1. Introduction
Nowadays, the network environments are becoming more and more complex and so the security problems. A Botnet is a system of customized bots (computers) controlled remotely by a botmaster. A botnet can perform different noxious exercises, for example, sending spam messages, phishing, click misrepresentation, Distributed Denial of Service DDoS and spreading malicious programming. To viably oversee a botnet, the botmaster develops a framework of a correspondence channel to send directions to the Bots and to get results from them [
1]. The fundamental contrast between a botnet and other malicious code is the structure utilized in the command and control (C & C) [
2]. Compared to other malware programs which are being used to perform malicious conduct exclusively, a botnet functions as a gathering of contaminated hosts dependent on the C & C correspondence channel. A botnets system can be ordered into two principal classes dependent on the C & C foundation: brought together and decentralized C & C [
3]. In incorporated botnets, the botmaster typically utilizes the C & C server to send a direction to the bots.
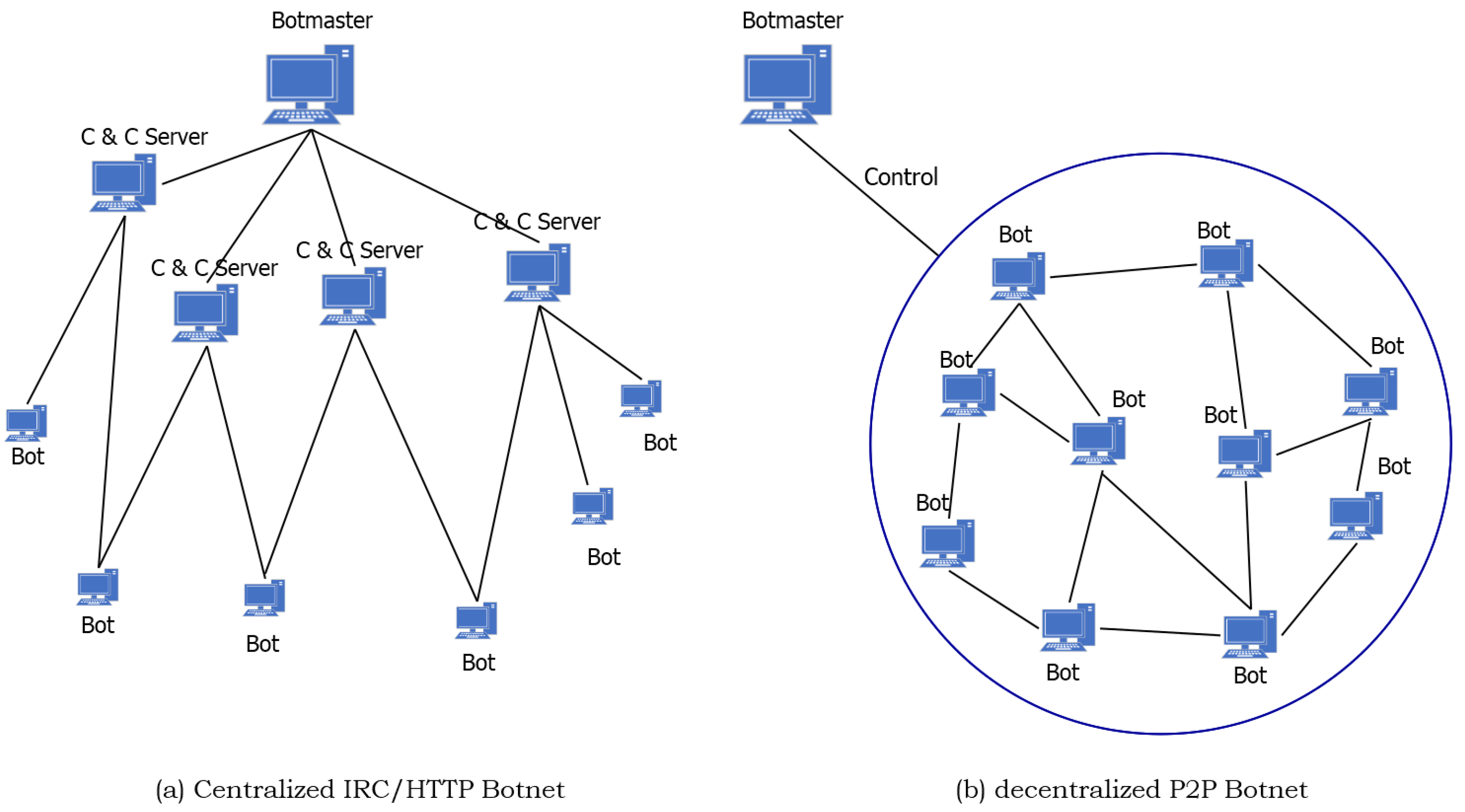
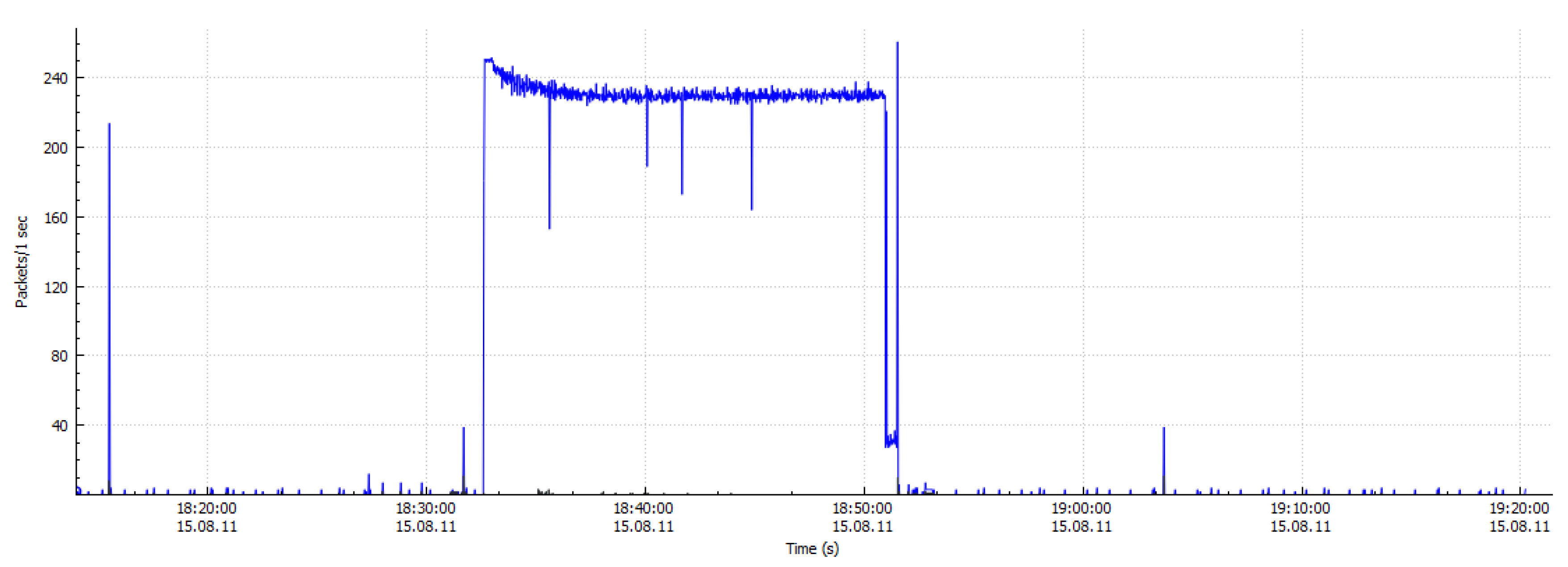
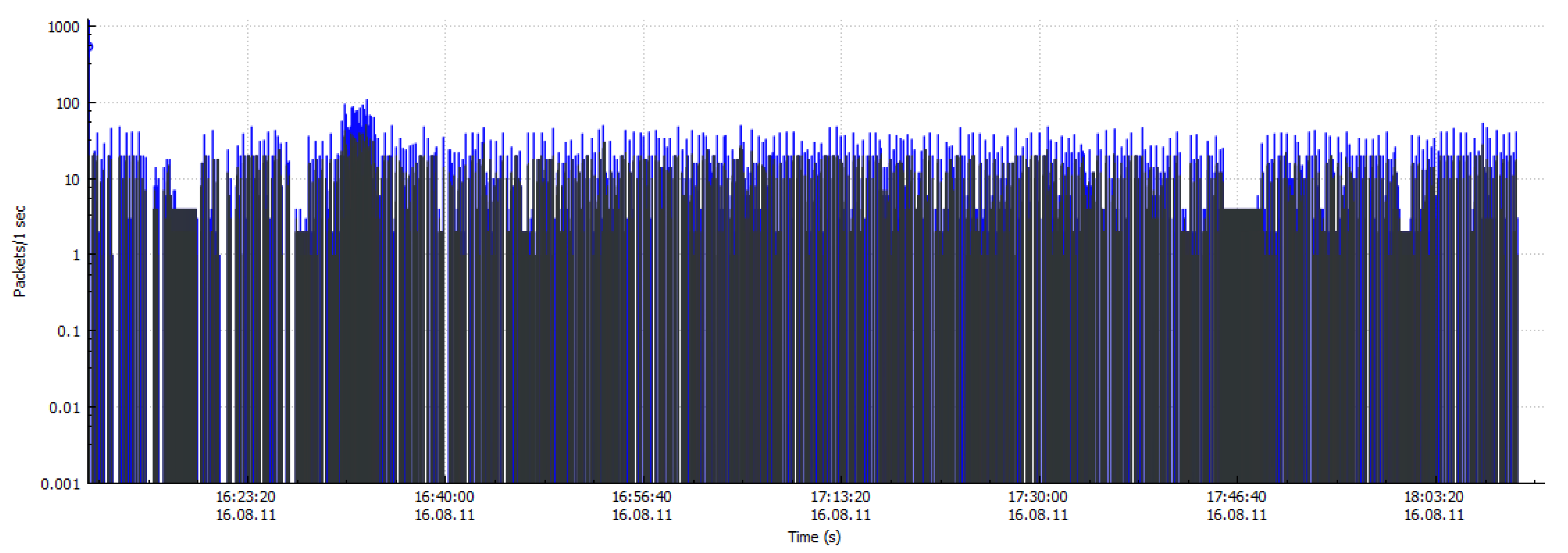
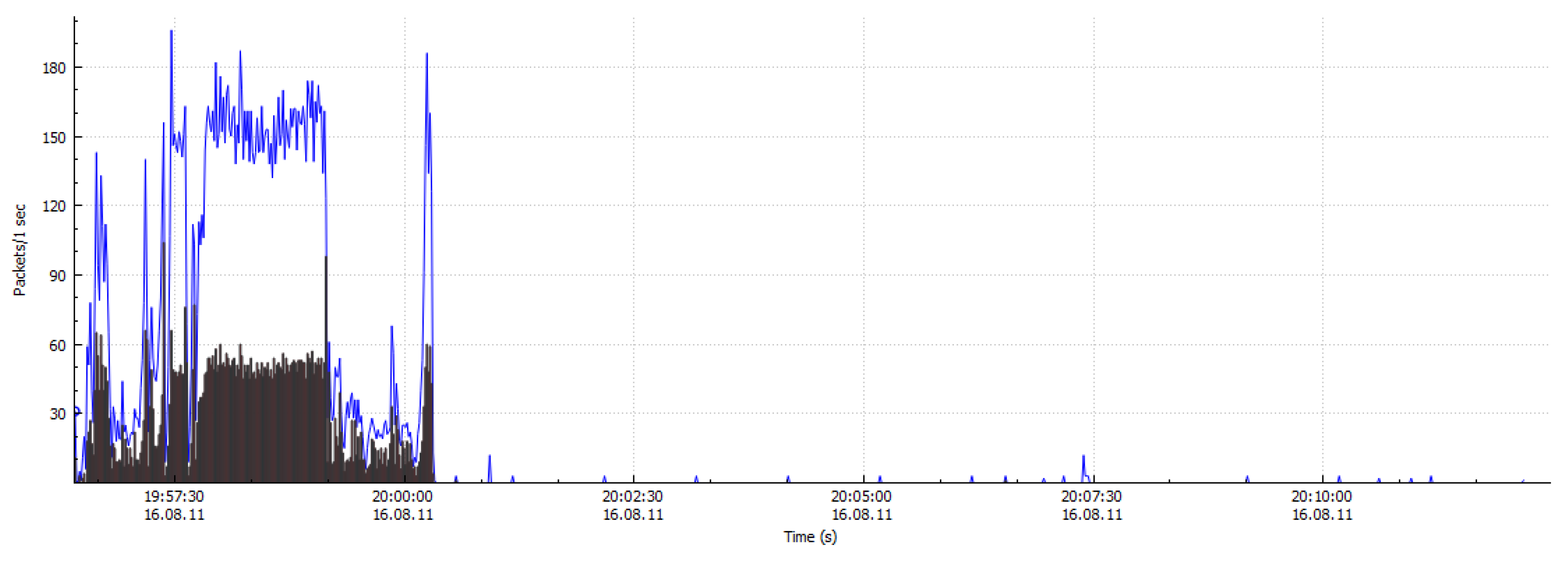
Figure 1 gives a brief overview of the centralized Internet Relay Chat IRC/HTTP traffic and decentralized Peer to Peer P2P botnet traffic. As the higher degree of concealment of botnet command and control server (C & C server), the attacker uses unknown programs to create intrusion in a large-scale network. Moreover, the botnets initiate almost all of the DDoS attacks and 80% to 90% of the spam attacks [
4]. Consequently, the botnet has become a significant threat to network security. Early botnets were easily detected due to commonly used IRC and HTTP as a communication protocol, with a single failure point. Recently, most of the botnets use P2P technology to create C & C mechanisms to enhance network traffic concealment. As compared to botnets with IRC and HTTP protocols, the P2P botnets without central nodes have greater threat and concealment. Therefore, the P2P botnets are increasingly favored by attackers. The P2P botnet detection has also become a hot research area in the field of cyber security. At present, the P2P applications have caused the explosive growth of Internet traffic, which is a massive challenge in terms of data storage and real-time analysis. Thus, the network of non-P2P traffic filtering is particularly important.
Recent research works on botnets among our surveyed literature focuses mainly on designing systems to detect command and control (C & C) botnets, where many bot-infected machines are controlled and coordinated by few entities to carry out malicious activities [
