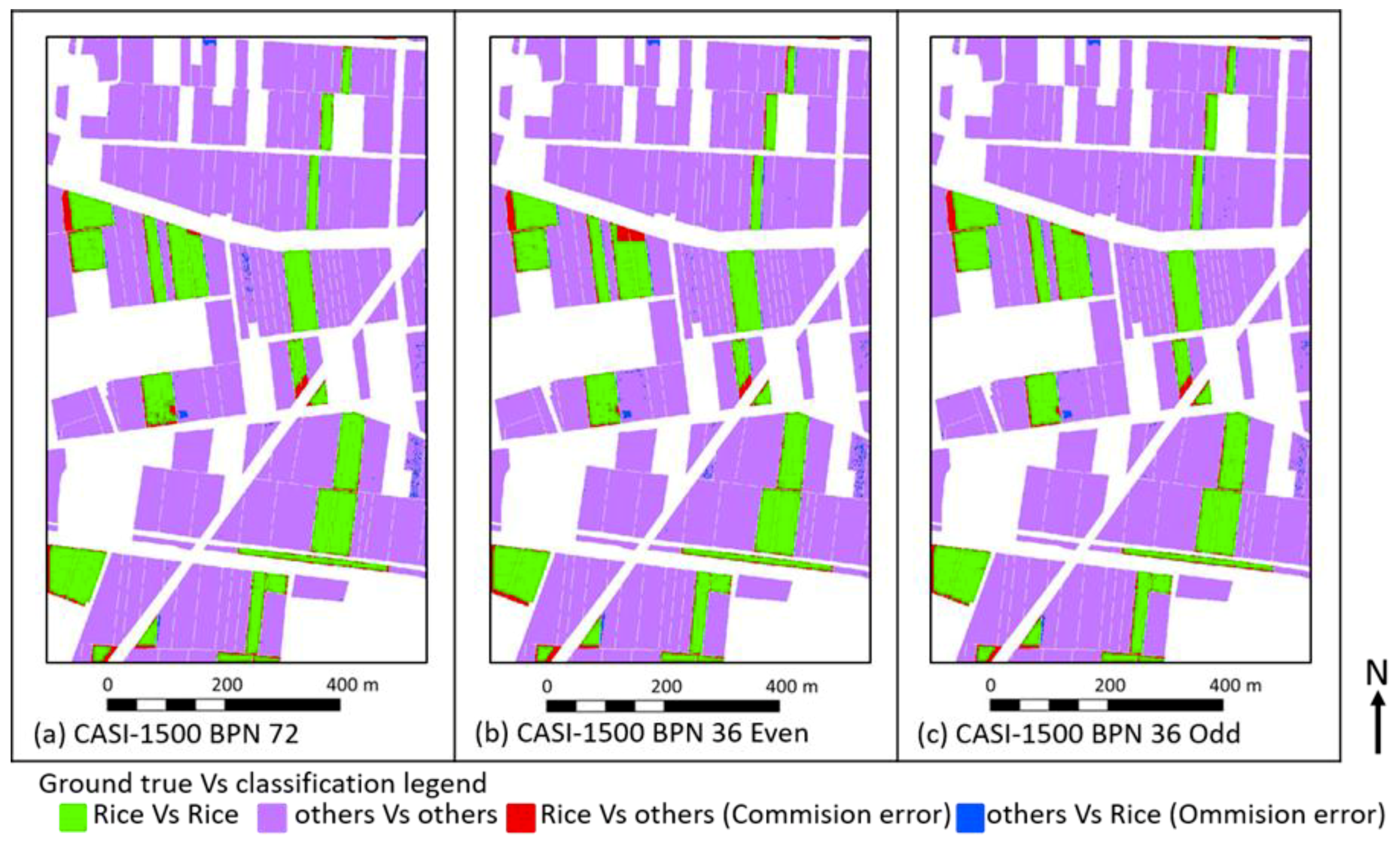
3.1.4. The Thematic Map Generated by BPN
3.2. The Error Matrix for Accuracy
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Y.P.; Chang, K.-W.; Chen, R.-K.; Lo, J.-C.; Shen, Y. Large-area rice yield forecasting using satellite imageries. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 27–35. [Google Scholar] [CrossRef]
- Wang, Y.P.; Shen, Y. Identifying and characterizing yield limiting soil factors with the aid of remote sensing and data mining techniques. Precis. Agric. 2015, 16, 99–118. [Google Scholar] [CrossRef]
- Wan, S. A spatial decision support system for extracting the core factors and thresholds for landslide susceptibility map. Eng. Geol. 2009, 108, 237–251. [Google Scholar] [CrossRef]
- Coca, F.C.-D.; García-Haro, F.J.; Gilabert, M.A.; Melia, J. Vegetation cover seasonal changes assessment from TM imagery in a semi-arid landscape. Int. J. Remote Sens. 2004, 25, 3451–3476. [Google Scholar] [CrossRef]
- Steele, B. Combining Multiple Classifiers: An Application Using Spatial and Remotely Sensed Information for Land Cover Type Mapping. Remote Sens. Environ. 2000, 74, 545–556. [Google Scholar] [CrossRef]
- Park, S.; Im, J.; Park, S.; Yoo, C.; Han, H.; Rhee, J. Classification and Mapping of Paddy Rice by Combining Landsat and SAR Time Series Data. Remote Sens. 2018, 10, 447. [Google Scholar] [CrossRef] [Green Version]
- Anys, H.; He, D.-C. Evaluation of textural and multipolarization radar features for crop classification. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1170–1181. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Breim, G.J.; Benediktsson, J.A.; Sveinsson, J.R. Multiple classifiers applied to multisource remote sensing data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2291–2299. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.K.; Arora, M.K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Wan, S.; Chang, S.-H. Combined particle swarm optimization and linear discriminant analysis for landslide image classification: Application to a case study in Taiwan. Environ. Earth Sci. 2014, 72, 1453–1464. [Google Scholar] [CrossRef]
- Carr, J.R. Spectral and textural classification of single and multiple band digital images. Comput. Geosci. 1996, 22, 849–865. [Google Scholar] [CrossRef]
- Carpenter, G.; Gjaja, M.; Gopal, S.; Woodcock, C. ART neural networks for remote sensing: Vegetation classification from Landsat TM and terrain data. IEEE Trans. Geosci. Remote Sens. 1997, 35, 308–325. [Google Scholar] [CrossRef] [Green Version]
