

Membrane Fouling Diagnosis of Membrane Components Based on MOJS-ADBN
 , ,
, ,
Abstract
:1. Introduction
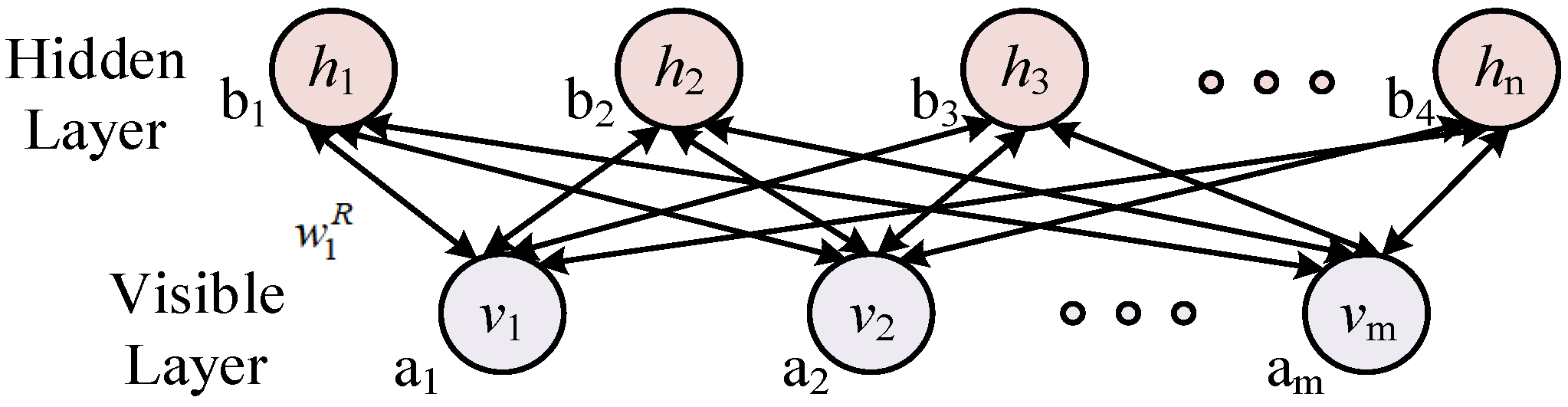
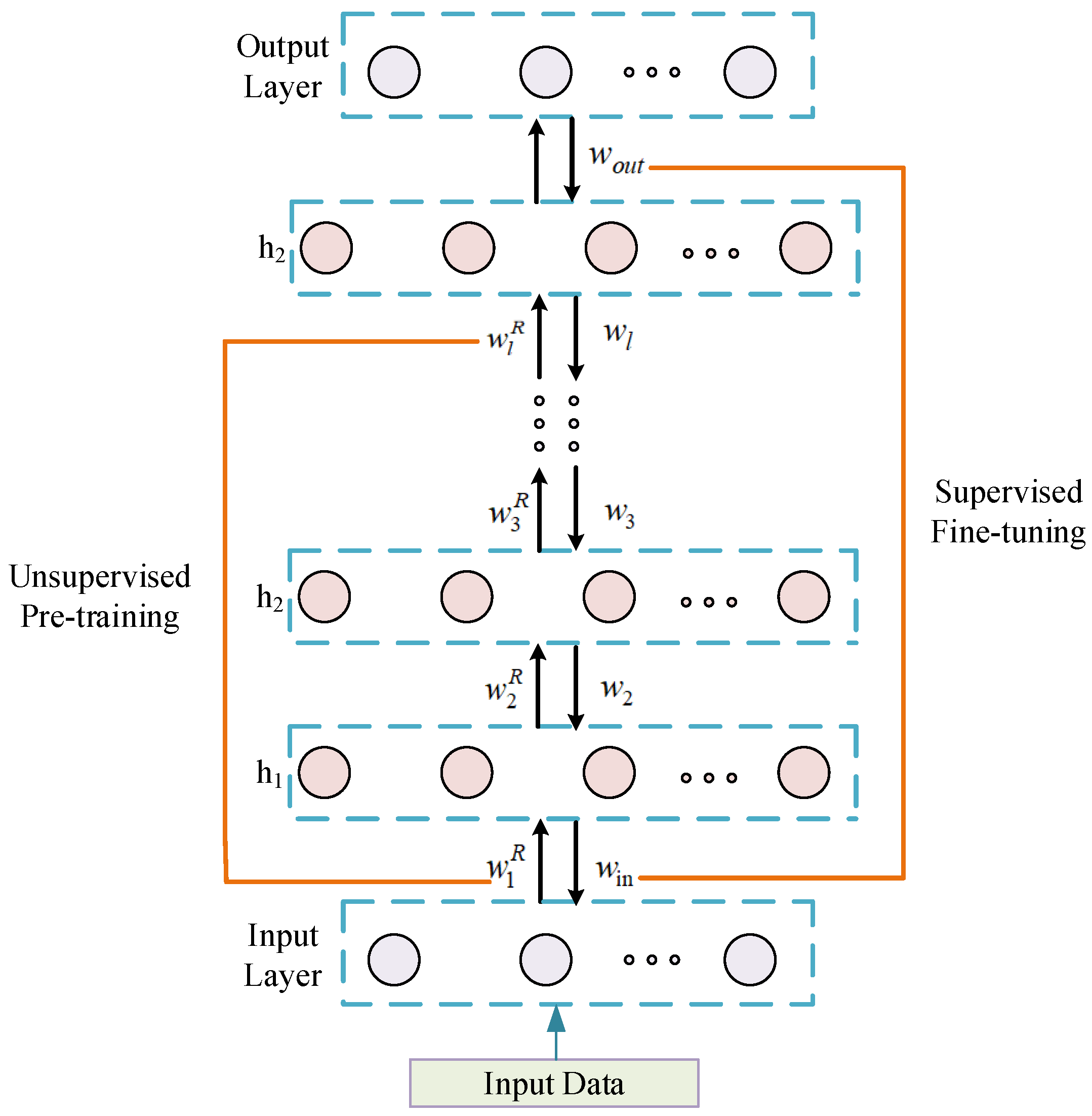
2. Traditional DBN Model
2.1. Subsection
2.2. Unsupervised Learning
2.3. Supervised Learning
3. MOJS-ADBN Learning Algorithm
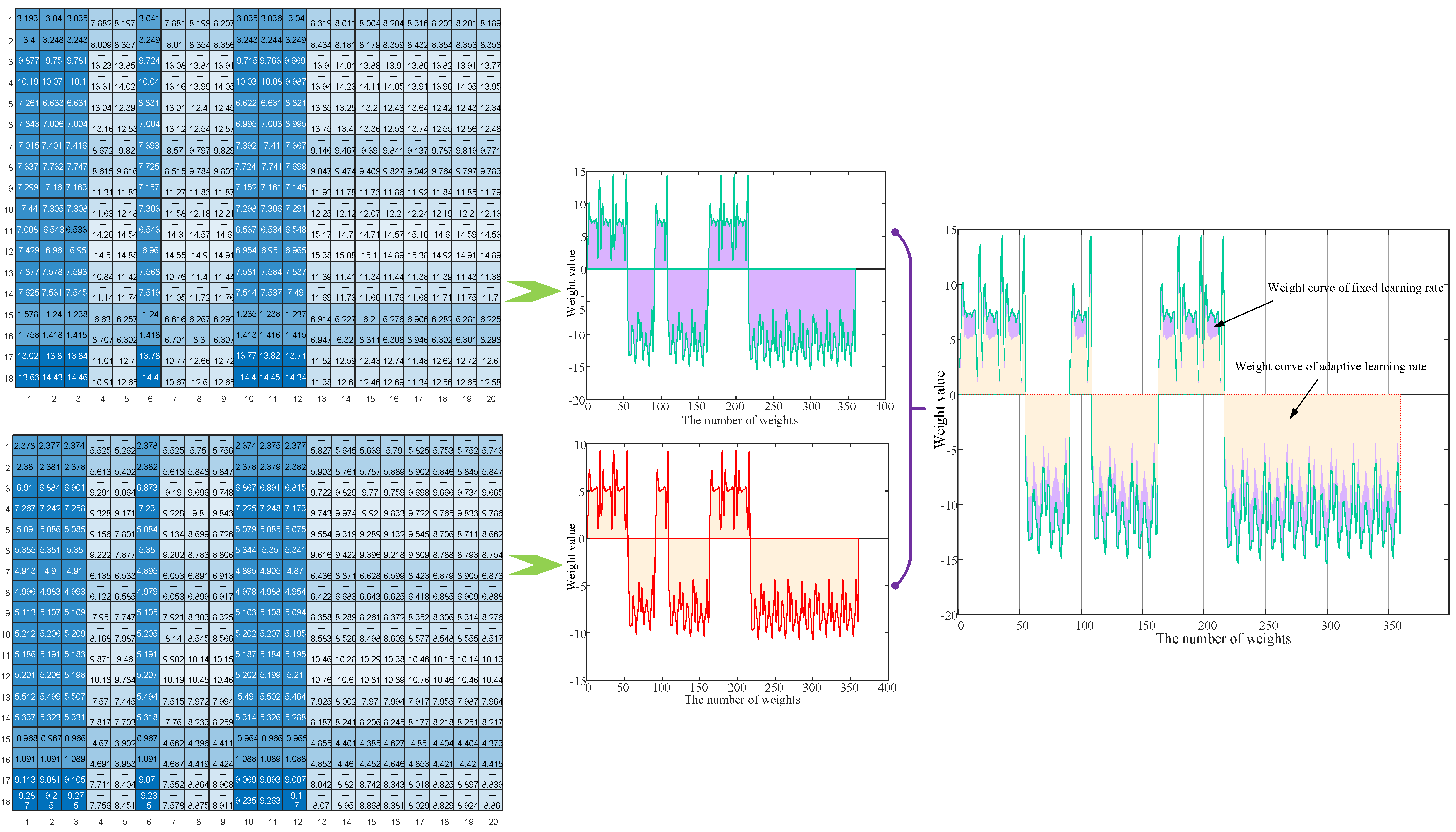
3.1. Adaptive Learning Rate CD Algorithm
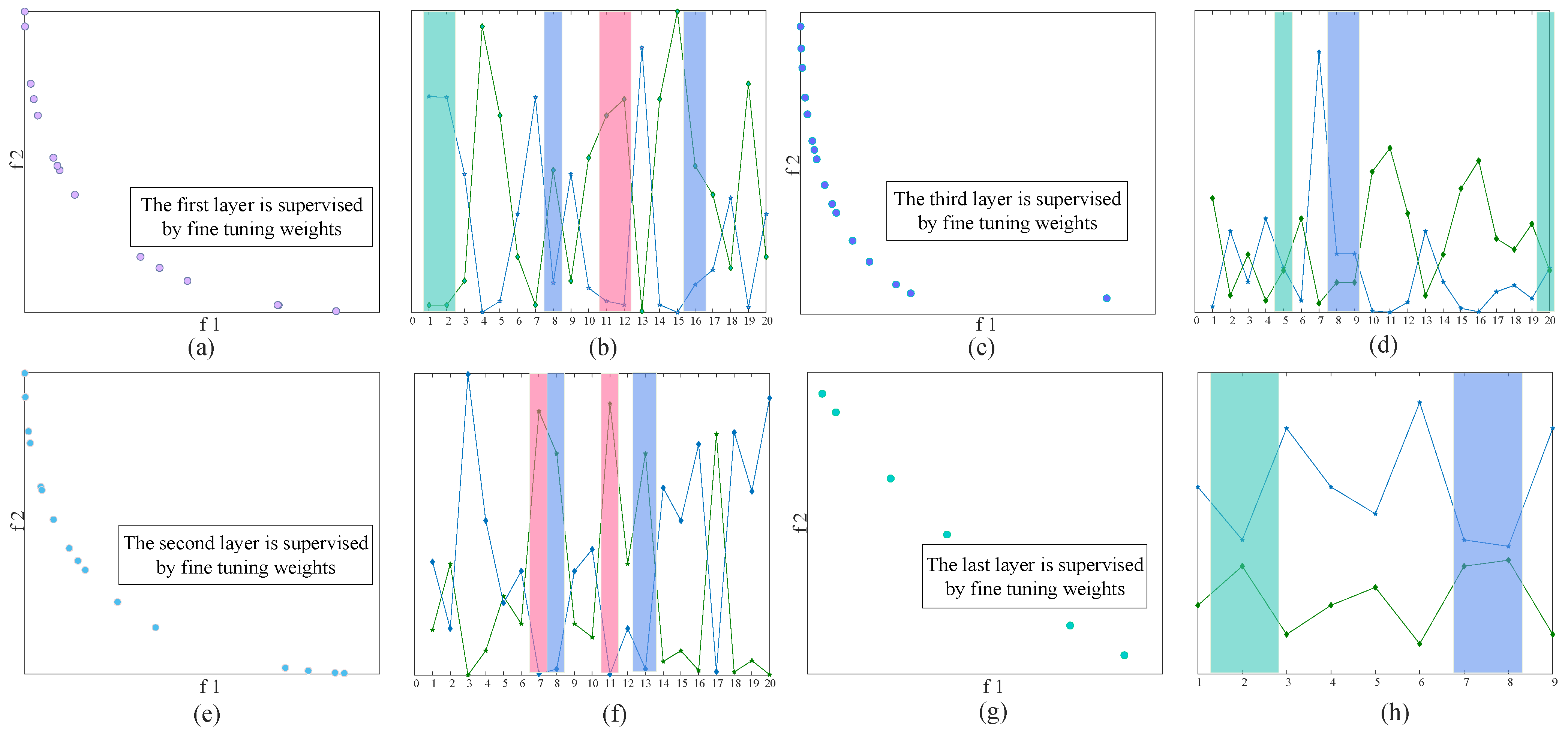
3.2. Supervised Fine Adjustment Based on MOJS
3.2.1. Time Control Function
3.2.2. Elite Choice
3.2.3. Lévy Flight
3.2.4. Update and Archive
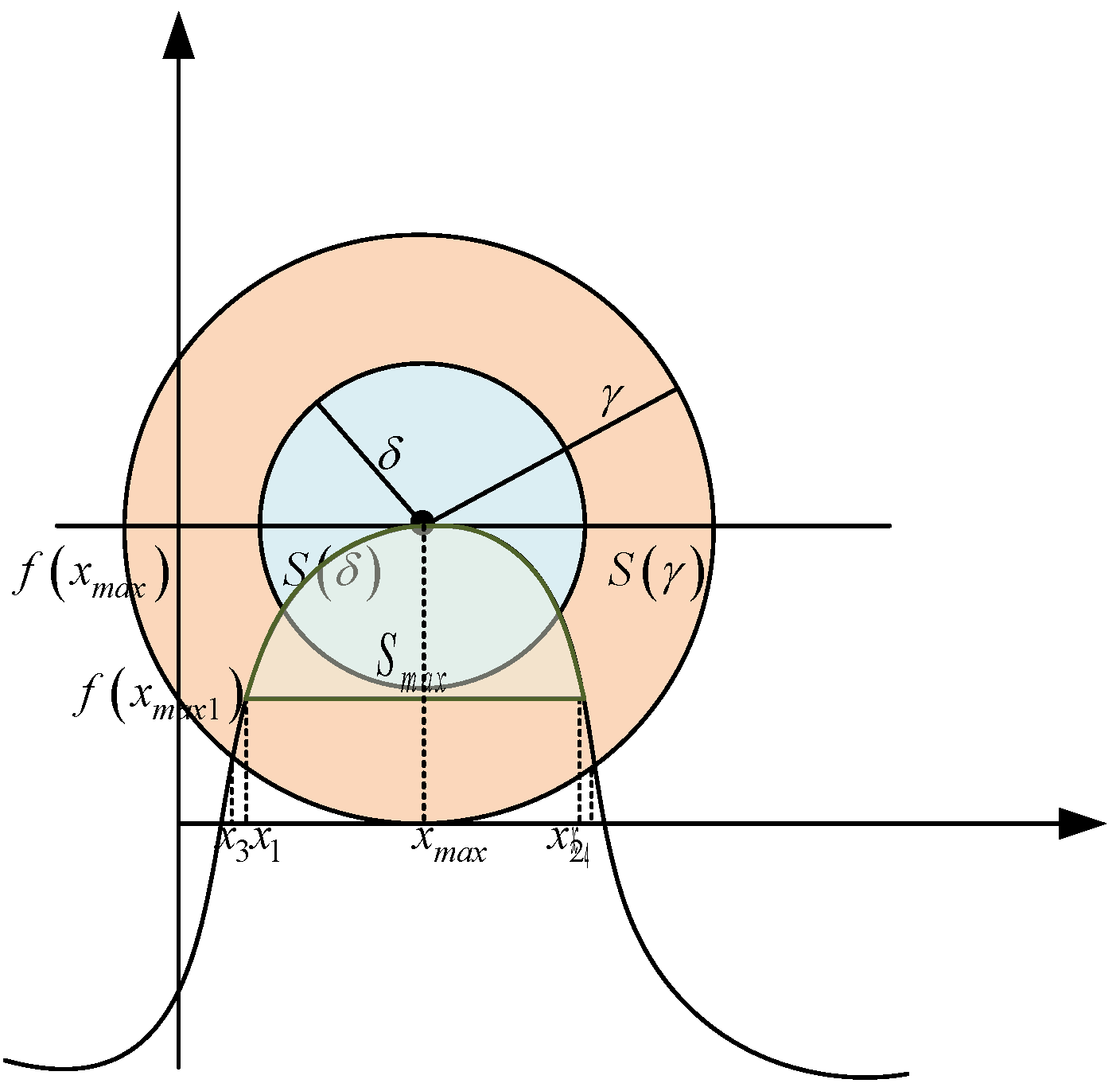
3.2.5. MOJS
3.2.6. Population Initialization
3.2.7. Increase Diversity through Opposition-Based Jumping
4. Algorithm and Convergence Analysis
4.1. Adaptive Learning Rate CD Algorithm Analysis
4.2. Unsupervised Training Phase
4.3. Supervised Training Phase
4.3.1. Multi-Objective Jellyfish Behavior Process
4.3.2. Stability of Reducible Random Matrix
4.3.3. Proof of Global Convergence
4.3.4. Global Stability Proof
4.3.5. Stability of the MOJS Algorithm in the Lyapunov Meaning
5. Simulation Experiment and Research Analysis
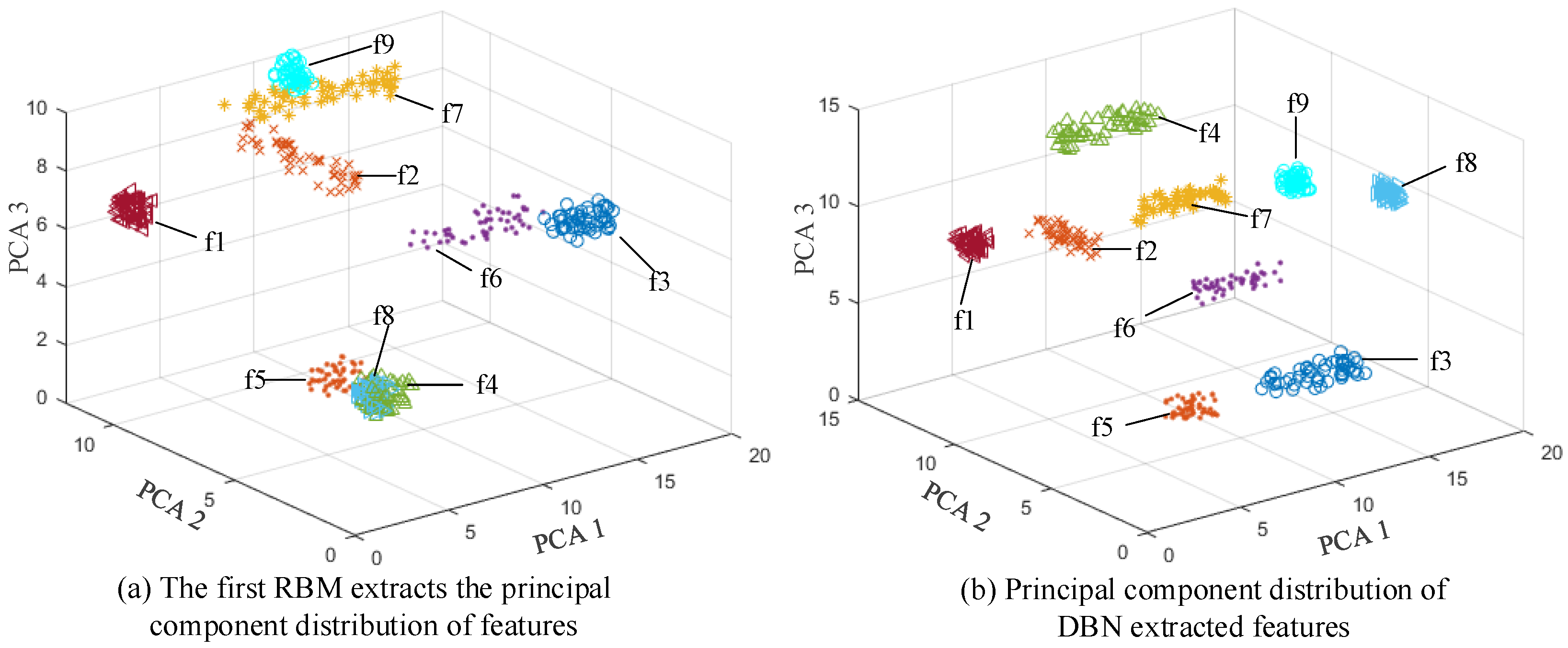
5.1. Membrane Fouling Data Acquisition
5.2. Experimental Process
5.3. Comparative Test
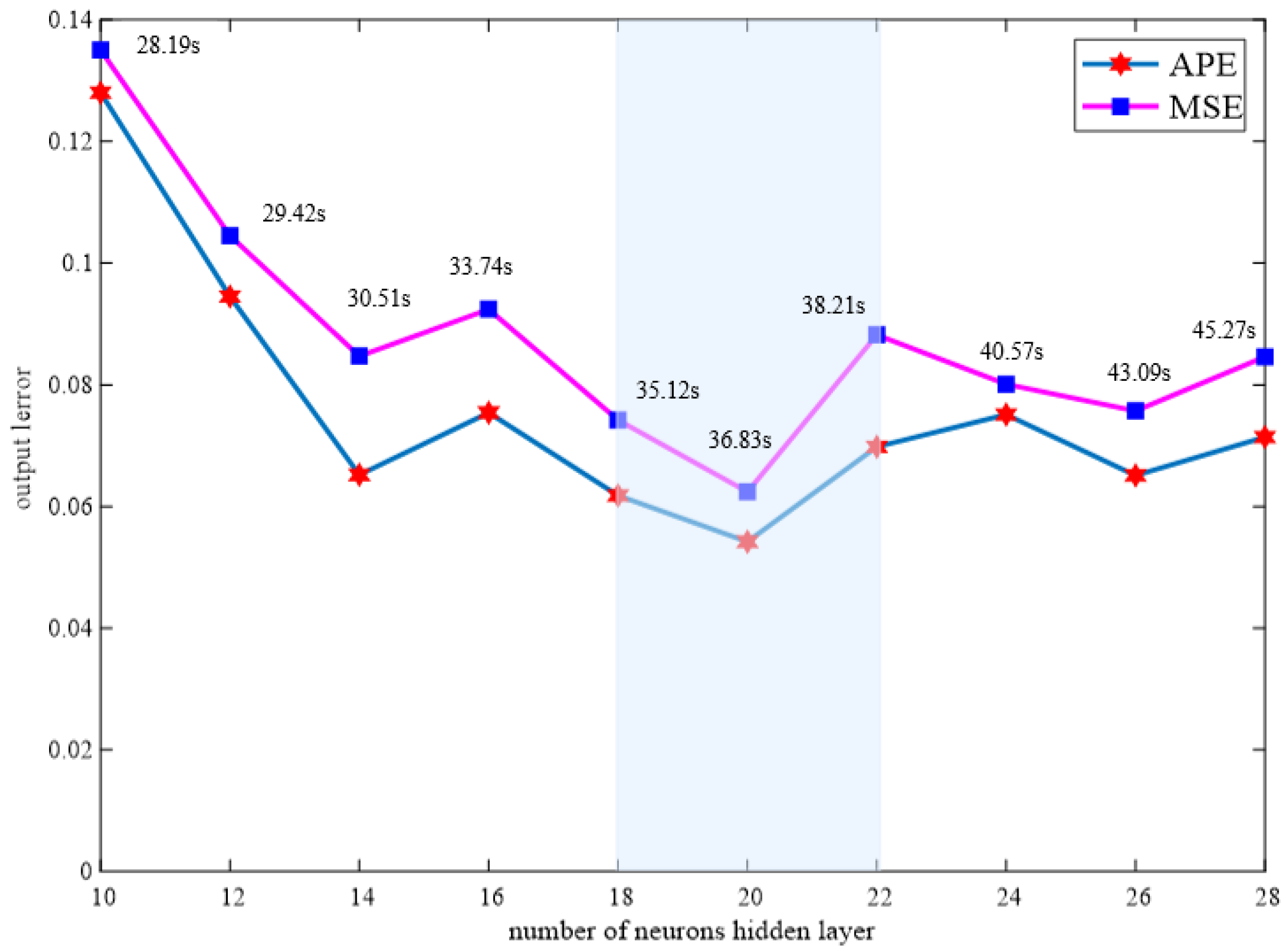
5.3.1. Comparative Test of Different Learning Rates
