A Framework for Real-Time 3D Freeform Manipulation of Facial Video


Abstract
:1. Introduction
- acquiring a 3D model of a target;
- registering the 3D model and a 2D image of the target;
- manipulating the model using 3D geometric transformation or deformation; and
- texturing the manipulated model and rendering it on the image.
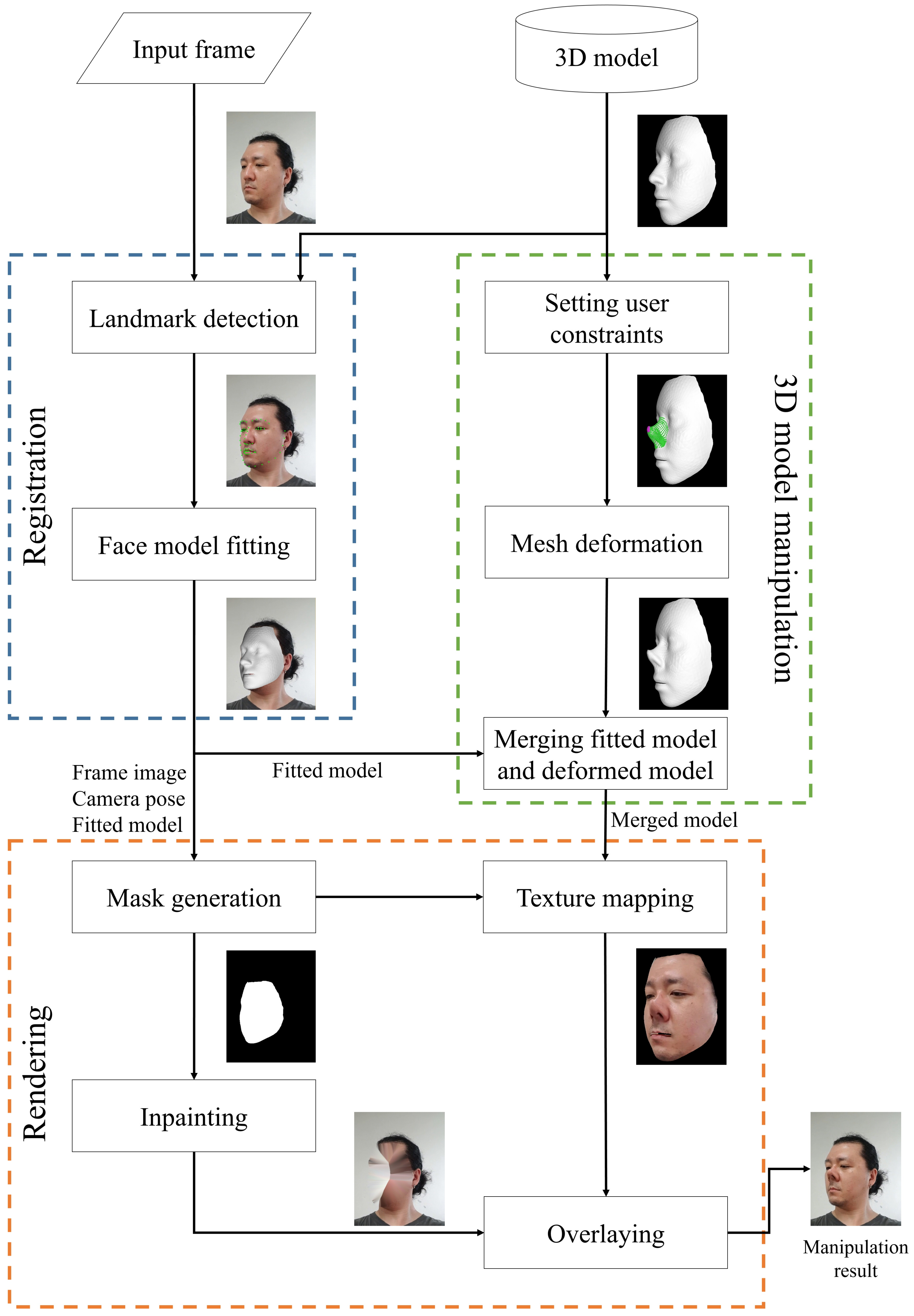
2. Facial Manipulation Framework
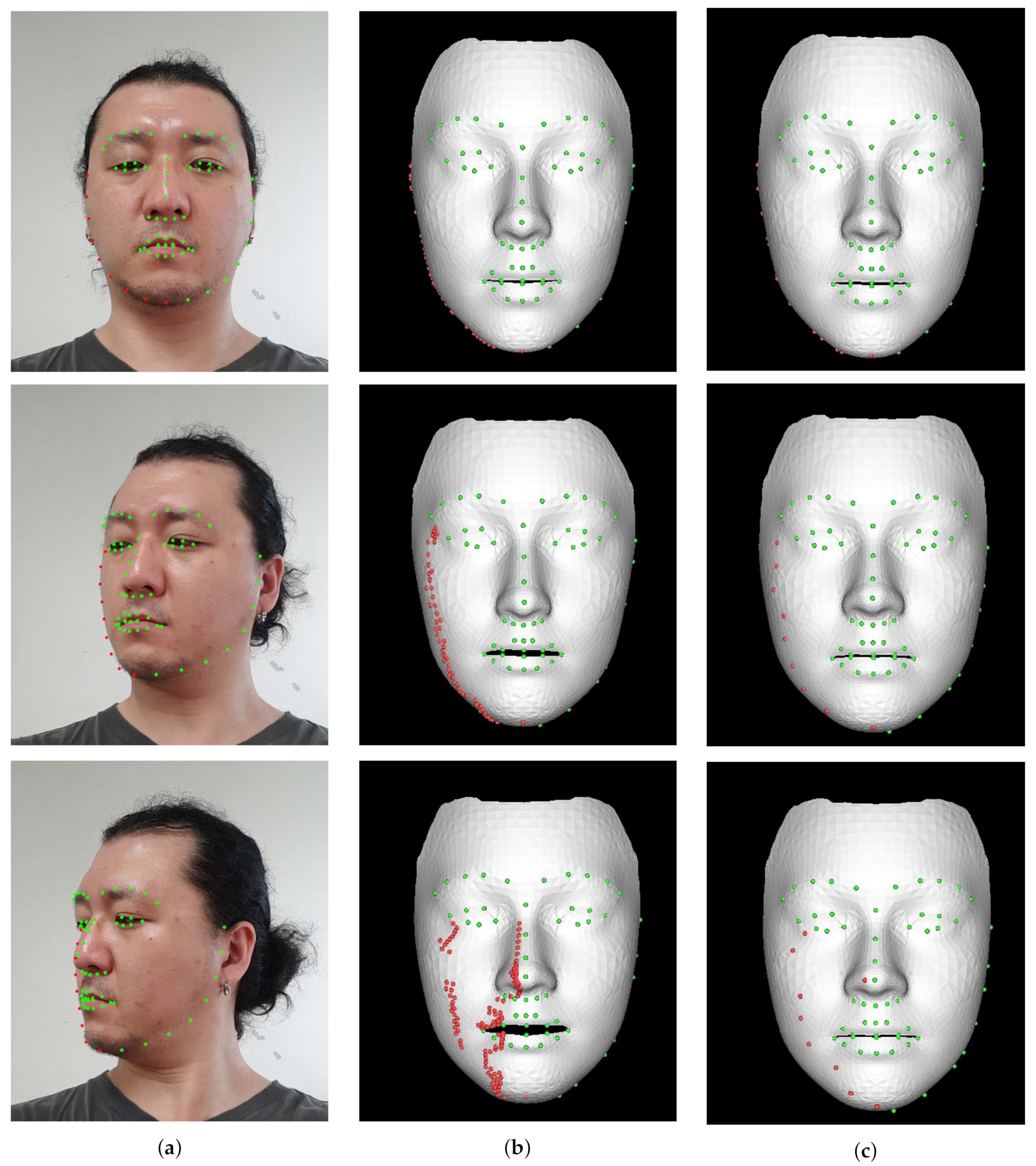
2.1. Registration
