Pedestrian Flow Tracking and Statistics of Monocular Camera Based on Convolutional Neural Network and Kalman Filter


Abstract
:1. Introduction
2. Related Work
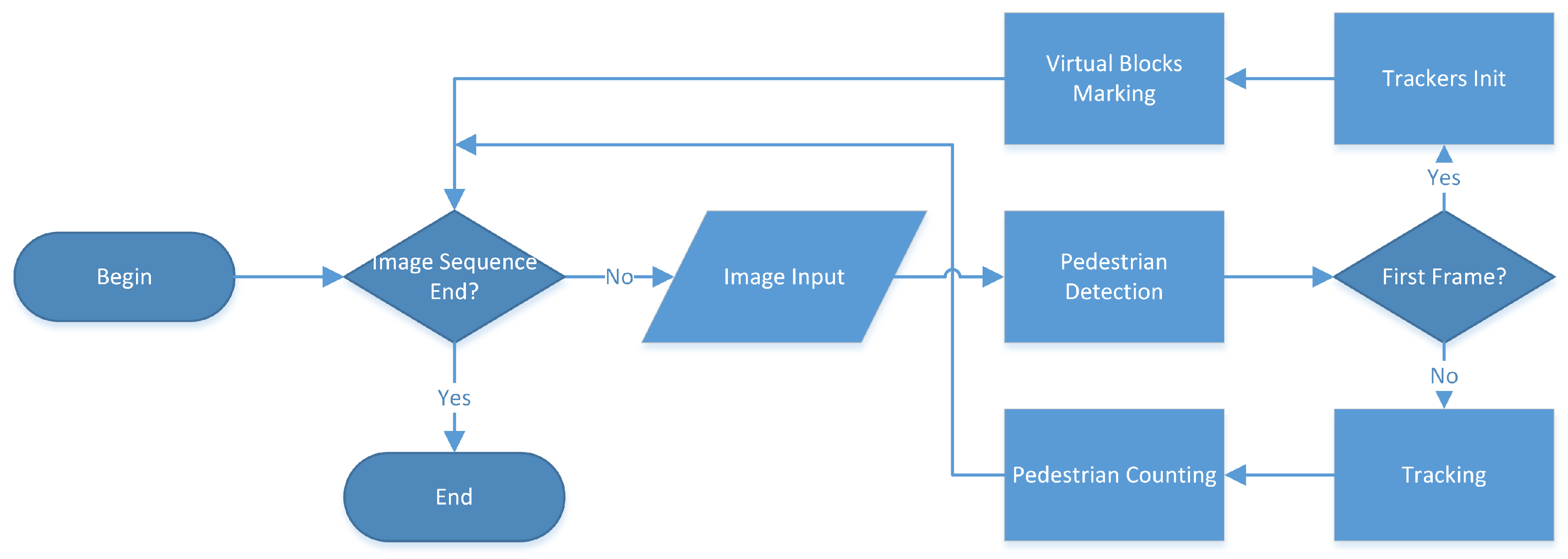
3. Methodology
3.1. Pedestrian Detection
3.2. Multi- Pedestrian Tracking
3.3. Pedestrian Counting
4. Experiment
4.1. The Performance of Pedestrian Flow Statistics Algorithms in Real Scene
4.2. The Performance of Tracking-by-Detection Algorithm Compared with Other Algorithms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Del Pizzo, L.; Foggia, P.; Greco, A.; Percannella, G.; Vento, M. Counting people by RGB or depth overhead cameras. Pattern Recognit. Lett. 2016, 81, 41–50. [Google Scholar] [CrossRef]
- Coşkun, A.; Kara, A.; Parlaktuna, M.; Ozkan, M.; Parlaktuna, O. People counting system by using kinect sensor. In Proceedings of the 2015 IEEE International Symposium on Innovations in Intelligent SysTems and Applications (INISTA), Taipei, Taiwan, 2–4 September 2015; pp. 1–7. [Google Scholar]
- Verma, N.K.; Dev, R.; Maurya, S.; Dhar, N.K.; Agrawal, P. People Counting with Overhead Camera Using Fuzzy-Based Detector. In Computational Intelligence: Theories, Applications and Future Directions—Volume I; Springer: Berlin, Germany, 2019; pp. 589–601. [Google Scholar]
- Kopaczewski, K.; Szczodrak, M.; Czyzewski, A.; Krawczyk, H. A method for counting people attending large public events. Multimed. Tools Appl. 2015, 74, 4289–4301. [Google Scholar] [CrossRef]
- Beymer, D. Person counting using stereo. In Proceedings of the Workshop on Human Motion, Austin, TX, USA, 7–8 December 2000; pp. 127–133. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; p. 2246. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A powerful random technique to estimate the background in video sequences. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2009, Taipei, Taiwan, 19–24 April 2009; pp. 945–948. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR 2005, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhou, C.; Yuan, J. Bi-box Regression for Pedestrian Detection and Occlusion Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 6, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference On Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Hu, W.; Li, X.; Luo, W.; Zhang, X.; Maybank, S.; Zhang, Z. Single and multiple object tracking using log-Euclidean Riemannian subspace and block-division appearance model. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2420–2440. [Google Scholar] [PubMed]
