
Biogas Production Prediction Based on Feature Selection and Ensemble Learning
Abstract
:1. Introduction
- We analyze the correlation coefficients between system features and target features, combine the working principle of the system, screen out the features with strong correlation, and obtain the optimal number of input model features based on the preliminary prediction.
- We use the K-fold cross-validation method to divide the dataset proportionally to avoid the overfitting problem.
- A stacking ensemble learning model is constructed based on different models for training and prediction, and the stacking model with the best prediction effect is obtained under different base learners and meta learners.
2. Materials and Methods
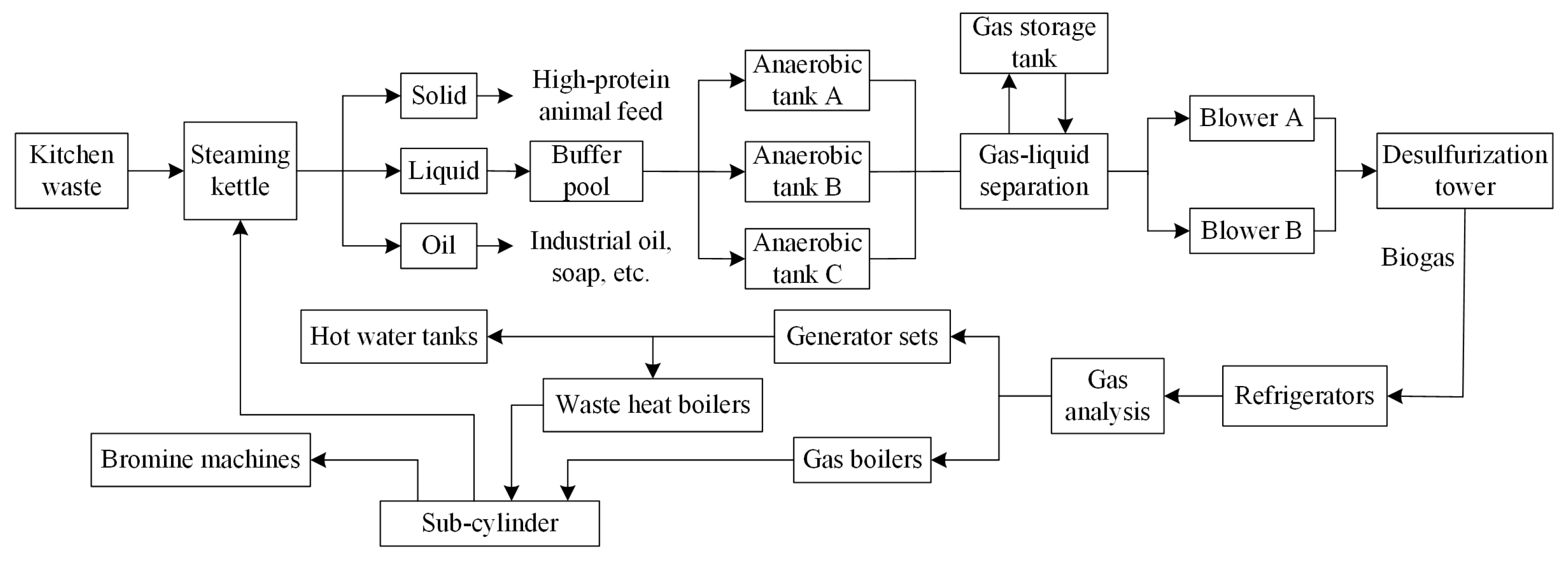
2.1. Biogas Power Generation Systems
2.1.1. System Introduction
2.1.2. The Necessity of Biogas Production Forecasting
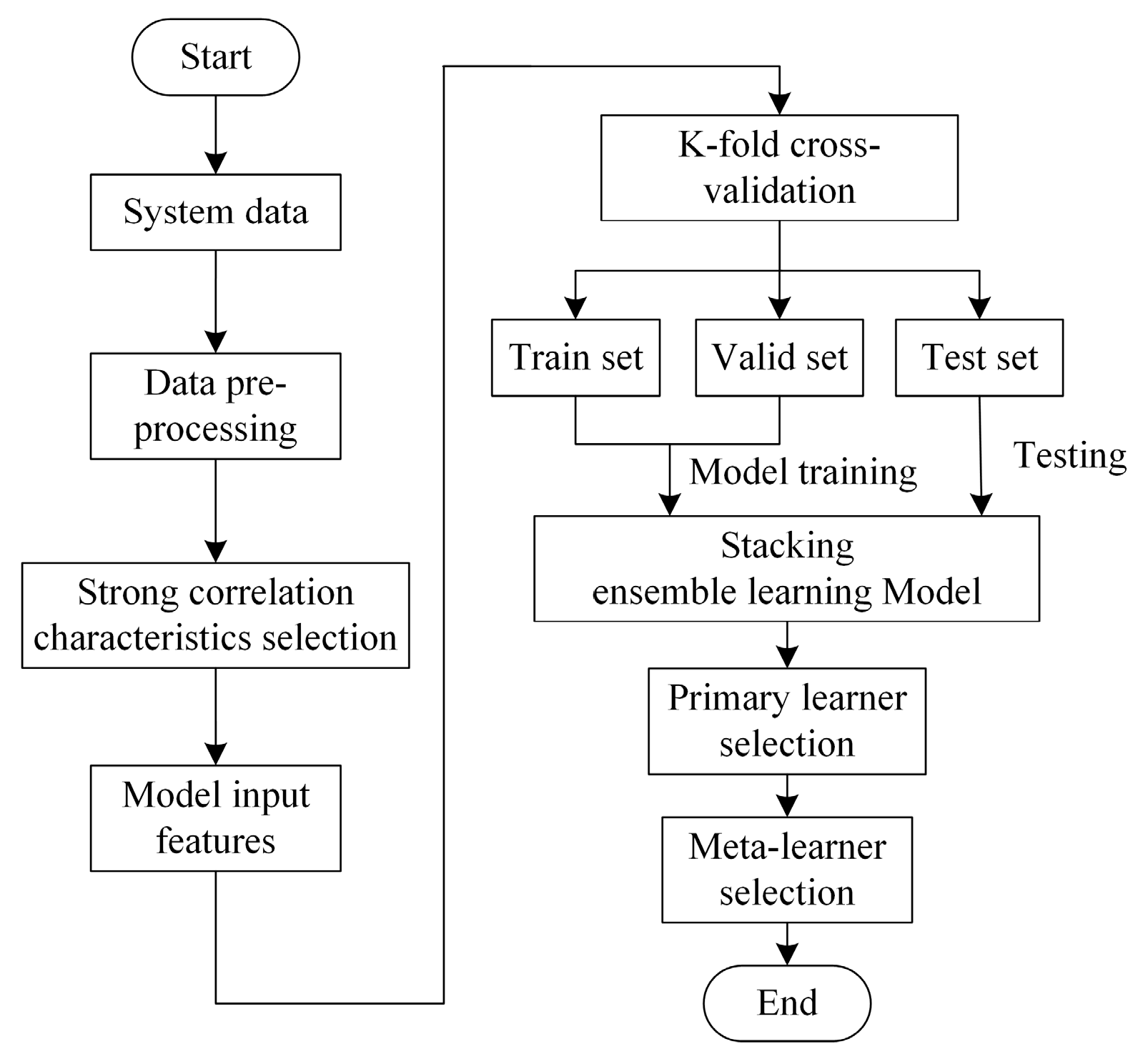
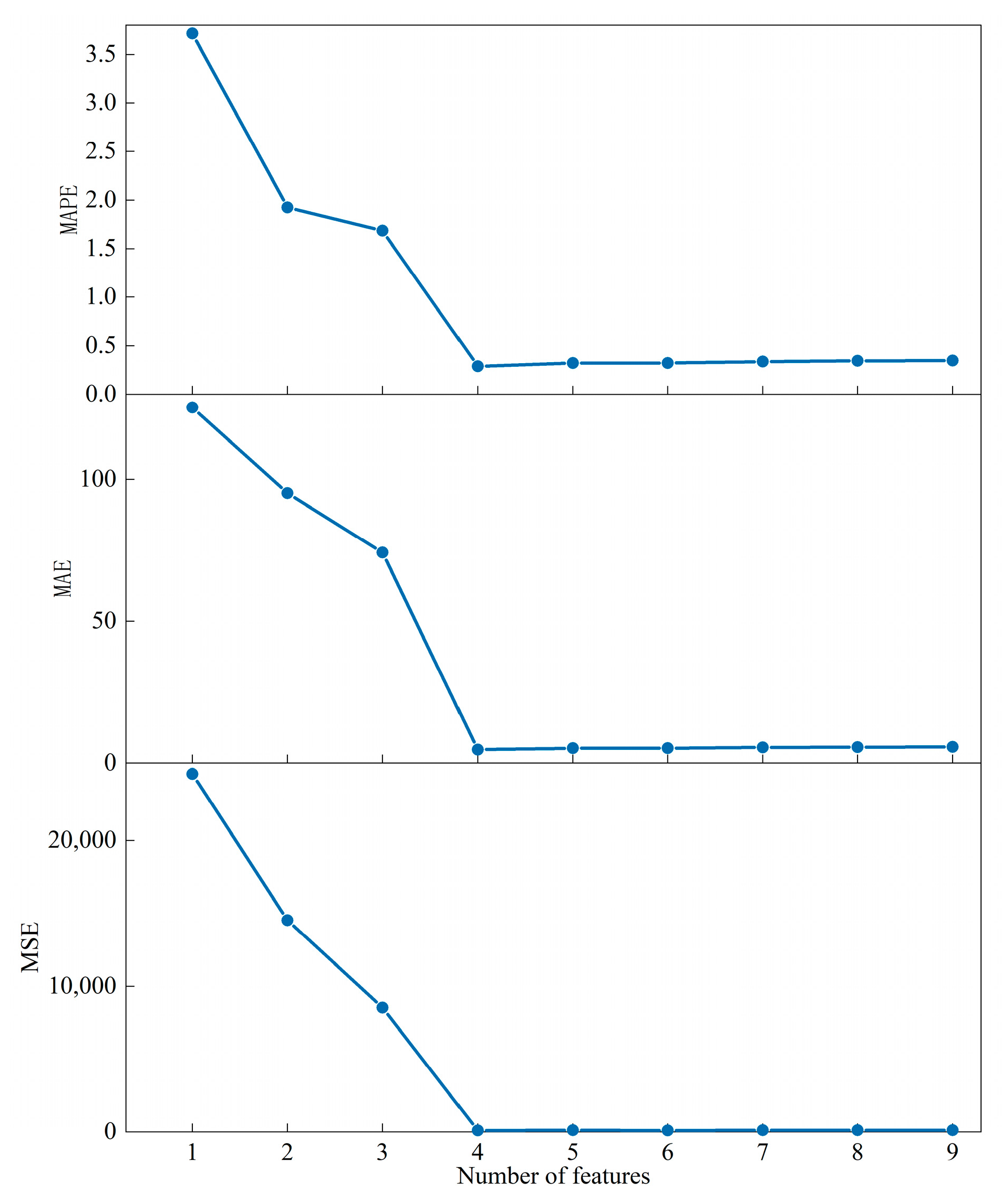
2.1.3. Feature Selection
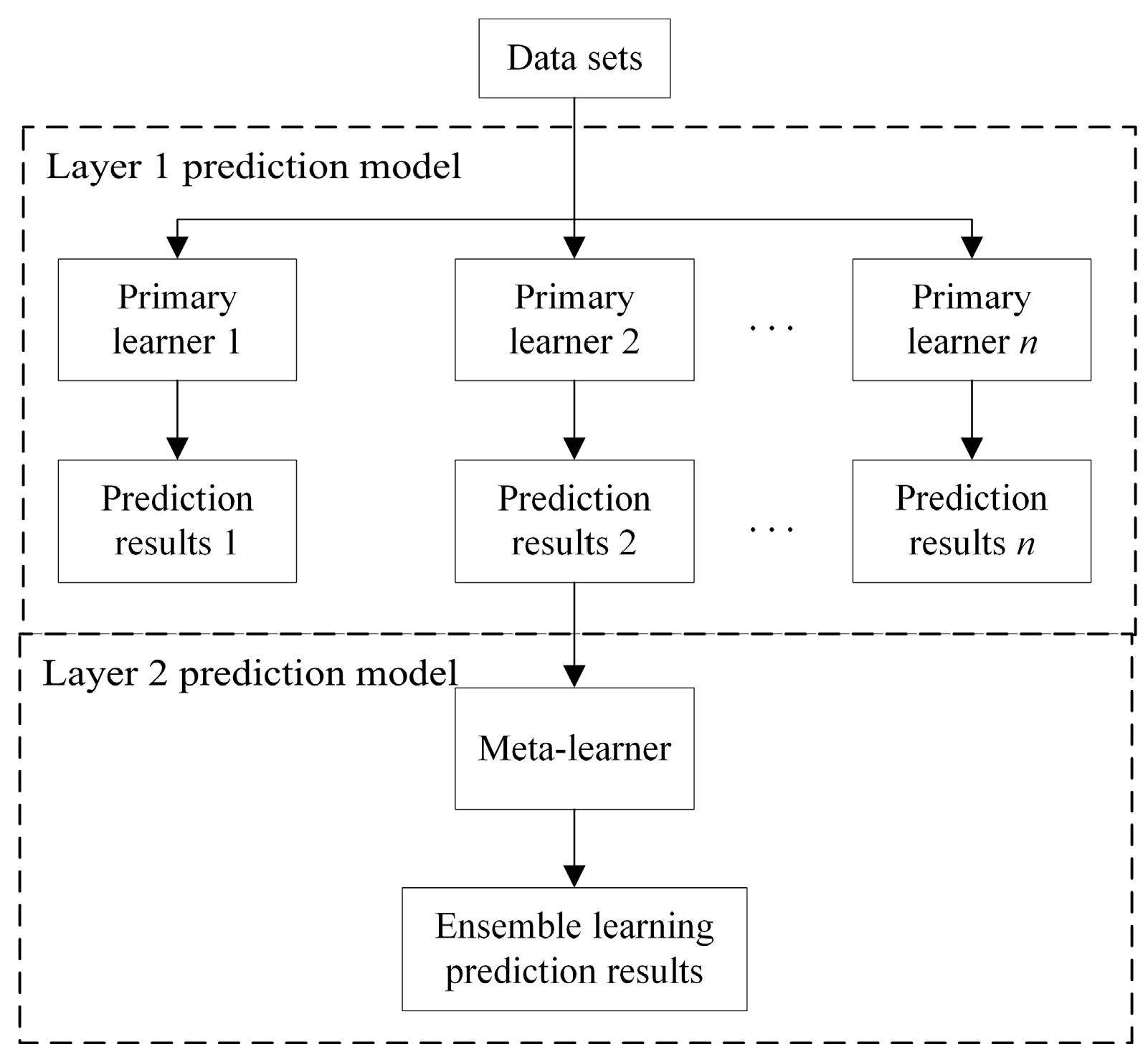
2.1.4. Prediction Model Structure
2.2. Biogas Prediction Based on Heterogeneous Ensemble Learning
