Loop Closure Detection Based on Multi-Scale Deep Feature Fusion


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related work
3. Loop Closure Detection Algorithm Based on Multi-Scale Deep Feature Fusion
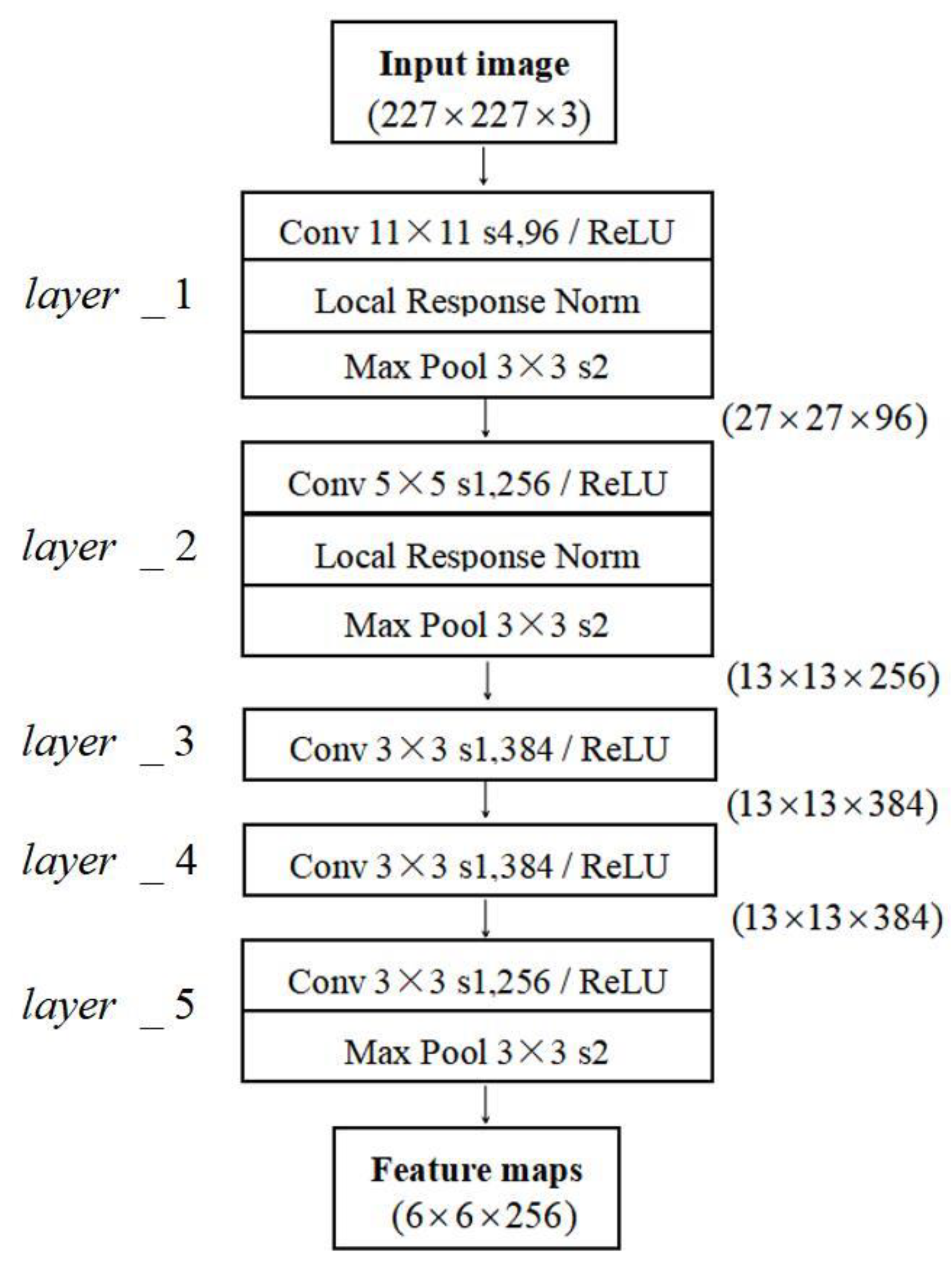
3.1. Feature Extraction Layer
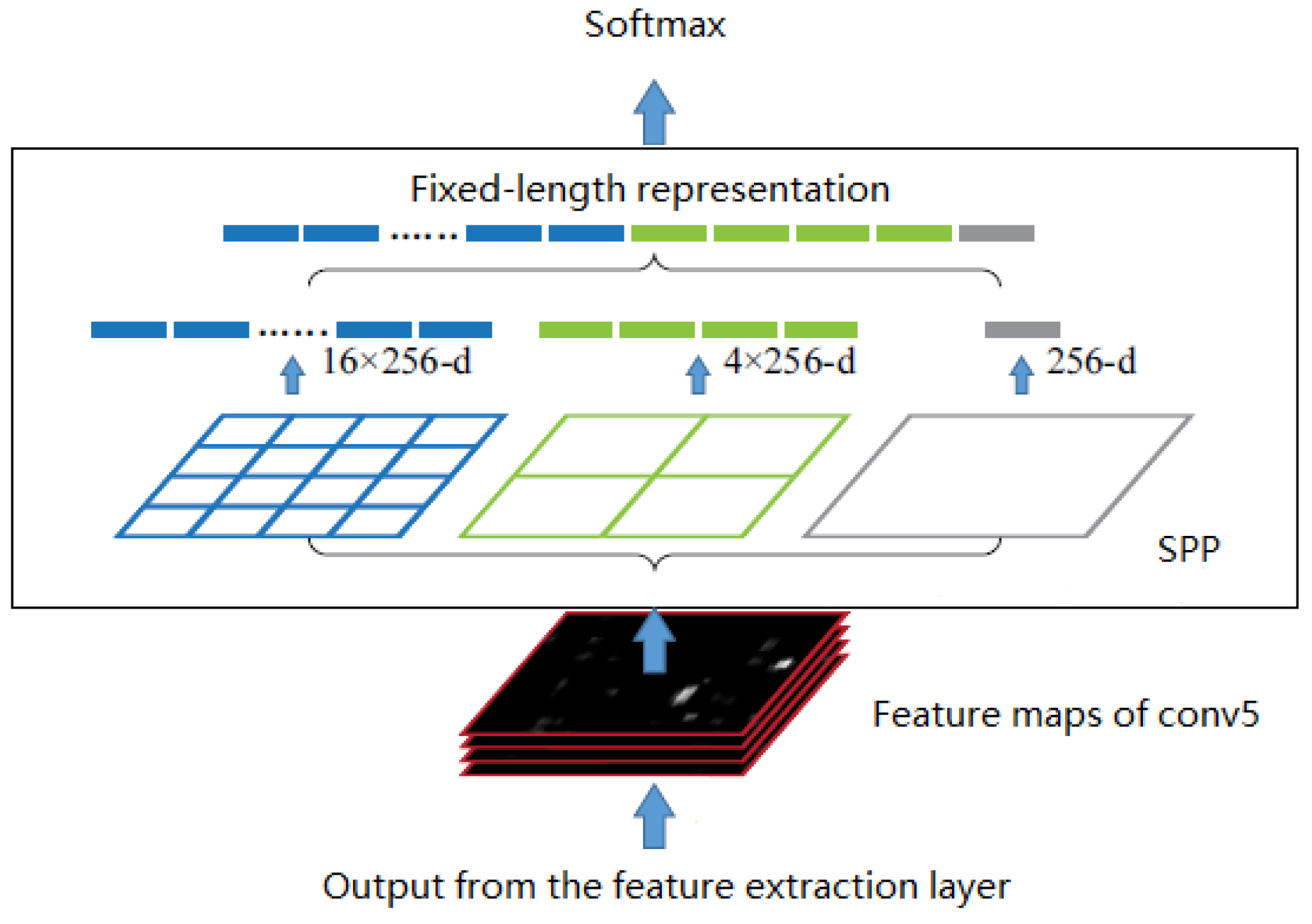
3.2. Feature Fusion Layer
3.3. Decision Layer
4. Parameter Training
4.1. Training Method
4.2. Model Training
5. Experiment
5.1. Dataset and Labeling
 in the key frame list. Assuming that their corresponding poses are which can be found in the ground truth, the relative translation of the two frames is , where represents the 2 norm of the translational part of the transformation matrix. If , the frame is added to the end of the key frame list.