- Benediktsson, J.A.; Swain, P.H.; Esroy, O.K. Neural network approaches versus statistical methods in classification of multisource remote sensing data. IEEE Trans. Geosci. Remote Sens. 1990, 28, 540–552. [Google Scholar] [CrossRef]
- Vinodhini, G.; Chandrasekaran, R.M. A comparative performance evaluation of neural network based approach for sentiment classification of online reviews. J. King Saud Univ. Comput. Inf. Sci. 2016, 28, 2–12. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Backer, S.D.; Scheunders, P. Genetic feature selection combined with composite fuzzy nearest neighbor classifiers for high-dimensional remote sensing data. In Proceedings of the IEEE International Conference on Systems, Man & Cybernetics, Nashville, TN, USA, 8–11 October 2000; pp. 1912–1916. [Google Scholar]
- Cheriyadat, A.; Bruce, L.M. Why principal component analysis is not an appropriate feature extraction method for hyperspectral data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; pp. 3420–3422. [Google Scholar]
- Bárdossy, A.; Samaniego, L. Fuzzy rule-based classification of remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2002, 40, 362–374. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Batistella, M.; Morán, E. Land-cover binary change detection methods for use in the moist tropical region of the Amazon: A comparative study. Int. J. Remote Sens. 2005, 26, 101–114. [Google Scholar] [CrossRef]
- Collin, A.; Lambert, N.; Etienne, S. Satellite-based salt marsh elevation, vegetation height, and species composition mapping using the superspectral WorldView-3 imagery. Int. J. Remote Sens. 2018, 39, 5619–5637. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Sagan, V.; Maimaitijiang, M.; Carron, J. Urban Tree Species Classification Using a WorldView-2/3 and LiDAR Data Fusion Approach and Deep Learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Lei, T.; Huang, P.; Chou, T. The knowledge rules of debris flow event: A case study for investigation Chen Yu Lan River, Taiwan. Eng. Geol. 2008, 98, 102–114. [Google Scholar] [CrossRef]
- Senthilnath, J.; Omkar, S.N.; Mani, V.; Karnwal, N.; Shreyas, P.B. Crop Stage Classification of Hyperspectral Data Using Unsupervised Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 6, 861–866. [Google Scholar] [CrossRef]
- Massarelli, C.; Matarrese, R.; Uricchio, V.F.; Muolo, M.R.; Laterza, M.; Ernesto, L. Detection of asbestos-containing materials in agro-ecosystem by the use of airborne hyperspectral CASI-1500 sensor including the limited use of two UAVs equipped with RGB cameras. Int. J. Remote Sens. 2017, 38, 2135–2149. [Google Scholar] [CrossRef]
