
Evaluation of Machine Learning Models for Ozone Concentration Forecasting in the Metropolitan Valley of Mexico


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Data Set
3.2. Feature Vector Construction
- Temperature:
- Photochemical Reactions: Ozone formation in the troposphere is a result of photochemical reactions. Higher temperatures generally increase the rate of these reactions, leading to a faster and more efficient production of ozone.
- Stability of the Atmosphere: On hot days, especially under high-pressure systems, the atmosphere can become more stable, trapping pollutants, including ozone and its precursors, close to the ground and increasing concentrations.
- Volatile Organic Compound (VOC) Emissions: Higher temperatures can also lead to increased emissions of VOCs from vegetation and certain human-made sources, further promoting ozone formation.
- Humidity:
- Radical Production: Water vapor can contribute to the formation of hydroxyl radicals (), which play a crucial role in oxidizing VOCs and other pollutants, leading to the production of ozone. However, the exact relationship between humidity and ozone production can be complex and might vary depending on other prevailing conditions.
- Dilution: On the other hand, extremely high humidity levels can lead to condensation and cloud formation, which may reduce solar radiation, slowing down photochemical reactions.
- Wind Direction:
- Transport of Precursors: The direction of the wind can transport ozone precursors (like and VOCs) from their sources to other areas. For instance, if a city has major industrial zones on its eastern side and the wind is blowing from east to west, areas downwind can experience elevated ozone levels due to the transported pollutants.
- Clean Air Advection: Conversely, winds from rural or oceanic directions can bring cleaner air, reducing ozone concentrations.
- Wind Speed:
- Dispersion: Faster wind speeds can help disperse pollutants, diluting their concentration. This can decrease the buildup of ozone precursors in a particular area and reduce localized ozone formation.
- Vertical Mixing: Strong winds, especially when accompanied by turbulence, can enhance the vertical mixing of the atmosphere, distributing ozone and its precursors over a larger vertical layer. This can lead to a decrease in ground-level ozone concentrations.
- Emission of Precursors: Primary pollutants like nitrogen oxides () and volatile organic compounds (VOCs) are emitted into the atmosphere. These are typically released from automobile exhaust, industrial processes, power plants, and other combustion processes.
- Photodissociation of Nitrogen Dioxide ():In the presence of sunlight, undergoes photodissociation, breaking down into nitrogen monoxide () and a free oxygen atom (O). The symbol “” represents a photon of sunlight.
- Formation of ozone:The free oxygen atom (O) rapidly reacts with molecular oxygen () in the atmosphere to form ozone ().
- Reconversion:Nitrogen monoxide () can also react with the ozone () to form nitrogen dioxide () and molecular oxygen (). This essentially reduces the concentration of ozone.
- VOCs Role in the Cycle: VOCs, in the presence of and sunlight, can generate more reactive intermediates, which will react with to form . This reaction “removes” from the environment, allowing more ozone to form without it being quickly converted back to oxygen. In other words, the VOCs help “tie up” , preventing it from immediately destroying the ozone that’s been formed.
- Month:
- Sunlight Intensity and Duration: Ozone formation is a photochemical process that requires sunlight. Therefore, months with longer daylight hours and more intense sunlight, typically the spring and summer months, tend to have higher ozone concentrations.
- Temperature: Months with warmer temperatures, typically summer months, can lead to higher ozone concentrations.
- Vegetation Growth and Emissions: Certain months, especially spring and early summer, might see increased biogenic emissions of volatile organic compounds (VOCs) from vegetation, which can contribute to ozone formation.
- Day of week:
- Emissions Variability: Weekdays often have higher vehicular traffic and industrial activities compared to weekends. This can lead to higher emissions of ozone precursors like on weekdays.
- Weekend Effect: Despite reduced precursor emissions on weekends, some urban areas observe higher ozone levels during weekends, a phenomenon known as the “weekend effect”. This can be due to the disproportionate reduction in emissions compared to VOCs on weekends, altering the chemical balance and facilitating ozone production.
- Hour:
- Daily Cycle: Shown in the ozone concentration pattern, there are usually lower levels in the early morning because the sun has not risen or is low in the sky, reducing the intensity of UV radiation needed for ozone formation; ozone peaks during the afternoon when sunlight is most intense and temperatures are highest; in the evening, the rate of ozone production decreases, but the loss processes are slower. UV radiation needed for ozone formation changes throughout the day, affecting the intensity of UV radiation reaching the surface.
- Emissions Patterns: Human activities, such as traffic and industrial operations, have specific hourly patterns.