- Zhang, L.; van der Maaten, L. Structure preserving object tracking. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1838–1845. [Google Scholar]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef] [PubMed]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Robust tracking-by-detection using a detector confidence particle filter. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1515–1522. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; Van Gool, L. Robust multiperson tracking from a mobile platform. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1831–1846. [Google Scholar] [CrossRef] [PubMed]
- Choi, W.; Pantofaru, C.; Savarese, S. A general framework for tracking multiple people from a moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1577–1591. [Google Scholar] [CrossRef] [PubMed]
- Khan, Z.; Balch, T.; Dellaert, F. MCMC-based particle filtering for tracking a variable number of interacting targets. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1805–1819. [Google Scholar] [CrossRef] [PubMed]
- Kuo, C.H.; Huang, C.; Nevatia, R. Multi-target tracking by on-line learned discriminative appearance models. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 685–692. [Google Scholar]
- Milan, A.; Roth, S.; Schindler, K. Continuous energy minimization for multitarget tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef] [PubMed]
- Ullah, M.; Cheikh, F.A.; Imran, A.S. Hog based real-time multi-target tracking in bayesian framework. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 416–422. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Kryjak, T.; Komorkiewicz, M.; Gorgon, M. Hardware-software implementation of vehicle detection and counting using virtual detection lines. In Proceedings of the 2014 Conference on IEEE Design and Architectures for Signal and Image Processing (DASIP), Madrid, Spain, 8–10 October 2014; pp. 1–8. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-nms—Improving object detection with one line of code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the IEEE International Conference On Computer Vision, RegióN Metropolitana, Chile, 11–18 December 2015; pp. 4705–4713. [Google Scholar]
- Kim, H.U.; Kim, C.S. CDT: Cooperative detection and tracking for tracing multiple objects in video sequences. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 851–867. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on. IEEE Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision↑ | Recall↑ | F1-Score↑ | TP↑ | FP↓ | FN↓ | mAP↑ | |
|---|---|---|---|---|---|---|---|
| detector (coco) | 0.87 | 0.67 | 0.76 | 17786 | 2644 | 8887 | 72.88% |
| detector (coco + new data) | 0.86 | 0.79 | 0.82 | 21156 | 3550 | 5517 | 83.39% |