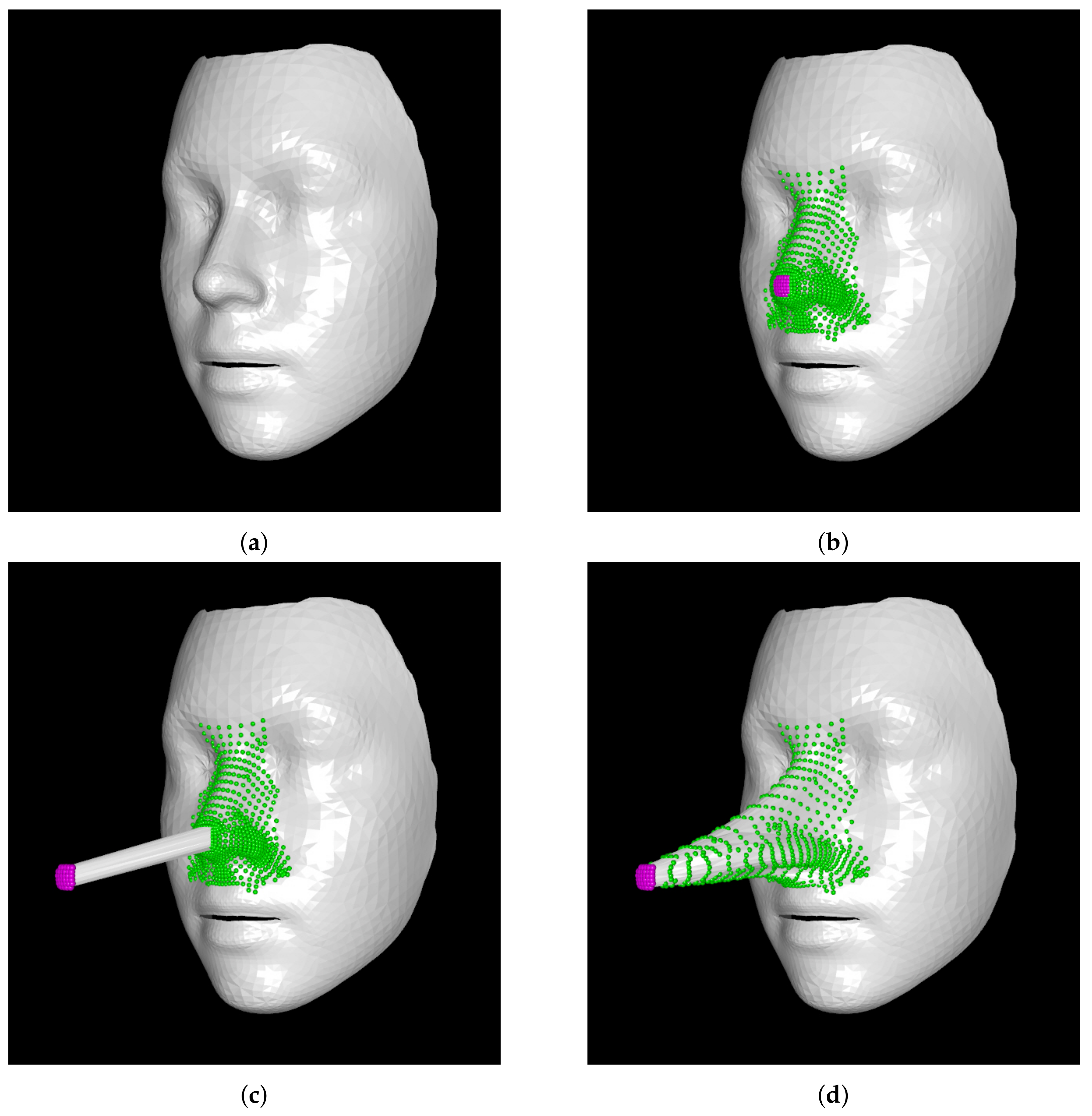
2.2. Manipulation
- static anchors (vertices to be fixed);
- handle anchors (vertices to be moved by a user); and
- ROI anchors (vertices of the region of interest, to which the deformation is propagated).
