

A Mixed Visual Encoding Model Based on the Larger-Scale Receptive Field for Human Brain Activity

Abstract
:1. Introduction
2. Methods
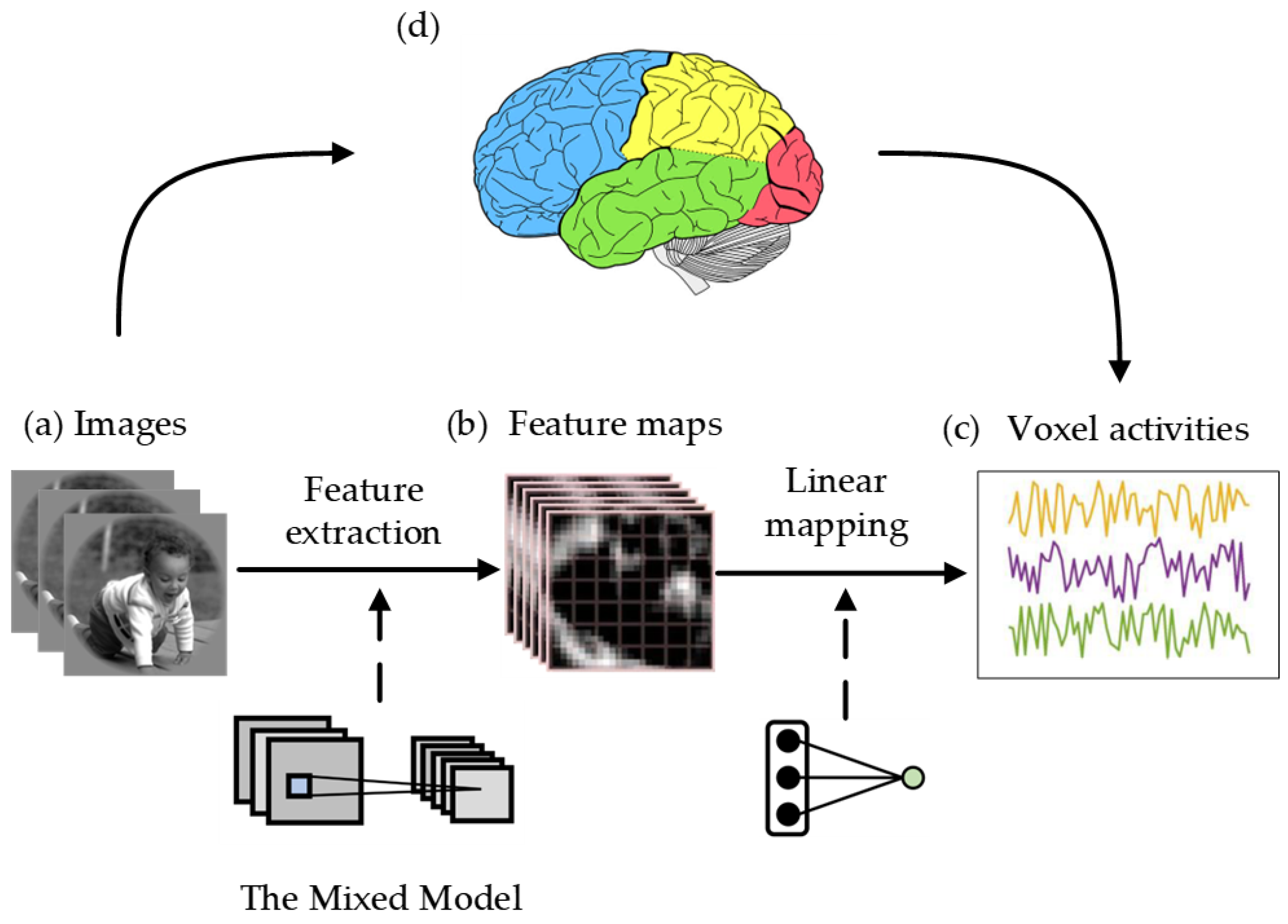
2.1. The Overview of the Mixed Visual Encoding Model
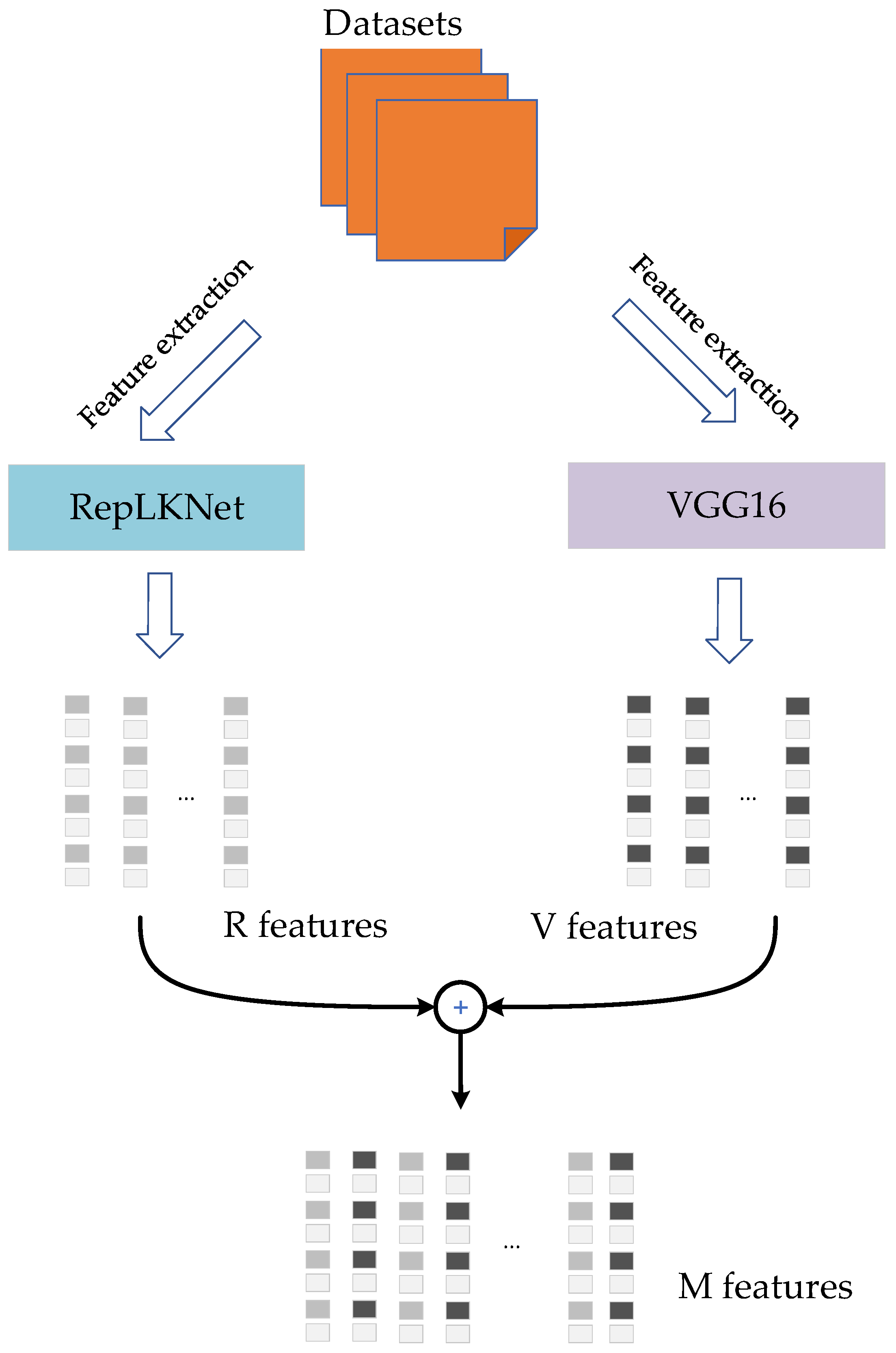
2.2. The Mixed Model
2.3. Voxel-Wise Linear Regression Mapping
3. Experimental and Results
3.1. Experimental Data
3.2. Experimental Configuration
3.2.1. The Pre-Trained Model
3.2.2. Comparison Models
3.3. Evaluation Strategy
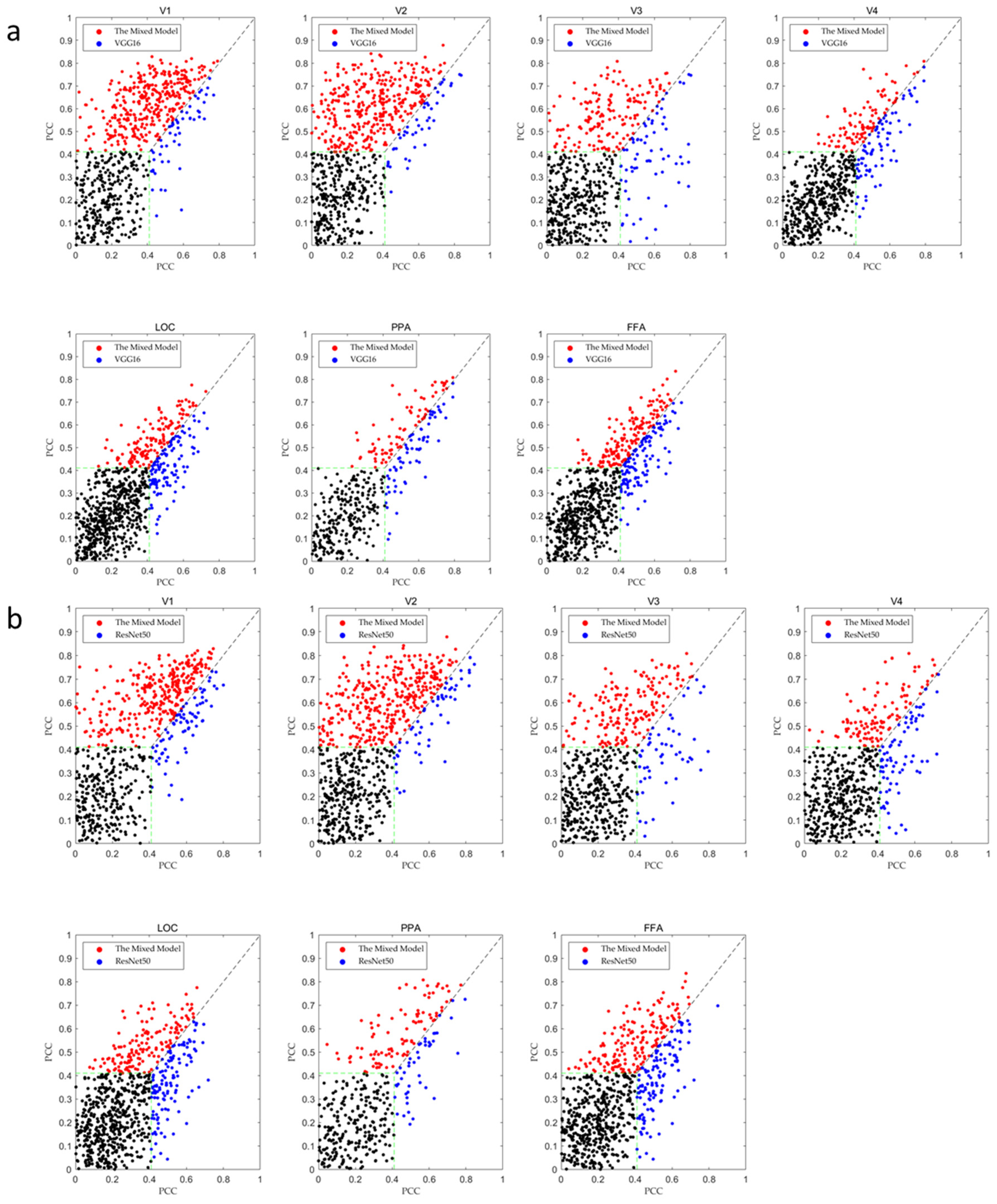
3.4. PCC Results for Different Models
4. Discussion
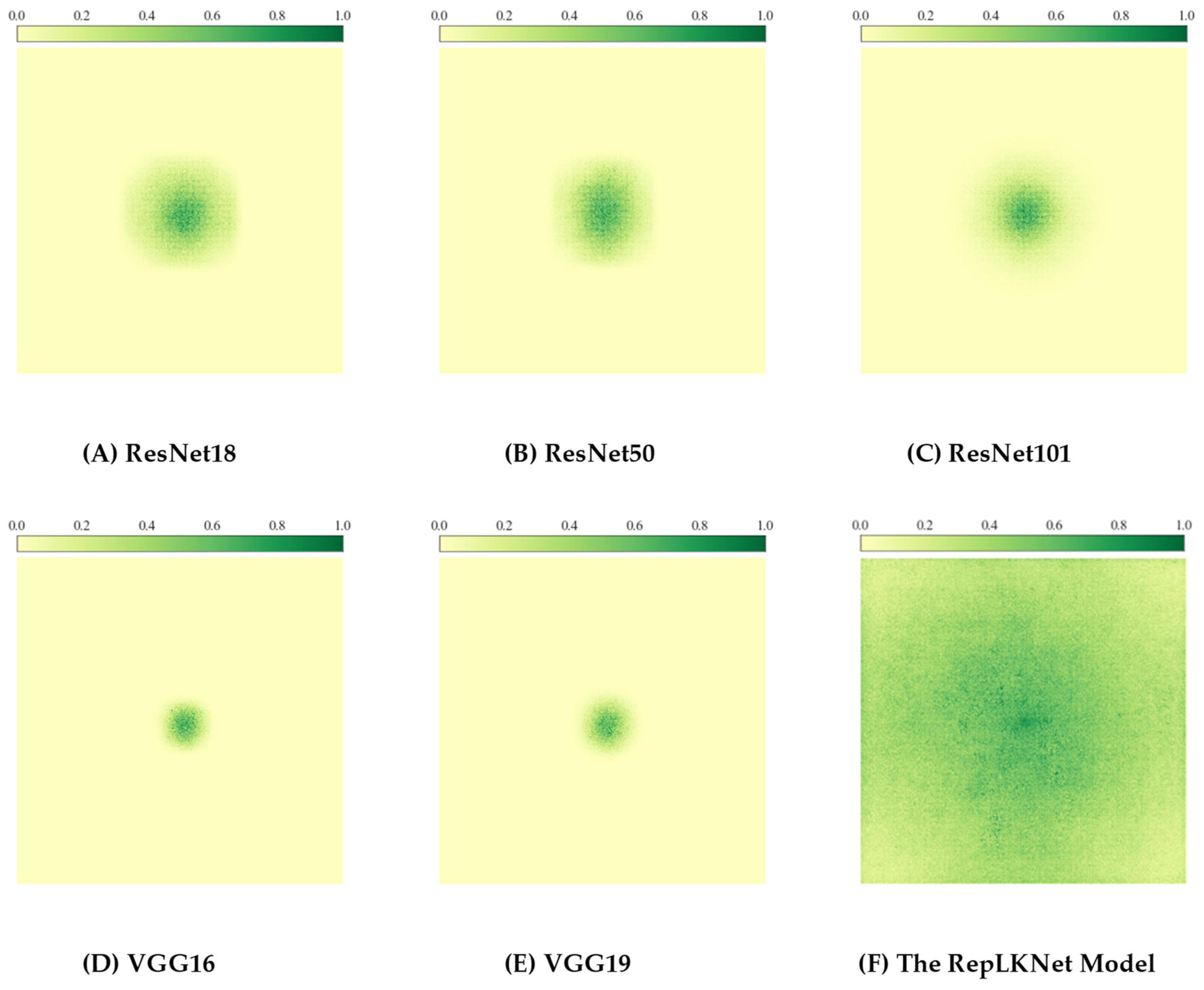
4.1. The ERF and the Convolutional Kernel Size
4.2. V1 Area Performance and Advanced Area Performance
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Huang, L.; Du, C.; Li, D.; Wang, B.; He, H. Neural Encoding for Human Visual Cortex with Deep Neural Networks Learning “What” and “Where”. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 827–840. [Google Scholar] [CrossRef]
- Engel, S.A.; Rumelhart, D.E.; Wandell, B.A.; Lee, A.T.; Glover, G.H.; Chichilnisky, E.-J.; Shadlen, M.N. fMRI of human visual cortex. Nature 1994, 369, 525. [Google Scholar] [CrossRef]
