
Rail-STrans: A Rail Surface Defect Segmentation Method Based on Improved Swin Transformer


Abstract
:1. Introduction
- In response to the public rail dataset, which is small and in black and white, this paper presents a comprehensive and colorful dataset of rail surface defects, derived from field photography, data tagging, and data expansion.
- Adding two Local Perception Modules (LPMs) to the Swin Transformer coding network improves segmentation accuracy by providing local context information.
- The decoding network now includes the Multiscale Feature Fusion Module (MFFM), which effectively fuses feature information of defects at different scales during the decoding process. This results in improved accuracy of multiscale defect segmentation.
- The decoding network now includes the Spatial Detail Extraction Module (SDEM), which preserves spatial detail information and enhances the segmentation accuracy of small-scale defects.
2. Materials and Methods
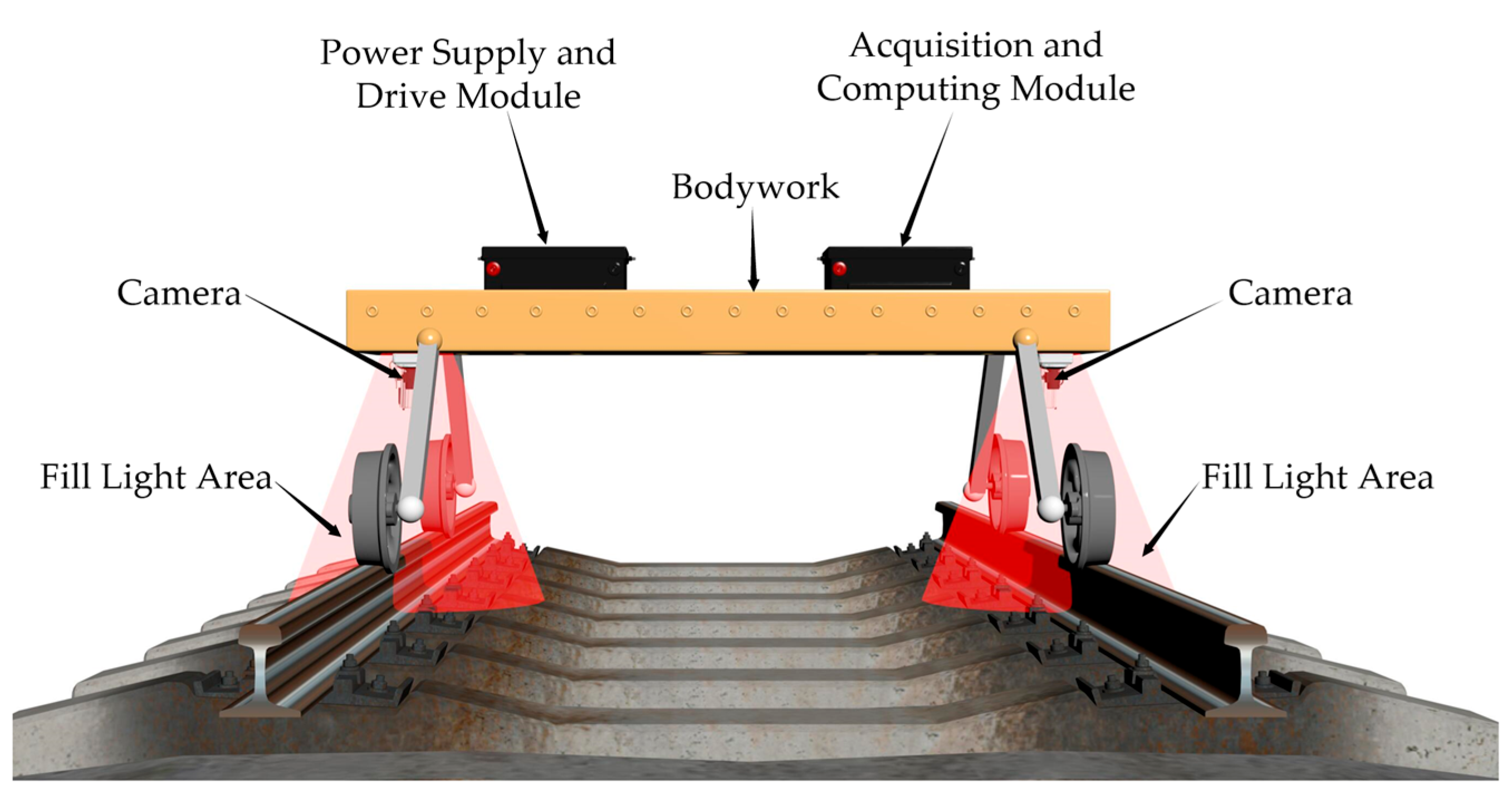
2.1. Dataset
2.2. Local Perception Module (LPM)
2.3. Multiscale Feature Fusion Module (MFFM)
2.4. Spatial Detail Extraction Module (SDEM)
2.5. Loss Function and Evaluation Metrics
3. Results
3.1. Experimental Environment
3.2. Experimental Results and Analysis
3.2.1. Ablation Experiments
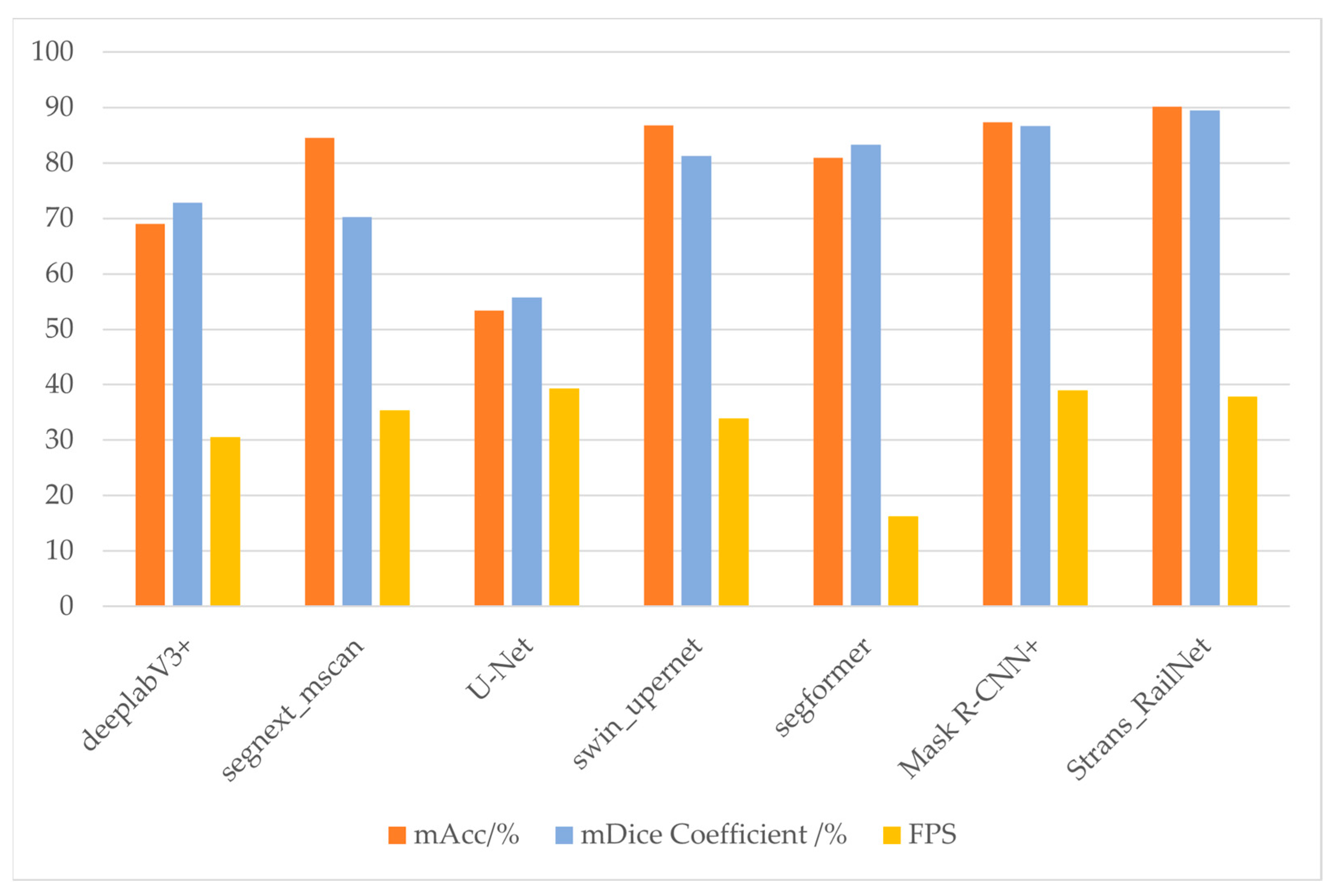
3.2.2. Comparison Experiments
- Model size: The model size of Rail-STrans is 357 M, which is slightly larger than deeplabV3+, larger than segnext_mscan, U-Net, and swin_upernet, and much smaller than SegFormer. The model size of Rail-STrans is moderate, which is larger than some lightweight networks, such as U-Net, but much smaller than SegFormer, which is much smaller, suggesting that it has some model compression advantages while maintaining high performance.
