
Optimization of Pickup Vehicle Scheduling for Steel Logistics Park with Mixed Storage

Abstract
:1. Introduction
- The pickup vehicle scheduling problem with mixed steel storage (PVSP-MSS) is investigated in this paper. The PVSP-MSS is formulated as a multi-objective mixed-integer linear programming model, aiming at simultaneously optimizing the makespan of pickup vehicles and the makespan of the steel logistics park. By solving this problem, the optimal yard allocation and loading sequence for vehicles can be obtained.
- The ESPEA is proposed to solve the PVSP-MSS with a high efficiency. In the proposed algorithm, a cooperative initialization strategy is first proposed to provide an initial solution for scheduling optimization. Then, insertion decoding is designed to optimize the quality of the solution by utilizing the idle time in the yard. Moreover, local search technology is proposed in the ESPEA to improve the solution quality by swapping pickup operations on critical paths in steel logistics parks.
- The experiments are executed based on the data from a real steel logistics park. The results show that compared with other algorithms, the proposed algorithm significantly reduces both the makespan of each pickup vehicle and the makespan of the steel logistics park.
2. Scheduling Framework and Pickup Vehicle Data
2.1. Scheduling Framework Based on the IIoT
2.2. Data of Pickup Vehicles
3. Pickup Vehicle Scheduling Model
3.1. Assumptions
- All vehicles have the same priority.
- All vehicles and yards are available at the start time of the steel logistics park.
- Interruptions during each operation do not occur.
- The transition time of vehicle operation is short and negligible.
3.2. Pickup Time Model
3.3. Variable Definitions
- (1)
- Parameters
| Total number of vehicles. | |
| m : | Total number of steel logistics park yards. |