5]. Those systems need to learn decision boundaries between human and bot activities. Therefore, Machine Learning-based classifiers are at the core of those systems and are often trained by labeled data in supervised learning environments. The most popular classifier is support vector machines (SVMs) with different kernels, while spatial-temporal time series analysis and probabilistic inferences are also notable techniques employed in ML-based classifiers. Clustering is mostly used in natural language processing (NLP), to build a large-scale system to identify bot queries [
6]. In botnet detection literature, the core assumption widely shared i.e., Botnet behaviors are different and distinguishable from a legitimate human user, e.g., human behaviors are more complex [
7].
Research has been done on the state-of-the-art machine learning models of the network to simulate real-time network traffic and create honeypots. The ground reality is often heuristic or a combination, labeled by human experts, for example, the game masters’ visual inspections serve to detect bots in online games [
8]. In retrospect, the evolution of botnet detection is clear from earlier and more straightforward uses of classification techniques such as clustering and Naive Bayes, the research focus has been expanded from the last step of classification to the important preceding step of constructing suitable metrics, which measures and distinguishes bot-based and human-based activities [
6,
7].
This paper aims to examine the features and strategies to detect the botnets. The main contributions of this paper are as follows:
This article presents a multi-layer approach to classify network traffic (P2P botnet traffic and non-P2P traffic) and identify botnets by applying machine learning classifier on network features such as port filtering, DNS query, and flow counting.
Our work presents a P2P botnet detection framework based on a decision tree algorithm for feature selection to extract the most relevant features and ignore the irrelevant features.
At the first layer, we filter non-P2P packets to reduce the amount of network traffic by applying port filtering using well-known ports, DNS query, and flow counting. The second layer further classified the captured network traffic into two classes such as non-P2P and P2P. At the third layer of our model, we reduced the features which may marginally affect the classification. At the final layer, we successfully detected P2P botnets using decision tree Classifier by extracting network communication features.
The proposed technique of this study covers the limitations of single stage botnet detection, e.g., class imbalance.