- Bertels, L.; Vanderstraete, T.; Van Coillie, S.; Knaeps, E.; Sterckx, S.; Goossens, R.; Deronde, B. Mapping of coral reefs using hyperspectral CASI data; a case study: Fordata, Tanimbar, Indonesia. Int. J. Remote Sens. 2008, 29, 2359–2391. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Vellido, A.; Lisboa, P.J.G.; Vaughan, J. Neural Networks in Business: A Survey of Applications (1992–1998). Expert Syst. Appl. 1999, 17, 51–70. [Google Scholar] [CrossRef]
- Gupta, J.N.; Stafford, E.F. Flowshop scheduling research after five decades. Eur. J. Oper. Res. 2006, 169, 699–711. [Google Scholar] [CrossRef]
- Peres-Neto, P.R.; Jackson, D.A.; Somers, K.M. How many principal components? Stopping rules for determining the number of non-trivial axes revisited. Comput. Stat. Data Anal. 2005, 49, 974–997. [Google Scholar] [CrossRef]
- Sander, J.; Ester, M.; Kriegel, H.-P.; Xu, X. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and Its Applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods for classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Kriegel, H.; Kröger, P.; Sander, J.; Zimek, A. Density-based clustering. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 231–240. [Google Scholar] [CrossRef]
- Tran, T.N.; Drab, K.; Daszykowski, M. Revised DBSCAN algorithm to cluster data with dense adjacent clusters. Chemom. Intell. Lab. Syst. 2013, 120, 92–96. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, B.; Wan, L.; Yang, M.; Xing, D. Restricted Airspace Unit Identification Using Density-Based Spatial Clustering of Applications with Noise. Sustainability 2019, 11, 5962. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Multispectral (WorldView-2) | Hyperspectral (CASI-1500) | ||||||
|---|---|---|---|---|---|---|---|
| Bands | Centre (nm) | FWHM (nm) | Paddy Rice Cluster Center | Band | Centre (nm) | FWHM (nm) | Paddy Rice Cluster Center |
| Coastal | 425 | 25 | −0.7668 | 1 | 370.7 | 4.8 | −0.2697 |
| Blue | 480 | 30 | −0.7729 | 2 | 380.2 | 4.8 | −0.4077 |
| Green | 545 | 35 | −0.4959 | 3 | 389.8 | 4.8 | −0.4064 |
| Yellow | 605 | 20 | −0.6557 | 4 | 399.3 | 4.8 | −0.5165 |
| Red | 660 | 30 | −0.8055 | 5 | 408.9 | 4.8 | −0.6197 |
| Red Edge | 725 | 20 | 0.3295 | ||||
| NIR1 | 832.5 | 62.5 | 0.4875 | 68 | 1008.3 | 4.8 | 0.3325 |
| NIR2 | 950 | 90 | 0.4907 | 69 | 1017.8 | 4.8 | 0.3204 |
| 70 | 1027.3 | 4.8 | 0.3045 | ||||
