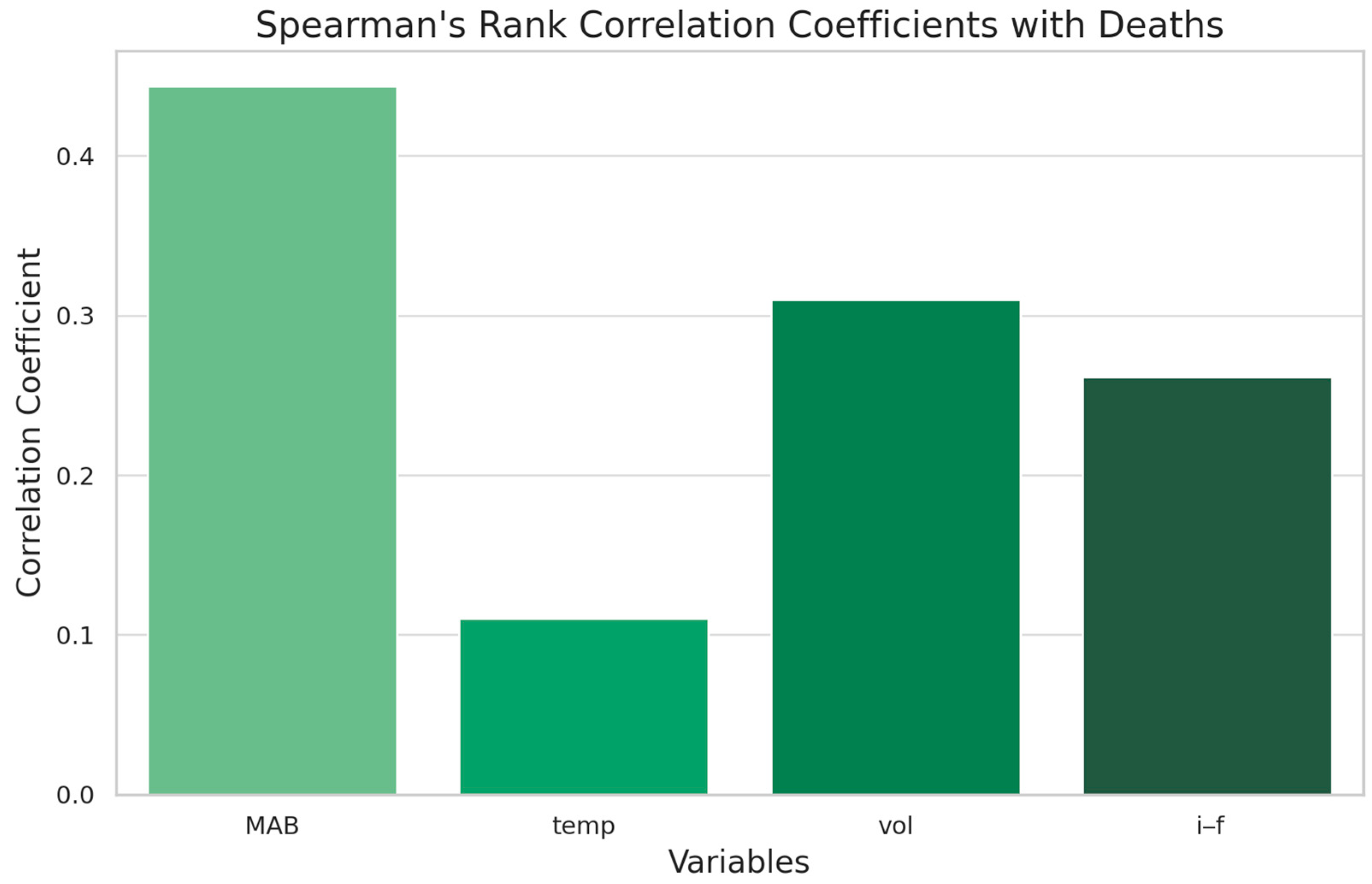
The results present the correlations between various factors and fish mortality. The author discusses the strength and direction of the correlations, highlighting potential relationships between factors like the median atomic weight of the fish, the volume of the cell occupying the fish, the fish concentration inside the cell, and the water temperature. The text also mentions the correlation’s significance or lack thereof in the binned data.