5.3.2. Comparison of Ablation Experiments
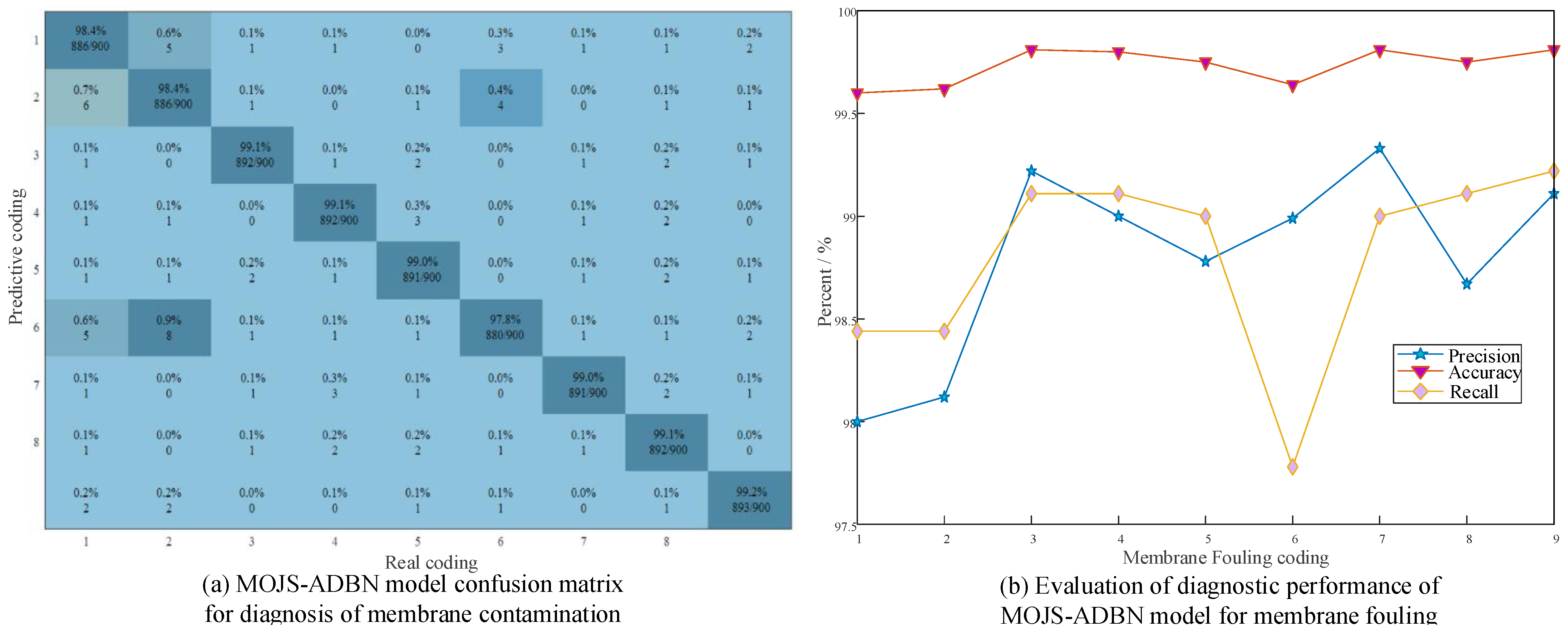
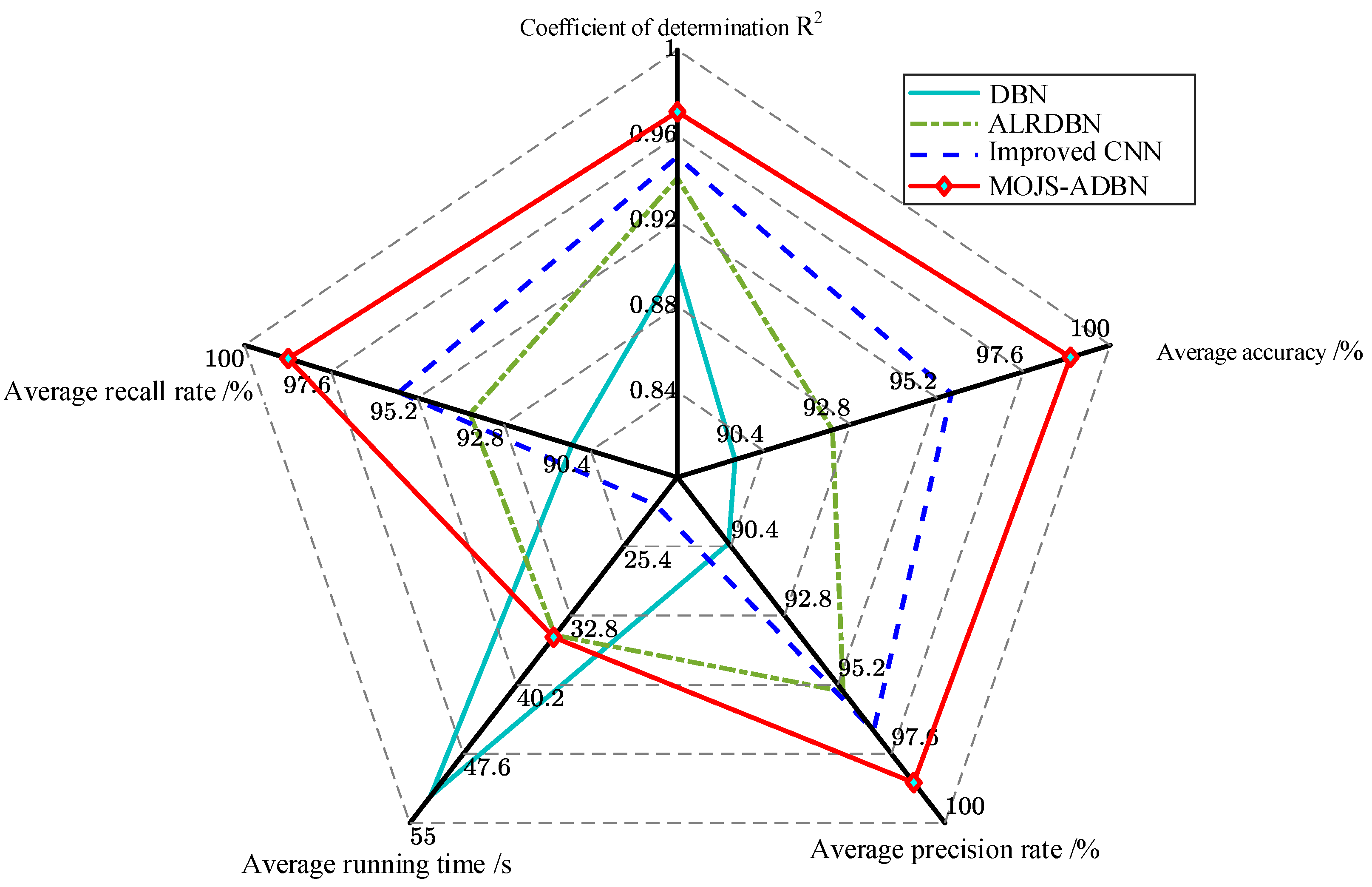
5.3.3. Variable Noise Membrane Fouling Diagnosis Results of Different Diagnostic Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.; Zhou, Z.; Cheng, C.; Wang, Z.W.; Pang, H.J.; Jiang, L.Y.; Jiang, L.M. Effects of packing carriers and ultrasonication on membrane fouling and sludge properties of anaerobic side-stream reactor coupled membrane reactors for sludge reduction. J. Membr. Sci. 2019, 581, 312–320. [Google Scholar] [CrossRef]
- Du, X.J.; Shi, Y.K.; Jegatheesan, V.; Haq, I.U. A review on the mechanism, impacts and control methods of membrane fouling in MBR system. Membranes 2020, 10, 24. [Google Scholar] [CrossRef]
- Wang, C.S.; Ng, T.C.A.; Ding, M.Y.; Ng, H.Y. Insights on fouling develop-ment and characteristics during different fouling stages between a novel vibrating MBR and an air-sparging MBR for domestic wastewater treatment. Water Res. 2022, 212, 118098. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.J.; Sankararao, B.; Yoo, C.K. Determination of MBR fouling and chemical cleaning interval using statistical methods applied on dynamic index data. J. Membr. Sci. 2011, 375, 345–353. [Google Scholar] [CrossRef]
