
Accuracy of Machine Learning Assisted Detection of Keratoconus: A Systematic Review and Meta-Analysis


Abstract
:1. Introduction
2. Materials and Methods
2.1. Literature Search Strategy
- -
- Full text original papers that evaluated machine learning algorithms in the diagnosis of KC;
- -
- No limit on the year of publication was applied;
- -
- Publications only in the English language were included;
- -
- Publications in which KC was the only corneal condition evaluated.
- -
- Criteria for exclusion:
- -
- Publications evaluating other corneal diseases without focusing only on KC;
- -
- Publications evaluating the efficacy of machine learning in treating KC (treatments);
- -
- Review papers;
- -
- Publications in which no machine learning algorithms were included, but only statistical research was undertaken;
- -
- Non-English publications.
2.2. Data Extraction
2.3. Reporting Completeness of Machine Learning Studies in KC
2.4. Statistical Methods
2.5. Outcomes Measure
3. Results
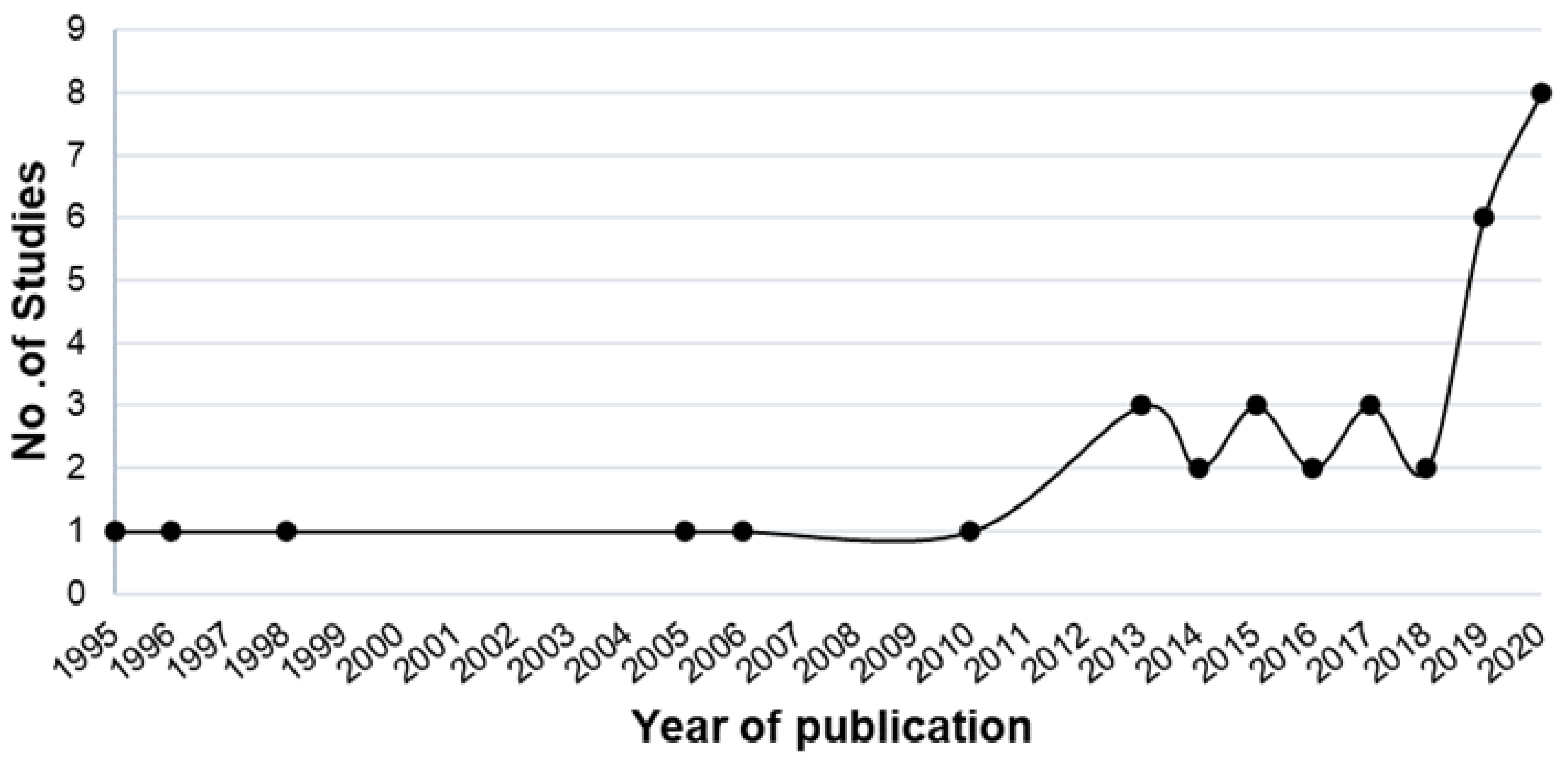
3.1. Search Collection
3.2. Search Characteristics
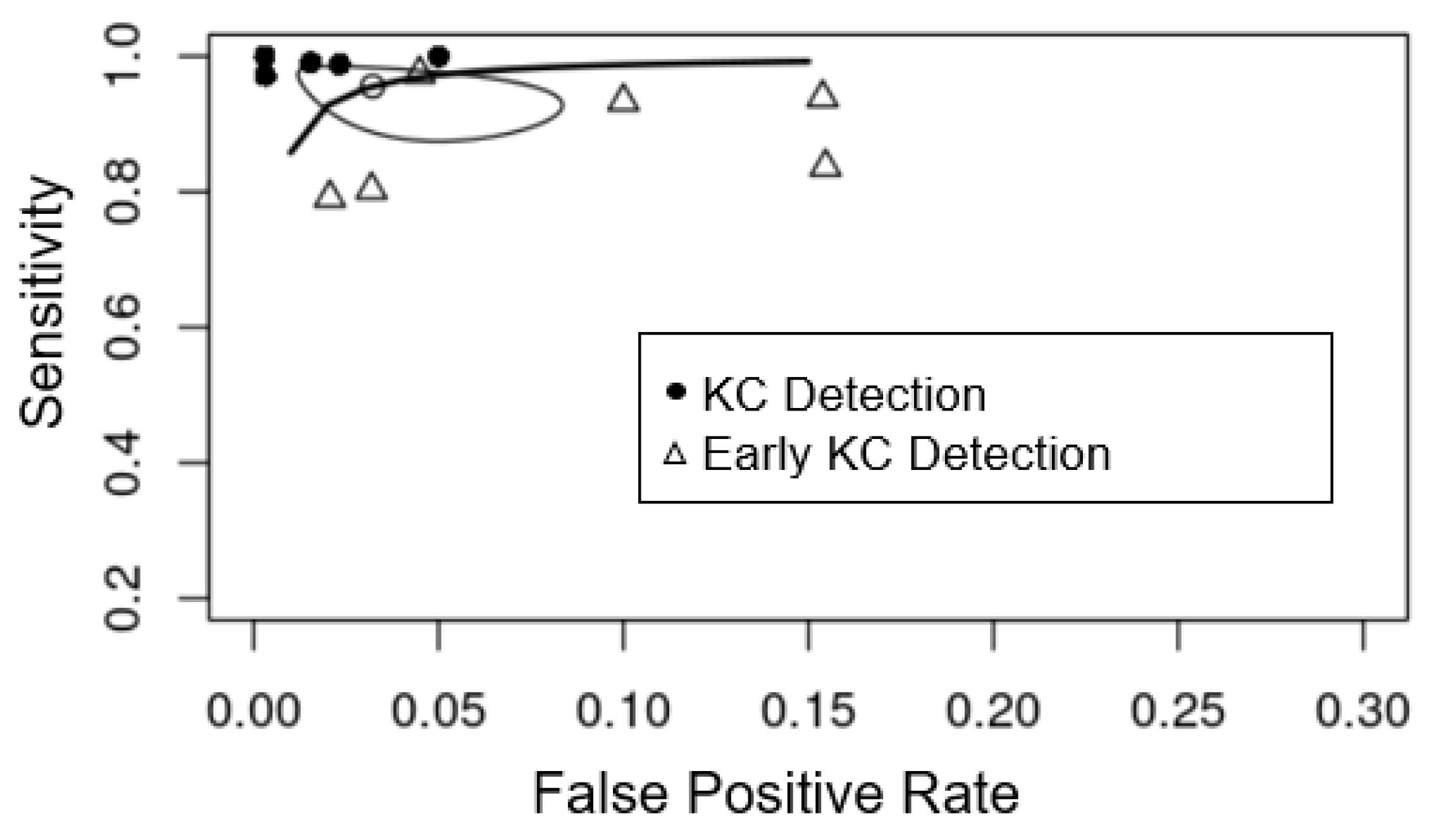
3.3. Detecting KC from Controls and Meta-Analysis
3.4. Detecting Early KC from Controls and Meta-Analysis
3.5. Detection of Different KC Severities
3.6. Reporting Completeness of Machine Learning Studies in KC
4. Discussion
4.1. Reporting Completeness of Machine Learning Studies in KC
4.2. Limitations in the Current Literature
4.3. Approach for Future Studies
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Whitcher, J.P.; Srinivasan, M.; Upadhyay, M.P. Corneal blindness: A global perspective. Bull. World Health Organ. 2001, 79, 214–221. [Google Scholar] [PubMed]
- Sharif, R.; Bak-Nielsen, S.; Hjortdal, J.; Karamichos, D. Pathogenesis of Keratoconus: The intriguing therapeutic potential of Prolactin-inducible protein. Prog. Retin. Eye Res. 2018, 67, 150–167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buzzonetti, L.; Bohringer, D.; Liskova, P.; Lang, S.; Valente, P. Keratoconus in Children: A Literature Review. Cornea 2020, 39, 1592–1598. [Google Scholar] [CrossRef] [PubMed]
- Röck, T.; Bartz-Schmidt, K.U.; Röck, D. Trends in corneal transplantation at the University Eye Hospital in Tübingen, Germany over the last 12 years: 2004–2015. PLoS ONE 2018, 13, e0198793. [Google Scholar] [CrossRef] [Green Version]
- Kelly, T.L.; Williams, K.A.; Coster, D.J.; Australian Corneal Graft Registry. Corneal transplantation for keratoconus: A registry study. Arch. Ophthalmol. 2011, 129, 691–697. [Google Scholar] [CrossRef]
- Andreu-Perez, J.; Poon, C.C.; Merrifield, R.D.; Wong, S.T.; Yang, G.Z. Big data for health. IEEE J. Biomed. Health Inform. 2015, 19, 1193–1208. [Google Scholar] [CrossRef]
- Verspoor, K.; Martin-Sanchez, F. Big Data in Medicine is Driving Big Changes. Yearb. Med. Inform. 2014, 23, 14–20. [Google Scholar] [CrossRef] [Green Version]
