
Proteometabolomic Analysis Reveals Molecular Features Associated with Grain Size and Antioxidant Properties amongst Chickpea (Cicer arietinum L.) Seeds Genotypes
 ,
,  , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Biological Material
2.2. Seed Measurement
2.3. Proximate Analysis
2.4. Total Antioxidant Capacity by 2,2-Diphenyl-1-picrylhydrazyl (DPPH) and Oxygen Radical Absorbance Capacity (ORAC)
2.5. Proteomic Analysis
2.6. Metabolomic Analysis
2.7. Statistical Analysis
3. Results
3.1. Phenotypic Features of Chickpea Genotypes with Different Grain Size
3.2. Proximate Analysis of Chickpea with Different Grain Size
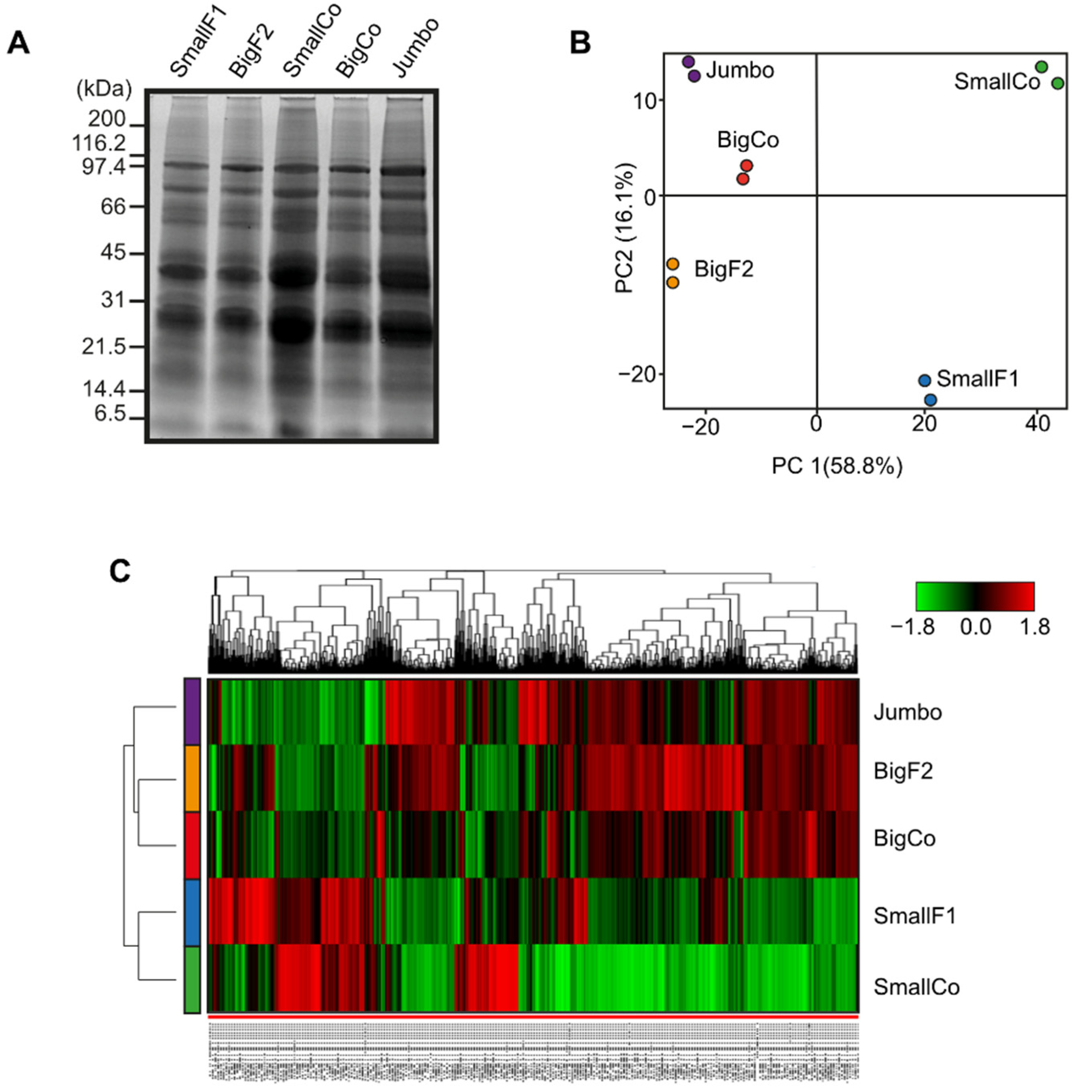
3.3. Comparative Proteomics Revealed Contrasting Proteome Profile in Small vs. Large Grain Genotypes
3.4. Untargeted Metabolomics Exhibited Additional Clues of the Nutraceutical Potential of Chickpeas
3.5. Targeted Metabolomics Confirmed the Accumulation of Antioxidant Polyphenols in SmallF1
4. Discussion
4.1. Large Chickpea Genotypes Have Higher Levels of Starch, Lipid, Amino Acid, and Gibberellin Metabolism-Related Proteins
4.2. Chickpea Grains Exhibited Essential Stress Response Connected to the Overproduction of Polyphenols
4.3. Alternative Application of Small Chickpeas as Nutraceutical Source
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Detail Proteomics and Metabolomics Methodologies
Appendix A.1. Proteomics Analyses
Appendix A.1.1. Sample Preparation
Appendix A.1.2. Nano-LC-MS/MS, Synchronous Precursor Selection (SPS)-MS3 and Data Analysis
Appendix A.1.3. Bioinformatic Analysis
Appendix A.2. Metabolomics Analysis
Appendix A.2.1. Untargeted Metabolomics Analyses
Appendix A.2.2. Targeted Metabolomics Analyses (Phenolic Compounds)
Sample Preparation
Multiple Reaction Monitoring (MRM)
References
