Hybrid Deep Learning (hDL)-Based Brain-Computer Interface (BCI) Systems: A Systematic Review

 ,
,  ,
,  ,
, 

Abstract
:1. Introduction
- non-stationarity, which is the reason why learning models trained on a temporally limited amount of data, might generalize poorly with respect to data recorded at a different time on the same individual;
- high inter-subject variability due to physiological artifacts differences between individuals. This aspect can severely affect the performance of learning models;
- data collection, time-consuming, and restricted. Medical data is not usually available due to personal data regulation.
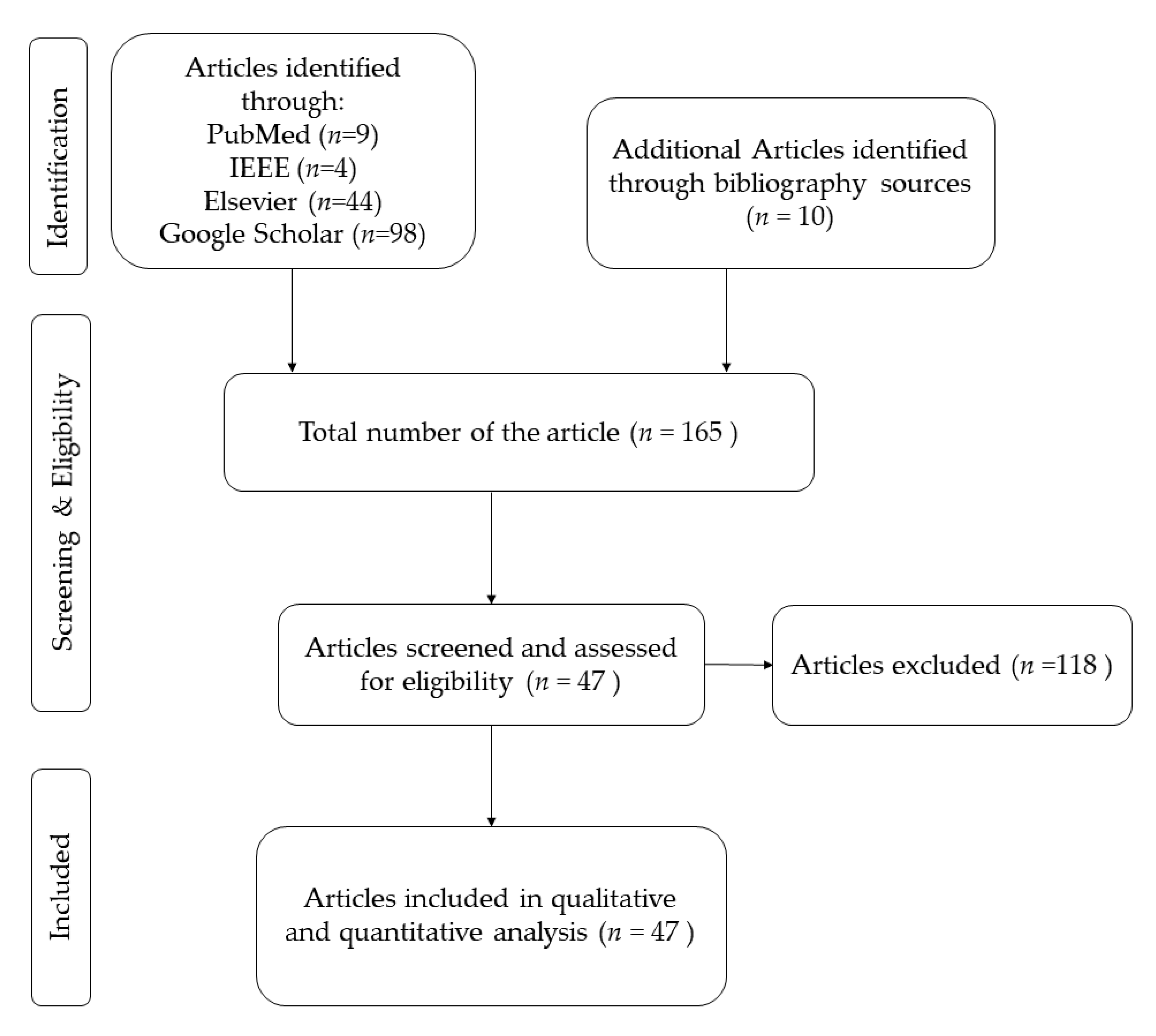
2. Materials and Methods
3. Results
3.1. Brain Intention Recordings
3.2. Preprocessing of the Data