2.2.1. Stacking Ensemble Learning Algorithm
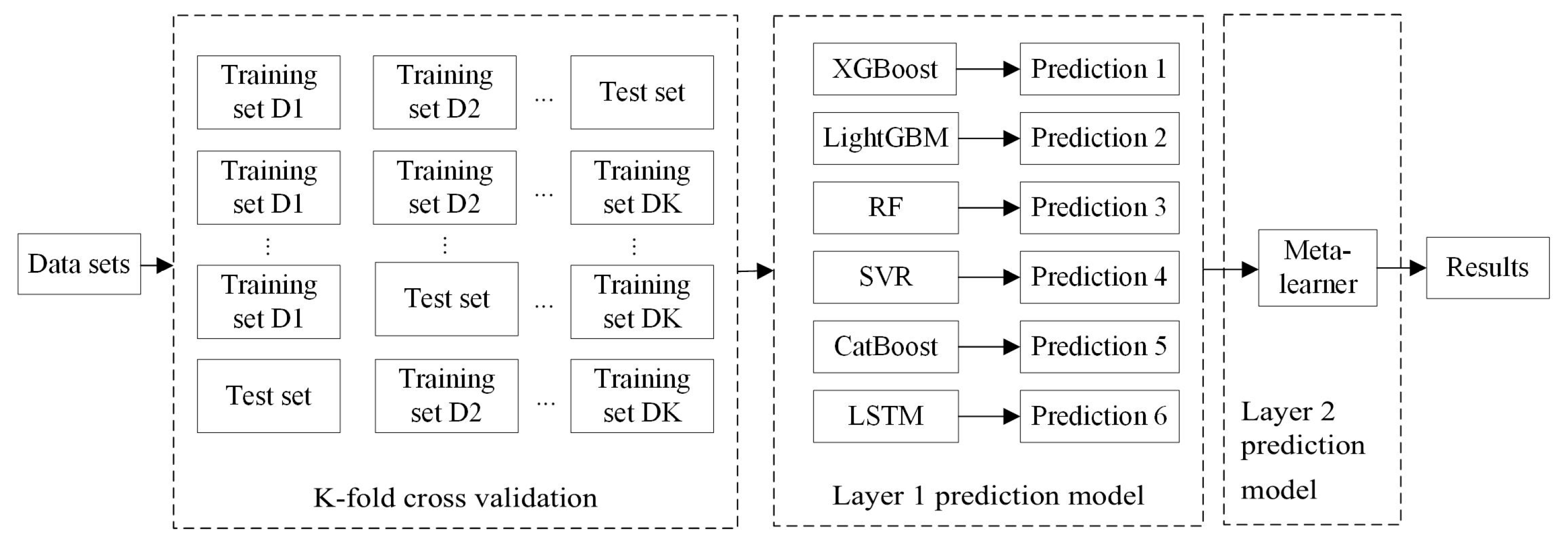
2.2.2. K-Fold Cross-Validation
2.2.3. Construction of the Heterogeneous Ensemble Learning Model
2.2.4. Evaluation Metrics
3. Results and Discussion
3.1. Data Sets
3.2. Feature Analysis
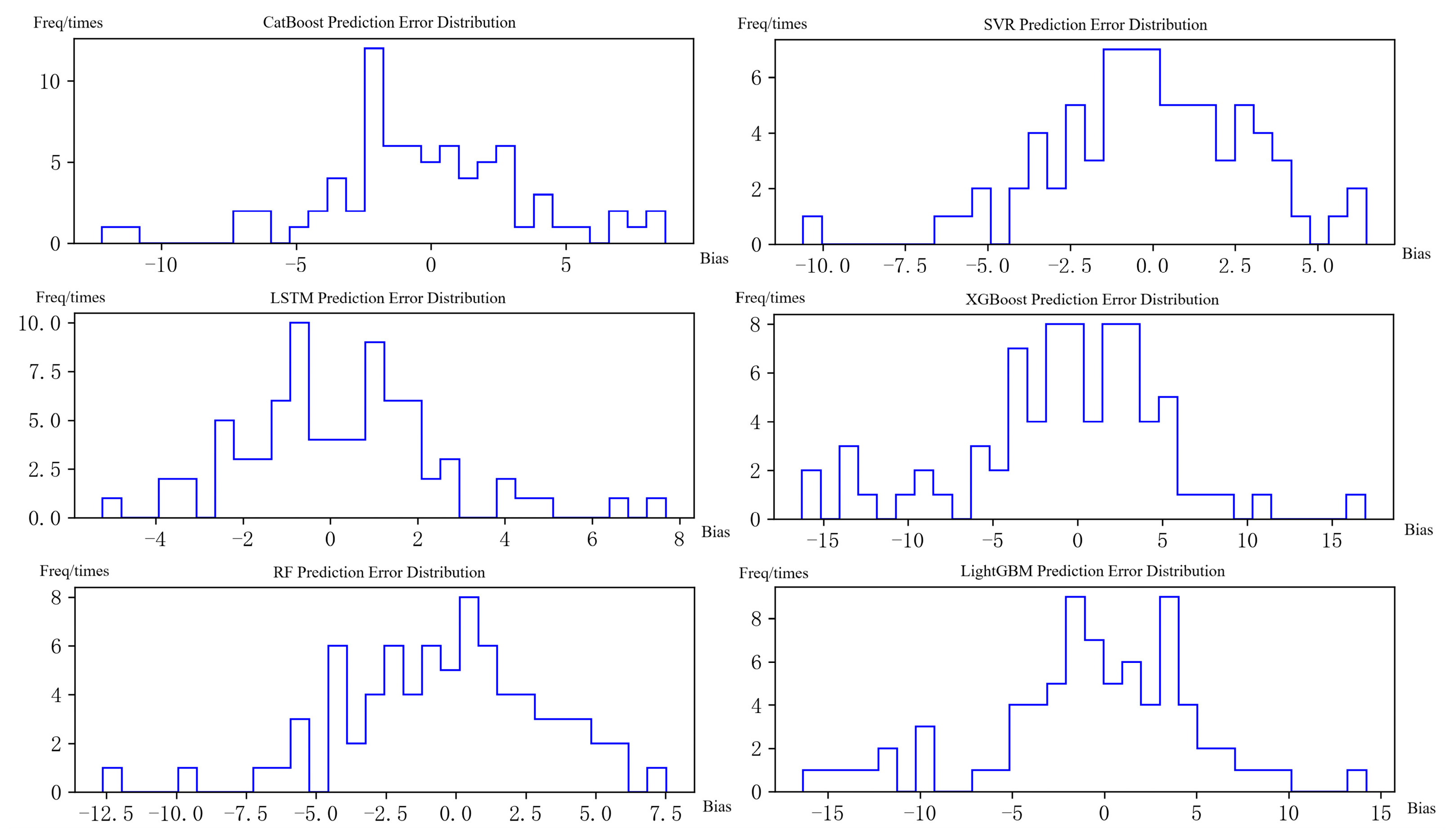
3.3. Individual Learner Prediction Performance Analysis
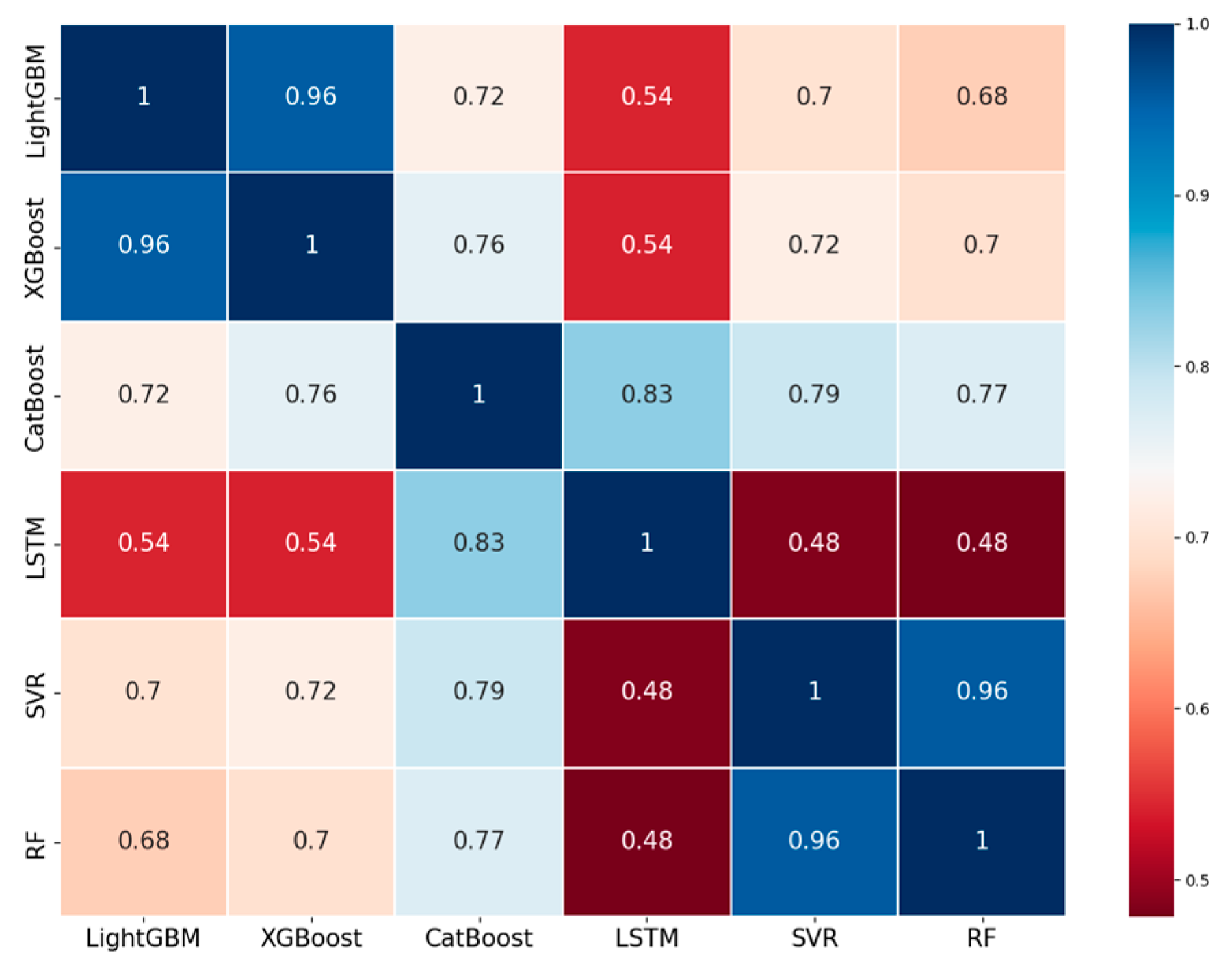
3.4. Meta-Learner Selection
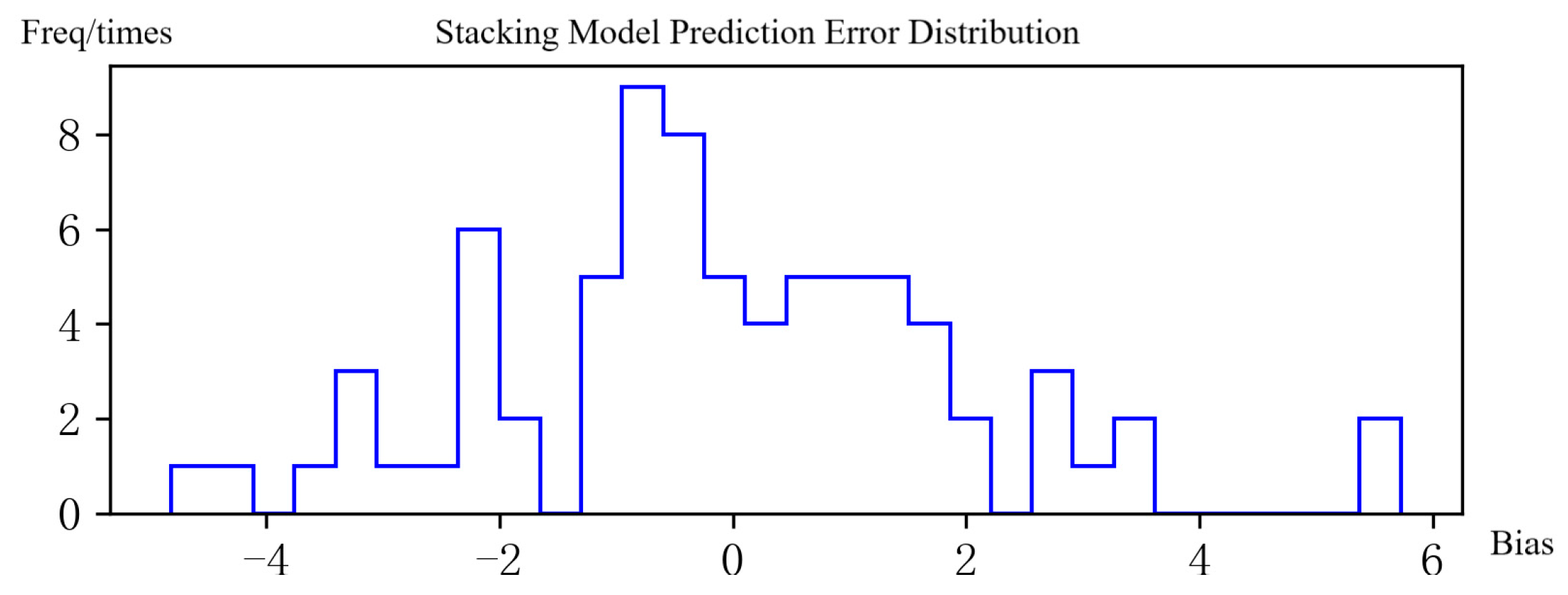
3.5. Prediction Performance Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, Y.L.; Wang, Y.Z.; Zhang, X.J.; Li, W.Y.; Li, J.; Li, H.J. Thermo-economic analysis of biomass-fired organic Rankine cycle combined heat and power system. Acta Energiae Solaris Sin. 2021, 42, 312–319. [Google Scholar] [CrossRef]
- Zhang, X.H.; Liang, J.X.; Zhao, C.M.; Wang, L.; Hu, J.L.; Zhong, J.Q. Research on low-carbon power planning with gas turbine units based on carbon transactions. Acta Energiae Solaris Sin. 2020, 41, 92–98. [Google Scholar]
