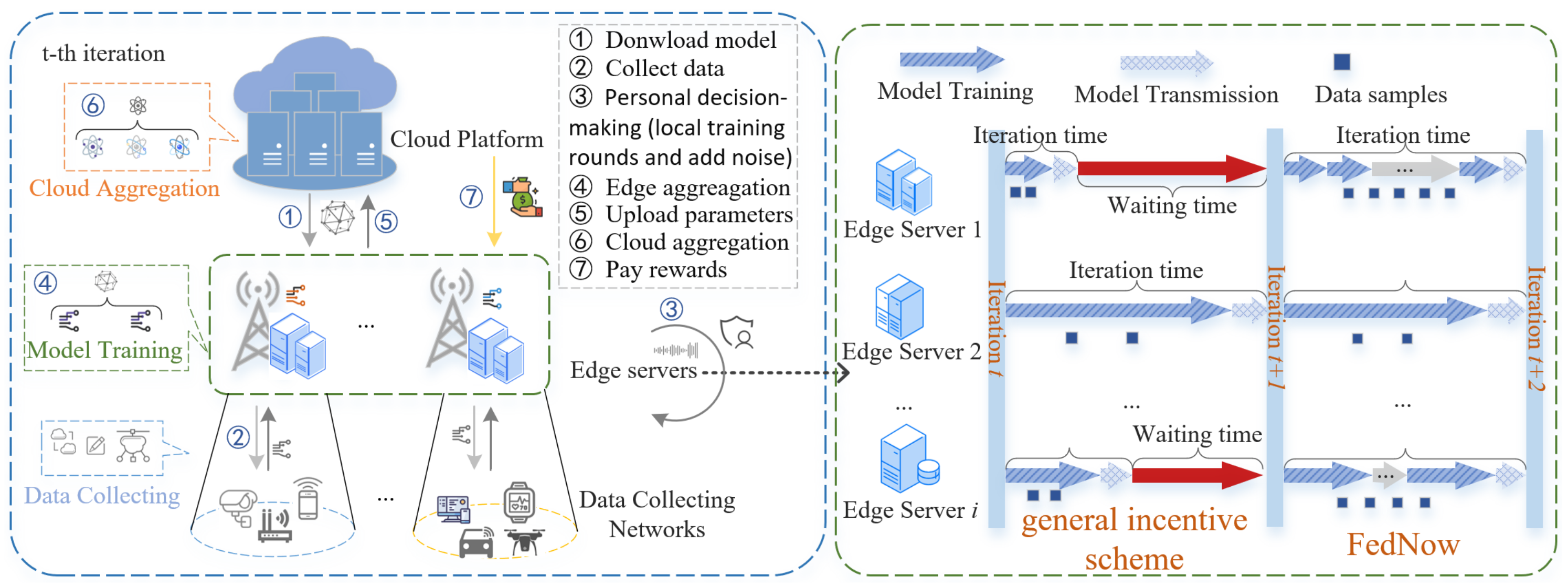
In this section, we present the design details of FedNow and explore its optimal design.
4.1. Optimal Rewards
By integrating the constraints of IR and IC, the cost optimization problem,
, of the incentive mechanism can be transformed as a non-collaborative cost optimization problem,
, which aims to motivate edge servers to make more data contributions (i.e., more training rounds and greater data size) at the lowest possible costs, i.e.,
Solving the above problem involves two challenges. First, due to the enormous number of
-IR and
-IC constraints (i.e.,
[
18]), directly solving the problem is significantly complex. Second, the multi-dimensional decisions of edge servers (i.e.,
and
) will affect their total payoffs and, consequently, influence the platform’s optimal incentive strategy
, leading to a nonconvex mixed-integer nonlinear programming problem. In order to overcome this complex problem, we first equivalently transform
-IR&
-IC constraints into a simplified set with fewer constraints (i.e,
, Lemma 1) and then derive the optimal rewards for different types of edge servers, thereby simplifying the platform’s strategies,
, into two-dimensional variable decisions that only involve
.
Lemma 1. In a scenario of information asymmetry between the cloud server and edge servers, a contract is feasible if and only if the following conditions hold:
- (i)
- (ii)
and ;
- (iii)
.
