

Screening Children’s Intellectual Disabilities with Phonetic Features, Facial Phenotype and Craniofacial Variability Index

Abstract
:1. Introduction
- Benchmark Dataset: establishing a video data set for automatic screening ID between 6 years old and 17 years old;
- ID measurement based on CVI: By utilizing an open-source face analysis tools, high-quality 3D facial features are extracted, the subject’s facial phenotype is measured with facial features and CVI and finally, an important reference for screening ID is produced;
- ID measurement based on Voice: By extracting multiple phonetic features from the subjects’ audio, the correlation between acoustic features and ID is explored;
- Automatic Screening of ID: machine learning algorithms are utilized to analyze 3D facial features and phonetic features, and an analysis system is established to automatically screen children for ID.
2. Materials and Methods
2.1. Dataset
- Comprehension: questions about social situations or common concepts.
- Similarities: asking how two words are alike/similar.
- Picture Completion: children are shown artwork of common objects with a missing part and asked to identify the missing part by pointing and/or naming.
- Block Design: children put together red-and-white blocks in a pattern according to a displayed model. This is timed, and some of the more difficult puzzles award bonuses for speed.
2.2. Analysis
- (1)
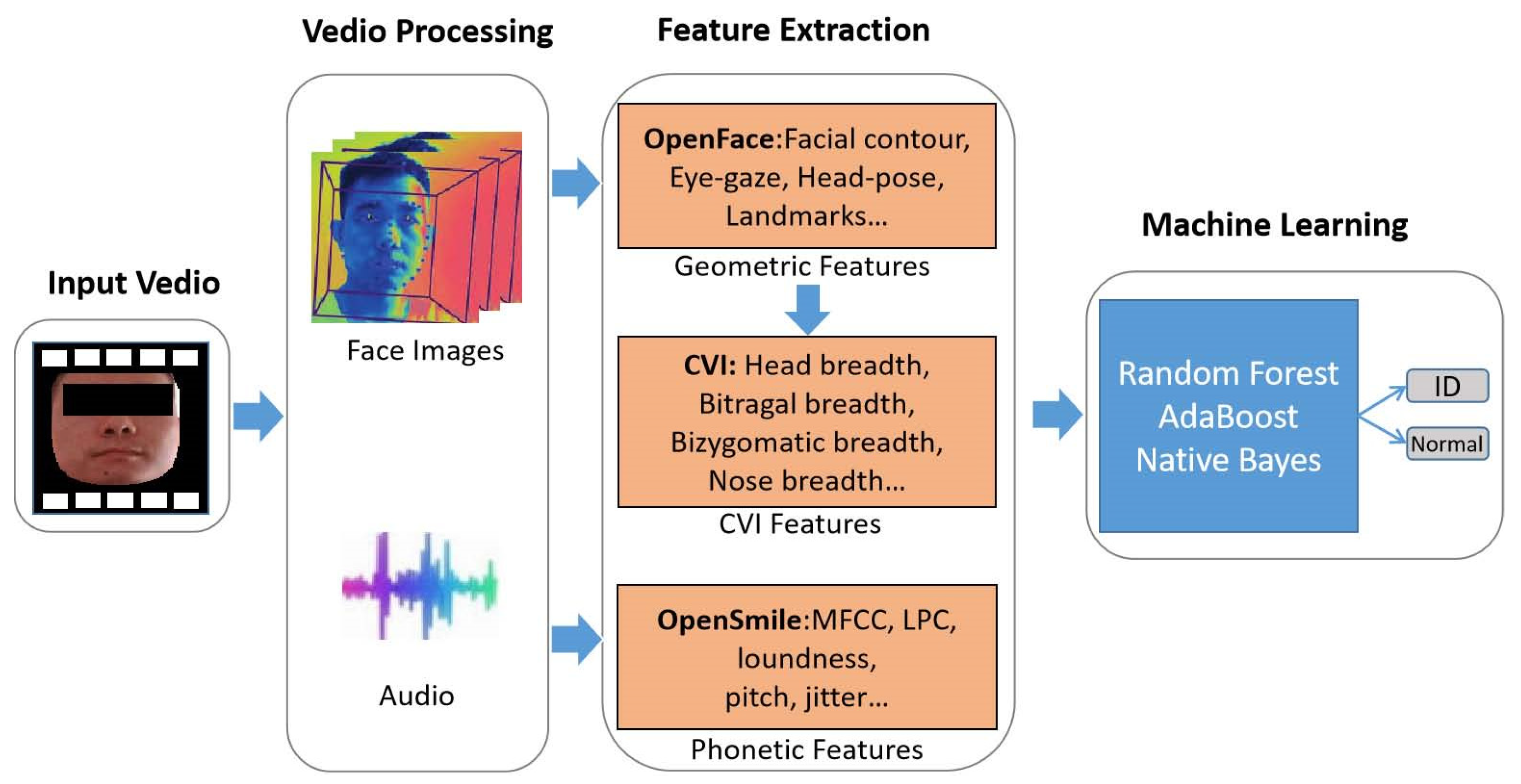
- Architecture: Figure 1 shows the architecture for screening ID. We processed WISC test videos of the subjects and extracted facial images and audio of the subjects. OpenFace and OpenSmile tools were used to extract facial features and phonetic features. Facial geometric features can be further transformed into CVI features. Furthermore, machine learning algorithms were utilized to establish a method for screening ID based on facial features and phonetic features.