- Li, Y.; Xiao, Z.Q.; Nie, S.S.; Cao, J.W.; Hua, H.C. Review of research on generative adversarial network and its application in new energy data quality. South. Power Syst. Technol. 2020, 14, 25–33. [Google Scholar] [CrossRef]
- Ju, P.; Zhou, X.X.; Chen, W.J.; Yu, Y.P.; Qin, C.; Li, R.M.; Wang, C.S.; Dong, X.Z.; Liu, J.; Wen, J.Y.; et al. “Smart Grid Plus” research overview. Electr. Power Autom. Equip. 2018, 38, 2–11. [Google Scholar] [CrossRef]
- Zhu, J.Q.; Niu, X.F.; Xiao, X.B. Prediction models of the carbon content of fly ash in a biomass boiler based on improved BP neural networks. Renew. Energy Resour. 2020, 38, 150–157. [Google Scholar]
- Xiong, X.; Guo, X.J.; Zeng, P.L.; Zou, R.L.; Wang, X.L. A short-term wind power forecast method via XGBoost hyper-parameters optimization. Front. Energy Res. 2022, 10, 905155. [Google Scholar] [CrossRef]
- Lu, J.X.; Zhang, Q.P.; Yang, Z.H.; Tu, M.F.; Lu, J.J.; Peng, H. Short-term load forecasting method based on CNN-LSTM hybrid neural network model. Autom. Electr. Power Syst. 2019, 43, 131–137. [Google Scholar] [CrossRef]
- Xing, Y.Q.; Xing, X.J.; Zhang, J.; Li, Y.L.; Zhang, X.F.; Zhang, X.W. A prediction model of biomass three-components contents based on machine learning and thermogravimetric analysis. Acta Energiae Solaris Sin. 2019, 40, 1330–1337. [Google Scholar]