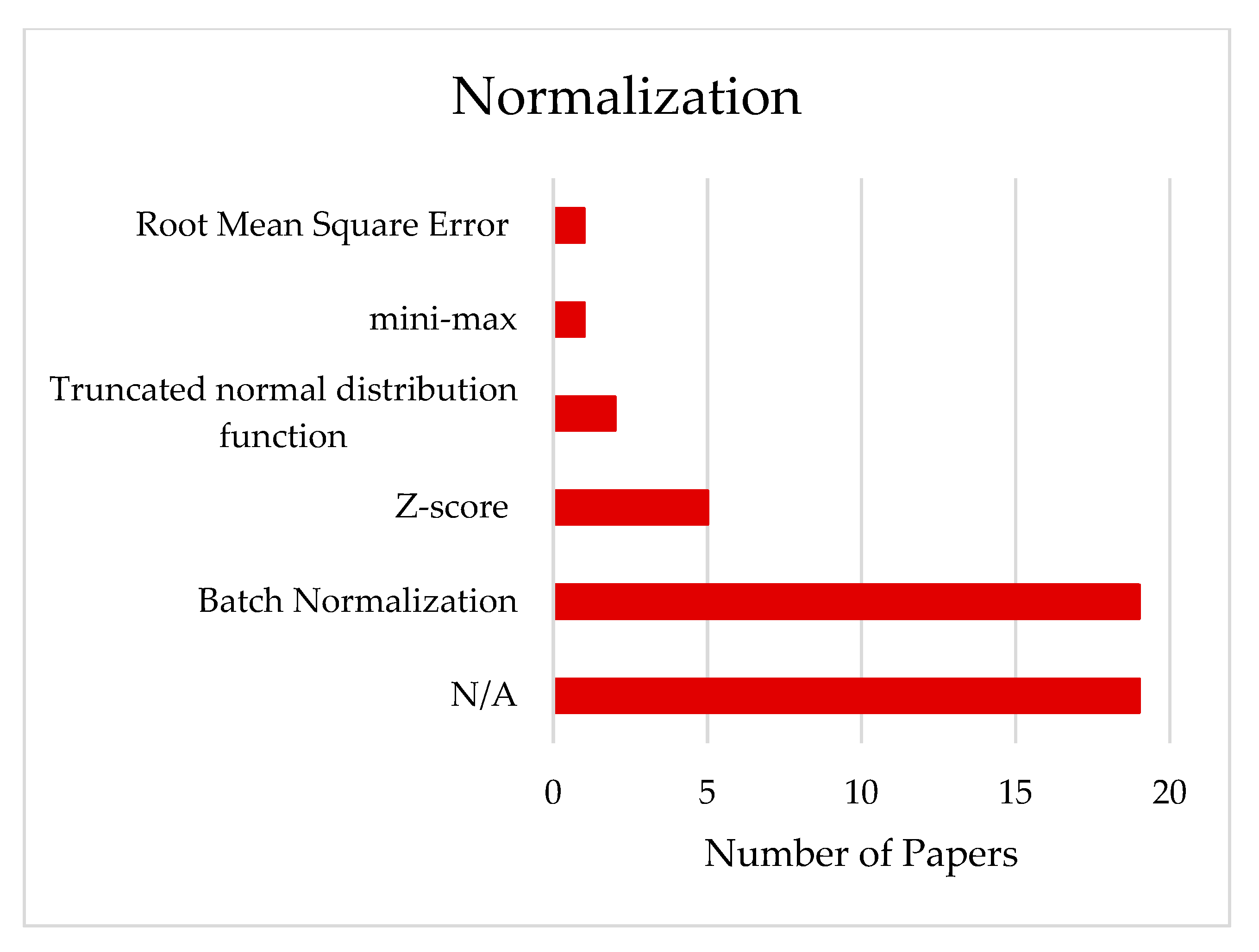
3.3. Normalization of the Data
3.4. Features Extraction
3.5. Hybrid Deep Learning Architecture
3.6. Optimization
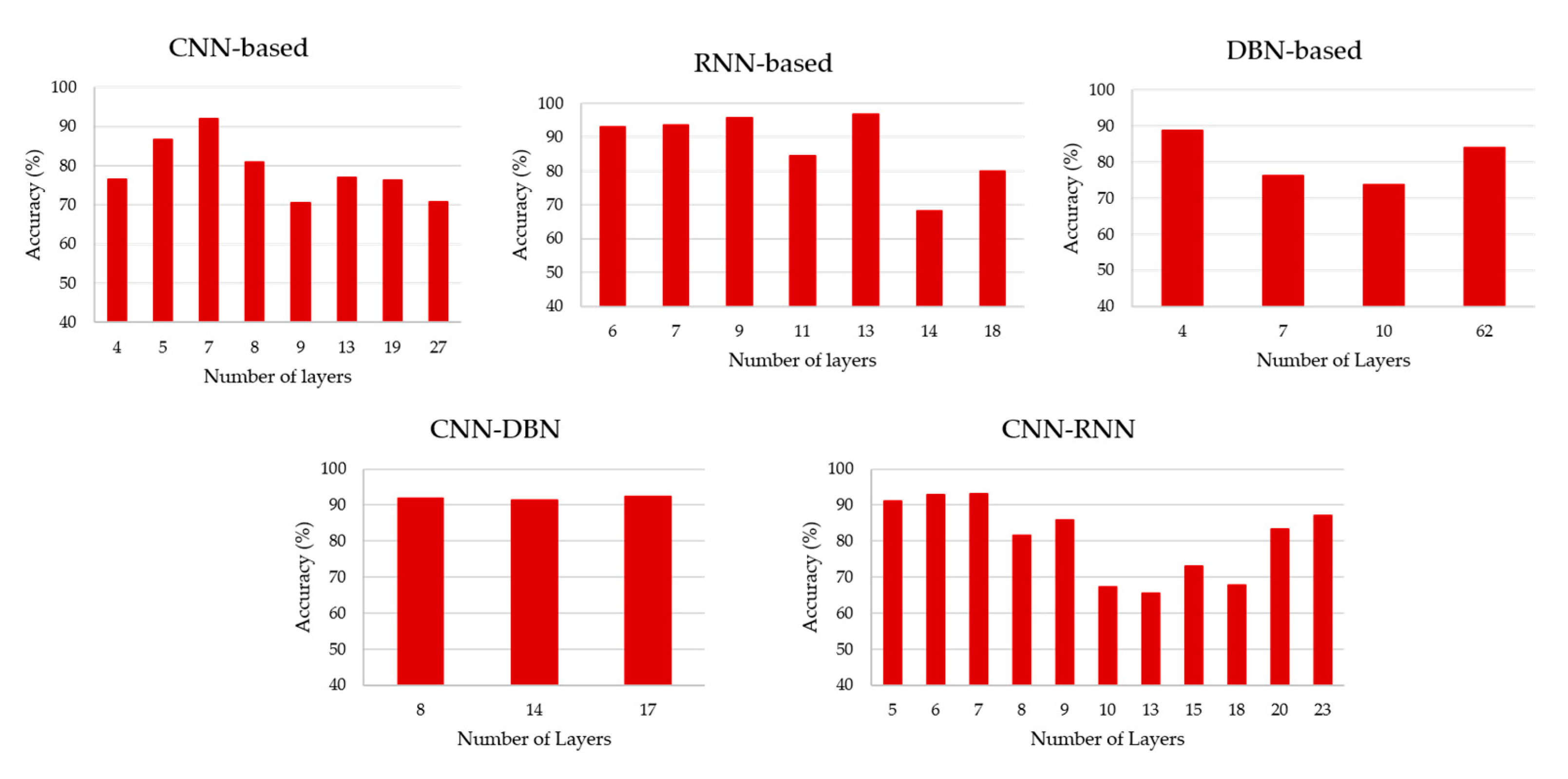
3.7. Number of Layers
3.8. Application, Datasets and Task/Protocol
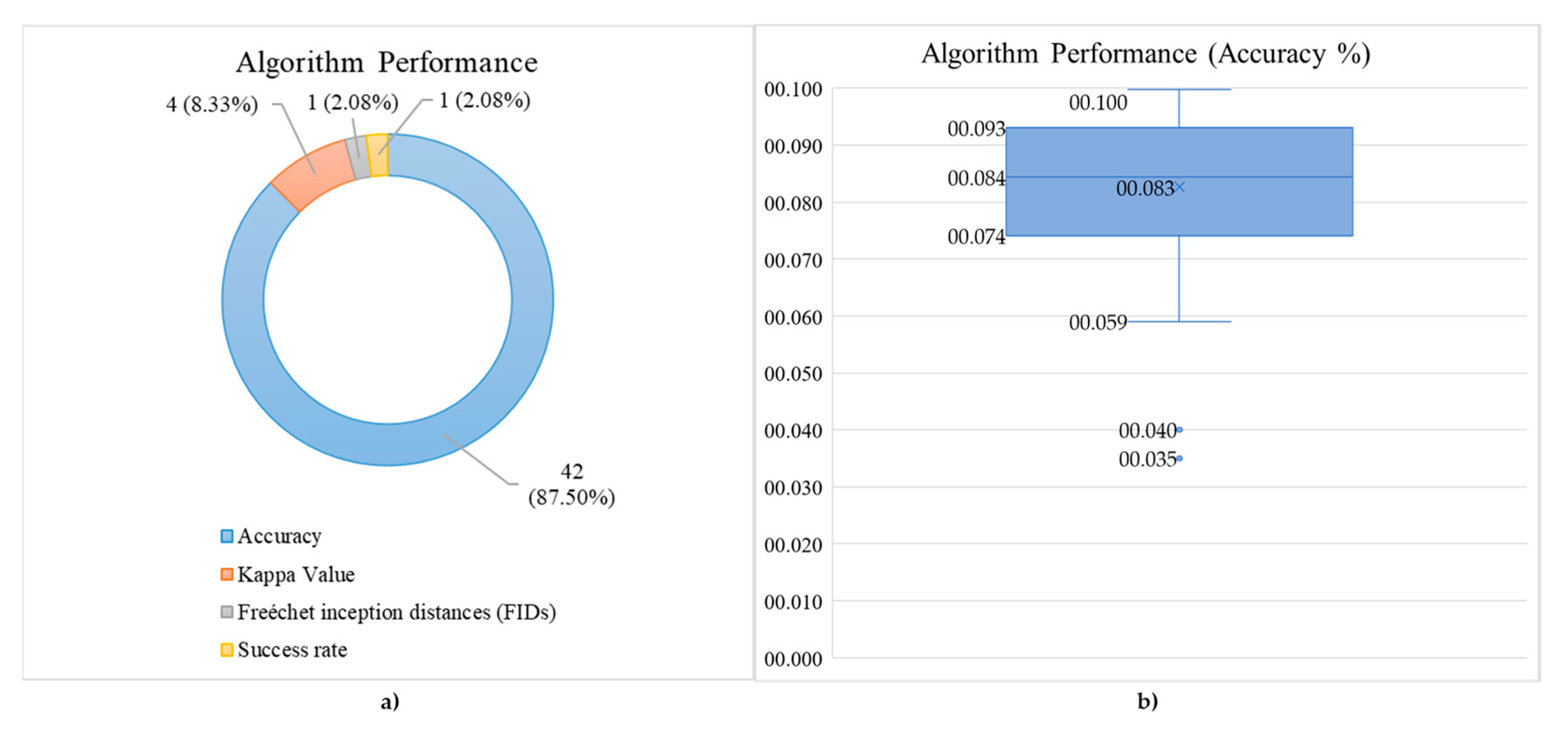
3.9. Hybrid Deep Learning (hDL) Performance
4. Discussion
4.1. Preprocessing
4.2. hDL Framework
4.2.1. Feature Extraction
4.2.2. Normalization
4.2.3. Architecture
4.2.4. Number of Layers
4.2.5. Optimization
5. Conclusions
6. Open Challenges
- More research is needed that uses other brain imaging techniques like functional Near-Infrared Spectroscopy (fNIRS), fMRI and MEG with the aim to investigate the richness of the information that the brain signal is able to bring.