| Set of vehicles, where . | |
| Set of yards in the steel logistics park, where . | |
| Index of vehicles, where . | |
| Number of operations of vehicles i. | |
| : | Set of operations of vehicle i, where . |
| : | Index of operations of vehicles i, where . |
| : | Index of yards, where . |
| The j operation of vehicle i. | |
| : | Optional set of yards for j operations of vehicle i. |
| : | Start time of operation . |
| : | Pickup time of operation at yard k. |
| : | Completion time of operation . |
| : | Makespan of steel logistics park. |
| : | Maximum makespan of all vehicles. |
| L : | A large number for maintaining the consistency of the inequality. |
- (2)
- Decision Variables
| : | Takes a value of 1 if the operation is processed at yard k and 0 otherwise. |
| : | Takes a value of 1 if the operation takes precedence over the operation at yard k and 0 otherwise. |
3.4. Mathematical Model for the PVSP-MSS
4. ESPEA for Solving the PVSP-MSS
4.1. Framework of the ESPEA
| Algorithm 1 Framework of the ESPEA |
|
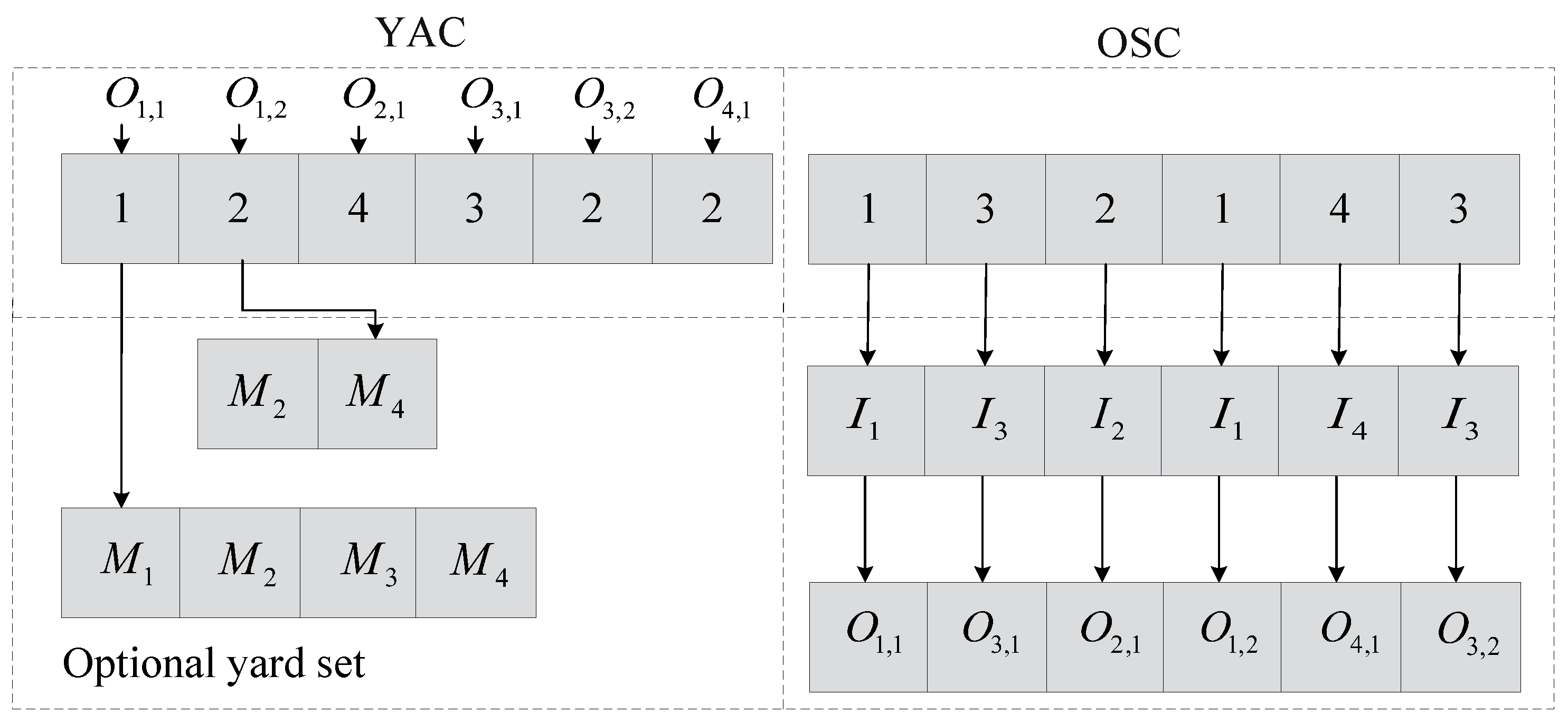
4.2. Particle Coding for Pickup Vehicle Arrangement
4.3. Cooperative Initialization Strategy
4.3.1. YWB
| Algorithm 2 Procedure of YWB |
|
4.3.2. MPT
| Algorithm 3 Procedure of MPT |
|
4.3.3. RVS
4.4. Insertion Decoding
4.4.1. Decoding the YAC
4.4.2. Decoding the OSC
4.5. Fitness Value
4.6. Environment Selection
4.7. Crossover and Mutation
4.7.1. Crossover Operator
4.7.2. Mutation Operator
4.8. Local Search Based on Critical Paths
| Algorithm 4 Local search based on critical paths |
|
5. Numerical Experiments
- (1)
- Validation of the proposed MILP model.
- (2)
- Effectiveness analysis of the improved strategies in the proposed ESPEA.
- (3)
- Comparison of the ESPEA with other multi-objective optimization algorithms on the PVSP-MSS.
