
Ensemble-Based Knowledge Distillation for Video Anomaly Detection

Abstract
:1. Introduction
- We introduce three novel ensemble-based knowledge distillation mechanisms for video anomaly detection, where the student model focuses on adapting itself to new incoming data while also focusing on not forgetting old patterns it learned before completely. The student model is also provided with an information transfer including different perspectives from multiple teacher models, during this adaptation process for new information. Consequently, instead of training/fine-tuning a model on a comprehensive-sized dataset growing continuously, the model can be updated with our ensemble knowledge distillation methods more efficiently while preventing the catastrophic forgetting problem. Although the focus of this paper is video anomaly detection, the proposed knowledge distillation methods can also be used in other computer vision tasks such as image classification, scene classification, etc.
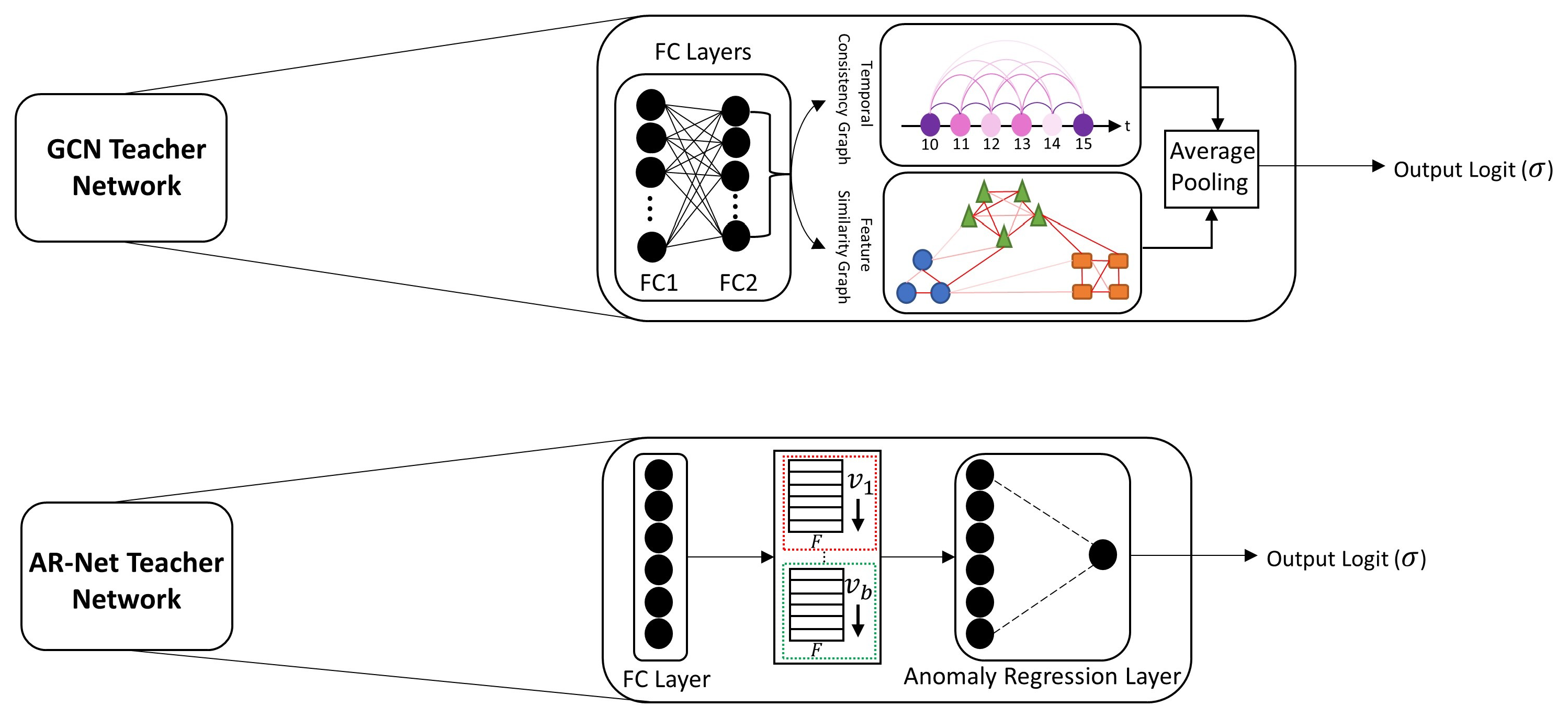
- We adapt AR-Net and GCN models into our ensemble-based knowledge distillation approach but other state-of-the-art methods can be easily adapted to our approach. We extensively evaluate AR-Net and GCN models on two comprehensive datasets, which are UCF-Crime [17] and RWF-2000 [18] to validate our proposed methods with respect to quantitative results. Within experiments, firstly we use the UCF-Crime dataset as the source dataset, which represents the baseline dataset including previous patterns the model first learned and RWF-2000 represents the target dataset including new patterns to be learned by the model. In later stages, we also switch dataset roles, meaning that we use RWF-2000 as the source dataset and UCF-Crime as the target dataset. Consequently, we try to ensure that the model shows stable performance and behavior in case the dataset roles are reversed.