- Investigating the effect of the presence or absence of preprocessing on the data and the performance of hDL architecture.
- Investigate the effects of the data’s input shape and their dimensionality.
- Automating the entire pipeline of the hDL-based BCI system.
- More exploration towards spatial and temporal features because it achieved high performance.
- New architecture combinations are encouraged to be explored between frequency features and temporal-frequency features with RNN-based and DBN-based architectures.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Meaning | Note |
|---|---|---|
| AE | Autoencoder | Artificial Neural Network |
| AEP | Azimuthal equidistant projection | Projecting Algorithm |
| AI | Artificial Intelligence | - |
| ADAM | ADAptive Momentum | Optimization Algorithm |
| ALPS | Age-Layered Population Structure | Genetic Algorithm |
| BCI | Brain-Computer Interface | - |
| BGRU | Bidirectional GRU | Recurrent Neural Network Structure |
| BN | Batch Normalization | Normalization Algorithm |
| BPF | Band Pass Filter | Signal Processing tool (Filter) |
| BSF | Band Stop Filter | Signal Processing tool (Filter) |
| BSS | Blind Source Separation | Signal Processing tool |
| BVP | Blood volume pressure | Physiological Signal |
| CAR | Common Average Reference | Signal Processing tool |
| CCV | Channel cross-covariance | Statistical Extracted Feature |
| CNN | Convolutional Neural Network | Deep Learning Neural Network |
| CRAM | Convolutional Recurrent Attention Model | Convolutional Recurrent Neural Network |
| CSP | Common Spatial Pattern | Signal Processing tool |
| CSTP-NN | Common Spatiotemporal Pattern Neural Network | Artificial Neural Network |
| D-AE | Denoising Autoencoder | Artificial Neural Network |
| DBN | Deep Belief Network | Deep Learning Neural Network |
| DBN-GC | Deep Belief Network Glia Cell | Deep Learning Neural Network |
| DE | Deferential Entropy | Extracted Feature |
| DEAP | Database for Emotion Analysis using Physiological Signals | Dataset Name |
| DL | Deep learning | - |
| DNN | Deep Neural Network | - |
| DWT | Discreet Wavelet Transformation | Signal Processing tool |
| EEG | Electroencephalography | Physiological Signal |
| eegmmidb | EEG Motor Movement/Imagery DataBase | Dataset Name |
| ERP | Event-Related Potential | Pattern in Electroencephalography |
| MI | Motor Imagery | Task/Protocol |
| EMG | Electromyography | Physiological Signal |
| EOG | Electrooculography | Physiological Signal |
| FC | Fully Connected | A layer in Deep learning Neural Network |
| FBCSP | Filter Bank Common Spatial Pattern | Signal Processing tool |
| FIDs | Freéchet inception distances | Evaluation metric |
| FIR | Finite Impulse Response | Signal Processing tool (Filter) |
| fNIRS | Functional Near Infra-red signal | Physiological Signal |
| GA | Genetic Algorithm | Artificial Intelligence Algorithm |
| GRU | Gated recurrent unit | Recurrent Neural Network Structure |
| GWO | Gray Wolf Optimizer | Optimization Algorithm |
| GSR | Galvanic skin response | Physiological Signal |
| HDL | Hybrid Deep Learning | - |
| HHS | Hilbert–Huang spectrum | Extracted Feature |
| HMM | Hidden Markov Model | Artificial Neural Network |
| ICA | Independent Component Analysis | Signal Processing tool |
| iid | independent identically distributed | Statistical Function |
| LPF | Low Pass Filter | Signal Processing tool (Filter) |
| LSTM | Long Short-Term Memory | Recurrent Neural Network Structure |
| MESAE | Multiple-fusion-layer based ensemble classifier of SAE | Deep Learning Neural Network |
| ML | Machine Learning | - |
| MLP | Multilayer Perceptron | Artificial Neural Network |
| MTRBM | Multichannel temporal Restricted Boltzmann Machine | Artificial Neural Network |
| NN | Neural Network | - |
| OVR-FBCSP | One-versus rest filter bank common spatial pattern | Signal Processing Tool |
| P300 | Potential after 300 ms | Pattern in Electroencephalography |
| PCA | Principal Component Analysis | Signal Processing Tool |
| PSD | Power Spectral Density | Signal Measure |
| RBN | Restricted Boltzmann Machine | Artificial Neural Network |
| ReLU | Rectified Linear Unit | Activation function in Neural Networks |
| RMSE | Root Mean Square Error | Statistical Function |
| RMSProp | Root Mean Square Propagation | Optimization Algorithm |
| RNN | Recurrent Neural Network | Deep Learning Neural Networks |
| RS | Respiration signal | Physiological Signal |
| SAE | Stacked Autoencoder | Deep Learning Neural Networks |
| SAM | Selective Attention Mechanism | Feature Extraction tool |
| SBD | Stop Band Filter | Signal Processing tool (Filter) |
| SGD | Stochastic Gradient Descendent | Optimization Algorithm |
| SI | Speech Imagery | Task/Protocol |
| SIMKAP | Simultaneous capacity | Task/Protocol |
| SNR | Signal to Noise Ratio | Signal Measure |
| SSAEP | Steady-state Auditory Evoked Potential | Task/Protocol |
| SSEP | Steady-state Evoked Potential | Task/Protocol |
| ST | Skin temperature | Physiological Signal |
| STFT | Short-Time Fourier Transform | Signal Processing tool |
| SVAE | Stacked Variational AutoEncoder | Deep Learning Neural Networks |
| VAE | Variational Autoencoder | Deep Learning Neural Networks |
| WAS-LSTM | Weighted Average Spatial-LSTM | Deep Learning Neural Networks |
| wICA | wavelet-enhanced independent component analysis | Signal Processing tool |
Appendix B
| Year | References | Database | Application | Training | Task | Pre-processing | Normalization | Feature extraction | Architecture | N° of Layers | Optimization | Results |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2015 | [23] | BCI competition IV | N/A | Offline | MI | Filter-Bank CSP (FBCSP) A bank of 9 filters from 4 to 40 Hz with a width of 4 Hz | N/A | Static & Dynamic Energy | CNN-Based | 9 | SGD | 70.60% |