4.3. Decision Tree Mortality Classification
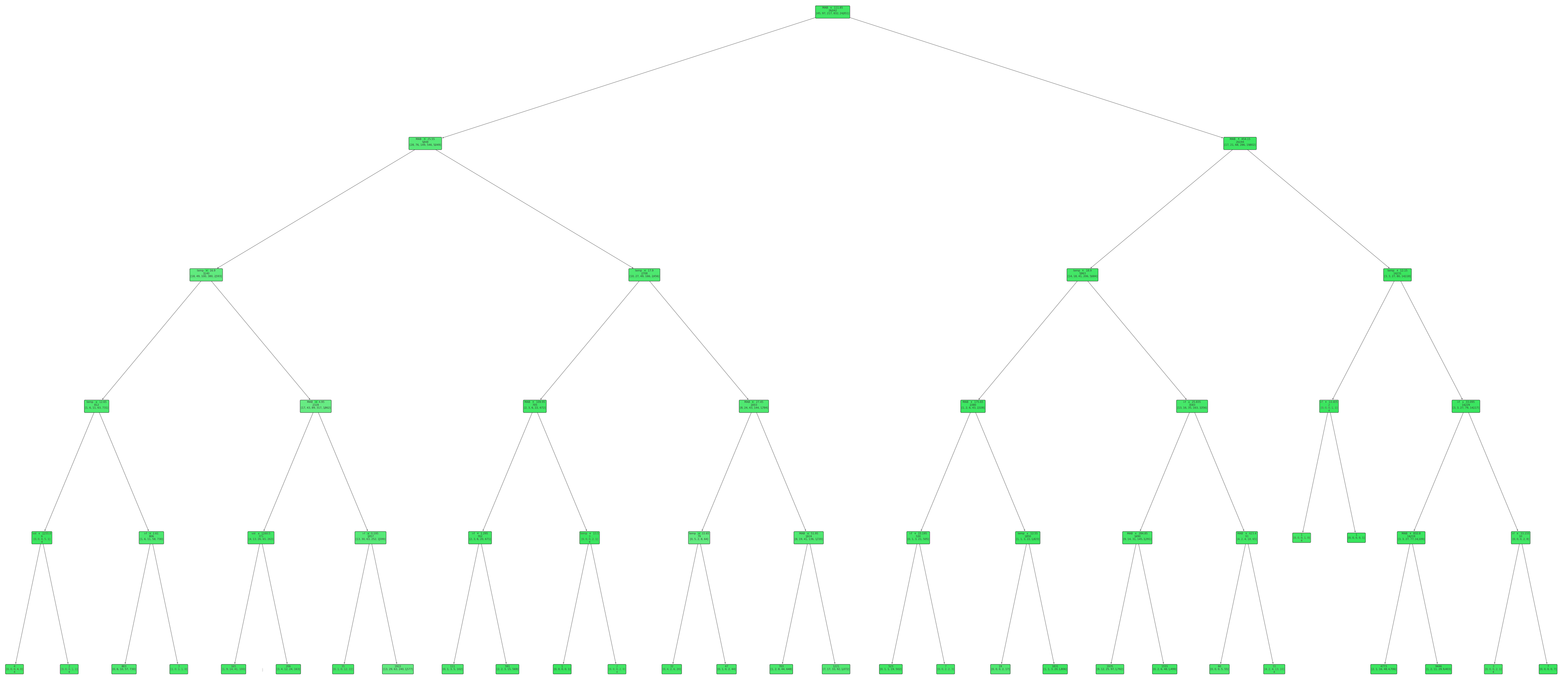
Figure 2 indicates the initial non-pruned decision tree visualization for fish mortality prediction. Focusing on the DT graph and its implications for classifying outcomes based on various variables, it is imperative to prune the decision tree using pruning techniques in order to avoid overfitting occurring. The bigger the decision tree becomes, the bigger the noise that is generated among the nodes, and the overfitting increases as well. High values of overfitting result in a lower classification accuracy for the classification process. A low classification accuracy leads to insufficient classification (
Figure 2) [
28,
29].
