1. Introduction
Medical image segmentation using automated techniques is vital for many clinical tasks, including discovering new biomarkers, monitoring disease progression, and facilitating computer-assisted determination and treatment direction [
1], particularly in the labeling of lesions or infected areas during public health crises. The recent advances in deep neural network structures have led to major enhancements in the performance of medical image segmentation models. However, medical image segmentation tasks exhibit immense diversity, as different imaging modalities produce images with distinct characteristics and appearances while the presentation of diseases also varies considerably. This heterogeneity makes the direct application of even a successful architecture such as U-Net [
2], a convolutional network for biomedical image segmentation, to a new task unlikely to achieve optimal results. Since the manual annotation of infected areas is a laborious and time-consuming task, and radiologists’ annotations are highly subjective and prone to personal bias informed by past clinical encounters, it is an urgent requirement to explore automated and robust segmentation techniques for medical images [
3].
Segmenting organs and lesions in computed tomography (CT) slides provides critical clinical data for disease identification and quantification [
4]. Recently, many algorithms using feature extraction and classification techniques have been developed for lung nodule segmentation, achieving promising performance. Nevertheless, visual similarities between nodules and the background make isolating them challenging. To address these challenges, researchers have developed deep learning approaches to learn more discriminative visual representations for segmentation [
5,
6,
7,
8,
9]. For instance, from heterogeneous CT slices, the authors of [
5] introduced a centrally focused convolutional neural network (CNN) to isolate lung nodules. Meanwhile, in generative adversarial networks, GAN-synthesized information is utilized to enhance the discriminative training model for lung pathology segmentation. A dual deep network that incorporates multiple residual streams at varying resolutions [
9] was designed to isolate lung tumors in CT images [
8]. In summary, deep learning shows promise for improving the segmentation of lung nodules and pathology markers in CT scans via learning robust features to overcome the difficulty of differentiating nodules from image backgrounds.
Artificial intelligence technologies have been widely applied to combat COVID-19 (coronavirus disease 2019), with many deep learning systems having been proposed for detecting infected patients through radiological imaging. However, labeled data are still limited. In this context, semi-supervised models can identify target regions from other anomalies given minimal labeling, making them well-suited for COVID-19 assessments. Additionally, transformer learning methods constitute another promising approach for situations with limited data [
10,
11]. Transformers excel at modeling global contexts and, with large-scale pre-training, demonstrate superior transfer learning ability on downstream tasks. This has been evidenced by their success in natural language processing (NLP) and machine translation tasks [
12,
13]. Recently, transformers have achieved or surpassed cutting-edge performance on various image recognition challenges [
6,
14]. In summary, semi-supervised learning and transformers are two effective artificial intelligence (AI) techniques which can address the lack of labeled medical imaging data, capitalizing on their abilities to learn from limited supervision and leverage pre-training. Their adoption could enable accurate screening from radiological images despite data constraints.
Detecting infected regions and affected areas in medical images remains challenging due to the variance in morphological characteristics like texture, size, and positioning across different medical image modalities. Additional difficulties arise from subtle visual differences between normal and infected tissues, as well as low-intensity contrast. Moreover, collecting extensive labeled infection data is arduous, as acquiring precise pixel-level annotations to train deep models is expensive and time-consuming [
15]. Infection detection in medical images is difficult due to infections’ heterogeneous appearances, their visual similarity to normal tissue, and the lack of abundant annotated data. Overcoming these obstacles is key to improving automated infection detection from medical images.
Here, we develop a novel medical segmentation network that establishes self-attention mechanisms for sequence-to-sequence prediction. In order to compensate for transformers’ need to sacrifice fine-grained feature resolution, we employ a hybrid CNN–Transformer structure. This combines the advantages of high-resolution spatial details from CNN representations with the overall context modeling capacities of transformers. Transformers are better at modeling long-range dependencies in images, more flexible at handling varying input sizes, and they provide greater model interpretability, offering a promising alternative to CNNs for medical image segmentation. We integrate transformers in medical segmentation, providing both locally precision segmentation and global contextual modeling for accurate analysis.