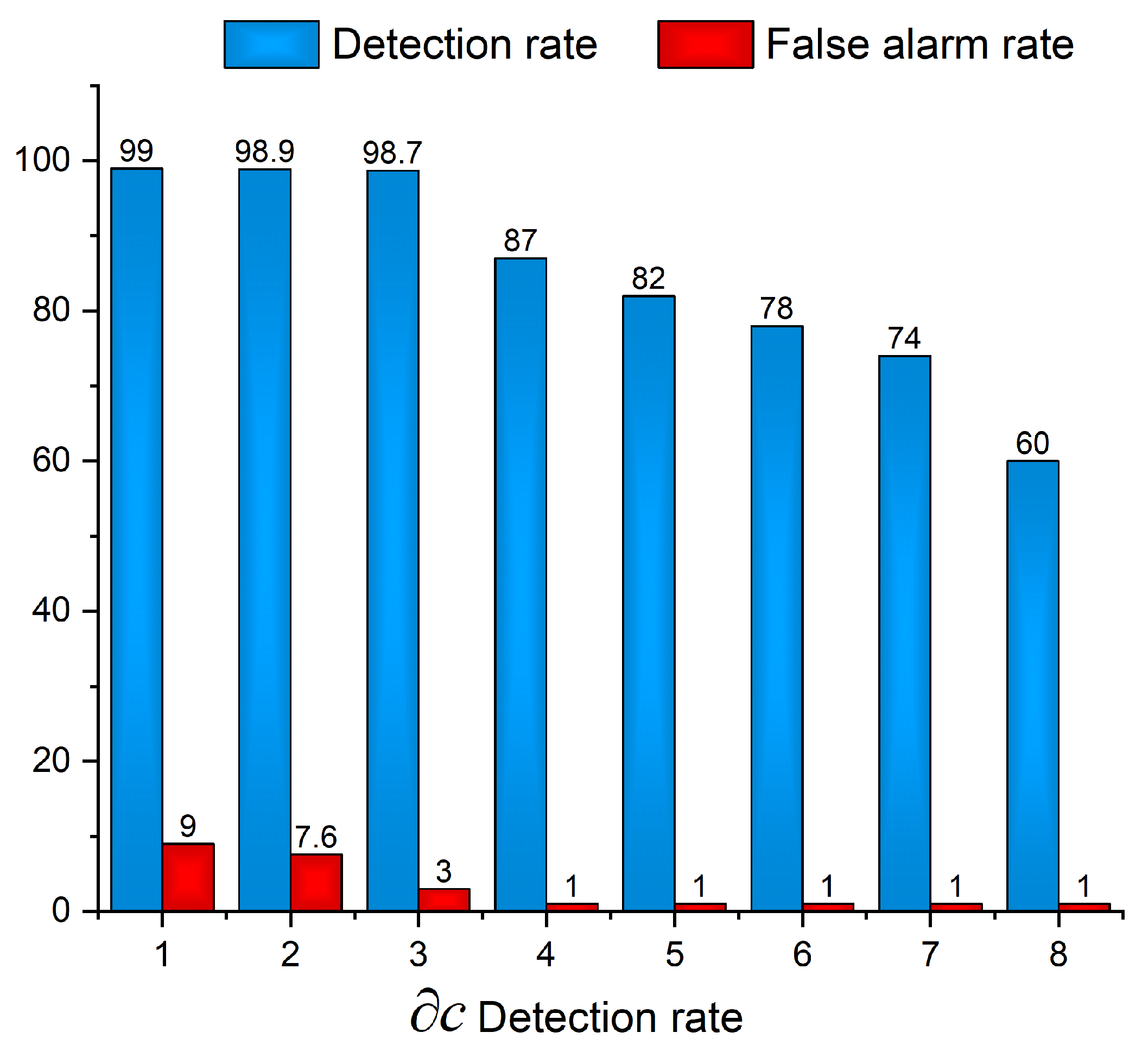
The accuracy of our model is 98.7% and the threshold of false alarm rate was reduced to 3. Furthermore, our experiments also demonstrate that the accuracy of proposed framework was improved up to 99% however at the expense of false reporting of benign files as botnets as well as false reporting of botnet as benign. We also consider the factor if benign files also send out search requests consistently so benign files may be reported as botnets. Additionally, it was observed the accuracy might be improved by increasing the epochs of deep learning algorithms at the expense of more execution cost.
To validate the performance of our proposed technique, we performed the experiments on diverse datasets and the results are compared with other machine learning algorithms implemented for botnet detection.
Structure of Paper
Section 1 of this paper discusses the background, problem description, and approach used in this study.
Section 2 gives a brief overview of the literature.
Section 3 gives a brief overview of the single stage along with its limitations and the motivation of choosing a multi-layer scheme. Moreover, the mechanism of the multi-layer scheme was also discussed.
Section 4 discusses the results of the experiments. Finally,
Section 5 concludes the paper.
2. Related Work
Machine Learning algorithms have been widely used to classify internet traffic. Irrespective of the class imbalance problem, Machine Learning classifiers such as Decision Trees and Neural Networks may produce a high accuracy for overall traffic flow but low accuracy for bytes. Accuracy for bytes means the number of bytes, carried by the packets of accurately classified traffic flow. Zhang et al. [
9], proposed two algorithms based on feature selection and extended
wsu_auc selection to apply the best features practically. They achieved more than 94% accuracy with an average byte accuracy of over 80%. Chen et al. [
10] has proposed a high-speed network detection method for botnets. In this PF RING (to optimize spark streaming), the problem was solved at a high packet drop rate and for extracting required fields from traffic information. The authors used the random forest technique on the CTU dataset. They have acquired high precision, but the unconvincing aspect of this publication is that they used only offline data, and no other data was collected online. Azab et al. [
11] proposed machine learning classifier (C45) and Correlation-based Feature Selection (CFS) for
Zeus V1.x,
Zeus V2.x and
benign HTTP traffic detection in networks. Azab et al. demonstrated 99.3% accuracy with 55.6% recall results.
Wang et al. [
12] proposed a solution to detect malicious Android apps. The authors utilized mobile traffic in which every HTTP traffic was treated as a document and this document was further used for word segmentation based on N-gram generation to generate candidate features which effectively characterized the particular flow of HTTP. The paper used the SVM machine learning algorithm for validation and demonstrated a high accuracy of 99.15% on static data while its detection rate was 54.81% on real environment testing. Albanese et al. [
13] proposed a graph-based botnet detection technique called MTD (Moving Target Defense). The paper addressed the limitations of the static detection technique as MTD periodically altered the placement of detectors, but the authors did not mention the traffic speed which was affected by the periodical alteration in detective algorithms. Haddadi and Nur [
14] have investigated five different botnet detection techniques. Two of them were rule-based systems and the other three were machine learning based techniques. The authors analysed their proposed approaches with different scenarios on twenty four publicly available datasets.
Alazab [
15] examined the evolution of malware by the nature of its activity and variants. The paper investigated malware implication on the computer industry and provided a framework using feature extraction from malicious code which reflected the behaviour of the code. In other paper, Alazab [
16] proposed a four-step methodology to develop a fully automated system for suspicious behavior detection. The four-step method classified the behavior of Application Program Interface API function calls based on the malicious intent hidden with the packed program. Zeng and Shen [
6] proposed a two-step distributed approach for storm botnet detection which included a set of heuristics and first-step port numbers and an SVM classifier. The accuracy of their method was more than 95% with 8–12% of false positive rate. This scheme worked well with 0% false positive rate and 8% false negative rate to detect storm botnets. According to Zhang et al. [
17], the P2P client was first identified by extracting the statistical pattern of P2P communication. The legal or legitimate P2P network and P2P botnet were further distinguished. Abdullah [
18] and Yin [
19] detected botnets based on host behavior. They detected zombie host and/or programs by monitoring changes in the host behavior, file, network connection, and registry contents. The method of detecting botnets based on host behavior cannot detect new and variant botnets. For example, an attacker could use new detection and hiding techniques such as rootkits and so on.
The detection based on traffic behavior has been mainly used in command and control phase [
20], by using difference between C & C flow and the normal traffic in the flow characteristics such as communication rules, average packet size, periodic connections, and so on [
21]. Therefore, Buczak and Guven [
22] suggested to combine machine learning neural network for botnet real-time monitoring. The botnet detection method based on traffic behavior mainly analyzed two characteristics such as “Connection failure rate”, and, “Flow characteristics”. According to Zhang [
17], the communication behavior between zombie hosts that joined the same botnet was similar. Therefore, P2P botnet traffic identification could adopt the scheme that firstly, analysed the traffic, and features were extracted. Secondly, the clustering algorithm was proposed to cluster the extracted data. The scheme was used to set the cluster threshold to improve the detection accuracy, without the use of existing botnet data stream for training. However, if there was only one zombie host in the current network, or if no traffic from different zombie hosts was found in the captured packets, this method was demonstrated inefficient by Zhang [
17]. The three DT algorithms REPTree, Carriage, and C45 were analyzed in the study [
23,
24], where C45 with the lowest performance because its algorithm was easily under pruning, and the overfitting algorithm was more severe than REPTree. Encrypted P2P or unknown traffic could be classified by the statistics-based method, but it is not highly accurate, and could not identify untrained P2P traffic correctly [
23].