Constraint (i) is the equivalent conversion of the -IR constraints. Constraints (ii) and (iii) jointly correspond to the -IC constraints. Constraint (i) ensures that if the edge server with the largest training cost can obtain non-negative utility by choosing the contract item intended for its type, then each type-j edge server can also receive a non-negative payoff by choosing the contract item of type-J. This is because . Constraint (ii) indicates that the platform should provide more rewards for the edge servers with a lower training cost and require more data in return. Constraint (iii) specifies the relationship between any two adjacent contract items. Based on the equivalent relaxation of -IR&-IC, we can derive the optimal rewards for each type of edge server, shown as follows:
Lemma 2. For any data size, s = , and any edge server type, , the optimal choice for the platform is to select the rewards that satisfy the following criteria: When deriving the optimal rewards for each type of edge server, most of the existing works tend to prioritize incentivizing low-cost edge servers [
20,
30,
41]. However, they often overlook the importance of resource efficiency, i.e., when the low-cost edge servers are providing more data for local model training, some expensive but computationally powerful edge servers may have already completed the local training, resulting in significant waiting times and resource waste for the entire participating group. In contrast, if the platform tends to choose the edge servers with the strongest computing ability, it may lead to excessive payment costs and, thus, low profits. In order to solve this dilemma, we expect to achieve a better trade-off between economic incentives and training efficiency.
4.2. Efficiency Score Function Design
Before presenting our efficiency score function, we first calculate the total costs of the general incentive mechanism that does not consider multiple rounds of local training, and we take this as the upper-bound cost of our optimization scheme. Hence, we obtain
Theorem 1. For any solution, from to , it is a feasible solution if and only if the platform’s costs under such a solution are lower than the upper-bound cost, , i.e., After deriving the upper-bound cost of problem
(Theorem 1), a general method that can be used is to relax integer constraints and then obtain a feasible solution that satisfies the constraints by rounding, but it cannot guarantee both the existence and the quality of the feasible solutions. Inspired by [
25,
42], we consider
as a high-efficiency participant selection problem, which aims to select an appropriate number of edge servers with the best score to form the incentivized set. We consider the edge servers that can generate higher benefits (i.e., lower model accuracy loss) at lower costs as high-efficiency participants and define marginal efficiency costs (MECs) as our efficiency score function, expressed as follows:
