
Analysis of Urban Residents’ Travelling Characteristics and Hotspots Based on Taxi Trajectory Data

Abstract
:1. Introduction
- (1)
- Impact of environmental factors on commuting: This stream of research underscores how changing weather and seasonal variations influence commuter behavior. Feng et al. utilized Harbin’s subway data to analyze the effect of adverse weather on public transportation, creating the WL long short-term memory model for forecasting commuter traffic during inclement weather conditions like rain and snow, thus assessing the impact on residents’ preference for rail transit [4]. Similarly, Lin et al. conducted a study in the Greater Bay Area of Guangdong, Hong Kong, and Macau. They used the mixed geographically weighted regression (MGWR) model to investigate how various weather conditions, such as rain, snow, wind, and increasing temperatures, impact urban commuting patterns both immediately and over time. Their results shed light on how these meteorological changes influence travel behaviors in different geographic areas [5].
- (2)
- Behavioral pattern studies for travel forecasting: Focusing on the analysis and prediction of residents’ travel characteristics, this type of research is crucial for enhancing public transit efficiency and offering customized travel services. Nithin et al. employed non-negative tensor decomposition (NTD) methods to visually represent the travel patterns of bus passengers in different areas of Davangere City over various time periods, including hours, days, and months. This approach made it easier to analyze how the mobility patterns of residents in the same areas changed across different seasons and allowed them to predict the spatial and temporal variations in resident movements in the near future [6]. Likewise, Ayad et al. leveraged advanced deep recurrent neural network techniques, which were trained on extensive resident travel data, to effectively capture the evolving and sequential characteristics of urban traffic flow. This effort resulted in the creation of a highly accurate urban traffic model, achieving an impressive accuracy rate of up to 95% [7].
- (3)
- Trajectory data mining and personalized travel data collection: Traditionally, when mining trajectory data for transportation analysis, researchers relied on data from questionnaires and fixed-route buses, which failed to efficiently capture personalized travel information of residents. However, with the rapid advancement of network technology and the public transportation industry in recent years, it has become more convenient to collect personalized travel data from sources such as taxi global navigation satellite system (GNSS) trajectory data, residents’ mobile signaling data, and social media data [8,9]. In one study, Zhu et al. used shared bicycle travel data of residents and introduced the time series weighted regression (TSWR) model to address the challenge of sparse statistical data when making long-term predictions. They enhanced the model’s accuracy by over 35% by incorporating the rule-based adjustment optimization (RAO) method to refine nonlinear components, considering various factors, compared with using the RAO method alone [10]. In another study, Hu et al. developed the position opportunity selection (POS) model by taking into account both the population and quantity of points of interest (POI). They obtained residents’ travel data in Harbin through the Unicom Smart Footprint platform. By comparing the POS model’s analysis and predictions of residents’ travel activities with actual behaviors, they found that the POS model’s results were generally consistent with real-world observations [11].
- (1)
- The HDBSCAN algorithm, with high efficiency in processing noise points, accurately identifies trajectory point clusters and noise points in taxi trajectory data on both weekdays and weekends. It generates three distinct peak periods in the morning, middle of the day, and evening based on different time intervals for trajectory clustering.
- (2)
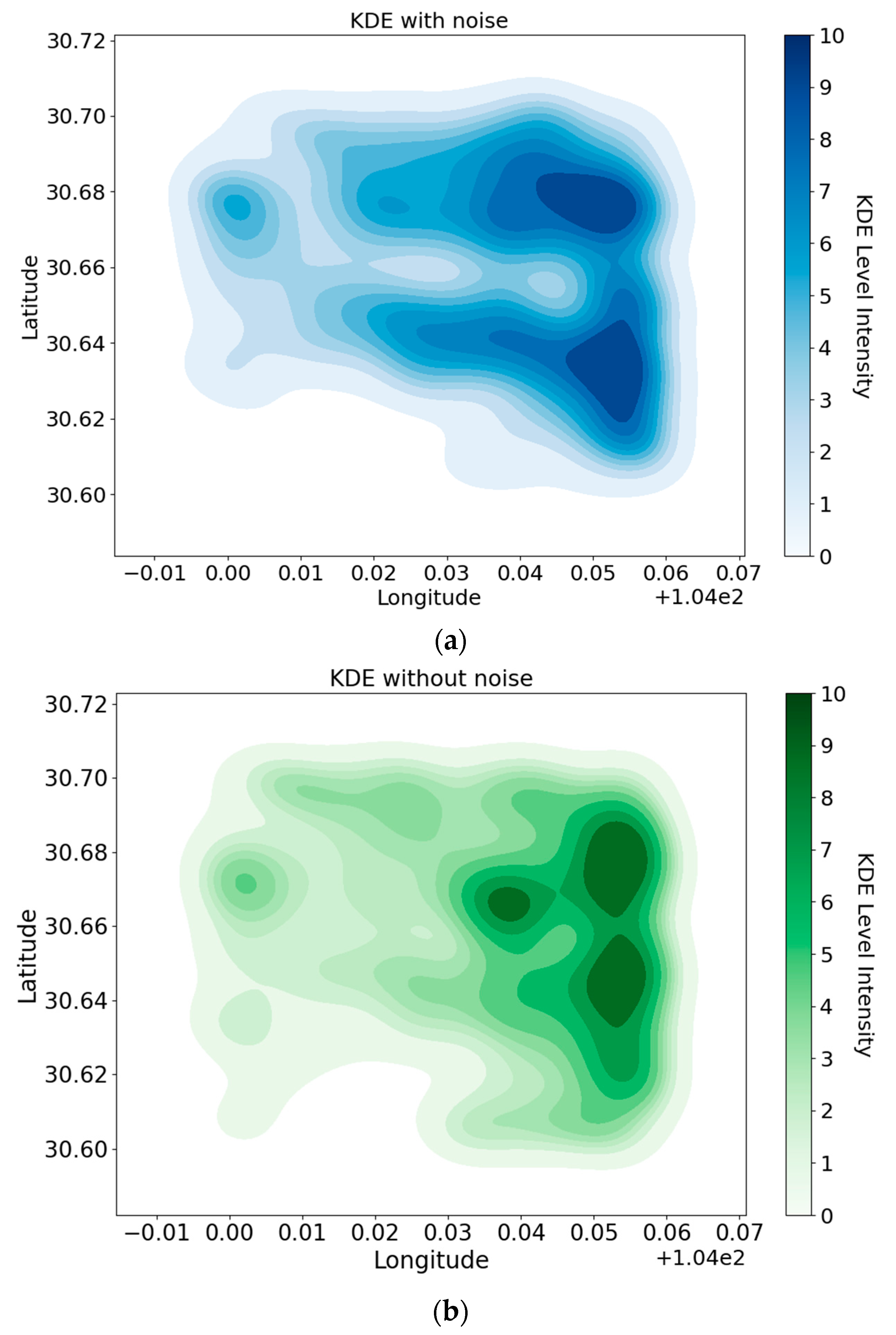
- Building upon the clustering results, it eliminates noise points outside the trajectory data clusters and conducts kernel density analysis. This leads to the creation of a more accurate heat map compared with single kernel density analysis. It also identifies hotspot areas where residents frequently travel.
