
Multi-Task Mean Teacher Medical Image Segmentation Based on Swin Transformer

Abstract
:1. Introduction
- We introduce a multi-task YOLOv5 with transformer (mt-transYL) framework for concurrent lesion segmentation and boundary detection from medical scans. Our experiments demonstrate enhanced diagnoses from this joint learning formulation.
- We introduce a student–teacher semi-supervised paradigm using consistency regularizations for further leveraging unlabeled data. Our mean teacher architecture exhibits strong self-ensembling capabilities amenable to limited annotation contexts.
- Comprehensive evaluations showcase our framework surpassing cutting-edge standards under multiple few-shot regimes by effectively amalgamating representations from related learning objectives alongside unlabeled data.
2. Related Works
2.1. Medical Image Segmentation
2.2. Semi-Supervised Learning
2.3. Transformers
3. Method
3.1. Multi-Task YOLOv5 with Transformer
3.1.1. Shadow Region Detection
- Up-sampling EFk to match the spatial resolution DF1
- Element-wise addition of DF1.
3.1.2. Shadow Edge Detection
3.2. YOLOv5 with Transformer Detection
3.3. Multi-Task Loss
3.3.1. Multi-Task Supervised Loss of Labeled Data
3.3.2. Intra-Task Consistency Loss
4. Experiments
4.1. Dataset and Experimental Settings
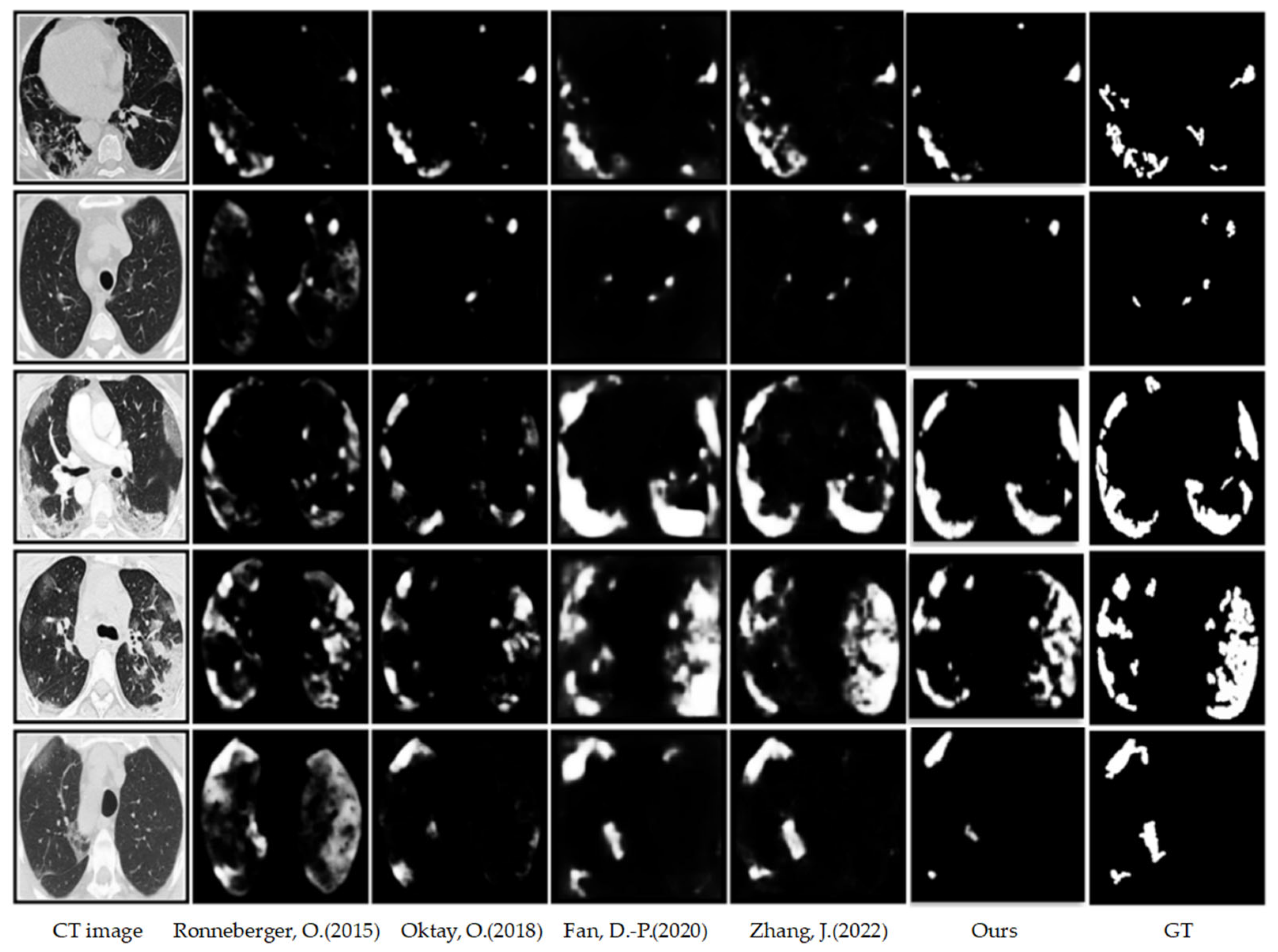
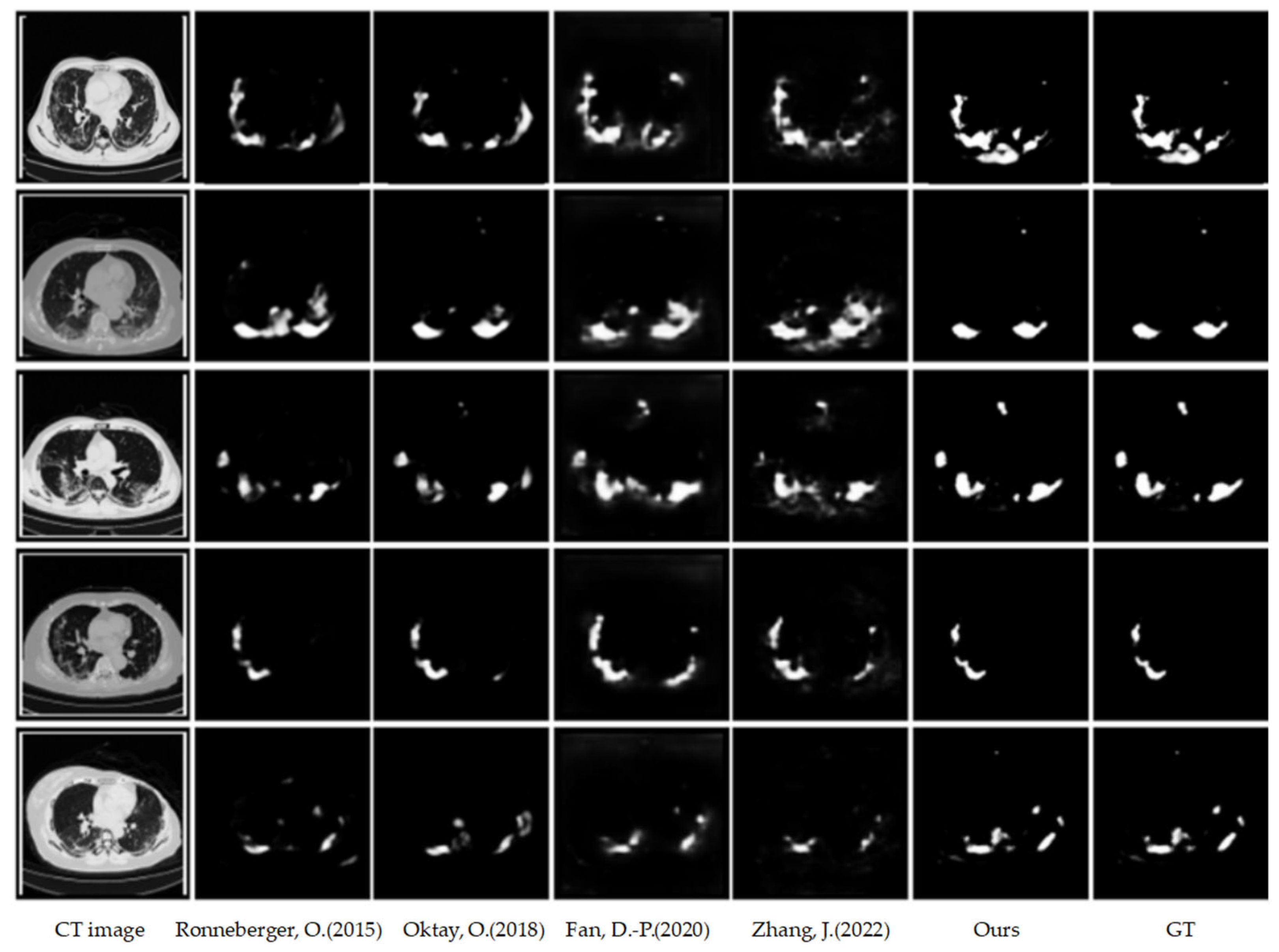
4.2. Results on COVID-SemiSeg Dataset
4.2.1. Qualitative Results on COVID-SemiSeg
4.2.2. Quantitative Results on COVID-SemiSeg
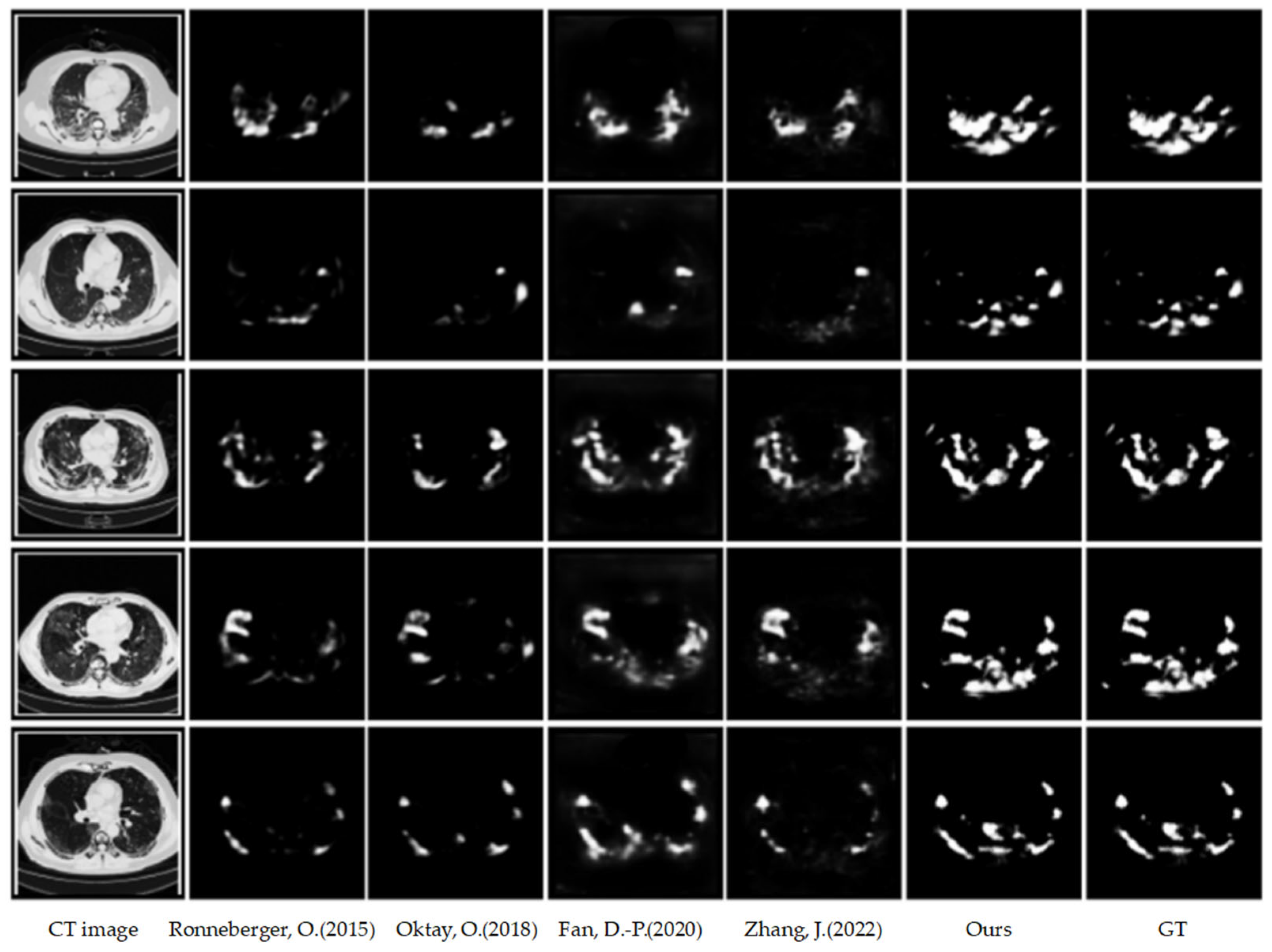
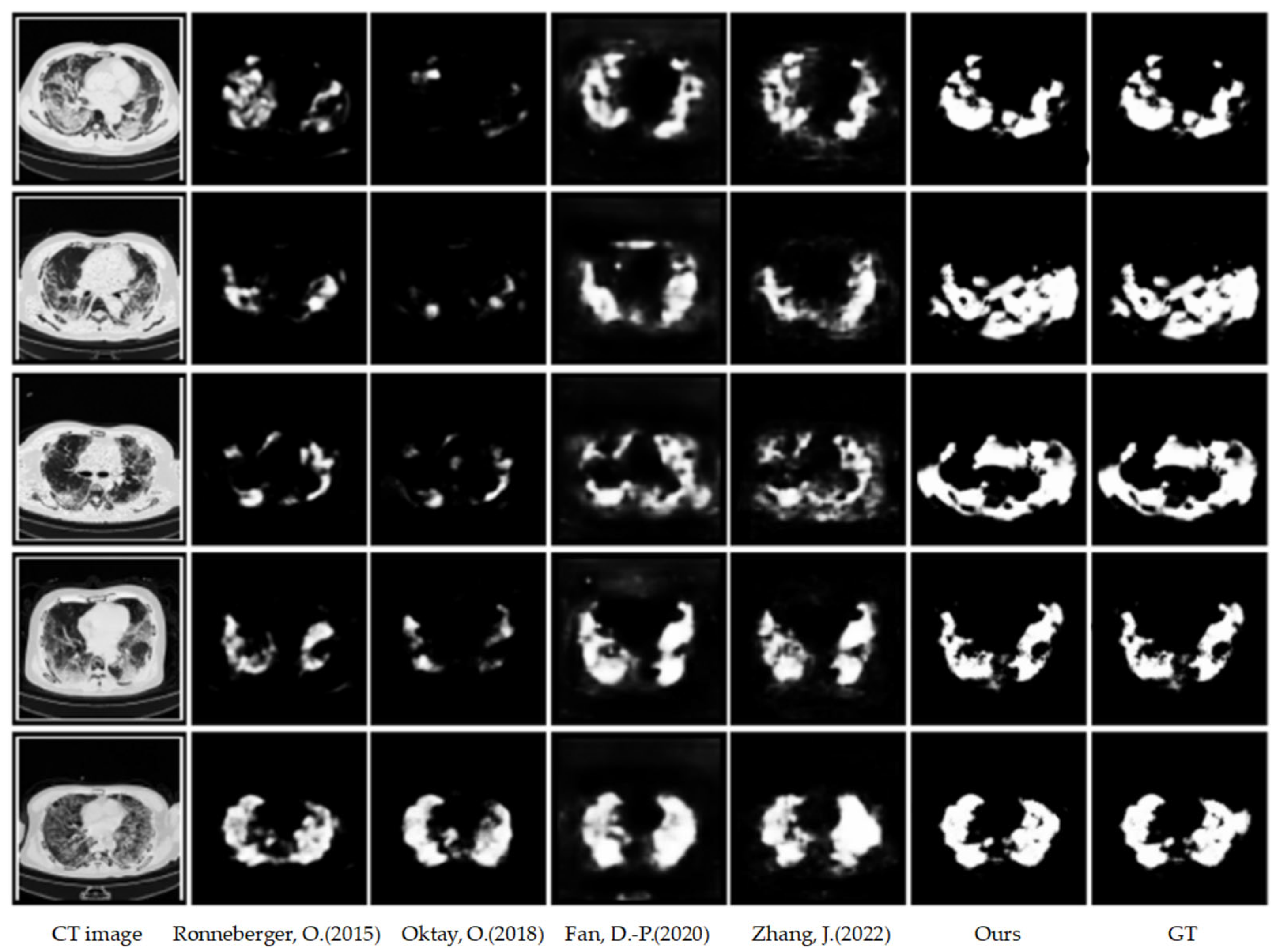
4.3. Results on COVID-HSS Dataset
4.3.1. Qualitative Results on COVID-HSS
4.3.2. Quantitative Results on COVID-HSS
4.4. Loss Function