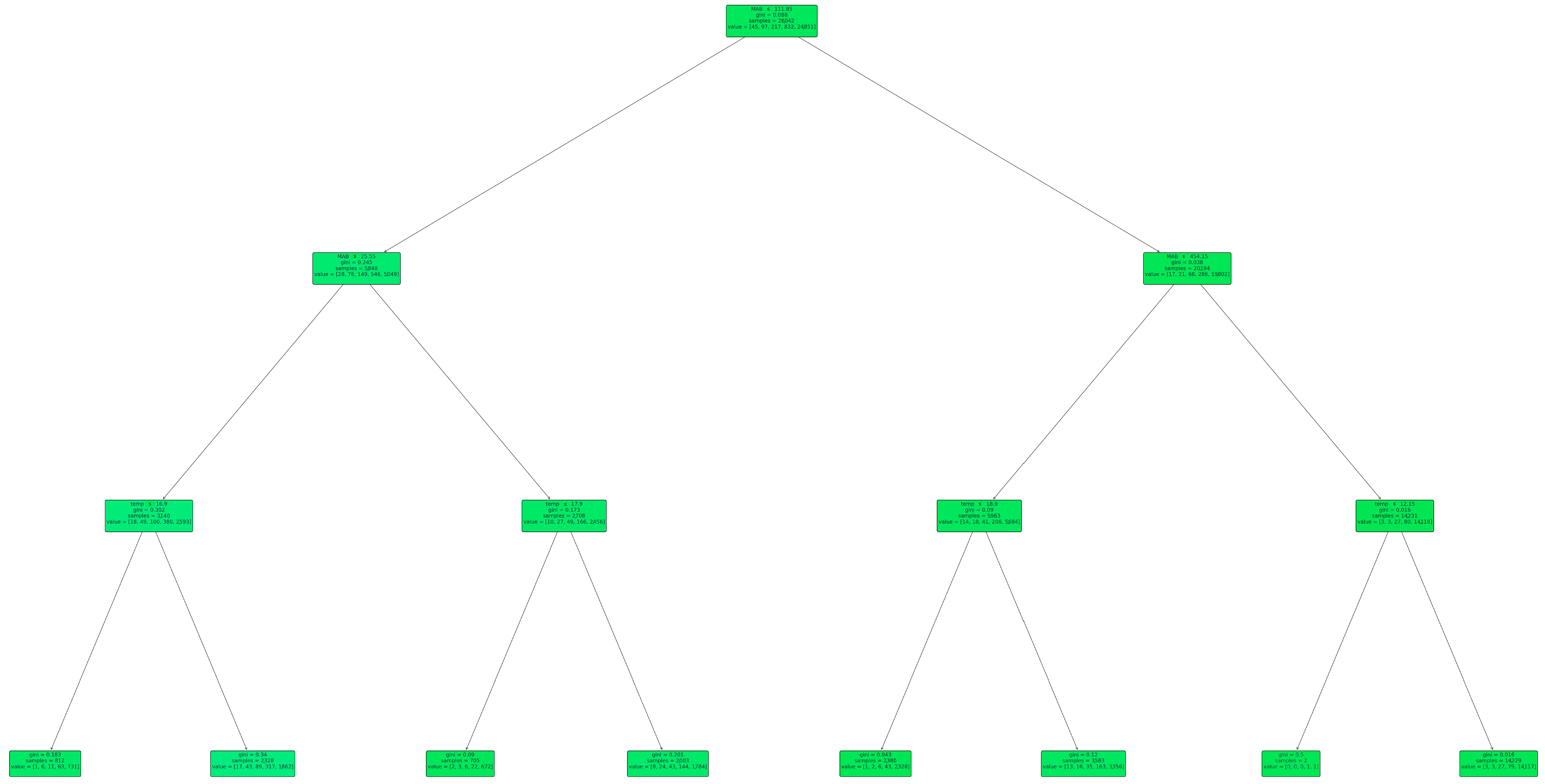
Figure 3 indicates the final pruned decision tree visualization for fish mortality prediction. The entire process also covers the training process of the DT classifier, including the preprocessing steps, pruning, and model evaluation using a 10-fold cross-validation. In DTs, each subsequent split aims to increase the homogeneity of the node with respect to the target variable, which, in this context, is likely related to the classes of fish mortality. The Gini impurity is a metric that quantifies the purity of a node, with a lower value indicating a higher purity. The “value” arrays give insight into the composition of the classes at each node, showing how many samples fall into each class. The class with the majority within each “value” array dictates the predicted class for that node or the further splitting rule if the node is not a terminal leaf node (
Figure 3) [
28,
29].