- Mixing Layer Depth: The depth of the atmospheric mixing layer changes throughout the day, affecting the dispersion of pollutants.
- Latitude:
- Sunlight Intensity: Near the equator (low latitudes), the sun’s rays are more direct, leading to more intense UV radiation, which can enhance photochemical reactions and thus ozone formation.
- Distribution of Emission Sources: Industrialized regions and urban centers, significant sources of ozone precursors like and VOCs, may be concentrated at specific latitudes.
- Stratospheric Intrusions: At high latitudes, stratospheric intrusions can introduce ozone-rich air from the stratosphere to the troposphere.
- Longitude:
- Time of Day: Due to the Earth’s rotation, the position of the sun changes with longitude, affecting the daily cycle of photochemical reactions.
- Distribution of Emission Sources: Significant emission sources might be concentrated at specific longitudes.
- Meteorological Patterns: Weather systems vary longitudinally, especially in regions influenced by oceanic or continental effects.
- Altitude:
- Decreased Pressure: As altitude increases, atmospheric pressure decreases, potentially affecting ozone formation.
- Temperature Profile: The temperature can either increase or decrease with altitude, affecting ozone concentrations.
- Vertical Distribution of : Ozone concentrations generally increase with altitude in the troposphere and are high in the stratosphere.
- Transport of Ozone Precursors: Elevated regions might be exposed to ozone precursors transported from lower altitudes.
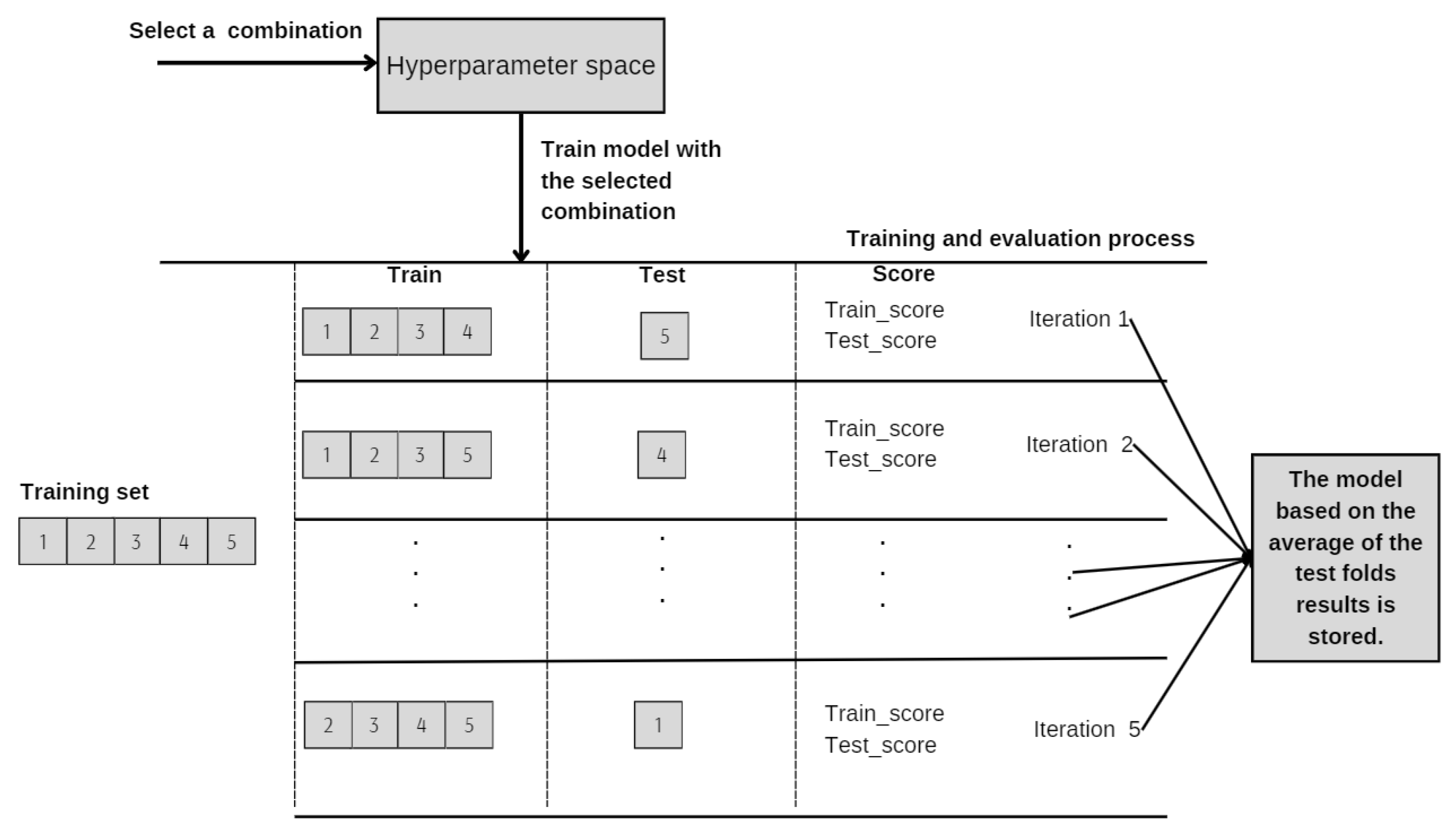
3.3. Hyperparameter Optimization
- Definition of Hyperparameter Space: The first step involves delineating the range or set of values for each hyperparameter under consideration. This set forms a grid of hyperparameter combinations, where each node represents a unique combination. The generation of this grid of options and evaluating all solutions is a task that demands too many resources and is impossible to carry out because many hyperparameters take continuous values. Therefore, it is chosen to define recommended or well-known ranges of values for these hyperparameters, creating a finite space of combinations.
