
Semantic Segmentation of 3D Point Clouds in Outdoor Environments Based on Local Dual-Enhancement

Abstract
:1. Introduction
2. Related Work
3. Semantic Segmentation of 3D Point Clouds
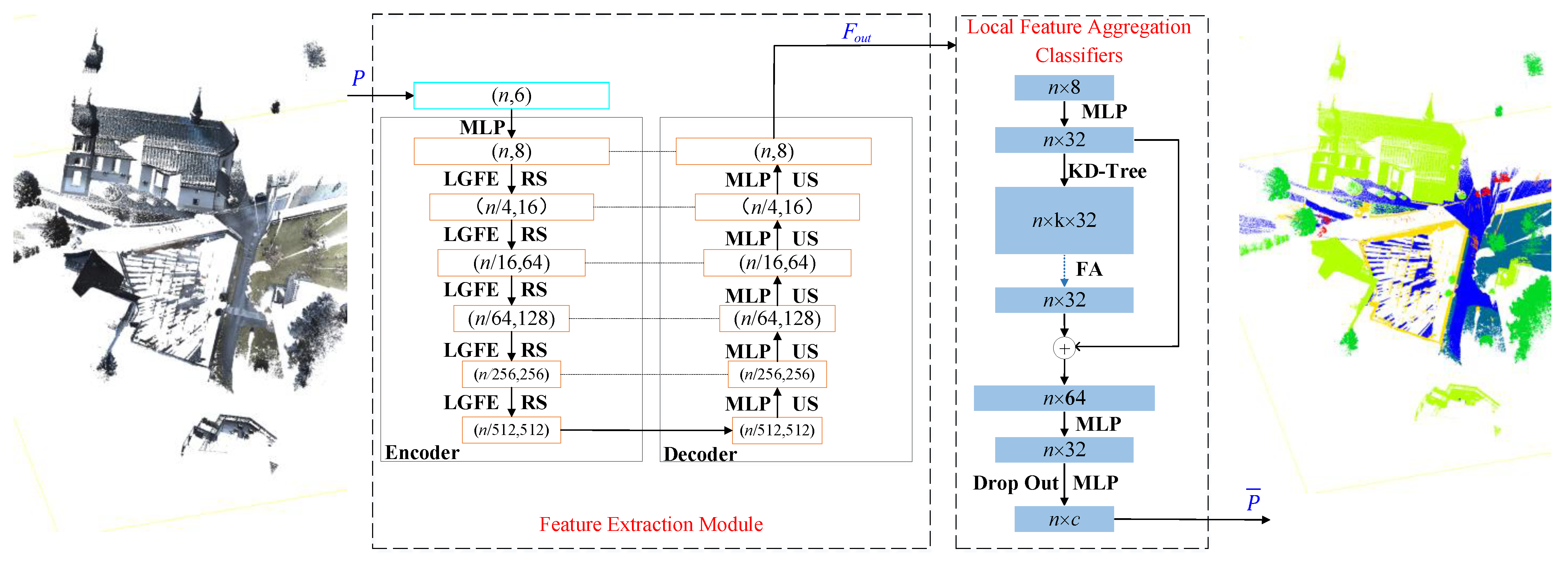
3.1. Framework of the LDE-Net
3.2. Feature Extraction Network
3.2.1. Encoder-Decoder Module
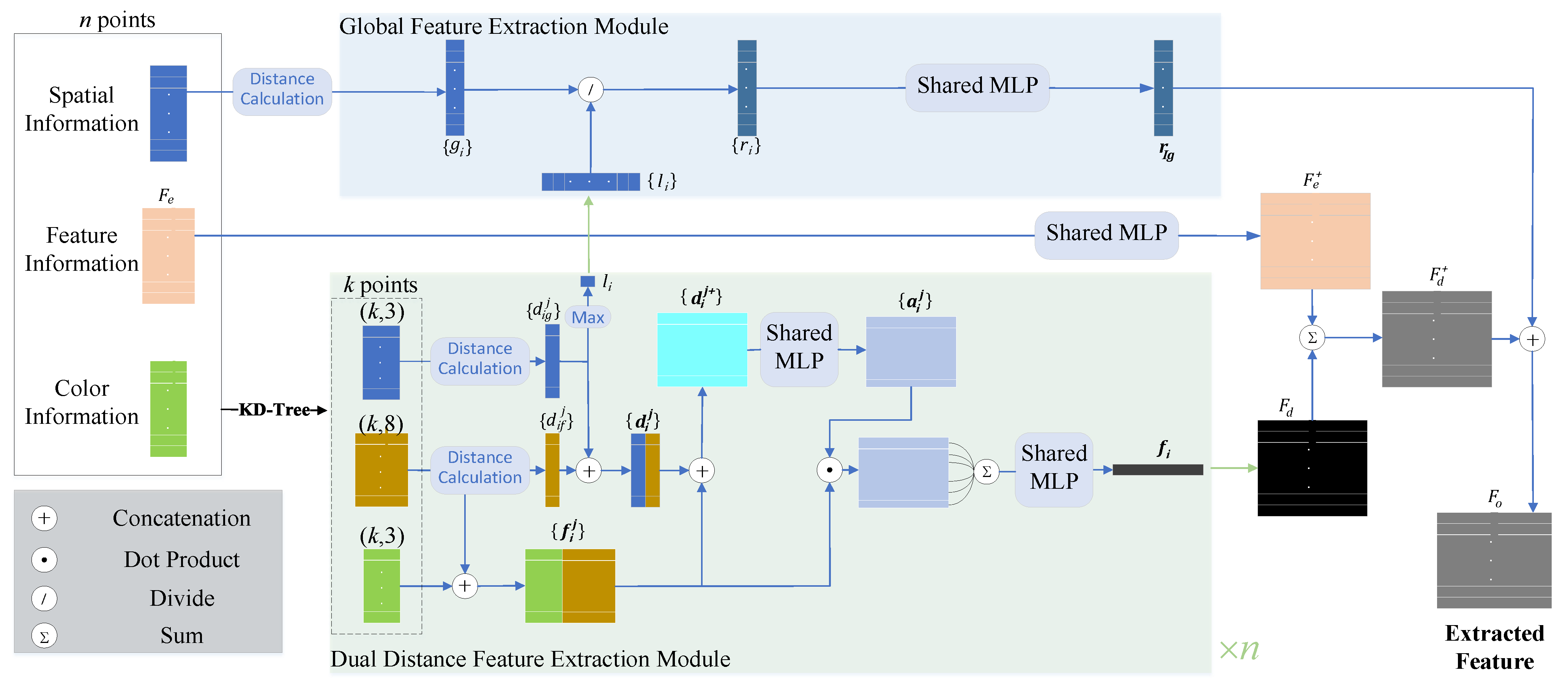
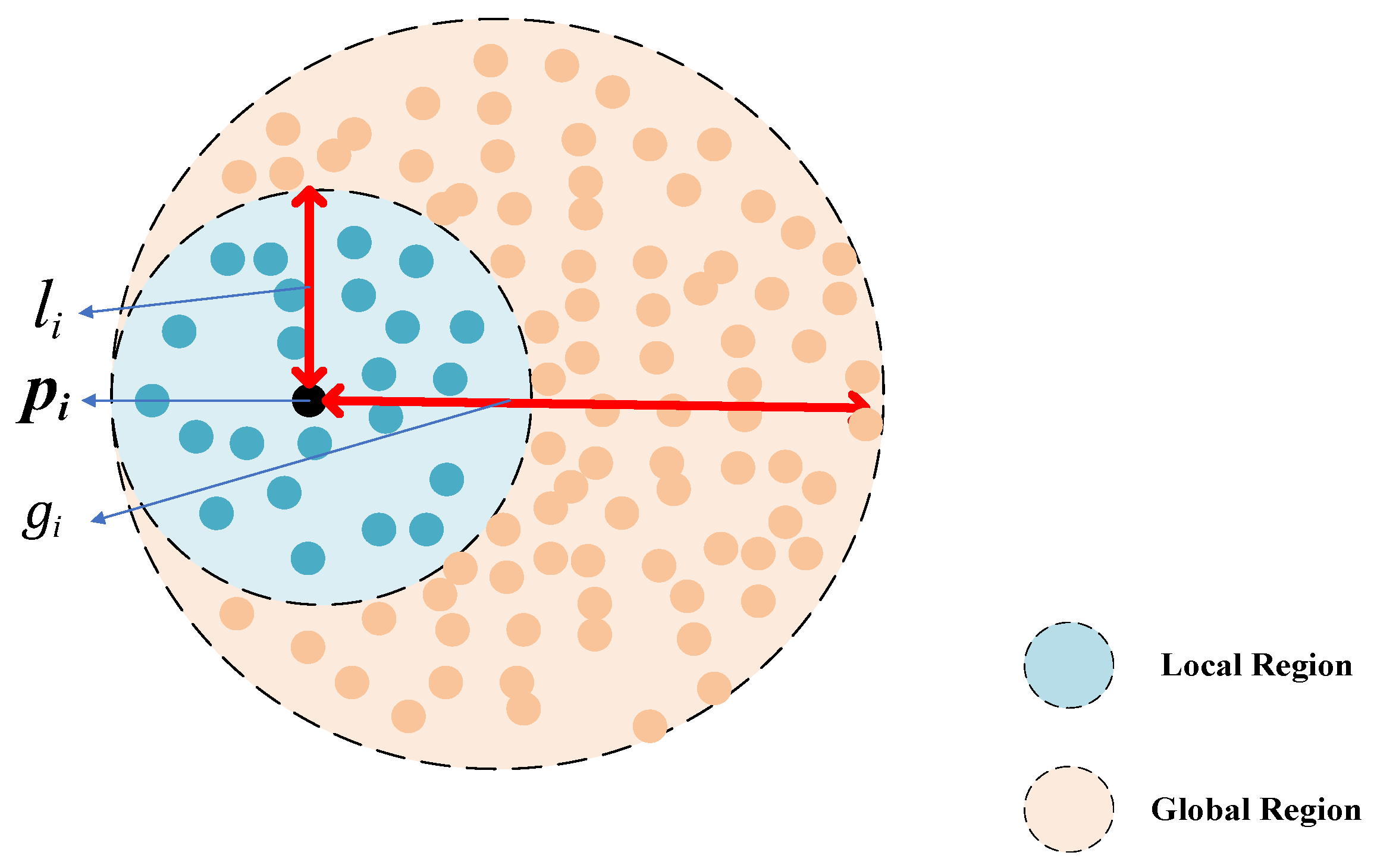
3.2.2. The Local-Global Feature Extraction Module
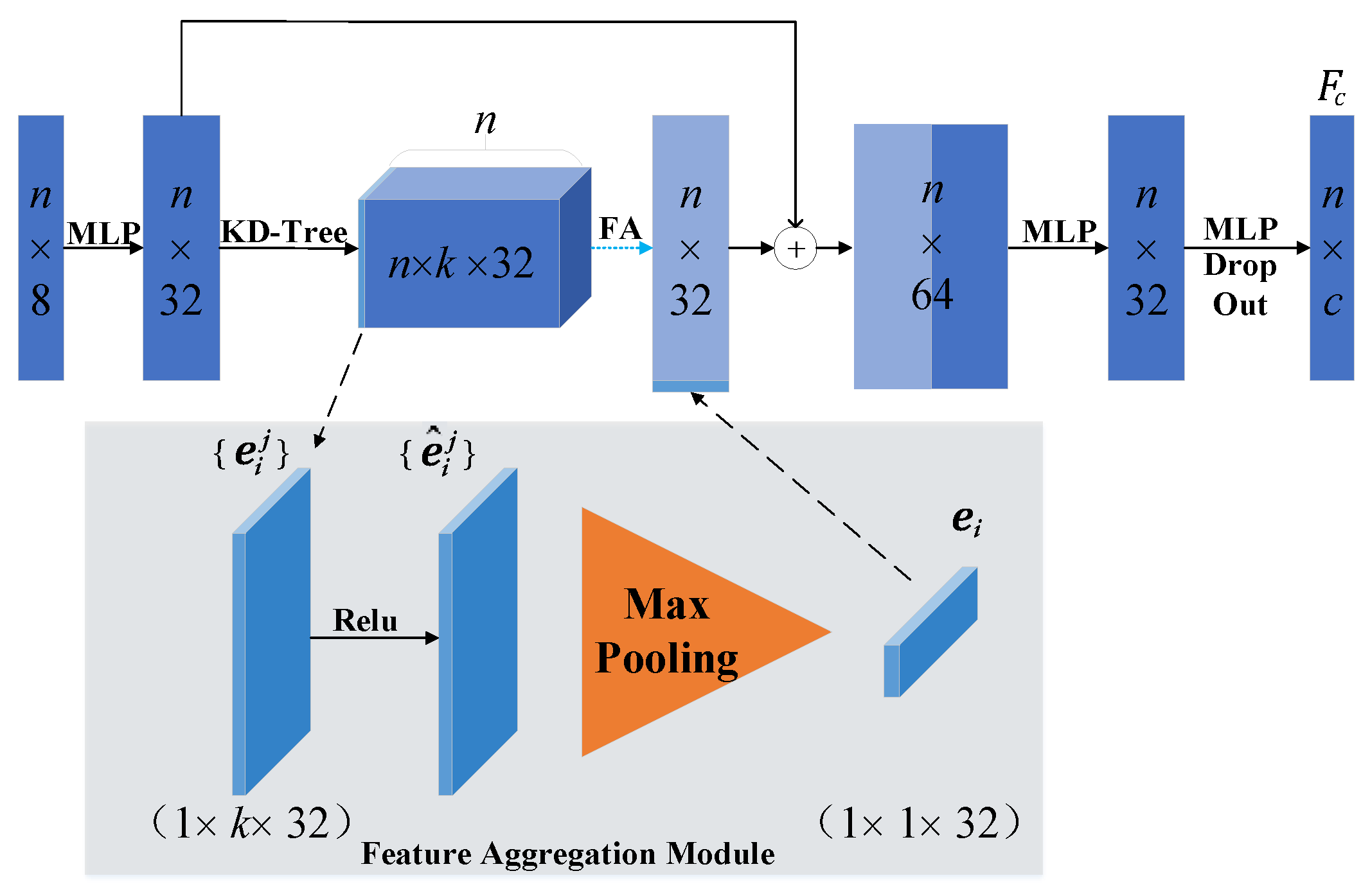
3.3. Local Feature Aggregation Classifiers
4. Experiment and Analysis
4.1. Dataset Introduction
4.2. Experimental Detail
4.3. Semantic3D
4.4. SemanticKITTI
4.5. Complexity Comparison Experiment
4.6. Ablation Experiments
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koppula, H.; Anand, A.; Joachims, T.; Saxena, A. Semantic labeling of 3d point clouds for indoor scenes. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 244–252. [Google Scholar]
- Tateno, K.; Tombari, F.; Navab, N. Real-time and scalable incremental segmentation on dense SLAM. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4465–4472. [Google Scholar]
- Deng, C.; Qiu, K.; Xiong, R.; Zhou, C. Comparative Study of Deep Learning Based Features in SLAM. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Nagoya, Japan, 13–15 July 2019; pp. 250–254. [Google Scholar]
- Li, J.; Li, Z.; Feng, Y.; Liu, Y.; Shi, G. Development of a Human–Robot Hybrid Intelligent System Based on Brain Teleoperation and Deep Learning SLAM. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1664–1674. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8338–8354. [Google Scholar] [CrossRef] [PubMed]