- (2)
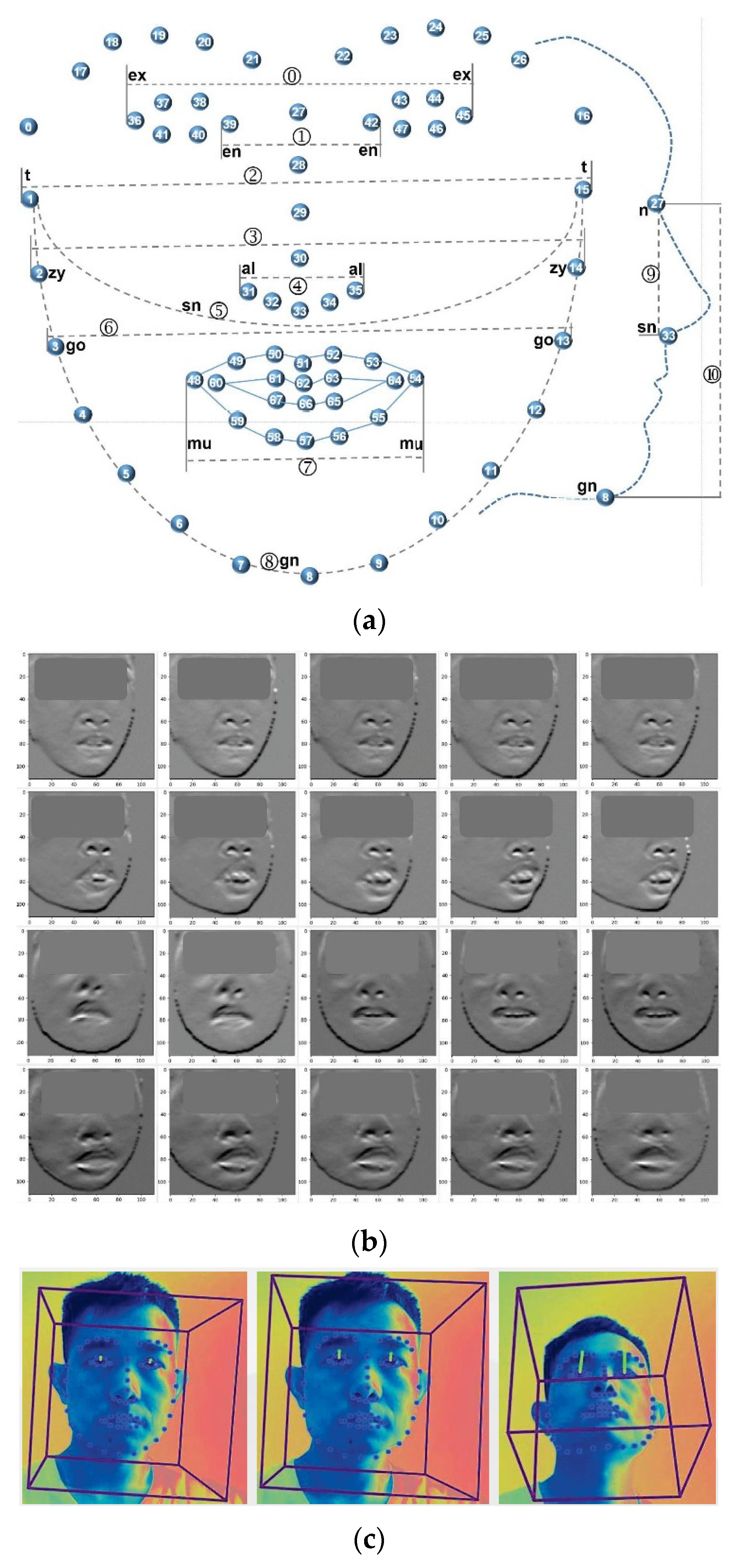
- 3D facial features: Openface2.0 is an open-source facial behavior analysis tool, which can implement facial landmark detection, head pose estimation, facial action unit recognition and eye-gaze estimation. It has been widely used in computer vision, affective computing and human–computer interaction [29]. In this study, Openface2.0 was used to extract 3D facial features from evaluation videos, including facial contour, eye-gaze [30] and head-pose [31]. The facial features of subjects were chosen, including 3D facial landmarks of the head, to analyze the facial phenotype of subjects. Figure 2a shows the 68 facial landmarks, which represent facial contour, eye shape, nose and mouth. Each landmark was represented by an L(x, y, z) to indicate its position in 3D space. Subjects of different ages and genders possessed different scales of faces, which is not conducive to compare different faces directly. Therefore, the tool scaled the subject’s face in 3D space, and the scaling ratio is represented by p_scale; finally, the facial phenotypes of the subjects were compared at same scale. Figure 2b shows the subjects’ 2D faces images detected from videos, and Figure 2c shows the 3D facial landmarks extracted from the 2D face images. Combining the temporal information of neighbor frames, head-pose landmarks were extracted frame by frame from the videos. Neighbor frames contain subjects’ action information, which helps to extract these landmarks more accurately. The head-pose features included three different features (p_rx, p_ry, p_rz), which measures the 3D rotation degree between the head and the IP camera. In order to boost the reliability of our algorithm, we filtered the data according to the condition of confidence ≥0.98 (how confident is the tracker in current landmark detection estimate), |p_rx| ≤ 0.5, |p_ry| ≤ 0.25 and |p_rz| ≤ 0.5. Only those data meeting the above conditions, i.e., 22,602 data frames, were chosen for constructing the algorithm.
- (3)
- Phonetic Features: Delays in speech development are common and may become more obvious when contrasted with the speech development of a sibling [14], which is a guidance for screening ID with phonetic features. Before extracting phonetic features, speech preprocessing is required, which mainly includes voice activity detection, speech enhancement and speaker-based speech