5.1. Evaluation Metric
5.2. Test Data
5.3. Validation of the Proposed MILP Model
5.4. Effectiveness Analysis of Each Improved Strategy
5.5. Performance Analysis via an Algorithm Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PVSP-MSS | Pickup vehicle scheduling problem with mixed steel storage |
| ESPEA | Enhanced algorithm based on SPEA2 |
| IIoT | Industrial Internet of Things |
| LD | Linear dichroism |
| MILP | Mixed-integer linear programming |
| OSC | Operation sequence chain |
| YAC | Yard allocation chain |
| YWB | Yard workload balancing mechanism |
| MPT | Minimum pickup time mechanism |
| RVS | Random vehicle sequential mechanism |
| HV | Hypervolume |
References
- Beham, A.; Raggl, S.; Hauder, V.A.; Karder, J.; Wagner, S.; Affenzeller, M. Performance, quality, and control in steel logistics 4.0. Procedia Manuf. 2020, 42, 429–433. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, J.; Yuan, M.; Yuan, Y.; Chen, B.; Zhang, Q.; Chen, C.; Guan, X. Joint optimization of steel plate shuffling and truck loading sequencing based on deep reinforcement learning. Adv. Eng. Inform. 2024, 60, 102392. [Google Scholar] [CrossRef]
- Choi, J.; Xuelei, J.; Jeong, W. Optimizing the construction job site vehicle scheduling problem. Sustainability 2018, 10, 1381. [Google Scholar] [CrossRef]
- Li, H.; Yuan, J.; Lv, T.; Chang, X. The two-echelon time-constrained vehicle routing problem in linehaul-delivery systems considering carbon dioxide emissions. Transp. Res. Part D Transp. Environ. 2016, 49, 231–245. [Google Scholar] [CrossRef]
- Dong, C.; Wang, H.; Zhang, H.; Zhang, M.; Guan, J.; Zhang, Z.; Lin, Q.; Zuo, Z. Research on Fine Scheduling and Assembly Planning of Modular Integrated Building: A Case Study of the Baguang International Hotel Project. Buildings 2022, 12, 1892. [Google Scholar] [CrossRef]
- Lim, A.; Zhang, Z.; Qin, H. Pickup and delivery service with manpower planning in Hong Kong public hospitals. Transp. Sci. 2017, 51, 688–705. [Google Scholar] [CrossRef]
- Kulkarni, S.; Krishnamoorthy, M.; Ranade, A.; Ernst, A.T.; Patil, R. A new formulation and a column generation-based heuristic for the multiple depot vehicle scheduling problem. Transp. Res. Part B Methodol. 2018, 118, 457–487. [Google Scholar] [CrossRef]
- Wang, C.L.; Wang, Y.; Zeng, Z.Y.; Lin, C.Y.; Yu, Q.L. Research on logistics distribution vehicle scheduling based on heuristic genetic algorithm. Complexity 2021, 2021, 1–8. [Google Scholar] [CrossRef]
- Cota, P.M.; Nogueira, T.H.; Juan, A.A.; Ravetti, M.G. Integrating vehicle scheduling and open routing decisions in a cross-docking center with multiple docks. Comput. Ind. Eng. 2022, 164, 107869. [Google Scholar] [CrossRef]