- Cross-Validation Mechanism: GridSearch is typically coupled with cross-validation to assess the performance of the model for each hyperparameter combination. Cross-validation involves dividing the training dataset into multiple smaller sets or folds. The model is trained on all but one fold (the training set) and validated on the remaining fold (the test set). This process is repeated so that each fold serves as the validation set once, ensuring comprehensive evaluation.The utilization of cross-validation helps to improve the model’s performance by reducing variance through averaging performance estimates from multiple iterations of training and testing on different data subsets. It presents a better generalization by evaluating the model on multiple subsets of the data, aiding in assessing its generalization capabilities. This is especially important for detecting overfitting, as the model’s performance is evaluated on various data partitions, resulting in a more robust estimate of its accuracy on unseen data, as is mentioned in the study guided by Kohavi [21].
- Selection of Optimal Hyperparameters: Post evaluation, the combination of hyperparameters that produces the best performance is selected based on the minimal average error of the test folds.
| n | = sample size. |
| N | = population size. |
| Z | = critical Z value; for a confidence level of , z equals 2.58. |
| = population variance. | |
| E | = absolute precision level; of the population’s standard deviation. |
3.4. Model Evaluation
3.5. Setup for the Experiment
4. Results
4.1. GridSearch
4.2. Optimal Model Selection
5. Discussion
5.1. General Discussion
5.2. Analysis of the Optimal Performing Model
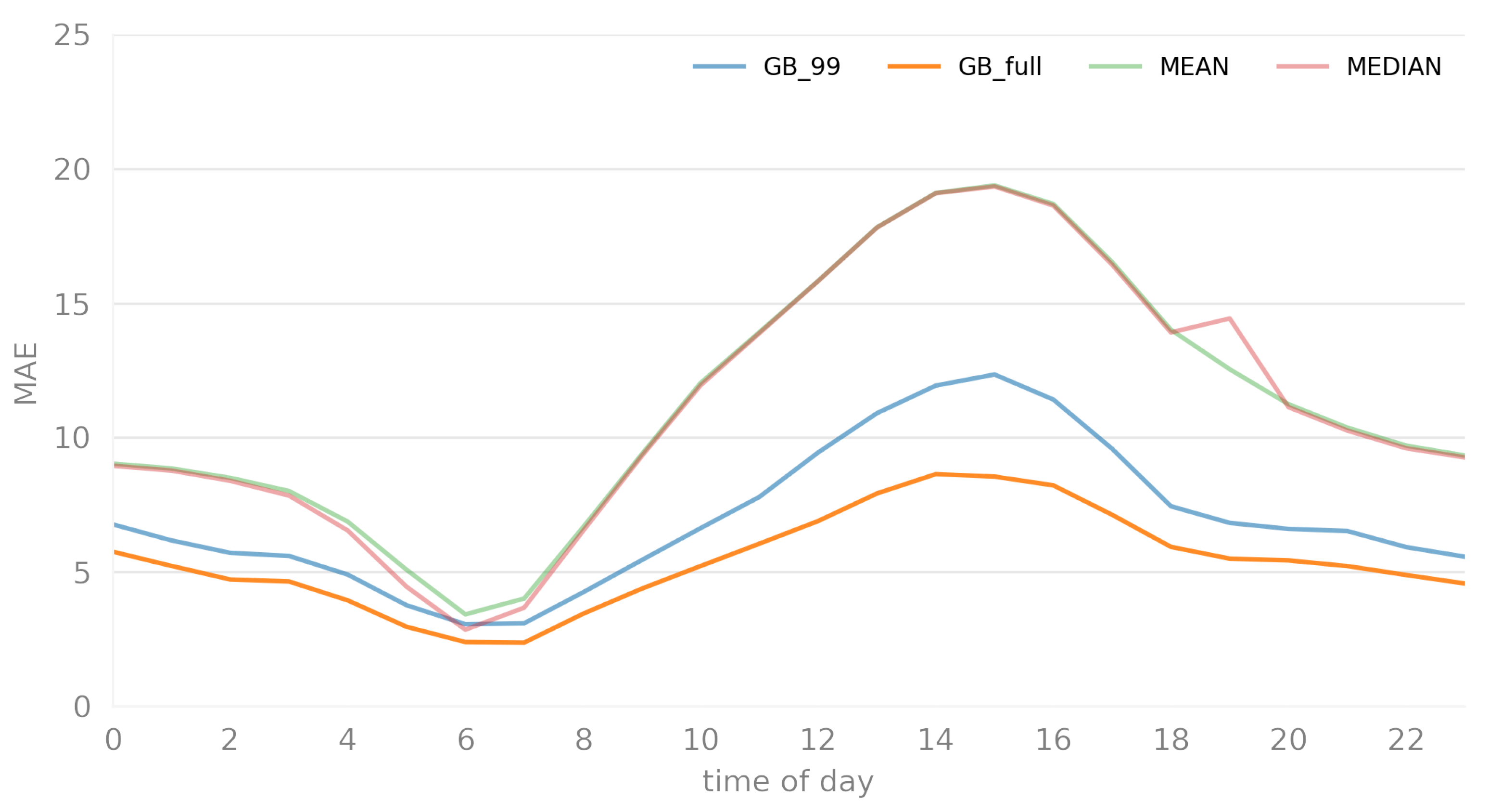
- Data Size Impact: The GB_full model, trained on a significantly larger dataset (519,327 records) compared to GB_99 (57,704 records), consistently shows lower MAE across all timeframes. This indicates the potential benefits of training on more extensive data, likely capturing more nuances and patterns, leading to better predictive performance.
- Performance Consistency: Both models exhibit a similar pattern in MAE fluctuations over the 24 h, suggesting that the underlying data characteristics influencing error rates are similar for both datasets. However, the magnitude of the error is consistently lower in the GB_full model, reinforcing the value of a more extensive training set.
- Timeframe Sensitivity: There are periods (like early morning hours) where the MAE is relatively lower for both models and periods (like afternoon to early evening) where MAE peaks. This pattern could indicate varying model performance based on time-specific factors, suggesting that certain hours have characteristics that are either more predictable or more challenging for the model.