| 71 | 1036.8 | 4.8 | 0.3730 | ||||
| 72 | 1046.3 | 4.8 | 0.3423 | ||||
| 2000 Samples Verification Accuracy | Full-Frame Image Verification Accuracy | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Image Type | Study Way | Kappa | Mean | OA * (%) | Mean | Kappa | Mean | OA (%) | Mean |
| Casi-1500 | K-means | 0.64 | 0.50 | 86.70 | 80.38 | 0.47 | 0.41 | 84.26 | 83.21 |
| WorldView2 | K-means | 0.35 | 74.05 | 0.35 | 82.16 | ||||
| Casi-1500 | PCA + K-means | 0.45 | 0.46 | 78.55 | 79.68 | 0.44 | 0.39 | 80.79 | 80.95 |
| WorldView2 | PCA + K-means | 0.47 | 80.80 | 0.34 | 81.11 | ||||
| Casi-1500 | DBSCAN | 0.74 | 0.64 | 89.30 | 86.38 | 0.60 | 0.63 | 86.48 | 88.09 |
| WorldView2 | DBSCAN | 0.55 | 83.45 | 0.65 | 89.70 | ||||
| Casi-1500 | PCA + DBSCAN | 0.83 | 0.77 | 92.70 | 90.15 | 0.57 | 0.56 | 85.04 | 86.97 |
| WorldView2 | PCA + DBSCAN | 0.71 | 87.60 | 0.56 | 88.91 | ||||
| Casi-1500 | LDA | 0.93 | 0.93 | 97.10 | 96.90 | 0.85 | 0.84 | 95.72 | 95.34 |
| WorldView2 | LDA | 0.92 | 96.70 | 0.83 | 94.96 | ||||
| Casi-1500 | PCA + LDA | 0.93 | 0.92 | 97.10 | 96.63 | 0.79 | 0.80 | 93.59 | 93.81 |
| WorldView2 | PCA + LDA | 0.91 | 96.15 | 0.80 | 94.03 | ||||
| Casi-1500 | BPN | 0.98 | 0.97 | 99.35 | 98.63 | 0.90 | 0.89 | 97.28 | 96.96 |
| WorldView2 | BPN | 0.95 | 97.90 | 0.88 | 96.64 | ||||
| Casi-1500 | PCA + BPN | 0.91 | 0.89 | 96.15 | 95.53 | 0.82 | 0.82 | 95.21 | 95.11 |
| WorldView2 | PCA + BPN | 0.87 | 94.90 | 0.81 | 95.02 | ||||
| Casi-1500 | BPN72 | 0.98 | 0.98 | 99.35 | 99.3 | 0.90 | 0.90 | 97.28 | 97.25 |
| Casi-1500 | BPN 36 odd | 0.99 | 99.55 | 0.90 | 97.37 | ||||
| Casi-1500 | BPN 36 even | 0.98 | 99.00 | 0.89 | 97.11 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, S.; Wang, Y.-P. The Comparison of Density-Based Clustering Approach among Different Machine Learning Models on Paddy Rice Image Classification of Multispectral and Hyperspectral Image Data. Agriculture 2020, 10, 465. https://doi.org/10.3390/agriculture10100465
Wan S, Wang Y-P. The Comparison of Density-Based Clustering Approach among Different Machine Learning Models on Paddy Rice Image Classification of Multispectral and Hyperspectral Image Data. Agriculture. 2020; 10(10):465. https://doi.org/10.3390/agriculture10100465
Chicago/Turabian StyleWan, Shiuan, and Yi-Ping Wang. 2020. "The Comparison of Density-Based Clustering Approach among Different Machine Learning Models on Paddy Rice Image Classification of Multispectral and Hyperspectral Image Data" Agriculture 10, no. 10: 465. https://doi.org/10.3390/agriculture10100465