- Chatterjee, M.; Gupta, S.; Bhar, A.; Chakraborti, D.; Basu, D.; Das, S. Analysis of root proteome unravels differential molecular responses during compatible and incompatible interaction between chickpea (Cicer arietinum L.) and Fusarium oxysporum f. sp. ciceri Race1 (Foc1). BMC Genom. 2014, 15, 1–19. [Google Scholar] [CrossRef]
- Varshney, R.K.; Mohan, S.M.; Gaur, P.M.; Gangarao, N.V.P.R.; Pandey, M.K.; Bohra, A.; Sawargaonkar, S.L.; Chitikineni, A.; Kimurto, P.K.; Janila, P.; et al. Achievements and prospects of genomics-assisted breeding in three legume crops of the semi-arid tropics. Biotechnol. Adv. 2013, 31, 1120–1134. [Google Scholar] [CrossRef] [PubMed]
- Abbo, S.; Molina, C.; Jungmann, R.; Grusak, M.A.; Berkovitch, Z.; Reifen, R.; Kahl, G.; Winter, P.; Reifen, R. Quantitative trait loci governing carotenoid concentration and weight in seeds of chickpea (Cicer arietinum L.). Theor. Appl. Genet. 2005, 111, 185–195. [Google Scholar] [CrossRef] [PubMed]
- Duranti, M.; Gius, C. Legume seeds: Protein content and nutritional value. Field Crops Res. 1997, 53, 31–45. [Google Scholar] [CrossRef]
- Jadhav, A.A.; Rayate, S.J.; Mhase, L.B.; Thudi, M.; Chitikineni, A.; Harer, P.N.; Jadhav, A.S.; Varshney, R.K.; Kulwal, P.L. Marker-trait association study for protein content in chickpea (Cicer arietinum L.). J. Genet. 2015, 94, 279–286. [Google Scholar] [CrossRef] [PubMed]
- Kumar, J.; Choudhary, A.K.; Solanki, R.K.; Pratap, A. Towards marker-assisted selection in pulses: A review. Plant Breed. 2011, 130, 297–313. [Google Scholar] [CrossRef]
- Wallace, T.C.; Murray, R.; Zelman, K.M. The nutritional value and health benefits of chickpeas and hummus. Nutrients 2016, 8, 766. [Google Scholar] [CrossRef]
- Merga, B.; Haji, J. Economic importance of chickpea: Production, value, and world trade. Cogent Food Agric. 2019, 5, 1615718. [Google Scholar] [CrossRef]
- SIAP, Servicio de Información Agroalimentaria y Pesquera.Anuario Estadístico de la Producción Agrícola. Available online: http://infosiap.siap.gob.mx/gobmx/datosAbiertos.php (accessed on 11 February 2021).
