Classification of Marine Vessels with Multi-Feature Structure Fusion


Abstract
:1. Introduction
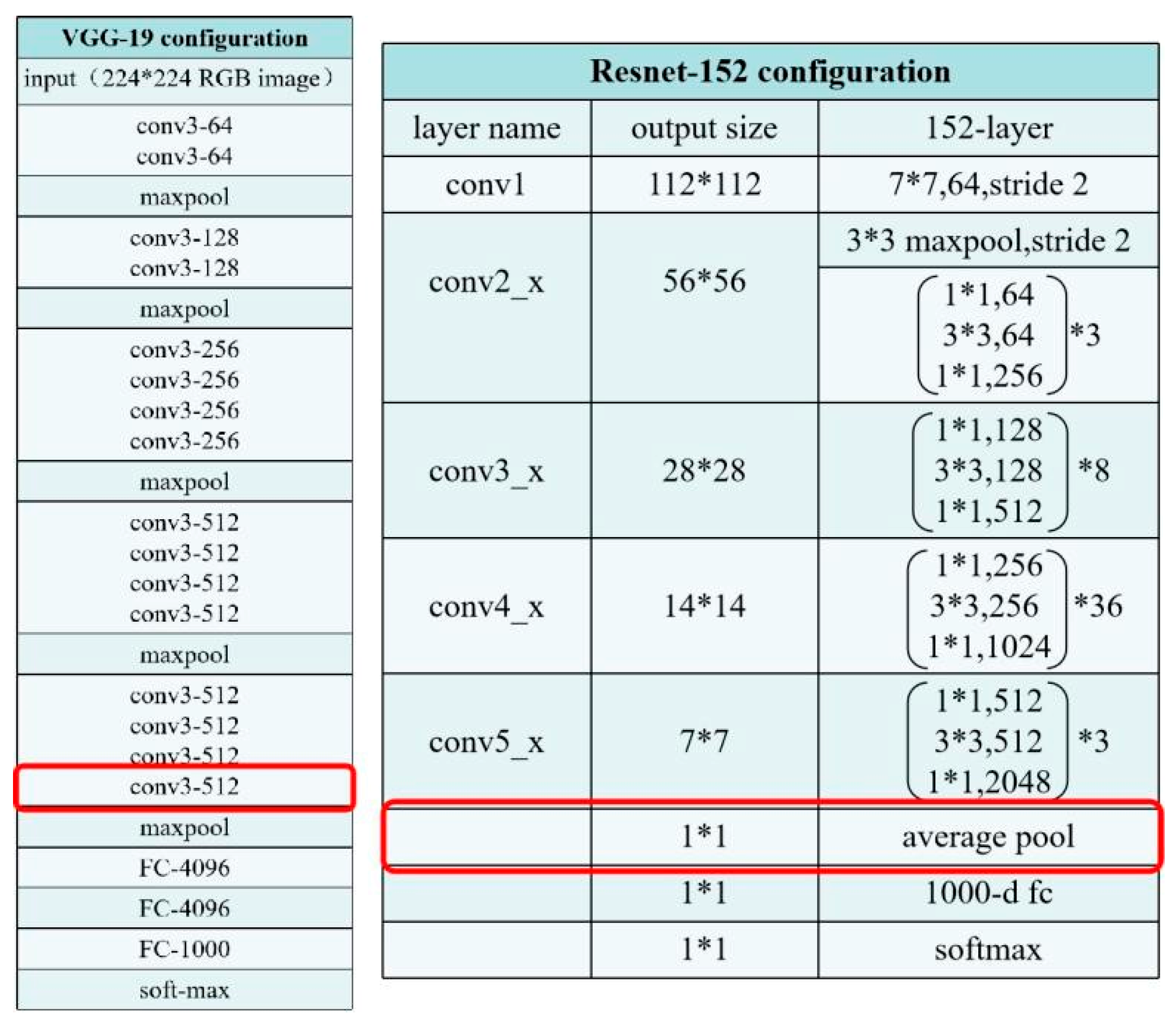
2. Feature Selection
3. Multi-feature Structure Fusion Based on Linear Discriminant Analysis
3.1. Linear Discriminant Analysis
3.2. Structure Fusion Mechanism
3.3. Multi-feature Structure Fusion Based on Linear Discriminant Analysis
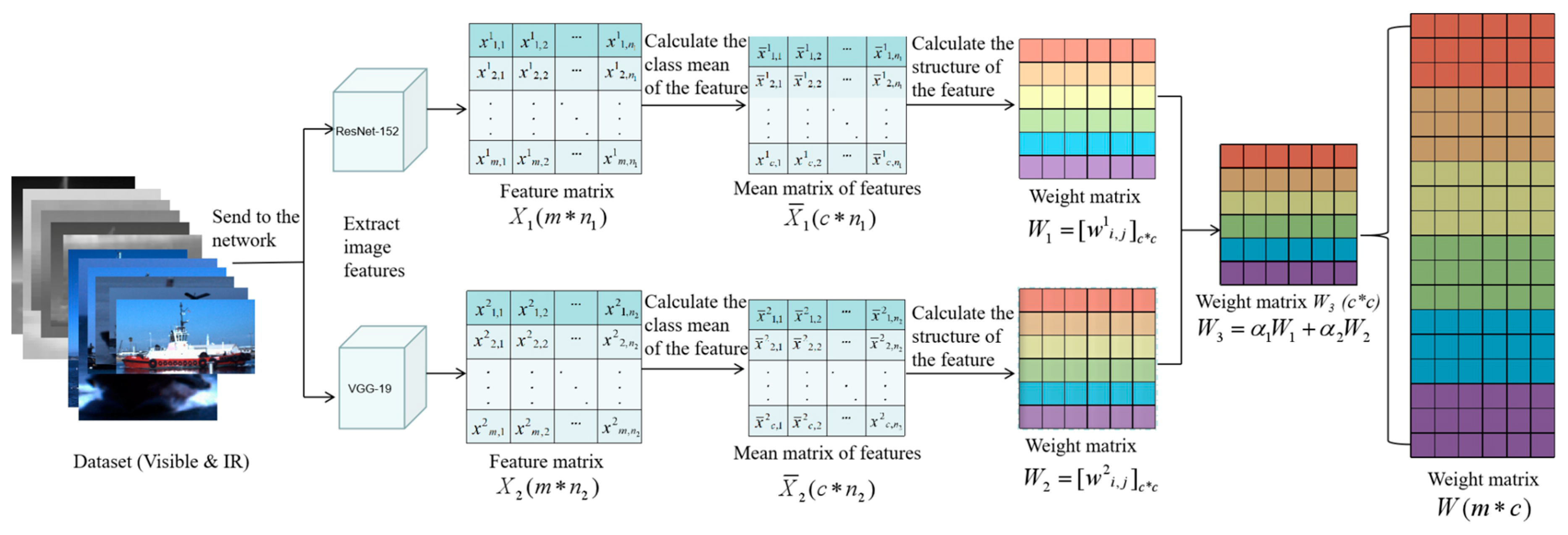
3.3.1. Weight Matrix Construction of the Same Kind Feature
3.3.2. Weight Matrix Fusion of Different Kind Features
3.3.3. Weight Matrix Generation after Feature Weighting
4. Experimental Results and Analysis
4.1. Dataset
4.2. Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Margarit, G.; Tabasco, A. Ship classification in single-pol SAR images based on fuzzy logic. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3129–3138. [Google Scholar] [CrossRef]
- Leclerc, M.; Tharmarasa, R.; Florea, M.C.; Boury-Brisset, A.C.; Kirubarajan, T.; Duclos-Hindié, N. Ship Classification using Deep Learning Techniques for Maritime Target Tracking. In Proceedings of the 21st International Conference on Information Fusion, Cambridge, UK, 10–13 July 2018; pp. 737–744. [Google Scholar]
- Eldhuset, K. An automatic ship and ship wake detection system for spaceborne SAR images in coastal regions. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1010–1019. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Zhang, M.M.; Choi, J.; Daniilidis, K.; Wolf, M.T.; Kanan, C. VAIS: A Dataset for Recognizing Maritime Imagery in the Visible and Infrared Spectrums. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 19 October 2015. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Zhang, D.F.; Zhang, J.S.; Yao, K.M. Infrared ship-target recognition based on SVM classification. Infrared Laser Eng. 2016, 45, 167–172. [Google Scholar]
- Feineigle, P.A.; Morris, D.D.; Snyder, F.D. Ship recognition using optical imagery for harbor surveillance. In Proceedings of the Association for Unmanned Vehicle Systems International (AUVSI), Washington, DC, USA, 6–9 August 2007; pp. 249–263. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vision. 2013, 105, 222–245. [Google Scholar]