- Mintz, Y.; Brodie, R. Introduction to artificial intelligence in medicine. Minim. Invasive Ther. Allied Technol. 2019, 28, 73–81. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine learning in medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Ramamurthy, S.; Reddy, J.; Jhanji, V. Topography and tomography in the diagnosis of corneal ectasia. Expert Rev. Ophthalmol. 2015, 10, 215–228. [Google Scholar] [CrossRef]
- Motlagh, M.N.; Moshirfar, M.; Murri, M.S.; Skanchy, D.F.; Momeni-Moghaddam, H.; Ronquillo, Y.C.; Hoopes, P.C. Pentacam® Corneal Tomography for Screening of Refractive Surgery Candidates: A Review of the Literature, Part I. Med. Hypothesis Discov. Innov. Ophthalmol. 2019, 8, 177–203. [Google Scholar] [PubMed]
- Maeda, N.; Klyce, S.D.; Smolek, M.K. Comparison of Methods for Detecting Keratoconus Using Videokeratography. Arch. Ophthalmol. 1995, 113, 870–874. [Google Scholar] [CrossRef] [PubMed]
- Reitsma, J.B.; Glas, A.S.; Rutjes, A.W.S.; Scholten, R.J.; Bossuyt, P.M.; Zwinderman, A.H. Bivariate analysis of sensitivity and specificity produces informative summary measures in diagnostic reviews. J. Clin. Epidemiol. 2005, 58, 982–990. [Google Scholar] [CrossRef]
- van Enst, W.A.; Ochodo, E.; Scholten, R.J.; Hooft, L.; Leeflang, M.M. Investigation of publication bias in meta-analyses of diagnostic test accuracy: A meta-epidemiological study. BMC Med. Res. Methodol. 2014, 14, 70. [Google Scholar] [CrossRef] [Green Version]
- Deeks, J.J.; Macaskill, P.; Irwig, L. The performance of tests of publication bias and other sample size effects in systematic reviews of diagnostic test accuracy was assessed. J. Clin. Epidemiol. 2005, 58, 882–893. [Google Scholar] [CrossRef] [PubMed]
- Kalin, N.S.; Maeda, N.; Klyce, S.D.; Hargrave, S.; Wilson, S.E. Automated topographic screening for keratoconus in refractive surgery candidates. CLAO J. Off. Publ. Contact Lens Assoc. Ophthalmol. Inc. 1996, 22, 164–167. [Google Scholar]
- Rabinowitz, Y.S.; Rasheed, K.; Yang, H.; Elashoff, J. Accuracy of ultrasonic pachymetry and videokeratography in detecting keratoconus. J. Cataract. Refract. Surg. 1998, 24, 196–201. [Google Scholar] [CrossRef]
- Twa, M.D.; Parthasarathy, S.; Roberts, C.; Mahmoud, A.M.; Raasch, T.W.; Bullimore, M.A. Automated decision tree classification of corneal shape. Optom. Vis. Sci. Off. Publ. Am. Acad. Optom. 2005, 82, 1038–1046. [Google Scholar] [CrossRef] [Green Version]
- Bessho, K.; Maeda, N.; Kuroda, T.; Fujikado, T.; Tano, Y.; Oshika, T. Automated keratoconus defection using height data of anterior and posterior corneal surfaces. Jpn. J. Ophthalmol. 2006, 50, 409–416. [Google Scholar] [CrossRef] [PubMed]
- Saad, A.; Gatinel, D. Topographic and Tomographic Properties of Forme Fruste Keratoconus Corneas. Investig. Opthalmol. Vis. Sci. 2010, 51, 5546–5555. [Google Scholar] [CrossRef]