segmentation. Voice activity detection can distinguish sound segments from silent segments in audio. The purpose of speech enhancement is to extract features as pure as possible from speech containing noise and improve the quality of speech. Speaker-based speech segmentation was mainly used to extracts the audio of child subjects in order to improve the effectiveness of our algorithms. The speech segmentation based on Bayesian Information Criterion was adopted in this study [32].
- (4)
- Geometric Features and CVI: ID is often caused by gene deficiency syndrome, abnormal pregnancy, abnormal birth, brain injury, etc., which also often lead to abnormal facial phenotypes. There is a certain extent of correlation between ID and facial phenotypes, so the severity of ID for subjects can be determined through the analysis of their facial phenotypes [36]. Facial landmarks can represent the facial phenotype of subjects to some extent, and the analysis results of facial landmarks may be utilized to judge the degree of ID. Using facial landmarks to define facial phenotypic abnormalities accurately is a key factor for the performance of the algorithm. Craniofacial variability index (CVI) has been utilized to describe, characterize, and evaluate craniofacial morphology, and has been widely used in evaluating dysmorphology, diagnosing auxiliary and assessing the effect of craniofacial surgery [37]. First, 16 characteristic measurements of the head and face are obtained, and each measurement is converted into a standardized z-score. The 16 z-scores are utilized to calculate standard deviation (SD, i.e., σz), which is the CVI score. Some studies have shown that the CVI of normal people has an approximate normal distribution, and the CVI of patients with craniofacial syndrome is significantly higher than a normal person; studies also showed that utilizing a subset of 16 characteristic measurements to calculate CVI can obtain similar conclusions [38,39]. Considering all videos collected by medical professionals capture the facial information of subjects, those characteristic measurements of the face were chosen to calculate the CVI, which included 11 geometric features, as shown in Figure 2a and Table 2. Table 2 defines the formulas for calculating the 30 geometric features, and the first 11 features of which were utilized to calculate CVI. The method of calculating σz, i.e., CVI, was given in [38].
