1. Introduction
The Cued Speech (CS) system is a visual mode of communication developed to facilitate access to spoken language for individuals with hearing impairments (HI). The CS code is composed of manual gestures that have two components: hand configuration, which is assigned to consonants, and position around the face, which is assigned to vowels. Each hand configuration and position around the face code a group of phonemes. Each phoneme in the group is visually contrastive and can be readily distinguished by lipreading. For instance, bilabial phonemes (/p/, /b/, and /m/) are coded by three different CS cues, and the manual cue which codes for the phoneme /p/ is also assigned for /d/ and /ʒ/, which is easily distinguished by lipreading. Importantly, when manual gestures are presented alone, speech perception remains ambiguous. However, when associated with lipreading information, a unique and precise phoneme can be perceived. Therefore, a CS cue is composed of two components: manual gestures (hand configuration and position around the face) and lipreading information [
1]. In the French version, consonants are coded by eight hand configurations and vowels by five positions around the speaker’s face. The ability to combine CS manual gestures and lipreading information into a specific phoneme is acquired by implicit learning throughout the linguistic experience and consistent and repetitive exposition of the system [
2,
3]. Previous research suggests that children who are exposed to CS before the age of two, and who receive continued exposure to the system at home and at school, can learn to integrate CS cues with lipreading effortlessly. As a result, they develop accurate phonological representations of speech, which support their language acquisition and communication skills [
3,
4,
5].
An intriguing research question in the domain of speech perception is how CS manual gestures interact with lipreading information in HI individuals. To address this question, Alegria and Lechat [
3] investigated the effect of the congruent and incongruent presentation of CS gestures and lipreading information (without sound) on phoneme identification in HI children who were exposed to CS at home and at school. The rationale was to evaluate how CS gestures and lipreading information combine to form unitary percepts as a function of the weight attributed to each source of information. The results showed that when CS gestures were presented congruently with lipreading information, the accuracy of phoneme identification increased significantly. However, when the CS gestures were presented incongruently with lipreading information, children’s performance declined compared to the condition in which they relied solely on lipreading. Furthermore, the analysis of errors committed in incongruent conditions revealed that phoneme identification was not random, but rather reflected a compromise between lipreading and CS gesture information. For instance, when lipread information of the phoneme /v/ was being presented with an incongruent CS cue representing the phoneme group /p/, d/, and /ʒ/, participants consistently reported perceiving the phoneme /d/. This suggests that CS gesture has a significant weight on the final percept, but it is not the only source of information used by the children. Lipread information was likely used as an inference to constrain the available choices for the final percept. The authors considered it plausible that children’s perceptual system proceeded with the reasoning that “It’s likely to be a /d/ since if it were a /p/ or a /ʒ/, the lips would show it” [
3]. Interestingly, the authors proposed that a similar interpretation can be used to understand the McGurk effect [
6]. In the classical McGurk situation, participants systematically report perceiving /da/ when presented with incongruent auditory /ba/ and visual /ga/. This parallel can be explained by the participants taking lipread information into consideration as an inference of upcoming acoustic signals. The fact that participants’ response was more likely to be /da/ than /ba/ or /ga/ could be explained by the participants’ operating on the assumption that the bilabial viseme of /ba/ should be unambiguously seen by lipreading. This illusory percept indicates a compromise between lipreading and auditory perception, where the lipread information is matched against the auditory information that corresponds to a bilabial phoneme/ba/, and to solve the conflict, the perceptual system adopts a compromise between both sources of information. The compromise between lipread input and auditory perception in the McGurk effect has been taken as evidence that audio and visual information automatically interact in speech processing. Building on these findings, a follow-up study used the McGurk paradigm to investigate whether CS cues interact with auditory speech information in HI adults who were exposed to CS at young ages and were regular users of the system [
7]. First, participants were presented with classical McGurk stimuli (auditory /pa/, lipreading /ka/) to verify whether or not they were sensitive to the expected effect (illusory perception of /ta/), similar to typically hearing individuals (TH). Second, CS gestures were associated with McGurk stimuli in three conditions: CS gestures congruent to lipreading information (i.e., /ka/), CS gestures congruent to the auditory input (i.e., /pa/), and CS gestures congruent to the expected illusional percept (i.e., /ta/), thus incongruent to auditory or to lipreading information. In the classical McGurk condition, participants’ responses were more likely to be a /ta/, indicating that HI individuals who are CS users are sensitive to the McGurk effect, similar to the TH group. However, when the CS manual gestures were congruent to either lipreading or the auditory input, the percentage of responses reporting /ta/ significantly decreased. In this condition, the perception of the CS gesture strengthened the incoherence between lips and sounds, and both labial and audio information were not bound. Contrastingly, when the manual gesture corresponded to the illusory percept (/ta/) and was incongruent with either lipreading or the auditory input, the percentage of responses reporting /ta/ was restored. Intriguingly, this result could suggest that the perception of the manual gesture increased the McGurk effect and facilitated the binding of audio and visual information. However, it is important to consider that CS manual gestures, being salient visual inputs, have the potential to attract or orient attention to the hands. Furthermore, for experienced CS users, manual gestures also convey phonological information that might influence phonetic decision-making. Therefore, based on the available data from this study, it is challenging to determine whether the observed increase in the proportion of responses reporting/ta/is primarily attributed to visual speech decoding or to an augmented McGurk effect. While this behavioral study [