- Smadja, D.; Touboul, D.; Cohen, A.; Doveh, E.; Santhiago, M.R.; Mello, G.R.; Krueger, R.R.; Colin, J. Detection of Subclinical Keratoconus Using an Automated Decision Tree Classification. Am. J. Ophthalmol. 2013, 156, 237–246.e1. [Google Scholar] [CrossRef]
- Mahmoud, A.M.; Nuñez, M.X.; Blanco, C.; Koch, D.D.; Wang, L.; Weikert, M.; Frueh, B.E.; Tappeiner, C.; Twa, M.; Roberts, C.J. Expanding the Cone Location and Magnitude Index to Include Corneal Thickness and Posterior Surface Information for the Detection of Keratoconus. Am. J. Ophthalmol. 2013, 156, 1102–1111. [Google Scholar] [CrossRef]
- Saad, A.; Guilbert, E.; Gatinel, D. Corneal Enantiomorphism in Normal and Keratoconic Eyes. J. Refract. Surg. 2014, 30, 542–547. [Google Scholar] [CrossRef] [Green Version]
- Silverman, R.H.; Urs, R.; RoyChoudhury, A.; Archer, T.J.; Gobbe, M.; Reinstein, D.Z. Epithelial Remodeling as Basis for Machine-Based Identification of Keratoconus. Investig. Opthalmol. Vis. Sci. 2014, 55, 1580–1587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koprowski, R.; Ambrosio, R. Quantitative assessment of corneal vibrations during intraocular pressure measurement with the air-puff method in patients with keratocdnus. Comput. Biol. Med. 2015, 66, 170–178. [Google Scholar] [CrossRef]
- Shetty, R.; Matalia, H.; Srivatsa, P.; Ghosh, A.; Dupps, W.; Roy, A.S. A Novel Zernike Application to Differentiate between Three-dimensional Corneal Thickness of Normal Corneas and Corneas with Keratoconus. Am. J. Ophthalmol. 2015, 160, 453–462.e2. [Google Scholar] [CrossRef]
- Kovács, I.; Miháltz, K.; Kránitz, K.; Juhász, É.; Takács, Á.; Dienes, L.; Gergely, R.; Nagy, Z.Z. Accuracy of machine learning classifiers using bilateral data from a Scheimpflug camera for identifying eyes with preclinical signs of keratoconus. J. Cataract. Refract. Surg. 2016, 42, 275–283. [Google Scholar] [CrossRef]
- Hidalgo, I.R.; Rodriguez, P.; Rozema, J.J.; Dhubhghaill, S.N.; Zakaria, N.; Tassignon, M.J.; Koppen, C. Evaluation of a Machine-Learning Classifier for Keratoconus Detection Based on Scheimpflug Tomography. Cornea 2016, 35, 827–832. [Google Scholar] [CrossRef]
- Ambrósio, R.; Lopes, B.T.; Faria-Correia, F.; Salomão, M.Q.; Bühren, J.; Roberts, C.J.; Elsheikh, A.; Vinciguerra, R.; Vinciguerra, P. Integration of Scheimpflug-Based Corneal Tomography and Biomechanical Assessments for Enhancing Ectasia Detection. J. Refract. Surg. 2017, 33, 434–443. [Google Scholar] [CrossRef] [Green Version]
- Silverman, R.H.; Urs, R.; Roychoudhury, A.; Archer, T.J.; Gobbe, M.; Reinstein, D.Z. Combined tomography and epithelial thickness mapping for diagnosis of keratoconus. Eur. J. Ophthalmol. 2017, 27, 129–134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopes, B.T.; Ramos, I.C.; Salomão, M.Q.; Guerra, F.P.; Schallhorn, S.C.; Schallhorn, J.M.; Vinciguerra, R.; Vinciguerra, P.; Price, F.W., Jr.; Price, M.O.; et al. Enhanced Tomographic Assessment to Detect Corneal Ectasia Based on Artificial Intelligence. Am. J. Ophthalmol. 2018, 195, 223–232. [Google Scholar] [CrossRef]