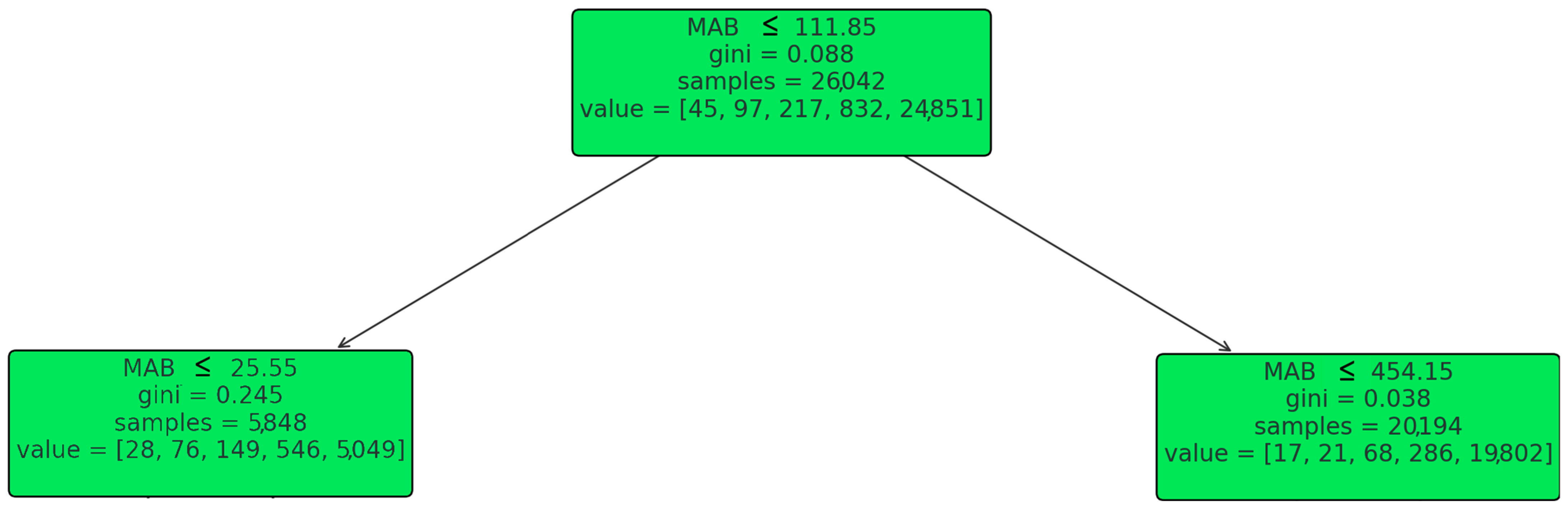
Figure 4 represents the root node of the decision tree while splitting, based on the feature “MAB” at a threshold of 111.85. The Gini impurity at this node is 0.088, suggesting a reasonable level of purity among the samples with respect to the target variable. The node is responsible for a significant number of samples, specifically 26,042, and these samples are distributed across various classes as indicated by the “value” array [45, 97, 217, 832, 24,851]. This distribution suggests that the majority of the samples at this node fall into the last class represented in the “value” array. From this root node, the decision tree further branches into two child nodes: The left child node is the result of the condition MAB ≤ 111.85. At this node, the Gini impurity is slightly higher than the root node, which is 0.245, indicating that the samples are less pure with respect to the target variable compared to the root node. The samples are divided among the classes as [28, 76, 149, 546, 5049]. This node will further branch out based on additional conditions. The right child node follows from the condition MAB > 111.85 and splits again at MAB ≤ 454.15. This node has a very low Gini impurity of 0.038, suggesting that the samples at this node are quite homogeneous. There are 20,194 samples at this node, distributed as [17, 21, 68, 286, 19,802] across the classes. The predominance of samples in the last class indicates a strong majority class presence at this node (
Figure 4).