Dhainotti et al. [
25] introduced a technique for characterization of a large scale surreptitious scan for entire IPv4 space (a “/0” scan) conducted by the Sality botnet. In addition, the authors presented an analysis of botnet scanning behaviour along with general correlation and visualizations method across global internet. Guofei. et al. [
26] presented a stochastic mechanism using an empirical test to isolate C & C botnet conversations from human to human conversations. They implemented a prototype system called BotProbe with desired accuracy. According to Guofei et al., about 53 % of the botnet command detected amongst thousands of real-world botnets (IRC-based), and about 14.4% were related to binary downloaded. In other study, Guofei et al. [
27] characterized a botnet as an orchestrated class of malicious instances operated through the C & C communication channels. A botnet’s essential properties were that the bots communicate with some Command & Control servers/peers, executing malevolent operations, and doing so in a correlated manner. Guofei et al., implemented a clustering paradigm for identical network traffic and identical malicious traffic; and further conducted cross-clustering correlations to categorize hosts sharing similar patterns of communication and similar patterns of malicious activity. The evaluations of Guofei et al. showed that their framework can effectively detect botnets with a very low false positive rate (0.003). Zhang et al. [
28] developed a framework to effectively and efficiently detect suspicious hosts probably to be bots. They transferred network traffic to botnet detection systems for fine-grained check and efficient botnet detection based on DPI (Deep Packet Inspection). The paper proposed to reduce network traffic to improve the scalability of existing botnet detection systems. Guofei et al. [
29] proposed a detection approach that identified Command & Control servers and the bots infected hosts in the networks. Their technique was predicated on the notion that bots inside the similar botnets were probably indicate spatial-temporal relationship and resemblance due to the pre-programmed events associated with C & C. The stream feature also included the number of upstream and downstream packets, the size of the uplink and downlink transmission bytes, the average length of the uplink and downlink data packets, the maximum length, the average variance, the duration of the data stream, and the packets that have been loaded in one stream. The stream feature selection method had a high detection rate because it did not depend on the botnet class to extract the common feature vector of the stream. Therefore, the detection strategy was widely concerned by experts and scholars in the field of network traffic analysis [
15]. In high-speed, complex, and changing network environments, the main factors that determine the efficiency and accuracy of detection are the characteristics of the extraction and the classification strategy used.
3. Proposed Scheme
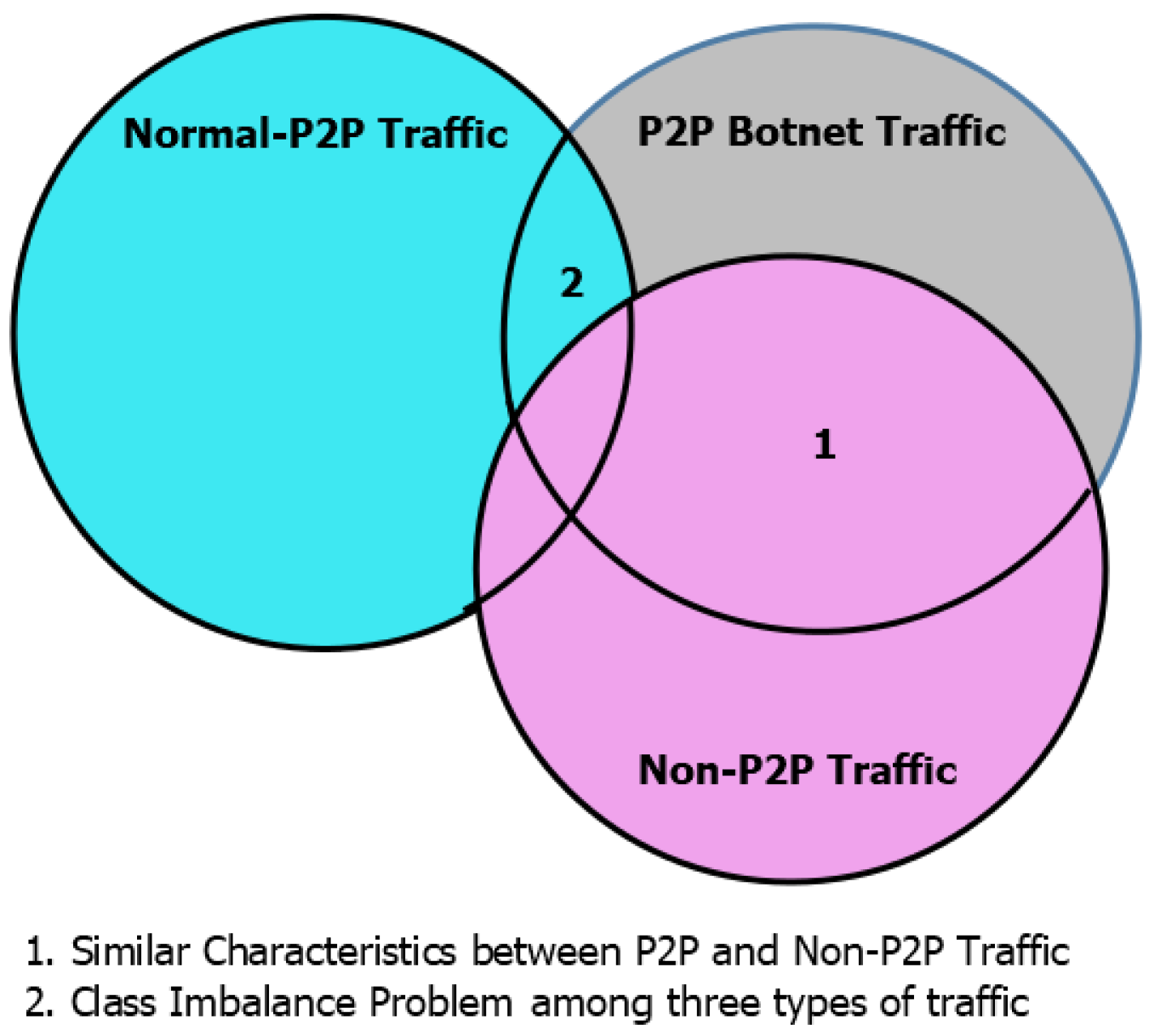
Three unique qualities of communication, i.e., P2P botnet, non-P2P and, Normal P2P activity, are demonstrated in
Figure 2. These three characteristics overlap each other. If the three types of activities are grouped into a single stage mechanism, a large part of the P2P botnet traffic with normal qualities for non-P2P activity could be misclassified and few substantial P2P streams could be misclassified as countless streams due to the class imbalance problem. In this way, a single phase mechanism doesn’t have the capability to order the traffic of three different qualities at the same time.
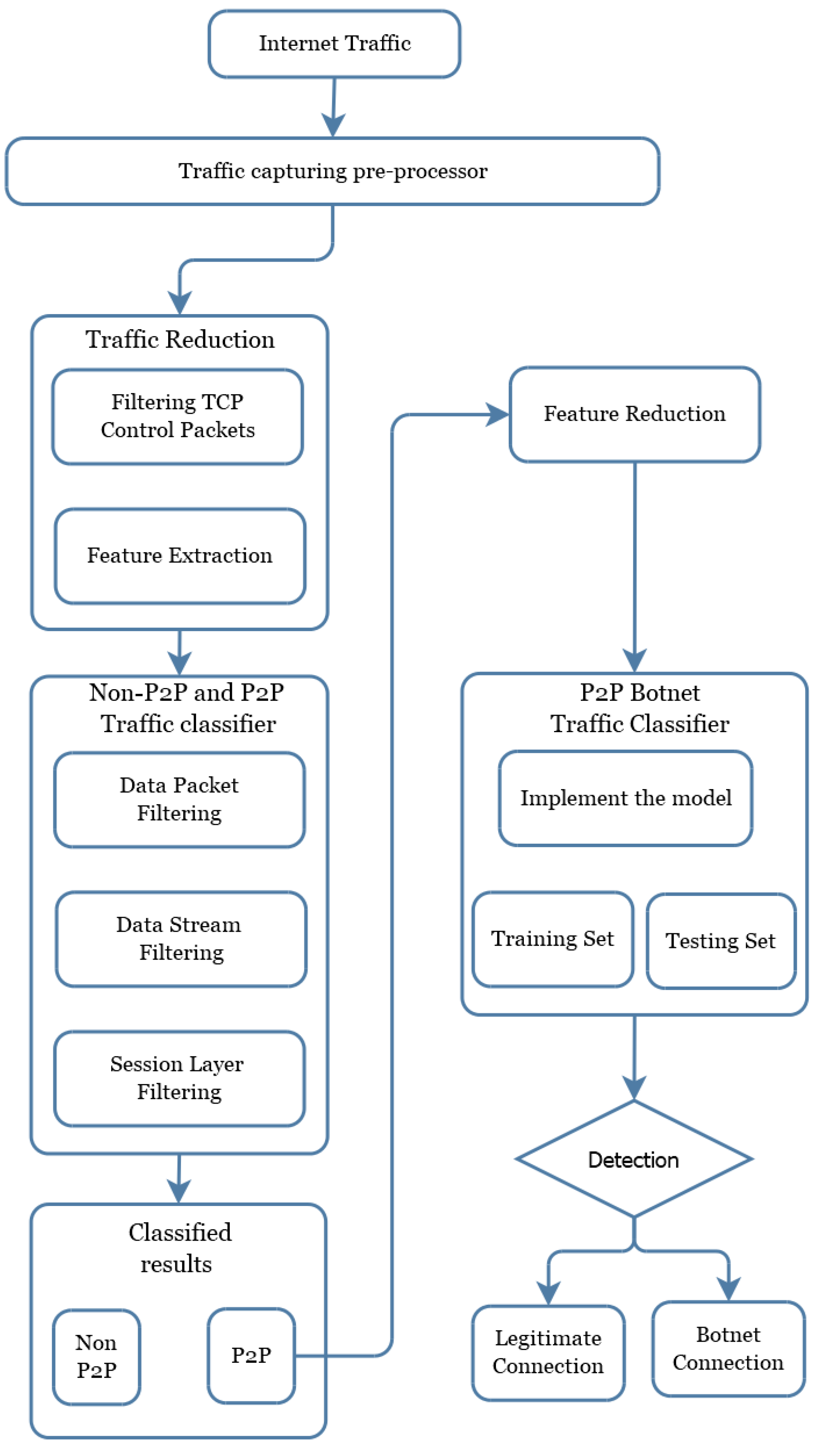
Therefore, a multi-layer method with a specific aim of settling the limitations of the single stage mechanism is very important. While there are many conceivable techniques exist, our research proposes a multi-layer mechanism, shown in
Figure 3.