- Farias, E.L.; Howe, K.J.; Thomson, B.M. Effect of membrane bioreactor solids retention time on reverse osmosis membrane fouling for wastewater reuse. Water Res. 2014, 49, 53–61. [Google Scholar] [CrossRef] [PubMed]
- Saravanan, N.; Ramachandran, K.I. Fault diagnosis of spur bevel gear box using discrete wavelet features and decision tree classification. Expert Syst. Appl. 2009, 36, 9564–9573. [Google Scholar] [CrossRef]
- Zhang, Z.Q.; Mei, J.M.; Zhao, H.M.; Chang, C.; Shen, H. Early bearing fault feature extraction based on CEMP time-frequency features. J. Vib. Shock 2020, 39, 168–173. [Google Scholar] [CrossRef]
- Wang, D.; Tsui, K.L.; Qin, Y. Optimization of segmentation fragments in empirical wavelet transform and its applications to extracting industrial bearing fault features. Measurement 2019, 133, 328–340. [Google Scholar] [CrossRef]
- Ling, G.B.; Wang, Z.W.; Shi, Y.K.; Wang, J.Y.; Lu, Y.R.; Li, L. Membrane Fouling Prediction Based on Tent-SSA-BP. Membranes 2022, 12, 691. [Google Scholar] [CrossRef]
- Hu, H.J.; Li, Y.X.; Liu, M.F.; Liang, W.H. Classification of defects in steel strip surface based on multiclass support vector machine. Multimed. Tools Appl. 2014, 69, 199–216. [Google Scholar] [CrossRef]
- Yu, J. A particle filter driven dynamic Gaussian mixture model approach for complex process monitoring and fault diagnosis. J. Process Control 2012, 22, 778–788. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, F.N.; Shen, W.H.; Liu, Z.; Corriou, J.P.; Seferlis, P. Sub-period division strategies combined with multiway principle component analysis for fault diagnosis on sequence batch reactor of wastewater treatment process in paper mill. Process Saf. Environ. 2021, 146, 9–19. [Google Scholar] [CrossRef]
- Mid, E.C.; Dua, V. Model-based parameter estimation for fault detection using multiparametric programming. Ind. Eng. Chem. Res. 2017, 56, 8000–8015. [Google Scholar] [CrossRef]
- Mid, E.C.; Dua, V. Fault detection in wastewater treatment systems using multiparametric programming. Processes 2018, 6, 231. [Google Scholar] [CrossRef]
- Wu, W.Q.; Song, C.Y.; Liu, J.; Zhao, J. Data-knowledge-driven distributed monitoring for large-scale processes based on digraph. J. Process Control 2022, 109, 60–73. [Google Scholar] [CrossRef]
- Han, H.G.; Liu, H.X.; Liu, Z.; Qiao, J.F. Fault detection of sludge bulking using a self-organizing type-2 fuzzy-neural-network. Control Eng. Pract. 2019, 90, 27–37. [Google Scholar] [CrossRef]
- Shi, Y.K.; Wang, Z.W.; Du, X.J.; Gong, B.; Jegatheesan, V.; Haq, I.U. Recent advances in the prediction of fouling in membrane bioreactors. Membranes 2021, 11, 381. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. A survey on Deep Learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, S.; Zhu, Y. Deep learning-based intelligent fault diagnosis methods toward rotating machinery. IEEE Access 2020, 9, 9335–9346. [Google Scholar] [CrossRef]