| 2015 | [12] | Local Dataset | Communication | Online | MI | N/A | Batch normalization | Selective Attention Mechanism (SAM) | RNN-Based | 7 | Adam Optimizer | 93.63% |
| 2017 | [20] | Local Dataset BCI competition IV | Medical Care | Offline | MI | Filtering (BPF: Butterworth filter:0.5–50 Hz) DAE | N/A | Optical Flow from the EEG video | CNN-RNN CNN-RNN | 8 | N/A | 72.22% 70.34% |
| 2017 | [43] | Local Dataset | Communication | Online | MI | Filtering (BPF: FIR: 1–200 Hz) CSP ICA | N/A | Variance | CNN-Based CNN-Based | 27 27 | SGD | 70.80% 70.79% |
| 2017 | [25] | DEAP dataset | Emotion recognition | Offline | SSEP | Filtering (BPF: 4–45 Hz) ICA | Z-Score | 425 silent physiological features from the 7 signals | DBN-Based | 10 | N/A | 73.70% |
| 2017 | [46] | Local Dataset | N/A | Offline | P300 | Filtering (BPF: FIR: 2–35 Hz) (SBF: 0.1 & 40 Hz) | N/A | Spatial and temporal features | CNN-RNN CNN-RNN CNN-RNN | 10 15 15 | Adam Optimizer | 67.25% 68.75% 70.00% |
| 2017 | [70] | EEGmmidb | Communication | Online | MI | N/A | N/A | Spatial and temporal features | CNN-RNN | 18 | Adam Optimizer RMSPropOptimizer | 95.53% |
| 2018 | [71] | Local Datasets BCI competition III BCI competition IV | N/A | Online | MI | Referencing Electrode Selection Artifact removal (ICA & PCA) Filtering (BPF: 8–12 Hz & 18–26 Hz) | Batch normalization | 16 spatial features through CNN + DWT | CNN-RNN | 8 | N/A | 87.36% |
| 2018 | [72] | EEGmmidb | N/A | Offline | MI | N/A | N/A | Spatial and temporal features | RNN-Based | 14 | Adam Optimizer | 68.20% |
| 2018 | [58] | BCI competition IV | N/A | Offline | MI | Filtering (68 BPF: 4–40 Hz) CSP | Batch normalization | Variance (Abstracted Features through CNN) | CNN-Based | 8 | Adam Optimizer | 81%. |
| 2018 | [65] | Local Dataset | Medical Care | Online | MI | Filtering (LPF: 40 Hz) | N/A | Abstracted Features through CNN | CNN-Based | 13 | Adam Optimizer | 76.90% |
| 2018 | [59] | OpenMIIR | Medical Care | Online | SSAEP | Filtering 5 BPF (α: 8–13 Hz, β: 14–30 Hz, γ: 31–51 Hz, δ: 0.5–3 Hz, θ: 4–7 Hz) | N/A | Optical Flow from the EEG video | CNN-RNN | 13 | N/A | 35% |
| 2018 | [73] | BCI competition II BCI Competition III | N/A | Offline | P300 | Filtering (BPF: Butterworth filter: 0.1–30 Hz) | Z-Score | Spatial and temporal features | DBN-Based | 4 | Mini-batch | 88.90% |
| 2018 | [69] | DEAP dataset | Emotion recognition | Offline | SSEP | Filtering BPF: Butterworth filter (α: 8–12 Hz, β: 12–30 Hz, γ: 30–100 Hz, θ: 4–8 Hz) | Z-score | Differential Entropy (DE) | CNN-RNN | 6 | Adam Optimizer | 90.24% |
| 2018 | [74] | DEAP dataset | Emotion recognition | Offline | SSEP | N/A | Z-score | Spatial and temporal features | CNN-RNN | 5 | Adam Optimizer | 91.03% |
| 2018 | [75] | DEAP dataset | Emotion recognition | Offline | SSEP | Filtering (BPF: 4–45 Hz) | N/A | (Statistical measures) (Power features) (Power differences) (Hilbert–Huang spectrum (HHS)) | DBN-Based | 7 | N/A | 76.36% |
| 2018 | [76] | Public (Bashivan, Bidelman, Yeasin EEG data set) | Mental state detection | Offline | Cognitive | Filtering (BPF 4–7, 8–13, 13–30 Hz) | N/A | High-level features | CNN-DBN | 14 17 | SGD | 91.32% 92.37% |
| 2019 | [60] | BCI competition IV | N/A | Offline | MI | N/A | Batch normalization | Spatial and temporal features | CNN-RNN | 9 | Adam Optimizer SGD | 59% |
| 2019 | [77] | BCI competition IV | N/A | Offline | MI | Filtering (16 BPF: Chebyshev Type II 4–38 Hz) | Truncated normal distribution function | Spatial and temporal features | CNN-RNN | 8 | Adam Optimizer | 83% |
| 2019 | [66] | Local Dataset BCI competition IV | N/A | Offline | MI | Remove the average Filtering (BPF: 8–13 Hz) | N/A | Spatial Features | CNN-DBN | 8 | N/A | 92% |
| 2019 | [78] | BCI competition IV | N/A | Offline | MI | Filtering (BPF: 0.5–100 Hz) | Batch normalization | Spatial and temporal features | CNN-RNN | 18 | Adam Optimizer | 40% |
| 2019 | [79] | BCI competition IV | N/A | Offline | MI | Filtering (1 Hz-45 Hz based on Morlet wavelet transformation) | Batch normalization | Spatial and temporal features | CNN-Based | 4 | SGD | 76.62% |
| 2019 | [41] | Local Dataset BCI competition IV | N/A | Offline | MI | Filtering (BPF: 6–13 & 17–30 Hz) | Batch normalization | Spatial Features through CNN | CNN-DBN | 10 | SGD | 56.4 (Kappa) |
| 2019 | [80] | EEG based speech database | Medical Care | Offline | SI | N/A | N/A | Spatial and temporal features Channel cross-covariance (CCV) | RNN-Based | 18 | Adam Optimizer | 79.98% |
| 2019 | [17] | EEGmmidb EEG-S TUH | Motor Imagery Recognition Person Identification (PI) Medical Care | Online | Cognitive | N/A | N/A | Spatial features | CNN-Based | 5 | Adam Optimizer | 98.64% |
| 2019 | [57] | Local Dataset | Mental State Detection | Offline | Cognitive | N/A | N/A | DWT | CNN-Based | 7 | Adam Optimizer | 92% |
| 2019 | [81] | (Exploiting P300 Amplitude changes) (BCI Competition III) (Auditory multi-class BCI) (BCI-Spelling using Rapid Serial Visual Presentation) (Examining EEG-Alcoholism Correlation) (Decoding auditory attention) | N/A | Offline | P300 | Filtering (BPF: 0.15–5 Hz 0.1–60 Hz 0.1–250 Hz 0.016–250 Hz 0.02–50 Hz 0.016–250 Hz) | Batch normalization | Spatial and temporal features | DBN-Based | 62 | RMSprop optimizer | 79.37% 88.52% |
| 2019 | [26] | Local Dataset | Mental stateDetection | Offline | Cognitive | Filtering (BPF: Butterworth filter 1–50 Hz) ICA | Batch normalization | Spatial and temporal features | CNN-RNN | 23 | N/A | 87% |
| 2019 | [11] | Local dataset Public dataset | Communication | Offline | SI | N/A | N/A | Spatial and temporal features | CNN-RNN | 6 | N/A | 95.53% |