3.1. Multi-Layer Detection Method
This section describes the method proposed in this paper to detect bot-bling traffic in phases. The focus of this method is on non-P2P traffic filtering and the extraction of the characteristics of the session. The architecture of the model is shown in
Figure 3. The first stage of the model will start from the traffic reduction followed by the three aspects of packet filtering rules, session characteristics, and classification algorithm. The second layer further classified the captured network traffic into two classes such as non-P2P and P2P. At the third layer of the model, we reduced the features which may marginally affect the classification. The final layer of the model classifies the traffic as either the traffic is normal P2P or botnet traffic. The detailed discussion on the entire mechanism of the proposed scheme is given in the rest of this section.
3.2. First Layer: Traffic Reduction
Reducing network traffic to detect malevolent behaviors is extremely important to manage a large amount of network traffic with limited resources, e.g., hard drive and memory. The hardest step in the process is to determine the network activity behavior by only scanning several packets for each flow. Our research therefore brings a new model to reduce congestion so that botnet detection systems can be deployed more easily on congested networks. In currently available identification methods for botnets, most of them use deep packet inspection (DPI) to evaluate packets content that is complicated and expensive and ineffective to simulate unidentified payload signatures [
30]. It is assumed that the payload of each packet in DPI can be accessed by the system. This strategy can be especially accurate when the payload is in decrypted form. Most of the new malicious code generators, however, use the concealment strategies, such as encapsulation of protocols, obstruction and encrypting the payloads [
31].
In addition, it is a costly task to evaluate all the packets on the congested networks because the amount of the packets transmitted through the networks are increasing day by day. Consequently, the DPI detection system can suffer from efficiency limited to the processing of the traffic from high-speed networks [
30]. This study aims to improve the efficiency by reducing the amount of packets without hampering the precision rate. To accomplish an ultimate objective of this study, the selection of only Transmission Control Protocol TCP packets proposes a new reduction in traffic for a Botnet identification paradigm. This detection technique is used to reduce the volume of the network traffic and will increase the efficiency of the Botnet detection model.
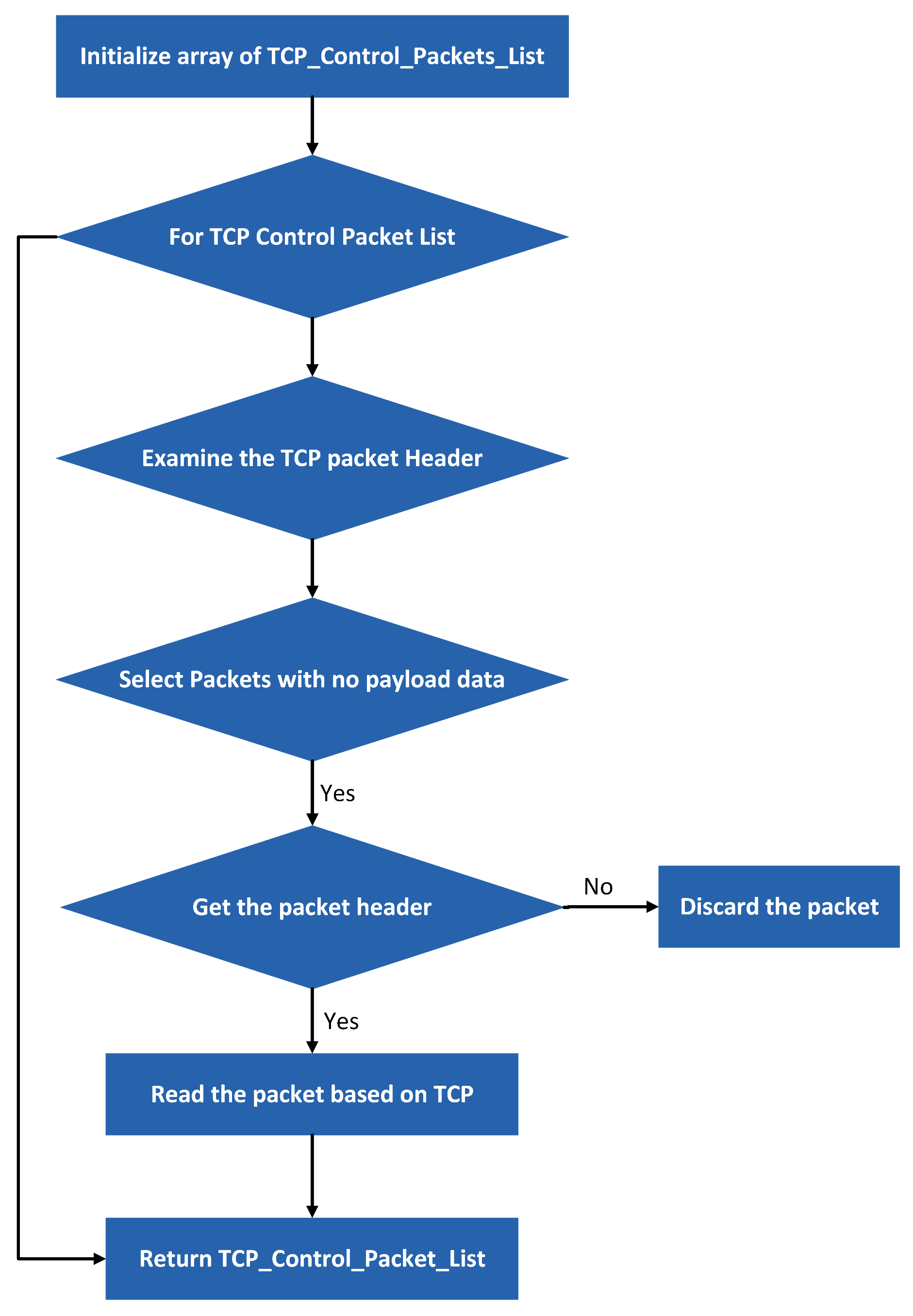
In this study, TCP traffic control packets are filtered to reduce network traffic volumes and improve the efficiency of the envisaged strategy. Filtering involves mainly two steps: filtering the network flow associated with the TCP protocol and obtaining the control packets SYN, ACK, FIN and RST TCP.
Figure 4 displays the network traffic reduction process (.PCAP files). An array of TCP Control Packets lists is initialized in the flowchart. New packets (TCP Control Packets List) are added to the array by tuples through the packets until the last packet in the file is reached. After the first loop i.e., for loop, the next loop examines the TCP packet header for loop, and the third loop selects packets without payload data. The flowchart’s final loop gets the packet header.