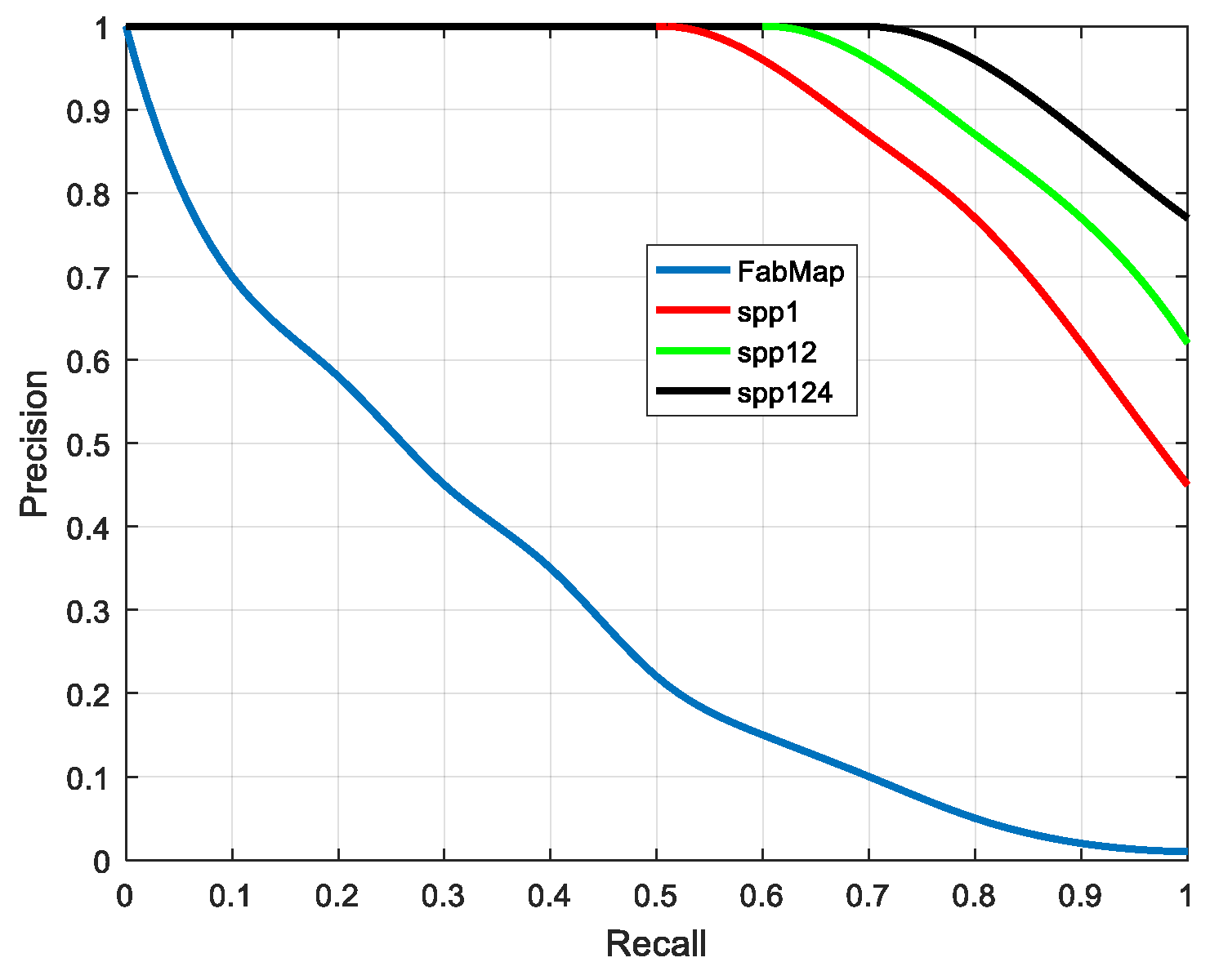
in the key frame list. Assuming that their corresponding poses are which can be found in the ground truth, the relative translation of the two frames is , where represents the 2 norm of the translational part of the transformation matrix. If , the frame is added to the end of the key frame list.5.2. Different layers of SPP
5.3. Similarity Measurement
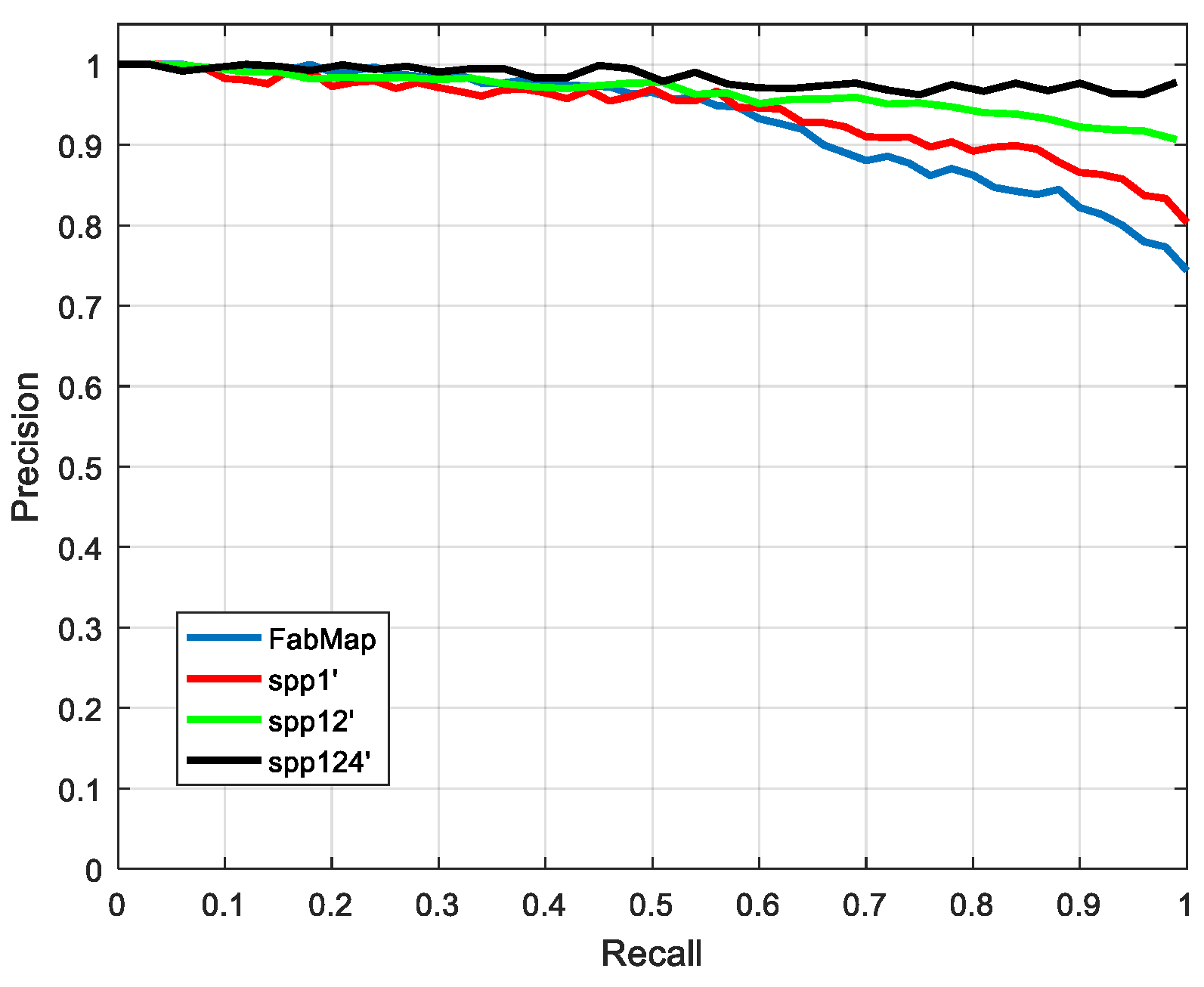
5.4. Illumination Changes
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar]
- Sivic, J. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H. SURF: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.; Sibley, G.; Newman, P.; Reid, I. A Constant-Time Efficient Stereo SLAM System. In Proceedings of the 20th British Machine Vision Conference (BMVC), London, UK, 7–10 September 2009; pp. 1–11. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Churchill, W.; Newman, P. Experience-based navigation for long-term localisation. Int. J. Robot. Res. 2013, 32, 1645–1661. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Ozuysal, M.; Strecha, C.; Fua, P. BRIEF: Computing a local binary descriptor very fast. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1281–1298. [Google Scholar] [CrossRef] [PubMed]
- Schindler, G.; Brown, M.; Szeliski, R. City-Scale Location Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Cummins, M.; Newman, P. Probabilistic appearance-based navigation and loop closing. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2042–2048. [Google Scholar]
- Glover, A.; Maddern, W.; Warren, M.; Stephanie, R.; Milford, M.; Wyeth, G. Openfabmap: An open source toolbox for appearance-based loop closure detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2007; pp. 4730–4735. [Google Scholar]