Inspired by parallel structure designs, the self-attentive features from transformers are up-sampled and combined with CNN features of high-resolution skipped from the encoding path. This fusion strategy enables the precise delineation of boundaries while preserving the transformers’ self-attention mechanism advantages for medical segmentation. Empirical experimental results suggest our transformer framework better leverages self-attention compared to existing self-attention CNN-based models. Simultaneously, incorporating more intensive low-level feature details generally improves segmentation accuracy. Extensive experiments across various medical image modalities demonstrate our method superiority over compared approaches. Our parallel integration of transformer global context modeling with CNN local detail extraction, coupled with multi-level feature fusion, allows transformers to significantly enhance the performance of medical image segmentation tasks. In summary, our framework seamlessly combines the strengths of transformers and CNNs, facilitating accurate and robust segmentation of medical images by effectively capturing both global and local contextual information.
In summary, our main contributions in this work are as follows:
We develop the attempt to investigate the integration of transformer architectures into general medical image segmentation tasks, demonstrating their applicability beyond NLP.
We introduce a novel transformer-based network tailored for infection segmentation, designed to mitigate the challenges posed by limited labeled data availability. Our system exhibits superior learning capabilities through random propagation and self-supervised pre-training on unlabeled data.
Our proposed framework achieves high-performance segmentation results in a self-supervision manner, highlighting the significant potential of pre-training transformers on large unlabeled medical image datasets to learn rich representations that can be effectively transferred to the segmentation task.
The remainder of this paper is organized as follows.
Section 2 provides a comprehensive review of related work, including existing segmentation methods and relevant techniques.
Section 3 details our conceptual framework and the methodologies employed in our automatic segmentation network.
Section 4 reports the extensive experimental results and provides in-depth analysis. Finally,
Section 5 concludes and discusses future research directions.
3. Method
Given an input image with spatial dimensions channels, our objective was to predict the corresponding label map through pixel-wise segmentation. The common approach trains a CNN, such as U-Net, to directly encode the input image into high-level feature representations and then decode these representations back to full spatial resolution.
In contrast to the current approaches, our framework incorporated self-attention mechanisms via transformer encoders. We first explain how transformers can directly encode features from decomposed image patches (
Section 3.1). Unlike CNN encoders, our transformer encoder incorporated self-attention to model global contexts and long-range dependencies in the image. This provides complementary information to aid medical image segmentation. Then, we elaborate on the overall framework.
Rather than completely replacing CNNs, we selectively applied transformers to leverage both local precision from convolutions and global reasoning from self-attention. This hybrid architecture balances strengths by dividing responsibilities—the transformer focuses solely on encoding semantics, while the CNN decodes for spatial acuity.
In summary, our key insight is to combine complementary components in a tailored encoder–decoder design for medical images. This moves beyond the existing methods by fusing advancements from both computer vision and NLP to best suit the problem domain of medical image segmentation.
3.1. Transformers Encoder
Following the vision transformer (ViT) [
45], we first tokenized the input image
by reshaping it into a sequence of flattened 2D patches,
, and every image patch was
size. The patches number
was as the input sequence length.
We employed a trainable linear projection layer to map these image patches
into a
D-dimensional latent space. To incorporate spatial information, we added positional embeddings to the patch embeddings before passing them through the projection layer:
Here, is the linear projection of patch embedding, and is the position embedding. The input image is divided into patches, which are then projected into an embedding space. Learned positional encodings are provided through learned embedding vectors. This tokenization and embedding process allows the transformer to model interactions between image patches for global context modeling. In other words, the image is divided into local patches and each patch is mapped to a vector space that retains spatial relationships. This tokenization presents the transformer with visual concepts and their arrangements, priming it to model semantic and positional interactions. The output patch embeddings summarized identity and layout to inform the downstream decoding.
The transformer encoder contains
identical layers, with each layer containing a multi-layer perceptron (MLP) block and a multi-head self-attention (MSA) block (Equations (2) and (3)). The MSA block first projects the embeddings into query, key, and value vectors. It then calculates attention based on the dot-product over all tokens using these projections. This models the global relationships in the image. The MLP then processes each token individually with non-linear transformations to encode semantic concepts. Layer normalization and residual connections are employed around each block. The
output can be obtained by:
Here, represents applying layer normalization, and is the transformer output encoding the image features after L layers. The stacked MSA and MLP blocks enable complex reasoning through multiple rounds of global self-attentive processing and local non-linear transformations.
