1. Introduction
Over the past several decades, supply chain management (SCM) has emerged as an important topic and many operational research problems for the SCM have been attracted. Even though many researchers obtained local operational efficiency by optimizing the logistics flow of each entity (i.e., raw-material providers, manufacturing plants, whole-sale distributers, and customers) within supply chain (SC), they have become to recognize that the coordination between the entities in the SC is important to obtain global efficiency of logistics throughout the entities in the SC. Due to this reason, an integrated schedule of manufacturing and delivery has recently received great attention from the researchers.
One review article by Chen [
1] introduced several single-period optimization models for integrating inbound-production and outbound-truck scheduling in the SC. The article introduced the integrated optimization models based on various objective function types using time, cost, and profit. For integrated scheduling problems between production and delivery, Fan et al. [
2] studied the integrated production with a single machine and delivery scheduling with batching. The limitation of the study was that they considered the batch delivery to only one customer. Cakici et al. [
3,
4] investigated a similar problem with Fan et al. [
2]. They extended the integrated scheduling problem to parallel machines in a production plant and multi-customers for batch delivery. However, they assumed that the delivery operation was processed using only a single truck. Agnetis et al. [
5] studied the coordination problem of the batching and delivery problem, where product-part batches were delivered between production sites by a 3PL provider. Between the delivery process from upstream to downstream production sites, only the batch with all jobs completed at the upstream site can be delivered to the downstream site with two transportation modes. Li et al. [
6] studied a coordination problem between the assembly manufacturing plant with parallel machines and multi-destination transportation with a constraint of make to order (MTO) inventory strategy. They decomposed the overall problem into a sub-problem of parallel machine scheduling and a sub-problem of 3PL transportation and solved the problem. Chang et al. [
7] considered a coordination problem between a manufacturing plant with the unrelated parallel machines and multi-destination transportation with capacitated delivery trucks. Their problem minimizes biobjectives with the total distribution cost and the delivery time without batching and inventory strategies. Li et al. [
8] considered a coordination problem of vehicle schedule and routing between the manufacturing plant with the parallel batch machines and multi-destination transportation with capacitated delivery trucks by the third-party logistics provider. The objective function of the article was to maximize the total profit of the company.
Meanwhile, an integrated scheduling problem between two production processes had a structural similarity with the integrated scheduling problems between production and delivery in the SC. Several studies on the two-stage production and assembly scheduling problem were introduced [
9,
10,
11]. In recent years, several meta-heuristic algorithms were proposed to optimally solve the integrated scheduling problem between production and delivery under different problem frameworks [
12,
13,
14,
15,
16,
17,
18].
The fulfillment of due dates of customers is important to obtain a global logistics efficiency in the overall supply chain. Even though the tardiness factor is a significant factor on the integrated scheduling, to the best of our knowledge, a few meta-heuristic algorithms generate a near-optimal solution for the integrated scheduling problems. Furthermore, to the best of our knowledge, none of the research has an integrated scheduling problem, including a batching decision between the scheduling problems with a tardiness objective measure. In this article, based on the contribution of the problem, we propose two effective and efficient variable neighborhood search (VNS) algorithms for minimizing total tardiness of our integrated scheduling framework.
2. Problem Statement and Mixed Integer Linear Programming (MILP) Model
A number of orders were sequentially carried out by manufacturing, batching, and delivery operations between a manufacturing plant and multi-delivery sites. Many jobs in the various orders by customers were firstly received and produced by one of the identical parallel machines in a manufacturing plant. The jobs to be shipped to the same customer were grouped in a batch. The batch was loaded into one of the available trucks with a truck containing limit and delivered to the associated customer. Once the trucks were successfully delivered to the current delivery location, for the next delivery, they were directly returned to the manufacturing plant. In this article, three main decisions are to be determined: (1) machine scheduling, which gives a job assignment to a machine and a job sequence produced in each machine, (2) batching, which decides grouping the jobs to the same delivery place within a delivery capacity, and (3) truck delivery scheduling, which decides a batch assignment to truck and a batch sequence delivered in each truck. Total tardiness violating due times of each job is important to improve the service level of customers. Thus, the objective function is to minimize the total tardiness. For the mathematical formulation, the parameters and decision variables were defined in
Appendix A.
