
Self-Distillation and Pinyin Character Prediction for Chinese Spelling Correction Based on Multimodality

Abstract
:1. Introduction
2. Related Work
2.1. Chinese Spelling Correction
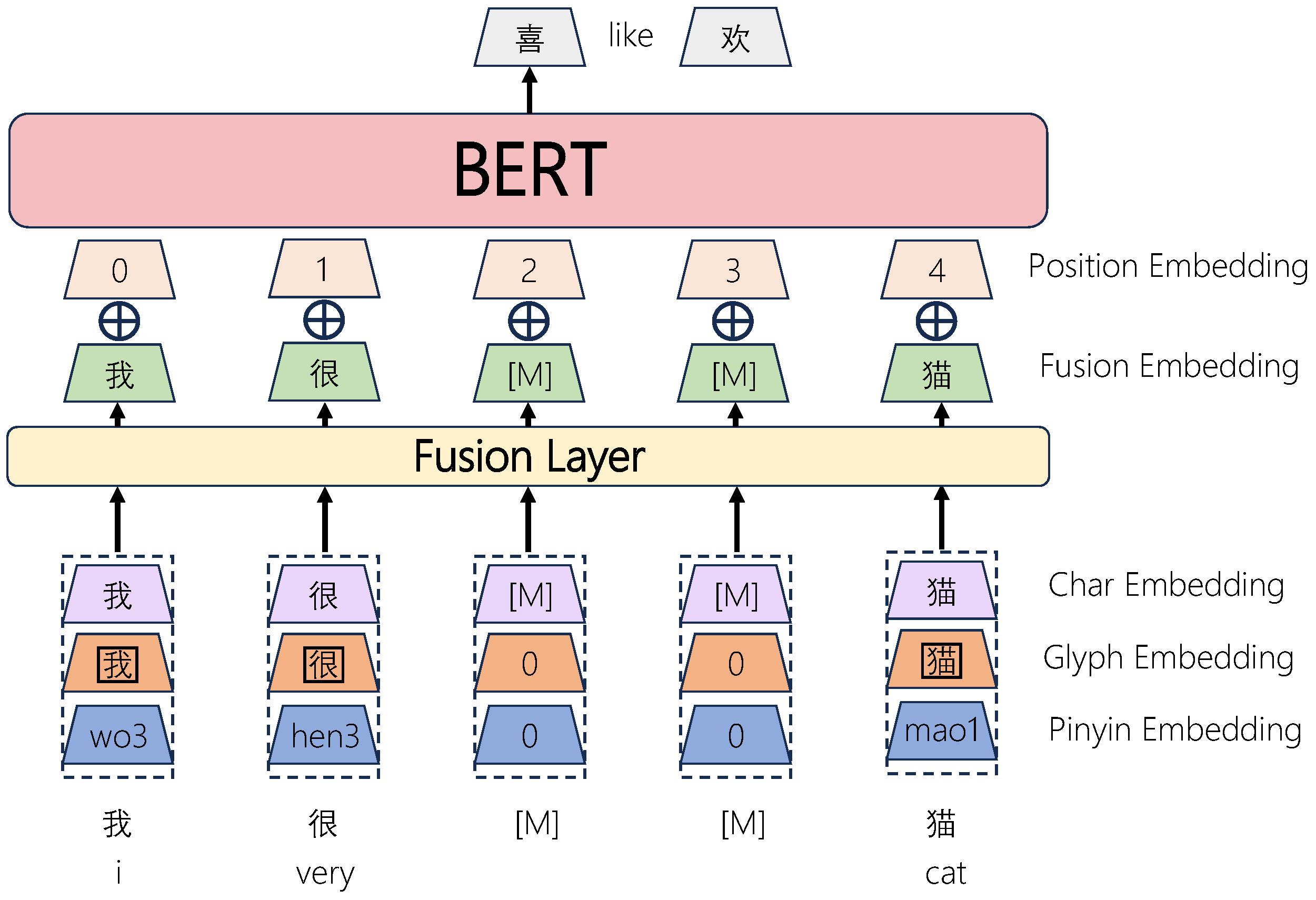
2.2. Multimodal Learning
2.3. Self-Distillation
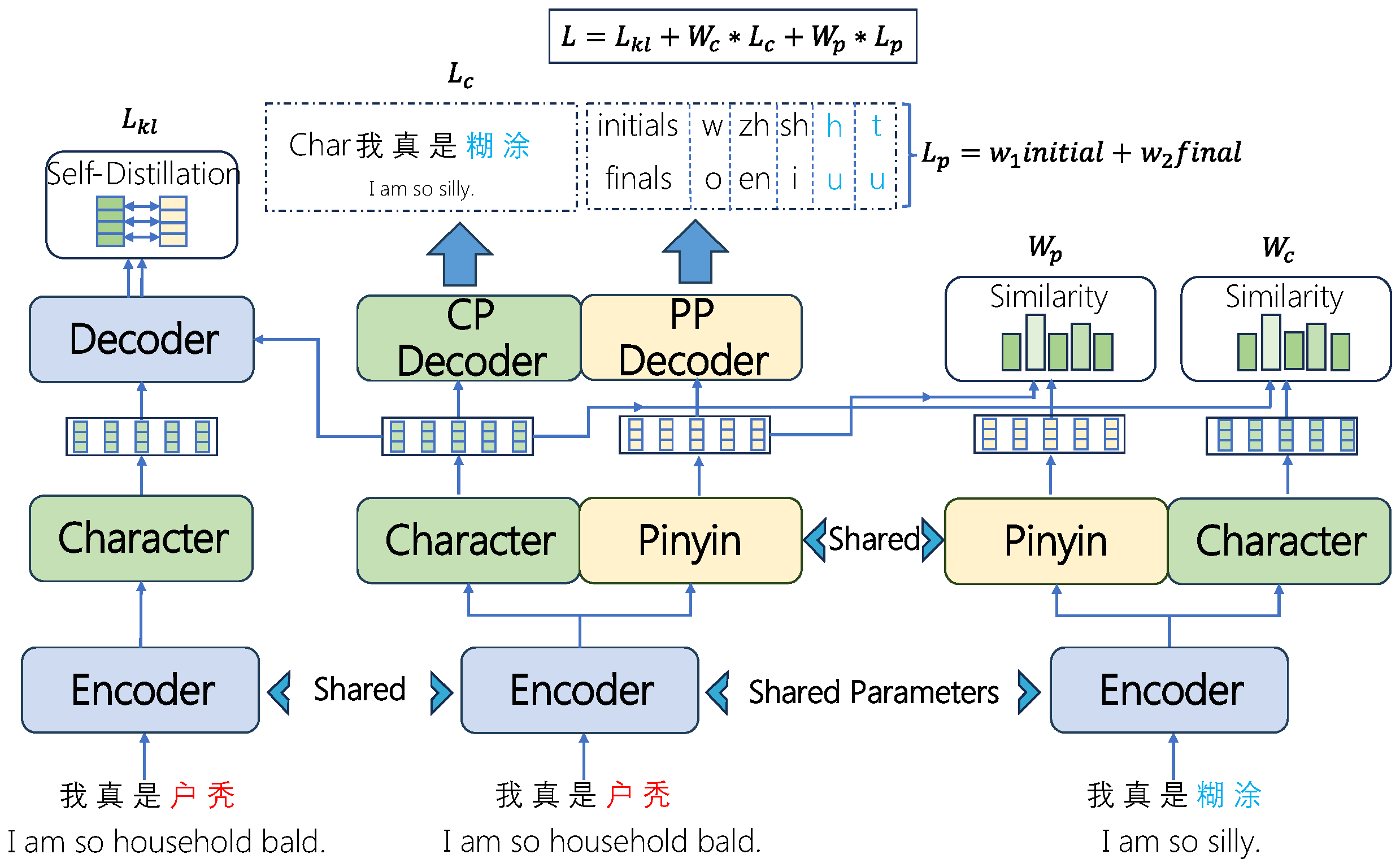
3. Methodology
3.1. Problem Definition
3.1.1. Architecture
3.1.2. Encoder
3.1.3. Character Prediction Decoder
3.1.4. Pinyin Prediction Decoder
3.1.5. Self-Distillation Decoder
3.1.6. Adaptive Weighting
3.2. Inference
4. Experiments
4.1. Datasets and Metrics
4.2. Baselines
- GAD [12]: This method learns the global relationship between potentially correct input characters and candidates for potentially incorrect characters.
- DCN [10]: Through a unique dynamic connection network, paths (K denotes the number of candidate words, n denotes the length of the sentence) are generated in the output stage of the model, and then an optimal path is selected by scoring through the dynamic connection network; an attentional mechanism is introduced to model the dependency relationship between neighboring characters.