- Huang, L.; Li, W.; Chen, C.; Zhang, F.; Lang, H. Multiple features learning for ship classification in optical imagery. Multimedia Tools Appl. 2018, 77, 13363–13389. [Google Scholar] [CrossRef]
- Akilan, T.; Wu, Q.J.; Zhang, H. Effect of fusing features from multiple DCNN architectures in image classification. IET Image Proc. 2018, 12, 1102–1110. [Google Scholar] [CrossRef]
- Shi, Q.; Li, W.; Zhang, F.; Hu, W.; Sun, X.; Gao, L. Deep CNN with Multi-Scale Rotation Invariance Features for Ship Classification. IEEE Access 2018, 6, 38656–38668. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, E.; Chen, W. Deep neural network for halftone image classification based on sparse auto-encoder. Eng. Appl. Artif. Intell. 2016, 50, 245–255. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, E. A universal defect detection approach for various types of fabrics based on the Elo-rating algorithm of the integral image. Text. Res. J. 2019, 1–28, (online publication, in press). [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, Y.; Duan, J. Color Inverse Halftoning Method with the Correlation of Multi-Color Components Based on Extreme Learning Machine. Appl. Sci. 2019, 9, 841. [Google Scholar] [CrossRef]
- Ibrahim, Y. Development of a deep convolutional neural network-based system for object recognition in visible light and infrared images. Master’s Thesis, Ahmadu Bello University, Zaria, Kaduna State, Nigeria, 2017. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Shi, Q.; Li, W.; Tao, R.; Sun, X.; Gao, L. Ship Classification Based on Multifeature Ensemble with Convolutional Neural Network. Remote Sens. 2019, 11, 419. [Google Scholar] [CrossRef]
- Khellal, A.; Ma, H.; Fei, Q. Convolutional neural network based on extreme learning machine for maritime ships recognition in infrared images. Sensors 2018, 18, 1490. [Google Scholar] [CrossRef]
- Sun, Q.; Zeng, S.G.; Heng, P.G.; Xia, D.S. The theory of canonical correlation analysis and its application to feature fusion. Chin. J. Comput. 2005, 28, 1524–1533. [Google Scholar]