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ye, Z.; Zhang, Y.; Wang, Y.; Huang, Z.; Song, B. Chest CT manifestations of new coronavirus disease 2019 (COVID-19): A pictorial review. Eur. Radiol. 2020, 30, 4381–4389. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical image segmentation using deep learning: A survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Jiao, R.; Zhang, Y.; Ding, L.; Xue, B.; Zhang, J.; Cai, R.; Jin, C. Learning with limited annotations: A survey on deep semi-supervised learning for medical image segmentation. Comput. Biol. Med. 2023, 169, 107840. [Google Scholar] [CrossRef] [PubMed]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.-A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic mri cardiac multistructures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef]
- Lalande, A.; Chen, Z.; Pommier, T.; Decourselle, T.; Qayyum, A.; Salomon, M.; Ginhac, D.; Skandarani, Y.; Boucher, A.; Brahim, K.; et al. Deep learning methods for automatic evaluation of delayed enhancement-mri. the results of the emidec challenge. Med. Image Anal. 2022, 79, 102428. [Google Scholar] [CrossRef]
- Xiong, Z.; Xia, Q.; Hu, Z.; Huang, N.; Bian, C.; Zheng, Y.; Vesal, S.; Ravikumar, N.; Maier, A.; Yang, X.; et al. A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2021, 67, 101832. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Y.; Gu, S.; Zhu, C.; Ge, C.; Zhang, Y.; An, X.; Wang, C.; Wang, Q.; Liu, X.; et al. Abdomenct-1k: Is abdominal organ segmentation a solved problem. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6695–6714. [Google Scholar] [CrossRef]