| 2019 | [82] | Local | Person identification | Offline | Resting state | DWT | Batch Normalization | Temporal features | RNN-Based | 9 | N/A | 95.60% |
| 2019 | [83] | Local | Comunications (Robotics) | Online | MI | Filtering (LPF 40 Hz) | Batch Normalization | Spatial features | CNN-Based | 19 | Adam Optimizer | 76.90% |
| 2019 | [84] | Public (Bashivan, Bidelman, Yeasin EEG data set) | Mental state detection | Offline | Cognitive | Filtering (BPF 0–7, 7–14, 14–49 Hz) | N/A | Spatial temporal frequency features | CNN-RNN | 13 | RMSProp Optimizer | 96.30% |
| 2020 | [85] | Local Dataset | Medical Care | Online | MI | Filtering (BPF: 0.2 Notch filter: 60 Hz)–45 Hz | Mini-max normalization | Temporal features | RNN-Based | 6 | Adam Optimizer | 97.50% |
| 2020 | [86] | MAKAUT Dataset AI Dataset | Emotion recognition | Online | SSEP | Filtering (BPF 10 order: Chebyshev) | N/A | (Time domain EEG features) (Frequency domain EEG features) (Time-frequency domain EEG features) (The standard CSP features) | RNN-Based | 6 | Adam Optimizer | 88.71% |
| 2020 | [10] | EEGmmidb | N/A | Offline | MI | N/A | Batch normalization | Spatial and temporal features | RNN-Based | 13 | Adam Optimizer | 98.81% 94.64% |
| 2020 | [42] | DEAP dataset | Emotion recognition | Online | SSEP | Filtering (BPF: 4–47 Hz) Common average referencing ocular artifacts removing by blind source separation algorithms | Z-score | Spatial and temporal features PSD | CNN-RNN | 7 | Adam Optimizer | 93.20% 93.00% |
| 2020 | [64] | (Graz University Dataset) (BCI competition IV) | N/A | Offline | MI | Filtering (BPF: 8–24 Hz, 8–30 Hz, 8–40 Hz) | Batch normalization | Spatial and temporal features | CNN-Based | 19 | Adam Optimizer | 76.07% |
| 2020 | [4] | BCI competition IV | N/A | Offline | MI | Filtering notch filter 50 Hz) | Batch normalization | Temporal features | CNN-RNN | 8 | Adam Optimizer | 95.62% |
| 2020 | [87] | BCI competition IV | N/A | Offline | MI | Filtering (FBCSP: 12BPF: 6–40 Hz) Hilbert transform algorithm | Batch normalization | Spatial features | DBN-Based | 29 | N/A | 0.630 Kappa |
| 2020 | [88] | DEAP dataset | Emotion recognition | Offline | SSEP | Filtering (BPF: 4–45 Hz) | Batch normalization | Spatial and temporal features | CNN-RNN | 9 | Adam Optimizer | 99.10% 99.70% |
| 2020 | [89] | BCI competition IV | N/A | Offline | MI | Filtering (BPF 4th order Butterworth 4–7 Hz, 8–13 Hz, 13–32 Hz) | N/A | High-level features | CNN-Based | 5 | N/A | 74.60% |
| 2020 | [90] | BCI competition III | Communication | Online | MI | Filtering (BPF: FIR: Hamming-windowed: 4–40 Hz) ICA Common average reference (CAR) | RMSE (root mean square error) | Spatial and temporal features | CNN-RNN | 9 | Adam Optimizer | 0.6 0.43 Success rates |
| 2020 | [91] | EEGmmidb | N/A | Offline | MI | Filtering (BPF: 8–13 Hz &13–30 Hz) | N/A | Spatial and temporal features | CNN-RNN | 20 | SGD | 82.10% 83.50% |
| 2020 | [92] | BCI competition IV | Data Augmentation | Offline | MI | Filtering (BPF: 8–30 Hz) Spectrogram | Batch normalization | Images features from Spectrogram | CNN-Based | 24 | Adam Optimizer | 126.4 98.2 (FIDs) |
| 2020 | [93] | BCI competition IV | Person identification | offline | MI | Filtering (Chebyshev 4–8 Hz, 8–12 Hz...) | Truncated normal distribution | Spatial and temporal features | CNN-RNN | 13 | Adam Optimizer | Kappa 0.8 |
| 2020 | [94] | “STEW” dataset | Mental state detection | Offline | “No task” & (SIMKAP) | Filtering (BPF 4–32 Hz) | Batch Normalization | (Frequency features (PSD)) (Linear domain features (Autoregressive coefficient)) (Non -Linear domain features (approximate entropy, Hurst Exponent) (Time domain) | RNN-Based | 11 | Gray Wolf Optimizer (GWO) | 84.45% |
| 2020 | [95] | BCI competition IV Local Dataset | N/A | Offline | MI SI | Filtering (Butterworth BPF 4–35 Hz) | Batch Normalization | Temporal-spatial-frequency features | CNN-RNN CNN-RNN CNN-RNN CNN-RNN | 20 15 20 15 | Adam Optimizer | 86% 82% 82% 71% Kappa: 0.64 |
Appendix C
Appendix C.1. Deep Learning Overview
Appendix C.2. Deep Belief Networks-Based Hybrid Deep Learning Algorithms
- DBN assisted by Glia cells (GC-DBN)
- Multiple-fusion-layer based ensemble classifier of stacked autoencoders (MESAE)
- Event-Related Potential Network (ERP-NET)
Appendix C.2.1. DBN Assisted by Glia Cells (GC-DBN)
Appendix C.2.2. Multiple-Fusion-Layer Based Ensemble Classifier of Stacked Autoencoders (MESAE)
- Initialize member SAEs.
- Model structure identification for member SAEs.
- Construct a hierarchical feature fusion network.
Appendix C.2.3. Event-Related Potential Network (ERP-NET)
Appendix C.3. CNN-Based Hybrid Deep Learning Algorithms
Appendix C.4. RNN-Based Hybrid Deep Learning Algorithms
- Weighted Average Spatial-LSTM (WAS-LSTM)
- Stacked RNN
Appendix C.4.1. Weighted Average Spatial-LSTM (WAS-LSTM)
- The autoregressive model.
- The Silhouette Score.
- The reward functions.
- To capture the cross-relationship among feature dimensions, which is extracted using Selective Attention Mechanism (SAM), in the optimized focal zone.
- It could stabilize the performance of LSTM via average methods.
Appendix C.4.2. Stacked RNN
- Rearrange the index of recorded electrodes according to their spatial positions so the data can be viewed as a spatial sequential stream.
- Spilt the samples according to the trial index.
- A parallel RNNs model was proposed.
Appendix C.5. CNN-RNN Hybrid Deep Leering Algorithms
- projecting the 3D locations of the electrodes into two dimensions using azimuthal equidistant projection (AEP);
- interpolating these locations into a 2D grey image;
- Show those images in a timeline that produce the EEG-video.