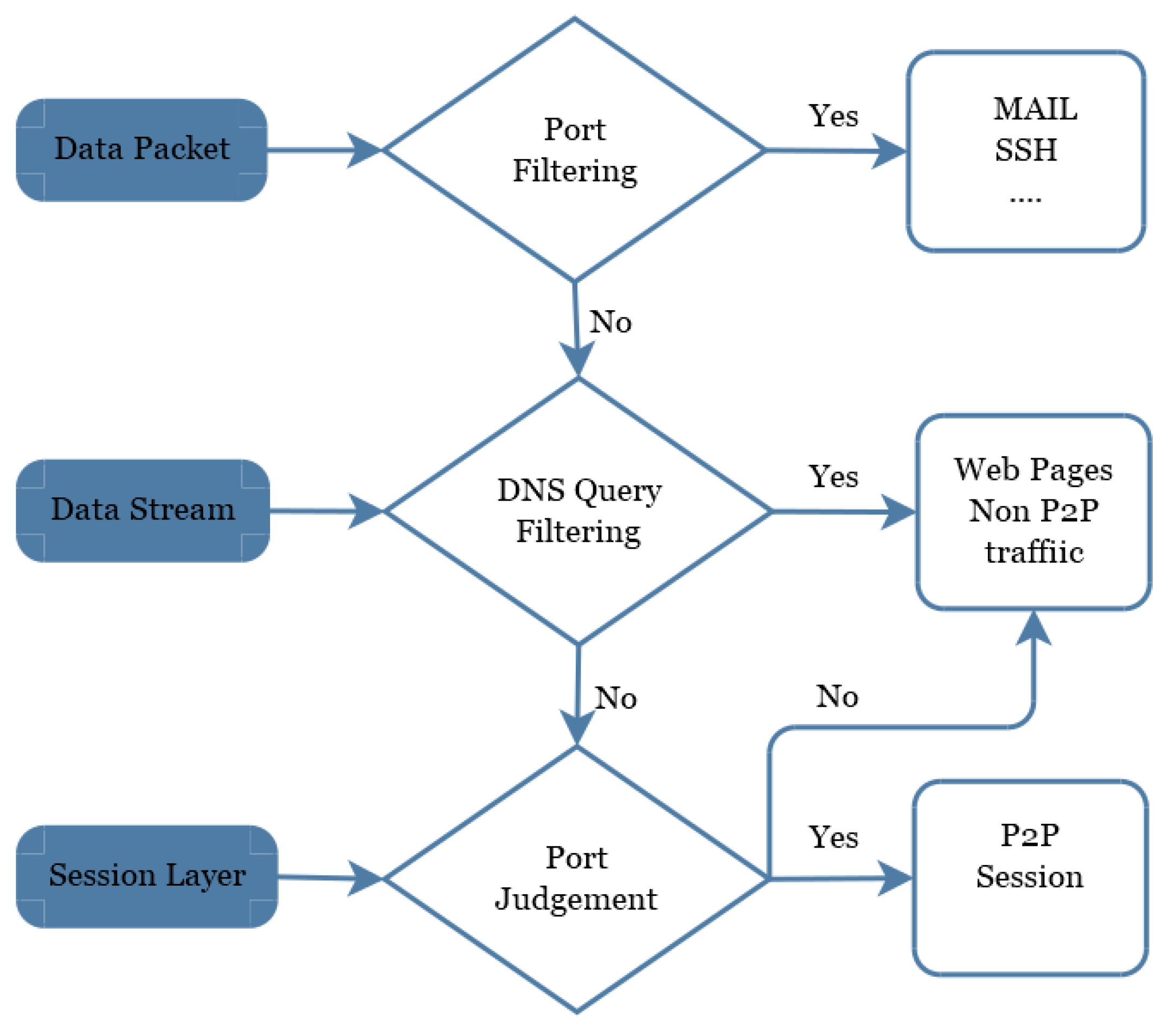
3.3. Second Layer: P2P and Non-P2P Traffic Classification
At present, port identification, signature recognition, and DNS query identification are commonly used methods for P2P traffic identification. These methods are based on stream feature [
21]. However, the port identification method cannot recognize P2P applications with random ports or custom ports. DPI (Deep Packet Inspection Technology) does not recognize encrypted P2P traffic [
32]. Stream-based identification methods can only determine P2P applications of the partial flow and has a high false alarm rate. Therefore, we use non-P2P well-known port filtering mechanism, DNS query, flow counting rules to filter non-P2P traffic, combined with fast heuristic P2P traffic identification method, as shown in
Figure 5.
The vulnerability of attack on internet application is usually initiated using open ports [
33]. We choose port and time interval as the unit of analysis. Since some ports are more often used than other ports, therefore, it is important to identify the frequency of attack on those specific ports. Limitations of Port scan attack identification techniques are associated with the extent which they can quantify their complexity, accuracy, performance, or timely delivery. The previously studied techniques for detecting port scan attacks work either at the packet level or at the flow level or both [
34]. In our proposed detection approach, we utilized packet level information because of its significance in determining the connection information along with capability of analysing payload of a packet. Another limitation of port scan detection is the challenge of labelling the large amount of network traffic data. This challenge is magnified further, if the security models produce profiles such as network traffic labelling for normal as well as malicious traffic, so updating the database of signatures (labels) dynamically will be a challenging task. However, more advanced approaches are still needed that can analyse both header and payload information to detect both labelled and unlabelled attacks.
To address the limitations of port scan detection methods, our framework is based on a multi-layer approach to detect multiple types of attacks such as IRC, SPAM, Click Fraud, DDoS, FastFlux, Port Scan, Compiled and Controlled record by CTU, HTTP, Waledac, Storm and Zeus botnets. More precisely, instead of limitations of port scan detection technique, our framework used multi-layers to effectively detect botnets. Port filtering is one layer used in our proposed framework and if we ignore port filtering or remove this layer from our framework so our system can be easily attacked by port scan attacks. Secondly, our experiments demonstrate in Table 3 that our framework captured port scan attacks 100%, which means that not a single packet of port scan attack was missed by our port filtering layer. Therefore, the error associated with port filtering method is very small due to a multi-layer approach. Algorithm 1 demonstrates the mechanism of second layer in our proposed model. We choose port and time interval as the unit of analysis. Since some ports are used more often than other ports; therefore, it is important to identify the frequency of attack on these specific ports. For instance, when we see something going through on port 25, we expect it to be a mail server, and likewise if we find something going through on port 80, we simply find that it is a webserver. The Internet Assigned Numbers Authority (IANA) [
35] officially assign port numbers for specific uses and applications.
| Algorithm 1 Second layer classification |
- INPUT:
Data Packet/ Data Stream/ Session Layer - OUTPUT:
MAIL/ SSH/ Non-P2P Traffic/ P2P Session - Step1:
Classify Data Packets by : if data packet is true then go to MAIL/SSH else go to step 2. - Step2:
Classify Data Stream by : if true then go to Non-P2P Traffic else go to step 3. - Step3:
Classify Session Layer : if true then go to P2P Session else go to Non-P2P traffic Traffic - Step4:
Return
|
Port filtering is a packet-level filtering method, mainly filtering the commonly used non-P2P application traffic. DNS query is a stream-level filtering method, flow counting, and port judgment is a session-level filtering method, the two rules are mainly filtered web pages and other non-P2P traffic. Among them, the port-based filtering method can identify some common non-P2P application traffic, such as Secure Shell SSH Defined generally using port 22 and Telnet (remote login) using port 23. Some commonly used applications and their corresponding port numbers are shown in
Table 1. TCP means Transmission Control Protocol, UDP means User Datagram Protocol.
In general, P2P node communication does not require domain name resolution but directly read the IP list stored in the local configuration file to obtain IP [
36]. However, for non-P2P applications, DNS domain name resolution must be used to obtain IP. Therefore, one of the criteria for determining non-P2P network data flows such as Web and Mail, etc., is resolved by the domain name and may be the destination IP address in the network flow.
When a user sends a Web application service request normally, the Web application uses a multi-port, parallel-requested connection to an IP address on a page. As a result, multiple data streams appear in the same session. The P2P network node communicates each time using a pair of random source and destination ports. Therefore, we can use flow counting and port determination to filter non-P2P traffic. If a session is using the TCP protocol and 808,080 or 443 port, and the number of sessions in the flow exceeds the threshold, then the session can be considered a web page traffic session. Where the number of valid streams in a session is represented, the threshold is selected based on the number of streams that appear in the normal page access session. Using the capture tool to collect simple and relatively complex web page requests, the analysis results show that the simple web page is generally three to four connection requests, and the complexity of the page connection request is five to eight. Therefore, the threshold is set to three in this article.