In this model, the variables and were specially introduced. The variable equals 1, if job is assigned to the first processing sequence of machine at the manufacturing plant. Similarly, the variable equals 1, if batch is assigned to the first delivery sequence to truck . Since the batching is one main decision in the model, the initial set is defined as the set of maximum available batches and the number of maximum available batches equals the number of jobs (). Some dummy batches had no assigned jobs in set B, and we ignored the batches on the truck delivery scheduling. In these cases, we ignored the batches on the truck delivery scheduling, which were = 0 for .
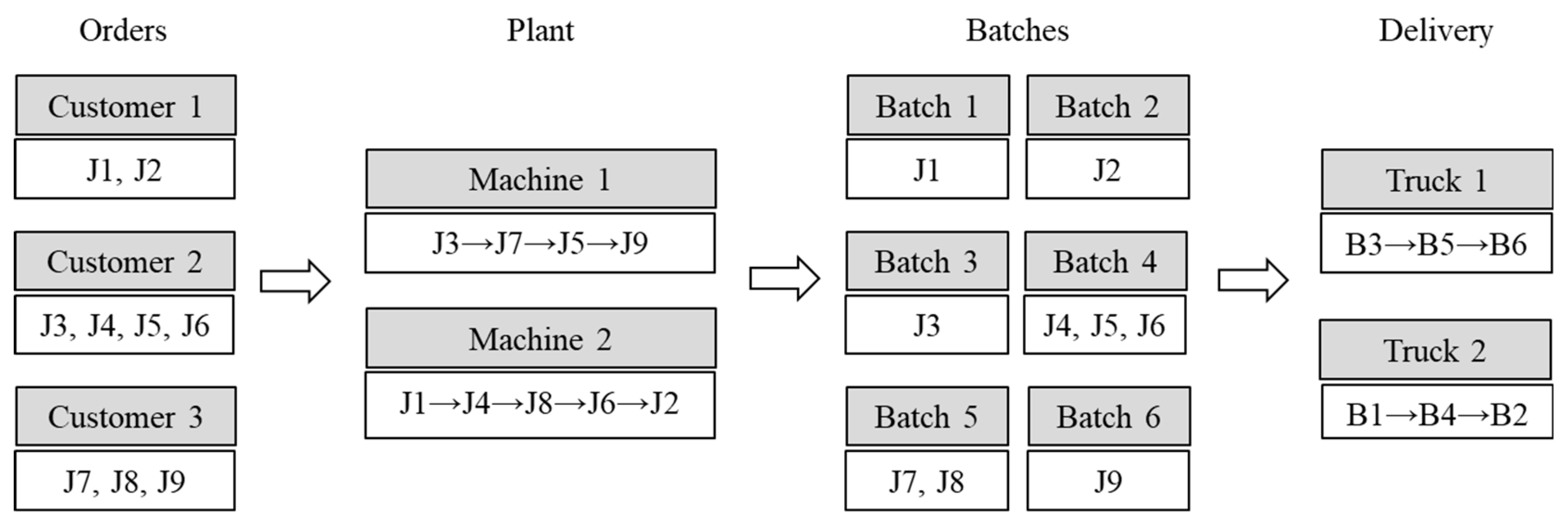
For illustrating the proposed problem, a simple example is given in
Figure 1 and
Table 1. In the example, nine jobs from three orders by the corresponding customers were required to schedule manufacturing and delivery by two machines and two trucks. Jobs 1 and 2 were ordered by customer 1, jobs 3, 4, 5, and 6 were ordered by customer 2, and jobs 7, 8, and 9 were ordered by customer 3, respectively. In
Table 1, the parameters of processing time, due time, and volume of each jobs, and transportation time to each customer are shown. From
Figure 1, machine 1 sequentially produces jobs 3, 7, 5, and 9, and machine 2 also sequentially produces jobs 1, 4, 8, 6, and 2 at the plant. According to the truck containing capacity (
) and the ordering customer, 6 batches were grouped using the manufactured jobs. Once batching was completed, truck scheduling was processed based on the batches. For truck scheduling, truck 1 sequentially delivered three batches 3, 5, and 6 to customers 2, 3, and 3, and truck 2 sequentially delivered three batches, 1, 4, and 2, to customers 1, 2, and 1, respectively. From these schedules, the tardiness of each job is calculated in the last column of
Table 1. Hence, the total tardiness of these schedules becomes 150.