- (5)
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schalock, R.; Luckasson, R.A.; Shogren, K.A. The renaming of mental retardation: Understanding the change to the term intellectual disability. Intellect. Dev. Disabil. 2007, 45, 116–124. [Google Scholar] [CrossRef] [PubMed]
- Schaefer, G.; Bodensteiner, J. Evaluation of the child with idiopathic mental retardation. Pediatr. Clin. N. Am. 1992, 39, C929–C943. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention (CDC). Economic costs associated with mental retardation, cerebral palsy, hearing loss, and vision impairment–United States 2003. MMWR Morb. Mortal. Wkly. Rep. 2004, 53, 57–59. [Google Scholar]
- Amor, D. Investigating the child with intellectual disability. J. Paediatr. Child Health 2018, 54, 1154–1158. [Google Scholar] [CrossRef] [PubMed]
- Chiurazzi, P.; Pirozzi, F. Advances in understanding genetic basis of intellectual disability. F1000Research 2016, 5. [Google Scholar] [CrossRef]
- Milani, D.; Ronzoni, L.; Esposito, S. Genetic Advances in Intellectual Disability. J. Pediatr. Genet. 2015, 4, 125–127. [Google Scholar]
- Schuit, M.; Segers, E.; Balkom, H.; van Balkom, H.; Verhoeven, L. Early language intervention for children with intellectual disabilities: A neurocognitive perspective. Res. Dev. Disabil. 2011, 32, 705–712. [Google Scholar] [CrossRef] [PubMed]
- Moeschler, J.; Shevell, M. Comprehensive evaluation of the child with intellectual disability or global developmental delays. Pediatrics 2014, 134, e903–e918. [Google Scholar] [CrossRef] [Green Version]
- WHO. ICD-10 Guide for Mental Retardation; World Health Organization: Geneva, Switzerland, 1996.
- Kulkarni, S.; Seneviratne, N.; Baig, M.S.; Khan, A.H.A. Artificial intelligence in medicine: Where are we now? Acad. Radiol. 2020, 27, 62–70. [Google Scholar] [CrossRef] [Green Version]
- Jin, B.; Cruz, L.; Goncalves, N. Deep Facial Diagnosis: Deep Transfer Learning from Face Recognition to Facial Diagnosis. IEEE Access. 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Torring, P.M.; Larsen, M.J.; Brasch-Andersen, C.; Krogh, L.N.; Kibæk, M.; Laulund, L.; Illum, N.; Dunkhase-Heinl, U.; Wiesener, A.; Popp, B.; et al. Is MED13L-related intellectual disability a recognizable syndrome? Eur. J. Med. Genet. 2019, 62, 129–136. [Google Scholar] [CrossRef] [PubMed]
- Memisevic, H.; Hadzic, S. Speech and language disorders in children with intellectual disability in Bosnia and Herzegovina. Disabil. CBR Incl. Dev. 2013, 24, 92–99. [Google Scholar] [CrossRef]
- Daily, D.K.; Ardinger, H.H.; Holmes, G.E. Identification and evaluation of mental retardation. Am. Fam. Physician 2000, 61, 1059–1067. [Google Scholar] [PubMed]
- Gurovich, Y.; Hanani, Y.; Bar, O.; Nadav, G.; Fleischer, N.; Gelbman, D.; Basel-Salmon, L.; Krawitz, P.M.; Kamphausen, S.B.; Zenker, M.; et al. Identifying facial phenotypes of genetic disorders using deep learning. Nat. Med. 2019, 25, 60–64. [Google Scholar] [CrossRef] [PubMed]
- Valentine, M.; Bihm, D.C.; Wolf, L.; Hoyme, H.E.; May, P.A.; Buckley, D.; Kalberg, W.; Abdul-Rahman, O.A. Computer-Aided Recognition of Facial Attributes for Fetal Alcohol Spectrum Disorders. Pediatrics 2017, 140, e20162028. [Google Scholar] [CrossRef] [PubMed]
- Hadj-Rabia, S.; Schneider, H.; Navarro, E.; Klein, O.; Kirby, N.; Huttner, K.; Wolf, L.; Orin, M.; Wohlfart, S.; Bodemer, C.; et al. Automatic recognition of the XLHED phenotype from facial images. Am. J. Med. Genet. Part A 2018, 173, 2408–2414. [Google Scholar] [CrossRef]