| Sequence | Count Result | GT | FP | FN | TP | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| Seq1 | 552 | 567 | 21 | 36 | 531 | 96.20% | 93.65% | 94.91% |
| Seq2 | 411 | 412 | 18 | 19 | 393 | 95.62% | 95.39% | 95.50% |
| Seq3 | 571 | 572 | 21 | 22 | 550 | 96.32% | 96.15% | 96.24% |
| Seq4 | 923 | 955 | 18 | 50 | 905 | 98.05% | 94.76% | 96.38% |
| Seq5 | 669 | 693 | 16 | 40 | 653 | 97.61% | 94.23% | 95.89% |
| TOTAL | 3126 | 3199 | 94 | 167 | 3032 | 96.99% | 94.78% | 95.87% |
| Measure | Better | Description |
|---|---|---|
| MOTA | higher | Multiple Object Tracking Accuracy. |
| MOTP | higher | Multiple Object Tracking Precision. |
| IDF1 | higher | The ratio of correctly identified detections. |
| MT | higher | Mostly tracked targets. |
| ML | lower | Mostly lost targets. |
| FP | lower | The total number of false positives. |
| FN | lower | The total number of false negatives. |
| ID Sw. | lower | The total number of identity switches. |
| Sequence | Algorithm | MOTA | IDF1 | MOTP | MT | ML | FP | FN | ID Sw |
|---|---|---|---|---|---|---|---|---|---|
| TUD-Crossing | MDP_Subcnn | 78.9 | 74.5 | 76.7 | 0.692 | 0 | 32 | 195 | 6 |
| DMT | 70 | 56.3 | 73.3 | 0.615 | 0 | 73 | 229 | 29 | |
| Sort | 67.5 | 57.6 | 74.5 | 0.462 | 0.077 | 32 | 308 | 18 | |
| PFS(our) | 74.6 | 49.9 | 76.2 | 0.615 | 0 | 49 | 193 | 38 | |
| PETS09-S2L2 | MDP_Subcnn | 47.5 | 36.8 | 72.6 | 0.071 | 0.095 | 341 | 4524 | 196 |
| DMT | 47.7 | 36.8 | 70.4 | 0.214 | 0.19 | 502 | 4429 | 113 | |
| Sort | 27.4 | 23.6 | 67.4 | 0 | 0.262 | 806 | 5958 | 240 | |
| PFS(our) | 56.7 | 32 | 74.4 | 0.19 | 0.048 | 358 | 3519 | 295 | |
| ETH-Jelmoli | MDP_Subcnn | 48.2 | 65.7 | 77.3 | 0.356 | 0.222 | 492 | 814 | 9 |
| DMT | 48.2 | 62.8 | 75 | 0.6 | 0.111 | 758 | 529 | 26 | |
| Sort | 39 | 52.9 | 74.1 | 0.2 | 0.289 | 439 | 1071 | 38 | |
| PFS(our) | 61.5 | 59 | 76.2 | 0.356 | 0.267 | 176 | 754 | 46 | |
| ETH-Linthescher | MDP_Subcnn | 63.9 | 67.1 | 77.1 | 0.244 | 0.31 | 495 | 2657 | 70 |
| DMT | 60.5 | 60.2 | 76.4 | 0.437 | 0.244 | 1425 | 1963 | 138 | |
| Sort | 52.2 | 54.5 | 73.8 | 0.147 | 0.406 | 397 | 3725 | 144 | |
| PFS(our) | 62.8 | 57.5 | 76.8 | 0.335 | 0.223 | 735 | 2374 | 215 | |
| ETH-Crossing | MDP_Subcnn | 63.8 | 76.5 | 79.5 | 0.192 | 0.269 | 64 | 293 | 6 |
| DMT | 59 | 54.7 | 81.5 | 0.308 | 0.308 | 169 | 221 | 21 | |
| Sort | 55.4 | 49.7 | 80.3 | 0.154 | 0.385 | 58 | 368 | 21 | |
| PFS(our) | 62.4 | 53.9 | 79.5 | 0.308 | 0.077 | 135 | 215 | 27 | |
| AVG-TownCentre | MDP_Subcnn | 49.5 | 64.5 | 70.1 | 0.389 | 0.155 | 1381 | 2106 | 121 |