Using the above problem parameters and decision variables, the MILP model for the proposed problem is as follows:
s.t.Constraint (2) is to determine the precedence relation of producing jobs within the same machine at the manufacturing plant and calculate the starting time of processing the jobs. Constraint (3) restricts that each job must be assigned to one of the machines in the manufacturing plant. Constraints (4)–(6) have a relation that jobs assigned to the same machine must appear exactly once in their sequence. Constraint (4) ensures that the beginning of the production sequence in each machine can assign, at most, one job. So, one job must be assigned to the first position if the rest of jobs are succeeded by the job in each machine. Constraint (5) guarantees that one job will be immediately preceded by one job in a machine if it is assigned to the machine, and Constraint (6) also guarantees that one job will be immediately succeeded by at most one job, if the job is assigned to one of machines. Also, no succeeding job is allowed if the job exists at the last position of the sequence in machines. Constraint (7) ensures that each job must be assigned to exactly one of the batches. Constraint (8) confirms that the total volume of jobs in batches must not be over the truck containing capacity.
Constraint (9) guarantees that all jobs in the same batch should belong and be shipped to the same customer. Constraint (10) restricts that the shipping starting time of each batch must be the longest completion time of manufacturing jobs in the batch. Constraints (11)–(12) force a relation between the jobs in the batch and the customer. In Constraint (13), the shipping time of each batch can be calculated by determining the precedence relation of the batches delivered by the same truck. Constraint (14) confirms that a truck must deliver only one batch to an associated customer at a time. Constraints (15)–(17) have a relation that batches assigned to the same truck must appear exactly once in their sequence. Constraint (15) ensures that the beginning of the delivery sequence in each truck can assign, at most, one batch. So, one batch must be assigned to the first position if the rest of the batches are succeeded by the batch in each truck. Constraint (5) guarantees that one batch will be immediately preceded by one batch in a truck if it is shipped to the truck, and Constraint (6) also guarantees that one batch will be immediately succeeded by at most one batch, if the batch is shipped to one of the trucks.
The above MILP formulation guarantees obtaining an optimal solution. However, the size of the formulation makes it hard to find an optimal solution within a limited time. This difficulty occurs from the number of integer variables and constraints. By the derived formulation, the numbers of integer variables and constraints depend on
and
, respectively. Thus, CPLEX failed to obtain an optimal solution before running out of memory in large-sized problems. If the problem is reduced to consider only a machine scheduling problem, it is equivalent to a total tardiness parallel-machine scheduling problem. If the problem is reduced to considering only a batching problem, it is equivalent to a well-known bin-packing problem. If the problem is reduced to considering only a truck scheduling problem, it is equivalent to a total tardiness parallel-machine scheduling problem. Each of those problems are known to be –NP-hard [
19]. Thus, it is necessary to propose an efficient heuristic to solve the problem within a short amount of time.
3. Variable Neighborhood Search (VNS) Algorithms
We develop VNS algorithms to solve the integrated scheduling problem efficiently. The VNS algorithm is designed to enrich the search space by restarting a local search heuristic with randomly generated neighborhood solutions from an incumbent solution by a pre-determined set of neighborhood structures. Systematic changes of the neighborhood solution within the local search is a key concept of VNS algorithms to improve a solution quality. Thus, the performance of VNS algorithm is mainly influenced by the local search heuristic and the neighborhood structure to meet problem characteristics [
20].