- Chandapura, R.; Salomao, M.Q.; Ambrosio, R.; Swarup, R.; Shetty, R.; Roy, A.S. Bowman’s topography for improved detection of early ectasia. J. Biophotonics 2019, 12, e201900126. [Google Scholar] [CrossRef] [PubMed]
- Issarti, I.; Consejo, A.; Jiménez-García, M.; Hershko, S.; Koppen, C.; Rozema, J. Computer aided diagnosis for suspect keratoconus detection. Comput. Biol. Med. 2019, 109, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Leão, E.; Ren, T.I.; Lyra, J.M.; Machado, A.; Koprowski, R.; Lopes, B.; Vinciguerra, R.; Vinciguerra, P.; Roberts, C.J.; Elsheikh, A.; et al. Corneal deformation amplitude analysis for keratoconus detection through compensation for intraocular pressure and integration with horizontal thickness profile. Comput. Biol. Med. 2019, 109, 263–271. [Google Scholar] [CrossRef] [PubMed]
- Bolarín, J.M.; Cavas, F.; Velázquez, J.; Alió, J. A Machine-Learning Model Based on Morphogeometric Parameters for RETICS Disease Classification and GUI Development. Appl. Sci. 2020, 10, 1874. [Google Scholar] [CrossRef] [Green Version]
- Castro-Luna, G.M.; Martínez-Finkelshtein, A.; Ramos-López, D. Robust keratoconus detection with Bayesian network classifier for Placido-based corneal indices. Contact Lens Anterior Eye 2020, 43, 366–372. [Google Scholar] [CrossRef]
- Issarti, I.; Consejo, A.; Jiménez-García, M.; Kreps, E.O.; Koppen, C.; Rozema, J.J. Logistic index for keratoconus detection and severity scoring (Logik). Comput. Biol. Med. 2020, 122, 103809. [Google Scholar] [CrossRef] [PubMed]
- Lavric, A.; Popa, V.; Takahashi, H.; Yousefi, S. Detecting Keratoconus from Corneal Imaging Data Using Machine Learning. IEEE Access 2020, 8, 149113–149121. [Google Scholar] [CrossRef]
- Shi, C.; Wang, M.; Zhu, T.; Zhang, Y.; Ye, Y.; Jiang, J.; Chen, S.; Lu, F.; Shen, M. Machine learning helps improve diagnostic ability of subclinical keratoconus using Scheimpflug and OCT imaging modalities. Eye Vis. 2020, 7, 48. [Google Scholar] [CrossRef]
- Velázquez-Blázquez, J.S.; Bolarín, J.M.; Cavas-Martínez, F.; Alió, J.L. EMKLAS: A New Automatic Scoring System for Early and Mild Keratoconus Detection. Transl. Vis. Sci. Technol. 2020, 9, 30. [Google Scholar] [CrossRef]
- Dos Santos, V.A.; Schmetterer, L.; Stegmann, H.; Pfister, M.; Messner, A.; Schmidinger, G.; Garhofer, G.; Werkmeister, R.M. CorneaNet: Fast segmentation of cornea OCT scans of healthy and keratoconic eyes using deep learning. Biomed. Opt. Express 2019, 10, 622–641. [Google Scholar] [CrossRef]
- Kamiya, K.; Ayatsuka, Y.; Kato, Y.; Fujimura, F.; Takahashi, M.; Shoji, N.; Mori, Y.; Miyata, K. Keratoconus detection using deep learning of colour-coded maps with anterior segment optical coherence tomography: A diagnostic accuracy study. BMJ Open 2019, 9, e031313. [Google Scholar] [CrossRef] [Green Version]