- Significant Improvement Over Baseline: Both Gradient Boosting models (GB_99 and GB_full) consistently outperform the baseline models across almost all timeframes. The MAEs for the baseline methods are significantly higher than those for the Gradient Boosting models, indicating the superior predictive capability of the latter.
- Effectiveness of Machine Learning Models: The considerable reduction in MAE when using the Gradient Boosting models compared to the baseline methods illustrates the value of machine learning in capturing complex patterns and relationships in the data that simple statistical measures cannot.
6. Conclusions
- Machine learning models are a significant alternative for ozone concentration forecasting. However, it is paramount to identify the variables influencing the phenomenon in constructing the feature vector. This enables the models to discern patterns and relationships among the variables correctly.
- Computational complexity can significantly impact the best model selection, as the computational resources required for hyperparameter optimization can be time-consuming and may not be feasible.
- A substantial volume of historical records to train models can enhance their precision. However, certain models do not efficiently handle large datasets, leading to disproportionately increased evaluation times. Therefore, employing a technique that allows for selecting a sufficiently representative sample to achieve results with an acceptable level of reliability without adversely affecting the outcomes of the models is of paramount importance. This approach ensures both the effectiveness and efficiency of the model training and evaluation process.
- Establishing a baseline is a critical step in model evaluation. It helps set realistic expectations and understand the value added by complex models.
- The GB models’ lower MAE scores, especially compared to the relatively high baseline MAEs, suggest that these models have successfully captured significant underlying trends and patterns in the hourly ozone concentration profile.
- Elevated errors observed during specific time intervals warrant further investigation as potential focal points for future enhancements in model performance. Delving into the underlying reasons for these heightened error rates during particular hours and exploring what additional data or modifications in feature engineering might mitigate these discrepancies could yield significant advancements in model accuracy and reliability.