- (3)
- Using the fusion algorithm, hidden Markov model road matching and hotspot detection were performed to determine hotspot paths. The chi-square test was employed to calculate the p-value for residents’ travel hotspot areas and hotspot paths during various peak hours on weekdays, resulting in a value of 0.023, which is less than 0.05. This demonstrates a significant correlation between the two.
2. Materials and Methods
2.1. Preprocessing of Trajectory Data
- (1)
- Deletion of default and duplicate values: Track data are examined segmentally to remove rows with missing attributes and duplicate records. Table 1 illustrates data defaults (first row) and typical duplicate records (second and third rows). Furthermore, the absence of data in any column can be referred to as a default value.
- (2)
- Removal of redundant values: Trajectory data often accumulate redundant points when taxis stop at gas stations, shops, or traffic lights or in traffic jams. To streamline data processing, a novel speed attribute was introduced for calculating taxi speeds using timestamp intervals. A speed threshold was established to eliminate redundant data, setting minimum and maximum speed limits at 6 and 16.7 m/s, respectively. These limits were chosen based on the speed restrictions of various roads in the study area. Any data not falling within this speed range will be discarded.
- (3)
- (4)
- Deletion of outliers: Data representing abnormal taxi trajectories, such as unchanged passenger status for an extended period, distances of over 2 km between adjacent points, or frequent, irregular changes in taxi passenger status over a short duration, are identified and removed [26].
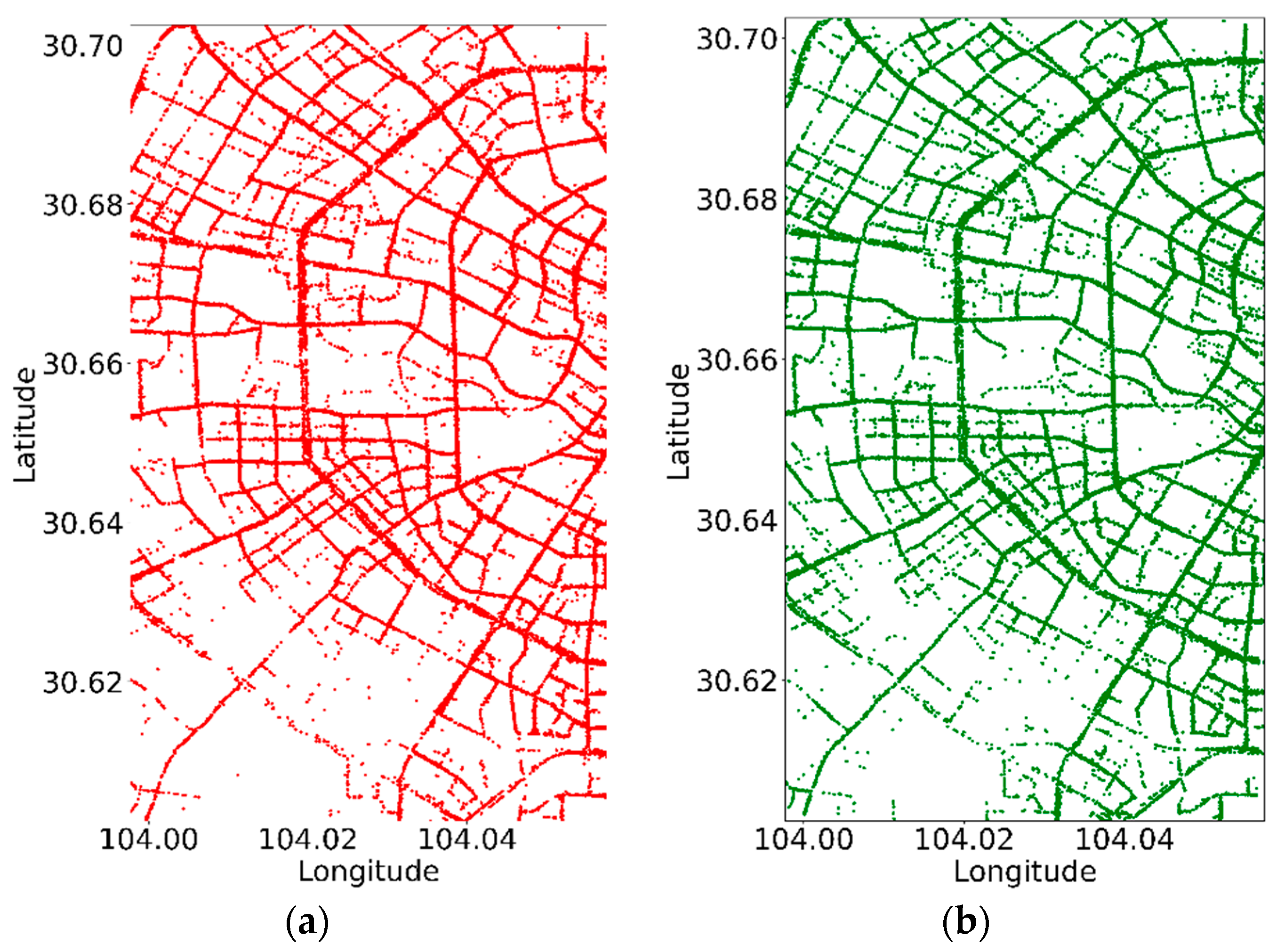
2.2. Extraction and Visualization of Passenger Pick-Up and Drop-Off Points
- (1)
- The taxi begins its operation with an initial status of 0.
- (2)
- The taxi picks up passenger A, changing its status to 1, marking the starting point O1.
- (3)
- After traveling a distance, passenger A disembarks, and the status reverts to 0, indicating the endpoint D1.
- (4)
- After driving for a certain distance, the taxi then picks up passenger B, changing the status back to 1, marking another starting point O2.
- (5)
- Upon reaching the destination, passenger B disembarks, and the status returns to 0, marking the endpoint D2.
- (6)
- This process repeats throughout the taxi’s operational day.