- REALISE [8]: The method predicts the output by encoding phonological and graphemic information based on semantic information and finally introduces a gating mechanism to selectively fuse semantic, phonological, and graphemic information.
- uChecker [38]: A masked pre-trained language model is proposed as an unsupervised Chinese spell checker. The method uses the pre-trained model to learn contextual information and uses a masked language modeling task to predict misspelled words for spell-checking.
- MDCSpell [14]: The method designs a multitasking framework with BERT as a corrector that captures visual and phonetic features of characters and integrates the hidden state of the detector to minimize the impact of errors.
- ECOPE [13]: This thesis proposes a method for Chinese spell correction using error-driven comparison probability optimization to improve the accuracy of future spell-checking by learning the comparison between past spelling errors and correct spellings.
- UMRSpell [39]: It aims to unify the detection and correction parts of the pre-trained model to achieve Chinese missing, redundancy, and spelling correction. The method utilizes the contextual information of the pre-trained model and the Transformer structure to achieve spelling detection and correction by means of joint learning.
4.3. Experimental Parameter Setting
4.4. Overall Results
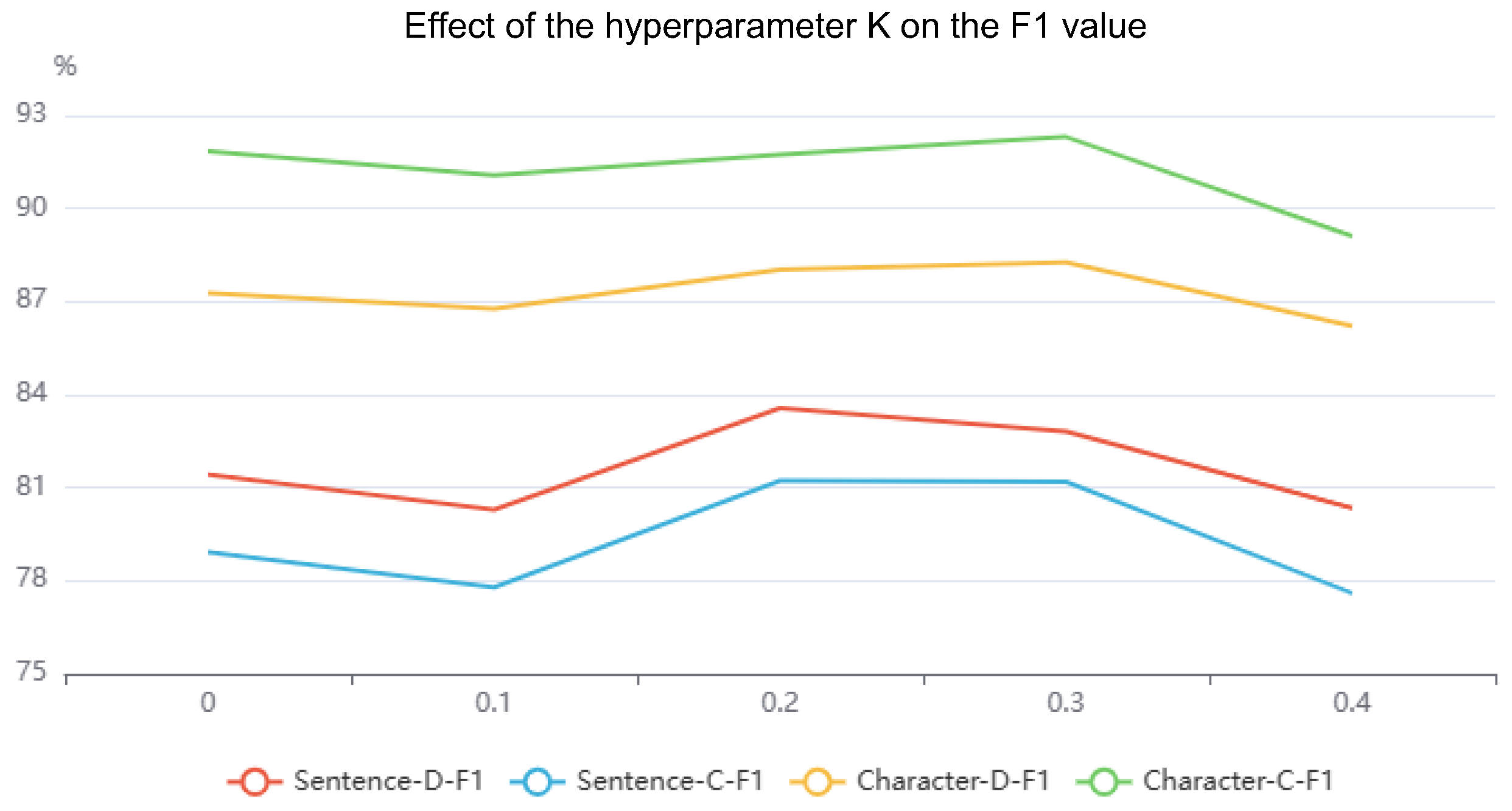
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martins, B.; Silva, M.J. Spelling Correction for Search Engine Queries. In Advances in Natural Language Processing, Proceedings of the International Conference on Natural Language Processing, EsTAL 2004, Alicante, Spain, 20–22 October 2004; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Afli, H.; Qiu, Z.; Way, A.; Sheridan, P. Using SMT for OCR Error Correction of Historical Texts; Language Resources and Evaluation; European Language Resources Association (ELRA): Paris, France, 2016. [Google Scholar]
- Huang, L.; Li, J.; Jiang, W.; Zhang, Z.; Chen, M.; Wang, S.; Xiao, J. PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 5958–5967. [Google Scholar]
- Hong, Y.; Yu, X.; He, N.; Liu, N.; Liu, J. FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based on DAE-Decoder Paradigm. In Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Toronto, ON, Canada, 2019. [Google Scholar]
- Zhang, S.; Huang, H.; Liu, J.; Li, H. Spelling Error Correction with Soft-Masked BERT. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Cheng, X.; Xu, W.; Chen, K.; Jiang, S.; Wang, F.; Wang, T.; Chu, W.; Qi, Y. SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Liu, S.; Yang, T.; Yue, T.; Zhang, F.; Wang, D. PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 2991–3000. [Google Scholar]
- Xu, H.-D.; Li, Z.; Zhou, Q.; Li, C.; Wang, Z.; Cao, Y.; Huang, H.; Mao, X.-L. Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021. [Google Scholar]