The basic VNS algorithm starts with a randomly generated initial solution and repeats the shaking and moving steps until the termination condition (maximum neighborhood number) is met. In the shaking step, a neighbor of the incumbent solution is randomly generated, and the local search heuristic is performed. After the shaking step, the incumbent solution is compared with the local optimal solution and updates the incumbent solution when the local optimal solution is better. Algorithm 1 shows the procedure of the basic VNS scheme given as follows:
| Algorithm 1. Basic VNS scheme |
Begin
Find an initial solution set .
Let iteration index .
Define maximum neighborhood number .
While ()
Shaking: find a random solution set
Perform a local search with to find a local optimum
Move or not:
If then
.
.
Else
.
End If
End While
End |
3.1. Neighboorhood Structure
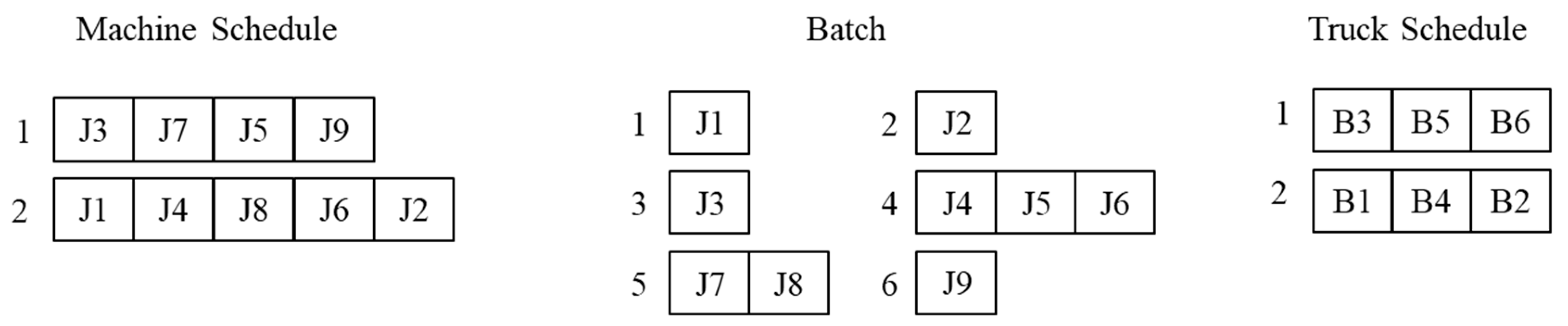
A solution of the integrated scheduling problem is represented by three sequences in this article: a job sequence for each machine, a job sequence for each batch, and a batch sequence for each truck. The example solution of the integrated schedule in
Figure 1 is represented as shown in
Figure 2.
The neighborhood solutions are generated by operations describing how they change the incumbent solution. In this article, we use the following nine basic neighborhood operations, for machine schedule (M1, M2, M3, M4), batching (B1), and truck schedule (T1, T2, T3, T4):
3.1.1. Neighborhood Operations for Machine Schedule
Within single machine: A machine and a job position p in the job sequence of the machine are randomly selected. Another job position q is randomly selected within the range [max(0, p-gapJob), min(p+gapJob, current number of jobs assigned to the machine)]. The interval gap between selecting jobs is defined as gapJob = n(J) preR, where preR ( is the predetermined relative interval ratio.
- M1.
InsertOnMachine (gapJob): The job at the position p is removed and inserted to the position q in the job sequence of the machine.
- M2.
SwapOnMachine (gapJob): The jobs at the positions p and q are interchanged in the job sequence of the machine.
Across machines: A machine m and a job position p in the job sequence of the machine m are randomly selected. Another machine n and job position q in the job sequence of the machine n are randomly selected within the range [max(0, p-gapJob), min(p+gapJob, current number of jobs assigned to the machine n)].