- Chang, P.; Li, Z.Y.; Wang, G.M.; Wang, P. An effective deep recurrent network with high-order statistic information for fault monitoring in wastewater treatment process. Expert Syst. Appl. 2021, 167, 114141. [Google Scholar] [CrossRef]
- Ba-Alawi, A.H.; Loy-Benitez, J.; Kim, S.; Yoo, C. Missing data imputation and sensor self-validation towards a sustainable operation of wastewater treatment plants via deep variational residual autoencoders. Chemosphere 2022, 288, 132647. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.K.; Wang, Z.W.; Du, X.J.; Gong, B.; Lu, Y.R.; Li, L. Membrane Fouling Diagnosis of Membrane Components Based on Multi-feature Information Fusion. J. Membr. Sci. 2022, 657, 120670. [Google Scholar] [CrossRef]
- Shi, Y.K.; Wang, Z.W.; Du, X.J.; Ling, G.B.; Jia, W.C.; Lu, Y.R. Research on the membrane fouling diagnosis of MBR membrane module based on ECA-CNN. J. Environ. Chem. Eng. 2022, 10, 107649. [Google Scholar] [CrossRef]
- Ji, D.X.; Yao, X.; Li, S.; Tang, Y.G.; Tian, Y. Model-free fault diagnosis for autonomous underwater vehicles using sequence convolutional neural network. Ocean Eng. 2021, 232, 108874. [Google Scholar] [CrossRef]