- mAcc (mean accuracy): Rail-STrans has the highest average accuracy of 90.1%, which means it has the best overall classification performance.
- mDice (mean dice) coefficient: Rail-STrans also has the highest average dice coefficient of 89.5%, indicating that it outperforms the other networks in terms of pixel-level segmentation accuracy.
- Defect accuracy and defect dice coefficient: In terms of defect segmentation, Rail-STrans has a defect accuracy of 80.78% and a defect dice coefficient of 79.46%, which is also relatively good and sometimes second only to SegFormer.
- Background accuracy and background dice coefficient: Rail-STrans performs very well in background classification and segmentation, with a background accuracy of 99.42% and a background dice coefficient of 99.54%, both of which are the highest among all networks.
- FPS (Frames Per Second): Although Rail-STrans does not have the highest FPS, it is still able to provide processing speeds in excess of 37 FPS, which is acceptable for many real-time applications.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jessop, C.; Ahlstrom, J.; Hammar, L.; Faester, S.; Danielsen, H.K. 3D Characterization of Rolling Contact Fatigue Crack Networks. Wear 2016, 366, 392–400. [Google Scholar] [CrossRef]
- Molodova, M.; Li, Z.; Nunez, A.; Dollevoet, R. Automatic Detection of Squats in Railway Infrastructure. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1980–1990. [Google Scholar] [CrossRef]
- Kou, L. A Review of Research on Detection and Evaluation of the Rail Surface Defects. Acta Polytech. Hung. 2022, 19, 167–186. [Google Scholar] [CrossRef]
- Xiong, Z.; Li, Q.; Mao, Q.; Zou, Q. A 3D Laser Profiling System for Rail Surface Defect Detection. Sensors 2017, 17, 1791. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Xie, W.; Ahmed, S.M.; Li, C.R. Defect Detection Method for Rail Surface Based on Line-Structured Light. Measurement 2020, 159, 107771. [Google Scholar] [CrossRef]
- Liu, Z.; Li, W.; Xue, F.; Xiafang, J.; Bu, B.; Yi, Z. Electromagnetic Tomography Rail Defect Inspection. IEEE Trans. Magn. 2015, 51, 6201907. [Google Scholar] [CrossRef]
- Fan, C.; Li, H.; Yan, B.; Sun, Y.; He, T.; Huang, T.; Yan, Z.; Sun, Q. High-Precision Distributed Detection of Rail Defects by Tracking the Acoustic Propagation Waves. Opt. Express 2022, 30, 39283–39293. [Google Scholar] [CrossRef] [PubMed]
- Kundu, T.; Datta, A.K.; Topdar, P.; Sengupta, S. Optimal Location of Acoustic Emission Sensors for Detecting Rail Damage. Proc. Inst. Civ. Eng.-Struct. Build. 2022, 177, 254–263. [Google Scholar] [CrossRef]
- Li, Q.; Ren, S. A Real-Time Visual Inspection System for Discrete Surface Defects of Rail Heads. IEEE Trans. Instrum. Meas. 2012, 61, 2189–2199. [Google Scholar] [CrossRef]
- Dubey, A.K.; Jaffery, Z.A. Maximally Stable Extremal Region Marking-Based Railway Track Surface Defect Sensing. IEEE Sens. J. 2016, 16, 9047–9052. [Google Scholar] [CrossRef]
- Yuan, X.; Wu, L.; Chen, H. Rail Image Segmentation Based on Otsu Threshold Method. Opt. Precis. Eng. 2016, 24, 1772–1781. [Google Scholar] [CrossRef]
- He, Z.; Wang, Y.; Mao, J.; Yin, F. Research on Inverse P-M Diffusion-Based Rail Surface Defect Detection. Acta Autom. Sin. 2014, 40, 1667–1679. [Google Scholar]
- Shi, T.; Kong, J.; Wang, X.; Liu, Z.; Zheng, G. Improved Sobel Algorithm for Defect Detection of Rail Surfaces with Enhanced Efficiency and Accuracy. J. Cent. South Univ. 2016, 23, 2867–2875. [Google Scholar] [CrossRef]
- He, Z.; Wang, Y.; Liu, J.; Yin, F. Background Differencing-Based High-Speed Rail Surface Defect Image Segmentation. Chin. J. Sci. Instrum. 2016, 37, 640–649. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, H.; Wang, X. Research on Rail Surface Defect Detection Method Based on Gray Equalization Model Combined with Gabor Filter. Surf. Technol. 2018, 19, 745–755. [Google Scholar]