- Shen, X.B.; Sun, Q.S.; Yuan, Y.H. Orthogonal canonical correlation analysis and its application in feature fusion. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013. [Google Scholar]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Zhu, H.; Kang, X.; Fan, C.; Zhang, E. Multi-feature structure fusion of contours for unsupervised shape classification. Pattern Recognit. Lett. 2013, 34, 1286–1290. [Google Scholar] [CrossRef]
- Lin, G.; Zhu, H.; Kang, X.; Fan, C.; Zhang, E. Feature structure fusion and its application. Inf. Fusion. 2014, 20, 146–154. [Google Scholar] [CrossRef]
- Lin, G.; Fan, G.; Kang, X.; Zhang, E.; Yu, L. Heterogeneous feature structure fusion for classification. Pattern Recognit. 2016, 53, 1–11. [Google Scholar] [CrossRef]
- Lin, G.; Zhu, H.; Kang, X.; Miu, Y.; Zhang, E. Feature structure fusion modelling for classification. IET Image Proc. 2015, 9, 883–888. [Google Scholar] [CrossRef]
- He, X.; Niyogi, P. Locality preserving projections. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–13 December 2003; pp. 153–160. [Google Scholar]
- Cai, D.; He, X.; Han, J. SRDA: An efficient algorithm for large-scale discriminant analysis. IEEE Trans. Knowl. Data Eng. 2008, 20, 1–12. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2012; pp. 568–598. [Google Scholar]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Dimension | Accuracy | |
|---|---|---|---|
| Visible | IR | ||
| HOG | 31,248 | 72.40% | 57.18% |
| LBP | 256 | 76.27% | 56.67% |
| VGG-16(relu5-3) | 100,352 | 84.93% | 51.64% |
| VGG-16(relu6) | 4096 | 82.13% | 59.03% |
| VGG-19(relu5-4) | 100,352 | 86.53% | 67.71% |
| VGG-19(fc6) | 4096 | 85.60% | 63.16% |
| VGG-19(relu6) | 4096 | 81.87% | 63.16% |
| GoogLeNet(cls3_pool) | 1024 | 79.73% | 54.62% |
| ResNet-50(pool5) | 2048 | 84.27% | 64.30% |
| ResNet-101(pool5) | 2048 | 86.67% | 64.58% |
| ResNet-152(pool5) | 2048 | 84.93% | 69.13% |
| Data Partition | Class Number | Train Number (Sample Distribution) | Test Number (Sample Distribution) |
|---|---|---|---|
| coarse-grained | 6 | 1411(67~499) | 1453(89~538) |
| fine-grained | 15 | 1411(24~218) | 1453(26~219) |
| Method | Feature | Dimension | Visible | IR |
|---|---|---|---|---|
| Single feature+ SVM | VGG-19(relu5-4) | 100,352 | 86.53% | 67.71% |