- Miyata, S.; Lim, J.; Akashi, Y.; Kuwahara, Y.; Tanaka, K. Fault detection and diagnosis for heat source system using convolutional neural network with imaged faulty behavior data. Sci. Technol. Built Environ. 2019, 26, 1–9. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, H.; Zhang, Y.; Zhang, F.; Huang, M. Modeling of wastewater treatment processes using dynamic Bayesian networks based on fuzzy PLS. IEEE Access 2020, 8, 92129–92140. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P.F. Failure diagnosis using deep belief learning based health state classification. Reliab. Eng. Syst. Safe 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Deng, W.; Liu, H.; Xu, J.; Zhao, H.; Song, Y. An improved quantum-inspired differential evolution algorithm for deep belief network. IEEE Trans. Instrum. Meas. 2020, 69, 7319–7327. [Google Scholar] [CrossRef]
- Wang, Y.L.; Pan, Z.F.; Yuan, X.F.; Yang, C.H.; Gui, W.H. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Trans. 2020, 96, 457–467. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, X.; Zhang, B.; Liu, Y.; Niu, G.; Hu, C. A novel approach for analog circuit fault diagnosis based on deep belief network. Measurement 2018, 121, 170–178. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; The, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Jia, Z.; Vong, C.M.; Bu, S.; Han, J.; Tang, X. Capturing high-discriminative fault features for electronics-rich analog system via deep learning. IEEE Trans. Ind. Inform. 2017, 13, 1213–1226. [Google Scholar] [CrossRef]