- Qu, Z.J.; Li, J.; Hou, X.X.; Gui, J.L. A D-stacking dual-fusion, spatio-temporal graph deep neural network based on a multi-integrated overlay for short-term wind-farm cluster power multi-step prediction. Energy 2023, 281, 128289. [Google Scholar] [CrossRef]
- Pan, G.B.; Gong, M.B.; He, M.; Wu, C.H.; Tang, X.Q.; Yang, L.; OuYang, J. Identification method of electricity charge recovery risk of specialized transformer user based on Stacking model fusion. Electr. Power Autom. Equip. 2021, 41, 152–160. [Google Scholar] [CrossRef]
- Liu, B.; Qin, C.; Ju, P.; Zhao, J.B.; Chen, Y.X.; Zhao, J. Short-term bus load forecasting based on XGBoost and stacking model fusion. Electr. Power Autom. Equip. 2020, 40, 147–153. [Google Scholar] [CrossRef]
- Barik, S.; Paul, K.K. Potential reuse of kitchen food waste. J. Environ. Chem. Eng. 2017, 5, 196–204. [Google Scholar] [CrossRef]
- Jiang, J.F.; Li, L.H.; Cui, M.C.; Zhang, F.G.; Liu, Y.X.; Liu, Y.H.; Long, J.Y.; Guo, Y.F. Anaerobic digestion of kitchen waste: The effects of source, concentration, and temperature. Biochem. Eng. J. 2018, 135, 91–97. [Google Scholar] [CrossRef]