- Wood, J.A.; Knights, E.J.; Chocty, M. Morphology of chickpea seeds (Cicer arietinum l.): Comparison of desi and kabuli types. Int. J. Plant Sci. 2011, 172, 632–643. [Google Scholar] [CrossRef]
- Li, N.; Xu, R.; Li, Y. Molecular networks of seed size control in plants. Ann. Rev. Plant Biol. 2019, 70, 435–463. [Google Scholar] [CrossRef]
- Biçer, B.T. The effect of seed size on yield and yield components of chickpea and lentil. Afr. J. Biotechnol. 2009, 8, 1482–1487. [Google Scholar]
- Cortés-Giraldo, I.; Girón-Calle, J.; Alaiz, M.; Vioque, J.; Megías, C. Hemagglutinating activity of polyphenols extracts from six grain legumes. Food Chem. Toxicol. 2012, 50, 1951–1954. [Google Scholar] [CrossRef]
- Nisa, Z.U.; Arif, A.; Waheed, M.Q.; Shah, T.M.; Iqbal, A.; Siddiqui, A.J.; Choudhary, M.I.; El-Seedi, H.R.; Musharraf, S.G. A comparative metabolomic study on desi and kabuli chickpea (Cicer arietinum L.) genotypes under rainfed and irrigated field conditions. Sci. Rep. 2020, 10, 1–11. [Google Scholar]
- Segev, A.; Badani, H.; Kapulnik, Y.; Shomer, I.; Oren-Shamir, M.; Galili, S. Determination of polyphenols, flavonoids, and antioxidant capacity in colored chickpea (Cicer arietinum L.). J. Food Sci. 2010, 75, S115–S119. [Google Scholar] [CrossRef]
- Gao, Y.; Yao, Y.; Zhu, Y.; Ren, G. Isoflavone content and composition in chickpea (Cicer arietinum L.) sprouts germinated under different conditions. J. Agric. Food Chem. 2015, 63, 2701–2707. [Google Scholar] [CrossRef]
- De Camargo, A.C.; Favero, B.T.; Morzelle, M.C.; Franchin, M.; Alvarez-Parrilla, E.; De La Rosa, L.A.; Geraldi, M.V.; Maróstica, M.R.; Shahidi, F.; Schwember, A.R. Is chickpea a potential substitute for soybean? phenolic bioactives and potential Health benefits. Int. J. Mol. Sci. 2019, 20, 2644. [Google Scholar] [CrossRef]
- Roorkiwal, M.; Bharadwaj, C.; Barmukh, R.; Dixit, G.P.; Thudi, M.; Gaur, P.M.; Chaturvedi, S.K.; Fikre, A.; Hamwieh, A.; Kumar, S.; et al. Integrating genomics for chickpea improvement: Achievements and opportunities. Theor. Appl. Genet. 2020, 133, 1703–1720. [Google Scholar] [CrossRef]
- De La Fuente, M.; Borrajo, A.; Bermúdez, J.; Lores, M.; Alonso, J.; López, M.; Santalla, M.; De Ron, A.M.; Zapata, C.; Alvarez, G. 2-DE-based proteomic analysis of common bean (Phaseolus vulgaris L.) seeds. J. Proteom. 2011, 74, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Ialicicco, M.; Viscosi, V.; Arena, S.; Scaloni, A.; Trupiano, D.; Rocco, M.; Chiatante, D.; Scippa, G.S. Lens culinaris Medik. seed proteome: Analysis to identify landrace markers. Plant Sci. 2012, 197, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Vessal, S.; Siddique, K.H.M.; Atkins, C.A. Comparative proteomic analysis of genotypic variation in germination and early seedling growth of chickpea under suboptimal soil-water conditions. J. Proteome Res. 2012, 11, 4289–4307. [Google Scholar] [CrossRef] [PubMed]
- Cardador-Martínez, A.; Loarca-Piña, G.; Oomah, B.D. Antioxidant activity in common beans (Phaseolus vulgaris L.). J. Agric. Food Chem. 2002, 50, 6975–6980. [Google Scholar] [CrossRef]