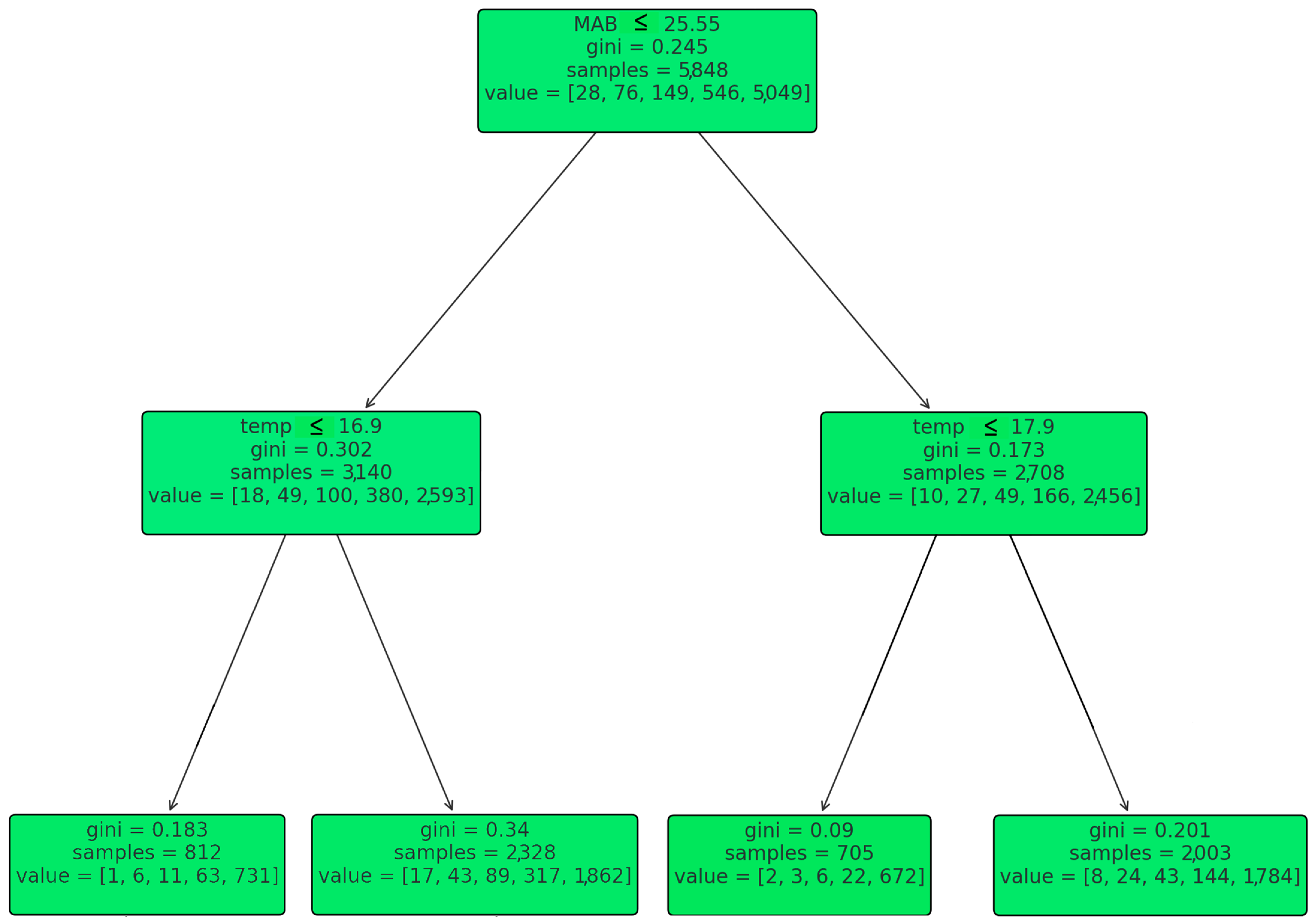
Figure 5 represents the root node while splitting on the feature “MAB”, with a threshold of 25.55. This indicates that the first decision in the tree to separate the data involves checking if the “MAB” value is less than or equal to 25.55. The Gini impurity for this node is 0.245, and it contains samples that fall into various classes, as indicated by the “value” array. The left child node of the root is further split based on the feature “Temp”, with a threshold of 16.9. The Gini impurity of this node is 0.302, and it also contains a mix of classes. The right child node of the root also splits based on the “Temp”, but with a threshold of 17.9. Its Gini impurity is 0.173. Each of the nodes following the “Temp” splits further into more nodes, which are not fully visible in the provided snippet. These subsequent nodes will have additional thresholds and possibly other features that they split on, further segmenting the data into the most homogeneous groups possible with respect to the target variable (likely the classes of fish mortality). Each of these rules would further branch out based on additional conditions until a final leaf node is reached, which would provide the predicted class. The predicted class at each leaf node would typically be the class that has the majority within that node, indicated by the ‘value’ array. The ‘value’ array, such as [18, 49, 100, 380, 2593], represents the distribution of samples across different classes at that node. The Gini impurity is a measure of the node’s purity; a smaller Gini index indicates a greater purity (
Figure 5).
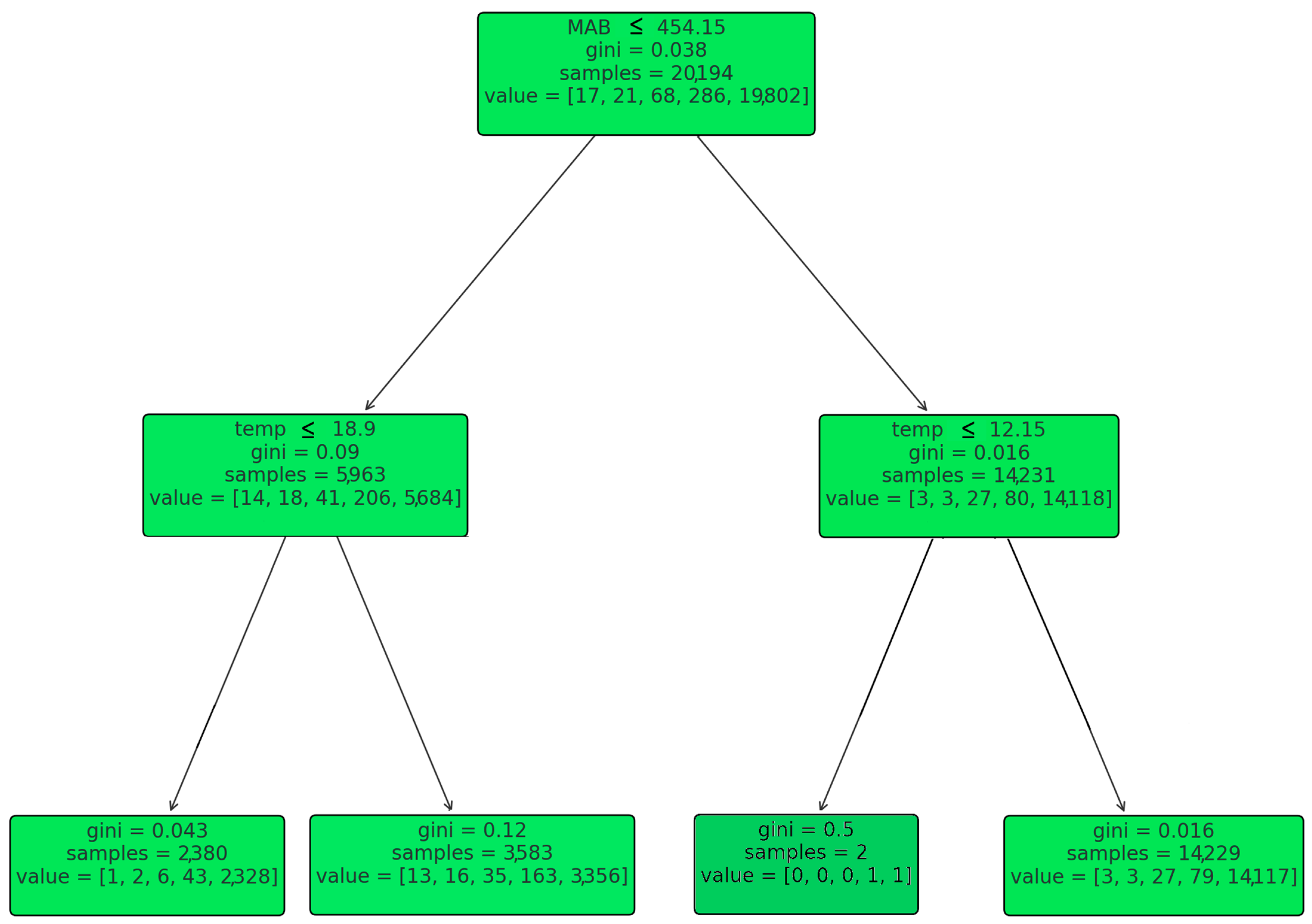