- Tree-based models like Random Forests or Gradient Boosting demonstrated better generalization to unseen data, but they tend to be more prone to overfitting than SVR models. This might necessitate more frequent retraining of tree-based models compared to SVR. However, given their shorter training times, they still present a better option in terms of model maintainability.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| AQI | Air Quality Index |
| CO | Carbon Monoxide |
| CONAGUA | Comisión Nacional del Agua |
| GB | Gradient Boosting |
| IOA | Index of Agreement |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| NO | Nitric Oxide |
| Nitrogen Dioxide | |
| NOx | Nitrogen oxides |
| O3 | Ozone |
| OH | Hydroxyl radicals |
| PM10 | Particulate matter 10 m or less in diameter |
| PM2.5 | Particulate matter 2.5 m or less in diameter |
| Coefficient of determination | |
| RAMA | Automatic Atmospheric Monitoring Network |
| REDMET | Meteorological Network |
| RF | Random Forest |
| RH | Relative humidity |
| RMSE | Root Mean Square Error |
| SIMAT | Atmospheric Monitoring System of Mexico City |
| SO2 | Sulfur dioxide |
| SVR | Support Vector Regression |
| tmp | Temperature |
| VOC | Volatile Organic Compound |
| wdr | Wind direction |
| wsp | Wind speed |
References
- Molina, L.T.; Madronich, S.; Gaffney, J.S.; Apel, E.; de Foy, B.; Fast, J.; Ferrare, R.; Herndon, S.; Jimenez, J.L.; Lamb, B.; et al. An overview of the MILAGRO 2006 Campaign: Mexico City emissions and their transport and transformation. Atmos. Chem. Phys. 2010, 10, 8697–8760. [Google Scholar] [CrossRef]
- Rojas-Martinez, R.; Perez-Padilla, R.; Olaiz-Fernandez, G.; Mendoza-Alvarado, L.; Moreno-Macias, H.; Fortoul, T.; McDonnell, W.; Loomis, D.; Romieu, I. Lung Function Growth in Children with Long-Term Exposure to Air Pollutants in Mexico City. Am. J. Respir. Crit. Care Med. 2007, 176, 377–384. [Google Scholar] [CrossRef] [PubMed]
- Baldasano, J.; Valera, E.; Jimenez, P. Air quality data from large cities. Sci. Total Environ. 2003, 307, 141–165. [Google Scholar] [CrossRef] [PubMed]
- Karthik L, B.; Sujith, B.; Rizwan A, S.; Sehgal, M. Characteristics of the Ozone Pollution and its Health Effects in India. Int. J. Med. Public Health 2017, 7, 56–60. [Google Scholar] [CrossRef]
- Niu, Y.; Zhou, Y.; Chen, R.; Yin, P.; Meng, X.; Wang, W.; Liu, C.; Ji, J.S.; Qiu, Y.; Kan, H.; et al. Long-term exposure to ozone and cardiovascular mortality in China: A nationwide cohort study. Lancet Planet. Health 2022, 6, e496–e503. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Rappenglück, B.; Osibanjo, O.; Retama, A. A machine learning approach to investigate the build-up of surface ozone in Mexico-City. J. Clean. Prod. 2022, 379, 134638. [Google Scholar] [CrossRef]
- Yarragunta, S.; Nabi, M.A.; Jeyanthi, P.; Revathy, S. Prediction of Air Pollutants Using Supervised Machine Learning. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 1633–1640. Available online: https://ieeexplore.ieee.org/document/9432078 (accessed on 30 November 2023).
- Liang, Y.C.; Maimury, Y.; Chen, A.H.L.; Juarez, J.R.C. Machine Learning-Based Prediction of Air Quality. Appl. Sci. 2020, 10, 9151. [Google Scholar] [CrossRef]
- Aljanabi, M.; Shkoukani, M.; Hijjawi, M. Ground-level Ozone Prediction Using Machine Learning Techniques: A Case Study in Amman, Jordan. Int. J. Autom. Comput. 2020, 17, 667–677. [Google Scholar] [CrossRef]
- Di, Q.; Amini, H.; Shi, L.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A.; et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef]
- Srivastava, C.; Singh, S.; Singh, A.P. Estimation of Air Pollution in Delhi Using Machine Learning Techniques. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 304–309. [Google Scholar] [CrossRef]
- Zhu, D.; Cai, C.; Yang, T.; Zhou, X. A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization. Big Data Cogn. Comput. 2018, 2, 5. [Google Scholar] [CrossRef]
- Aditya, C.R.; Deshmukh, C.R.; Nayana, D.K.; Vidyavastu, P.G. Detection and Prediction of Air Pollution using Machine Learning Models. Int. J. Eng. Trends Technol. 2018, 59, 204–207. [Google Scholar] [CrossRef]
- Contreras-Ochando, L.; Ferri, C. airVLC: An Application for Visualizing Wind-Sensitive Interpolation of Urban Air Pollution Forecasts. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 1296–1299. Available online: https://ieeexplore.ieee.org/document/7836819 (accessed on 30 November 2023).