- Sereno, M.I.; Dale, A.M.; Reppas, J.B.; Kwong, K.K.; Belliveau, J.W.; Brady, T.J.; Rosen, B.R.; Tootell, R.B.H. Borders of Multiple Visual Areas in Humans Revealed by Functional Magnetic Resonance Imaging. Science 1995, 268, 889–893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paninski, L.; Pillow, J.; Lewi, J. Statistical models for neural encoding, decoding, and optimal stimulus design. Prog. Brain Res. 2007, 165, 493–507. [Google Scholar] [PubMed] [Green Version]
- Kriegeskorte, N. Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing. Annu. Rev. Vis. Sci. 2015, 1, 417–446. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poldrack, R.A.; Farah, M.J. Progress and challenges in probing the human brain. Nature 2015, 526, 371–379. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhang, C.; Wang, L.; Ding, P.; Hu, L.; Yan, B.; Tong, L. A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream. Brain Sci. 2021, 11, 1004. [Google Scholar] [CrossRef]
- Dumoulin, S.O.; Wandell, B.A. Population receptive field estimates in human visual cortex. Neuroimage 2008, 39, 647–660. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wang, J. Research progress of visual cortex subarea and its fMRI. Prog. Mod. Biomed. 2006, 6, 79–81. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Sharkawy, A.N. Principle of neural network and its main types. J. Adv. Appl. Comput. Math. 2020, 7, 8–19. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Agrawal, P.; Stansbury, D.; Malik, J.; Gallant, J.L. Pixels to voxels: Modeling visual representation in the human brain. arXiv 2014, arXiv:1407.5104. [Google Scholar]
- Qiao, K.; Zhang, C.; Chen, J.; Wang, L.; Tong, L.; Yan, B. Effective and efficient roi-wise visual encoding using an end-to-end cnn regression model and selective optimization. In International Workshop on Human Brain and Artificial Intelligence; Springer: Singapore, 2021; pp. 72–86. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Virtual, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning PMLR 2019, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2016, 29. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 11963–11975. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Ding, X.; Chen, H.; Zhang, X.; Han, J.; Ding, G. Repmlpnet: Hierarchical vision mlp with re-parameterized locality. arXiv 2022, arXiv:2112.11081. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Ding, X.; Hao, T.; Tan, J.; Liu, J.; Han, J.; Guo, Y.; Ding, G. Resrep: Lossless cnn pruning via decoupling remembering and forgetting. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 11–17 October 2021; pp. 4510–4520. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef]
- Yamins, D.L.K.; DiCarlo, J.J. Using Goal-Driven Deep Learning Models to Understand Sensory Cortex. Nat. Neurosci. 2016, 19, 356–365. [Google Scholar] [CrossRef]
- Khosla, M.; Ngo, G.; Jamison, K.; Kuceyeski, A.; Sabuncu, M. Neural encoding with visual attention. Adv. Neural Inf. Process. Syst. 2020, 33, 15942–15953. [Google Scholar]
- Zhou, Q.; Du, C.; He, H. Exploring the Brain-like Properties of Deep Neural Networks: A Neural Encoding Perspective. Mach. Intell. Res. 2022, 19, 439–455. [Google Scholar] [CrossRef]
- Yamins, D.L.; Hong, H.; Cadieu, C.F.; Solomon, E.A.; Seibert, D.; DiCarlo, J.J. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl. Acad. Sci. USA 2014, 111, 8619–8624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grill-Spector, K.; Kourtzi, Z.; Kanwisher, N. The lateral occipital complex and its role in object recognition. Vis. Res. 2001, 41, 1409–1422. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Batch size | 32 |
| Drop path | 0.1 |
| LR | 4 × 10−3 |
| Warmup epoch | 5 |
