Plant phenotyping is an important tool for linking environmental and genetic research, and is used to evaluate drought and climate-change resistance by comparing the growth differences between plant varieties [
1]. Plant researchers can bridge the gap between genomics and phenotype through field investigations [
2]. Many types of phenotypic parameters available in the field are valuable for yield estimation and quality detection, such as plant height, spike number, leaf coverage, and so on. Among these, leaf coverage has a direct effect on the interception of photosynthetic radiation, water interception, heat fluxes, and CO
2 exchange. Leaf coverage can also be used as a key linkage between canopy reflectance and crop-growth models. Over the past decades, the study of leaf coverage evolved away from the general use of potted plants as research objects [
3]. However, current methods, such as continuous imaging by fixed-position cameras, or destructive methods based on crop harvesting, are usually time-consuming.
Moreover, since crop growth can vary between outdoor and indoor environments, indoor observations are not suitable for predicting outdoor growth trends. Numerous adverse factors affect the precision of field phenotypic observations, such as differences in nutrients and water availability. Moreover, environmental influences such as wind, humidity, changing solar radiation, and cloud coverage also degrade data accuracy. To accurately and reliably study the in-field growth pattern of plant cultivars, researchers use high-throughput field phenotyping (HTFP), whereby phenotypic parameters are acquired by using automated or semi-automated systems. Currently, most HTFP-based systems for estimating leaf coverage use multispectral or hyperspectral images or RGB images. In the present study, we focus on the use of RGB images, because the associated technology is much lighter and cheaper than a spectral system, and can be fixed to a small unmanned aerial vehicle (UAV) platform. Digital photography is a popular tool for acquiring field information about small crops because it is affordable and easy to use with minimal training. The key step of extracting leaf coverage from RGB images is image segmentation, and existing segmentation methods for RGB images focus mainly upon two aspects: The first aspect is solely based on color information. For example, Dahan et al. presented a technique that synergistically combines depth and color image information from real devices. They use the color information to fill and clean depth and use depth to enhance color-image segmentation [
4]. Panjwani and Healey introduced a segmentation method that uses a color Gaussian–Markov random-field model, which considers both spatial interactions within each spectral band and the interactions between color planes [
5]. Shafarenko et al. explored a bottom-up segmentation approach that was developed to segment randomly-textured color images [
6], and Hoang et al. put color and texture information together in the segmentation process to finish the segmentation of synthetic and natural images [