- CDMX, G. Dirección de Monitoreo Atmosférico. 2003. Available online: http://www.aire.cdmx.gob.mx/aire/default.php (accessed on 18 January 2023).
- México, G. Estaciones Meteorológicas Automáticas (EMAS). 2008. Available online: https://smn.conagua.gob.mx/es/observando-el-tiempo/estaciones-meteorologicas-automaticas-ema-s (accessed on 23 March 2023).
- Lelieveld, J.; Dentener, F.J. What controls tropospheric ozone? J. Geophys. Res. Atmos. 2000, 105, 3531–3551. [Google Scholar] [CrossRef]
- Finlayson-Pitts, B.; Pitts, J. Atmospheric Chemistry of Tropospheric Ozone Formation: Scientific and Regulatory Implications. Air Waste 1993, 43, 1091–1100. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Series Title: The Springer Series on Challenges in Machine Learning; Springer: Cham, Switzerland; pp. 3–33. Available online: https://link.springer.com/chapter/10.1007/978-3-030-05318-5_12019 (accessed on 30 November 2023).
- Kohavi, R.; John, G.H. Automatic Parameter Selection by Minimizing Estimated Error. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 304–312. Available online: https://www.sciencedirect.com/science/article/abs/pii/B9781558603776500451?via%3Dihub (accessed on 30 November 2023).
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence-Volume 2, Montreal, QC, Canada, 20–25 August 1995; IJCAI’95. pp. 1137–1143. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Liu, Y.; Wang, Y.; Zhang, J. New Machine Learning Algorithm: Random Forest. In Information Computing and Applications; Series Title: Lecture Notes in Computer Science; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7473, pp. 246–252. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley: Hoboken, NJ, USA, 1977. [Google Scholar]
- Abdiansah, A.; Wardoyo, R. Time Complexity Analysis of Support Vector Machines (SVM) in LibSVM. Int. J. Comput. Appl. 2015, 128, 28–34. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Paper | Predicted | Predictors | Models | Metrics |
|---|---|---|---|---|
| A Machine Learning approach to investigate the build-up of surface ozone in Mexico City (2022) [6]. | . | Temperature, Relative humidity, Wind speed and direction, , , UV-A and Planetary Boundary Layer Height. | Random Forest, Gradient Boosting, Deep Neural Network. | , Index of Agreement (IOA). |
| Prediction of Air Pollutants Using Supervised Machine Learning (2021) [7]. | Air quality index for , , , , , , . | Country, State, City, Place, Last updated, Min, Max, Average, and Pollutants(, , , , , ). | Decision Tree, Support Vector Machine, Logistic Regression, Random Forest, Naive Bayes, K-Nearest Neighbor. | Accuracy. |
| Machine Learning-Based Prediction of Air Quality (2020) [8] | Air quality index for 1 h, 8 h, and 24 h. | and moving average, average of the last eight hours, concentration for the last eight hours, Air uality index based on the maximum concentration of , , , , and . | Random Forest, AdaBoost, Support Vector Regression, Artificial Neural Network. | RMSE, MAE, . |
| Ground-level Ozone Prediction Using Machine Learning Techniques: A Case Study in Amman, Jordan (2020) [9] | . | Ozone, Temperature, Humidity, Wind direction, and speed, Memorable day (weekend, holiday), Day of the year. | Multi-Layer Perceptron, Support Vector Regression, Decision Tree, XGBoost. | RMSE, MAE, . |
| An ensemble-based model of concentration across the contiguous United States with high spatiotemporal resolution (2019) [10] | . | Satellite-derived aerosol optical depth, Satellite-based measurements, Chemical transport model predictions, Land-use variables, and Meteorological variables. | Ensemble Model (Neural Network, Random Forest, Gradient Boosting). | RMSE, . |