- We present extensive experiments and analyze different parameters with respect to the knowledge distillation mechanism and three different ensemble-based formulations. Results show that our proposed approaches reduce the catastrophic forgetting problem of the model on the source dataset while generally improving the performance of the model on the target dataset. We also discuss limitations and possible future work plans for our proposed approaches.
- We share our code for future research studies on this link: https://github.com/BurcakAsal/AnomalyEnsembleKD (accessed on 19 January 2024).
2. Related Works
2.1. Supervision Factor
- Unsupervised Models: These models do not require any pre-annotated label or ground-truth information. They focus on intrinsic feature patterns of video data samples and the classification process is considered as outlier detection. An outlier pattern is assumed as its intrinsic features are not similar enough to other normal intrinsic features.
- Supervised Models: In supervised models, frame level annotations or bounding box level annotations are used in the training process as ground-truth information besides video level annotations.
- Weakly Supervised Model: These types of models use a weak supervision method, where both normal and abnormal labels are provided as video-level annotations in the training process. Frame-level labels or bounding box-level labels for localization are not provided to these models in the training process.
2.2. Weak Supervision for Video Anomaly Detection
2.3. Knowledge Distillation
- While the model is updating itself with respect to the stream data, it should not update itself by using all of the previously collected data; therefore, it should focus on using the new stream information/data.
- While the model is updating itself with respect to the new data, it should also remember important data patterns, it should not forget important and fundamental patterns within the total big data. Therefore, the proposed model should not be affected by the Catastrophic Forgetting while adapting the new data.
- In constant stream data, fixed-size data should be used for the updating process.
- Fine-Tuning Case for New Tasks: On two datasets, which do not intersect with respect to the samples and classes they include. One dataset of these two is the dataset for the new task and a pre-trained model trained on the latter dataset (used for the old task) beforehand, is re-trained on the dataset for a new task. While in the retraining process, parameters from the specific last layers or the parameters of all layers of the pre-trained model can be updated/optimized for the new task.
- Continuous Learning for Known Classes: In this situation, additional training data are constantly (or in certain intervals) added from a streaming source to the baseline data used before. The task has not changed and the new samples’ classes are exactly the same as the samples’ classes from the old data. This concept can be also thought as a standard online learning concept.
- Continuous Learning of Known and New Classes: In addition to the second scenario, now in this case, classes from new samples can also be different from old ones.
- Response-Based Knowledge: This knowledge strategy is the basic approach within the scope of the KD approach. Distillation loss is obtained by calculating the difference between the teacher model’s end output logit values and the student model’s end output logit values. Softmax function is generally utilized to obtain output logit values for both of the models. An additional temperature constant is also utilized within the formula to prevent focusing too much on one of the softmax outputs while passing information, thus distributing information transfer uniformly with respect to each softmax output.
- Feature-Based Knowledge: Different from Response-Based Knowledge, the Feature-Based Knowledge approach proposes to use intermediate-level layers of teacher and student models for the knowledge distillation method.
- Relation-Based Knowledge: Relation/correlation matrix representation of outputs for both teacher and student models are focused on this type of knowledge strategy. In the later stage, the distillation-based loss function is minimized by calculating the difference between teacher and student model relation matrices. Additionally, the relation matrices can be calculated by utilizing end-output logits or intermediate-level output logits. Lastly, an inner product or a specialized distance/similarity-based function can be utilized to create a relation matrix for the teacher/student models.