- Prior, R.L.; Hoang, H.; Gu, L.; Wu, X.; Bacchiocca, M.; Howard, L.; Hampsch-Woodill, M.; Huang, D.; Ou, B.; Jacob, R. Assays for hydrophilic and lipophilic antioxidant capacity (oxygen radical absorbance capacity (ORACFL)) of plasma and other biological and food samples. J. Agric. Food Chem. 2003, 51, 3273–3279. [Google Scholar] [CrossRef]
- Monribot-Villanueva, J.L.; Elizalde-Contreras, J.M.; Aluja, M.; Segura-Cabrera, A.; Birke, A.; Guerrero-Analco, J.A.; Ruiz-May, E. Endorsing and extending the repertory of nutraceutical and antioxidant sources in mangoes during postharvest shelf life. Food Chem. 2019, 285, 119–129. [Google Scholar] [CrossRef]
- Monribot-Villanueva, J.L.; Altúzar-Molina, A.; Aluja, M.; Zamora-Briseño, J.A.; Elizalde-Contreras, J.M.; Bautista-Valle, M.V.; Arellano de los Santos, J.; Sánchez-Martínez, D.E.; Rivera-Reséndiz, F.J.; Vázquez-Rosas-Landa, M.; et al. Integrating proteomics and metabolomics approaches to elucidate the ripening process in white Psidium guajava. Food Chem. 2022, 367, 130656. [Google Scholar] [CrossRef]
- Juárez-trujillo, N.; Monribot-villanueva, J.L.; Jiménez-fernández, V.M.; Suárez-montaño, R.; Aguilar-colorado, Á.S.; Guerrero-analco, J.A.; Jiménez, M. Phytochemical characterization of Izote (Yucca elephantipes ) flowers. J. Appl. Bot. Food Qual. 2018, 210, 202–210. [Google Scholar]
- Camacho-vázquez, C.; Ruiz-may, E.; Guerrero-analco, J.A.; Elizalde-contreras, J.M.; Enciso-ortiz, E.J.; Rosas-saito, G.; López-sánchez, L.; Kiel-martínez, A.L.; Bonilla-landa, I.; Monribot-villanueva, J.L.; et al. Filling gaps in our knowledge on the cuticle of mangoes (Mangifera indica) by analyzing six fruit cultivars: Architecture/structure, postharvest physiology and possible resistance to fruit fly (Tephritidae) attack. Postharvest Biol. Technol. 2019, 148, 83–96. [Google Scholar] [CrossRef]
- Pang, Z.; Zhou, G.; Ewald, J.; Chang, L.; Hacariz, O.; Basu, N.; Xia, J. Using MetaboAnalyst 5.0 for LC–HRMS spectra processing, multi-omics integration and covariate adjustment of global metabolomics data. Nat. Prot. 2022, 17, 1735–1761. [Google Scholar] [CrossRef]
- Takai, T.; Fukuta, Y.; Shiraiwa, T.; Horie, T. Time-related mapping of quantitative trait loci controlling grain-filling in rice (Oryza sativa L.). J. Exp. Bot. 2005, 56, 2107–2118. [Google Scholar] [CrossRef]
- Nitride, C.; Vegarud, G.E.; Comi, I.; Devold, T.G.; Røseth, A.; Marti, A.; Iametti, S.; Mamone, G.; Picariello, G.; Alfieri, F.; et al. Effect of sprouting on the proteome of chickpea flour and on its digestibility by ex vivo gastro-duodenal digestion complemented with jejunal brush border membrane enzymes. Food Res. Int. 2022, 154, 111012. [Google Scholar] [CrossRef]
- Zhang, S.; Ghatak, A.; Bazargani, M.M.; Bajaj, P.; Varshney, R.K.; Chaturvedi, P.; Jiang, D.; Weckwerth, W. Spatial distribution of proteins and metabolites in developing wheat grain and their differential regulatory response during the grain filling process. Plant J. 2021, 107, 669–687. [Google Scholar] [CrossRef]