- Zhang, C.; He, Y.; Yuan, L.; Xiang, S. Analog circuit incipient fault diagnosis method using DBN based features extraction. IEEE Access 2018, 6, 23053–23064. [Google Scholar] [CrossRef]
- Dai, J.; Song, H.; Sheng, G.; Jiang, X. Dissolved gas analysis of insulating oil for power transformer fault diagnosis with deep belief network. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 2828–2835. [Google Scholar] [CrossRef]
- Zhu, D.; Cheng, X.; Yang, L.; Chen, Y.S.; Yang, S.X. Information fusion fault diagnosis method for deep-sea human occupied vehicle thruster based on deep belief network. IEEE Trans. Cybern. 2021, 99, 3055770. [Google Scholar] [CrossRef]
- Su, X.; Cao, C.; Zeng, X.; Feng, Z.; Shen, J.; Yan, X.; Wu, Z. Application of DBN and GWO-SVM in analog circuit fault diagnosis. Sci. Rep. 2021, 11, 7969. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA–DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Code | Fault Type | Tolerance |
|---|---|---|
| f1 | No fouling | — |
| f2 | C too large | 5% |
| f3 | C too small | 5% |
| f4 | B too large | 5% |
| f5 | B too small | 5% |
| f6 | X too large | 7% |
| f7 | X too small | 7% |
| f8 | H too large | 7% |
| f9 | H too small | 7% |
| Learning Rate | Average Accuracy/% |
|---|---|
| 0.01 | 95.26 |