- M3.
InsertAcrossMachine (gapJob): The job at the position p in the job sequence of the machine m is removed and inserted to the position q in the job sequence of the machine n.
- M4.
SwapAcrossMachine (gapJob): The job at the positions p and q are interchanged in the associated job sequence of the machines m and n, respectively.
3.1.2. Neighborhood Operations for Batching
- B.
SwapAcrossBatch(): Two batches and job i and j in each batch are randomly selected with checking the feasibility of the truck capacity. The job i and j are interchanged.
3.1.3. Neighborhood Operations for Truck Schedule
Within single truck: A truck and a batch position r in the batch sequence of the truck are randomly selected. Another batch position s is randomly selected within the range [max(0, r-gapBatch), min(r+gapBatch, current number of batches assigned to the truck)]. The interval gap between selecting batches is defined as gapBatch = n(B) preR, where preR ( is the predetermined relative interval ratio.
- T1.
InsertOnTruck (gapBatch): The batch in the position r is removed and inserted to the position s in the batch sequence of the truck.
- T2.
SwapOnTruck (gapBatch): The batches in the position r and s are interchanged in the batch sequence of the truck.
Across trucks: A truck k and a batch position r in the batch sequence of the truck k are randomly selected. Another truck l and batch position s in the batch sequence of the truck l are randomly selected within the range [max(0, r-gapBatch), min(r+gapBatch, current number of batches assigned to the truck l)].
- T3.
InsertAcrossTruck (gapBatch): The batch at the position r in the batch sequence of the truck k is removed and inserted to the position s in the batch sequence of the truck l.
- T4.
SwapAcrossTruck (gapBatch): The batch at the positions r and s are interchanged in the batch sequence of the associated trucks k and l, respectively.
In order to simultaneously determine machine schedule, batch assignment, and truck delivery schedule, a combination of the basic neighborhood operations for each decision would be examined in each iteration of the main VNS scheme. For the combination, the neighborhood operations for each decision are grouped, respectively, and an operation is randomly selected in each group when making a neighborhood. The grouped neighborhood structure is shown in
Table 2.
3.2. Local Search Scheme
For the local search in VNS algorithms, we used a search method based on sequence arrays (SMSA). To apply SMSA to the integrated scheduling problem, three sequence arrays were used, which are machine scheduling, batching, and truck scheduling arrays. The sequence arrays, which are represented by a single dimensional string array with digits, and those require assignment rules to determine manufacturing sequence of machines, batching construction, and shipping sequence of trucks. The digits for machine, batching, and truck scheduling represent a job sequence to apply to the machine assignment rule, the batching rule, and the truck assignment rule, respectively [
21]. The decoding processes of the sequence arrays are carried out by the three rules. Joo and Kim [
16] studied a similar problem (makespan problem) and compared the several assigning rules for their GA algorithm. The processing time and completion time-based assigning rules for machine and truck sequence arrays, and the minmax-based and rotation-based batching rules for batch sequence array were compared. They concluded that the completion time-based assigning rule for the machine and truck sequence arrays and the rotation-based batching rule for batch sequence array provided the best performance in terms of its effectiveness and efficiency for their algorithm. According to their result, we used three rules for decoding the sequence arrays to a compound solution for our local search scheme. The procedures of the three rules are as follows:
Machine assignment rule: Calculate the completion times of each machine by temporarily assigning the current job to the end of the sequence in the corresponding machine. And then, find the machine with the shortest completion time is found and the job is permanently assigned to the machine and placed on the end-position of the manufacturing sequence of the machine.
Batching rule: Find the first available batch, allowing the capacity of the batch to be greater than the volume of the job, as well as shipping towards the same customer and assigning the job to the batch. If no batch was satisfied by the conditions from the current available batches, create a new batch and assigned the job to the batch.
Truck assignment rule: Calculate the completion times of each truck by temporarily assigning the current batch to the end of the sequence in the corresponding truck. And then, find the truck with the shortest completion time and the batch was permanently assigned to the truck and placed on the end-position of the shipping sequence of the truck.