- Shibata, M.; Hirotsuka, M.; Mizutani, Y.; Takahashi, H.; Kawada, T.; Matsumiya, K.; Hayashi, Y.; Matsumura, Y. Diversity of γ- glutamyl peptides and oligosaccharides, the “kokumi” taste enhancers, in seeds from soybean mini core collections. Biosci. Biotechnol. Biochem. 2018, 82, 507–514. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, J.; Liu, K.; Wang, Z.; Liu, L. Abscisic acid and ethylene interact in wheat grains in response to soil drying during grain filling. New Phytol. 2006, 171, 293–303. [Google Scholar] [CrossRef]
- Wu, C.Y.; Trieu, A.; Radhakrishnan, P.; Kwok, S.F.; Harris, S.; Zhang, K.; Wang, J.; Wan, J.; Zhai, H.; Takatsuto, S.; et al. Brassinosteroids regulate grain filling in rice. Plant Cell 2008, 20, 2130–2145. [Google Scholar] [CrossRef] [Green Version]
- Cui, W.; Song, Q.; Zuo, B.; Han, Q.; Jia, Z. Effects of gibberellin (GA4+7) in grain filling, hormonal behavior, and antioxidants in high-density maize (Zea mays L.). Plants 2020, 9, 978. [Google Scholar] [CrossRef]
- Shi, C.L.; Dong, N.Q.; Guo, T.; Ye, W.W.; Shan, J.X.; Lin, H.X. A quantitative trait locus GW6 controls rice grain size and yield through the gibberellin pathway. Plant J. 2020, 103, 1174–1188. [Google Scholar] [CrossRef]
- Abu-Zaitoon, Y.M.; Bennett, K.; Normanly, J.; Nonhebel, H.M. A large increase in IAA during development of rice grains correlates with the expression of tryptophan aminotransferase OsTAR1 and a grain-specific YUCCA. Physiol. Plant. 2012, 146, 487–499. [Google Scholar] [CrossRef]
- Liu, L.; Tong, H.; Xiao, Y.; Che, R.; Xu, F.; Hu, B.; Liang, C.; Chu, J.; Li, J.; Chu, C. Activation of Big Grain1 significantly improves grain size by regulating auxin transport in rice. Proc. Natl. Acad. Sci. USA 2015, 112, 11102–11107. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, M.; Liang, J. RGB1 regulates grain development and starchaccumulation through its effect on OsYUC11-nediated auxin biosynthesis in rice endosperm cells. Front. Plant Sci. 2021, 12, 224. [Google Scholar]
- Singh, N.; Dash, S.; Khan, Y.J. Survival of chickpea, sesame, niger, castor and safflower seeds stored at low and ultra low moisture contents for 16–18 years. Seed Sci. Technol. 2016, 44, 542–555. [Google Scholar] [CrossRef]
- Börner, A.; Khlestkina, E.K. Ex-situ genebanks—Seed treasure chambers for the future. Russ. J. Genet. 2019, 55, 1299–1305. [Google Scholar] [CrossRef]
- Xu, M.; Jin, Z.; Peckrul, A.; Chen, B. Pulse seed germination improves antioxidative activity of phenolic compounds in stripped soybean oil-in-water emulsions. Food Chem. 2018, 250, 140–147. [Google Scholar] [CrossRef]
- Xu, M.; Jin, Z.; Ohm, J.B.; Schwarz, P.; Rao, J.; Chen, B. Improvement of the antioxidative activity of soluble phenolic compounds in chickpea by germination. J. Agric. Food Chem. 2018, 66, 6179–6187. [Google Scholar] [CrossRef]
- Sang, S.; Chu, Y.F. Whole grain oats, more than just a fiber: Role of unique phytochemicals. Mol. Nutr. Food Res. 2017, 61, 1600715. [Google Scholar] [CrossRef]
- Boz, H. p-Coumaric acid in cereals: Presence, antioxidant and antimicrobial effects. Int. J. Food Sci. Technol. 2015, 50, 2323–2328. [Google Scholar] [CrossRef]