- Lavric, A.; Valentin, P. KeratoDetect: Keratoconus Detection Algorithm Using Convolutional Neural Networks. Comput. Intell. Neurosci. 2019, 2019, 8162567. [Google Scholar] [CrossRef] [Green Version]
- Kuo, B.-I.; Chang, W.-Y.; Liao, T.-S.; Liu, F.-Y.; Liu, H.-Y.; Chu, H.-S.; Chen, W.-L.; Hu, F.-R.; Yen, J.-Y.; Wang, I.-J. Keratoconus Screening Based on Deep Learning Approach of Corneal Topography. Transl. Vis. Sci. Technol. 2020, 9, 53. [Google Scholar] [CrossRef] [PubMed]
- Ventura, B.V.; Machado, A.P.; Ambrósio, R.; Ribeiro, G.; Araújo, L.N.; Luz, A.; Lyra, J.M. Analysis of Waveform-Derived ORA Parameters in Early Forms of Keratoconus and Normal Corneas. J. Refract. Surg. 2013, 29, 637–643. [Google Scholar] [CrossRef]
- Chan, C.; Ang, M.; Saad, A.; Chua, D.; Mejia, M.; Lim, L.; Gatinel, D. Validation of an Objective Scoring System for Forme Fruste Keratoconus Detection and Post-LASIK Ectasia Risk Assessment in Asian Eyes. Cornea 2015, 34, 996–1004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Z.; Li, W.; Jiang, J.; Zhuang, X.; Chen, W.; Peng, M.; Wang, J.; Lu, F.; Shen, M.; Wang, Y. Characteristic of entire corneal topography and tomography for the detection of sub-clinical keratoconus with Zernike polynomials using Pentacam. Sci. Rep. 2017, 7, 16486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, K.; Verspoor, K.; Sahebjada, S.; Baird, P.N. Evaluating the Performance of Various Machine Learning Algorithms to Detect Subclinical Keratoconus. Transl. Vis. Sci. Technol. 2020, 9, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yousefi, S.; Yousefi, E.; Takahashi, H.; Hayashi, T.; Tampo, H.; Inoda, S.; Arai, Y.; Asbell, P. Keratoconus severity identification using unsupervised machine learning. PLoS ONE 2018, 13, e0205998. [Google Scholar] [CrossRef]
- Henriquez, M.A.; Hadid, M.; Izquierdo, L., Jr. A systematic review of subclinical keratoconus and forme fruste keratoconus. J. Refract. Surg. 2020, 36, 270–279. [Google Scholar] [CrossRef]
- Alio, J.L.; Vega-Estrada, A.; Sanz-Diez, P.; Peña-García, P.; Durán-García, M.L.; Maldonado, M. Keratoconus management guidelines. Int. J. Keratoconus Ectatic Corneal Dis. 2015, 4, 1–39. [Google Scholar]
- Gomes, J.A.; Tan, D.; Rapuano, C.J.; Belin, M.W.; Ambrósio, R., Jr.; Guell, J.L.; Malecaze, F.; Nishida, K.; Sangwan, V.S. Global consensus on keratoconus and ectatic diseases. Corneal 2015, 34, 359–369. [Google Scholar] [CrossRef]
- Pentacam User Guide. System for Measuring and Analysing the Front Part of the Eye. User Guide Pentacam®/Pentacam®HR/Pentacam®AXL. Available online: https://www.pentacam.com/fileadmin/user_upload/pentacam.de/downloads/interpretations-leitfaden/interpretation_guideline_3rd_edition_0915.pdf2018 (accessed on 8 June 2021).