2.3. Road Network Matching
- (1)
- Calculating transition probabilities: This step involves computing the transition probabilities between taxi trajectory points and multiple candidate paths on the map:
- (2)
- Observation probability calculation: Here, the observation probability between the taxi trajectory points and multiple corresponding paths is determined:
- (3)
- Maximum probability matching: This step calculates the maximum probability for aligning the taxi trajectory points with the map paths:
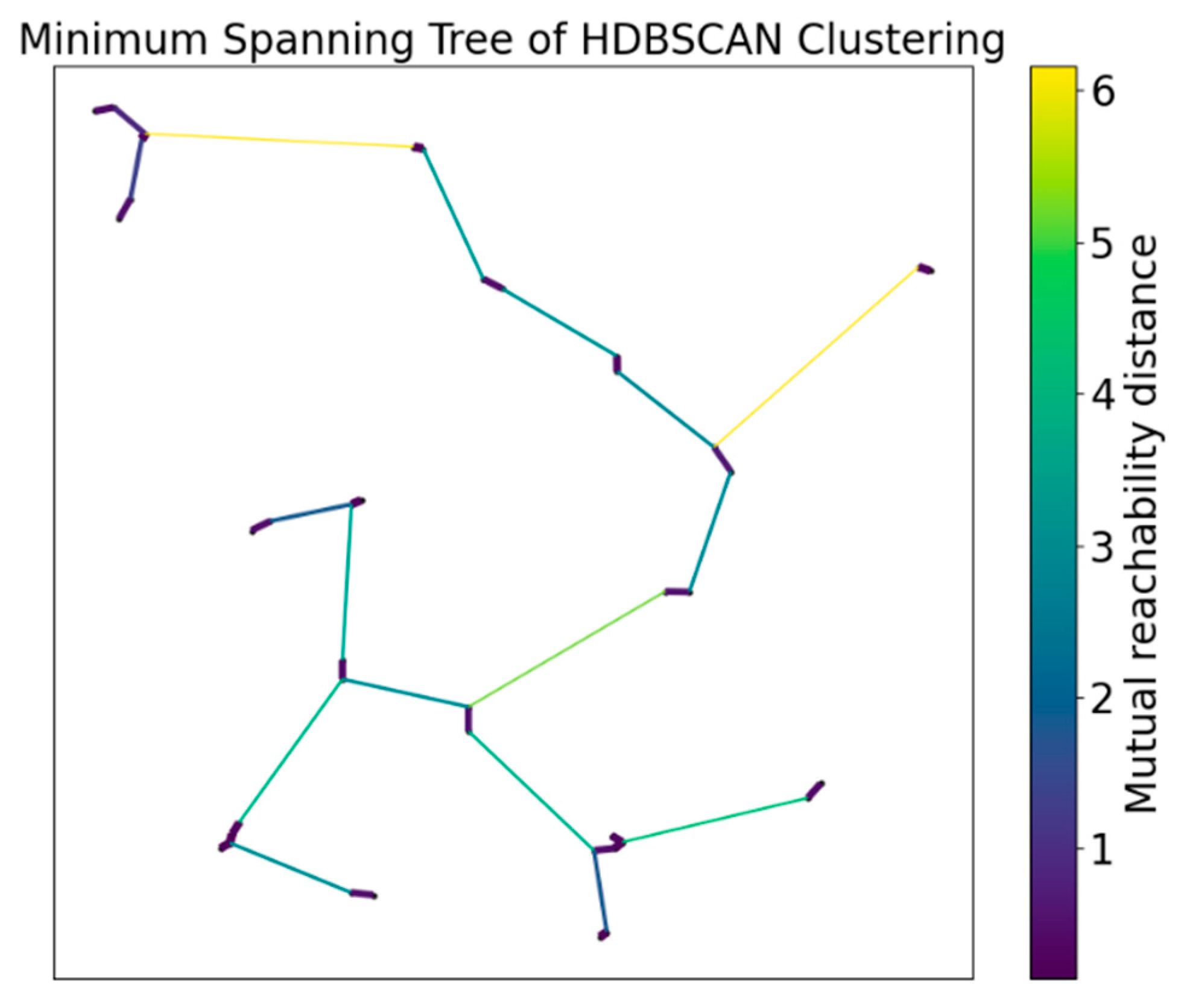
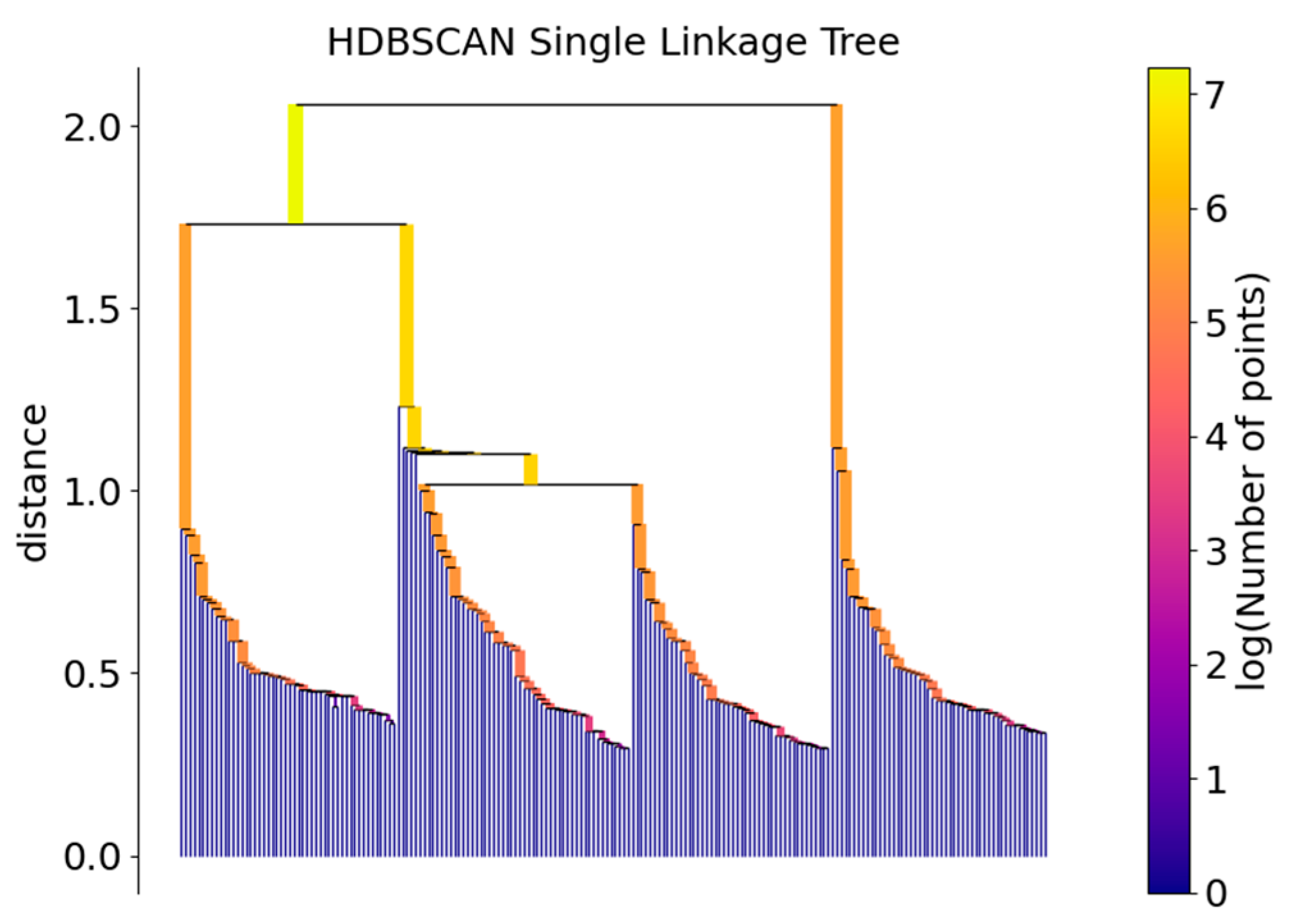
2.4. HDBSCAN Algorithm Cluster Analysis
- (1)
- Matrix construction based on point distance.