7] provides valuable insights, it does not definitively establish a direct interaction between the perception of CS gestures and audiovisual (AV) speech processing. Further research is necessary to investigate how the perception of CS gestures interacts with natural speech cues in AV speech processing. From a theoretical perspective, this research topic holds particular significance due to the limited number of studies that have specifically investigated the interaction between gestures conveying phonological information and speech processing [
8]. While there is a growing body of literature on speech and gesture interaction, most studies have predominantly focused on semantic [
9,
10], iconic [
11], or prosodic [
12,
13] gestures. Consequently, there is a noticeable gap in the literature on AV integration examining the effect of manual gestures conveying phonological information on automatic speech processing. From a clinical perspective, the interest in this research topic is driven by the fact that multimodal approaches in auditory rehabilitation hold great potential for compensating for challenges in speech perception, particularly in noisy listening conditions and for individuals with hearing impairments. By investigating the interaction between CS manual gestures and natural speech cues, we can gain insights into the potential role of this multimodal approach in auditory rehabilitation strategies. Understanding how CS perception influences auditory processing and the temporal dynamics of AV integration can inform the development of effective rehabilitation interventions.
In ecological conditions of speech perception, such as face-to-face communication, audio and visual information are related by a high level of cross-predictability due to their common underlying motor cause. Interestingly, the work from Kim and Davis [
13] demonstrated that coupling a talker’s face with speech masked in noise enhances participants’ ability to detect the time interval during which a spoken sentence is presented, compared to when auditory speech was presented with a fixed face. Importantly, the authors also showed that the AV speech detection advantage was lost when the temporal correlation between auditory and video components was distorted. The observed AV advantage might be related to general (low-level) properties of AV perception of objects, and is not specific to speech. In multimodal speech perception, visual feature analysis of mouth articulatory movements helps to predict the content of auditory information, facilitating speech decoding. In an influential study, Klucharev et al. [
14] manipulated the congruence between audio and video streams to differentiate neural responses that are speech-specific from general properties of AV perception. Participants were exposed to vowels (/a/, /o/, /i/, and /y/) in four conditions: auditory-only, visual-only, and two audiovisual conditions (congruent and incongruent). Results showed that the presentation of bimodal AV stimuli resulted in an amplitude attenuation of the first negative deflection (N1) of ERPs to bimodal conditions compared to unimodal conditions. Importantly, the observed amplitude suppression was present regardless of the congruence between auditory and visual stimuli. Additionally, the authors also observed a congruence-dependent modulatory effect at a later stage of speech processing. The presentation of phonetically congruent AV stimuli elicited an amplitude attenuation of the second positive deflection (P2) of the ERP responses. This latter modulatory effect, elicited by the presentation of phonetically congruent inputs, was interpreted as a neural marker of the fusion between visual and acoustic units into an AV percept. Subsequently, the study from van Wassenhove et al. [
15] utilized an ERP paradigm in which participants were exposed to speech syllable (/pa/, /ta/, and /ka/) in unimodal (audio-only or visual-only) conditions and in bimodal AV conditions. The authors also manipulated the phonetic congruence between the audio and visual streams by creating McGurk stimuli (audio /pa/ and visual /ka/). The results from the bimodal AV conditions showed a reduction in the amplitudes of both the N1 and P2 ERP components compared to the unimodal conditions. Furthermore, the authors found that the components peaked earlier in the bimodal condition for phonetically congruent stimuli, but not for McGurk stimuli. Interestingly, at N1 and at P2 time windows, the magnitude of latency facilitation varied depending on the phoneme’s identity and the visual salience of its labial image (viseme); the latency facilitation was more pronounced for the bilabial /p/ phoneme, followed by /t/ and finally /k/. By capitalizing on the congruence-dependent latency facilitation and its modulation by visemic visual salience, the authors proposed an analysis-by-synthesis model of AV integration to explain their results within the theoretical framework of predictive coding. The proposed model suggests that bottom-up perceptual processing of visual speech information (pre-phonatory mouth movements) contributes to the creation of an online prediction model about the upcoming auditory signal. The amount and nature of visual information extracted during this period creates an abstract representation of the upcoming phoneme (internal predictor) that is continuously updated up to the point at which the auditory input is recorded. In phonetically congruent contexts, acoustic information matches against the internal predictor derived from visual inputs (visemes), and no prediction errors are computed. Furthermore, visemic input carrying information about the phoneme’s place of articulation would reduce spectral uncertainties in the auditory flow, constraining the auditory process to the second formant. Consequently, the computational costs of auditory processing would decrease, and the efficiency of speech processing would be maximized at the N1 and P2 time windows. These results paved the way for a series of studies on AV speech integration utilizing ERP analysis [
16,
17,
18,
19,
20,
21,
22,
23], which have tested the robustness of N1 and P2 modulatory effects. By employing a meta-analytical approach, the study of Baart et al. [
24] confirmed the robustness of N1 and P2 amplitude attenuation and latency facilitation elicited by AV speech perception. Building upon these findings, the present study aims to investigate the effect of CS perception on the auditory processing of typically hearing participants by examining the temporal course of AV integration between CS gestures and natural speech cues through the use of event-related potentials (ERP) analysis.