2.3. Rendering
3. Experimental Results
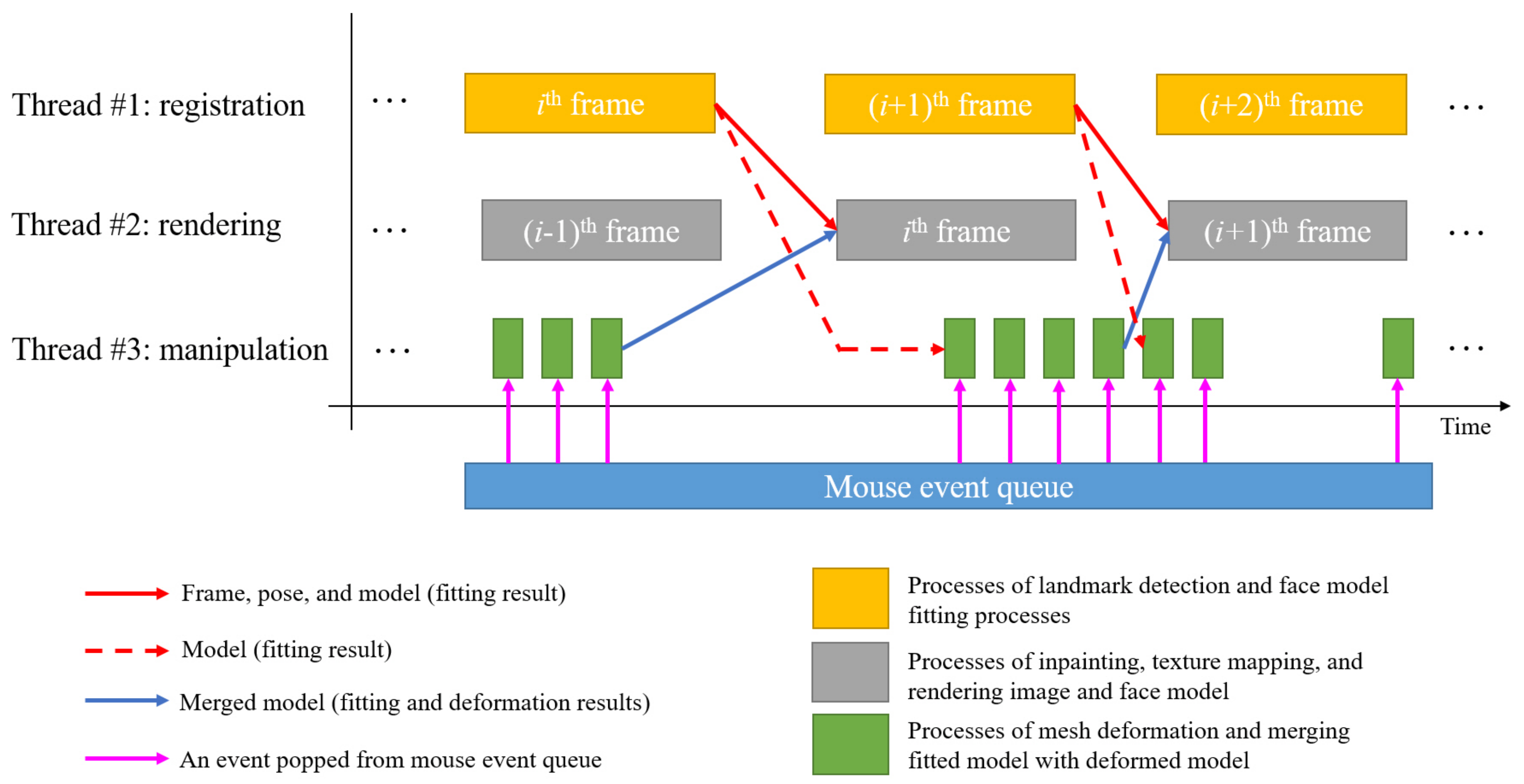
3.1. Implementation
3.2. Manipulation Results
3.3. Performance Evaluation and Comparison
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- FaceApp - Free Neural Face Transformation Filters. Available online: https://faceapp.com (accessed on 12 September 2019).
- Face Warp—Plastic Surgery. Available online: https://play.google.com/store/apps/details?id=com.hamsoft.face.follow (accessed on 12 September 2019).
- Wombatica Software—Create And Share. Available online: https://wombatica.com (accessed on 12 September 2019).
- Virtual Plastic Surgery Simulator. Available online: https://www.plastic-surgery-simulator.com (accessed on 12 September 2019).
- Snow. Available online: https://snow.me (accessed on 12 September 2019).