- Tena, N.; Martín, J.; Asuero, A.G. State of the art of anthocyanins: Antioxidant activity, sources, bioavailability, and therapeutic effect in human health. Antioxidants 2020, 9, 451. [Google Scholar] [CrossRef]
- Stephens, B.R.; Bomser, J.A. Glycitein in health. In Isoflavones: Chemistry, Analysis, Function and Effects; The Royal Society of Chemistry: London, UK, 2012; pp. 465–479. [Google Scholar]
- Yi, J.; Xia, W.; Wu, J.; Yuan, L.; Wu, J.; Tu, D.; Fang, J.; Tan, Z. Betulinic acid prevents alcohol-induced liver damage by improving the antioxidant system in mice. J. Vet. Sci. 2014, 15, 141–148. [Google Scholar] [CrossRef]
- Do Nascimento, P.G.G.; Lemos, T.L.G.; Bizerra, A.M.C.; Arriaga, A.M.C.; Ferreira, D.A.; Santiago, G.M.P.; Braz-Filho, R.; Costa, J.G.M. Antibacterial and antioxidant activities of ursolic acid and derivatives. Molecules 2014, 19, 1317–1327. [Google Scholar] [CrossRef]
- Mengoni, F.; Lichtner, M.; Battinelli, L.; Marzi, M.; Mastroianni, C.M.; Vullo, V.; Mazzanti, G. In vitro anti-HIV activity of oleanolic acid on infected human mononuclear cells. Planta Med. 2002, 68, 111–114. [Google Scholar] [CrossRef]
- Gurfinkel, D.M.; Rao, A.V. Soyasaponins: The relationship between chemical structure and colon anticarcinogenic activity. Nutr. Cancer 2009, 47, 24–33. [Google Scholar] [CrossRef]
- Šamec, D.; Karalija, E.; Šola, I.; Vujčić Bok, V.; Salopek-Sondi, B. The role of polyphenols in abiotic stress response: The influence of molecular structure. Plants 2021, 10, 118. [Google Scholar] [CrossRef]
- Dey, N.; Bhattacharjee, S. Accumulation of polyphenolic compounds and osmolytes under dehydration stress and their implication in redox regulation in four indigenous aromatic rice cultivars. Rice Sci. 2020, 27, 329–344. [Google Scholar] [CrossRef]
- Kiani, R.; Arzani, A.; Mirmohammady Maibody, S.A.M. Polyphenols, flavonoids, and antioxidant activity involved in salt tolerance in wheat, Aegilops cylindrica and their amphidiploids. Front. Plant Sci. 2021, 12, 493. [Google Scholar] [CrossRef]
- Cory, H.; Passarelli, S.; Szeto, J.; Tamez, M.; Mattei, J. The role of polyphenols in human health and food systems: A mini-review. Front. Nutr. 2018, 5, 87. [Google Scholar] [CrossRef]
- Tian, S.; Sun, Y.; Chen, Z.; Yang, Y.; Wang, Y.; Trabelsi, N. Functional properties of polyphenols in grains and effects of physicochemical processing on polyphenols. J. Food Qual. 2019, 2019, 2793973. [Google Scholar] [CrossRef] [Green Version]
- Vollmannová, A.; Margitanová, E.; Tóth, T.; Timoracká, M.; Urminská, D.; Bojňanská, T.; Čičová, I. Cultivar influence on total polyphenol and rutin contents and total antioxidant capacity in buckwheat, amaranth, and quinoa seeds. Czech J. Food Sci. 2013, 31, 589–595. [Google Scholar] [CrossRef]
- Song, J.; He, Y.; Luo, C.; Feng, B.; Ran, F.; Xu, H.; Ci, Z.; Xu, R.; Han, L.; Zhang, D. New progress in the pharmacology of protocatechuic acid: A compound ingested in daily foods and herbs frequently and heavily. Pharmacol. Res. 2020, 161, 105109. [Google Scholar] [CrossRef]