- Hallgrimsson, B.; Aponte, J.D.; Katz, D.C.; Bannister, J.J.; Riccardi, S.L.; Mahasuwan, N.; McInnes, B.L.; Ferrara, T.M.; Lipman, D.M.; Neves, A.B.; et al. Automated syndrome diagnosis by three-dimensional facial imaging. Genet. Med. 2022, 22, 1682–1693. [Google Scholar] [CrossRef]
- Benevides, T.W.; Shore, S.M.; Palmer, K.; Duncan, P.; Plank, A.; Andresen, M.L.; Caplan, R.; Cook, B.; Gassner, D.; Hector, B.L.; et al. Listening to the autistic voice: Mental health priorities to guide research and practice in autism from a stakeholderdriven project. Autism 2020, 24, 822–833. [Google Scholar] [CrossRef]
- Karmele, L.; Unai, M.; Calvo, P.M.; Jiri, M.; Blanca, B.; Nora, B.; Ainara, E.; Milkel, T.; Mirian, E.-T. Advances on Automatic Speech Analysis for Early Detection of Alzheimer Disease: A Non-linear Multi-task Approach. Curr. Alzheimer Res. 2018, 15, 139–148. [Google Scholar]
- Charalambos, T.; Eckerström, M.; Kokkinakis, D. Voice quality and speech fluency distinguish individuals with Mild Cognitive Impairment from Healthy Controls. PLoS ONE 2020, 15, e0236009. [Google Scholar]
- Rejaibi, E.; Komaty, A.; Meriaudeau, F.; Agrebi, S.; Othmani, A. MFCC-based Recurrent Neural Network for Automatic Clinical Depression Recognition and Assessment from Speech. Biomed. Signal Process. Control 2022, 71, 103107. [Google Scholar] [CrossRef]
- He, L.; Cao, C. Automated depression analysis using convolutional neural networks from speech. J. Biomed. Inform. 2018, 83, 103–111. [Google Scholar] [CrossRef] [PubMed]
- McGinnis, E.W.; Anderau, S.P.; Hruschak, J.; Gurchiek, R.D.; Lopez-Duran, N.L.; Fitzgerald, K.; Rosenblum, K.L.; Muzik, M.; McGinnis, R.S. Giving voice to vulnerable children: Machine learning analysis of speech detects anxiety and depression in early childhood. IEEE J. Biomed. Health Inform. 2019, 23, 2294–2301. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Zhang, Q.; Ma, S.; Cai, M.; Liu, D.; Liu, Z.; Yang, J. A lightweight CNN and Transformer hybrid model for mental retardation screening among children from spontaneous speech. Comput. Biol. Med. 2022, 151, 106281. [Google Scholar] [CrossRef]
- Liu, Q.; Cai, M.; Liu, D.; Ma, S.; Zhang, Q.; Liu, Z.; Yang, J. Two stream Non-Local CNN-LSTM network for the auxiliary assessment of mental retardation. Comput. Biol. Med. 2022, 147, 105803. [Google Scholar] [CrossRef]
- Wechsler, D.; Kodama, H. Wechsler Intelligence Scale for Children; Springer: New York, NY, USA, 2011. [Google Scholar]
- Ryan, J.; Glass, L.A.; Bartels, J.M. Internal Consistency Reliability of the WISC-IV among Primary School Students. Psychol. Rep. 2009, 104, 874–878. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Wood, E.; Baltrusaitis, T.; Zhang, X.; Sugano, Y.; Robinson, P.; Bulling, A. Rendering of Eyes for Eye-Shape Registration and Gaze Estimation Erroll Wood. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3756–3764. [Google Scholar]
- Zadeh, A.; Chong Lim, Y.; Baltrusaitis, T.; Morency, L.P. Convolutional experts constrained local model for 3d facial landmark detection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2519–2528. [Google Scholar]