- Wang, H.; Wang, M.; Zhang, H.; Liu, G. Vision Saliency Detection of Rail Surface Defects Based on PCA Model and Color Features. Process Autom. Instrum. 2017, 38, 73–76. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Sresakoolchai, J.; Stittle, H. Machine Learning to Identify Dynamic Properties of Railway Track Components. Int. J. Struct. Stab. Dyn. 2022, 22, 2250109. [Google Scholar] [CrossRef]
- Sresakoolchai, J.; Kaewunruen, S. Railway Defect Detection Based on Track Geometry Using Supervised and Unsupervised Machine Learning. Struct. Health Monit.-Int. J. 2022, 21, 1757–1767. [Google Scholar] [CrossRef]
- Zhang, Z.; Che, X.; Song, Y. An Improved Convolutional Neural Network for Convenient Rail Damage Detection. Front. Energy Res. 2022, 10, 1007188. [Google Scholar] [CrossRef]
- Li, Q.; Yuan, X.; Li, Y.; Zhu, Z. Rail Base Flaw Detection and Quantification Based on the Modal Curvature Method and the Back Propagation Neural Network. Eng. Fail. Anal. 2022, 142, 106792. [Google Scholar] [CrossRef]
- Liu, W.; Tang, Z.; Lv, F.; Chen, X. An Efficient Approach for Guided Wave Structural Monitoring of Switch Rails Via Deep Convolutional Neural Network-Based Transfer Learning. Meas. Sci. Technol. 2023, 34, 024004. [Google Scholar] [CrossRef]
- Zheng, D.; Li, L.; Zheng, S.; Chai, X.; Zhao, S.; Tong, Q.; Wang, J.; Guo, L. A Defect Detection Method for Rail Surface and Fasteners Based on Deep Convolutional Neural Network. Comput. Intell. Neurosci. 2021, 2021, 2565500. [Google Scholar] [CrossRef] [PubMed]
- Kou, L.; Sysyn, M.; Fischer, S.; Liu, J.; Nabochenko, O. Optical Rail Surface Crack Detection Method Based on Semantic Segmentation Replacement for Magnetic Particle Inspection. Sensors 2022, 22, 8214. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Ge, S.; He, Y.; Liu, J.; An, X. An Improved Feature Pyramid Network and Metric Learning Approach for Rail Surface Defect Detection. Appl. Sci. 2023, 13, 6047. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2016, arXiv:1605.06211. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Wang, Y.; Sun, Z.; Zhao, W. Encoder- and Decoder-Based Networks Using Multiscale Feature Fusion and Nonlocal Block for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1159–1163. [Google Scholar] [CrossRef]
- Hu, X.; Jing, L.; Sehar, U. Joint Pyramid Attention Network For Real-Time Semantic Segmentation of Urban Scenes. Appl. Intell. 2022, 52, 580–594. [Google Scholar] [CrossRef]
- Gu, Y.; Hao, J.; Chen, B.; Deng, H. Top-Down Pyramid Fusion Network for High-Resolution Remote Sensing Semantic Segmentation. Remote Sens. 2021, 13, 4159. [Google Scholar] [CrossRef]
- Xiao, B.; Xu, B.; Bi, X.; Li, W. Global-Feature Encoding U-Net (GEU-Net) for Multi-Focus Image Fusion. IEEE Trans. Image Process. 2021, 30, 163–175. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef] [PubMed]
- Dong, H.; Song, K.; Wang, Y.; Yan, Y.; Jiang, P. Automatic Inspection and Evaluation System for Pavement Distress. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12377–12387. [Google Scholar] [CrossRef]
- Chen, L.; Xu, X.; Pan, L.; Cao, J.; Li, X. Real-Time Lane Detection Model Based on Non Bottleneck Skip Residual Connections and Attention Pyramids. PLoS ONE 2021, 16, e0252755. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Lei, Y.; Wang, Y.; Yang, W.; Qi, J. Hand Gesture Segmentation against Complex Background Based on Improved Atrous Spatial Pyramid Pooling. J. Ambient Intell. Humaniz. Comput. 2022, 14, 11795–11807. [Google Scholar] [CrossRef]