- Maddern, W.; Milford, M.; Wyeth, G. CAT-SLAM: Probabilistic localisation and mapping using a continuous appearance-based trajectory. Int. J. Robot. Res. 2012, 31, 429–451. [Google Scholar] [CrossRef]
- Dalai, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ulrich, I.; Nourbakhsh, I. Appearance-based place recognition for topological localization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 1023–1029. [Google Scholar]
- Oliva and, A. Torralba. Building the gist of a scene: The role of global image features in recognition. Vis. Percept. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar]
- Murillo, A.C.; Kosecka, J. Experiments in place recognition using gist panoramas. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV), Kyoto, Japan, 27 September–4 October 2009; pp. 2196–2203. [Google Scholar]
- Furgale, P.; Barfoot, T.D. Visual teach and repeat for long-range rover autonomy. J. Field Robot. 2010, 27, 534–560. [Google Scholar] [CrossRef]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Naseer, T.; Spinello, L.; Burgard, W.; Stachniss, C. Robust visual robot localization across seasons using network flows. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 2564–2570. [Google Scholar]
- Mcmanus, C.; Upcroft, B.; Newmann, P. Scene Signatures: Localised and Point-less Features for Localisation. Image Proc. 2014. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. Comput. Sci. 2014, 1–11. [Google Scholar]
- Wan, J.; Wang, D.Y. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 584–599. [Google Scholar]