- Liu, C.-L.; Lai, M.-H.; Chuang, Y.-H.; Lee, C.-Y. Visually and Phonologically Similar Characters in Incorrect Simplified Chinese Words. In Coling 2010: Posters; Coling 2010 Organizing Committee: Beijing, China, 2010; pp. 739–747. [Google Scholar]
- Wang, B.; Che, W.; Wu, D.; Wang, S.; Hu, G.; Liu, T. Dynamic Connected Networks for Chinese Spelling Check. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021. [Google Scholar]
- Sun, Z.; Li, X.; Sun, X.; Meng, Y.; Ao, X.; He, Q.; Wu, F.; Li, J. ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021. [Google Scholar]
- Guo, Z.; Ni, Y.; Wang, K.; Zhu, W.; Xie, G. Global Attention Decoder for Chinese Spelling Error Correction. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021. [Google Scholar]
- Li, Y.; Zhou, Q.; Li, Y.; Li, Z.; Liu, R.; Sun, R.; Wang, Z.; Li, C.; Cao, Y.; Zheng, H.-T. The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking. In Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Toronto, ON, Canada, 2022. [Google Scholar]
- Zhu, C.; Ying, Z.; Zhang, B.; Mao, F. MDCSpell: A multi-task detector-corrector framework for Chinese spelling correction. In Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 1244–1253. [Google Scholar]
- Zhang, R.; Pang, C.; Zhang, C.; Wang, S.; He, Z.; Sun, Y.; Wu, H.; Wang, H. Correcting Chinese spelling errors with phonetic pre-training. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 2250–2261. [Google Scholar]
- Li, J.; Wang, Q.; Mao, Z.; Guo, J.; Yang, Y.; Zhang, Y. Improving Chinese Spelling Check by Character Pronunciation Prediction: The Effects of Adaptivity and Granularity. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 4275–4286. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Zhang, D.; Li, S.; Zhu, Q.; Zhou, G. Effective Sentiment-relevant Word Selection for Multi-modal Sentiment Analysis in Spoken Language. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Agrawal, A.; Lu, J.; Antol, S.; Mitchell, M.; Zitnick, L.C.; Batra, D.; Parikh, D. VQA: Visual Question Answering. Int. J. Comput. Vision 2016, 123, 2425–2433. [Google Scholar] [CrossRef]
- Chao, W.L.; Hu, H.; Sha, F. Being Negative but Constructively: Lessons Learnt from Creating Better Visual Question Answering Datasets. In North American Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Toronto, ON, Canada, 2018. [Google Scholar]
- Hitschler, J.; Riezler, S. Multimodal Pivots for Image Caption Translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Barrault, L.; Bougares, F.; Specia, L.; Lala, C.; Elliott, D.; Frank, S. Findings of the Third Shared Task on Multimodal Machine Translation. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Belgium, Brussels, 27 July 2018. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-training of Generic Visual-Linguistic Representations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D.; Zhou, M. Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training. arXiv 2019, arXiv:1908.06066. [Google Scholar]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Meng, Y.; Wu, W.; Wang, F.; Li, X.; Nie, P.; Yin, F.; Li, M.; Han, Q.; Sun, X.; Li, J. Glyce: Glyph-vectors for Chinese Character Representations. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wei, X.; Huang, J.; Yu, H.; Liu, Q. PTCSpell: Pre-trained Corrector Based on Character Shape and Pinyin for Chinese Spelling Correction. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 6330–6343. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mobahi, H.; Farajtabar, M.; Bartlett, P.L. Self-Distillation Amplifies Regularization in Hilbert Space. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Zhang, X.; Yan, H.; Yu, S.; Qiu, X. Sdcl: Self-distillation contrastive learning for Chinese spell checking. arXiv 2022, arXiv:2210.17168. [Google Scholar]
- Liu, S.; Song, S.; Yue, T.; Yang, T.; Cai, H.; Yu, T.; Sun, S. CRASpell: A contextual typo robust approach to improve Chinese spelling correction. In Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 3008–3018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Wu, S.H.; Liu, C.L.; Lee, L.H. Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013. In Proceedings of the International Joint Conference on Natural Language Processing. Asian Federation of Natural Language Processing, Nagoya, Japan, 14–19 October 2013. [Google Scholar]
- Yu, L.-C.; Lee, L.-H.; Tseng, Y.-H.; Chen, H.H. Overview of SIGHAN 2014 Bake-off for Chinese Spelling Check. In Proceedings of the Cips-sighan Joint Conference on Chinese Language Processing, Wuhan, China, 20–21 October 2014. [Google Scholar] [CrossRef]
- Tseng, Y.-H.; Lee, L.-H.; Chang, L.-P.; Chen, H.H. Introduction to SIGHAN 2015 Bake-off for Chinese Spelling Check. In Proceedings of the 8th SIGHAN Workshop on Chinese Language Processing (SIGHAN’15), Beijing, China, 30–31 July 2015. [Google Scholar]
- Wang, D.; Song, Y.; Li, J.; Han, J.; Zhang, H. A hybrid approach to automatic corpus generation for chinese spelling check. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2517–2527. [Google Scholar]
- Li, P. uChecker: Masked Pretrained Language Models as Unsupervised Chinese Spelling Checkers. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2812–2822. [Google Scholar]
- He, Z.; Zhu, Y.; Wang, L.; Xu, L. UMRSpell: Unifying the Detection and Correction Parts of Pre-trained Models towards Chinese Missing, Redundant, and Spelling Correction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 10238–10250. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Detection-Level | Correction-Level | Char-Level | |||||
|---|---|---|---|---|---|---|---|---|---|
| D-P | D-R | D-F | C-P | C-R | C-F | D-F | C-F | ||
| SIGHAN13 | GAD | 85.7 | 79.5 | 82.5 | 84.9 | 78.7 | 81.5 | 87.6 | 93.5 |
| DCN | 86.8 | 79.6 | 83.0 | 84.7 | 77.7 | 81.0 | 85.2 | 86.4 | |
| REALISE | 88.6 | 82.5 | 85.4 | 87.2 | 81.2 | 84.1 | 86.1 | 88.4 | |