Figure 1a illustrates the structure of the transformer layers. There are 12 transformer layers in the second convolutional block of the CNN encoder, and each transformer encoder contains multiple identical layers stacked on top of each other, with each layer containing two sublayers, a multi-head self-attention (MSA) layer and a multi-layer perceptron (MLP) layer. Since we mapped the vectorized patches into a latent
D-dimensional embedding space using a trainable linear projection, the number of hidden dimensions and attention heads can adjust based on the input image dimensions, reflecting the transformer’s capability to accommodate images of varying sizes—a crucial and practical feature in clinical settings. The self-attention mechanism models the global interactions between image patches, while the MLP provides non-linear transformations to encode semantic concepts. Stacking these layers allows modeling of the global context and long-range dependencies present in the input image.
3.2. Infection Segmentation Network
3.2.1. Framework Overview
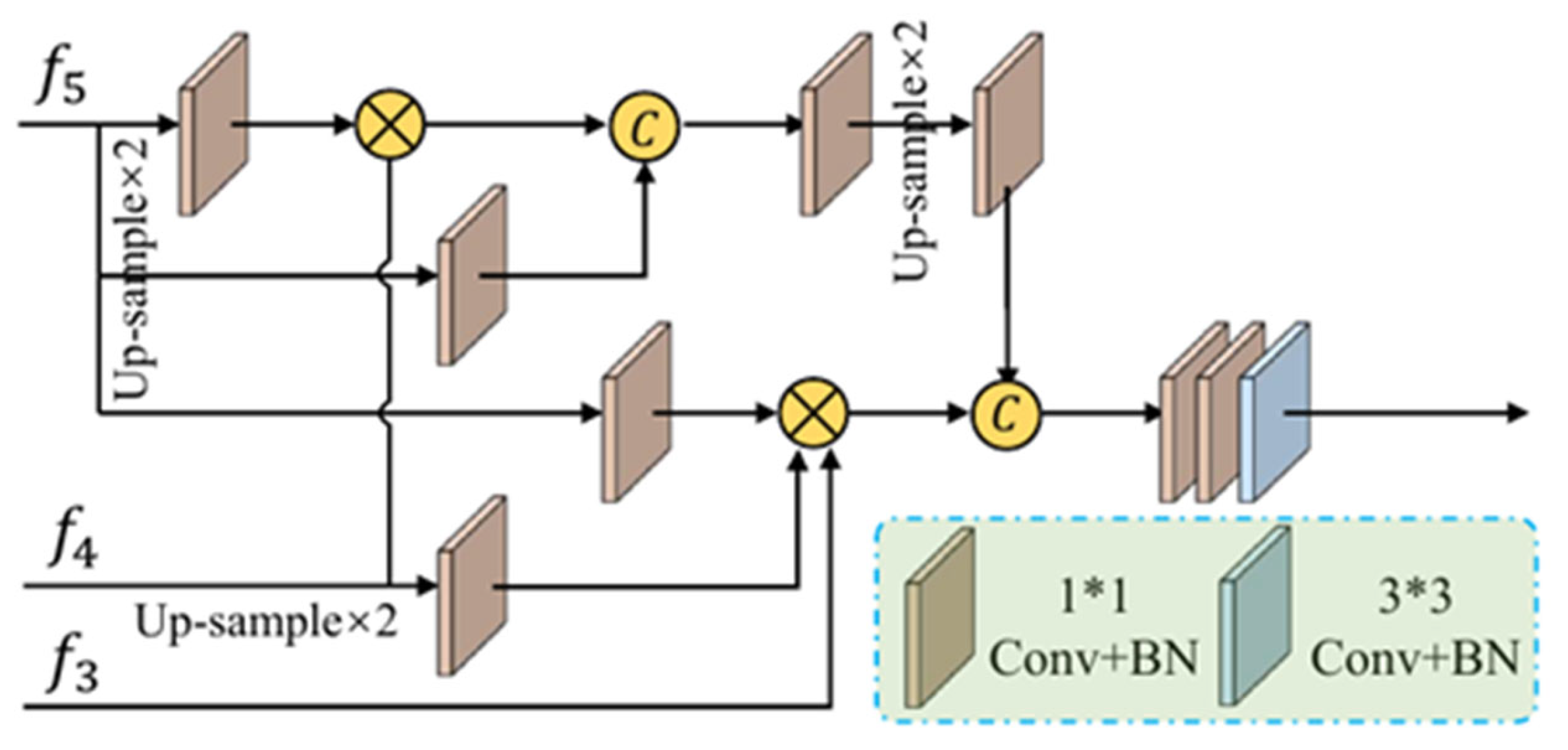
The overview of our framework’s architecture is shown in
Figure 1. Firstly, the input medical images are passed through two convolutional layers to obtain high-resolution feature representations with low-level semantic. An edge attention is then applied to explicitly enhance the representation of region boundaries.