| Estimation of Air Pollution in Delhi Using Machine Learning Techniques (2018) [11] | Air pollution levels for , , , , , . | Vertical wind, Wind speed and direction, Temperature, and Relative humidity. | Linear Regression, Stochastic Gradient Descent, Random Forest, Decision Tree, Support Vector Regression, Multi-layer Perceptron, Gradient Boosting Adaptive Boosting. | RMSE, MAE, . |
| A Machine Learning Approach for Air Quality Prediction: Model Regularization and Optimization (2018) [12]. | Next day concentration for , , . | Air temperature, Relative humidity, Wind speed, and direction, Wind gust, Precipitation accumulation, Visibility, Dew point, Wind cardinal direction, Pressure, Weather conditions, Weekday/weekend, Concentration pollutant, and Bias term. | MTL with Linear Regression. | RMSE. |
| Detection and Prediction of Air Pollution Using Machine Learning Models (2018) [13]. | Classification of Samples into Polluted or Non-Polluted Categories, . | Temperature, Wind speed, Dew point, Pressure, Concentration, Classification result. | Autoregression, Logistic Regression. | MA, SDA, MAE. |
| AirVLC: an Application for Visualizing Wind-sensitive Interpolation of Urban Air Pollution Forecasts (2016) [14]. | , , , . | Pollution level, Meteorological conditions (Temperature, Relative humidity, Pressure, Wind speed, Rain), Calendar features (Year, Month, Day in the month, Day in the week, Hour), and Traffic intensity features. | Linear Regression, Quantile Regression, K-Nearest Neighbor, Random Forest, Decision Tree. | RMSE. |
| Temporal and Geospatial Variables | |||||||
|---|---|---|---|---|---|---|---|
| longitude | latitude | altitude | month | weekday | hour | ||
| 24 h prior meteorological and pollutant variables | |||||||
| Relative humidity (rh) | Temperature (tmp) | Wind direction (wdr) | Wind speed (wsp) | ||||
| Solar radiation from EMAs stations 24 h prior | |||||||
| ECOGUARDAS | TEZONTLE | MOLINODELREY | ENCBI | ENCBII | PRESAMADIM | ||
| Meteorological variables | Pollutant variables | EMAs Stations | |||||
| Mean 00to03 | Mean 00to03 | Mean 00to03 | |||||
| Mean 04to07 | Mean 04to07 | Mean 04to07 | |||||
| Mean 08to11 | Mean 08to11 | Mean 08to11 | |||||
| Mean 12to15 | Mean 12to15 | Mean 12to15 | |||||
| Mean 16to19 | Mean 16to19 | Mean 16to19 | |||||
| Mean 20to23 | Mean 20to23 | Mean 20to23 | |||||
| previous day’s maximum | previous day’s maximum | previous day’s maximum | |||||
| previous day’s minimum | previous day’s minimum | previous day’s minimum | |||||
| Model | Hyperparameters |
|---|---|
| RandomForest | Max depth: 40–50 |
| Max features: 10–25 | |
| SVR (kernel RBF) | Scaling: [StandardScaler, MinMaxScaler] |
| Gamma: [0.001, 0.01, 0.1, 1, 10, 100] | |
| C: [0.001, 0.01, 0.1, 1, 10, 100] | |
| SVR (kernel poly) | Scaling: [StandardScaler, MinMaxScaler] |
| Degree: [2, 3, 4, 5, 6, 7, 8, 9] | |
| C: [0.001, 0.01, 0.1, 1, 10, 100] | |
| GradientBoosting | n estimators: [1, 2, 5, 10, 20, 50, 100, 200, 300] |
| Max depth: [5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] | |
| Learning rate: [0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] |
| Timeframe | MAE from Mean | MAE from Median | Timeframe | MAE from Mean | MAE from Median |
|---|---|---|---|---|---|
| 2015–2022 | 21.53 | 20.77 | |||
| 00:00 | 9.03 | 8.95 | 12:00 | 15.83 | 15.82 |
| 01:00 | 8.85 | 8.77 | 13:00 | 17.82 | 17.81 |
| 02:00 | 8.50 | 8.39 | 14:00 | 19.10 | 19.09 |
| 03:00 | 8.01 | 7.84 | 15:00 | 19.38 | 19.34 |