For the local search with SMSA, we classified seven modification cases according to which sequence arrays were selected to apply the modification (see
Table 3). Cases 1, 2, and 3 applied only one sequence array to the modification process and cases 4, 5, and 6 applied two of three sequence arrays to the modification process. Case 7 applies all three sequence arrays to the modification process. One of seven cases is randomly chosen according to the case selection probability
in every iteration of the local search with SMSA.
In this article, we developed two kinds of procedures for the local search with SMSA. The difference between two procedures is to update whether the case selection probabilities are used or not when the modification of sequence array is processed. The first local search uses the static even case selection probability with the value 1/(the number of modification cases). The second local search uses the dynamic case selection probability, which is increased when the case is selected and decreases with a deterioration rate when the case is not selected. Three sequence operators for the modification of sequence array in SMSA were used. For the operators, two front and rear positions were randomly selected in the original sequence array.
Pull operator: All digits between two positions (including the digits in the positions) are removed and placed to the end of the sequence array and the digits on the right side of the rear position are pulled to the position of the front point.
Insert operator: The digit in the rear position is removed and simply inserted into the position in front of the digit in the front position.
Swap operator: The two digits at the front position and the rear position are mutually interchanged.
The pseudo codes of two local search procedures with SMSA are given in Algorithm 2 and 3 as follows:
| Algorithm 2. Local search with static case selection probability |
Begin
Define termination count .
Define number of modification cases
Let the initial case selection probability .
Find an initial sequence arrays encoded from the solution set .
Let current local optimum .
Let iteration index .
While ()
Modification of Sequence Arrays:
Find a random number .
Let the case index .
While ()
If then
Selecting case .
Break
End If
End While
Modify the sequence arrays to a new sequence arrays according to case .
Generate a corresponding solution set decoded from the sequence arrays .
Move or not:
If then
.
.
.
Else
End If
End While
Return the local optimum .
End |
| Algorithm 3. Local search with dynamic case selection probability |
Begin
Define termination count .
Define number of modification cases
Let the initial case selection probability .