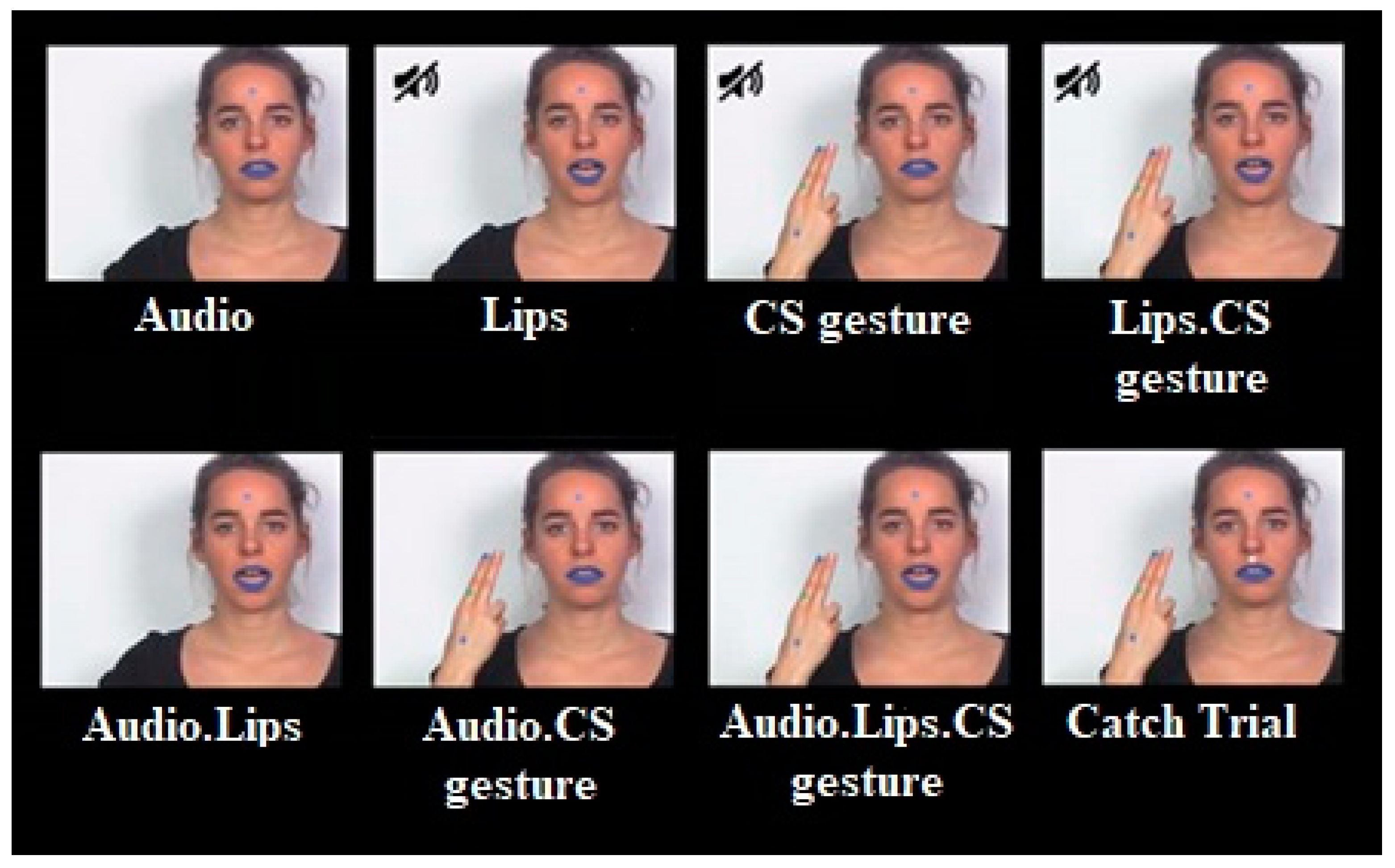
In CS production, manual gestures are performed slightly ahead of the mouth articulatory movement (≈200 ms), and both visual speech cues anticipate speech sounds [
25]. Given the temporal coordination of CS perception, manual gestures likely provide a temporal cue of speech onset initiating speech processing. In the present study, the stimulus set consisted of three speech syllables (/pa/,/ta/,/ka/) presented in both unimodal and bimodal AV conditions. In the conditions involving CS gestures, participants observed one of three possible hand configurations (corresponding to/p/,/t/, or/k/), with the gestures placed in the same position around the face (corresponding to the vowel/a/). Therefore, the natural dynamics of CS perception and the spatial alignment of gestures and lipread information satisfies the spatial-temporal alignment prerequisites for AV integration [
14,
17].