| 04:00 | 6.87 | 6.54 | 16:00 | 18.69 | 18.63 |
| 05:00 | 5.08 | 4.45 | 17:00 | 16.53 | 16.43 |
| 06:00 | 3.42 | 2.85 | 18:00 | 14.01 | 13.91 |
| 07:00 | 4.01 | 3.67 | 19:00 | 12.54 | 12.43 |
| 08:00 | 6.66 | 6.52 | 20:00 | 11.24 | 11.13 |
| 09:00 | 9.38 | 9.31 | 21:00 | 10.37 | 10.26 |
| 10:00 | 12.03 | 11.94 | 22:00 | 9.70 | 9.60 |
| 11:00 | 13.92 | 13.88 | 23:00 | 9.33 | 9.26 |
| Model | Hyperparameters | Test Score | Train Score | Gap |
|---|---|---|---|---|
| RandomForest Execution time: 2600 | max depth = 45, max features = 25. | 7.825020 | 2.923992 | 4.901028 |
| StandardScaler → SVR (RBF) Execution time: 29,672 | C = 100, gamma = 0.01. | 7.845238 | 3.350762 | 4.494476 |
| C = 10, gamma = 0.001. | 8.757496 | 8.652644 | 0.104852 | |
| StandardScaler → SVR (poly) Execution time: 104,571 | C = 100, degree = 3. | 9.062664 | 5.348223 | 3.714441 |
| C = 10, degree = 2. | 11.562271 | 10.979601 | 0.582670 | |
| MinMaxScaler → SVR (RBF) Execution time: 22,465 | C = 100, gamma = 0.1. | 7.785040 | 6.806308 | 0.978732 |
| C = 100, gamma = 0.01. | 8.700342 | 8.617988 | 0.082355 | |
| MinMaxScaler → SVR (poly) Execution time: 1,705,128 | C = 100, degree = 3. | 7.925763 | 6.892926 | 1.032837 |
| C = 10, degree = 4. | 8.060671 | 7.198237 | 0.862434 | |
| GradientBoosting Execution time: 42,584 | learning rate = 0.1, max depth = 10, max features = 12, n estimators = 300. | 7.144314 | 1.735895 | 5.408419 |
| learning rate = 0.1, max depth = 9, max features = 11, n estimators = 300. | 7.187491 | 2.818148 | 4.369343 |
| Model | Fit Time | Evaluation Score 1 |
|---|---|---|
| GradientBoosting[0] 2 | 522 | 7.015008 |
| GradientBoosting[1] | 423 | 7.126916 |
| StandardScaler → SVR (RBF)[0] | 54,058 | 7.689650 |
| RandomForest | 392 | 7.808124 |
| MinMaxScaler → SVR (poly)[0] | 8172 | 7.901960 |
| MinMaxScaler → SVR (poly)[1] | 3250 | 8.037673 |
| MinMaxScaler → SVR (RBF)[0] | 1968 | 8.717526 |
| StandardScaler → SVR (RBF)[1] | 4191 | 8.758239 |
| StandardScaler → SVR (poly)[0] | 73,851 | 9.468176 |
| MinMaxScaler → SVR (RBF)[1] | 1959 | 10.733147 |
| StandardScaler → SVR (poly)[1] | 4242 | 11.405547 |
| Timeframe | GB_99 | GB_full | Timeframe | GB_99 | GB_full |
|---|---|---|---|---|---|
| 00:00 | 6.772 | 5.754 | 12:00 | 9.444 | 6.893 |
| 01:00 | 6.172 | 5.223 | 13:00 | 10.905 | 7.919 |
| 02:00 | 5.709 | 4.718 | 14:00 | 11.932 | 8.639 |
| 03:00 | 5.595 | 4.645 | 15:00 | 12.345 | 8.546 |
| 04:00 | 4.9 | 3.941 | 16:00 | 11.413 | 8.22 |
| 05:00 | 3.76 | 2.958 | 17:00 | 9.582 | 7.125 |
| 06:00 | 3.054 | 2.39 | 18:00 | 7.443 | 5.932 |
| 07:00 | 3.088 | 2.369 | 19:00 | 6.824 | 5.493 |
| 08:00 | 4.239 | 3.441 | 20:00 | 6.6 | 5.428 |
| 09:00 | 5.44 | 4.377 | 21:00 | 6.521 | 5.217 |
| 10:00 | 6.628 | 5.218 | 22:00 | 5.924 | 4.885 |
| 11:00 | 7.789 | 6.05 | 23:00 | 5.565 | 4.567 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domínguez-García, R.; Arellano-Vázquez, M. Evaluation of Machine Learning Models for Ozone Concentration Forecasting in the Metropolitan Valley of Mexico. Appl. Sci. 2024, 14, 1408. https://doi.org/10.3390/app14041408
Domínguez-García R, Arellano-Vázquez M. Evaluation of Machine Learning Models for Ozone Concentration Forecasting in the Metropolitan Valley of Mexico. Applied Sciences. 2024; 14(4):1408. https://doi.org/10.3390/app14041408
Chicago/Turabian StyleDomínguez-García, Rodrigo, and Magali Arellano-Vázquez. 2024. "Evaluation of Machine Learning Models for Ozone Concentration Forecasting in the Metropolitan Valley of Mexico" Applied Sciences 14, no. 4: 1408. https://doi.org/10.3390/app14041408