3. Proposed Approaches
3.1. Equally Weighted Combination (EWC) Approach
3.2. Confidence Based Maximum Selection (CBMS) Approach
3.3. Confidence Based Weighted Combination (CBWC) Approach
4. Experimental Evaluation
4.1. Datasets
4.2. Results Obtained without Knowledge Distillation
4.3. Results Obtained with Response-Based Knowledge Distillation
4.4. Results of EWC Approach
4.5. Results of CBMS Approach
4.6. Results of CBWC Approach
4.7. An Additional Experiment
4.8. Comparison with State-of-the-Art Studies
4.9. Discussion on Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ramachandra, B.; Jones, M.; Vatsavai, R.R. A survey of single-scene video anomaly detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2293–2312. [Google Scholar] [CrossRef]
- Suarez, J.J.P.; Naval, P.C., Jr. A survey on deep learning techniques for video anomaly detection. arXiv 2020, arXiv:2009.14146. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Pawar, K.; Attar, V. Deep learning approaches for video-based anomalous activity detection. World Wide Web 2019, 22, 571–601. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Mohammadi, B.; Fathy, M.; Sabokrou, M. Image/video deep anomaly detection: A survey. arXiv 2021, arXiv:2103.01739. [Google Scholar]
- Şengönül, E.; Samet, R.; Abu Al-Haija, Q.; Alqahtani, A.; Alturki, B.; Alsulami, A.A. An Analysis of Artificial Intelligence Techniques in Surveillance Video Anomaly Detection: A Comprehensive Survey. Appl. Sci. 2023, 13, 4956. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; Yang, K.; Ju, B.; Liu, S.; Wang, Y.; Yang, D.; Sun, P.; Song, L. Amp-net: Appearance-motion prototype network assisted automatic video anomaly detection system. IEEE Trans. Ind. Inform. 2023, 20, 2843–2855. [Google Scholar] [CrossRef]
- Wang, L.; Tian, J.; Zhou, S.; Shi, H.; Hua, G. Memory-augmented appearance-motion network for video anomaly detection. Pattern Recognit. 2023, 138, 109335. [Google Scholar] [CrossRef]
- Ren, J.; Xia, F.; Liu, Y.; Lee, I. Deep Video Anomaly Detection: Opportunities and Challenges. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 959–966. [Google Scholar]
- Raja, R.; Sharma, P.C.; Mahmood, M.R.; Saini, D.K. Analysis of anomaly detection in surveillance video: Recent trends and future vision. Multimed. Tools Appl. 2023, 82, 12635–12651. [Google Scholar] [CrossRef]
- Panagiotatos, G.; Passalis, N.; Iosifidis, A.; Gabbouj, M.; Tefas, A. Curriculum-based teacher ensemble for robust neural network distillation. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Wan, B.; Fang, Y.; Xia, X.; Mei, J. Weakly supervised video anomaly detection via center-guided discriminative learning. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1237–1246. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An open large scale video database for violence detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190. [Google Scholar]
- Zhu, S.; Chen, C.; Sultani, W. Video Anomaly Detection for Smart Surveillance. In Computer Vision: A Reference Guide; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–8. [Google Scholar]
- Liu, W.; Luo, W.; Li, Z.; Zhao, P.; Gao, S. Margin Learning Embedded Prediction for Video Anomaly Detection with A Few Anomalies. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 3023–3030. [Google Scholar]
- Zhang, J.; Qing, L.; Miao, J. Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4030–4034. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv 2019, arXiv:1907.10211. [Google Scholar]
- Ramachandra, B.; Jones, M.; Vatsavai, R. Learning a distance function with a Siamese network to localize anomalies in videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2598–2607. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 322–339. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S.I. Claws: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 358–376. [Google Scholar]