We used an ERP paradigm to investigate whether CS perception modulates auditory processing in individuals who were either naïve towards the system or experienced CS producers. First, we sought to validate the experimental paradigm replicating findings of N1 and P2 amplitude attenuation and latency shortening elicited by the bimodal presentation of lipreading information and auditory information. Second, we aimed to verify whether the perception of CS gestures associated with lipreading information and the auditory input modulates the amplitude and latency of responses. At the N1 time window, we anticipated that the perception of CS gestures would provide a temporal cue of speech onset, preparing listeners for upcoming information and replicating previous findings that demonstrate amplitude attenuation and latency modulation. We expected these effects to occur in both groups thanks to the visual anticipation of CS gestures relative to speech onset. Likewise, at the P2 time window, we expected to observe amplitude attenuation and latency facilitation in both groups thanks to the effect of lipreading on speech decoding. Additionally, we predicted that modulatory effects occurring at the P2 latency range would be exclusively related to the presence of lipreading information in the group of naïve participants. Conversely, in the group of experienced CS producers, we anticipated that effects would be experience-dependent and related to the perception of CS gestures, which would facilitate speech decoding. Finally, our third goal was to verify whether CS gestures interacted with auditory speech processing when presented in isolation from lipreading information. In this condition, we expected to find N1 amplitude attenuation in both groups. These modulatory effects were expected to occur as a consequence of decreased uncertainty in the temporal domain and to be independent of the ability to decode CS gestures into speech information. At a later stage of speech processing, at which phonological decoding takes place, we expected to find different patterns of responses between the groups. Specifically, we expected P2 amplitude attenuation and latency facilitation to occur only in the group of people who are able to decode CS gestures into phonological information. In contrast, in the group of naïve participants, we did not anticipate finding any effects on either the amplitude or the latency of the P2 component. This prediction was based on the premise that CS producers possess the ability to mentally represent CS gestures in association with their corresponding phonological counterparts. When experienced CS producers are exposed to manual gestures, they are hypothesized to create an online prediction model of the upcoming phoneme until the lipreading information is observed. The simultaneous perception of lipreading information and manual gestures would provide perceivers with a strong prediction about the auditory input. Consequently, when the auditory input aligns with the internal prediction, it is anticipated that auditory speech processing will be facilitated.
4. Discussion
The primary goal of the present study was to show how CS information interacts with AV speech cues and modulates speech processing in TH adults who were either experienced CS producers or naïve towards the system. We formulated hypotheses regarding how CS perception may interact at different stages of speech processing. Firstly, we hypothesized that CS gestures would provide a temporal cue for speech onset, thereby decreasing the uncertainty in the temporal uncertainty. As a result, we predicted that both experienced CS producers and CS-naïve participants would show attenuated responses at the N1 latency range, reflecting the influence of CS on early sensory processing, which we expected to be experience-independent. Additionally, we anticipated that the perception of CS gestures would elicit experience-dependent modulatory effects at the P2 time window, indicating its influence on later stages of speech processing. Specifically, we predicted that in the group of experienced CS producers, we would observe smaller and earlier P2 peaks, indicating that the information provided by CS gestures would facilitate speech decoding. Before delving into the results, it is important to acknowledge a potential limitation of the present study, namely the unequal number of participants in each group. Consequently, we were unable to test for statistically significant differences in the pattern of responses between the two groups. Therefore, we have focused our discussion on describing the results observed in each group, without drawing conclusions based on between-group differences.