- Gao, X.; Zhang, T. Unsupervised learning to detect loops using deep neural networks for visual SLAM system. Auton. Robot. 2017, 41, 1–18. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, T. Loop closure detection for visual slam systems using deep neural networks. In Proceedings of the Chinese Control Conference, Hangzhou: Chinese Association of Automation, Hangzhou, China, 28–30 July 2015; pp. 5851–5856. [Google Scholar]
- He, Y.L.; Chen, J.T.; Zeng, B. A Fast loop closure detection method based on lightweight convolutional neural network. Comput. Eng. 2018, 44, 182–187. [Google Scholar]
- Xia, Y.; Li, J.; Qi, L.; Fan, H. Loop closure detection for visual SLAM using PCANet features. In Proceedings of the IEEE International Joint Conference, Vancouver, BC, Canada, 24–29 July 2016; pp. 2274–2281. [Google Scholar]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proceedings of the IEEE International Conference, Lijiang, China, 20–25 April 2015; pp. 2238–2245. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]

















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Yuan, D.; Liu, C.; Wu, Q. Loop Closure Detection Based on Multi-Scale Deep Feature Fusion. Appl. Sci. 2019, 9, 1120. https://doi.org/10.3390/app9061120
Chen B, Yuan D, Liu C, Wu Q. Loop Closure Detection Based on Multi-Scale Deep Feature Fusion. Applied Sciences. 2019; 9(6):1120. https://doi.org/10.3390/app9061120
Chicago/Turabian StyleChen, Baifan, Dian Yuan, Chunfa Liu, and Qian Wu. 2019. "Loop Closure Detection Based on Multi-Scale Deep Feature Fusion" Applied Sciences 9, no. 6: 1120. https://doi.org/10.3390/app9061120