- (2)
- Creation of a distance-weighted graph and minimum spanning tree (MST).
- (3)
- Creation of an interconnectivity diagram.
- (4)
- Construction of hierarchical clustering tree.
- (5)
- Simplification of the clustering tree hierarchy.
- (6)
- Optimal clustering selection.
2.5. Kernel Density Analysis of Trajectory Points
- (1)
- Kernel function: This function assigns weights to each data point, creating a smooth distribution around them and estimating a continuous probability density function from discrete data. In this experiment, the Gaussian kernel, resembling a normal distribution curve and suitable for most scenarios, was used. The mathematical expression of the Gaussian kernel is shown in Equation (5):
- (2)
- Bandwidth selection: Bandwidth is a crucial parameter in KDE as it dictates the smoothness of the kernel function. An overly large bandwidth can result in overfitting, where the model excessively conforms to the data set. Conversely, a small bandwidth can lead to underfitting, failing to capture the underlying trends in the data. Therefore, choosing an appropriate bandwidth value is essential for accurate KDE.
- (3)
- KDE calculation formula: The mathematical formulation of KDE is outlined in Equation (6):
2.6. Chi-Square Test
3. Experiments, Results, and Analysis
3.1. Data Sources and Structure
3.2. Analysis of Residents’ Travel Time Characteristics
3.2.1. Weekday Travel Demand Analysis
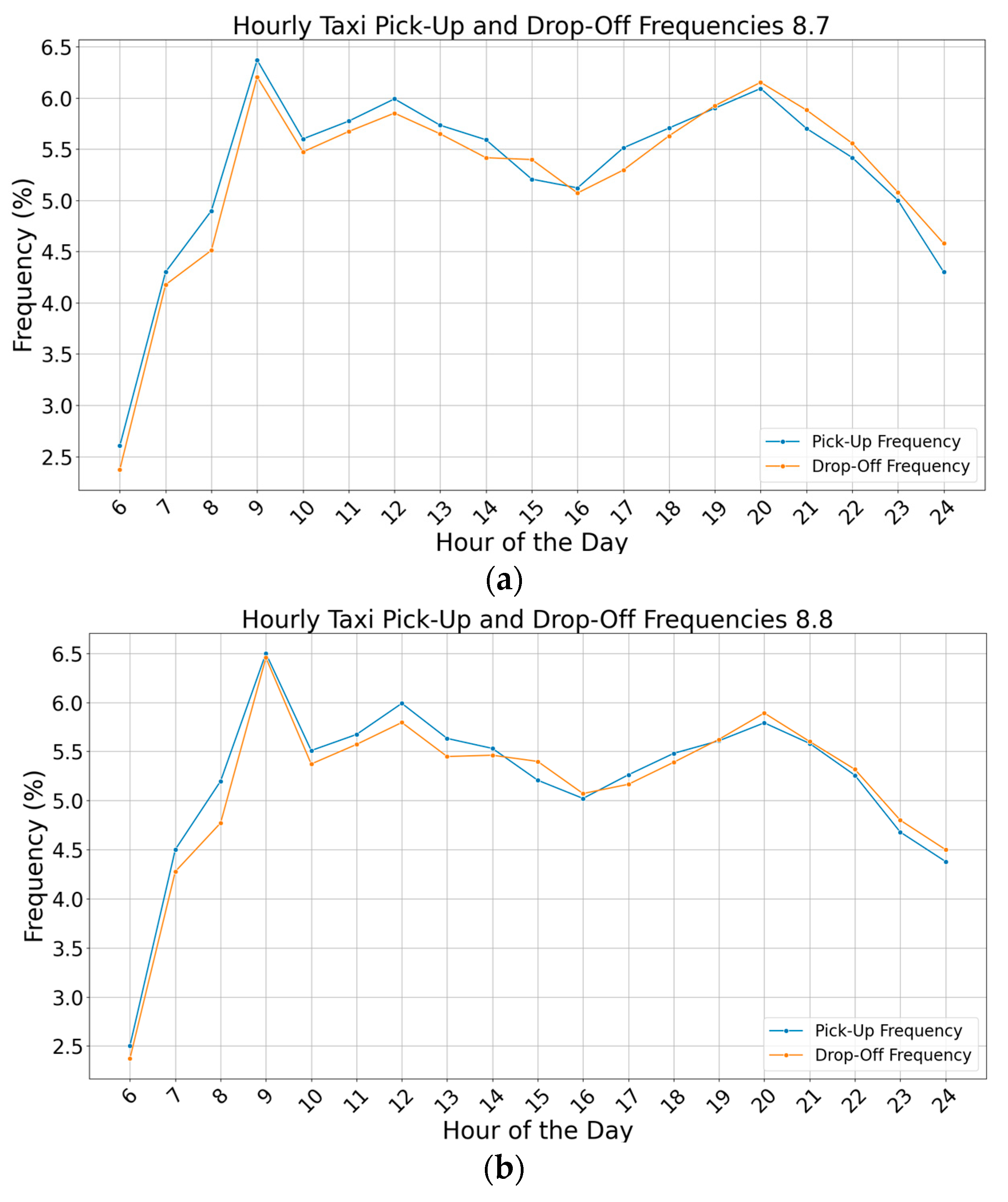
- (1)
- Travel volume experiences a marked surge after 6:00, reaching its zenith at around 9:00. This surge is attributed to residents commuting to work or school, creating a pronounced morning peak in taxi usage.
- (2)
- There is a minor increase in the number of taxi passengers after 11:00, reaching its highest point at around noon, and then gradually decreasing after 13:00. This pattern corresponds to lunch breaks at workplaces and schools, leading to increased taxi usage as residents travel to dine and rest.