References
- Kübler, A. The history of BCI: From a vision for the future to real support for personhood in people with locked-in syndrome. Neuroethics 2020, 13, 163–180. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, S.; Pan, J. Advances in hybrid brain-computer interfaces: Principles, design, and applications. Comput. Intell. Neurosci. 2019, 2019, 3807670. [Google Scholar] [CrossRef] [PubMed]
- McFarland, D.J.; Wolpaw, J.R. Brain-computer interfaces for communication and control. Commun. ACM 2011, 54, 60–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uyulan, C. Development of LSTM&CNN Based Hybrid Deep Learning Model to Classify Motor Imagery Tasks. bioRxiv 2020. [Google Scholar] [CrossRef]
- Bigdely-Shamlo, N.; Mullen, T.; Kothe, C.; Su, K.M.; Robbins, K.A. The PREP pipeline: Standardized preprocessing for large-scale EEG analysis. Front. Neuroinform. 2015, 9, 16. [Google Scholar] [CrossRef]
- Barbati, G.; Porcaro, C.; Zappasodi, F.; Rossini, P.M.P.M.; Tecchio, F. Optimization of an independent component analysis approach for artifact identification and removal in magnetoencephalographic signals. Clin. Neurophysiol. 2004, 115, 1220–1232. [Google Scholar] [CrossRef]
- Ferracuti, F.; Casadei, V.; Marcantoni, I.; Iarlori, S.; Burattini, L.; Monteriù, A.; Porcaro, C. A functional source separation algorithm to enhance error-related potentials monitoring in noninvasive brain-computer interface. Comput. Methods Programs Biomed. 2020, 191, 105419. [Google Scholar] [CrossRef]
- Porcaro, C.; Coppola, G.; Lorenzo, G.D.; Zappasodi, F.; Siracusano, A.; Pierelli, F.; Rossini, P.M.; Tecchio, F.; Seri, S. Hand somatosensory subcortical and cortical sources assessed by functional source separation: An EEG study. Hum. Brain Mapp. 2009, 30, 660–674. [Google Scholar] [CrossRef]
- Porcaro, C.; Medaglia, M.T.; Krott, A. Removing speech artifacts from electroencephalographic recordings during overt picture naming. Neuroimage 2015, 105, 171–180. [Google Scholar] [CrossRef]
- Hou, Y.; Jia, S.; Member, S.; Zhang, S.; Lun, X.; Shi, Y.; Li, Y.; Yang, H.; Zeng, R.; Lv, J. Deep Feature Mining via Attention-based BiLSTM-GCN for Human Motor Imagery Recognition. arXiv 2020, arXiv:2005.00777. [Google Scholar]
- Reddy, P.P. Mind-Reading AI: Re-Create Scenario from Brain Database. EasyChair 2019, 1774. [Google Scholar]
- Zhang, X.; Yao, L.; Zhang, S.; Kanhere, S.; Michael, S.; Liu, Y. Internet of Things Meets Brain-Computer Interface: A Unified Deep Learning Framework for Enabling Human-Thing Cognitive Interactivity. IEEE Internet Things J. 2015, 14, 2084–2092. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ma, Z.; Zheng, H.; Li, T.; Chen, K.; Wang, X.; Liu, C.; Xu, L.; Wu, X.; Lin, D.; et al. The combination of brain-computer interfaces and artificial intelligence: Applications and challenges. Ann. Transl. Med. 2020, 8, 712. [Google Scholar] [CrossRef] [PubMed]
- Livingstone, D.J. Artificial Neural Networks: Methods and Applications; Humana Press: Totowa, NJ, USA, 2008. [Google Scholar]
- Zhang, L.; Wang, M.; Liu, M.; Zhang, D. A Survey on Deep Learning for Neuroimaging-Based Brain Disorder Analysis. Front. Neurosci. 2020, 14, 779. [Google Scholar] [CrossRef]
- Botalb, A.; Moinuddin, M.; Al-Saggaf, U.M.; Ali, S.S.A. Contrasting Convolutional Neural Network (CNN) with Multi-Layer Perceptron (MLP) for Big Data Analysis. In Proceedings of the 2018 International Conference on Intelligent and Advanced System (ICIAS), Kuala Lumpur, Malaysia, 13–14 August 2018. [Google Scholar]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; Mcalpine, D.; Zhang, Y. A Survey on Deep Learning based Brain Computer Interface: Recent Advances and New Frontiers. arXiv 2019, arXiv:1905.04149. [Google Scholar]
- Roy, Y.; Banville, H.; Albuquerueq, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep Learning-Based Electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 51001. [Google Scholar] [CrossRef]
- Gordon, J.; Hernández-Lobato, J.M. Combining deep generative and discriminative models for Bayesian semi-supervised learning. Pattern Recognit. 2020, 100, 107156. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Zhang, W.; Chen, J.; Liu, C. Multimodal Classification with Deep Convolutional-Recurrent Neural Networks for Electroencephalography. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 767–776. [Google Scholar]
- Medaglia, M.T.; Tecchio, F.; Seri, S.; Di Lorenzo, G.; Rossini, P.M.; Porcaro, C. Contradiction in universal and particular reasoning. Hum. Brain Mapp. 2009, 30, 4187–4197. [Google Scholar] [CrossRef] [Green Version]
- Abo Alzahab, N.; Alimam, H.; Alnahhas, M.H.D.S.; Alarja, A.; Marmar, Z. Determining the optimal feature for two classes Motor-Imagery Brain-Computer Interface (L/R-MI-BCI) systems in different binary classifiers. Int. J. Mech. Mechatron. Eng. 2019, 19, 132–150. [Google Scholar]
- Sakhavi, S.; Guan, C.; Yan, S. Parallel convolutional-linear neural network for motor imagery classification. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 2736–2740. [Google Scholar]
- Lotte, F.; Congedo, M.; Lécuyer, A.; Lamarche, F.; Arnaldi, B. A Review of Classification Algorithms for EEG-based Brain-Computer Interfaces. J. Neural Eng. 2007, 4, R1–R13. [Google Scholar] [CrossRef]
- Yin, Z.; Zhao, M.; Wang, Y.; Yang, J.; Zhang, J. Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Comput. Methods Programs Biomed. 2017, 140, 93–110. [Google Scholar] [CrossRef]
- Jeong, J.; Yu, B.; Lee, D. Classification of Drowsiness Levels Based on a Deep Spatio-Temporal Convolutional Bidirectional LSTM Network Using Electroencephalography Signals. Brain Sci. 2019, 9, 348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Porcaro, C.; Ostwald, D.; Hadjipapas, A.; Barnes, G.R.; Bagshaw, A.P. The relationship between the visual evoked potential and the gamma band investigated by blind and semi-blind methods. Neuroimage 2011, 56, 1059–1071. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porcaro, C.; Tecchio, F. Semi-blind Functional Source Separation Algorithm from Non-invasive Electrophysiology to Neuroimaging. In Blind Source Separation; Springer: Berlin/Heidelberg, Germany, 2014; pp. 521–551. ISBN 9783642550164. [Google Scholar]
- Castellanos, N.P.; Makarov, V.A. Recovering EEG brain signals: Artifact suppression with wavelet enhanced independent component analysis. J. Neurosci. Methods 2006, 158, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 1, pp. 448–456. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; NeurIPS: Montréal, QC, Canada, 2018; pp. 2483–2493. [Google Scholar]
- Srivastava, N.; Hinton, G.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfittin. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Di Pino, G.; Porcaro, C.; Tombini, M.; Assenza, G.; Pellegrino, G.; Tecchio, F.; Rossini, P.M. A neurally-interfaced hand prosthesis tuned inter-hemispheric communication. Restor. Neurol. Neurosci. 2012, 30, 407–418. [Google Scholar] [CrossRef]