Let the deterioration rate .
Find an initial sequence arrays encoded from the solution set .
Let current local optimum .
Let iteration index .
While ()
Modification of Sequence Arrays:
Find a random number .
Let the case index .
While ()
If then
Selecting case .
Break
End If
End While
Modify the sequence arrays to a new sequence arrays according to case .
Generate a corresponding solution set decoded from the sequence arrays .
Move or not:
If then
.
.
.
.
Else
.
End If
End While
Return the local optimum .
End |
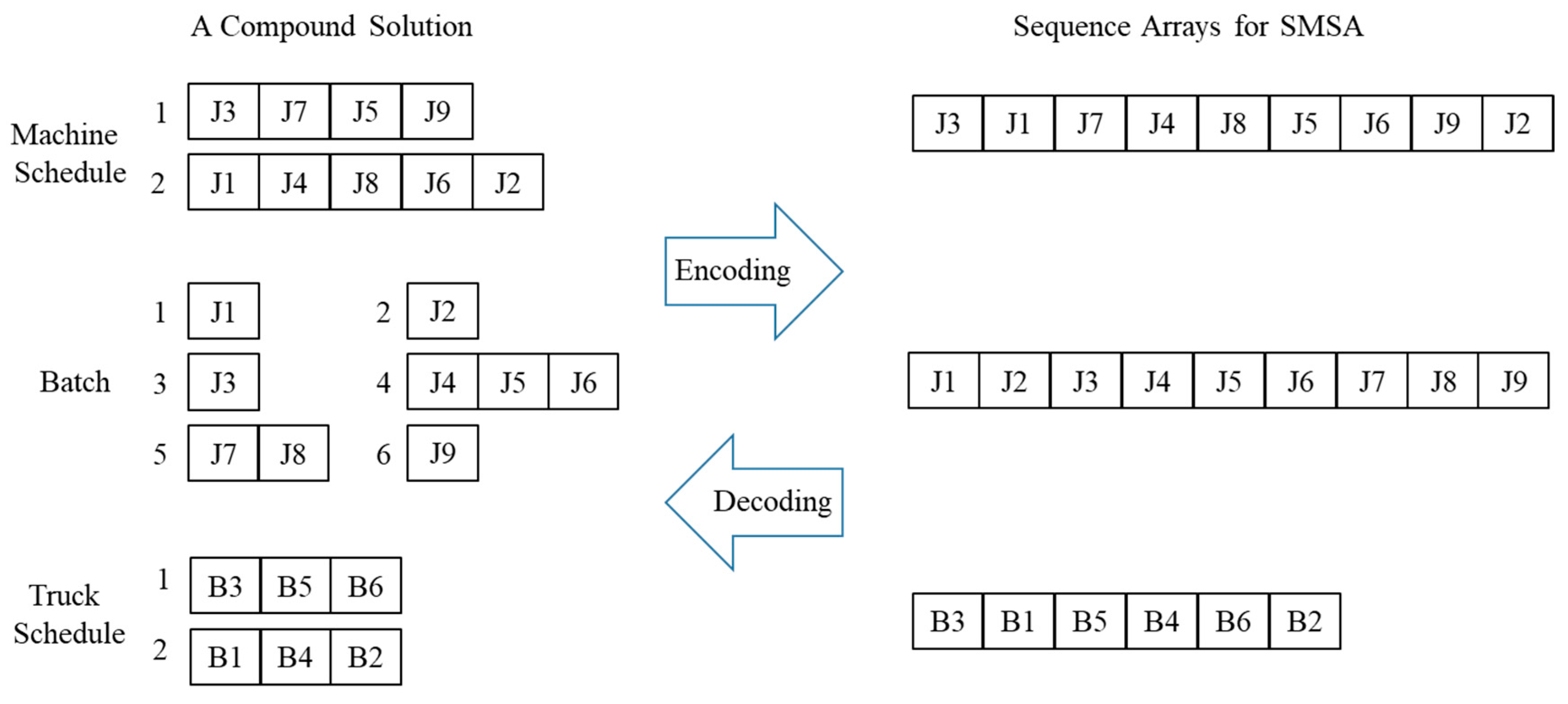
3.3. Encoding and Decoding of a Solution
SMSA used for local search in VNS algorithms is operated with three sequence arrays that have single dimensional string arrays. So, the encoding and decoding procedures between the compound (integrated) solution and sequence arrays for SMSA are required. The procedures used are the three assigning rules applied to the local search in
Section 3.2.
Figure 3 describes encoding and decoding procedures with the example integrated schedule presented in
Figure 2 and
Table 1.
4. Computational Testing Experiments
In this section, we conduct extensive computational testing experiments to access the performance of two VNS algorithms using the local search with static case selection probability (VNS_S) and VNS algorithm using the local search with dynamic case selection probability (VNS_D).
Since the problem complexity increases as the number of jobs (
J) increases, we divided the test problems into two groups using
J. The first group is to compare the performances of VNS algorithms with the optimal solution, and the test problems in the group are randomly generated with
J selecting between 5 and 10. For the optimal solution, ILOG CPLEX 12.7 was adopted to solve the MILP formulation in
Section 2. We terminated a particular run if an optimal solution was not found in an imposed 7200 (s) time limit. The test problems in the second group are randomly generated with
J selecting more than 10. The group is to compare the relative performance of the solutions obtained by VNS algorithms. VNS algorithms were coded with the language C#, and all experiments were tested on a PC with 1.86 GHz Intel Core 2 CPU processor and 2 GB RAM.
The problem complexity is affected by five problem parameters which are the number of jobs (J), the number of machines (M), the number of trucks (T), the number of customers (C), and tardiness factor ()). Test problems are randomly made according to the five parameters. The tardiness factor () is to generate the due times for each job. The due times for each job generated are more scattered as the value of is increased. Three values, 0.1, 0.3, and 0.5, are considered for the tardiness factor.