- Chung, H.V.; Lee, I.K. Image-based deformation of objects in real scenes. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 159–166. [Google Scholar]
- Park, J.; Seo, B.; Park, J. [Poster] Interactive deformation of real objects. In Proceedings of the 2014 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 10–12 September 2014; pp. 295–296. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, X.; Cheng, M.M.; Zhou, K.; Hu, S.M.; Mitra, N.J. Interactive Images: Cuboid Proxies for Smart Image Manipulation. ACM Trans. Graph. 2012, 31, 99:1–99:11. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, Z.; Shamir, A.; Hu, S.M.; Cohen-Or, D. 3Sweepp: Extracting Editable Objects from a Single Photo. ACM Trans. Graph. 2013, 32, 195:1–195:10. [Google Scholar] [CrossRef]
- Kholgade, N.; Simon, T.; Efros, A.; Sheikh, Y. 3D Object Manipulation in a Single Photograph Using Stock 3D Models. ACM Trans. Graph. 2014, 33, 127:1–127:12. [Google Scholar] [CrossRef]
- Haouchine, N.; Petit, A.; Roy, F.; Cotin, S. [POSTER] Deformed Reality: Proof of Concept and Preliminary Results. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR-Adjunct), Nantes, France, 9–13 October 2017; pp. 166–167. [Google Scholar] [CrossRef]
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–21 July 2016; pp. 2387–2395. [Google Scholar] [CrossRef]
- Dale, K.; Sunkavalli, K.; Johnson, M.K.; Vlasic, D.; Matusik, W.; Pfister, H. Video Face Replacement. ACM Trans. Graph. 2011, 30, 130:1–130:10. [Google Scholar] [CrossRef]
- Kitanovski, V.; Izquierdo, E. Augmented reality mirror for virtual facial alterations. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1093–1096. [Google Scholar] [CrossRef]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. FaceWarehouse: A 3D Facial Expression Database for Visual Computing. IEEE Trans. Vis. Comput. Graph. 2014, 20, 413–425. [Google Scholar] [CrossRef] [PubMed]
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Real-time avatar animation from a single image. Face Gesture 2011, 2011, 117–124. [Google Scholar] [CrossRef]
- Weng, Y.; Cao, C.; Hou, Q.; Zhou, K. Real-time facial animation on mobile devices. Graph. Model. 2014, 76, 172–179. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Wu, H.; Weng, Y.; Shao, T.; Zhou, K. Real-time Facial Animation with Image-based Dynamic Avatars. ACM Trans. Graph. 2016, 35, 126:1–126:12. [Google Scholar] [CrossRef]
- Nagano, K.; Seo, J.; Xing, J.; Wei, L.; Li, Z.; Saito, S.; Agarwal, A.; Fursund, J.; Li, H. paGAN: Real-time Avatars Using Dynamic Textures. ACM Trans. Graph. 2018, 37, 258:1–258:12. [Google Scholar] [CrossRef]
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Huber, P.; Hu, G.; Tena, R.; Mortazavian, P.; Koppen, P.; Christmas, W.J.; Ratsch, M.; Kittler, J. A multiresolution 3D morphable face model and fitting framework. In Proceedings of the 11th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Rome, Italy, 27–29 February 2016. [Google Scholar]
- Sorkine, O.; Alexa, M. As-rigid-as-possible Surface Modeling. In Proceedings of the Fifth Eurographics Symposium on Geometry Processing (SGP ’07), Barcelona, Spain, 4–6 July 2007; Eurographics Association: Aire-la-Ville, Switzerland, 2007; pp. 109–116. [Google Scholar]
- Park, J.; Park, J. A Framework for Virtual 3D Manipulation of Face in Video. In Proceedings of the 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Reutlingen, Germany, 18–22 March 2018; pp. 649–650. [Google Scholar] [CrossRef]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face Alignment at 3000 FPS via Regressing Local Binary Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2014. [Google Scholar]
- Telea, A. An Image Inpainting Technique Based on the Fast Marching Method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Without Correspondence Filtering | With Correspondence Filtering | |||
|---|---|---|---|---|
| Without OpenMP | With OpenMP | Without OpenMP | With OpenMP | |
| Frontal face | 35.70 | 25.77 | 30.15 | 20.63 |
| Oblique face | 97.15 | 60.31 | 68.03 | 30.58 |
| Module | Process | Time | Subtotal Time |
|---|---|---|---|
| Registration | Facial landmark detection | 36.28 | 58.49 |
| Face model fitting | 22.21 | ||
| Manipulation | Mesh deformation | 7.14 | 12.48 |
| Merging fitted and deformed models | 5.34 | ||
| Rendering | Inpainting | 31.16 | 41.71 |
| Update textures | 3.37 | ||
| Update texture coordinates | 6.49 | ||
| Rendering image | 0.36 | ||
| Rendering face model | 0.33 | ||
| Total | 112.68 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Seo, B.-K.; Park, J.-I. A Framework for Real-Time 3D Freeform Manipulation of Facial Video. Appl. Sci. 2019, 9, 4707. https://doi.org/10.3390/app9214707
Park J, Seo B-K, Park J-I. A Framework for Real-Time 3D Freeform Manipulation of Facial Video. Applied Sciences. 2019; 9(21):4707. https://doi.org/10.3390/app9214707
Chicago/Turabian StylePark, Jungsik, Byung-Kuk Seo, and Jong-Il Park. 2019. "A Framework for Real-Time 3D Freeform Manipulation of Facial Video" Applied Sciences 9, no. 21: 4707. https://doi.org/10.3390/app9214707