- Chen, B.; Tan, W.; Coatrieux, G.; Zheng, Y.; Shi, Y.Q. A Serial Image Copy-Move Forgery Localization Scheme with Source/Target Distinguishment. IEEE Trans. Multimed. 2021, 23, 3506–3517. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, J.; Huang, Z.; Tian, Y. FPANet: Feature Pyramid Aggregation Network For Real-Time Semantic Segmentation. Appl. Intell. 2022, 52, 3319–3336. [Google Scholar] [CrossRef]
- Liao, Y.; Liu, Q. Multi-Level and Multi-Scale Feature Aggregation Network for Semantic Segmentation in Vehicle-Mounted Scenes. Sensors 2021, 21, 3270. [Google Scholar] [CrossRef]
- Lin, Z.; Sun, W.; Tang, B.; Li, J.; Yao, X.; Li, Y. Semantic Segmentation Network with Multi-Path Structure, Attention Reweighting and Multi-Scale Encoding. Vis. Comput. 2023, 39, 597–608. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; Li, Y.; Jin, Y. Adaptive Multi-Scale Dual Attention Network for Semantic Segmentation. Neurocomputing 2021, 460, 39–49. [Google Scholar] [CrossRef]
- Zhang, X.; Du, B.; Wu, Z.; Wan, T. LAANet: Lightweight Attention-Guided Asymmetric Network for Real-Time Semantic Segmentation. Neural Comput. Appl. 2022, 34, 3573–3587. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. arXiv 2018, arXiv:1802.05751. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv 2021, arXiv:2012.15840. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. arXiv 2018, arXiv:1807.10221. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. arXiv 2022, arXiv:2209.0857. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Model Size/M | mAcc/% | mDice Coefficient/% | Background Acc/% | Defect Acc/% | Background Dice Coefficient/% | Defect Dice Coefficient/% |
|---|---|---|---|---|---|---|---|
| swin_upernet | 701 | 85.04 | 72.31 | 99.27 | 70.81 | 99.55 | 45.07 |
| swin_upernet + LPM | 701 | 85.13 | 84.36 | 99.44 | 70.82 | 99.62 | 69.10 |
| Swin Transformer + SDEM | 508 | 87.56 | 87.41 | 99.45 | 75.67 | 99.54 | 75.28 |
| Swin Transformer + MFFM | 556 | 86.44 | 85.11 | 99.43 | 73.45 | 99.56 | 70.66 |
| Swin Transformer + LPM + SDEM | 508 | 88.02 | 87.56 | 99.51 | 76.53 | 99.64 | 75.48 |
| Swin Transformer + MFFM + SDEM | 357 | 88.54 | 88.32 | 99.52 | 77.56 | 99.58 | 77.06 |
| Swin Transformer + LPM + MFFM | 556 | 86.98 | 87.62 | 99.32 | 74.64 | 99.63 | 75.61 |
| Rail-STrans | 357 | 90.1 | 89.5 | 99.42 | 80.78 | 99.54 | 79.46 |
| Model | Model Size/M | mAcc/% | mDice Coefficient/% | Background Acc/% | Defect Acc/% | Background Dice Coefficient/% | Defect Dice Coefficient/% | FPS |
|---|---|---|---|---|---|---|---|---|
| deeplabV3+ | 340 | 68.96 | 72.79 | 99.48 | 38.44 | 99.15 | 46.43 | 30.56 |
| segnext_mscan | 150 | 84.54 | 70.21 | 99.37 | 69.7 | 99.59 | 40.84 | 35.43 |
| U-Net | 118 | 53.4 | 55.72 | 96.54 | 10.26 | 96.21 | 15.32 | 39.36 |
| swin_upernet | 701 | 86.76 | 81.21 | 98.82 | 74.69 | 99.17 | 63.26 | 33.87 |
| SegFormer | 961 | 80.96 | 83.27 | 99.55 | 62.37 | 99.42 | 67.12 | 16.31 |
| Mask R-CNN+ | 225 | 87.37 | 86.66 | 99.85 | 74.87 | 99.44 | 73.88 | 39.01 |
| Rail-STrans | 357 | 90.1 | 89.5 | 99.42 | 80.78 | 99.54 | 79.46 | 37.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, C.; Luo, H.; Han, Y.; Ma, Z. Rail-STrans: A Rail Surface Defect Segmentation Method Based on Improved Swin Transformer. Appl. Sci. 2024, 14, 3629. https://doi.org/10.3390/app14093629
Si C, Luo H, Han Y, Ma Z. Rail-STrans: A Rail Surface Defect Segmentation Method Based on Improved Swin Transformer. Applied Sciences. 2024; 14(9):3629. https://doi.org/10.3390/app14093629
Chicago/Turabian StyleSi, Chenghao, Hui Luo, Yuelin Han, and Zhiwei Ma. 2024. "Rail-STrans: A Rail Surface Defect Segmentation Method Based on Improved Swin Transformer" Applied Sciences 14, no. 9: 3629. https://doi.org/10.3390/app14093629