| 0.05 | 93.73 |
| 0.1 | 96.21 |
| 0.5 | 94.57 |
| 1 | 96.75 |
| Diagnosis Method | Network Structure | Testing MSE | Average Time/s | Average Accuracy/% | |
|---|---|---|---|---|---|
| Mean | Variance | ||||
| BP | 18-20-9 | 0.0294 | 0.0121 | 55.42 | 78.51 |
| ELM | 18-20-9 | 0.0313 | 0.0106 | 59.47 | 81.05 |
| SVM | Gaussian Kernel Function | 0.0251 | 0.0092 | 62.73 | 80.93 |
| LSSVM | Gaussian Kernel Function | 0.0247 | 0.0085 | 60.51 | 83.57 |
| DBN | 18-20-20-20-9 | 0.0218 | 0.0075 | 52.14 | 90.92 |
| ALRDBN | 18-20-20-20-9 | 0.0157 | 0.0053 | 34.91 | 93.75 |
| Improved CNN | 21 layers | 0062 | 0.0035 | 20.97 | 95.72 |
| MOJS-ADBN | 18-20-20-20-9 | 0.0052 | 0.0027 | 35.12 | 98.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Wang, Z.; Du, X.; Gong, B.; Lu, Y.; Li, L.; Ling, G. Membrane Fouling Diagnosis of Membrane Components Based on MOJS-ADBN. Membranes 2022, 12, 843. https://doi.org/10.3390/membranes12090843
Shi Y, Wang Z, Du X, Gong B, Lu Y, Li L, Ling G. Membrane Fouling Diagnosis of Membrane Components Based on MOJS-ADBN. Membranes. 2022; 12(9):843. https://doi.org/10.3390/membranes12090843
Chicago/Turabian StyleShi, Yaoke, Zhiwen Wang, Xianjun Du, Bin Gong, Yanrong Lu, Long Li, and Guobi Ling. 2022. "Membrane Fouling Diagnosis of Membrane Components Based on MOJS-ADBN" Membranes 12, no. 9: 843. https://doi.org/10.3390/membranes12090843