- Yuan, J.H.; Yuan, Z.Y.; Ou, X.M. Modelling of environmental benefit evaluation of energy transition to multi-energy complementary system. Energy Procedia 2019, 158, 4882–4888. [Google Scholar] [CrossRef]
- Lautert, R.R.; Brignol, W.D.; Canha, L.N.; Adeyanju, O.M.; Garcia, V.J. A flexible-reliable operation model of storage and distributed generation in a biogas power plant. Energies 2022, 15, 3154. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C. Data processing strategies in wind energy forecasting models and applications: A comprehensive review. Appl. Energy 2019, 249, 392–408. [Google Scholar] [CrossRef]
- Zheng, Y.F.; Li, Y.; Wang, G.; Chen, Y.P.; Xu, Q.; Fan, J.H.; Cui, X.T. A novel hybrid algorithm for feature selection based on whale optimization algorithm. IEEE Access 2019, 7, 14908–14923. [Google Scholar] [CrossRef]
- Akogul, S. A novel approach to increase the efficiency of filter-based feature selection methods in high-dimensional datasets with strong correlation structure. IEEE Access 2023, 11, 115025–115032. [Google Scholar] [CrossRef]
- Zhang, D.D.; Chen, B.A.; Zhu, H.Y.; Goh, H.H.; Dong, Y.X.; Wu, T.M. Short-term wind power prediction based on two-layer decomposition and BiTCN-BiLSTM-attention model. Energy 2023, 285, 128762. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, Y.; Ding, Z.; Li, S.N.; Wan, Y.; Hu, X.R. Charging demand forecasting of electric vehicle based on empirical mode decomposition-fuzzy entropy and ensemble learning. Autom. Electr. Power Syst. 2020, 44, 114–121. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012; pp. 67–95. [Google Scholar]
- Shi, J.Q.; Zhang, J.H. Load forecasting based on multi-model by stacking ensemble learning. Proc. CSEE 2019, 39, 4032–4042. [Google Scholar] [CrossRef]
- Deng, W.; Guo, Y.X.; Li, Y.; Zhu, L.; Liu, D.G. Power losses prediction based on feature selection and stacking integrated learning. Power Syst. Prot. Control 2020, 48, 108–115. [Google Scholar] [CrossRef]
- You, W.X.; Li, Q.Q.; Yang, N.; Shen, K.; Li, W.W.; Wu, Z.L. Electricity theft detection based on multiple different learner fusion by stacking ensemble learning. Autom. Electr. Power Syst. 2022, 46, 178–186. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System Features | Correlation Coefficient with Biogas Production |