- Chen, S.; Gopalakrishnan, P. Speaker, environment and channel change detection and clustering via the bayesian information criterion. In Proc. DARPA Broadcast News Transcription and Understanding Workshop; Morgan Kaufmann Publishers: Burlington, MA, USA, 1998; Volume 8, pp. 127–132. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Jassim, W.A.; Paramesran, R.; Harte, N. Speech emotion classification using combined neurogram and INTERSPEECH 2010 paralinguistic challenge features. IET Signal Process. 2017, 11, 587–595. [Google Scholar] [CrossRef]
- Mika, S.; Schölkopf, B.; Smola, A.; Müller, K.R.; Scholz, M.; Rätsch, G. Kernel PCA and De-noising in feature spaces. Adv. Neural Inf. Process. Syst. 1998, 11, 536–542. [Google Scholar]
- Giliberti, A.; Currò, A.; Papa, F.T.; Frullanti, E.; Ariani, F.; Coriolani, G.; Grosso, S.; Renieri, A.; Mari, F. MEIS2 Gene Is Responsible for Intellectual Disability, Cardiac Defects and a Distinct Facial Phenotype. Eur. J. Med. Genet. 2020, 63, 103627. [Google Scholar] [CrossRef]
- Ward, R.; Jamison, P.; Farkas, L. Craniofacial variability index: A simple measure of normal and abnormal variation in the head and face. Am. J. Med. Genet. 1998, 80, 232–240. [Google Scholar] [CrossRef]
- Ozdemir, M.B.; Ilgaz, A.; Dilek, A.; Ayten, H.; Esat, A. Describing Normal Variations of Head and Face by Using Standard Measurement and Craniofacial Variability Index (CVI) in Seven-Year-Old Normal Children. J. Craniofacial Surg. 2007, 18, 470–474. [Google Scholar] [CrossRef] [PubMed]
- Roelfsema, N.M.; Hop, W.C.J.; Van Adrichem, L.N.A.; Wladimiroff, J.W. Craniofacial Variability Index in Utero: A ThreeDimensional Ultrasound Study. Ultrasound Obstet. Gynecol. 2007, 29, 258–264. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. Arch. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-Class AdaBoost*. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Rennie, J.D.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the poor assumptions of naive bayes text classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 616–623. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Müller-Putz, G.; Scherer, R.; Brunner, C.; Leeb, R.; Pfurtscheller, G. Better than random: A closer look on BCI results. Int. J. Bioelectromagn. 2008, 10, 52–55. [Google Scholar]
- Coplan, J. Three pitfalls in the early diagnosis of mental retardation. Clin. Pediatr. 1982, 21, 308–310. [Google Scholar] [CrossRef]
- Jones, K.; Jones, M.; Campo, M. Smith’s Recognizable Patterns of Human Malformation, 8th ed.; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Ulovec, Z.; Šoši±, Z.; Škrinjari±, I.; ±atovi±, A.; Čivljak, M.; Szirovicza, L. Prevalence and significance of minor anomalies in children with impaired development. Acta Paediatr. 2004, 93, 836–840. [Google Scholar] [CrossRef]
- Marden, P.M.; Smith, D.W.; McDonald, M.J. Congenital anomalies in the newborn infant, including minor variations. J. Pediatr. 1964, 64, 357–371. [Google Scholar] [CrossRef]
- Nordberg, A.; Miniscalco, C.; Lohmander, A.; Himmetlmann, K. Speech problems affect more than one in two children with cerebral palsy: Swedish populationbased study. Acta Paediatr. 2013, 102, 161–166. [Google Scholar] [CrossRef]
- Leung, A.K.C.; Kao, C.P. Evaluation and management of the child with speech delay. Am. Fam. Physician 1999, 59, 3121. [Google Scholar] [PubMed]
- Bleszynski, J.J. Longitudinal research on the development of speech of people with mild mental retardation. US-China Educ. Rev. 2016, 6, 249–256. [Google Scholar]