- (3)
- There is a notable decrease in taxi passenger numbers during the evening, particularly between 14:00 and 17:00. This reduction is likely due to evening rush hour congestion, impacting the efficiency of taxi services.
- (4)
- Another peak in taxi usage is observed between 19:00 and 21:00, coinciding with residents engaging in social and entertainment activities after work or school.
- (5)
- Taxi passenger volume gradually decreases after 23:00, aligning with residents’ typical bedtime routines on weekdays.
3.2.2. Weekend Travel Demand Analysis
- (1)
- On weekends, taxi usage increases gradually after 6:00, with a slower ascent around 9:00 and reaching a morning peak at 10:00. The delayed start is attributed to the additional rest time available to residents on weekends.
- (2)
- After 10:00, there is a slight decline in passenger volume, followed by a rebound after 11:00, peaking again at noon. This pattern reflects residents’ leisure activities, such as visiting entertainment spots and dining venues and shopping during their off days.
- (3)
- A subdued peak forms at around 14:00, followed by another gradual increase at around 15:00, as residents opt to rest at home or continue their activities in entertainment or shopping venues.
- (4)
- A sharp rise in taxi usage is noted at around 19:00, with the number of passengers reaching an evening peak at 20:00. This increase is linked to residents visiting entertainment venues or dining out, followed by a return home after a day of leisure activities. These travel patterns on weekends align well with the typical leisure and rest behaviors of residents.
3.2.3. Comparative Analysis
- (1)
- On weekdays, peak hours are predominantly in the time periods of 7:00–9:00, 11:00–13:00, and 19:00–21:00. The uniformity in residents’ travel purposes on these days, primarily for work or school, results in more regular and concentrated traffic flow. Time-bound obligations, such as office check-ins and school start times, contribute to this pattern.
- (2)
- Weekends exhibit more varied peaks and troughs in passenger volume, and the timing of taxi usage tends to be later compared with weekdays. This variation stems from the lack of uniform travel purposes on weekends, giving residents the freedom to choose their destinations and travel times without strict time constraints. Consequently, weekend travel is characterized by more rest time and flexibility.
- (3)
- Combining the findings from Section 3.2.1 and Section 3.2.2 with Figure 12, it is observed that weekday travel times predominantly range from 19 to 40 min, while weekend travel times are mostly between 16 and 35 min. The longer travel times on weekdays could be attributed to longer commutes to work or school. In contrast, weekend travels are typically shorter city trips. Additionally, there are some variations in travel times, influenced by factors such as the proximity of destinations to residential areas or traffic conditions. On weekdays, shorter travel times might occur when schools or workplaces are closer to homes, while traffic congestion could extend travel durations. On weekends, travel times vary due to the flexible nature of leisure travel, but they generally represent shorter distances.
3.3. Mining Hotspots in Residents’ Travel Space
3.3.1. Hotspot Area Identification
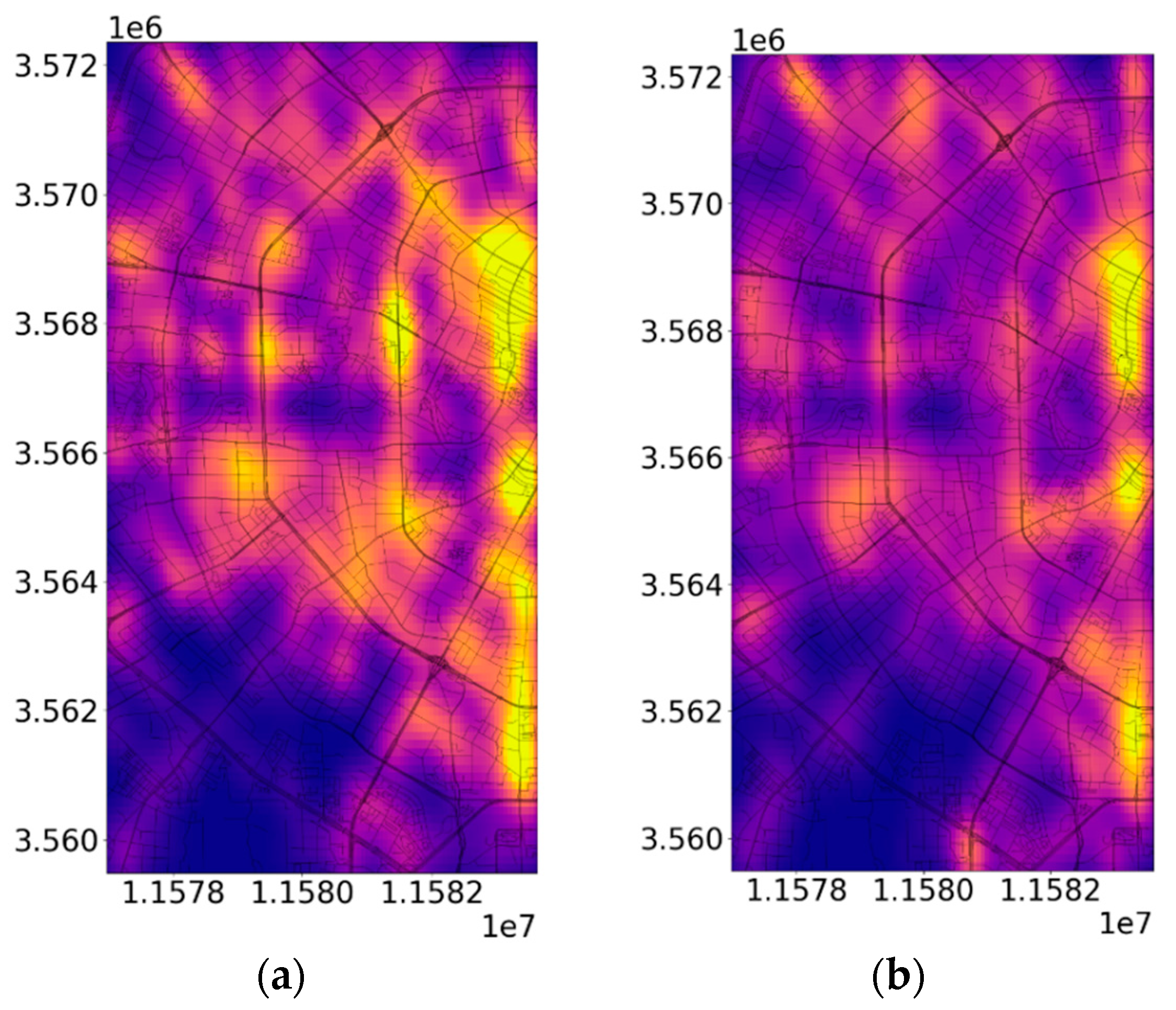
- (1)
- The heat map for the 7:00–9:00 time period, as shown in Figure 13.