where
denotes the optimal rewards for type set
(since the number of types changes, the optimal rewards that decrease (by type) will also change accordingly). Given
, it is evident that the MECs are influenced by the local training rounds
. However, the edge servers’ CPU-cycle frequency
f is private information and unobservable by the platform. In order to calculate the efficiency score of the edge servers without access to their private attributes, we introduce an exponential mechanism [
33], defined as follows:
Definition 3 (Exponential mechanism).
There exists a random mechanism and a score function , where is the input and is the output of the mechanism; satisfies ϵ-differential privacy ifwhere is the global sensitivity of the score function, which is defined as the maximum distance between any two input scores, i.e., . The definition of the exponential mechanism indicates that each edge server has a probability,
, to determine its local training round as
. Moreover, the closer
and
are, the greater the probability
is. As a result,
can be defined as
Thus, the global sensitivity
. For any local training round
, the platform can calculate the mapping probability
as
For the mapping probability
, the platform can use the expected rounds,
, to approximate the edge servers’ true local training rounds
, i.e., given
,
, the expected local training rounds can be calculated by
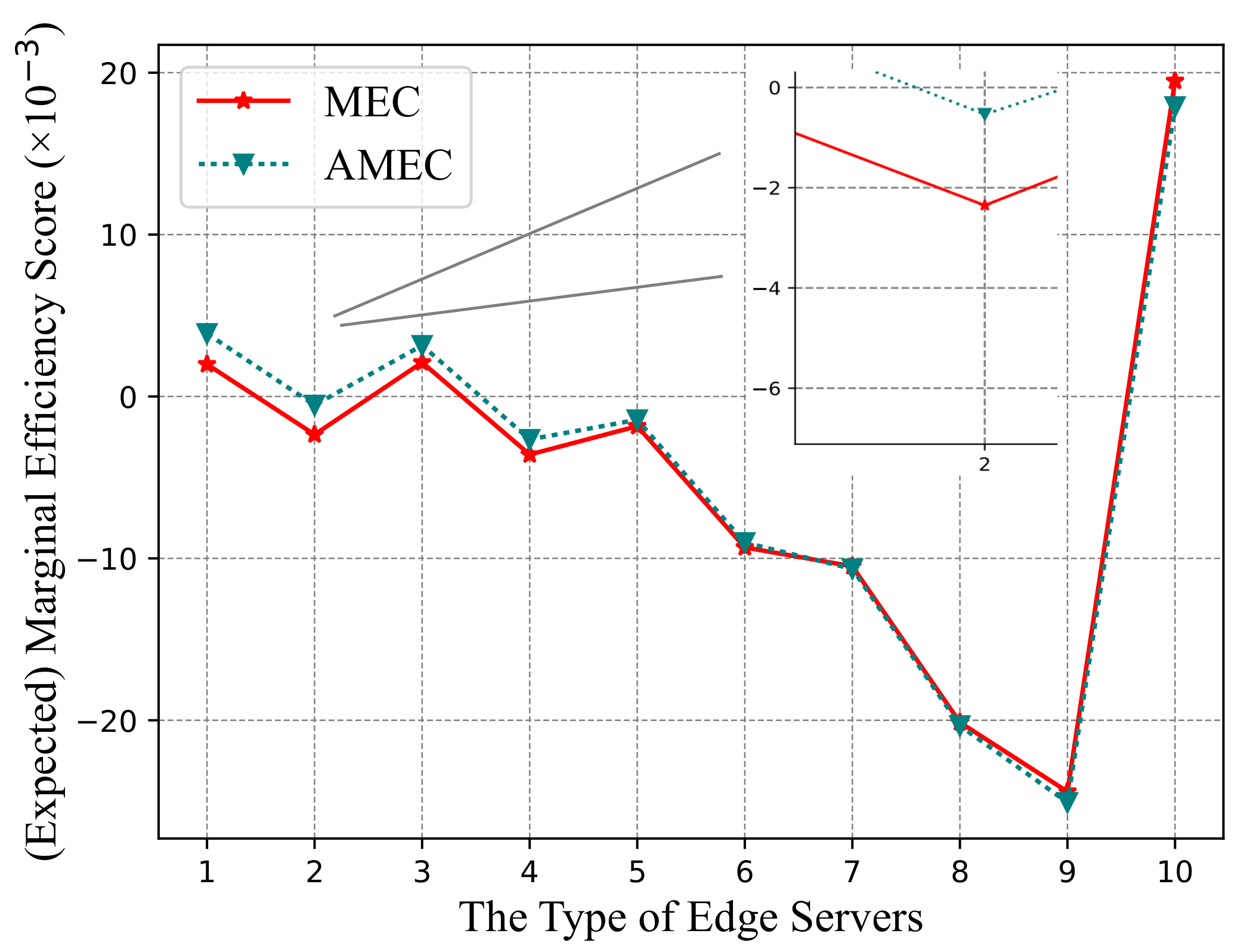
Therefore, the approximate marginal efficiency cost (AMEC) can be expressed as
The platform sorts each type of edge server according to their AMEC in ascending order. A smaller AMEC indicates a higher margin utility and higher quality. The platform will select edge servers according to their AMEC from low to high until finding a threshold type, , such that and , where represents the set of selected edge servers (Assuming there are only five types of edge servers: {1, 2, 3, 4, and 5} and . Since the order sorted by the edge servers’ AMEC may not follow the same order as their contract types, e.g., AMEC: {2, 1, 4, 3, and 5}, then , , and ). For the selected set , we denote and re-index the edge servers’ type in by in ascending order of training cost, . However, since the platform’s cost, , is affected by both and , even if the incentivized set is determined, the platform may be able to obtain a better feasible solution by adjusting its data requirements . Based on the above analysis, we obtain
Proposition 1. Given a set of contract items and , where
- (i)
if and , there exists a threshold type , such that , where - (ii)
if the threshold type exists, there exists an optimal type and required data size such that , where is the platform’s optimal incentivized type set.