7]. In addition, Xiong et al. introduced a segmentation method that combines the hue-saturation-value (HSV) color space and the Otsu method. Their experimental results show that the algorithm presented herein has a good effect and can meet real-time demand [
8]. Thus, segmentation based on color information is seriously affected by the illumination. In this way, each type of method usually applies to a certain reproductive period. Except for the disadvantages described above, excess dependence on color information will lead to incomplete extraction. The second aspect of extracting leaf coverage from RGB images is based on the classifier. For example, Wang et al. introduced the novel fuzzy c-means approach (FCM), which uses local contextual information and the inherently high inter-pixel correlations to automatically segment images. Experimental results show that the proposed method provides competitive segmentation results compared with other FCM-based methods, and is generally faster [
9]. Bai et al. presented an automated object-segmentation approach based on principal pixel analysis and a support vector machine, which effectively segments the entire salient object with reasonable performance and higher speed [
10]. Recently, Chen et al. introduced a new segmentation method by combining three technologies: Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. This method is superior for dealing with complex conditions [
11]. Moreover, Ravi et al. proposed a semantic segmentation of images by using multi-feature extraction and random forest (RF). According to their conclusion, this method offers good performance and accuracy in a small class [
12]. Although all the methods mentioned above improve the processing accuracy of specific scenes in image processing, they still have many shortcomings. For example, the color-based segmentation methods are sensitive to changes in light intensity, and so they cannot be regarded as environmentally robust methods. Furthermore, deep-learning (DL) technology requires a large training set and high-performance hardware (e.g., a high graphics processing unit (GPU) frequency) [
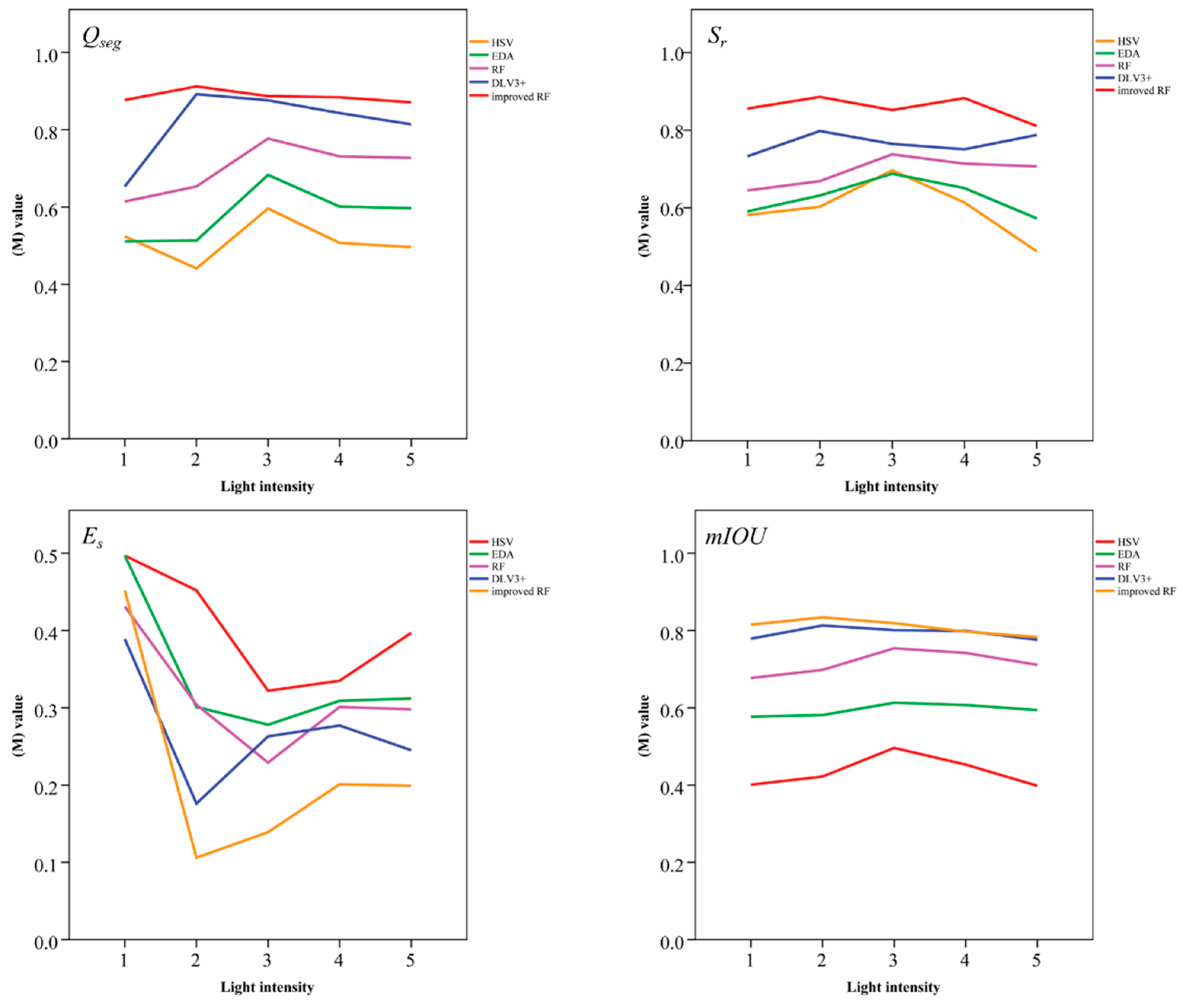
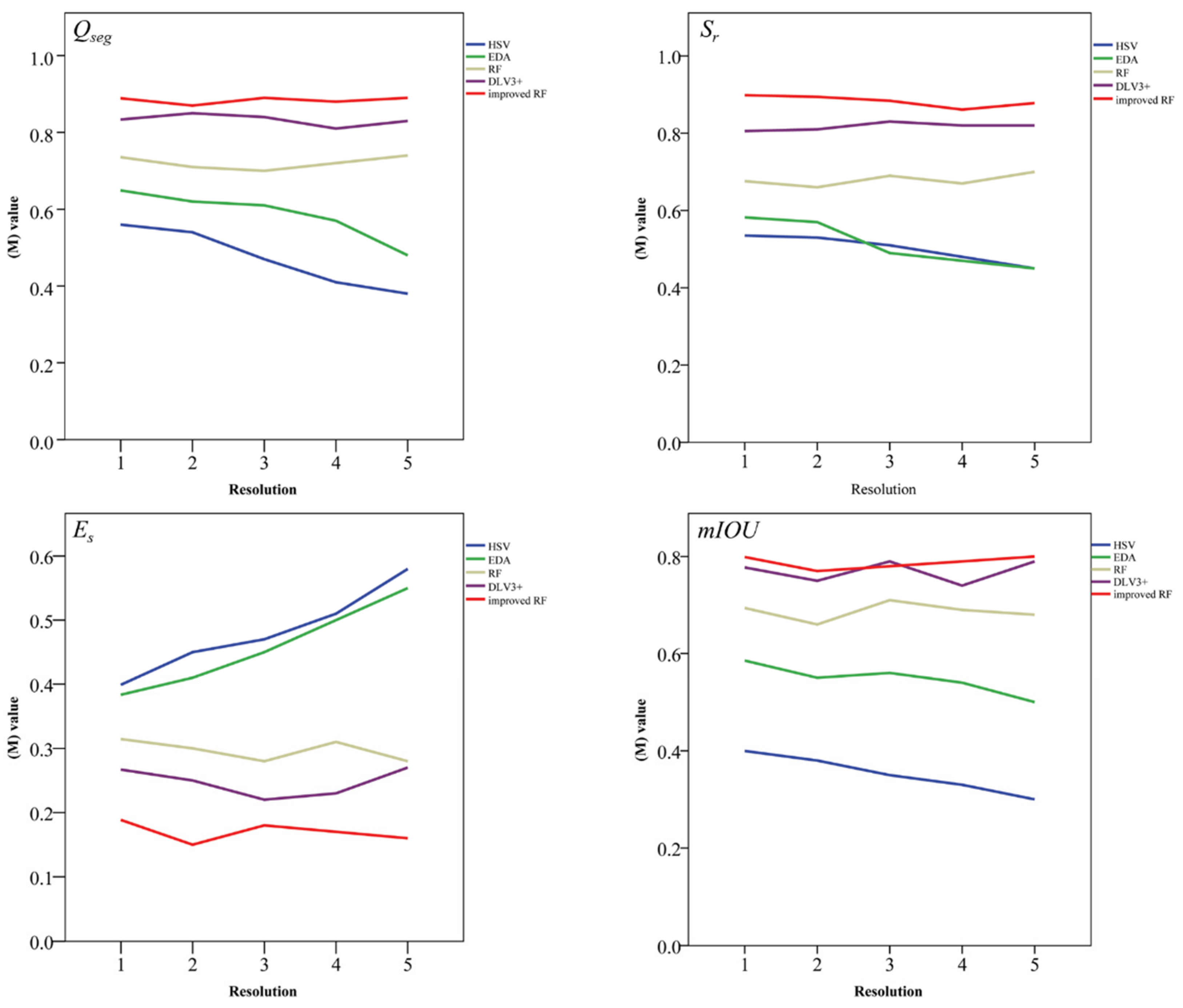
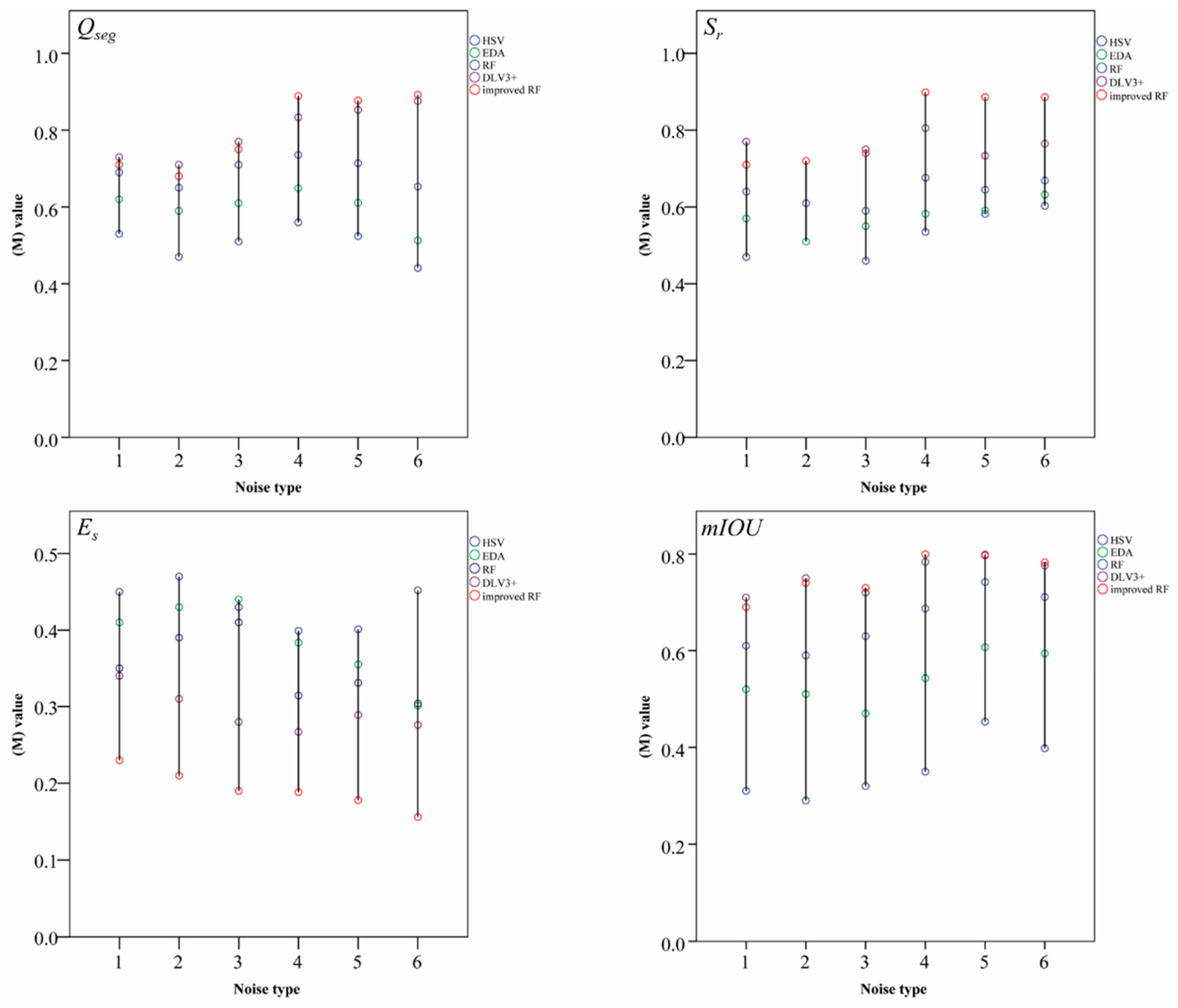
13]. To resolve these problems, we investigate herein a segmentation algorithm based upon an improved random forest classifier. First, the original UAV remote-sensing image dataset is augmented by three strategies, so that it can meet the requirement of big-data training. To highlight target characteristics, the background of the dataset is removed by using the K-means clustering algorithm. We then extract several image features, including color features and texture features, to describe the differences between the leaf part and the stem part. The improved RF classifier is trained by using the feature matrix and outputs the binary segmentation results.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}