The obtained low-level features are passed through three convolutional layers to extract high-level features . These high-level features serve two purposes. First, they are aggregated in parallel by a partial prediction decoder (PPD) to generate a coarse global infection localization map . Second, combined with are passed through a cascade of reverse attention (RA) modules guided by the localization map . Notably, each RA module guides the subsequent RA module in the cascade. Finally, the output of the last RA module passes through a sigmoid activation function to predict the infection regions.
Our network extracted multi-level features, utilized self-attention to model global context, and hierarchically refined localization via a cascaded decoder design for precise infection segmentation. The cascaded decoder mimics the workflow of radiologists, providing context and direction to focus the model on areas of interest. This hierarchical strategy tailors the model capacity to efficiently improve segmentation performance.
3.2.2. Edge Attention Module
As shown in prior work, edge information provides useful constraints to guide feature extraction for segmentation tasks [
46,
47,
48]. Since low-level feature representations (e.g.,
in our model) contain several edge features at a moderate resolution, we fed these low-level feature representations
to a newly introduced edge attention (EA) module. This module learns an explicit edge-aware feature representation. Meanwhile,
passes through a convolutional layer with a single filter to produce an edge map prediction.
The edge attention module improves medical image segmentation in the following way. It first identifies edges and boundaries between structures in the input image using gradient information. These detected edges provide vital cues for delineating infection regions from surrounding healthy tissue. The predicted edge maps are then used to refine the convolutional feature representations extracted from the image. By element-wise multiplying the edge maps with the convolutional filters, the features are enhanced at semantically meaningful edges, incorporating critical localization cues. The refined edge-aware features help guide the network’s attention to focus on the most relevant regions for accurate segmentation. The edge-guided spatial attention provides fine-grained localization signals to help distinguish infection areas from other tissues. In essence, the edge attention module incorporates explicit edge knowledge to enhance the convolutional features. By refining features and steering attention based on edges, the module enables the more precise delineation of infection regions, thus improving medical image segmentation performance. The edge-guided spatial attention is crucial for accurate localization of infection regions.
We subsequently assessed the disparity between the edge map prediction from the EA module and the ground-truth (GT) edge map
derived from the annotated segmentation tasks. This was performed by computing the binary cross entropy (BCE) loss function:
Here, (x, y) indexes the spatial coordinates within the predicted edge map and the ground-truth edge map . The ground-truth edge map is derived by computing the gradient of the annotated segmentation mask. The and h are the corresponding width and height of the edge maps, respectively. The binary cross-entropy loss compares the predicted and ground-truth edge maps at each pixel location, providing localized supervision for predicting salient boundaries. By explicitly guiding the model to focus on edges, it learns to delineate challenging vague transitions between infection regions and healthy tissues.
We exploited low-level edge information by passing the convolutional features through the edge attention module. By optimizing the edge map predictions against the ground-truth edge maps using the BCE loss, it guides the network to obtain edge-aware feature representations that are beneficial for the segmentation task. The BCE loss compares the predicted and ground-truth edge maps pixel-by-pixel, guiding the network to learn edge-aware features that can effectively capture and represent the boundary information present in the input image.
3.2.3. Parallel Partial Decoder
Many established medical segmentation frameworks utilize both high-level and low-level representations extracted by the encoder to segment organs/lesions [
2,
19,
49,
50,
51]. However, as pointed out in [
47], compared to high-level feature representations, low-level representations require substantially increased computational resources due to their larger spatial resolutions, while contributing minimally to performance improvements.