| ResNet-152(pool5) | 2048 | 84.93% | 69.13% | |
| SFLPP [24] | ResNet-152(pool5) + VGG-19(relu5-4) | 85 | 84.93% | 65.43% |
| SRDA [29] | ResNet-152(pool5) + VGG-19(relu5-4) | 5 | 86.93% | 70.56% |
| The proposed SF-SRDA | ResNet-152(pool5) + VGG-19(relu5-4) | 5 | 87.60% | 70.98% |
| Method | Visible | IR | ||
|---|---|---|---|---|
| Train Time in 873 Images | Test Time in 750 Images | Train Time in 539 Images | Test Time in 703 Images | |
| VGG-19(relu5-4) + SVM | 31.02 | 0.03 | 94.74 | 0.03 |
| ResNet-152(pool5) + SVM | 1.74 | 0.004 | 1.58 | 0.005 |
| SFLPP [24] | 7.14 | 0.29 | 3.01 | 0.16 |
| SRDA [29] | 1.58 | 0.10 | 0.82 | 0.08 |
| The proposed SF-SRDA | 2.49 | 0.10 | 1.43 | 0.08 |
| Test Feature | Daytime | Nighttime | IR | ||
|---|---|---|---|---|---|
| Visible | IR | Visible + IR | IR | ||
| Gnostic Field [5] | 82.4% | 58.7% | 82.4% | 51.9% | - |
| CNN [5] | 81.9% | 54.0% | 82.1% | 59.9% | - |
| Gnostic Field + CNN [5] | 81.0% | 56.8% | 87.4% | 61.0% | - |
| Gabor + MS-CLBP [11] | 77.73% | - | - | - | - |
| MFL (decision-level) + ELM [11] | 85.07% | - | - | - | - |
| MFL (feature-level) + SVM [11] | 85.33% | - | - | - | - |
| HOG + SVM [19] | 71.87% | - | - | - | - |
| ME-CNN [19] | 87.33% | - | - | - | - |
| ELM-CNN [20] | - | - | - | - | 61.17% |
| LBP + SVM | 76.27% | - | - | - | 56.67% |
| HOG + SVM | 72.40% | - | - | - | 57.18% |
| SFLPP [24] | 84.93% | 70.67% | 79.60% | 46.75% | 65.43% |
| SRDA [29] | 86.93% | 74.68% | 86.52% | 55.84% | 70.56% |
| The proposed SF-SRDA | 87.60% | 74.68% | 87.98% | 57.79% | 70.98% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, E.; Wang, K.; Lin, G. Classification of Marine Vessels with Multi-Feature Structure Fusion. Appl. Sci. 2019, 9, 2153. https://doi.org/10.3390/app9102153
Zhang E, Wang K, Lin G. Classification of Marine Vessels with Multi-Feature Structure Fusion. Applied Sciences. 2019; 9(10):2153. https://doi.org/10.3390/app9102153
Chicago/Turabian StyleZhang, Erhu, Kelu Wang, and Guangfeng Lin. 2019. "Classification of Marine Vessels with Multi-Feature Structure Fusion" Applied Sciences 9, no. 10: 2153. https://doi.org/10.3390/app9102153