- An, Y.; Li, B.; Hu, H.; Zhou, X. Building an Omnidirectional 3-D Color Laser Ranging System through a Novel Calibration Method. IEEE Trans. Ind. Electron. 2019, 66, 8821–8831. [Google Scholar] [CrossRef]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and Recognition Using Structure from Motion Point Clouds. In Proceedings of the Computer Vision—ECCV 2008, Berlin/Heidelberg, Germany, 12–18 October 2008; pp. 44–57. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Bulò, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar]
- Che, Z.; Li, G.; Li, T.; Jiang, B.; Shi, X.; Zhang, X.; Lu, Y.; Wu, G.; Liu, Y.; Ye, J. D2-City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios. arXiv 2019, arXiv:1904.01975. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intel. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Li, J.; Lu, C.; Luo, Z.; Xue, H.; Wang, C. LiDAR-Video Driving Dataset: Learning Driving Policies Effectively. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5870–5878. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The ApolloScape Dataset for Autonomous Driving. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–10676. [Google Scholar]
- Song, X.; Wang, P.; Zhou, D.; Zhu, R.; Guan, C.; Dai, Y.; Su, H.; Li, H.; Yang, R. ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5447–5457. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21329–21338. [Google Scholar]
- Boulch, A.; Saux, B.L.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. In Proceedings of the Workshop on 3D Object Retrieval, Lyon, France, 23 April 2017; pp. 17–24. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.-H.; Kautz, J. SPLATNet: Sparse Lattice Networks for Point Cloud Processing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar]
- Rethage, D.; Wald, J.; Sturm, J.; Navab, N.; Tombari, F. Fully-Convolutional Point Networks for Large-Scale Point Clouds. In Proceedings of the Computer Vision—ECCV 2018, Cham, Switzerland, 8–14 September 2018; pp. 625–640. [Google Scholar]
- Graham, B.; Engelcke, M.; Maaten, L.v.d. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Jiang, M.; Wu, Y.; Lu, C. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Cham, Switzerland, 8–14 September 2018; pp. 395–409. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5560–5568. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1607–1616. [Google Scholar]
- Thomas, H.; Goulette, F.; Deschaud, J.E.; Marcotegui, B.; LeGall, Y. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 390–398. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10288–10297. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5105–5114. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Dataset Used | Characteristic | Limited | |
|---|---|---|---|---|
| Projection-based | SnapNet [18] | Semantic3D | These methods project a 3D point cloud onto a 2D image plane. They can be segmented by using the mature 2D image processing technology. They have low computational complexity. | These methods lose some information in the process of projection. They have poor segmentation for complex 3D shapes. They select the appropriate projection angle and parameters manually. |