- Feng, J.C.; Hong, F.T.; Zheng, W.S. Mist: Multiple instance self-training framework for video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14009–14018. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised video anomaly detection with contrastive learning of long and short-range temporal features. In Proceedings of the 2021 18th IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Wu, J.; Zhang, W.; Li, G.; Wu, W.; Tan, X.; Li, Y.; Ding, E.; Lin, L. Weakly-supervised spatio-temporal anomaly detection in surveillance video. arXiv 2021, arXiv:2108.03825. [Google Scholar]
- Lv, H.; Zhou, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Localizing anomalies from weakly-labeled videos. IEEE Trans. Image Process. 2021, 30, 4505–4515. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Liu, J. Learning causal temporal relation and feature discrimination for anomaly detection. IEEE Trans. Image Process. 2021, 30, 3513–3527. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Liu, F.; Jiao, L. Self-training multi-sequence learning with Transformer for weakly supervised video anomaly detection. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), Virtual, 22 February–1 March 2022; Volume 36, pp. 1395–1403. [Google Scholar]
- Chen, Y.; Liu, Z.; Zhang, B.; Fok, W.; Qi, X.; Wu, Y.C. Mgfn: Magnitude-contrastive glance-and-focus network for weakly-supervised video anomaly detection. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 387–395. [Google Scholar]
- Losing, V.; Hammer, B.; Wersing, H. Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing 2018, 275, 1261–1274. [Google Scholar] [CrossRef]
- Käding, C.; Rodner, E.; Freytag, A.; Denzler, J. Fine-tuning deep neural networks in continuous learning scenarios. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 588–605. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3048–3068. [Google Scholar] [CrossRef]
- Ruffy, F.; Chahal, K. The state of knowledge distillation for classification. arXiv 2019, arXiv:1912.10850. [Google Scholar]
- You, S.; Xu, C.; Xu, C.; Tao, D. Learning from multiple teacher networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1285–1294. [Google Scholar]
- Furlanello, T.; Lipton, Z.; Tschannen, M.; Itti, L.; Anandkumar, A. Born again neural networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1607–1616. [Google Scholar]
- Park, S.; Kwak, N. Feed: Feature-level ensemble for knowledge distillation. arXiv 2019, arXiv:1909.10754. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing 2020, 415, 106–113. [Google Scholar] [CrossRef]
- Du, S.; You, S.; Li, X.; Wu, J.; Wang, F.; Qian, C.; Zhang, C. Agree to disagree: Adaptive ensemble knowledge distillation in gradient space. Adv. Neural Inf. Process. Syst. 2020, 33, 12345–12355. [Google Scholar]
- Yuan, F.; Shou, L.; Pei, J.; Lin, W.; Gong, M.; Fu, Y.; Jiang, D. Reinforced multi-teacher selection for knowledge distillation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 14284–14291. [Google Scholar]
- Doshi, K.; Yilmaz, Y. Towards interpretable video anomaly detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2655–2664. [Google Scholar]
- De Zarzà, I.; de Curtò, J.; Calafate, C.T. Socratic Video Understanding on Unmanned Aerial Vehicles. Procedia Comput. Sci. 2023, 225, 144–154. [Google Scholar] [CrossRef]
- De Curtò, J.; de Zarzà, I.; Roig, G.; Calafate, C.T. Summarization of Videos with the Signature Transform. Electronics 2023, 12, 1735. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 | |
|---|---|---|---|
| Teacher | 82.1 | 59.1 | 70.7 |
| Student | 60.8 | 77.3 | 68.9 |
| UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 | |
|---|---|---|---|
| Teacher | 81.3 | 57.6 | 69.3 |
| Student | 59.2 | 75.2 | 67.2 |
| Alpha () | UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 68.4 | 77.5 | 73.5 |
| 0.2 | 68.9 | 77.1 | 73.2 |
| 0.3 | 70.3 | 74.8 | 72.4 |
| 0.4 | 72.1 | 74.0 | 73.0 |
| 0.5 | 73.0 | 70.2 | 71.6 |
| Alpha () | UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 69.4 | 76.8 | 73.1 |
| 0.2 | 69.2 | 74.9 | 72.2 |