- (2)
- The heat map for the 11:00–13:00 time period, presented in Figure 14.
- (3)
- During the evening peak hours of 19:00–21:00, the heat map, as illustrated in Figure 15.
3.3.2. Hotspot Path Mining
- (1)
- Road network matching: Trajectory data points are spatially matched to the nearest road network segment using the hidden Markov model method. This step associates each trajectory point with road segments, providing related information like road name and vehicle passenger status.
- (2)
- Hotspot detection: The geographical coordinates in the trajectory data are mapped to a discrete spatial grid for space discretization. Kernel density analysis is then applied to calculate the density of pick-up and drop-off points in each grid, identifying high-density areas and streets.
- (3)
- Road extraction: This involves determining the geographical coordinates of the start and end points of hotspot paths, followed by path searching using the Dijkstra algorithm based on passenger volume, and finally recording and exporting the generated paths.
- (4)
- Chi-square test: A crosstab is created based on hotspot areas and paths, and chi-square statistics and p-values are calculated under the null hypothesis. A p-value below 0.05 suggests a significant relationship between hotspot areas and paths.
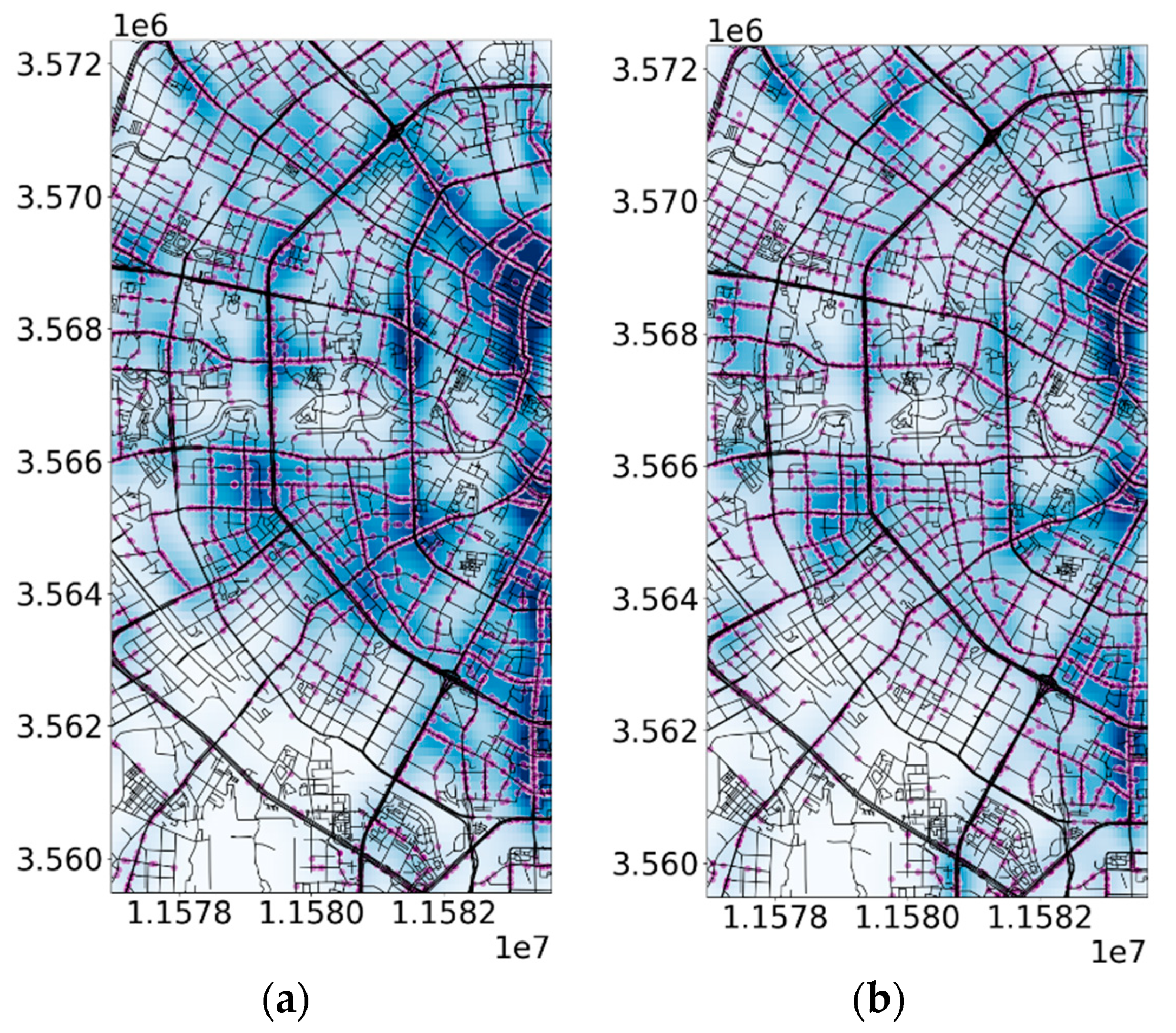
- (1)
- During the 7:00–9:00 time period, as shown in Figure 16.
- (2)
- The visualization of hotspots for pick-up and drop-off points during the 11:00–13:00 time period is displayed in Figure 17.
- (3)
- In Figure 18, we can observe the visualization of hotspots for pick-up and drop-off points during the 19:00–21:00 time period.
- (4)
- Information regarding the geographical boundaries of hotspot areas and the paths commonly taken for pick-up and drop-off activities during the time intervals of 7:00–9:00, 11:00–13:00, and 19:00–21:00 was gathered. A cross tabulation table that combines hotspot areas and paths for residents’ travel was created, as presented in Table 3.
4. Related Work
- (1)
- Use the clustering algorithm to mine hotspot areas.
- (2)
- Improve the clustering algorithm to improve the clustering accuracy of trajectory data.
- (3)
- Analyze residents’ travel mechanisms by mining travel hotspots
- (4)
- Solve the unbalanced supply and demand of transportation resources through travel characteristics.
5. Conclusions
- (1)
- Mathematical statistical analyses, individual assessments, and comparative examinations of taxi pick-up and drop-off point traffic volumes during distinct time intervals on weekdays and weekends were conducted. The investigation reveals that on weekdays, residents’ travel times range from 19 to 40 min, while on weekends, the average travel time falls within the range of 16 to 35 min. Furthermore, it is observed that the morning and afternoon peak hours for residents’ travel on weekdays occur earlier compared with those on weekends.