|---|---|
| Anaerobic tank: Inlet main line pressure | 0.1994 |
| Anaerobic tank: Outlet main line pressure | 0.1731 |
| Blower A: Inlet pressure | −0.3835 |
| Blower A: Current | 0.3130 |
| Blower B: Inlet pressure | −0.3152 |
| Blower B: Current | 0.3143 |
| Anaerobic tank A: Pressure | −0.0471 |
| Anaerobic tank A: Water inlet | 0.2837 |
| Anaerobic tank A: Gas flow rate | 0.6860 |
| Anaerobic tank B: Pressure | −0.0414 |
| Anaerobic tank B: Water intake | 0.2999 |
| Anaerobic tank B: Gas flow rate | 0.7231 |
| Anaerobic tank C: Pressure | 0.1121 |
| Anaerobic tank C: Water inlet | 0.3270 |
| Anaerobic tank C: Gas flow rate | 0.6860 |
| Meta-Learner | MSE | MAE | MAPE |
|---|---|---|---|
| XGBoost | 74.489 | 3.658 | 0.220 |
| CatBoost | 80.054 | 3.699 | 0.223 |
| LightGBM | 86.994 | 4.709 | 0.238 |
| LSTM | 107.86 | 5.07 | 0.3022 |
| RF | 98.64 | 4.21 | 0.2520 |
| SVR | 118.03 | 5.19 | 0.3244 |
| Model | Primary Learner Set | Average Error Correlation Coefficient | MSE | MAE | MAPE |