| 0.3 | 71.2 | 74.1 | 72.6 |
| 0.4 | 72.3 | 71.2 | 71.8 |
| 0.5 | 73.7 | 69.0 | 70.9 |
| Alpha () | UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 70.8 | 78.1 | 74.1 |
| 0.2 | 69.7 | 76.5 | 73.0 |
| 0.3 | 69.9 | 75.3 | 72.2 |
| 0.4 | 71.6 | 73.9 | 72.7 |
| 0.5 | 72.8 | 69.6 | 71.4 |
| Alpha () | RWF-2000 | UCF-Crime | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 69.1 | 75.2 | 72.2 |
| 0.2 | 71.4 | 75.7 | 73.7 |
| 0.3 | 71.0 | 73.3 | 72.1 |
| 0.4 | 73.8 | 72.6 | 73.4 |
| 0.5 | 74.3 | 70.4 | 72.3 |
| Alpha () | UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 71.3 | 78.4 | 74.7 |
| 0.2 | 71.8 | 77.2 | 74.4 |
| 0.3 | 72.5 | 75.1 | 73.5 |
| 0.4 | 73.1 | 74.9 | 73.6 |
| 0.5 | 73.9 | 70.3 | 72.1 |
| Alpha () | RWF-2000 | UCF-Crime | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 72.9 | 76.7 | 74.9 |
| 0.2 | 73.8 | 75.5 | 74.7 |
| 0.3 | 75.4 | 76.3 | 76.0 |
| 0.4 | 74.5 | 72.9 | 73.7 |
| 0.5 | 74.2 | 73.3 | 73.6 |
| Alpha () | UCF-Crime | RWF-2000 | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 71.0 | 77.6 | 74.2 |
| 0.2 | 71.9 | 77.4 | 74.8 |
| 0.3 | 73.7 | 76.8 | 75.1 |
| 0.4 | 73.6 | 74.9 | 74.0 |
| 0.5 | 72.5 | 71.1 | 71.9 |
| Alpha () | RWF-2000 | UCF-Crime | UCF-Crime + RWF-2000 |
|---|---|---|---|
| 0.1 | 73.8 | 77.0 | 75.3 |
| 0.2 | 73.4 | 76.9 | 75.2 |
| 0.3 | 74.4 | 76.1 | 75.4 |
| 0.4 | 75.0 | 76.2 | 75.7 |
| 0.5 | 75.6 | 73.2 | 74.2 |
| GCN Teacher (UCF-Crime) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 109 | 27 |
| Predicted Negative | 31 | 123 |
| GCN Teacher (RWF-2000) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 117 | 86 |
| Predicted Negative | 83 | 114 |
| AR-Net Teacher (UCF-Crime) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 114 | 22 |
| Predicted Negative | 26 | 128 |
| AR-Net Teacher (RWF-2000) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 120 | 84 |
| Predicted Negative | 80 | 116 |
| AR-Net Student (UCF-Crime) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 106 | 49 |
| Predicted Negative | 34 | 101 |
| AR-Net Student (RWF-2000) | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | 175 | 60 |
| Predicted Negative | 25 | 140 |
| Misclassification | GCN Teacher | AR-Net Teacher | Common |
|---|---|---|---|
| UCF-Crime | 58 | 48 | 45 |
| RWF-2000 | 169 | 164 | 157 |
| Method | F-AUC |
|---|---|
| (Sultani et al., 2018) [17] | 75.41 |
| (Zhong et al., 2019) [14] | 82.12 |
| (Zhang et al., 2019) [21] | 78.66 |
| (Zhu and Newsam, 2019) [23] | 79.00 |
| (Wu et al., 2020) [25] | 82.44 |
| (Zaheer et al., 2020) [26] | 83.03 |
| (Feng et al., 2021) [27] | 82.30 |
| (Tian et al., 2021) [28] | 84.30 |
| (Lv et al., 2021) [30] | 85.38 |
| (Wu and Liu, 2021) [31] | 84.89 |
| (Li et al., 2022) [32] | 85.62 |
| (Chen et al., 2023) [33] | 86.98 |
| Ours (CBMS) | 75.82 |
| Method | Advantages | Disadvantages |
|---|---|---|
| (Lv et al., 2021) [30] | - More Advanced Temporaland Semantic Context Encoding - More Advanced WeakSupervision Strategy | - Trained and Testedon Fixed-Size Datasets - No Separate AdaptationMechanism |
| (Li et al., 2022) [32] | - Transformer Based ConvolutionalNetwork Structure - Two Stage SelfTraining Strategy | - Trained and Testedon Fixed-Size Datasets - No Separate AdaptationMechanism |
| (Chen et al., 2023) [33] | - Transformer Based Glanceand Focus Modules - Feature Amplification Mechanism | - Trained and Testedon Fixed-Size Datasets - No Separate AdaptationMechanism |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asal, B.; Can, A.B. Ensemble-Based Knowledge Distillation for Video Anomaly Detection. Appl. Sci. 2024, 14, 1032. https://doi.org/10.3390/app14031032
Asal B, Can AB. Ensemble-Based Knowledge Distillation for Video Anomaly Detection. Applied Sciences. 2024; 14(3):1032. https://doi.org/10.3390/app14031032
Chicago/Turabian StyleAsal, Burçak, and Ahmet Burak Can. 2024. "Ensemble-Based Knowledge Distillation for Video Anomaly Detection" Applied Sciences 14, no. 3: 1032. https://doi.org/10.3390/app14031032