- Wang, J.; Fang, X.; Ge, L.; Cao, F.; Zhao, L.; Wang, Z.; Xiao, W. Antitumor, antioxidant and anti-inflammatory activities of kaempferol and its corresponding glycosides and the enzymatic preparation of kaempferol. PLoS ONE 2018, 13, e0197563. [Google Scholar] [CrossRef]
- Pei, K.; Ou, J.; Huang, J.; Ou, S. p-Coumaric acid and its conjugates: Dietary sources, pharmacokinetic properties and biological activities. J. Sci. Food Agric. 2016, 96, 2952–2962. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Xi, R.; Zhang, Z.; Li, W.; Liu, Y.; Jin, F.; Wang, X. 4-Hydroxyphenylacetic acid attenuated inflammation and edema via suppressing HIF-1α in seawater aspiration-induced lung injury in rats. Int. J. Mol. Sci. 2014, 15, 12861–12884. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Jiang, Z.; Chang, X.; Xue, H.; Yahefu, W.; Zhang, X. 4-hydroxyphenylacetic acid prevents acute APAP-induced liver injury by increasing phase II and antioxidant enzymes in mice. Front. Pharmacol. 2018, 9, 653. [Google Scholar] [CrossRef] [PubMed]
- Peungvicha, P.; Temsiririrkkul, R.; Prasain, J.K.; Tezuka, Y.; Kadota, S.; Thirawarapan, S.S.; Watanabe, H. 4-Hydroxybenzoic acid: A hypoglycemic constituent of aqueous extract of Pandanus odorus root. J. Ethnopharmacol. 1998, 62, 79–84. [Google Scholar] [CrossRef]
- Chong, K.P.; Rossall, S.; Atong, M. In vitro antimicrobial activity and fungitoxicity of syringic acid, caffeic acid and 4-hydroxybenzoic acid against Ganoderma Boninense. J. Agric. Sci. 2009, 1, 15. [Google Scholar] [CrossRef]
- Abedi, F.; Razavi, B.M.; Hosseinzadeh, H. A review on gentisic acid as a plant derived phenolic acid and metabolite of aspirin: Comprehensive pharmacology, toxicology, and some pharmaceutical aspects. Phytother. Res. 2020, 34, 729–741. [Google Scholar] [CrossRef]
- Bar-El Dadon, S.; Abbo, S.; Reifen, R. Leveraging traditional crops for better nutrition and health—The case of chickpea. Trends Food Sci. Technol. 2017, 64, 39–47. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RT | m/z | Compound | Adduct | Adduct m/z * | Mass Error | Chemical Group |
|---|---|---|---|---|---|---|
| Carbohydrates | ||||||
| 0.44 | 245.0432 | Sedoheptulose | [M + Cl]− | 245.0434 | −0.8 | Ketoheptose |
| 0.47 | 705.1849 | Stachyose | [M + K]+ | 705.1855 | −0.9 | Tetrasaccharide |
| 0.50 | 527.1593 | Dextrin | [M + Na]+ | 527.1583 | 1.9 | Polysaccharide |
| 1.45 | 451.1423 | Xylopyranosyl-rhamnopyranosyl-arabinose | [M + Na]+ | 451.1422 | 0.2 | Oligosaccharide |
| 1.82 | 383.1566 | Tri-methyl-mannobiose | [M − H]− | 383.1559 | 1.8 | Disaccharide derivative |
| 2.71 | 419.1524 | Methylbutanoyl-apiosylglucose | [M + Na]+ | 419.1524 | 0.0 | O-acyl carbohydrate |
| 3.77 | 435.2243 | Ethyl cellulose | [M − H2O − H]− | 435.2230 | 3.0 | Polysaccharide |
| Nitrogen-containing Compounds | ||||||
| 0.42 | 104.1078 | Choline | [M + H]+ | 104.1075 | 2.9 | Phospholipid precursor |
| 1.14 | 134.0472 | Adenine | [M − H]− | 134.0467 | 3.7 | Aminopurine |
| 2.65 | 247.1441 | Feruloylputrescine | [M − H2O + H]+ | 247.1447 | −2.4 | Polyamine derivative |