- Kumar, G.; Bhatia, P.K. A detailed review of feature extraction in image processing systems. In Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 5–12. [Google Scholar]
- Tombini, M.; Rigosa, J.; Zappasodi, F.; Porcaro, C.; Citi, L.; Carpaneto, J.; Rossini, P.M.; Micera, S. Combined analysis of cortical (EEG) and nerve stump signals improves robotic hand control. Neurorehabil. Neural Repair 2012, 26, 275–281. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A Survey of Deep Neural Network Architectures and Their Applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Shaheen, F.; Verma, B.; Asaduddoula, M. Impact of Automatic Feature Extraction in Deep Learning Architecture. In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, QLD, Australia, 30 November–2 December 2016. [Google Scholar]
- Tang, X.; Yang, J.; Wan, H. A Hybrid SAE and CNN Classifier for Motor Imagery EEG Classification. In Proceedings of the Computer Science On-line Conference, Zlin, Czech Republic, 24–27 April 2019; Volume 1, pp. 265–278. [Google Scholar]
- Dai, M.; Zheng, D.; Na, R.; Wang, S.; Zhang, S. EEG classification of motor imagery using a novel deep learning framework. Sensors 2019, 19, 551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Jiang, D.; Zhang, Y.; Zhang, P. Emotion recognition from spatiotemporal EEG representations with hybrid convolutional recurrent neural networks via wearable multi-channel headset. Comput. Commun. 2020, 154, 58–65. [Google Scholar] [CrossRef]
- Maryanovsky, D.; Mousavi, M.; Moreno, N.G.; De Sa, V.R. Csp-NN: A Convolutional Neural Network Implementation of Common Spatial Patterns. In Proceedings of the GBCIC, Graz, Austria, 18–22 September 2017. [Google Scholar]
- Abbaspour, S.; Fotouhi, F.; Sedaghatbaf, A.; Fotouhi, H.; Vahabi, M.; Linden, M. A comparative analysis of hybrid deep learning models for human activity recognition. Sensors 2020, 20, 5707. [Google Scholar] [CrossRef] [PubMed]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [Green Version]
- Maddula, R.K.; Stivers, J.; Mousavi, M.; Ravindran, S.; De Sa, V.R. Deep recurrent convolutional neural networks for classifying P300 BCI signals. In Proceedings of the Proceedings of the 7th Graz Brain-Computer Interface Conference 2017, Graz, Austria, 18–22 September 2017. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A Survey of Optimization Methods from a Machine Learning Perspective. IEEE Trans. Cybern. 2020, 50, 3668–3681. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- McHugh, M.L. interrater reliability: The kappa statistic. Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Advances in Neural Information Processing Systems; NIPS: Long Beach, CA, USA, 2017; pp. 6627–6638. [Google Scholar]
- Liu, Q.; Farahibozorg, S.; Porcaro, C.; Wenderoth, N.; Mantini, D. Detecting large-scale networks in the human brain using high-density electroencephalography. Hum. Brain Mapp. 2017, 38, 4631–4643. [Google Scholar] [CrossRef] [Green Version]
- Mantini, D.; Perrucci, M.G.; Cugini, S.; Ferretti, A.; Romani, G.L.; Del Gratta, C. Complete artifact removal for EEG recorded during continuous fMRI using independent component analysis. Neuroimage 2007, 34, 598–607. [Google Scholar] [CrossRef]
- Guarnieri, R.; Marino, M.; Barban, F.; Ganzetti, M.; Mantini, D. Online EEG artifact removal for BCI applications by adaptive spatial filtering. J. Neural Eng. 2018, 15, 56009. [Google Scholar] [CrossRef]
- Hsu, S.H.; Mullen, T.R.; Jung, T.P.; Cauwenberghs, G. Real-Time Adaptive EEG Source Separation Using Online Recursive Independent Component Analysis. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 309–319. [Google Scholar] [CrossRef] [PubMed]
- Pion-Tonachini, L.; Hsu, S.H.; Chang, C.Y.; Jung, T.P.; Makeig, S. Online Automatic Artifact Rejection using the Real-time EEG Source-mapping Toolbox (REST). In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Rostam, Z.R.K.; Mahmood, S.A. Classification of Brainwave Signals Based on Hybrid Deep Learning and an Evolutionary Algorithm. J. Zankoy Sulaimani 2019, 21, 35–44. [Google Scholar] [CrossRef]
- Saidutta, Y.M.; Zou, J.; Fekri, F. Increasing the learning Capacity of BCI Systems via CNN-HMM models. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1777–1780. [Google Scholar]
- Tan, C.; Sun, F.; Zhang, W. Deep transfer learning for EEG-based brain computer interface. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 916–920. [Google Scholar]
- Zhang, D.; Yao, L.; Chen, K.; Member, S.; Monaghan, J. A Convolutional Recurrent Attention Model for Subject-Independent EEG Signal Analysis. IEEE Signal Process. Lett. 2019, 26, 715–719. [Google Scholar] [CrossRef]
- Kohler, J.; Daneshmand, H.; Lucchi, A.; Hofmann, T.; Zhou, M.; Neymeyr, K. Exponential convergence rates for Batch Normalization: The power of length-direction decoupling in non-convex optimization. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS 2019), Okinawa, Japan, 16–18 April 2019. [Google Scholar]
- Yang, G.; Pennington, J.; Rao, V.; Sohl-Dickstein, J.; Schoenholz, S.S. A mean field theory of batch normalization. arXiv 2019, arXiv:1902.08129. [Google Scholar]
- Gouveia, A.; Correia, M. A systematic approach for the application of restricted boltzmann machines in network intrusion detection. In Advances in Computational Intelligence; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10305, pp. 432–446. [Google Scholar]
- Raza, H.; Chowdhury, A.; Bhattacharyya, S.; Samothrakis, S. Single-Trial EEG Classification with EEGNet and Neural Structured Learning for Improving BCI Performance. In Proceedings of the International Joint Conference on Neural Networks (IJCNN 2020), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Kuhner, D.; Fiederer, L.D.J.; Aldinger, J.; Burget, F.; Volker, M.; Schirrmeister, R.T.; Do, C.; Bodecker, J.; Nebel, B.; Burgard, W. Deep Learning Based BCI Control of a Robotic Service Assistant Using Intelligent Goal Formulation. bioRxiv 2018. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Wang, T.; Du, Y.; Dai, Y. Motor imagery EEG recognition with KNN-based smooth auto-encoder. Artif. Intell. Med. 2019, 101, 101747. [Google Scholar] [CrossRef]
- Stathakis, D. How many hidden layers and nodes? Int. J. Remote Sens. 2009, 30, 2133–2147. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Huang, C.; Gu, T.; Yang, Z.; Liu, Y. DeepKey: An EEG and Gait Based Dual-Authentication System. arXiv 2017, arXiv:1706.01606. [Google Scholar]
- Yang, Y.; Wu, Q.; Fu, Y.; Chen, X. Continuous convolutional neural network with 3D input for EEG-based emotion recognition. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; pp. 433–443. [Google Scholar]
- Zhang, X.; Yao, L.; Sheng, Q.Z.; Kanhere, S.S.; Gu, T.; Zhang, D.; Zhang, X.; Yao, L.; Sheng, Q.Z.; Kanhere, S.S.; et al. Converting Your Thoughts to Texts: Enabling Brain Typing via Deep Feature Learning of EEG Signals. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom) Converting, Athens, Greece, 19–23 March 2018; pp. 1–10. [Google Scholar]