| SqueezeSeg [19] | KITTI | |||
| SqueezeSegV2 [20] | KITTI | |||
| RangeNet++ [21] | KITTI | |||
| Voxel-based | SPLATNet [22] | RueMonge2014, ShapeNet | These methods convert the point cloud data into a voxel grid. They use voxel information to represent 3D objects. They can retain neighborhood information. | These methods may result in information loss. They have high time and space complexity. They can be difficult to select the correct voxel resolution. |
| FCPN [23] | ScanNets, ShapeNet | |||
| SSCNs [24] | ShapeNet, NYU Depth (v2) | |||
| Point-based | PointNet [25] | ModelNet40, ShapeNet, Stanford 3D | These methods directly process 3D point cloud data and preserve geometric information and details in the point cloud. They can effectively deal with the sparsity of the point cloud. They have low computational and memory consumption. | Most of these methods adopt expensive neighborhood search mechanisms. They require large scale, high quality annotated data. They are computationally complex. |
| PointSIEF [26] | S3DIS, ScanNet | |||
| PointWeb [28] | S3DIS, ScanNet, ModelNet40 | |||
| ShellNet [29] | ModelNet40, ShapeNet, ScanNet, S3DIS, Semantic3D | |||
| RandLA-Net [5] | SemanticKITTI, Semantic3D, S3DIS |
| Methods | mIou | OA | Class Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Man-Made | Natural | HighVeg | Low Veg | Buildings | Hard Scape | Scanning | Cars | |||
| SnapNet_ | 59.1 | 88.6 | 82.0 | 77.3 | 79.7 | 22.9 | 91.1 | 18.4 | 37.3 | 64.4 |