We introduced a parallel partial decoder (PPD), which is beneficial for medical image segmentation by allowing efficient multi-scale feature utilization, information fusion, and balancing precision with efficiency while being robust to scale variations. The parallel branches in the PPD allow for the concurrent decoding of features from multiple scales of the encoder. This incorporates both fine local details from early layers and high-level global context from later layers. The fusion of multi-scale information enables a more comprehensive understanding of image structures, improving segmentation accuracy. The decoder can selectively aggregate multi-scale features to balance precision and efficiency. To prioritize precision for small structures, fine-grained features are emphasized. For scenarios where efficiency is prioritized over some precision sacrifice, coarse-scale features are utilized instead. This configurability allows catering the trade-off to diverse segmentation scenarios with varying precision needs and resource constraints. In essence, the PPD facilitates the flexible utilization of multi-scale encoder representations. By fusing features from layers of varying granularity, it balances segmentation precision and efficiency in an application-specific manner. The configurability enables optimized trade-offs for different precision requirements and computational budgets.
This motivated a more efficient utilization of multi-scale encodings in our framework. Rather than naively fusing layers, we strategically applied low-level features to refine boundaries via our edge attention module. The high-level features focus solely on generating an initial coarse prediction to localize regions of interest, as shown in
Figure 2.
Our PPD aggregation and cascaded reverse attention streams then allow low-level cues to be exploited in a targeted manner. By deliberating directing model capacity based on scale utility, we balance precision and efficiency. Experiments validated that our structured approach prevents wasteful redundancy while improving contour accuracy. These optimizations help address deployment constraints concerning inference speed, memory footprint, and power consumption.
Specifically, given an input medical image, we extracted two low-level features
and three high-level features
using Res2Net convolutional blocks [
52]. We then aggregated the high-level feature maps through the PPD
[
53] to produce a coarse global localization map
.
3.2.4. Reverse Attention Module
Clinicians typically segment regions of infection in a two-step process—coarsely localizing regions of infection, and then accurately annotating local tissue structures. We mirrored this workflow with two components. First, the PPD acts as a coarse locator, generating a global localization map
indicating the rough locations of an infection region without structural details. Next, a progressive reverse attention (RA) framework acts as the refined labeler to discriminatively delineate infections by removing estimated regions from high-level feature representations [
53,
54]. Rather than simply aggregating all levels [
54], we dynamically acquired reverse attention across three parallel high-level feature maps. This progressively exploited complementary regions and details from the deeper layers. This was achieved by eliminating elements of the current estimations from the up-sampled high-level features.
The resulting RA features
are obtained through fusing high-level feature maps
and edge-aware features
from the edge attention module using the reverse attention weights
:
where
is the down-sampling operation;
is the concatenation operation. Our network mimics the clinician workflow with coarse localization followed by fine labeling of structural details. The global guidance provided by the localization map and the progressive reverse attention mechanism allow the module to selectively zoom in on informative regions.
The RA weight
is crucial for salient object detection [
46], with the definition as:
where
is the up-sampling operation;
represents the sigmoid activation function; and
denotes the reversed subtraction operation between the input and a matrix with each element as 1. The reversed subtraction
subtracts the localization map from a matrix of ones to reverse the activation in Equation (5).
Figure 3 shows the details of this procedure.
This reverse attention mechanism essentially reverses the background to foreground patterns learned by the CNN, helping to disentangle infection regions from normal tissue. The weights then filter out irrelevant regions while passing through discriminative cues that are progressively refined across stages. Together with the edge guidance from the edge attention module, this multi-level erasing and fusion process elegantly captures subtle characteristics that are difficult for standalone networks to model, moving towards an expert-level understanding.
Importantly, the erasing strategy, which is guided by the RA module, progressively refines the initial coarse prediction map into a more accurate final segmentation prediction. The reverse attention weights are learned to erase the prior coarse estimations and focus on complementary infection details. By iteratively refining the localization in this manner, the initial coarse prediction is transformed into a precise final segmentation map.
The reverse attention module progressively refines coarse segmentation predictions in a hierarchical manner to enhance accuracy and capture finer details. It disentangles infection regions from normal tissues by using attention mechanisms to selectively focus on amplifying features of infection regions while suppressing irrelevant features of normal tissues. This highlights infection boundaries and contrasts between infected and healthy areas.
The module employs an iterative erasing strategy that gradually removes less relevant features from the coarse predictions to emphasize salient infection-related features. This erasing strategy aligns with the intuition of selective attention, where the network iteratively attends to and refines the most infection-relevant features while filtering out distracting or less informative features.
Through this progressive selective attention and erosion of non-essential features, the reverse attention module disentangles infections from complex surroundings and refines the segmentation map for improved accuracy and localization.