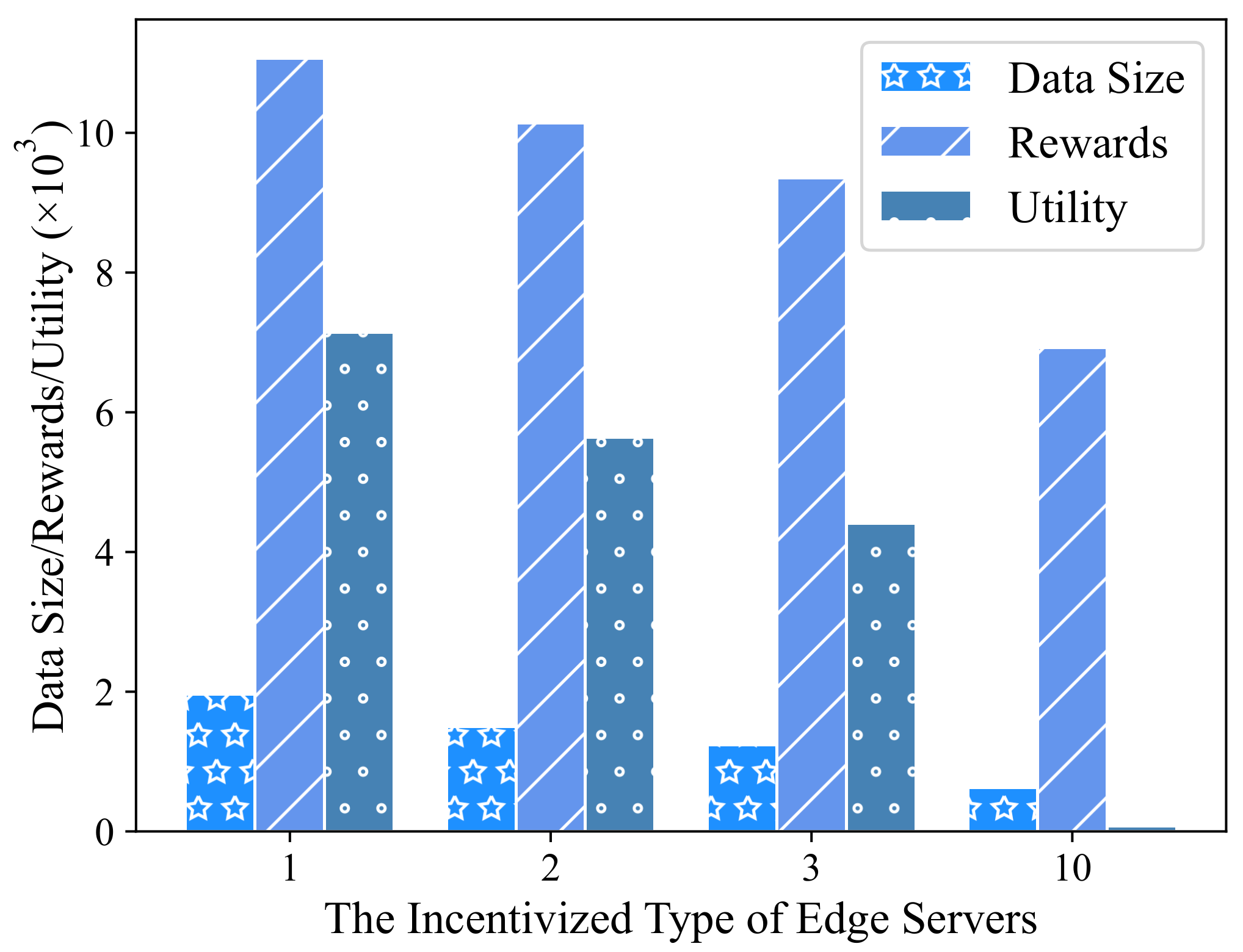
Proposition 1(i) shows that, given , the optimal choice for the platform is to incentivize the edge servers that can provide more total data at lower payment costs. In addition, the platform only provides positive contract items for the incentivized type of edge servers, whereas the non-incentivized edge servers will receive zero contract items. Proposition 1(ii) suggests that if a feasible solution exists, the platform can adjust its incentive strategy (i.e., required data size ), which may lead to a better solution that minimizes the platform’s costs. According to the above analysis, we first designed an iterative algorithm to determine all incentivized edge servers and then characterized the training process of FedNow, which enables the edge servers to personally determine their local training rounds; we used the Monte Carlo method to obtain a better (near-optimal) response for the platform, including the incentivized set and corresponding . With and , the incentivized edge servers will honestly complete model training to compute the optimal global model parameters.