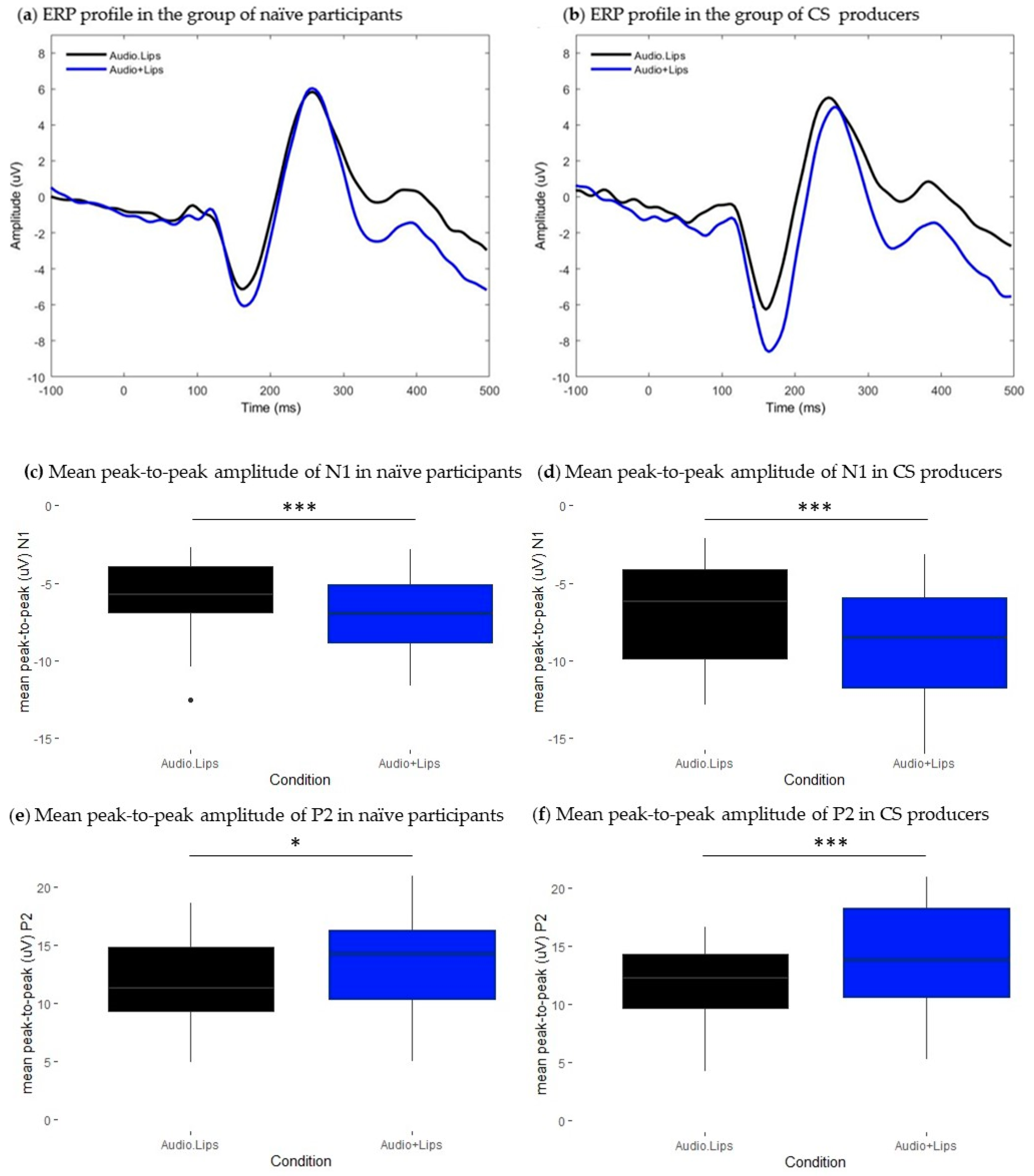
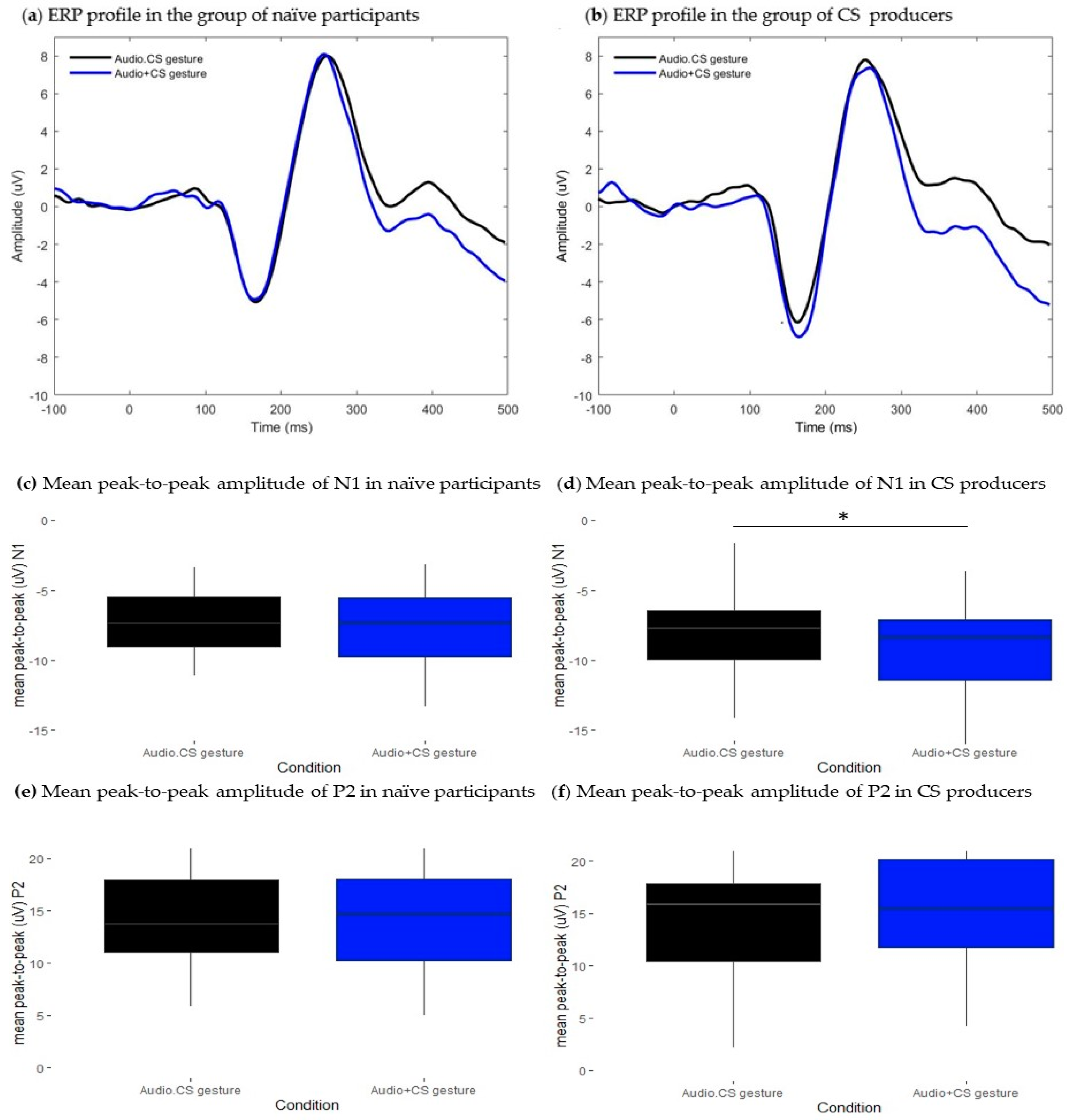
As a preliminary objective, we aimed to validate our ERP paradigm by replicating the findings of influential studies on audiovisual (AV) integration. These studies have provided compelling evidence that AV perception of lipreading information leads to attenuated auditory event-related potentials (ERPs) at N1 and P2 latency ranges [
15,
18,
20,
22]. Furthermore, earlier peak latencies of both N1 and P2 components have been reported in some studies [
15,
22], while others have shown earlier peaks, specifically in the N1 component [
20,
21]. In the initial phase of our study, our key findings align with the existing body of evidence, demonstrating that lipreading information interacts with auditory speech cues by attenuating the amplitude of responses at the N1 and P2 latency ranges. However, our results were less consistent with regard to component latencies, as we only replicated N1 latency facilitation uniquely in the group of CS producers and did not observe any effect on P2 latency. In this sense, our results appear to support findings from a previous work that suggested that N1 amplitude attenuation is more robust than N1 latency facilitation [
20]. Moreover, they extend the discussion about the potential effects of experimental factors, such as task instruction and task type, on the pattern of responses at the behavioral level [
29] and at the neurophysiological level [
15]. One influential finding from van Wassenhove et al. [
15] was that latency facilitation varied in function of the degree to which the visual signal predicts auditory targets, known as articulator-specific latency facilitation. In our study, participants were not specifically instructed to identify phonemes, but rather to detect audio and visual catch trials. Interestingly, Stekelenburg and Vroomen [