- (2)
- A fusion algorithm was used to cluster OD points on both weekdays and weekends, resulting in spatially continuous clusters. Kernel density analysis provided an accurate heat map of pick-up and drop-off points after eliminating the noise influence, identifying travel hotspots. Different functional area travel characteristics were observed: During the morning peak (7:00–9:00), taxis are frequently used in residential areas and transportation hubs, with drop-offs common at schools, commercial buildings, and government agencies. In the afternoon peak (11:00–13:00), travel shifts from schools, businesses, and government locations to dining and entertainment areas. In the evening peak (19:00–21:00), pick-up and drop-off points are widely distributed, moving from schools, commercial zones, and residential areas to dining streets, shopping plazas, and entertainment venues.
- (3)
- Utilizing the hidden Markov model approach, trajectory points were matched with the road network. Hotspot detection was subsequently conducted based on these hotspot areas, resulting in the identification of hotspot paths. Through the application of the chi-square test method, it was determined that the p-value from the chi-square test is 0.023, which is less than the conventional significance threshold of 0.05. This statistical analysis takes into account spatial changes in hotspot areas and the count of hotspot paths across different time periods. The result provides strong evidence to support the assertion that hotspot areas and hotspot paths exhibit a significant relationship.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, S.; Zhang, J.; Chen, X.; Liao, G. Identification of Urban Functional Zones Using Taxi Temporal Data. J. Jilin Univ. (Eng. Technol. Ed.) 2023, 1–10. [Google Scholar] [CrossRef]
- Luo, Y. Analysis of Urban Residents’ Spatio-Temporal Characteristics of Travel Based on Chongqing Taxi Trajectory Data. Jiangxi Sci. 2023, 41, 895–901. [Google Scholar]
- Yu, Q.; Wang, Z.; Song, Y.; Shen, X.; Zhang, H. Potential and flexibility analysis of electric taxi fleets V2G system based on trajectory data and agent-based modeling. Appl. Energy 2024, 355, 122323. [Google Scholar] [CrossRef]
- Feng, S.; Liu, H.; Li, L. Prediction model of rail transit passenger flow in rain and snow weather. J. Harbin Inst. Technol. 2022, 54, 1–6. [Google Scholar]
- Lin, P.; Hong, Y.; He, Y.; Pei, M. Advancing and lagging effects of weather conditions on intercity traffic volume: A geographically weighted regression analysis in the Guangdong-Hong Kong-Macao Greater Bay Area. Int. J. Transp. Sci. Technol. 2024, 13, 58–76. [Google Scholar] [CrossRef]
- Shanthappa, N.K.; Mulangi, R.H.; Manjunath, H.M. The Spatiotemporal Patterns of Bus Passengers: Visualisation and Evaluation using Non-negative Tensor Decomposition. J. Geovisualization Spat. Anal. 2023, 7, 9. [Google Scholar] [CrossRef]
- Ismaeel, A.G.; Janardhanan, K.; Sankar, M.; Natarajan, Y.; Mahmood, S.N.; Alani, S.; Shather, A.H. Traffic Pattern Classification in Smart Cities Using Deep Recurrent Neural Network. Sustainability 2023, 15, 14522. [Google Scholar] [CrossRef]
- Cai, Y.; Li, B.; Niu, Y.; Wang, Y. Recognition of Taxi Operation Mode and Benefit Analysis Based on Trajectory Data. Geomat. Spat. Inf. Technol. 2023, 48, 146–150. [Google Scholar]
- Bin Asad, K.M.; Yuan, Y. The impact of scale on extracting urban mobility patterns using texture analysis. Comput. Urban Sci. 2023, 3, 33. [Google Scholar] [CrossRef]
- Lin, H.; He, Y.; Li, S.; Liu, Y. Insights into Travel Pattern Analysis and Demand Prediction: A Data-Driven Approach in Bike-Sharing Systems. J. Transp. Eng. Part A Syst. 2024, 150, 04023132. [Google Scholar] [CrossRef]
- Hu, B.; Liu, X. Prediction Model for Residents Travelling OD in Urban Areas Based on Mobile Phone Signaling Data. J. Transp. Syst. Eng. Inf. Technol. 2023, 23, 296–306. [Google Scholar]
- Jin, J.; Liu, C.; Liu, Y. Research on Big Data Analysis of Taxi Trajectory Based on Machine Learning. Comput. Knowl. Technol. 2023, 19, 63–66. [Google Scholar]
- Xiao, H.; Bi, J.; Wang, T. Research on Spatial Analysis of Urban Taxi Services Based on Trajectory Data. J. Spatio-Temporal Inf. Sci. 2023, 30, 95–101. [Google Scholar]
- Bao, Y.; Huang, Z.; Gong, X.; Zhang, Y.; Yin, G.; Wang, H. Optimizing segmented trajectory data storage with HBase for improved spatio-temporal query efficiency. Int. J. Digit. Earth 2023, 16, 1124–1143. [Google Scholar] [CrossRef]
- He, Q. Research on Intersection Flow Prediction and Taxi Routing Recommendation Algorithm Based on Spatio-temporal Data. Southwest Univ. Sci. Technol. 2023. [Google Scholar] [CrossRef]
- Zou, T. Visual Recommendation of Urban Mixed Traffic Based on Multilayer Complex Networks. Southwest Univ. Sci. Technol. 2023, 1–56. [Google Scholar]
- Liu, T.; Cheng, G.; Yang, J. Multi-Scale Recursive Identification of Urban Functional Areas Based on Multi-Source Data. Sustainability 2023, 15, 13870. [Google Scholar] [CrossRef]
- Mepparambath, R.M.; Soh, Y.S.; Jayaraman, V.; Tan, H.E.; Ramli, M.A. A novel modelling approach of integrated taxi and transit mode and route choice using city-scale emerging mobility data. Transp. Res. Part A Policy Pract. 2023, 170, 103615. [Google Scholar] [CrossRef]
- Luo, L.; Zhu, X.; Sun, L.; Yao, L.; Liu, H. Mining Urban Residents’ Travel Characteristics Based on Taxi Trajectory Data. J. Transp. Eng. 2023, 23, 114–121. [Google Scholar]
- Yu, H.; Guo, X.; Luo, X.; Bian, W.; Zhang, T. Construct Trip Graphs by Using Taxi Trajectory Data. Data Sci. Eng. 2023, 8, 1–22. [Google Scholar] [CrossRef]
- Ou, X. Calculation of Traffic Accessibility Based on Taxi Trajectory Data. Transp. Transp. 2023, 39, 26–31. [Google Scholar]