In the small-sized group, eight test problems were randomly generated for each tardiness factor. Under the predetermined one of tardiness factor values, the size of four problem parameters, which are the numbers of jobs, machines, trucks, and customers, were randomly selected by U [5,10], U [2,6], U [2,4], and U [3,4], respectively. In the large-sized group, a total of 24 test problems with 20, 40, and 60 jobs were randomly generated for each tardiness factor. Under the predetermined one of job sizes and one of tardiness factor values, the size of three problem parameters, which are the numbers of machines, trucks, and customers, were randomly selected by U [3,6], U [2,4], and U [3,6], respectively. The processing time and the transportation time were randomly selected by U [60,120] and U [60,240]. The volume of jobs was randomly selected by U [5,10] with a fixed value of the batch capacity as 20. The relative interval ratio selected by truck schedule were predetermined as {0.05, 0.1, 0.2, 0.4, 0.7, 1.0}.
The performance of VNS algorithms were relatively compared, and two performance measures, called relative deviation index (RDI) and mean absolute deviation (MAD), were defined. The measures are expressed by Equations (22) and (23), respectively.
where
and
are the objective function values of the best feasible solution obtained by one of the algorithms (or the optimal solution by CPLEX) and the worst feasible solution obtained by one of the algorithms, respectively.
is an objective function value obtained by any VNS algorithm.
where
is a mean value of the replicated objective function values by any VNS algorithm.
All problems were tested by 30 replications. The performance results of the small-sized group are presented in
Table 4. The objective function values of the optimal solution by CPLEX are represented, and the average RDI and MAD by VNS algorithms are compared. For the small-sized group, low values of RDI and MAD are indications that all VNS algorithms give good performances. In
Table 4, computational times (CPU times) of instances are also calculated. We can find the CPU time of CPLEX exponentially increases as the number of jobs increases. Meanwhile, CPLEX could not search an optimal solution for problems over 7–8 jobs in the given time limit.
In
Table 5, the performance results of the large-sized group are summarized. The average RDI and MAD of VNS_D is lower than those of VNS_S. The results indicate that VNS algorithms with a local search with dynamic case selection probability significantly improve the performance of the algorithms compared to VNS algorithms with a local search with static case selection probability. The CPU times of each VNS algorithm are short enough to obtain the best solution. The observed differences between two local search schemes are more statistically significant as tardiness factors decrease. This result indicates that VNS_D gives a better performance for the proposed scheduling problem as the due date becomes more tightly controlled.
To compare the performances of the VNS algorithms with the other meta-heuristics, we tested GA-based algorithms with the same problem sets. The performance results are also presented in
Table 5. The tested GA is a single-stage algorithm with independent dispatching rules. It uses a chromosome representing two string arrays for machine and truck scheduling and one string array with job batching. In this article, VNS algorithms proposed give better performance than GA in any job size and any tardiness factors. The results indicate that VNS algorithms improve the performance by broadly exploring the solution space compared with GA.
5. Conclusions
This article considered an integrated problem of one batching and two scheduling decisions between a manufacturing plant and multi-delivery sites. Many jobs ordered by multiple customers are firstly manufactured by one of machines in the plant. In this problem, two scheduling (machine and delivery truck scheduling) problems and one batching problem must be simultaneously determined to minimize the total tardiness. To find the optimal solution, a MILP model was developed. We mainly found an optimal solution using CPLEX for small-sized groups, but it was inefficient and impractical to find the optimal solution for the problems of large-sized groups. Thus, two VNS algorithms, which were applied with different local search schemes, were applied to improve the performance of the algorithm. We conclude that the VNS algorithm with dynamic case selection probability finds better solutions in reasonable CPU times, compared with the VNS algorithm with static case selection probability and the GA based on the test results.






{kind=link}
{kind=link}
{kind=link}