| SEGCloud | 61.3 | 88.1 | 83.9 | 66.0 | 86.0 | 40.5 | 91.1 | 30.9 | 27.5 | 64.3 |
| RF_MSSF | 62.7 | 90.3 | 87.6 | 80.3 | 81.8 | 36.4 | 92.2 | 24.1 | 42.6 | 56.6 |
| ShellNet | 69.3 | 93.2 | 96.3 | 90.4 | 83.9 | 41.0 | 94.2 | 34.7 | 43.9 | 70.2 |
| GAENet | 70.8 | 91.9 | 86.4 | 77.7 | 88.5 | 60.6 | 94.2 | 37.3 | 43.5 | 77.8 |
| SPG | 73.2 | 94.0 | 97.4 | 92.6 | 87.9 | 44.0 | 84.2 | 31.0 | 63.5 | 76.2 |
| KPConv | 74.6 | 92.9 | 90.9 | 82.2 | 84.2 | 47.9 | 94.9 | 40.0 | 77.3 | 79.7 |
| RandLA-Net | 77.4 | 94.8 | 95.6 | 91.4 | 86.6 | 51.5 | 95.7 | 51.5 | 69.8 | 76.8 |
| Our | 77.6 | 95.0 | 96.8 | 90.5 | 85.1 | 52.3 | 97.5 | 54.3 | 71.2 | 79.5 |
| Methods | mIou | Road | Sidewalk | Parking | Other-Ground | Building | Car | Truck | Bicycle | Motorcycle | Other-Vehicle | Vegetation | Trunk | Terrain | Person | Bicyclist | Motorcyclist | Fence | Pole | Traffic-Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet | 14.6 | 61.6 | 35.7 | 15.8 | 1.4 | 41.4 | 46.3 | 0.1 | 1.3 | 0.3 | 0.8 | 31.0 | 4.6 | 17.6 | 0.2 | 0.2 | 0.0 | 12.9 | 2.4 | 3.7 |
| SPG | 17.4 | 45.0 | 28.5 | 0.6 | 0.6 | 64.3 | 49.3 | 0.1 | 0.2 | 0.2 | 0.8 | 48.9 | 27.2 | 24.6 | 0.3 | 2.7 | 0.1 | 20.8 | 15.9 | 0.8 |
| PointNet++ | 20.1 | 72.0 | 41.8 | 18.7 | 5.6 | 62.3 | 53.7 | 0.9 | 1.9 | 0.2 | 0.2 | 46.5 | 13.8 | 30.0 | 0.9 | 1.0 | 0.0 | 16.9 | 6.0 | 8.9 |
| SqueezeSegV2 | 39.7 | 88.6 | 67.6 | 45.8 | 17.7 | 73.7 | 81.8 | 13.4 | 18.5 | 17.9 | 14.0 | 71.8 | 35.8 | 60.2 | 20.1 | 25.1 | 3.9 | 41.1 | 20.2 | 36.3 |