Figure 6 represents the root node while splitting the decision tree’s right child node based on the feature “MAB” at a threshold of 454.15. The Gini impurity at this node is remarkably low, at 0.038, indicating that the samples are quite pure with respect to the target variable, and there is a strong majority class present. There are 20,194 samples at this node, which are distributed across various classes as indicated by the “value” array [17, 21, 68, 286, 19,802]. From this node, the decision tree branches into two paths: On the left, if “Temp” is less than or equal to 18.9, the Gini impurity increases slightly to 0.09, and the number of samples at this node is 5963. The samples are distributed as [14, 18, 41, 206, 5684] across the classes. This path indicates that temperature plays a significant role in classifying samples when “MAB” is less than or equal to 454.15. On the right, if “Temp” is greater than 18.9 and less than or equal to 12.15, the Gini impurity is very low at 0.016, with 14,231 samples. The “value” array is [3, 3, 27, 80, 14,118], suggesting a strong class presence. This suggests that lower temperatures are associated with a particular class when the “MAB” is greater than 454.15 (
Figure 6).
Focusing on the DT structure and its implications for classifying outcomes based on various variables, the authors discuss specific thresholds for features like “MAB”, “Temp”, “Vol”, and “i–f”, detailing how these thresholds lead to different branches and classifications. The entire process also covers the training process of the DT classifier, including preprocessing steps, pruning, and model evaluations using a 10-fold cross-validation (