| DMT | 45.5 | 54.6 | 68.5 | 0.283 | 0.274 | 653 | 3127 | 117 | |
| Sort | 27.2 | 45.1 | 67.4 | 0.058 | 0.279 | 1111 | 3930 | 162 | |
| PFS(our) | 47.5 | 59.7 | 69.5 | 0.372 | 0.115 | 1483 | 2094 | 178 | |
| ADL-Rundle-1 | MDP_Subcnn | 33.4 | 49.9 | 72.4 | 0.344 | 0 | 2899 | 3230 | 70 |
| DMT | 26 | 42.2 | 70.1 | 0.219 | 0.281 | 1697 | 5146 | 47 | |
| Sort | 20.3 | 31.5 | 72.5 | 0.188 | 0.375 | 1493 | 5812 | 108 | |
| PFS(our) | 39.8 | 38.6 | 73.8 | 0.25 | 0.094 | 1444 | 3998 | 164 | |
| ADL-Rundle-3 | MDP_Subcnn | 44.9 | 51.6 | 79.6 | 0.205 | 0.159 | 793 | 4752 | 56 |
| DMT | 43.3 | 45.4 | 75.4 | 0.295 | 0.136 | 1168 | 4517 | 84 | |
| Sort | 37.4 | 43.4 | 77 | 0.295 | 0.182 | 1498 | 4765 | 99 | |
| PFS(our) | 34.8 | 34.1 | 80 | 0.273 | 0.159 | 2012 | 4422 | 197 | |
| KITTI-16 | MDP_Subcnn | 50 | 66.6 | 70.3 | 0.353 | 0.059 | 262 | 566 | 22 |
| DMT | 44.7 | 60.5 | 69.3 | 0.235 | 0 | 232 | 690 | 19 | |
| Sort | 34.6 | 42.8 | 70.1 | 0.118 | 0.059 | 144 | 938 | 30 | |
| PFS(our) | 50 | 56.7 | 73.2 | 0.235 | 0.059 | 268 | 544 | 39 | |
| KITTI-19 | MDP_Subcnn | 40.9 | 61.8 | 68.1 | 0.242 | 0.081 | 1143 | 1965 | 51 |
| DMT | 45.7 | 55.5 | 72.8 | 0.306 | 0.097 | 884 | 1946 | 72 | |
| Sort | 29.1 | 46.4 | 68.4 | 0 | 0.258 | 855 | 2852 | 79 | |
| PFS(our) | 37.8 | 46.4 | 69 | 0.274 | 0.129 | 1327 | 1890 | 109 | |
| Venice-1 | MDP_Subcnn | 42.6 | 48.4 | 76 | 0.353 | 0.235 | 729 | 1867 | 21 |
| DMT | 32.4 | 38 | 70.9 | 0.294 | 0.412 | 527 | 2538 | 18 | |
| Sort | 24.7 | 24.4 | 69.7 | 0.118 | 0.471 | 485 | 2888 | 62 | |
| PFS(our) | 43.7 | 40.1 | 75.8 | 0.294 | 0.176 | 435 | 2071 | 64 | |
| TOTAL | MDP_Subcnn | 47.5 | 55.7 | 74.2 | 0.3 | 0.186 | 8631 | 22,969 | 628 |
| DMT | 44.5 | 49.2 | 72.9 | 0.347 | 0.221 | 8088 | 25,335 | 684 | |
| Sort | 33.4 | 40.4 | 72.1 | 0.117 | 0.309 | 7318 | 32,615 | 1001 | |
| PFS(our) | 48.1 | 45 | 74.7 | 0.327 | 0.15 | 8422 | 22,074 | 1372 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, M.; Luo, H.; Hui, B.; Chang, Z. Pedestrian Flow Tracking and Statistics of Monocular Camera Based on Convolutional Neural Network and Kalman Filter. Appl. Sci. 2019, 9, 1624. https://doi.org/10.3390/app9081624
He M, Luo H, Hui B, Chang Z. Pedestrian Flow Tracking and Statistics of Monocular Camera Based on Convolutional Neural Network and Kalman Filter. Applied Sciences. 2019; 9(8):1624. https://doi.org/10.3390/app9081624
Chicago/Turabian StyleHe, Miao, Haibo Luo, Bin Hui, and Zheng Chang. 2019. "Pedestrian Flow Tracking and Statistics of Monocular Camera Based on Convolutional Neural Network and Kalman Filter" Applied Sciences 9, no. 8: 1624. https://doi.org/10.3390/app9081624