The details of searching for feasible solutions are shown in Algorithm 1. The platform first calculates all edge servers’ AMEC (Line 2–4), then sorts the edge servers based on their AMEC in ascending order and searches for the threshold type (Line 5–18). The time complexity of calculating (Line 4) is , while the time complexity for checking whether the feasibility condition holds (Line 11) is also . Therefore, the time complexity of Algorithm 1 is .
| Algorithm 1 Calculation of the feasible solution |
![Applsci 14 00494 i001]() |
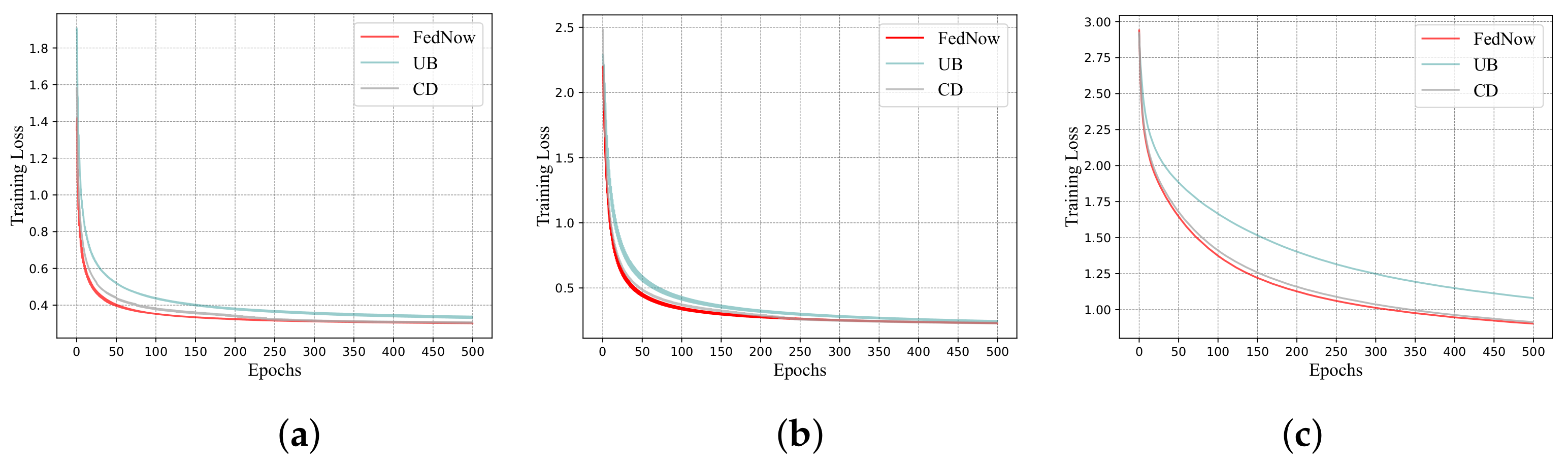
Algorithm 2 describes the training process of FedNow when computing the optimal model parameters. The time complexity of the Monte Carlo method is
, where
N means the number of sampling times. For a strongly convex objective
, the general upper bound of global iterations is expressed as
[
43], which is affected by both global accuracy
and local accuracy
. Given a fixed global accuracy
, the upper bound of the local iterations, i.e.,
, can be normalized to 1 so that
[
16]. We represent the time used for one global iteration of FEL as
; the upper bound of the time complexity for Algorithm 2 is
.
| Algorithm 2 The training process of FedNow |
![Applsci 14 00494 i002]() |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}