- Chen, D.; Lam, A.K. Reliability and repeatability of the Pentacam on corneal curvatures. Clin. Exp. Optom. 2009, 92, 110–118. [Google Scholar] [CrossRef]
- Michael, W.; Belin, M. Point/Counterpoint: The Pentacam Versus the Orbscan. 2006. Available online: https://crstoday.com/ (accessed on 8 June 2021).
- Shanthi, S.; Aruljyothi, L.; Balasundaram, M.B.; Janakiraman, A.; Nirmala, D.K.; Pyingkodi, M. Artificial intelligence applications in different imaging modalities for corneal topography. Surv. Ophthalmol. 2021. [Google Scholar] [CrossRef]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.J.; Dahly, D.L.; Damen, J.A.; Debray, T.P.A.; et al. Prediction models for diagnosis and prognosis of covid-19 infection: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef] [Green Version]
- Venkateswaran, N.; Galor, A.; Wang, J.; Karp, C.L. Optical coherence tomography for ocular surface and corneal diseases: A review. Eye Vis. 2018, 5, 13. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning; Department of Computer Science University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]
- Bogunović, H.; Montuoro, A.; Baratsits, M.; Karantonis, M.G.; Waldstein, S.M.; Schlanitz, F.; Schmidt-Erfurth, U. Machine Learning of the Progression of Intermediate Age-Related Macular Degeneration Based on OCT Imaging. Investig. Opthalmol. Vis. Sci. 2017, 58, BIO141–BIO150. [Google Scholar] [CrossRef] [Green Version]
- Arcadu, F.; Benmansour, F.; Maunz, A.; Willis, J.; Haskova, Z.; Prunotto, M. Deep learning algorithm predicts diabetic retinopathy progression in individual patients. NPJ Digit. Med. 2019, 2, 92. [Google Scholar] [CrossRef]
- Wang, M.; Shen, L.Q.; Pasquale, L.R.; Petrakos, P.; Formica, S.; Boland, M.; Wellik, S.R.; De Moraes, C.G.; Myers, J.S.; Saeedi, O.; et al. An Artificial Intelligence Approach to Detect Visual Field Progression in Glaucoma Based on Spatial Pattern Analysis. Investig. Opthalmol. Vis. Sci. 2019, 60, 365–375. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, A.; Wong, T.Y.; Ting, D.S.W.; Govindaiah, A.; Souied, E.H.; Smith, R.T. Artificial Intelligence to Stratify Severity of Age-Related Macular Degeneration (AMD) and Predict Risk of Progression to Late AMD. Transl. Vis. Sci. Technol. 2020, 9, 25. [Google Scholar] [CrossRef] [Green Version]
- Sample, P.A.; Boden, C.; Zhang, Z.; Pascual, J.; Lee, T.-W.; Zangwill, L.M.; Weinreb, R.N.; Crowston, J.G.; Hoffmann, E.M.; Medeiros, F.A.; et al. Unsupervised machine learning with independent component analysis to identify areas of progression in glaucomatous visual fields. Investig. Opthalmol. Vis. Sci. 2005, 46, 3684–3692. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Objectives | First Author | Year | No. of Centers Involved (Country) | Sample Size | No. of KC/Early KC Eyes | Machine Learning Method/s Used | Data Type (No. of Parameters) | Corneal Imaging Modality | Evaluation Methods |
|---|---|---|---|---|---|---|---|---|---|
| Detect KC eyes from controls | Maeda et al. [12] | 1995 | 1 (USA) | 176 | 44 | Combined discriminant analysis and classification tree | P (8) | TMS-1 | Internal |
| Kalin et al. [16] | 1996 | NR | 106 | 5 | Combined discriminant analysis and classification tree | P (8) | TMS-1 | Validation study | |
| Rabinowitz et al. [17] | 1998 | 1 (USA) | 241 | 99 | Linear discriminant analysis | P (5) | TMS-1 | Internal | |
| Twa et al. [18] | 2005 | NR (USA) | 244 | 112 | Decision tree | P (36) | Keratron | Internal | |
| Bessho et al. [19] | 2006 | 2 (Japan) | 165 | 63 | logistic regression | P (na) | Orbscan II | External | |