20], who employed a similar task, did not observe N1 latency facilitation. These results suggest that specific task demands might potentially influence the timing of responses. Furthermore, another implication of this task choice is that, on data analysis, ERP data from all syllables are pooled together, and the averaging process could smooth differences in peak latencies undermining effects on components latencies. In light of the aforementioned, we consider that the less robust effect on the latency domain could be related to the type of task used and to our data processing.
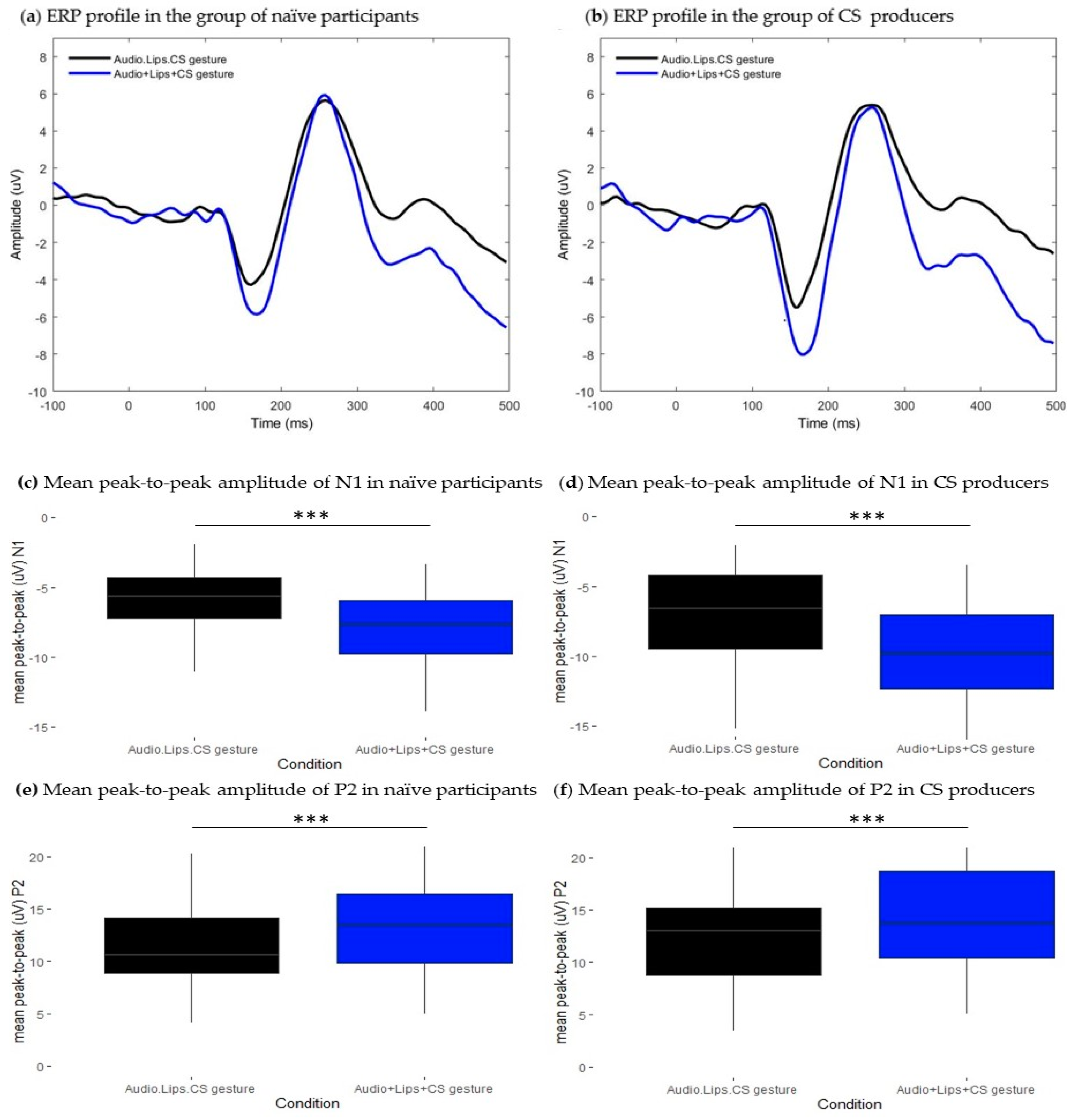
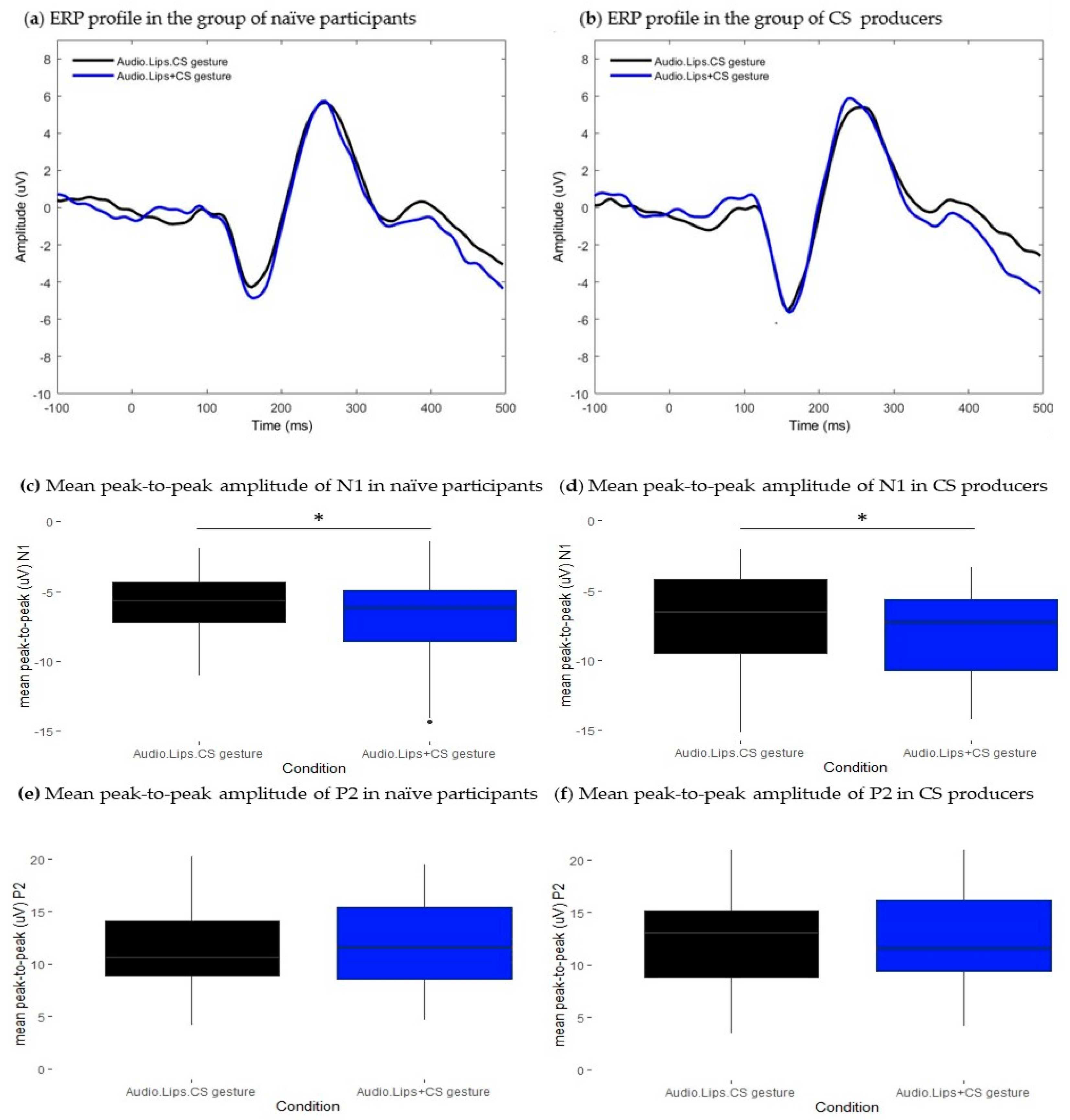
When CS gestures were associated with both the lipread information and the auditory input, the amplitudes of both N1 and P2 components were attenuated in both groups. In the group of experienced CS producers, N1 amplitude attenuation was accompanied by latency facilitation. Taken together, these results could suggest that adding CS gestures to natural AV speech cues elicited a similar pattern of responses as that observed in the AV lipreading condition. To confirm this hypothesis, we compared modulatory effects elicited by the AV presentation of lipreading information combined with CS gestures to those obtained to the estimated sum of responses obtained in the AV lipreading condition plus responses in the CS gestures condition. In both groups, the perception of CS gestures further attenuated the amplitude of the N1 component relative to bimodal AV lipreading perception. Given that the effect occurred independently of participants’ knowledge of CS, a plausible interpretation of the functional meaning of N1 amplitude attenuation could be that manual gestures provided a temporal cue of speech onset, thereby decreasing the uncertainty in the temporal domain. In this sense, these results could suggest that the perception of CS gestures prepares listeners for upcoming speech