| 2.79 | 186.0917 | Indole-butyric acid | [M − H2O + H]+ | 186.0919 | −1.1 | Auxin |
| 3.36 | 250.0726 | Feruloylglycine | [M − H]− | 250.0721 | 2.0 | Amino acid derivative |
| 7.03 | 268.0369 | Indoleglycerol phosphate | [M − H2O − H]- | 268.0375 | −2.2 | Amino acid derivative |
| Phenolics | ||||||
| 0.45 | 451.1239 | Catechin glucoside | [M − H]− | 451.1246 | −1.6 | Flavanol glucoside |
| 0.54 | 601.1380 | Peonidin | [2M − H]− | 601.1362 | 3.0 | O-Methylated anthocyanidin |
| 1.46 | 331.0681 | Galloyl glucose | [M − H]− | 331.0671 | 3.0 | Gallic acid glucoside |
| 1.71 | 165.0551 | Coumaric acid | [M + H]+ | 165.0546 | 3.0 | Hydroxycinnamic acid |
| 7.04 | 447.1292 | Glycitin | [M + H]+ | 447.1286 | 1.3 | Glycosyloxyisoflavone |
| 7.70 | 555.1107 | Malonylglycitin | [M + Na]+ | 555.1109 | −0.4 | Glycosyloxyisoflavone |
| 8.65 | 533.1292 | Malvidin-acetylglucoside | [M − H]− | 533.1306 | −2.6 | Anthocyanin derivative |
| 9.69 | 285.076 | Glycitein | [M + H]+ | 285.0757 | 1.1 | Methoxyisoflavone |
| Terpenoids | ||||||
| 7.95 | 957.505 | Soyasaponin V | [M − H]− | 957.5065 | −1.6 | Triterpenoid saponin |
| 10.26 | 925.5156 | Saponin D | [M − H]− | 925.5166 | −1.1 | Triterpenoid saponin |
| Lipids | ||||||
| 11.53 | 316.2849 | Dehydrophytosphingosine | [M + H]+ | 316.2846 | 0.9 | Sphingolipid |
| 12.38 | 315.0478 | Glycerophosphoinositol | [M − H2O − H]− | 315.0481 | −1.0 | Phospholipid derivative |
| 13.40 | 295.2272 | Epoxy-hydroxystearate | [M − H2O − H]− | 295.2273 | −0.3 | Epoxy fatty acid |
| 13.98 | 255.2325 | Hexadecanoic acid | [M − H]− | 255.2324 | 0.4 | Fatty acid |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quiroz-Figueroa, F.R.; Monribot-Villanueva, J.L.; Bojórquez-Velázquez, E.; Gómez-Peraza, R.L.; Elizalde-Contreras, J.M.; Bautista-Valle, M.V.; Guerrero-Analco, J.A.; Valdez-Morales, M.; Singh, R.K.; Ruiz-May, E. Proteometabolomic Analysis Reveals Molecular Features Associated with Grain Size and Antioxidant Properties amongst Chickpea (Cicer arietinum L.) Seeds Genotypes. Antioxidants 2022, 11, 1850. https://doi.org/10.3390/antiox11101850
Quiroz-Figueroa FR, Monribot-Villanueva JL, Bojórquez-Velázquez E, Gómez-Peraza RL, Elizalde-Contreras JM, Bautista-Valle MV, Guerrero-Analco JA, Valdez-Morales M, Singh RK, Ruiz-May E. Proteometabolomic Analysis Reveals Molecular Features Associated with Grain Size and Antioxidant Properties amongst Chickpea (Cicer arietinum L.) Seeds Genotypes. Antioxidants. 2022; 11(10):1850. https://doi.org/10.3390/antiox11101850
Chicago/Turabian StyleQuiroz-Figueroa, Francisco R., Juan L. Monribot-Villanueva, Esaú Bojórquez-Velázquez, Rosa L. Gómez-Peraza, José M. Elizalde-Contreras, Mirna V. Bautista-Valle, José A. Guerrero-Analco, Maribel Valdez-Morales, Rupesh Kumar Singh, and Eliel Ruiz-May. 2022. "Proteometabolomic Analysis Reveals Molecular Features Associated with Grain Size and Antioxidant Properties amongst Chickpea (Cicer arietinum L.) Seeds Genotypes" Antioxidants 11, no. 10: 1850. https://doi.org/10.3390/antiox11101850