3.2.5. Loss Function
We employed a weighted intersection over union (IoU) loss and a symmetric binary cross-entropy (BCE) loss for supervision during training. The weighted IoU loss allows higher importance to be assigned to certain classes or regions, helping the model prioritize clinically significant areas and improving segmentation accuracy in critical regions. It addresses class imbalance and differences in contextual importance. The asymmetric BCE loss allows customization based on clinical implications. It mitigates class imbalance issues and makes the model more robust to misclassifications. The weighted IoU guides the focus on salient areas, while the asymmetric BCE improves robustness. This makes the model more effective at delineating anomalies from normal tissues.
Together, these losses align the model with clinical objectives by emphasizing critical regions, balancing class importance, and penalizing asymmetric errors tailored to medical imaging challenges. By combining losses tailored for medical images, the model becomes better equipped to handle complexities like class imbalance while improving performance in clinically valuable regions.
As Equation (4) mentioned, we take the edge loss function
for supervision. The full loss function
comprises a weighted intersection over union loss(IoU)
, combined with a weighted BCE loss
for segmentation supervision,
The proposed loss function consists of a weighted IoU and an asymmetric BCE loss. The global and local losses provide effective supervision at the image and pixel levels, respectively, for more accurate segmentation. Different from the standard IoU loss, the weighted IoU loss emphasizes hard pixels to highlight their importance, while the asymmetric BCE assigns greater weight to challenging mislabeled hard pixels, instead of treating all pixels equally. The formulation of these losses draws from successful applications in other domains like salient object detection [
55,
56]. Correntropy-induced losses [
57,
58] could also be explored here for improved robustness.
Additionally, we adopt the global map
as well as three side-outputs (i.e.,
,
, and
) with deep supervision by comparing their up-sampled versions (
) to the ground truth segmentation mask during training. This provides direct optimization guidance at multiple encoder stages. The total loss is:
where Gs is the labeled mask, and Ledge denotes cross-entropy loss for edge prediction. This benefits gradient flow across features and prevents overfitting.
4. Experiments and Discussions
In our experiments, standard augmentations like random rotation and flipping are applied. We utilized a 12 layer Vision Transformer (ViT) [
45] architecture for the pure transformer encoder model, with an input resolution of 8 × 8 and a patch size of 16, unless specified. Four 2× up-sampling was used in the cascaded up-sampler (CUP) for full resolution. The models were trained for 20k iterations using the Adam optimizer with a learning rate of 0.0001 and a batch size of 6. The training was performed on an Nvidia RTX2080Ti GPU (Graphics Processing Unit, TechPowerUp, Yorkshire, NY, USA).
We demonstrated our framework on different medical image datasets in distinct modalities, CT and skin image dataset. The CT segmentation dataset contains 100 axial CT scans from COVID patients, with radiologist segmentations of lung infections, and the HAM10000 dataset [
59], Human Against Machine, contains 10,000 training images, a large collection of dermatoscopic images from multi-sources showing common pigmented skin lesions, including the ISIC (International Skin Imaging Collaboration) 2016 and 2018 skin lesion datasets. The COVID CT dataset contains 349 CT scans from 216 patient cases, with extracted metadata like age, gender, location, medical history, scan time, COVID severity, and radiology reports. It has more COVID positive cases than other datasets, providing greater image diversity.
The HAM10000 dataset includes ISIC 2016 (900 images) and ISIC 2018 (1000 images) of dermatoscopic images from different populations and modalities, covering important diagnostic categories of pigmented skin lesions.
The datasets were split into training (70%), validation (20%), and testing (10%) sets in a 7:2:1 ratio. All images were resized to 512 × 512 pixels.
The combined datasets include CT scans across age groups, as well as chest and eye images, reflecting a rigorous and diverse collection for model training and evaluation. Utilizing these diverse data spanning COVID CT, dermatology cases, and varied anatomies/modalities aimed to develop robust, generalizable segmentation models for clinical use.
These datasets contain expert annotations and clinical severity ratings, using standard training schemes and hardware. This benchmarks performance on realistic data.