- Wang, C.; Shi, H.; Zuo, X. A multi-objective genetic algorithm based approach for dynamical bus vehicles scheduling under traffic congestion. Swarm Evol. Comput. 2020, 54, 100667. [Google Scholar] [CrossRef]
- Liao, T.W. Integrated outbound vehicle routing and scheduling problem at a multi-door cross-dock terminal. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5599–5612. [Google Scholar] [CrossRef]
- Yağmur, E.; Kesen, S.E. Multi-trip heterogeneous vehicle routing problem coordinated with production scheduling: Memetic algorithm and simulated annealing approaches. Comput. Ind. Eng. 2021, 161, 107649. [Google Scholar] [CrossRef]
- Wen, W.; Chen, K.; Wang, J.; Xu, Z.; Wang, R.; Chen, B.; Zhang, Q. Vehicle Scheduling for Steel Logistics Based on Vehicle Batching. In Proceedings of the 2022 IEEE International Conference on Industrial Technology (ICIT), Shanghai, China, 22–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Tang, L.; Li, K. An Inherited Tabu Search Algorithm for the truck and trailer vehicle scheduling problem in iron and steel industry. ISIJ Int. 2009, 49, 51–57. [Google Scholar] [CrossRef]
- Kunnapapdeelert, S.; Thawnern, C. Capacitated vehicle routing problem for Thailand’s steel industry via saving algorithms. J. Syst. Manag. Sci. 2021, 11, 171–181. [Google Scholar]
- Pang, K.W.; Chan, H.L. Data mining-based algorithm for storage location assignment in a randomised warehouse. Int. J. Prod. Res. 2017, 55, 4035–4052. [Google Scholar] [CrossRef]
- Wang, J.; Xu, Z.; Wen, W.; Wang, R.; Lin, Y.; Yuan, Y.; Chen, B.; Zhang, Q. Optimization for Storage Scheduling of Steel Plates Based on Cloud Manufacturing Platform. IEEE Trans. Ind. Inform. 2023, 19, 11653–11663. [Google Scholar] [CrossRef]
- Simeone, A.; Zeng, Y.; Caggiano, A. Intelligent decision-making support system for manufacturing solution recommendation in a cloud framework. Int. J. Adv. Manuf. Technol. 2021, 112, 1035–1050. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK Rep. 2001, 103, 1–21. [Google Scholar]
- Gao, K.Z.; Suganthan, P.N.; Chua, T.J.; Chong, C.S.; Cai, T.X.; Pan, Q.K. A two-stage artificial bee colony algorithm scheduling flexible job-shop scheduling problem with new job insertion. Expert Syst. Appl. 2015, 42, 7652–7663. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, J. Flexible job-shop scheduling with flexible workdays, preemption, overlapping in operations and satisfaction criteria: An industrial application. Int. J. Prod. Res. 2016, 54, 4894–4918. [Google Scholar] [CrossRef]