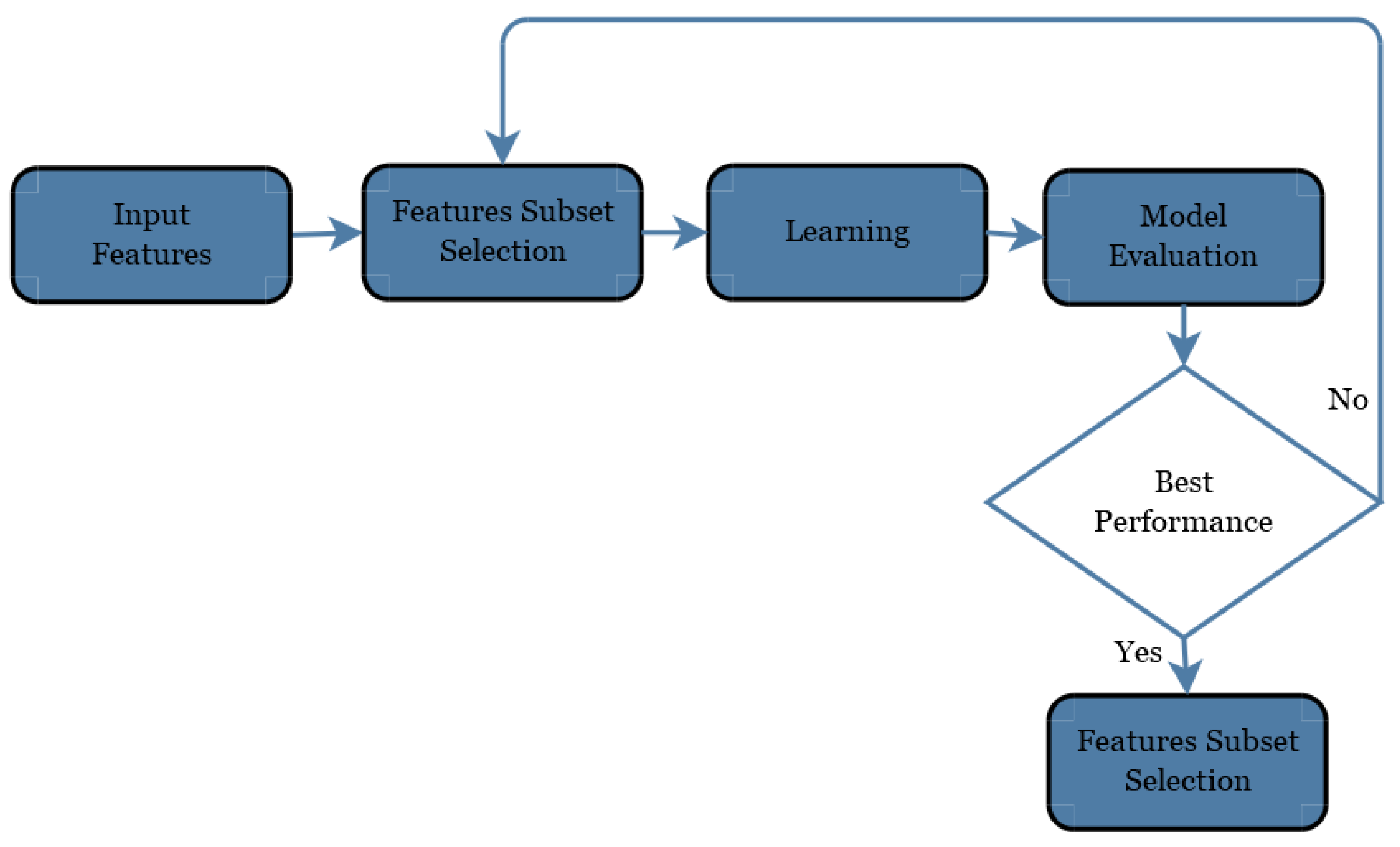
3.4. Third Layer: Feature Extraction and Feature Reduction
Reducing the number of characteristics from the features list is the method to remove those functionalities which may marginally effect the classification [
37]. Feature reduction helps in reducing the overfitting and data set imbalance problems. The reliability of reducing the features is therefore one of the most significant aspects affecting the precision rate of the detection model.
In the phase of feature extraction, the features are synthesized which are valuable in locating the malevolent behavior of the Bot and these characteristics are obtained in 29 iterator qualities based on 60-s connections. The interpretation of a link is obtained as the subgroup of packets received between two different networks (source port, source IP address, destination port, and destination IP address). All features are obtained explicitly from the control packet header via a thorough check of the payload material of the packets instead of previous approaches. The efficiency is therefore improved and utilization of the computational resources is reduced e.g., memory allocation and processing. The feature list was collected from the 60-s connection and consists of 60-s connection function vector.
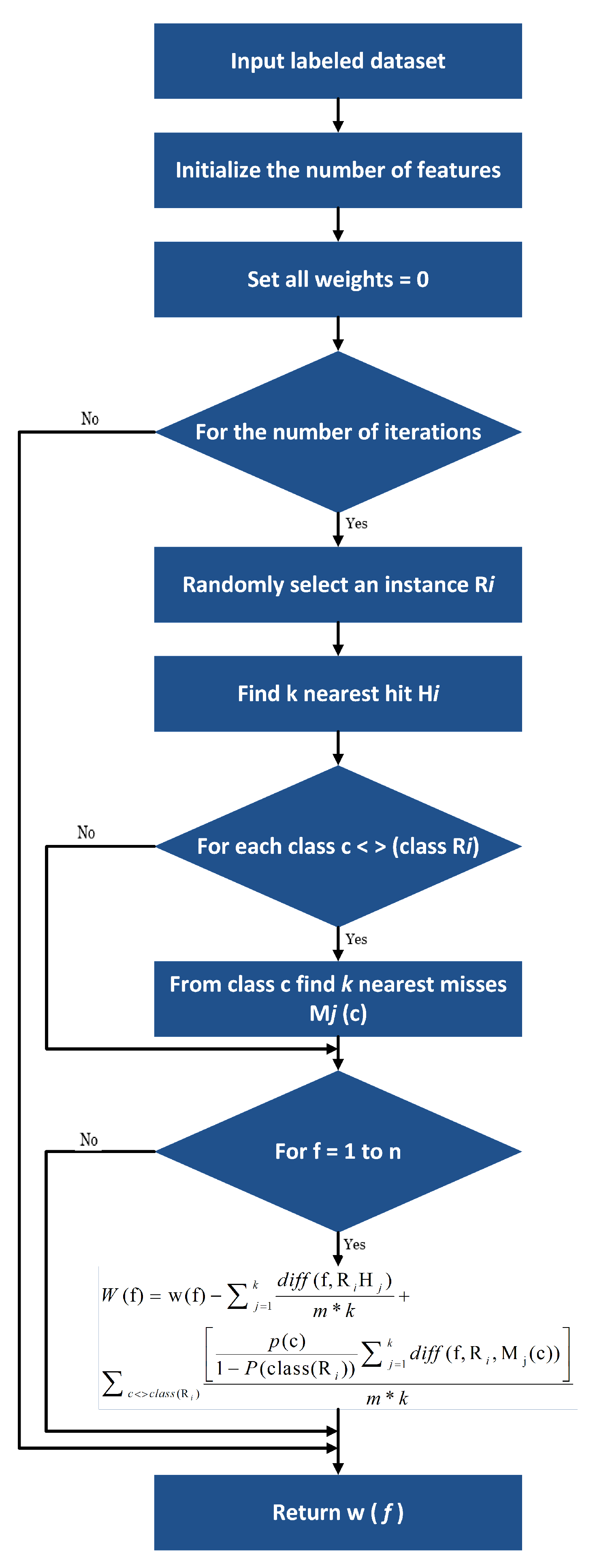
The purpose of this study is to select an appropriate subset of features that will enhance the efficiency of the machine learning classifiers and reduce model complexity without drastically reducing the precision. We used a classification technique for feature reduction to eliminate less important features in order to reduce the amount of data, in order to achieve better levels of accuracy. The decision tree consists of two node types: two children’s internal nodes and children’s leaf nodes. Any internal node has a decision mechanism to demonstrate the next node to visit. Training samples containing a number of features starts the construction of the tree. During construction of the tree, the training set is repetitively divided into small subsets. A predicted class is assigned to each resulting node based on the decision matrix of the class distribution in the training set. The internal node test is determined on the basis of an impurity measurement to pick the selected function and threshold values. The most common impurity metric is entropy impurity [
38], which we used for feature reduction, is shown in
Figure 6.