| uChecker | 75.4 | 73.4 | 74.4 | 72.6 | 70.8 | 71.7 | - | - | |
| MDCSpell | 89.1 | 78.3 | 83.4 | 87.5 | 76.8 | 81.8 | - | - | |
| ECOPE | 87.2 | 81.7 | 84.4 | 86.1 | 80.6 | 83.3 | - | - | |
| UMRSpell | 83.0 | 73.6 | 78.0 | 80.0 | 71.0 | 75.2 | 84.9 | 96.4 | |
| SPMSpell (our) | 87.7 | 83.7 | 85.6 | 86.9 | 82.8 | 84.6 | 92.1 | 95.3 | |
| SIGHAN14 | GAD | 66.6 | 71.8 | 69.1 | 65.0 | 70.1 | 67.5 | 82.9 | 87.6 |
| DCN | 67.4 | 70.4 | 68.9 | 65.9 | 68.7 | 67.2 | 78.9 | 86.2 | |
| REALISE | 67.8 | 71.5 | 69.6 | 66.3 | 70.0 | 68.1 | 78.5 | 80.1 | |
| uChecker | 61.7 | 61.5 | 61.6 | 57.6 | 57.5 | 57.6 | - | - | |
| MDCSpell | 70.2 | 68.8 | 69.5 | 69.0 | 67.7 | 68.3 | - | - | |
| ECOPE | 65.8 | 69.0 | 67.4 | 63.7 | 66.9 | 65.3 | - | - | |
| UMRSpell | 69.0 | 56.6 | 62.2 | 63.9 | 57.2 | 60.4 | 73.2 | 93.3 | |
| SPMSpell (our) | 68.6 | 73.5 | 70.5 | 67.0 | 71.2 | 69.0 | 81.5 | 89.0 | |
| SIGHAN15 | GAD | 75.6 | 80.4 | 77.9 | 73.2 | 77.8 | 75.4 | 88.2 | 90.1 |
| DCN | 77.1 | 80.9 | 79.0 | 74.5 | 78.2 | 76.3 | 85.0 | 84.9 | |
| REALISE | 77.3 | 81.3 | 79.3 | 75.9 | 79.9 | 77.8 | 87.4 | 86.2 | |
| uChecker | 75.4 | 72.0 | 73.7 | 70.6 | 67.3 | 68.9 | - | - | |
| MDCSpell | 80.8 | 80.6 | 80.7 | 78.4 | 78.2 | 78.3 | - | - | |
| ECOPE | 78.2 | 82.3 | 80.2 | 76.6 | 80.4 | 78.4 | - | - | |
| UMRSpell | 77.2 | 72.2 | 75.0 | 69.3 | 64.8 | 67.0 | 83.0 | 91.5 | |
| SPMSpell (our) | 81.7 | 85.6 | 83.6 | 79.4 | 83.4 | 81.3 | 88.3 | 92.8 | |
| Dataset | Model | Detection-Level | Correction-Level | Char-Level | |||||
|---|---|---|---|---|---|---|---|---|---|
| D-P | D-R | D-F | C-P | C-R | C-F | D-F | C-F | ||
| SIGHAN15 | SPMSpell | 81.7 | 85.6 | 83.6 | 79.4 | 83.4 | 81.3 | 88.3 | 92.8 |
| w/o PP | 79.0 | 82.5 | 81.0 | 77.4 | 80.6 | 79.4 | 87.0 | 90.9 | |
| w/o PP | 80.1 | 82.3 | 81.2 | 78.0 | 80.2 | 79.1 | 87.1 | 91.2 | |
| w/o PP | 80.4 | 84.3 | 82.3 | 77.5 | 80.5 | 79.5 | 87.1 | 90.3 | |
| Dataset | Model | Detection-Level | Correction-Level | ||||
|---|---|---|---|---|---|---|---|
| D-P | D-R | D-F | C-P | C-R | C-F | ||
| SIGHAN13 | SPMSpell (BERT) | 85.0 | 77.0 | 80.8 | 83.0 | 75.2 | 78.9 |
| SPMSpell (REALISE) | 87.6 | 82.5 | 85.4 | 87.2 | 81.2 | 84.1 | |
| SPMSpell (ChineseBERT) | 87.7 | 83.7 | 85.6 | 86.9 | 82.8 | 84.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Liu, F.; Liu, J.; Duan, J.; Wang, H. Self-Distillation and Pinyin Character Prediction for Chinese Spelling Correction Based on Multimodality. Appl. Sci. 2024, 14, 1375. https://doi.org/10.3390/app14041375
He L, Liu F, Liu J, Duan J, Wang H. Self-Distillation and Pinyin Character Prediction for Chinese Spelling Correction Based on Multimodality. Applied Sciences. 2024; 14(4):1375. https://doi.org/10.3390/app14041375
Chicago/Turabian StyleHe, Li, Feng Liu, Jie Liu, Jianyong Duan, and Hao Wang. 2024. "Self-Distillation and Pinyin Character Prediction for Chinese Spelling Correction Based on Multimodality" Applied Sciences 14, no. 4: 1375. https://doi.org/10.3390/app14041375