- Yang, J.; Yao, S.; Wang, A.J. Deep Fusion Feature Learning Network for MI-EEG Classification. IEEE Access 2018, 6, 79050–79059. [Google Scholar] [CrossRef]
- Ma, X.; Qiu, S.; Du, C.; Xing, J.; He, H. Improving EEG-Based Motor Imagery Classification via Spatial and Temporal Recurrent Neural Networks. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Societ, Honolulu, HI, USA, 18–21 July 2018; pp. 1903–1906. [Google Scholar]
- Li, J. A Hybrid Network for ERP Detection and Analysis Based on Restricted Boltzmann Machine. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 563–572. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Qiu, M.; Wang, Y.; Xiaowei, C. Emotion Recognition from Multi-Channel EEG through Parallel Convolutional Recurrent Neural Network. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN) 2018, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Chao, H.; Zhi, H.; Dong, L.; Liu, Y. Recognition of Emotions Using Multichannel EEG Data and DBN-GC-Based Ensemble Deep Learning Framework. Comput. Intell. Neurosci. 2018, 2018, 9750904. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Z.; Gao, X.; Wang, Y.; Li, J.; Xu, H. Deep Convolutional Neural Networks for mental load classification based on EEG data. Pattern Recognit. 2018, 76, 582–595. [Google Scholar] [CrossRef]
- Zhang, R.; Zong, Q.; Dou, L.; Zhao, X. A novel hybrid deep learning scheme for four-class motor imagery classification. J. Neural Eng. 2019, 16, 66004. [Google Scholar] [CrossRef] [PubMed]
- Riyad, M.; Khalil, M.; Adib, A. Cross-Subject EEG Signal Classification with Deep Neural Networks Applied to Motor Imagery. In Proceedings of the International Conference on Mobile, Secure, and Programmable Networking, Mohammedia, Morocco, 23–24 April 2019; Springer International Publishing: Cham, Switzerland; pp. 124–139. [Google Scholar]
- Qiao, W.; Bi, X. Deep Spatial-Temporal Neural Network for Classification of EEG-Based Motor Imagery. In Proceedings of the 2019 International Conference on Artificial Intelligence and Computer Science, Wuhan, China, 12–13 July 2019; pp. 265–272. [Google Scholar]
- Saha, P.; Fels, S. Hierarchical Deep Feature Learning For Decoding Imagined Speech From EEG. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 10019–10020. [Google Scholar]
- Ditthapron, A.; Banluesombatkul, N.; Ketrat, S.; Chuangsuwanich, E.; Wilaiprasitporn, T. Universal Joint Feature Extraction for P300 EEG Classification Using Multi-Task Autoencoder. IEEE Access 2019, 7, 68415–68428. [Google Scholar] [CrossRef]
- Kaushik, P.; Gupta, A.; Roy, P.P.; Dogra, D.P. EEG-Based Age and Gender Prediction Using Deep BLSTM-LSTM Network Model. IEEE Sens. J. 2019, 19, 2634–2641. [Google Scholar] [CrossRef]
- Kuhner, D.; Fiederer, L.D.J.; Aldinger, J.; Burget, F.; Völker, M.; Schirrmeister, R.T.; Do, C.; Boedecker, J.; Nebel, B.; Ball, T.; et al. A service assistant combining autonomous robotics, flexible goal formulation, and deep-learning-based brain–computer interfacing. Rob. Auton. Syst. 2019, 116, 98–113. [Google Scholar] [CrossRef]
- Qiao, W.; Bi, X. Ternary-task convolutional bidirectional neural turing machine for assessment of EEG-based cognitive workload. Biomed. Signal Process. Control 2019, 57, 101745. [Google Scholar] [CrossRef]
- Wu, D.; Wan, H.; Liu, S.; Yu, W.; Jin, Z.; Wang, D. DeepBrain: Towards Personalized EEG Interaction through Attentional and Embedded LSTM Learning. arXiv 2020, arXiv:2002.02086. [Google Scholar]
- Ghosh, L.; Saha, S.; Konar, A. Bi-directional Long Short-Term Memory model to analyze psychological effects on gamers. Appl. Soft Comput. J. 2020, 95, 106573. [Google Scholar] [CrossRef]
- Chen, J.; Yu, Z.; Gu, Z. Semi-supervised Deep Learning in Motor Imagery-Based Brain- Computer Interfaces with Stacked Variational Autoencode. J. Phys. Conf. Ser. 2020, 1631, 12007. [Google Scholar] [CrossRef]
- Cho, J.; Hwang, H. Spatio-Temporal Representation of an Electoencephalogram for Emotion Recognition Using a Three-dimensional Network Neural. Sensors 2020, 20, 3491. [Google Scholar] [CrossRef] [PubMed]
- An, S.; Kim, S.; Chikontwe, P.; Park, S.H. Few-Shot Relation Learning with Attention for EEG-based Motor Imagery Classification. arXiv 2020, arXiv:2003.01300. [Google Scholar]
- Jeong, J.; Shim, K.; Kim, D.; Lee, S. Brain-Controlled Robotic Arm System based on Multi-Directional CNN-BiLSTM Network using EEG Signals. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1226–1238. [Google Scholar] [CrossRef]
- Fadel, W.; Wahdow, M.; Kollod, C.; Marton, G.; Ulbert, I. Chessboard EEG Images Classification for BCI Systems Using Deep Neural Network. In Proceedings of the International Conference on Bio-inspired Information and Communication Technologies, Shanghai, China, 7–8 July 2020; pp. 97–104. [Google Scholar]
- Zhang, K.; Xu, G.; Han, Z.; Ma, K.; Zheng, X.; Chen, L.; Duan, N.; Zhang, S. Data Augmentation for Motor Imagery Signal Classification Based on a Hybrid Neural Network. Sensors 2020, 20, 4485. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zong, Q.; Dou, L.; Zhao, X.; Tang, Y.; Li, Z. Hybrid deep neural network using transfer learning for EEG motor imagery decoding. Biomed. Signal Process. Control 2020, 63, 102144. [Google Scholar] [CrossRef]
- Das Chakladar, D.; Dey, S.; Roy, P.P.; Dogra, D.P. EEG-based mental workload estimation using deep BLSTM-LSTM network and evolutionary algorithm. Biomed. Signal Process. Control 2020, 60, 101989. [Google Scholar] [CrossRef]
- Wang, L.; Huang, W.; Yang, Z.; Zhang, C. Temporal-spatial-frequency depth extraction of brain-computer interface based on mental tasks. Biomed. Signal Process. Control 2020, 58, 101845. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Wang, X.; Zhang, W.; Zhang, S.; Liu, Y. Know Your Mind: Adaptive Cognitive Activity Recognition with Reinforced CNN. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 896–905. [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzahab, N.A.; Apollonio, L.; Di Iorio, A.; Alshalak, M.; Iarlori, S.; Ferracuti, F.; Monteriù, A.; Porcaro, C. Hybrid Deep Learning (hDL)-Based Brain-Computer Interface (BCI) Systems: A Systematic Review. Brain Sci. 2021, 11, 75. https://doi.org/10.3390/brainsci11010075
Alzahab NA, Apollonio L, Di Iorio A, Alshalak M, Iarlori S, Ferracuti F, Monteriù A, Porcaro C. Hybrid Deep Learning (hDL)-Based Brain-Computer Interface (BCI) Systems: A Systematic Review. Brain Sciences. 2021; 11(1):75. https://doi.org/10.3390/brainsci11010075
Chicago/Turabian StyleAlzahab, Nibras Abo, Luca Apollonio, Angelo Di Iorio, Muaaz Alshalak, Sabrina Iarlori, Francesco Ferracuti, Andrea Monteriù, and Camillo Porcaro. 2021. "Hybrid Deep Learning (hDL)-Based Brain-Computer Interface (BCI) Systems: A Systematic Review" Brain Sciences 11, no. 1: 75. https://doi.org/10.3390/brainsci11010075