4.1. Experimental Setting
Thorough validation is essential for developing trust in automatic segmentation models prior to clinical use. Comprehensive validation provides confidence that these models can generalize to new data while maintaining reliable performance across diverse clinical scenarios. Key validation techniques include quantitative metrics to evaluate segmentation accuracy, qualitative visual analysis for assessing clinical utility, comparisons against baseline methods, and incorporation of feedback from clinicians. Ultimately, rigorous multifaceted validation combining metrics, visual analysis, comparisons, and clinician input enables a holistic understanding of model capabilities, limitations, and clinical relevance.
4.1.1. Baselines
For the experiments on infection region segmentation, the proposed network is compared with traditional medical segmentation models such as U-Net [
2], Attention U-Net [
36], and Inf-Net [
60]. This benchmarks the proposed method against widely used medical segmentation architectures, including a standard U-Net baseline and prior attention-based models.
4.1.2. Evaluation Metrics
According to [
61], we utilized several common evaluation metrics: the Dice Similarity Coefficient, specificity, and precision. We also included three object detection metrics, structure measure [
62], mean absolute error, and enhanced-alignment measure [
63].
These metrics compare the prediction map with Sigmoid activation to the ground-truth G of object-level annotations. The metrics measure similarity/dissimilarity between the ground truth and predicted segmentation. We quantified segmentation performance using popular medical metrics along with additional detection-based metrics. These evaluate alignment, error, and topological similarity between predictions and ground truth annotations.
4.2. CT Segmentation Dataset Results
In this experiment, we compiled a CT infection segmentation dataset, leveraging unlabeled images to augment the limited labeled training data. Our labeled data
come from the CT segmentation dataset [
13], which has 45 CT images randomly chosen for training, 5 for validation, and 50 for testing.
The infection segmentation results in
Figure 4 show that our network markedly outperforms the baseline algorithms. Specifically, it yields segmentation maps that closely match the ground truth with significantly fewer incorrectly segmented tissue regions. Additionally, U-Net results in inadequate segmentation with many mis-segmented areas. Our success is attributable to a strategy of coarse-to-fine segmenting. First, a parallel partial decoder localizes infection regions roughly, then the segmentation is refined by multiple edge attention modules. This mimics radiologists’ workflow of segmenting infections from CT images, and consequently achieves a promising performance. Furthermore,
Figure 4 confirms the superiority of our semi-supervised approach over baselines. Our model produces segmentation with more accurate boundaries, while baselines result in relatively fuzzy boundaries, particularly in regions of subtle infection. The additional unlabeled data and multi-scale edge attention allow our model to capture fine-grained infection patterns and boundaries.
As shown in
Table 1, our proposed model has specificity 0.01 higher than U-Net and 0.03 than Attention U-Net. It also has a lower MAE than the baselines. This improvement is likely due to our model’s implicit mechanism of reverse attention and unambiguous models of edge attention modules providing strong feature extraction abilities.
Overall, our model outperforms the baselines on most metrics. The additional unlabeled data and refined attention mechanisms allow our model to better distinguish infection regions.
4.3. Skin Lesions Dataset Results
To validate the effectiveness of the algorithm across different medical image modalities, we utilized the ISIC2016 and ISIC2018 skin lesion image datasets. The 2016 dataset contained 900 images, which we divided into 600 for training, 200 for testing, and 100 for validation. The 2018 dataset had 5000 images, which we split into 3500 training images, 1000 testing images, and 500 validation images.
As shown in
Figure 5 and
Figure 6, our network demonstrates superior lesion segmentation compared to the baseline algorithm. The segmentation maps from our network align closely with the ground truth data and contain significantly fewer erroneous segmented regions than the baselines. In contrast, U-Net and Attention U-Net yield very unsatisfactory segmentation results on this task. While Inf-Net delivers a comparable performance to our network, our approach still produces slightly better delineation of edge details in the infection regions. Overall, these results highlight the effectiveness of our network for accurate lesion segmentation in the ISIC2016 dataset.
The results in
Table 2 and
Table 3 demonstrate that our proposed model achieves the best performance across all evaluation metrics compared to the baseline algorithms. Our model also outperforms Inf-Net on multiple indicators, which can be attributed to the addition of the transformer module in our architecture.
In summary, our model consistently surpasses the baseline algorithms on most metrics for all the datasets. The use of additional unlabeled data and refined attention mechanisms enables our model to more accurately identify infection regions. The quantitative results validate the superior infection segmentation capability of our proposed model across different imaging modalities.