| Saad et al. [20] | 2010 | NR | 143 | 31 | Discriminant analysis | P (51) | Orbscan IIz | Internal | |
| Smadja et al. [21] | 2013 | 1 (France) | 325 | 148 | Decision tree | P (55) | GALILEI | Internal | |
| Mahmoud et al. [22] | 2013 | 3 (Colombia, USA, Switzerland) | 407 | 163 | logistic regression | P (na) | GALILEI | External | |
| Saad et al. [23] | 2014 | 1 (France) | 166 | 64 | Discriminant analysis | P (7) | Orbscan IIz | Internal | |
| Silverman et al. [24] | 2014 | 1 (UK) | 204 | 74 | Multiple methods | P (161) | Artemis-1 | Internal | |
| Koprowski et al. [25] | 2015 | 1 (Brazil) | 746 | 477 | Decision tree | P (11) | Corvis | Internal | |
| Shetty et al. [26] | 2015 | 1 (India) | 128 | 85 | Logistic regression | P (na) | Pentacam | Internal | |
| Kovacs et al. [27] | 2016 | 1 (Hungary) | 120 | 60 | Neural network | P (na) | Pentacam HR | Internal | |
| Ruiz et al. [28] | 2016 | 1 (Belgium) | 648 | 454 | Support vector machine | P (22) | Pentacam HR | Internal | |
| Ambrosio et al. [29] | 2017 | 2 (Brazil, Italy) | 756 | 276 | Multiple methods | P (na) | Pentacam HR & Corvis ST | Internal | |
| Silverman et al. [30] | 2017 | 1 (USA) | 141 | 30 | Discriminant analysis | P (240) | Artemis-1 & Pentacam | Internal | |
| Lopes et al. [31] | 2018 | 5 (UK, Brazil, Italy, USA) | 3648 | 370 | Multiple methods | P (na) | Pentacam | Internal & External | |
| Chandapura et al. [32] | 2019 | NR | 439 | 218 including 102 early KC | Random forest | P (27) | Pentacam & OCT | Internal | |
| * Dos Santos et al. [41] | 2019 | 1 (Austria) | 142 | 70 | Convolutional neural network | I | OCT | Internal | |
| Issarti et al. [33] | 2019 | 1 (Belgium) | 624 | 312 | Neural network | P (28) | Pentacam | Internal | |
| Kamiya et al. [42] | 2019 | 1 (Japan) | 543 | 304 | Convolutional neural network | I | AS-OCT | Internal | |
| * Lavric et al. [43] | 2019 | NR | 3000 | 1500 | Convolutional neural network | I | SyntEyes model | Internal | |
| Leão et al. [34] | 2019 | 2 (Brazil, Italy) | 574 | 223 | Discriminant analysis | P (na) | Corvis ST | NR | |
| Bolarin et al. [35] | 2020 | 1 (Spain) | 169 | 107 | logistic regression | P | Sirius | Internal | |
| Castro-Luna et al. [36] | 2020 | 1 (Spain) | 60 | 30 | Naive Bayes | P | CSO | Internal | |
| * Issarti et al. [37] | 2020 | 2 (Belgium) | 812 | 508 | Neural Network | P (90) | Pentacam HR | Internal & External | |
| Kuo et al. [44] | 2020 | 1 (Taiwan) | 326 | 170 | Convolutional neural network | I | TMS-4 | Internal | |
| Lavric et al. [38] | 2020 | NR | 3151 | 1181 including 791 early KC | Multiple methods | P (443) | SS-1000 CASIA OCT | Internal | |
| * Shi et al. [39] | 2020 | 1 (China) | 121 | 38 | Neural network | P (49) | UHR-OCT & Pentacam HR | Internal | |
| Velazquez-Blazquez et al. [40] | 2020 | 1 (Spain) | 178 | 104 including 61 early KC | Logistic regression | P (27) | Sirius | Internal | |
| Detect early KC eyes from controls | Saad et al. [20] | 2010 | NR | 143 | 40 | Discriminant analysis | P (51) | Orbscan IIz | Internal |
| Smadja et al. [21] | 2013 | 1 (France) | 224 | 47 | Decision tree | P (55) | GALILEI | Internal | |
| * Ventura et al. [45] | 2013 | NR (Brazil) | 204 | 68 | Neural network | P (41) | Ocular Response Analyzer | Internal | |
| Chan et al. [46] | 2015 | 1 (Singapore) | 128 | 24 | Discriminant analysis | P (na) | Orbscan IIz | Validation study | |
| Kovacs et al. [27] | 2016 | 1 (Hungary) | 75 | 15 | Neural network | P (na) | Pentacam HR | Internal | |
| Ruiz et al. [28] | 2016 | 1 (Belgium) | 261 | 67 | Support vector machine | P (22) | Pentacam HR | Internal | |