information, potentially decreasing the costs of the early stage of processing. However, these findings only partially confirm our hypothesis since we also predicted observing modulatory effects at the P2 time window in the group of CS producers. This result may suggest that having knowledge of CS is not enough to integrate it into an internal representation of speech phonological information, in line with the findings of one behavioral study [
3]. Moreover, results from the fourth section extend this interpretation. In this section, we aimed to test the effect of bimodal AV presentation of CS gestures without lipreading on auditory speech processing. In the group of CS producers, results showed that bimodal presentation only modulated the amplitude of the N1 component and did not elicit modulatory effects at the P2 time window. In the group of naïve participants, the amplitude of responses was similar between conditions, but the latency of the P2 component was delayed when CS gestures were presented with the auditory input. These results were unexpected since we had anticipated observing N1 latency facilitation and amplitude attenuation in both groups as a consequence of the visual lead provided by gestures related to the sound onset [
17]. Moreover, we were not expecting to observe modulatory effects occurring at the P2 time window in the group of naïve participants. These results indicate that the perception of manual gestures interacts with auditory speech processing in the former group, while in the latter group, it decreases the efficiency at which phonological information is processed. In individuals who are unfamiliar with CS, manual gestures may be too salient to ignore and may carry irrelevant information about the auditory input. Consequently, this could decrease the efficiency of phonological decoding. Conversely, for individuals who are familiar with CS, manual gestures are processed as visual speech cues that interact with the early stages of speech processing but are not fully integrated into multimodal speech perception. This finding would strengthen the hypothesis that AV interaction is not the same as AV integration as proposed by [
30] “At early stages of speech processing, the early latency processes appear to cross-feed low-level information between the individual sensory cortices. This cross-feeding may modify the original input signal and can therefore be described as a multisensory interaction, but not necessarily as multisensory integration.”
While this study successfully validated its aims by demonstrating how the perception of CS information interacts with auditory processing in TH individuals, there were some limitations that must be acknowledged. As mentioned above, the unequal group sample sizes prevented us from drawing firmer conclusions regarding the effect of intensive exposure to CS on AV speech processing. It remained unclear whether group differences could explain why we observed lipreading-induced N1 latency facilitation in the CS producer group but not in the naïve participant group. Moreover, it is worth noting that the age of exposure to CS has been found to be a significant factor influencing the ability to use CS information in speech decoding [
4,
5]. In our study, the majority of participants in the CS producer group (89%) were individuals who were exposed to CS during adulthood and were proficient in translating natural speech into CS code. However, their ability to decode CS information was limited to the identification of isolated phonemes, which met our inclusion criteria. Given the aforementioned considerations, further studies involving a comparable sample size of CS decoders relative to CS interpreters and naïve participants are needed to shed light on this issue.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}