- Doostali, S.; Babamir, S.M.; Eini, M. CP-PGWO: Multi-objective workflow scheduling for cloud computing using critical path. Clust. Comput. 2021, 24, 3607–3627. [Google Scholar] [CrossRef]
- While, L.; Hingston, P.; Barone, L.; Huband, S. A faster algorithm for calculating hypervolume. IEEE Trans. Evol. Comput. 2006, 10, 29–38. [Google Scholar] [CrossRef]
- Li, R.; Gong, W.; Lu, C. A reinforcement learning based RMOEA/D for bi-objective fuzzy flexible job shop scheduling. Expert Syst. Appl. 2022, 203, 117380. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2006, 11, 712–731. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2013, 18, 577–601. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
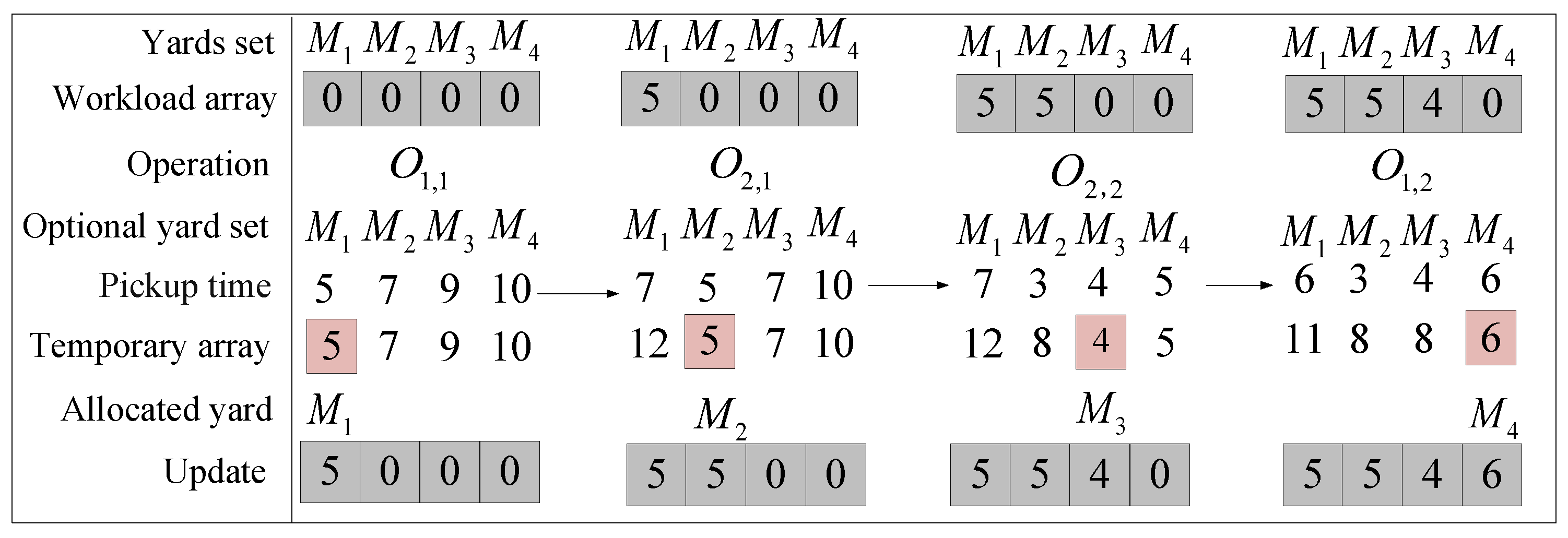{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Size | |
|---|---|---|
| Vehicle Number | Total Number of Operations | |
| 1 | 10 | 25 |
| 2 | 20 | 57 |
| 3 | 30 | 84 |
| 4 | 40 | 89 |
| 5 | 50 | 135 |
| 6 | 60 | 163 |
| 7 | 70 | 187 |
| 8 | 80 | 212 |
| 9 | 90 | 239 |
| 10 | 100 | 264 |
| V/O/Y | GUROBI | ESPEA | ||||
|---|---|---|---|---|---|---|
| 5/4/4 | 39 | 37 | 23.59 | 43 | 38 | 37.13 |
| 6/4/4 | 43 | 40 | 43,241 | 43 | 41 | 36.2 |
| 7/4/4 | - | - | - | 41 | 30 | 36.8 |
| 8/4/4 | - | - | - | 49 | 30 | 36.69 |
| 9/4/4 | - | - | - | 56 | 30 | 37.41 |
| 10/4/4 | - | - | - | 47 | 32 | 37.24 |
| Index | SPEA2 | ESPEA-1 | ESPEA-2 | ESPEA-3 | ||||
|---|---|---|---|---|---|---|---|---|
| aver | best | aver_gap | best_gap | aver_gap | best_gap | aver_gap | best_gap | |
| 1 | 0.54297521 | 0.557345 | 3.62% | 3.06% | 4.79% | 3.06% | 4.82% | 3.06% |
| 2 | 0.36817818 | 0.409204 | 14.87% | 8.46% | 17.06% | 10.03% | 19.94% | 11.89% |
| 3 | 0.35772439 | 0.380317 | 21.37% | 20.68% | 26.66% | 23.26% | 29.43% | 26.36% |
| 4 | 0.36172758 | 0.400679 | 17.41% | 12.94% | 22.50% | 16.72% | 25.56% | 19.06% |
| 5 | 0.33120254 | 0.35396 | 26.70% | 24.87% | 29.18% | 24.62% | 33.40% | 30.81% |
| 6 | 0.25820991 | 0.296639 | 37.35% | 24.16% | 41.45% | 25.86% | 47.79% | 31.36% |
| 7 | 0.22072806 | 0.248489 | 48.40% | 35.68% | 53.32% | 41.78% | 57.34% | 44.66% |
| 8 | 0.20389379 | 0.225313 | 57.08% | 49.95% | 59.15% | 47.52% | 64.47% | 57.68% |
| 9 | 0.21106804 | 0.224812 | 56.37% | 49.36% | 59.92% | 52.98% | 64.26% | 58.99% |
| 10 | 0.21625091 | 0.235104 | 53.35% | 47.19% | 56.03% | 48.36% | 61.94% | 52.91% |
| Algorithm | Special Parameters | Common Parameters |
|---|---|---|
| ESPEA | Near neighbor threshold k = Elite archive size = 100 | Maximum iteration number = 100 Popsize size = 100 Crossover rate = 1 Mutation = 0.8 |