| Ambrosio et al. [29] | 2017 | 2 (Brazil, Italy) | 574 | 94 | Multiple methods | P (na) | Pentacam HR & Corvis ST | Internal | |
| Xu et al. [47] | 2017 | 1 (China) | 363 | 77 | Discriminant analysis | P (na) | Pentacam HR | Internal | |
| Lopes et al. [31] | 2018 | 5 (UK, Brazil, Italy, USA) | 3537 | 259 | Multiple methods | P (na) | Pentacam | Internal & External | |
| Issarti et al. [33] | 2019 | 1 (Belgium) | 389 | 77 | Neural network | P (28) | Pentacam | Internal | |
| Cao et al. [48] | 2020 | 1 (Australia) | 88 | 49 | Multiple methods | P (11) | Pentacam | Internal | |
| * Issarti et al. [37] | 2020 | 2 (Belgium) | 812 | 117 | Neural Network | P (90) | Pentacam HR | Internal & External | |
| * Kuo et al. [44] | 2020 | 1 (Taiwan) | 354 | 28 | Convolutional neural network | I | TMS-4 | Internal | |
| * Shi et al. [39] | 2020 | 1 (China) | 121 | 33 | Neural network | P (49) | UHR-OCT & Pentacam HR | Internal | |
| KC Severity | Yousefi et al. [49] | 2018 | multi-center (Japan) | 3156 | Density-based clustering | P (420) | CASIA OCT | NA |
| Imaging Modalities | Pooled Sensitivity | Pooled Specificity |
|---|---|---|
| Pentacam (n = 5) | 0.987 (95% CI 0.971–0.994) | 0.989 (95% CI 0.963–0.997) |
| TMS (n = 4) | 0.943 (95% CI 0.897–0.969) | 0.978 (95% CI 0.954–0.989) |
| Orbscan (n = 3) | 0.947 (95% CI 0.886–0.976) | 0.983 (95% CI 0.917–0.997) |
| Pooled total (n = 26) | 0.970 (95% CI 0.949–0.982) | 0.985 (95% CI 0.971–0.993) |
| Imaging Modalities | Pooled Sensitivity | Pooled Specificity |
|---|---|---|
| Pentacam (n = 6) | 0.882 (95% CI 0.795–0.935) | 0.935 (95% CI 0.874–0.967) |
| Orbscan (n = 2) | 0.842 (95% CI 0.504–0.965) | 0.958 (95% CI 0.821–0.991) |
| Pooled total (n = 10) | 0.882 (95% CI 0.822–0.923) | 0.947 (95% CI 0.914–0.967) |
| First Author | Year | Severity Grading (No. of Eyes) | Definition/Classification Methods | Corneal Imaging Modality | Reported Sensitivity in Detection of Each Severity Level |
|---|---|---|---|---|---|
| Maeda et al. [12] | 1995 | Mild (15) Moderate (18) Advanced (11) | NA | TMS-1 | Mild: 100% Moderate: 100% Advanced: 91% |
| Kamiya et al. [42] | 2019 | Grade 1 (108) Grad e2 (75) Grade 3 (42) Grade 4 (79) | Amsler–Krumeich classification | AS-OCT | Grade 1: 88.9% Grade 2: 68% Grade 3: 71.4% Grad e4: 74.7% |
| Issarti et al. [33] | 2019 | Mild KC (220) | a Self-defined | Pentacam | 98.81% |
| Issarti et al. [33] | 2019 | Moderate KC (229) | b Self-defined | Pentacam | 99.91% |
| Bolarin et al. [35] | 2020 | Grade I (44) Grade II (18) Grade III (15) Grade IV (15) Grade IV plus (15) | RETICS grading | Sirius | Grade I: 59.1% Grade II: 33.3% Grade III: 40% Grade IV: 80% Grade IV plus: 86.7% |
| Velazquez-Blazquez et al. [40] | 2020 | Mild KC (42) | RETICS grading | Sirius | Mild KC: 63% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, K.; Verspoor, K.; Sahebjada, S.; Baird, P.N. Accuracy of Machine Learning Assisted Detection of Keratoconus: A Systematic Review and Meta-Analysis. J. Clin. Med. 2022, 11, 478. https://doi.org/10.3390/jcm11030478
Cao K, Verspoor K, Sahebjada S, Baird PN. Accuracy of Machine Learning Assisted Detection of Keratoconus: A Systematic Review and Meta-Analysis. Journal of Clinical Medicine. 2022; 11(3):478. https://doi.org/10.3390/jcm11030478
Chicago/Turabian StyleCao, Ke, Karin Verspoor, Srujana Sahebjada, and Paul N. Baird. 2022. "Accuracy of Machine Learning Assisted Detection of Keratoconus: A Systematic Review and Meta-Analysis" Journal of Clinical Medicine 11, no. 3: 478. https://doi.org/10.3390/jcm11030478