- Jiang, H. Research on the Distribution Characteristics of Chengdu’s Urban Functional Zones Based on Taxi Trajectory. Urban Constr. Theory Res. (Electron. Ed.) 2022, 33, 49–51. [Google Scholar]
- Zhang, T.-y.; Yao, E.-j.; Yang, Y.; Pan, L.; Li, C.-p.; Li, B.; Zhao, F. Deployment optimization of battery swapping stations accounting for taxis’ dynamic energy demand. Transp. Res. Part D Transp. Environ. 2023, 116, 103617. [Google Scholar] [CrossRef]
- Zhao, N. Application of Mining Taxi Hotspots and Routes Based on Big Data in Urban Planning. Master’s Thesis, Southeast University, Nanjing, China, 2019. [Google Scholar] [CrossRef]
- Cesario, E. Big data analytics and smart cities: Applications, challenges, and opportunities. Front. Big Data 2023, 6, 1149402. [Google Scholar] [CrossRef] [PubMed]
- Sheng, Z.; Lv, Z.; Li, J.; Xu, Z.; Sun, H.; Liu, X.; Ye, R. Taxi travel time prediction based on fusion of traffic condition features. Comput. Electr. Eng. 2023, 105, 108530. [Google Scholar] [CrossRef]
- Li, M.; Zhang, H.; Qiu, P.; Cheng, S.; Chen, J.; Lu, F. A Trajectory Prediction Algorithm for Mobile Objects Based on Fuzzy Long Short-Term Memory Neural Network. J. Surv. Mapp. 2018, 47, 1660–1669. [Google Scholar]
- Yu, W.; Ai, T.; Liu, P. Network Kernel Density Analysis Method for Facility POI Distribution Hotspot Analysis. J. Surv. Mapp. 2015, 44, 1378–1383, 1400. [Google Scholar]
- Wang, L. Study on the Characteristics of Urban Taxi Passenger Travel Based on KDE and GWR. Master’s Thesis, Chang’an University, Xi’an, China, 2020. [Google Scholar] [CrossRef]
- Zhao, S.; Xiao, Y.; Ning, Y.; Zhou, Y.; Zhang, D. An Optimized K-means Clustering for Improving Accuracy in Traffic Classification. Wirel. Pers. Commun. 2021, 120, 81–93. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, L.; Wu, Z. Identifying Urban Functional Zones Using Taxi Trajectory Data. J. Geomat. Sci. Technol. 2018, 35, 413–417, 424. [Google Scholar]
- Zhou, J.; Murphy, E.; Long, Y. Commuting Efficiency Gains: Assessing Different Transport Policies with New Indicators. Int. J. Sustain. Transp. 2019, 13, 710–721. [Google Scholar] [CrossRef]
- Yan, L.; Wang, D.; Zhang, S.; Xie, D. Evaluating the multi-scale patterns of jobs-residence balance and commuting time—Cost using cellular signaling data: A case study in Shanghai. Transportation 2019, 46, 777–792. [Google Scholar] [CrossRef]
- Ma, X.; Chai, Y.; Zhang, Y. Study on Work and Commuting Behavior Characteristics of Employees in Beijing Suburbs Based on GPS Data—A Case Study of Shangdi Information Industry Park. Hum. Geogr. 2018, 33, 60–67. [Google Scholar]
- Sun, J.; Dong, H.; Qin, G.; Tian, Y. Quantifying the Impact of Rainfall on Taxi Hailing and Operation. J. Adv. Transp. 2020, 2020, 7081628. [Google Scholar] [CrossRef]
- Wang, H.; Huang, H.; Ni, X.; Zeng, W. Revealing Spatial-Temporal Characteristics and Patterns of Urban Travel: A Large-Scale Analysis and Visualization Study with Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2019, 8, 257. [Google Scholar] [CrossRef]
- He, Q.; Li, X.; Li, A. Traffic intersection flow prediction model based on graph convolutional network. Comput. Appl. Res. 2023, 40, 440–444. [Google Scholar]
- Zheng, Z.; Rasouli, S.; Timmermans, H. Modeling taxi driver anticipatory behavior. Comput. Environ. Urban Syst. 2018, 69, 133–141. [Google Scholar] [CrossRef]
- Safikhani, A.; Kamga, C.; Mudigonda, S.; Faghih, S.S.; Moghimi, B. Spatio-temporal Modeling of Yellow Taxi Demands in New York City Using Generalized STAR Models. Int. J. Forecast. 2017, 36, 1138–1148. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Xu, J.; Rahmatizadeh, R.; Bölöni, L.; Turgut, D. Real-Time Prediction of Taxi Demand Using Recurrent Neural Networks. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2572–2581. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| cab_id | Latitude | Longitude | Status | Timestamp |
|---|---|---|---|---|
| 5912 | 30.631813 | 104.030495 | Nun | 3 August 2014 21:51:07 |
| 6313 | 30.631852 | 104.035066 | 1 | 3 August 2014 22:58:45 |
| 6313 | 30.631852 | 104.035066 | 1 | 3 August 2014 22:58:45 |
| Attribute Fields | Data Example | Data Types | Data Description |
|---|---|---|---|
| cab_id | 3949 | Long Int | Taxi collection terminal number |
| latitude | 30.628614 | Float | Latitude of data collected (GCJ-02 coordinate system) |
| longitude | 104.02519 | Float | Longitude of data collected (GCJ-02 coordinate system) |
| status | 0 | Int | Passenger loading status (0 means empty; 1 means loaded) |
| timestamp | 3 August 2014 22:50:54 | Timestamp | Timestamp of recorded data |
| Hotspot | Tianfu Square | Yindu Building | Taurus Park | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Time Period | M | N | E | M | N | E | M | N | E | |
| Hot Path | ||||||||||
| Shudu Avenue | 982 | 683 | 1249 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Xiyu Street | 844 | 631 | 986 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Xinhua Avenue | 0 | 0 | 0 | 893 | 702 | 1093 | 0 | 0 | 0 | |
| Renmin Middle Road | 0 | 0 | 0 | 947 | 816 | 1276 | 0 | 0 | 0 | |
| Jinfu Road | 0 | 0 | 0 | 0 | 0 | 0 | 1216 | 935 | 1427 | |
| Seedling Road | 0 | 0 | 0 | 0 | 0 | 0 | 893 | 537 | 1046 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, J.; Meng, C.; Liu, X. Analysis of Urban Residents’ Travelling Characteristics and Hotspots Based on Taxi Trajectory Data. Appl. Sci. 2024, 14, 1279. https://doi.org/10.3390/app14031279
Du J, Meng C, Liu X. Analysis of Urban Residents’ Travelling Characteristics and Hotspots Based on Taxi Trajectory Data. Applied Sciences. 2024; 14(3):1279. https://doi.org/10.3390/app14031279
Chicago/Turabian StyleDu, Jiusheng, Chengyang Meng, and Xingwang Liu. 2024. "Analysis of Urban Residents’ Travelling Characteristics and Hotspots Based on Taxi Trajectory Data" Applied Sciences 14, no. 3: 1279. https://doi.org/10.3390/app14031279