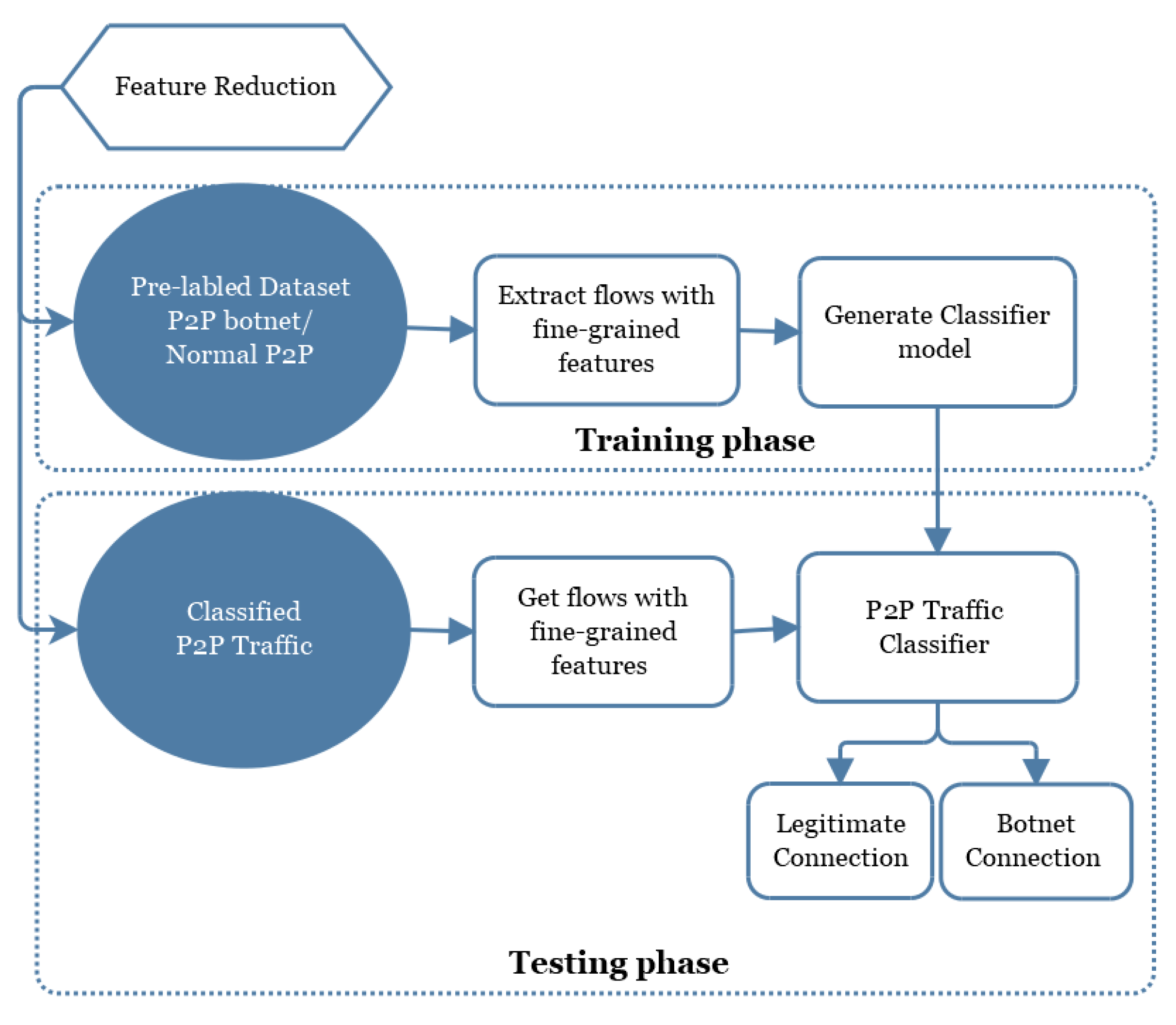
3.5. Fourth Layer: P2P Traffic Classification
According to data flow characteristics analysis of P2P botnet, the traffic characteristics of benign and botnets are similar. Therefore, this paper uses the session-based strategy for feature extraction. Thus, improving the detection efficiency by reducing the number of stream features and the number of data for same destination address in same session. P2P zombie host and other suspicious host communication processes automatically initiate a connection using a malicious program or code. The flow of the duration is generally short and very fixed. Therefore, we can extract the session features such as the average, maximum, minimum, and standard deviation of the duration of the session, and the average interval of the upstream (downstream) stream packets in the session.
Figure 7 demonstrates the flow diagram and Algorithm 2 describes the mechanism of P2P traffic classification which is fourth layer in our proposed model.
| Algorithm 2 Fourth Layer: P2P Traffic Classification |
- INPUT:
Pre-labled Dataset from the second layer (Non-P2P/P2P Session) - OUTPUT:
Legitimate Connection/Botnet Connection - -
Traning Phase: - Step1:
Inset Pre-labled Dataset i.e., Non-P2P Traffic/P2P Traffic - Step2:
Extract Flows with fine-grained features - Step3:
Generate Classifier Model Go to Step 6. - -
Classifying Phase: - Step4:
Classified P2P Traffic - Step5:
Get flows with fine-grained features gain the features of the p2p traffic. - Step6:
P2P Traffic Classifier classify the P2P traffic in two classes as follows: Legitimate connection, Botnet Connection - Step7:
Return
|
In the process of communication between two nodes in the P2P botnet, the size and transmission quantity of the transmitted packets are relatively small, and the C & C communication flow generated by the zombie host in the same network has great similarity. Therefore, we can distinguish between normal P2P network traffic and P2P botnet traffic by distributing the traffic into small sessions.In summary, all the features which were extracted from the session are shown in
Table 2.
5. Conclusions
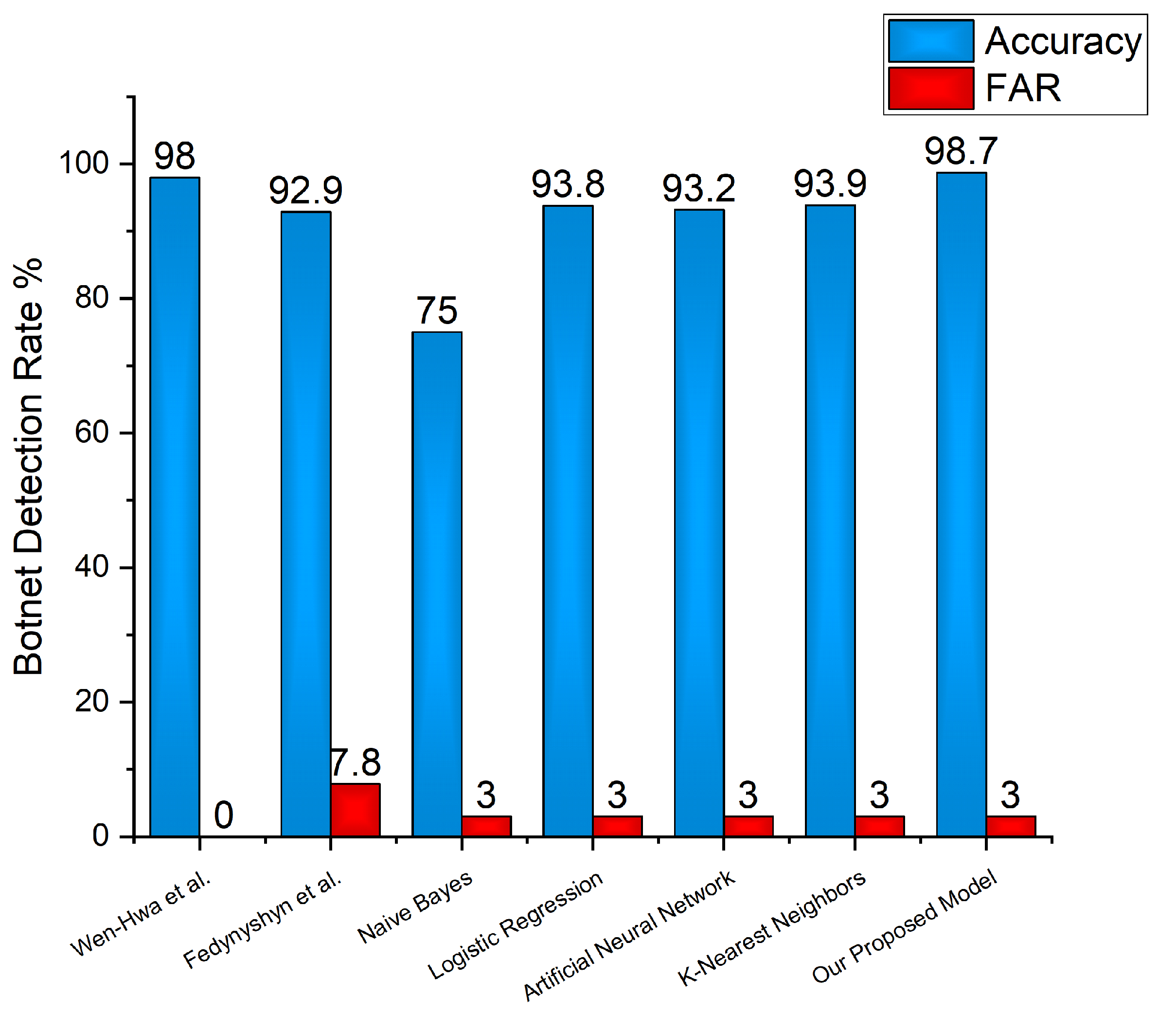
This study demonstrates some efficient results by analysing the network traffic about the most relevant attacks: IRC, SPAM, Click Fraud, DDoS, FastFlux, Port Scan, Compiled and Controlled record by CTU, HTTP, Waledac, Storm and Zeus botnets. Our results prove the significance of the proposed framework as compared to the results obtained from different classifiers. It was observed that the Decision Tree algorithm had a high accuracy to detect P2P botnet traffic. A multi-layer hybrid technique for P2P botnet detection is proposed on the basis of session features. First, non-P2P traffic was filtered by packet, stream and session levels, respectively. Next, P2P botnet classifiers were used to classify the Normal P2P communication and P2P botnet on the basis of session features. Finally, this study combines the advantages of two different detection strategies i.e., Detection Methods Based on traffic behavior and Detection Method Based on Flow Similarity. The validity of the proposed method was verified by using aforementioned datasets. The network environment was set up in the lab of cyber security at UESTC. The experimental results show the significance of the multi-layer technique in the detection of P2P botnet traffic effectively, using the decision tree classifier. We evaluated the model by comparing the five different classifiers and two other previously published models and noted that our proposed model has a higher accuracy than others.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}