- Heller, N.; Isensee, F.; Maier-Hein, K.H.; Hou, X.; Xie, C.; Li, F.; Nan, Y.; Mu, G.; Lin, Z.; Han, M.; et al. The state of the art in kidney and kidney tumor segmentation in contrast-enhanced ct imaging: Results of the kits19 challenge. Med. Image Anal. 2020, 67, 101821. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.N.; Wu, Z.; Ding, X. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liao, Q.; Yuan, L.; Zhu, H.; Xing, J.; Zhang, J. Exploiting shared knowledge from non-covid lesions for annotation-effificient COVID-19 ct lung infection segmentation. IEEE J. Biomed. Health Inform. 2021, 25, 4152–4162. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, L.; Wan, L.; Wang, S.; Feng, W.; Heng, P.-A. A Multi-task Mean Teacher for Semi-supervised Shadow Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- You, C.; Dai, W.; Min, Y.; Liu, F.; Clifton, D.A.; Zhou, S.K.; Staib, L.H.; Duncan, J.S. Rethinking semi-supervised medical image segmentation: A variance-reduction perspective. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2024; Volume 36. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Li, S.; Zhang, C.; He, X. Shape-aware semi-supervised 3d semantic segmentation for medical images. In Proceedings of the Conference on Medical Image Computing and Computer—Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Cham, Switzerland, 2020; pp. 552–561. [Google Scholar]
- Luo, X.; Chen, J.; Song, T.; Wang, G. Semi-supervised medical image segmentation through dual-task consistency. Proc. AAAI Conf. Artif. Intell. 2021, 35, 8801–8809. [Google Scholar] [CrossRef]
- Wu, J.; Fu, R.A.; Fang, H.; Zhang, Y.; Yang, Y.; Xiong, H.; Liu, H.; Xu, Y. Medsegdiff: Medical image segmentation with diffusion probabilistic model. In Proceedings of the Medical Imaging with Deep Learning, Tromsø, Norway, 9–11 January 2024. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, K.; Wang, J.; Liu, J.; Kang, M.; Pan, Z. Trans-Inf-Net: COVID-19 Lung Infection Segmentation based on Transformer. In Proceedings of the 8th ICVR, Nanjing, China, 26–28 May 2022; pp. 306–312. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Shi, F.; Wang, J.; Shi, J.; Wu, Z.; Wang, Q.; Tang, Z.; He, K.; Shi, Y.; Shen, D. Review of artifificial intelligence techniques in imaging data acquisition, segmentation and diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 2020, 14, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Hu, Y.-C.; Liu, C.-J.; Halpenny, D.; Hellmann, M.D.; Deasy, J.O.; Mageras, G.; Veeraraghavan, H. Multiple resolution residually connected feature streams for automatic lung tumor segmentation from CT images. IEEE Trans. Med. Imaging 2019, 38, 134–144. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kohl, S.; Romera-Paredes, B.; Meyer, C.; De Fauw, J.; Ledsam, J.R.; MaierHein, K.; Ronneberger, O. A probabilistic u-net for segmentation of ambiguous images. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 6965–6975. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Glocker, B.; Rueckert, D. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhao, N.; Tong, N.; Ruan, D.; Sheng, K. Fully Automated Pancreas Segmentation with Two-Stage 3D Convolutional Neural Networks. In Medical Image Computing and Computer Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2019; pp. 201–209. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Tang, Y.; Tang, Y.; Xiao, J.; Summers, R.M. TUNA-Net: Task-oriented Unsupervised Adversarial Network for Disease Recognition in CrossDomain Chest X-rays. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 431–440. [Google Scholar]
- Cheplygina, V.; de Bruijne, M.; Pluim, J.P. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, L.; Chen, J.; Fredericksen, M.; Hughes, D.P.; Chen, D.Z. Deep adversarial networks for biomedical image segmentation utilizing unannotated images. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2017; pp. 408–416. [Google Scholar]