| Epoch Number | 90 |
| Areas | Models | ||||
|---|---|---|---|---|---|
| VGG16 | ResNet50 | End-to-End | RepLKNet | Ours (Mixed Model) | |
| V1 | 0.620 | 0.650 | 0.683 | 0.741 | 0.743 |
| V2 | 0.617 | 0.645 | 0.644 | 0.740 | 0.746 |
| V3 | 0.576 | 0.557 | 0.559 | 0.647 | 0.650 |
| V4 | 0.569 | 0.547 | 0.300 | 0.521 | 0.582 |
| LOC | 0.573 | 0.566 | 0.311 | 0.490 | 0.589 |
| PPA | 0.590 | 0.546 | 0.233 | 0.545 | 0.601 |
| FFA | 0.601 | 0.589 | 0.320 | 0.512 | 0.624 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; Wang, L.; Chen, P.; Qin, R.; Hou, L.; Yan, B. A Mixed Visual Encoding Model Based on the Larger-Scale Receptive Field for Human Brain Activity. Brain Sci. 2022, 12, 1633. https://doi.org/10.3390/brainsci12121633
Ma S, Wang L, Chen P, Qin R, Hou L, Yan B. A Mixed Visual Encoding Model Based on the Larger-Scale Receptive Field for Human Brain Activity. Brain Sciences. 2022; 12(12):1633. https://doi.org/10.3390/brainsci12121633
Chicago/Turabian StyleMa, Shuxiao, Linyuan Wang, Panpan Chen, Ruoxi Qin, Libin Hou, and Bin Yan. 2022. "A Mixed Visual Encoding Model Based on the Larger-Scale Receptive Field for Human Brain Activity" Brain Sciences 12, no. 12: 1633. https://doi.org/10.3390/brainsci12121633