| RangeNet++ | 52.2 | 91.8 | 75.2 | 65.0 | 27.8 | 87.4 | 91.4 | 25.7 | 25.7 | 34.4 | 23.0 | 80.5 | 55.1 | 64.6 | 38.3 | 38.8 | 4.8 | 58.6 | 47.9 | 55.9 |
| RandLA-Net | 53.9 | 90.7 | 73.7 | 60.3 | 20.4 | 86.9 | 94.2 | 40.1 | 26.0 | 25.8 | 38.9 | 81.4 | 61.3 | 66.8 | 49.2 | 48.2 | 7.2 | 56.3 | 49.2 | 47.7 |
| Our | 54.9 | 91.3 | 73.9 | 62.0 | 22.6 | 88.6 | 93.9 | 40.0 | 27.9 | 28.2 | 40.5 | 81.2 | 61.9 | 67.1 | 45.0 | 49.3 | 10.9 | 58.0 | 50.0 | 54.1 |
| Total Time (Seconds) | Parameters (Millions) | mIoU (%) | |
|---|---|---|---|
| PointNet | 192 | 0.8 | 14.6 |
| PointNet++ | 9831 | 0.97 | 20.1 |
| SPG | 43,584 | 0.25 | 17.4 |
| RandLA-Net | 185 | 1.24 | 53.9 |
| LDE-Net (Our) | 191 | 1.32 | 54.9 |
| mIoU (%) | Total Time (Seconds) | Parameters (Millions) | |
|---|---|---|---|
| Base-Net | 50.1 | 173 | 1.10 |
| Base-Net + LGFE | 53.3 | 189 | 1.30 |
| Base-Net + LFAC | 52.1 | 190 | 1.27 |
| Base-Net + LGFE + LFAC (LDE-Net) | 54.9 | 191 | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; An, Y.; Cui, Y.; Dong, H. Semantic Segmentation of 3D Point Clouds in Outdoor Environments Based on Local Dual-Enhancement. Appl. Sci. 2024, 14, 1777. https://doi.org/10.3390/app14051777
Zhang K, An Y, Cui Y, Dong H. Semantic Segmentation of 3D Point Clouds in Outdoor Environments Based on Local Dual-Enhancement. Applied Sciences. 2024; 14(5):1777. https://doi.org/10.3390/app14051777
Chicago/Turabian StyleZhang, Kai, Yi An, Yunhao Cui, and Hongxiang Dong. 2024. "Semantic Segmentation of 3D Point Clouds in Outdoor Environments Based on Local Dual-Enhancement" Applied Sciences 14, no. 5: 1777. https://doi.org/10.3390/app14051777