- Bai, W.; Oktay, O.; Sinclair, M.; Suzuki, H.; Rajchl, M.; Tarroni, G.; Glocker, B.; King, A.; Matthews, P.M.; Rueckert, D. Semi-supervised learning for networkbased cardiac MR image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2017; pp. 253–260. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Effificient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems 2011, Granada, Spain, 2–14 December 2011; pp. 109–117. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.-W.; Heng, P.-A. Uncertainty-aware self-ensembling model for semisupervised 3D left atrium segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer: Cham, Switzerland, 2019; pp. 605–613. [Google Scholar]
- Roy, S.; Koehler, G.; Ulrich, C.; Baumgartner, M.; Petersen, J.; Isensee, F.; Jaeger, P.F.; Maier-Hein, K. Mednext: Transformer-driven scaling of convnets for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer Nature: Cham, Switzerland, 2023. [Google Scholar]
- Rahman, M.M.; Marculescu, R. Multi-scale hierarchical vision transformer with cascaded attention decoding for medical image segmentation. In Proceedings of the Medical Imaging with Deep Learning, Paris, France, 3–5 July 2024. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Xie, S.; Girshick, R.; Doll, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P. Deeply supervised salient object detection with short connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.-W.; Xu, X.; Qin, J.; Heng, P.-A. Bidirectional feature pyramid network with recurrent attention residual modules for shadow detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 121–136. [Google Scholar]