|---|---|---|---|---|---|
| Model 1 (proposed method) | CatBoost, LSTM, SVR, RF | 0.68 | 74.489 | 3.658 | 0.220 |
| Model 2 | CatBoost, LightGBM, XGBoost, SVR | 0.86 | 117.08 | 4.72 | 0.280 |
| Model 3 | CatBoost, LightGBM, LSTM, SVR | 0.745 | 84.54 | 4.63 | 0.224 |
| Model 4 | LightGBM, XGBoost, LSTM, RF | 0.8 | 104.97 | 4.20 | 0.254 |
| Model 5 | CatBoost, XGBoost, LSTM, SVR | 0.755 | 98.61 | 4.03 | 0.242 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, S.; Guo, L.; Li, Y.; Huang, H.; Peng, J.; Liu, X. Biogas Production Prediction Based on Feature Selection and Ensemble Learning. Appl. Sci. 2024, 14, 901. https://doi.org/10.3390/app14020901
Peng S, Guo L, Li Y, Huang H, Peng J, Liu X. Biogas Production Prediction Based on Feature Selection and Ensemble Learning. Applied Sciences. 2024; 14(2):901. https://doi.org/10.3390/app14020901
Chicago/Turabian StylePeng, Shurong, Lijuan Guo, Yuanshu Li, Haoyu Huang, Jiayi Peng, and Xiaoxu Liu. 2024. "Biogas Production Prediction Based on Feature Selection and Ensemble Learning" Applied Sciences 14, no. 2: 901. https://doi.org/10.3390/app14020901