4.4. Ablation Study
In this section, we employ several experiments to confirm the performance of every key element of our framework, including the PPD, RA, EA, and TRANS modules; in
Table 4, we set Backbone as Bb. The experiments validated the effectiveness of the PPD and other core components of the proposed model and
Table 4 shows the results.
Effectiveness of PPD. To determine the contribution of the PPD, we compared backbone only No. 1 and backbone+ PPD (No. 3) in
Table 4. The PPD clearly improves performance, demonstrating its necessity.
Effectiveness of RA. Comparing backbone only (No. 1) and backbone + RA (No. 4) shows RA boosts metrics like Dice, sensitivity, and MAE. This indicates RA helps accurately distinguish infected regions.
Effectiveness of PPD and RA. No. 6 combines PPD and RA. As
Table 4 shows, No. 6 outperforms other settings on most metrics. This shows PPD and RA are central components underlying our strong performance.
Effectiveness of EA. Adding EA (No. 2 vs. No. 1, No. 5 vs. No. 4, No. 7 vs. No. 6) consistently improves segmentation, demonstrating its contribution.
Effectiveness of TRANS. Finally, adding the TRANS module (No. 8 vs. No. 7) boosts our model across indicators, validating its role in improving segmentation.
In summary, our ablation studies demonstrate the necessity and complementary value of the PPD, RA, EA, and TRANS components proposed. Together, they enable our model’s cutting-edge infection segmentation performance.
4.5. Time Costs
We validated the effectiveness of our experiments using an Nvidia GTX 2080Ti GPU and an Intel Xeon Silver 4210 CPU (Intel, Santa Clara, CA, USA). Due to setting the size of all three datasets to 512 × 512, the average training and testing time of different models and segmentation methods on the three datasets remained basically consistent, as shown in
Table 5. The time is reported in seconds per image.
Although our method does not match the computational efficiency of Inf-Net for training and testing times, we achieved a better image segmentation performance at the cost of increased computation time. This trade-off between accuracy and speed is acceptable and expected, as our approach prioritizes segmentation quality over pure efficiency on the hardware used. The validation results demonstrate the effectiveness of our method, albeit with some sacrifice in speed compared to highly optimized networks like Inf-Net.
4.6. Potential Limitations
Image quality variability can impact the performance of segmentation models. Models trained on high-quality data, especially in the selected public dataset in our work may not generalize to real-world clinical images of varying quality.
Biases in the training data arising from limited or labeling errors can propagate biases in model predictions, leading to disparities across patient populations. Careful curation for representativeness and techniques like augmentation and adversarial training can help mitigate such biases.
Models trained on data from specific clinical settings may not generalize well to new clinical settings with different data distributions. Domain adaptation and transfer learning approaches can potentially improve generalization across domains.
In summary, key limitations around image variability, data bias, and generalization across clinical settings need to be addressed through robust algorithms, careful data curation to ensure representativeness, evaluation on diverse data, and techniques like augmentation, adversarial training, and transfer learning. Addressing these challenges will enable the reliable deployment of automatic segmentation models in clinical practice.
5. Conclusions
Transformers are structured with inherent powerful self-attention mechanisms that enable them to model long-range dependencies effectively. This work investigates the application of transformers for general medical image segmentation tasks. To fully utilize the capabilities of transformers, we encoded robust global context by training image features as sequences. Additionally, we incorporated low-level CNN features through a hybrid design. Our approach provides an alternative to the prevailing FCN-based methods for segmentation tasks across different medical image modalities. Our transformer-based model outperforms various popular segmentation methods, demonstrating that transformers can move beyond their success in NLP to effectively capture visual relationships in medical images. The promising results highlight the potential of transformers in medical imaging applications. Rather than relying on the local self-attention mechanisms in CNNs, pure transformer encoders can better model global dependencies, which is advantageous for medical image segmentation. Overall, our model advances the field of medical image segmentation by demonstrating the applicability and advantages of transformers for encoding domain knowledge in this task.
The key future directions involve developing unified AI-based system for integrated diagnosis, interactive segmentation to enable human–AI collaboration, multimodal fusion for leveraging complementary information from different imaging modalities, multi-task learning for joint optimization of multiple clinical tasks, clinical decision support systems, and the seamless integration of these AI solutions into clinical workflows and mobile health applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}