- Fan, D.-P.; Yang, J.-F.; Cheng, M.-M.; Zhao, J.-X.; Liu, J.-J. EGNet: Edge guidance network for salient object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Cheng, M.-M.; Feng, J.; Jiang, J.; Liu, J.; Hou, Q. A simple pooling-based design for real-time salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the ECCV 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar]
- Zhang, Y.; Zhang, J. Dual-task mutual learning for semi-supervised medical image segmentation. In Proceedings of the Pattern Recognition and Computer Vision: 4th Chinese Conference, PRCV 2021, Beijing, China, 29 October–1 November 2021; pp. 548–559. [Google Scholar]
- Yang, X.; He, X.; Zhao, J.; Zhang, Y.; Zhang, S.; Xie, P. COVID-CT-dataset: A CT scan dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Fan, D.P.; Zhou, T.; Ji, G.P.; Zhou, Y.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images. IEEE Trans. Med. Imaging 2020, 39, 2626–2637. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.-P.; Cheng, M.-M.; Liu, Y.; Li, T.; Borji, A. Structuremeasure: A new way to evaluate foreground maps. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.-P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.-M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Dice | Sen. | Spec. | MAE | ||
|---|---|---|---|---|---|---|---|
| COVID-SemiSeg Dataset | U-Net [25] | 0.574 | 0.561 | 0.949 | 0.706 | 0.744 | 0.105 |
| AttU-Net [26] | 0.582 | 0.508 | 0.961 | 0.684 | 0.762 | 0.096 | |
| Inf-Net [50] | 0.647 | 0.709 | 0.910 | 0.737 | 0.827 | 0.103 | |
| Trans-Inf-Net [19] | 0.695 | 0.721 | 0.939 | 0.778 | 0.854 | 0.083 | |
| transYLmtMT | 0.714 | 0.651 | 0.970 | 0.741 | 0.863 | 0.061 |
| Dataset | Method | Dice | Sen. | Spec. | MAE | ||
|---|---|---|---|---|---|---|---|
| COVID-HSSOrdinary | U-Net [25] | 0.279 | 0.338 | 0.754 | 0.607 | 0.665 | 0.019 |