- Dodd, B.; Thompson, L. Speech disorder in children with Down’s syndrome. J. Intellect. Disabil. Res. 2001, 45, 308–316. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Variables | Number (%) or Mean (SD) |
|---|---|
| Gender | |
| Male | 49 (70.0) |
| Female | 21 (30.0) |
| Age | 9.63 (3.02) |
| Height | 139.41 (19.21) |
| Weight | 37.00 (14.43) |
| BMI | 18.66 (4.80) |
| ID | Name | Formula | ID | Name | Formula | ID | Name | Formula |
|---|---|---|---|---|---|---|---|---|
| F01 | ex-ex | |Pe08 − Pe42| | F11 | n-gn | |Pf27 − Pf8| | F21 | h-re | |Pe17 − Pe11| |
| F02 | en-en | |Pe14 − Pe36| | F12 | w-le | |Pe08 − Pe14| | F22 | w-nb | |Pf31 − Pf32 − Pf33 − Pf34 − Pf35| |
| F03 | t-t | |Pf01 − Pf15| | F13 | w-re | |Pe36 − Pe42| | F23 | h-nb | |Pf27 − Pf28 − Pf29 − Pf30| |
| F04 | zy-zy | |Pf02 − Pf14| | F14 | la-le | ∠(Pe17 − Pe08 − Pe11) | F24 | a-nb | ∠(Pf31 − Pf30 − Pf35) |
| F05 | al-al | |Pf31 − Pf35| | F15 | ra-le | ∠(Pe17 − Pe14 − Pe11) | F25 | ia-lm | ∠(Pf61 − Pf60 − Pf67) |
| F06 | t-sn-t | |Pf1 − Pf33 − Pf15| | F16 | la-re | ∠(Pe45 − Pe36 − Pe39) | F26 | oa-lm | ∠(Pf49 − Pf48 − Pf59) |
| F07 | go-go | |Pf03 − Pf13| | F17 | ra-re | ∠(Pe45 − Pe42 − Pe39) | F27 | ia-rm | ∠(Pf63 − Pf64 − Pf65) |
| F08 | mu-mu | |Pf48 − Pf54| | F18 | a-le-nb | ∠(Pe08 − Pe14 − Pe36) | F28 | oa-rm | ∠(Pf53 − Pf54 − Pf55) |
| F09 | t-gn-t | |Pf01 − Pf08 − Pf15| | F19 | a-re-nb | ∠(Pe42 − Pe36 − Pe14) | F29 | a-2e | ∠(vec(Pe14 − Pe08), vec(Pe36 − Pe42)) |
| F10 | n-sn | |Pf27 − Pf33| | F20 | h-le | |Pe17 − Pe11| | F30 | a-s | ∠(vec(Glx, Gly, Glz), vec(Grx, Gry, Grz)) |
| Percentile | σNor | σPos | Percentile | σNor | σPos |
|---|---|---|---|---|---|
| 5th | 0.404 | 0.577 | 70th | 0.951 | 1.334 |
| 10th | 0.461 | 0.638 | 75th | 1.016 | 1.427 |
| 15th | 0.503 | 0.685 | 80th | 1.085 | 1.521 |
| 20th | 0.537 | 0.730 | 85th | 1.173 | 1.631 |
| 25th | 0.567 | 0.776 | 90th | 1.297 | 1.807 |
| 50th | 0.744 | 0.996 | 95th | 1.502 | 2.479 |
| Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Classifier | Geometric Features (30) | |||
| Random Forest | 0.715 | 0.698 | 0.715 | 0.693 |
| AdaBoost | 0.653 | 0.644 | 0.653 | 0.648 |
| Native Bayes | 0.714 | 0.717 | 0.714 | 0.715 |
| Classifier | CVI Features + Geometric Features (31) | |||
| Random Forest | 0.743 | 0.748 | 0.743 | 0.745 |
| AdaBoost | 0.715 | 0.714 | 0.715 | 0.715 |
| Native Bayes | 0.772 | 0.773 | 0.772 | 0.749 |
| Classifier | Phonetic Features (38) | |||
| Random Forest | 0.759 | 0.677 | 0.677 | 0.677 |
| AdaBoost | 0.754 | 0.666 | 0.684 | 0.675 |
| Native Bayes | 0.796 | 0.690 | 0.832 | 0.754 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Ma, S.; Yang, X.; Liu, D.; Yang, J. Screening Children’s Intellectual Disabilities with Phonetic Features, Facial Phenotype and Craniofacial Variability Index. Brain Sci. 2023, 13, 155. https://doi.org/10.3390/brainsci13010155
Chen Y, Ma S, Yang X, Liu D, Yang J. Screening Children’s Intellectual Disabilities with Phonetic Features, Facial Phenotype and Craniofacial Variability Index. Brain Sciences. 2023; 13(1):155. https://doi.org/10.3390/brainsci13010155
Chicago/Turabian StyleChen, Yuhe, Simeng Ma, Xiaoyu Yang, Dujuan Liu, and Jun Yang. 2023. "Screening Children’s Intellectual Disabilities with Phonetic Features, Facial Phenotype and Craniofacial Variability Index" Brain Sciences 13, no. 1: 155. https://doi.org/10.3390/brainsci13010155