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6). Derived from the illustrated DT structure, when the “MAB” is less than or equal to 111.85, it results in diverse branches, predominantly leading to classes 3 and 4. Conversely, when the “MAB” exceeds 111.85, most outcomes are categorized as class 4, occasionally extending to class 3. The “Temp” emerges as a pivotal factor, introducing various thresholds such as 16.90, 12.65, 17.90, and 18.90, contributing to distinct branches and classifications. For example, when the “MAB” is less than 25.55 and the “Temp” is less than 16.90, additional temperature limits further categorize the results into classes number 3 and 4. The “Vol” thresholds, including 2155.00 and 1160.50, are featured in the tree representation, helping with the result classification when paired with the variables “MAB” and “Temp”. The “i–f” within the cage also shapes the results, with thresholds of 2.61, 0.20, and 1.29. In collaboration with the variables “MAB” and “Temp,” the “i–f” factor serves to more accurately categorize examples into unique classes (
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6) [
29,
30].
The DT classifier underwent training on a preprocessed dataset, involving different phases including excluding missing values and the discretization of “Deaths” variable values into five equal-width bins. To prevent overfitting, the model underwent pruning using a maximum depth value for a decision tree representation of 5, and its performance was evaluated through 10-fold cross-validation.
The results indicate a robust accuracy through a series of training, validation, and testing sets, achieving classification accuracies of 95.47% for the training set, 95.43% for the validation set, and 96.26% for the testing set. The visualization of the pruned DT offers insights into the model’s decision-making process for classifying data based on the provided features (
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6) (
Table 9) [
28,
29,
30,
31].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}