| AttU-Net [26] | 0.254 | 0.308 | 0.738 | 0.586 | 0.670 | 0.018 | |
| Inf-Net [50] | 0.349 | 0.590 | 0.804 | 0.586 | 0.652 | 0.045 | |
| Trans-Inf-Net [19] | 0.570 | 0.737 | 0.973 | 0.678 | 0.699 | 0.026 | |
| transYLmtMT | 0.821 | 0.857 | 0.979 | 0.930 | 0.910 | 0.012 |
| Dataset | Method | Dice | Sen. | Spec. | MAE | ||
|---|---|---|---|---|---|---|---|
| COVID-HSSSerious | U-Net [25] | 0.287 | 0.349 | 0.784 | 0.612 | 0.668 | 0.019 |
| AttU-Net [26] | 0.266 | 0.321 | 0.755 | 0.593 | 0.668 | 0.019 | |
| Inf-Net [50] | 0.357 | 0.592 | 0.816 | 0.590 | 0.654 | 0.046 | |
| Trans-Inf-Net [19] | 0.578 | 0.742 | 0.973 | 0.686 | 0.706 | 0.026 | |
| transYLmtMT | 0.824 | 0.859 | 0.979 | 0.936 | 0.912 | 0.013 |
| Dataset | Method | Dice | Sen. | Spec. | MAE | ||
|---|---|---|---|---|---|---|---|
| COVID-HSSCritical | U-Net [25] | 0.284 | 0.363 | 0.762 | 0.613 | 0.662 | 0.019 |
| AttU-Net [26] | 0.231 | 0.301 | 0.732 | 0.583 | 0.651 | 0.018 | |
| Inf-Net [50] | 0.330 | 0.601 | 0.793 | 0.575 | 0.621 | 0.053 | |
| Trans-Inf-Net [19] | 0.561 | 0.734 | 0.971 | 0.670 | 0.692 | 0.028 | |
| transYLmtMT | 0.823 | 0.862 | 0.987 | 0.924 | 0.903 | 0.015 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Li, F.; Zhang, X.; Cheng, Y.; Hei, X. Multi-Task Mean Teacher Medical Image Segmentation Based on Swin Transformer. Appl. Sci. 2024, 14, 2986. https://doi.org/10.3390/app14072986
Zhang J, Li F, Zhang X, Cheng Y, Hei X. Multi-Task Mean Teacher Medical Image Segmentation Based on Swin Transformer. Applied Sciences. 2024; 14(7):2986. https://doi.org/10.3390/app14072986
Chicago/Turabian StyleZhang, Jie, Fan Li, Xin Zhang, Yue Cheng, and Xinhong Hei. 2024. "Multi-Task Mean Teacher Medical Image Segmentation Based on Swin Transformer" Applied Sciences 14, no. 7: 2986. https://doi.org/10.3390/app14072986