| RMOEA/D | Memory size LP = 40 Learning rate = 0.4 Discount rate = 0.6 Greedy factor = 0.8 Neighborhood vector T = [5, 10, 15, 20] Vectors number = 100 | |
| MOEA/D | Neighborhood vector T = 20 Vector number = 100 | |
| NSGAII | None | |
| NSGAIII | None | |
| SPEA2 | Near neighbor threshold k = Elite archive size = 100 |
| Index | ESPEA | RMOEA/D | MOEA/D | SPEA2 | NSGAII | NSGAIII | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| aver | best | aver | best | aver | best | aver | best | aver | best | aver | best | |
| 1 | 0.56913054 | 0.574422 | 0.559479 | 0.572862 | 0.556422 | 0.558821 | 0.562658 | 0.57438 | 0.568211 | 0.57438 | 0.564754 | 0.574212 |
| 2 | 0.44158741 | 0.457874 | 0.435142 | 0.441398 | 0.412667 | 0.4349381 | 0.422917 | 0.443818 | 0.422483 | 0.43538 | 0.419455 | 0.444849 |
| 3 | 0.46301166 | 0.480571 | 0.448158 | 0.467332 | 0.432563 | 0.4433533 | 0.434173 | 0.458972 | 0.432443 | 0.444264 | 0.442867 | 0.455924 |
| 4 | 0.45417245 | 0.477058 | 0.440325 | 0.455548 | 0.419309 | 0.432326 | 0.424721 | 0.452521 | 0.431632 | 0.442927 | 0.434009 | 0.445102 |
| 5 | 0.44181358 | 0.463014 | 0.589584 | 0.610275 | 0.410716 | 0.434287 | 0.419627 | 0.441983 | 0.419262 | 0.430315 | 0.417667 | 0.429318 |
| 6 | 0.3816034 | 0.389679 | 0.352019 | 0.372049 | 0.349841 | 0.3614302 | 0.354652 | 0.368318 | 0.354481 | 0.369025 | 0.354934 | 0.370934 |
| 7 | 0.34729293 | 0.359455 | 0.328926 | 0.346557 | 0.321556 | 0.3286682 | 0.327551 | 0.337147 | 0.327222 | 0.334943 | 0.324626 | 0.341105 |
| 8 | 0.33535407 | 0.355284 | 0.318119 | 0.336925 | 0.308004 | 0.3128554 | 0.320283 | 0.337848 | 0.317105 | 0.327807 | 0.3167 | 0.323428 |
| 9 | 0.34669923 | 0.357434 | 0.317965 | 0.336408 | 0.326519 | 0.339133 | 0.330039 | 0.335774 | 0.329104 | 0.338439 | 0.329755 | 0.34147 |
| 10 | 0.35019048 | 0.359495 | 0.323144 | 0.338917 | 0.328994 | 0.3369403 | 0.331614 | 0.346047 | 0.330904 | 0.344449 | 0.33791 | 0.348614 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Xu, Z.; He, M.; Xue, L.; Xu, H. Optimization of Pickup Vehicle Scheduling for Steel Logistics Park with Mixed Storage. Appl. Sci. 2024, 14, 3628. https://doi.org/10.3390/app14093628
Wang J, Xu Z, He M, Xue L, Xu H. Optimization of Pickup Vehicle Scheduling for Steel Logistics Park with Mixed Storage. Applied Sciences. 2024; 14(9):3628. https://doi.org/10.3390/app14093628
Chicago/Turabian StyleWang, Jinlong, Zhezhuang Xu, Mingxing He, Liang Xue, and Hongjie Xu. 2024. "Optimization of Pickup Vehicle Scheduling for Steel Logistics Park with Mixed Storage" Applied Sciences 14, no. 9: 3628. https://doi.org/10.3390/app14093628